Привет, Хабр! Меня зовут Сергей Евсеев, сегодня я расскажу, как в Apache NiFi настраивается ETL-пайплайн на задаче с JSON’ами. В этом мне помогут инструменты Jolt и Avro. Пост пригодится новичкам и тем, кто выбирает инструмент для решения схожей задачи.
Что делает наша команда
Команда работает с данными по рекрутингу — с любой аналитикой, которая необходима персоналу подбора сотрудников. У нас есть различные внешние или внутренние источники, из которых с помощью NiFi или Apache Spark мы забираем данные и складируем к себе в хранилище (по умолчанию Hive, но есть еще PostgreSQL и ClickHouse). Этими же инструментами мы можем брать данные из хранилищ, создавать витрины и складывать обратно, предоставлять данные внутренним клиентам или делать дашборды и давать визуализацию.
Описание задачи
У нас есть внешний сервис, на котором рекрутеры работают с подбором. Сервис может отдавать данные через свою API, а мы эти данные можем загружать и складировать в хранилище. После загрузки у нас появляется возможность отдавать данные другим командам или работать с ними самим. Итак, пришла задача — нужно загрузить через API наши данные. Дали документацию для загрузки, поехали. Идем в NiFi, создаем пайплайн для запросов к API, их трансформации и складывания в Hive. Пайплайн начинает падать, приходится посидеть, почитать документацию. Чего-то не хватает, JSON-ы идут не те, возникают сложности, которые нужно разобрать и решить.
Ответы приходят в формате JSON. Документации достаточно для начала загрузки, но для полного понимания структуры и содержимого ответа — маловато.
Мы решили просто загружать все подряд — на месте разберемся, что нам нужно и как мы это будем грузить, потом пойдем к источникам с конкретными вопросами. Так как каждый метод API отдает свой класс данных в виде JSON, в котором содержится массив объектов этого класса, нужно построить много таких пайплайнов с обработкой разного типа JSON’ов. Еще одна сложность — объекты внутри одного и того же класса могут отличаться по набору полей и их содержимому. Это зависит от того, как, например, сотрудники подбора заполнят информацию о вакансии на этом сервисе. Этот API работает без версий, поэтому в случае добавления новых полей информацию о них мы получим только либо из данных, либо в процессе коммуникации.
Какими инструментами мы пользовались
Чтобы решить эту задачу, мы взяли Apache NiFi и HDFS/Hive, в процессе добавились Jolt и Avro. Apache NiFi — это opensource ETL-инструмент, который умеет работать со множеством систем, он работает в JVM в операционной системе хоста.
Архитектурно у него можно выделить следующие компоненты:
Web Server, на котором размещено API управления и контроля NiFi на основе HTTP;
Flow Controller — мозги NiFi, управляет его ресурсами;
Extensions — различные расширения NiFi, которые тоже запускаются в JVM. Например, Registry. В нем можно хранить наши пайплайны;
FlowFile Repository хранит всю информацию о флоуфайлах;
Content Repository — содержимое всех флоуфайлов;
Provenance Repository — хранилище историй о каждом флоуфайле.
А вот из каких элементов строится пайплайн в NiFi:
processor — функция, выполняющая операцию над входящим флоуфайлом и передающая его на заданные логикой выходы;
flowfile — сущность, состоящая из набора байт (content) и метаданных к нему (attributes);
connection — соединение между процессорами, очередь между флоуфайлами;
process group — набор процессоров и соединений между ними, из которого можно создавать более сложные пайплайны. Process group можно сохранять как шаблон, выносить в Registry или XML-файл и передавать коллегам для работы.
В NiFi из коробки очень много процессоров, которые могут выполнять разную логику. Процессоры можно разделить на следующие типы:
Data Ingestion занимаются генерацией или загрузкой данных из других систем в NiFi. Например, GetFile;
Data Transformation работают с содержимым флоуфайлов. К примеру, ReplaceText;
Routing and Mediation — направление, фильтрация, валидация флоуфайлов. Например, RouteOnAttribute;
Splitting and Aggregation - разделение одного флоуфайла на множество и наоборот. К примеру, SplitText;
Attribute Extraction — работа с атрибутами. Например, нужно прописать какую-то логику обработки атрибутов через regexp;
Data Egress/Sending Data — отправка данных из NiFi в другие системы. К примеру, PutFile.
