Привет! Меня зовут Юля, я работаю в дирекции больших данных Билайн, недавно я познакомилась с фреймворком Flink и хочу рассказать о своих впечатлениях на примере простой с первого взгляда задачи.
Итак, что же такое Flink?
Apache Flink – это фреймворк и движок для statefull вычислений над неограниченными и ограниченными потоками данных. Flink был разработан для работы во всех распространенных кластерных средах, выполняя вычисления с in-memory скоростью на любом масштабе данных.
Из основных моментов можно подчеркнуть:
программы можно писать как в параллельном режиме, так и пайплайнами
позволяет реализовать последовательность заданий (batch) и поток заданий (stream)
достаточно хорошо оптимизирован и обладает высокой пропускной способностью и низкими задержками
поддерживает приложения на Java, Scala, Python и SQL
задачи в Flink устойчивы к отказам и используют строго одну семантику
Flink не обладает собственной системой хранения данных, но использует коннекторы для различных источников данных, таких как Apache Kafka, HDFS, Apache Cassandra, ElasticSearch, Amazon Kinesis и другие.
Для разработки программ есть три основных API - DataStream API, Table API и Python API. В рамках данной статьи мы рассмотрим только DataStream API.
Постановка задачи
Соединить два Kafka потока – Green и Red. Каждый поток содержит сообщения с описанием события в своей системе. Каждое событие состоит из идентификатора события в системе, идентификатора сессии и времени совершения события. Важно заметить, что время совершения события близко, но не равно времени записи событий в топики kafka.
Выходной поток должен содержать пару событий совершенных ближе всего по времени в рамках одной сессии. Также для анализа хотелось бы хотелось бы записывать в отдельный поток все пары событий, которые не попали в результат.
Для MVP получилась вот такая схема:
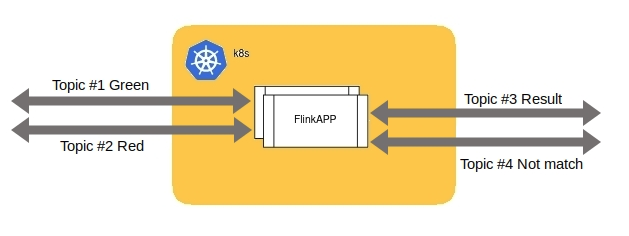
Первый подход
Так как нам нужно соединить потоки, первое, на что мы стали смотреть – join.
Flink предоставляет нам 4 основных вида соединений двух потоков:
1. Соединение с вращающимся окном (Tumbling Window Join) - задается размер окна, в функцию соединения передаются все пары в рамках окна с совпадающим ключом.

2. Соединение со скользящим окном (Sliding Window Join) – задается не только размер, но и смещение окна, в функцию соединения попадают все пары в рамках окна с совпадающим ключом.

3. Соединения с окном в виде сессии (Session Window Join) – задается зазор между сессиями, в функцию соединения также попадают все пары с совпадающим ключом.

4. Интервальное соединение (Interval Join) немного интересней - задаются границы интервала времени и для каждого события первого потока откладывается заданный интервал, соединение происходит если в рамках этого интервала во втором потоке находятся события с совпадающим ключом. На вход функции соединения подаются все пары совпавших событий.

Все соединения отдают пары значений в итоговый поток. Нам нужна только одна пара из всех совпавших событий в результирующем потоке. Наше соединение должно выглядеть примерно так:
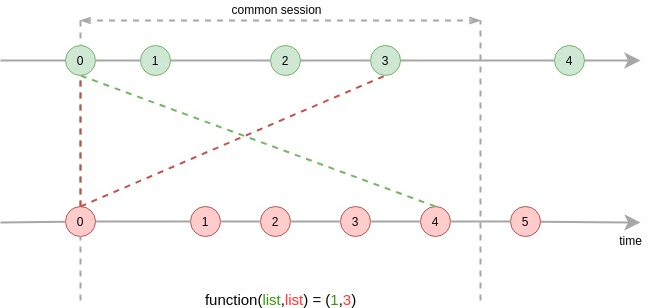
То есть соединять по интервалам времени обоих потоков и отдавать на вход функции не пары совпавших по ключу значений, а списки значений каждого потока в рамках ключа и интервала времени, в функции соединения прописать логику выбора лучшей пары из двух списков и отдать эту пару в результат соединения. На картинке лучшей парой оказались событие 3 из первого потока и событие 1 из второго потока.