Продемонстрирую все сказанное на примере. Идея пайплайна в том, что мы генерируем какой-то json и отправляем его в process group, где зашита логика, которая раскидает его по разным выходам в зависимости от типа json. (слайд 12.28)
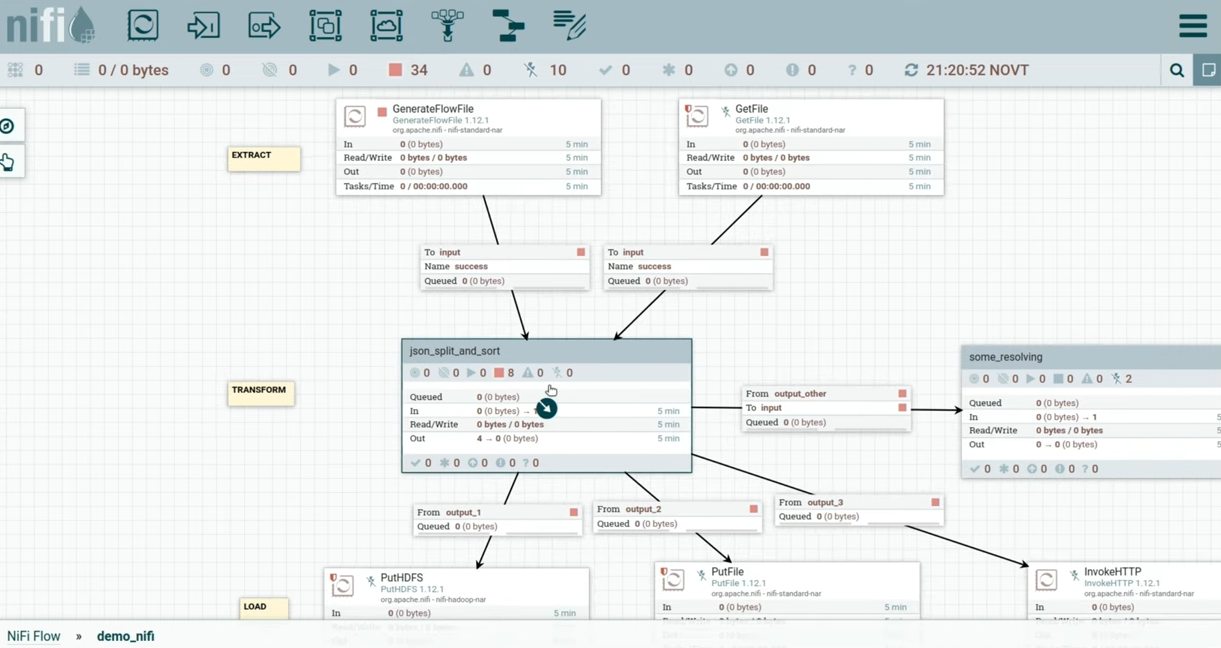
У меня есть процесс GenerateFlowFile. В нем я забил кастомный текст, это json. Внутри есть одно поле Data, в котором лежит по два поля — тип и id. Попробуем их обработать. Запустил процессор, флоуфайл упал в очередь, давайте его посмотрим. (слайд 13.10)
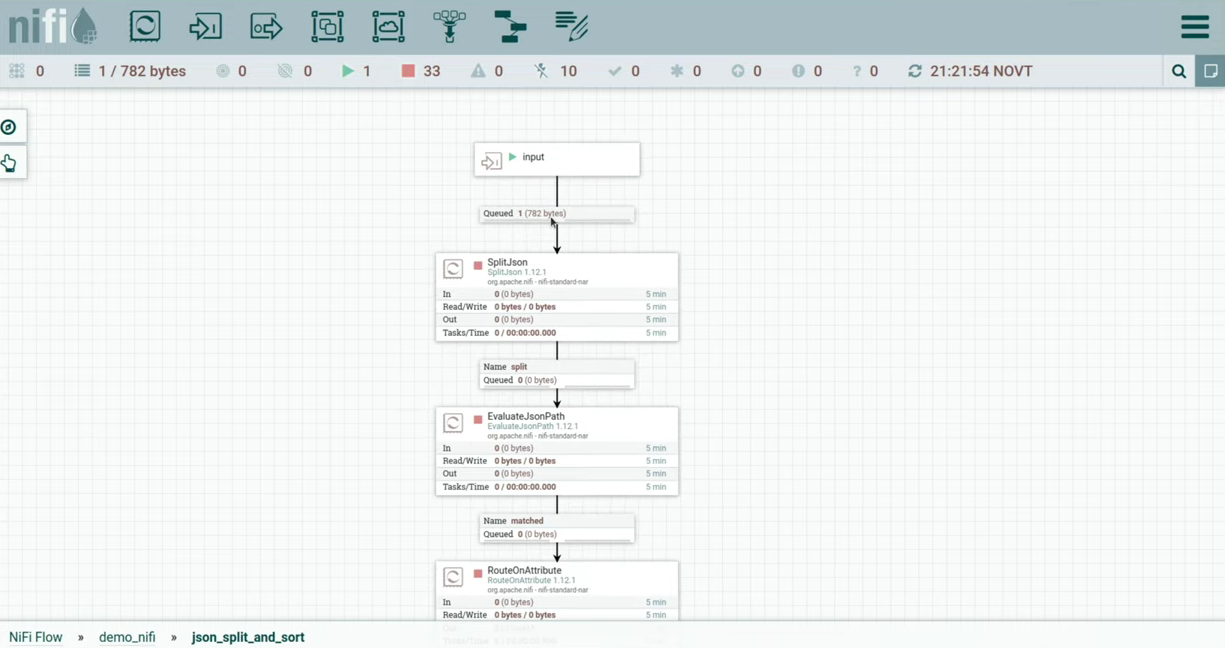
Дальше мы проваливаемся внутрь process group, запускаем в ней input и видим, что флоуфайл зашел в нашу process group. Отправляем ее в процессор SplitJson. (слайд 13.22)
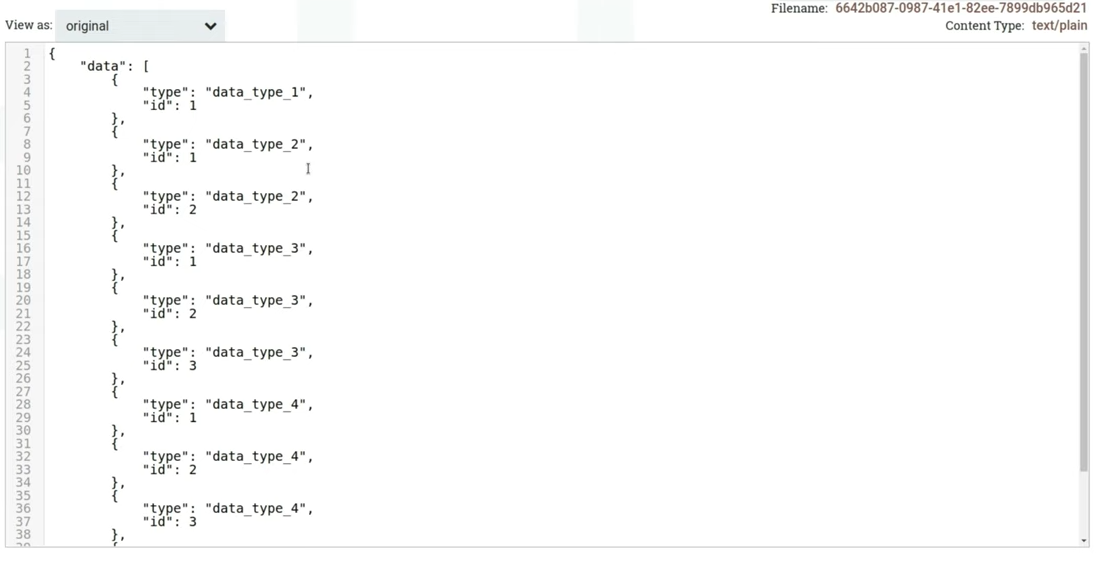
В настройках процессора мы указали JsonPath Expression — поле, на которое он будет смотреть при разделении json на отдельные флоуфайлы. Это будет поле data, в котором лежит массив. При запуске у нас появляется десять флоуфайлов, выглядеть они будут следующим образом (слайд 13.50)

Дальше необходимо извлечь наш тип из json в атрибуты. Указываем в property flowfile-attribute поле, из которого нужно извлечь данные, и атрибут, в который это нужно запихать — в нашем случае это data_type. При