Мы поняли, что стандартными джоинами не обойтись, придется придумывать что-то своё и спускаться чуть ниже в уровне абстракции.
Для того чтобы понять дальнейшие ходы решения, давайте рассмотрим некоторые ключевые концепты фреймворка.
Стейт
В Flink существует два основных вида - Keyed State и Operator State.
Operator State это данные записываемые каждым отдельным оператором, которые могут использоваться в обработке будущих событий.

Как видно из картинки, при обработке события (в данном случае оператором map) откладываются в сторону (в данном случае в распределенную файловую систему) некоторые данные, например при чтении из kafka это будут данные о партициях и оффсетах читаемого топика. Этот механизм позволяет увеличивать параллелизм программы “на лету” распределяя сохраненные данные между большим количеством операторов.
Но в рамках нашей задачи нам интересней рассмотреть Keyed State, ведь именно с ним мы будем дальше работать.
Keyed State, как следует из названия, всегда относится к ключам и может использоваться только в функциях и операторах разбитых по ключам потоков (KeyedStream). Это тоже данные в операторе, но каждая запись привязана к определенному ключу в потоке.
Оба вида стейта могут иметь одну из двух форм – регулируемый (managed) или сырой (raw), далее мы будем говорить о регулируемом стейте, так как он используется по умолчанию и в рамках нашей задачи нет необходимости переопределять операторы.
Flink предлагает нам пять видов объектов для хранения стейта это
1. ValueState<T> стейт хранит само событие
2. ListState<T> это список событий (тип также совпадает с типом события)
3. ReducingState<T> хранит одно событие, отражающее все события по этому ключу, при добавлении события вызывается функция свертки ReduceFunction.
4. AggregatingState<IN, OUT> также хранит одно событие, отражающее все события по этому ключу, но в отличие от ReducingState тип хранимого значения может отличаться от типа события в потоке, при добавлении вызывается функция агрегации AggregateFunction.
5. MapState<UK, UV> хранит события в структуре ключ-значение, типы не зависят от типа событий в потоке.
Process Functions
Процесс-функции (ProcessFunction) – это группа функций, каждая из которых является низкоуровневой операцией потоковой обработки, дающей доступ к основным строительным блокам всех (ациклических) потоковых приложений:
события (элементы потока)
стейт (доступен только при применении к потокам разбитым по ключам так как используется Keyed State)
таймеры (время события и время обработки, так же как стейт доступны только для потоков разбитых по ключам)
Процесс функции обрабатывают поток вызывая функцию processElement(…) на каждое событие. Таймеры позволяют приложениям реагировать на изменения времени обработки и/или времени события. Каждый вызов функции processElement(...) получает объект Context, который дает доступ к метке времени события и к TimerService. TimerService это сервис управления таймерами, можно зарегистрировать или удалить таймер по времени события или по времени обработки события, а также получить текущее время обработки и значение вотермарки. При срабатывании таймера вызывается функция onTimer(…). Таймер всегда привязан к ключу, во время обработки которого был создан, что позволяет при вызове onTimer(…) управлять стейтом данного ключа.
В случае соединения двух потоков доступны функции CoProcessFunction и KeyedCoProcessFunction, в них для каждого потока реализуется своя функция обработки элементов - processElement1(...) и processElement2(…).
Для решения нашей задачи мы реализовали KeyedCoProcessFunction со стейтом в виде списка (ListState) и таймером по времени событий.
class MatchingFunction(conf: ServiceConf, outputTag: OutputTag[String]) extends KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity] {
lazy val redState: ListState[RedEntity] = getRuntimeContext.getListState(new ListStateDescriptor[RedEntity]("red list", classOf[RedEntity]))
lazy val greenState: ListState[GreenEntity] = getRuntimeContext.getListState(new ListStateDescriptor[GreenEntity]("green list", classOf[GreenEntity]))
override def processElement1(red: RedEntity,
context: KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity]#Context,
out: Collector[ResultEntity]): Unit = {
if (greenState.get().asScala.nonEmpty && redState.get().asScala.isEmpty) {
context.timerService().registerEventTimeTimer((context.timestamp() / 1000) + 60)
}
redState.add(red)
}
override def processElement2(green: GreenEntity,
context: KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity]#Context,
out: Collector[ResultEntity]): Unit = {
if (redState.get().asScala.nonEmpty && greenState.get().asScala.isEmpty) {
context.timerService().registerEventTimeTimer((context.timestamp() / 1000) + 60)
}
greenState.add(green)
}
override def onTimer(timestamp: Long,
ctx: KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity]#OnTimerContext,
out: Collector[ResultEntity]): Unit = {
val redList = redState.get.asScala.toList.distinct
val greenList = greenState.get.asScala.toList.distinct
// here will be function logic
}
}
Для каждого потока создали стейт, важно заметить, что при создании стейта обязательно создается дескриптор. Далее реализовали функции обработки элементов в потоках, они делают одно и то же – проверяют, если в стейте соседнего потока есть события, а в стейте обрабатываемого потока событий нет, то запускается таймер, ну и обрабатываемое событие в любом случае добавляется в стейт.
Перед реализацией логики обработки по таймеру мы вспомнили что в случае чтения кафки в поток по умолчания за время события берется время записи события в кафку. Но в нашей задаче время записи в кафку не соответствует времени возникновения события и было бы удобно смотреть именно на время возникновения, а не на время записи.
Flink позволяет изменить механизм присваивания времени событию в любой момент обработки потока – для этого нужно реализовать интерфейс WatermarkStrategy с собственной логикой проставления времени события и генератором вотермарок. Давайте подробнее рассмотрим что такое вотермарка.
Watermark
Вотермарка (watermark) – запись, встроенная в поток и хранящая информацию о временной метке t. Значение вотермарки это флаг того, что время события в потоке достигло времени t и в этом потоке больше не должно быть событий с меткой времени t’<= t, то есть время всех следующих событий в потоке будет строго больше времени вотермарки.

У генератора вотермарки всего два метода, onEvent - когда приходит событие и onPeriodicEmit - периодически запускаемая функция.
Переопределив стратегию вотермарок мы добились того, чтобы время события бралось из одного из полей пришедшего события, но функция начала вести себя очень странно и непредсказуемо. Начав разбираться в причинах непредсказуемого поведения мы поняли, что мы не учли в своей новой логике того, что каждую партицию в кафке приложение читает параллельно и хоть в кафке в рамках партиции гарантированно время событий возрастающее, в наш поток они приходят без порядка времени. Коннектор Flink-Kafka решает эту проблему именно засчет стратегии вотермарок, которую мы решили переписать.
Поняв, что не стоит придумывать велосипед, мы вернули стандартную стратегию вотермарок и времени события на место, а таймер заменили на таймер времени обработки.
Также при разборе причин странного поведения функции мы увидели что в наших потоках встречаются опаздывающие события, причем время “опоздания” иногда превышает время таймера, то есть события могут добавляться в стейт после срабатывания таймера и оставаться там навсегда, ведь из соседнего потока по этому ключу уже ничего не придёт.
Получается даже при очистке стейта по таймеру размер нашего стейта будет расти со временем за счет этих необработанных событий. Давайте поподробнее рассмотрим как Flink хранит стейт.
State Backend
Flink поддерживает два основных типа хранения стейта:
HashMapStateBackend – используется по умолчанию, держит данные в виде структуры ключ-значение в памяти приложения (Java heap). Преимуществом является быстрый доступ к данным.
EmbeddedRocksDBStateBackend – держит данные в виде массива байт в базе данных RocksDB. Подходит для приложений с очень большим стейтом, оптимизирован для быстрого чтения, но имеет свои ограничения
Для приложений с большим стейтом используется EmbeddedRocksDBStateBackend, но засчет сериализации и десериализации объектов он примерно в 10 раз медленнее чем HashMapStateBackend
Посмотрев внимательно на опаздывающие события мы увидели что они почти никогда не попадают в “лучшую” пару и скорость обработки для нас важнее точности.