запуске появляется также десять флоуфайлов, контент не поменялся, но добавился атрибут data_type с содержимым data_type_1. Оно соответствует тому значению, которое лежало в поле data_type json’а. (слайд 14.20)
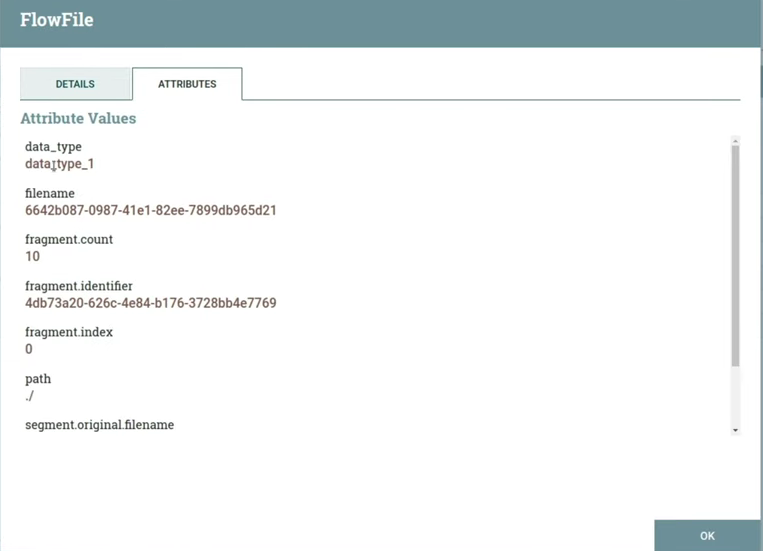
Теперь можем отправить это все в процессор RouteOnAttribute. В нем я создал три property, название каждой из которых соответствует типу из json. С помощью NiFi Expression Language я написал что-то наподобие if, где data_type — это имя атрибута, над которым нужно провести операцию, а метод equals сравнивает содержимое атрибута с заданной строкой ‘data_type_1’. (слайд 14.58)
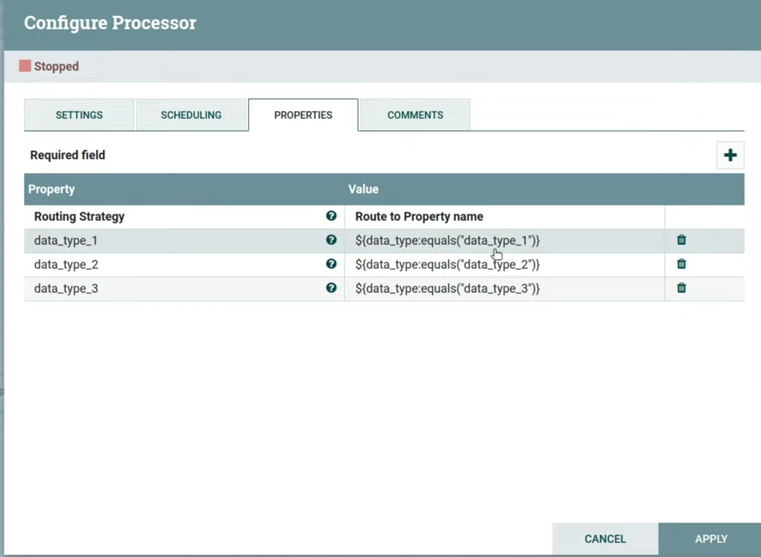
После запуска процессора можно заметить, что флоуфайлы разделились на разные очереди. data_type_4 не был прописан в property, поэтому он упал в выход unmatched. (слайд 15.23)
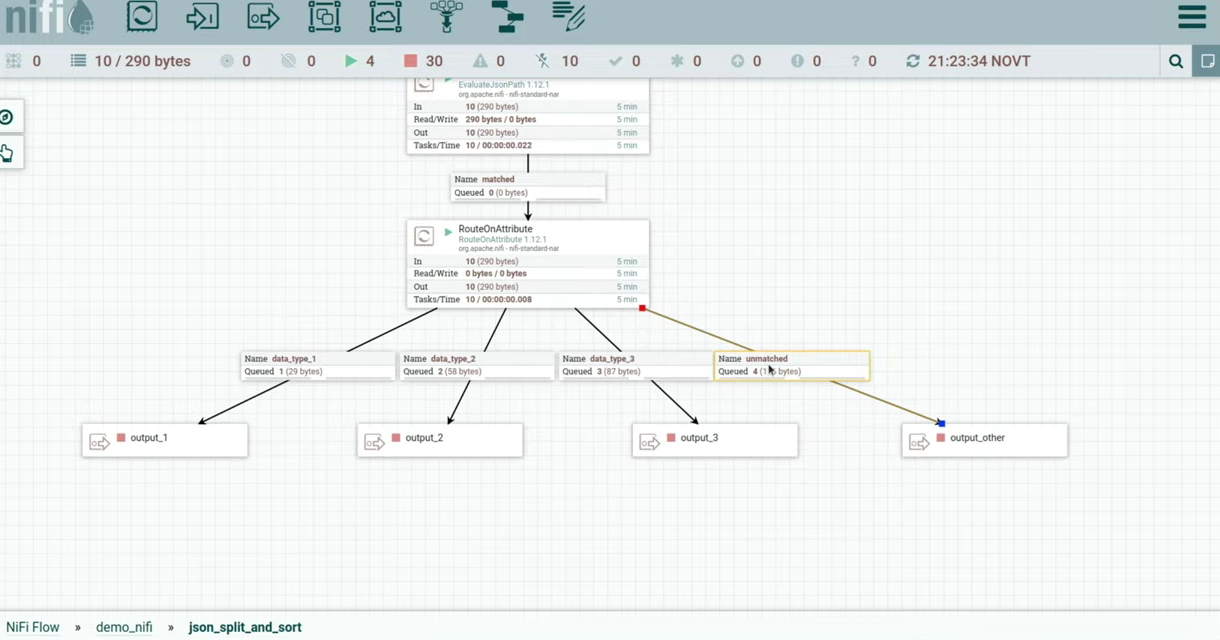
Запустим наши выходы. Видим, что флоуфайлы упали на различные процессоры, которые могут раскидать их по разным системам, в зависимости от типа из json. Также я замокал process group, в которой можно нарисовать логику resolve для unmatched флоуфайлов.
Avro