Опаздывающие события решили отбрасывать, в этом нам помогло свойство дескриптора стейта – время жизни (Time-To-Live). Создали конфиг и добавили время жизни к дескриптору стейта:
val ttlConfig: StateTtlConfig = StateTtlConfig
.newBuilder(Time.minutes(conf.timeToLiveStateMin))
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot()
.build
val redStateDescriptor: ListStateDescriptor[RedEntity] = new ListStateDescriptor[RedEntity]("red list", classOf[RedEntity])
redStateDescriptor.enableTimeToLive(ttlConfig)
lazy val redState: ListState[RedEntity] = getRuntimeContext.getListState(redStateDescriptor)
Теперь при добавлении значения в стейт начинается обратный отсчет заданного в конфиге времени, по истечении определенного нами времени объект в стейте помечается флагом на удаление и становится недоступным для чтения, при следующей сборке мусора или при следующем чекпоинте этот объект удаляется из памяти.
Side Outputs
По условию задачи кроме потока с лучшими парами, нам нужен поток для анализа все остальных обработанных результатов, в этом нам поможет механизм сбора побочных данных.
Он доступен при обработке потоков функциями:
ProcessFunction
KeyedProcessFunction
CoProcessFunction
KeyedCoProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
Для вывода нам нужно определить тэг вывода, важно заметить, что тип тэга должен совпадать с типом данных в побочном потоке. Мы сделали тэг “not-matched-events” со строковым типом:
val outputTag = OutputTag[String]("not-matched-events")Дальше добавили в функцию таймера логику сбора обработанных, событий в строку содержащую пару объектов из двух потоков и разницу во времени их возникновения.
Для получения потока побочных данных нужно вызвать тег от результирующего потока функции:
val sideOutputStream: DataStream[String] = resultStream.getSideOutput(outputTag)
sideOutputStream.addSink(sideSink)Итоговая функция и параллельное выполнение
В итоге функция соединения потоков выглядит вот так:
class MatchingFunction(conf: ServiceConf, outputTag: OutputTag[String]) extends KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity] {
val ttlConfig: StateTtlConfig = StateTtlConfig
.newBuilder(Time.minutes(conf.timeToLiveStateMin))
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot()
.build
val redStateDescriptor: ListStateDescriptor[RedEntity] = new ListStateDescriptor[RedEntity]("red list", classOf[RedEntity])
redStateDescriptor.enableTimeToLive(ttlConfig)
lazy val redState: ListState[RedEntity] = getRuntimeContext.getListState(redStateDescriptor)
val greenStateDescriptor: ListStateDescriptor[GreenEntity] = new ListStateDescriptor[GreenEntity]("green list", classOf[GreenEntity])
greenStateDescriptor.enableTimeToLive(ttlConfig)
lazy val greenState: ListState[GreenEntity] = getRuntimeContext.getListState(greenStateDescriptor)
override def processElement1(red: RedEntity,
context: KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity]#Context,
out: Collector[ResultEntity]): Unit = {
if (greenState.get().asScala.nonEmpty && redState.get().asScala.isEmpty) {
val timer = (context.timerService().currentProcessingTime() / 1000) + 60
context.timerService().registerEventTimeTimer(timer)
}
redState.add(red)
}
override def processElement2(green: GreenEntity,
context: KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity]#Context,
out: Collector[ResultEntity]): Unit = {
if (redState.get().asScala.nonEmpty && greenState.get().asScala.isEmpty) {
val timer = (context.timerService().currentProcessingTime() / 1000) + 60
context.timerService().registerEventTimeTimer(timer)
}
greenState.add(green)
}
override def onTimer(timestamp: Long,
ctx: KeyedCoProcessFunction[Long, RedEntity, GreenEntity, ResultEntity]#OnTimerContext,
out: Collector[ResultEntity]): Unit = {
val redList = redState.get.asScala.toList.distinct
val greenList = greenState.get.asScala.toList.distinct
val combined = for {
a <- redList
b <- greenList
} yield (a, b)
combined.foldLeft(None: Option[(RedEntity, GreenEntity)]) {
case (None, x) => Some(x)
case (Some((g0, r0)), next@(g1, r1)) if (g0.timestamp - r0.timestamp).abs > (g1.timestamp - r1.timestamp).abs => Some(next)
case (acc, _) => acc
}
.foreach { case (red: RedEntity, green: GreenEntity) =>
out.collect(
ResultEntity(
green.id,
red.id,
red.session,
red.address,
Math.min(red.timestamp, green.timestamp)
))
combined
.filter(tuple => tuple._1 != red && tuple._2 != green)
.map { case (red: RedEntity, green: GreenEntity) => (red, green, (red.timestamp - green.timestamp).abs) }
.foreach { case (wrongRed: RedEntity, wrongGreen: GreenEntity, diffTs: Long) =>
ctx.output(
outputTag,
s"not-matched: green($wrongGreen), red($wrongRed), diff=$diffTs"
)
}
}
redState.clear()
greenState.clear()
}
}
То есть у нас получилась вот такая логика работы функции:
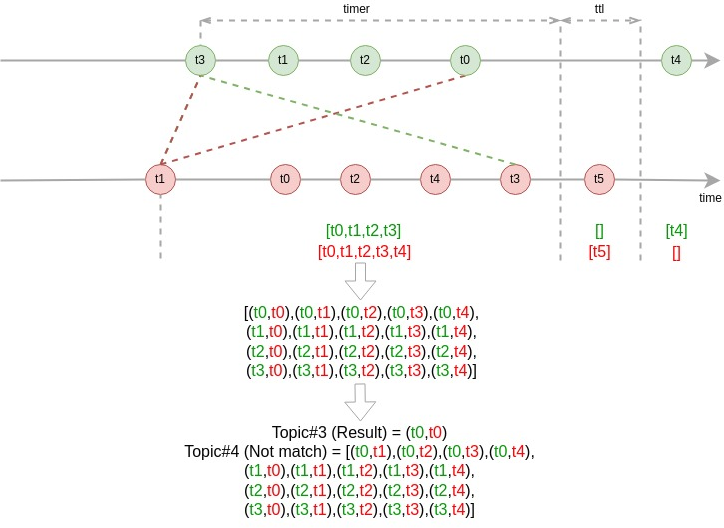
Замечу, что есть события, которые не попадают в итоговые потоки (даже в побочный поток для анализа), но в данном случае мы выбрали оптимальное соотношение скорости обработки к качеству выходных данных.
Ещё одним преимуществом Flink’а является масштабируемость. Если наши потоки сильно вырастут в размерах и текущее приложение перестанет успевать обрабатывать все приходящие данные вовремя, можно поднять параллельность выполнения. Для этого понадобится вызвать у оператора, который не справляется с нагрузкой метод setParallelism(num), где num - количество потоков, а Flink запустит параллельное выполнение копий этого оператора и распределит между копиями приходящие данные, если на это есть ресурсы. Также метод setParallelism можно вызвать у переменной среды выполнения, в этом случае параллелизм поднимется у всех операторов, объявленных после вызова метода.
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)Параллелизм всего приложения можно установить при запуске приложения на кластере и даже установить стандартное значение для всех приложений в настройках кластера.
Конечно, в случае операторов связанных со стейтом высокий параллелизм может привести к замедлению обработки, в рамках этой статьи мы не будем подробно разбирать тему параллелизма, но хотелось упомянуть о такой возможности.
Заключение
В итоге у нас получилось приложение, которое благодаря гибкости стейта соединяет два потока “на лету” в результате получая два потока - один с результатом, другой со строками для анализа. Данные читаются и записываются в кафку, а благодаря параллельному выполнению для любого количества данных можно подобрать оптимальное время обработки. Полный код примера можно посмотреть вот тут.
Конечно, в рамках одной статьи невозможно рассмотреть все особенности фреймворка, у Flink есть разные API и множество возможностей для реализации разного рода задач. Использование фреймворка отличается даже в рамках нашей компании, например, коллеги из блока по работе с данными используют в своих задачах Table API для потоковой обработки. Если моя статья найдет отклик, думаю они тоже захотят поделиться особенностями реализации своих задач.