Avro представляет из себя систему сериализации данных. Avro-файл состоит из бинарных данных с прилагающейся avro-схемой, которая описывает эти данные в виде json. Ещё Avro поддерживает динамическую типизацию, то есть возможность десериализовать наши данные без описания данных в коде, например, за счет схемы, прилагающейся к файлу.
Система поддерживает и эволюцию схем — если соблюдать правила совместимости, то можно десериализовать файл со схемой, отличной от той, с которой файл был сериализован, и наоборот. Есть поддержка высокой скорости записи, это подходит для потоковых ETL-задач, например, Kafka. Часто встречаются случаи, когда NiFi работает с какими-то файлами, записывает их в Avro, а затем закидывает в Kafka. Тип хранения тут строчный, поэтому нужно осторожно подходить к аналитике больших объемов таких файлов, лучше преобразовать в другие форматы. Есть возможность автоматической генерации avro-схемы, что пригодится при работе с json’ами.
В нашей задаче можно использовать возможность создания hive-таблицы на основе avro-схемы. Можно закинуть json в Avro, автоматически сгенерируется avro-схема, на основе которой и будет создана hive-таблица. Также есть возможность менять avro-схему в основе hive-таблицы без необходимости изменения сохраненных данных.
Jolt
Иногда возникают проблемы, связанные с тем, что в json приходят разные типы или для записи в Avro не подходит структура. Тут нам пригождается Jolt — java-библиотека для трансформации json2json, использующая “спецификации” в виде json в качестве инструкции для преобразования. Используется в основном для трансформации структуры json-документа, но в новых фичах появилась возможность работы с конкретными значениями. Например, в NiFi из атрибута можно закинуть timestamp внутрь json. Кроме этого Jolt предоставляет нам возможность совершать цепочку трансформаций, например, сначала поменять структуру, затем сменить типы, а после — cardinality.
В нашей задаче с помощью Jolt мы сможем превратить nested json в prefix soup, сделать структуру json’а максимально плоской. А ещё — привести определенные поля к конкретному типу, то есть если в одном и том же поле в разных json приходят разные типы, то преобразовать их в один тип. Также можно изменить cardinality какого-то поля, например, поле, в котором может прийти string или array<string>, привести к array<string> — все входящие json’ы Jolt в этом поле сделает array<string>. Помимо прочего, можем обогатить данные за счет вставки в json значений из атрибутов флоуфайла.
Продемонстрирую, как может выглядеть шаблон такого пайплайна. Я замокал input, допустим, мы из какого-то источника забираем json следующего вида. (слайд 21.27)
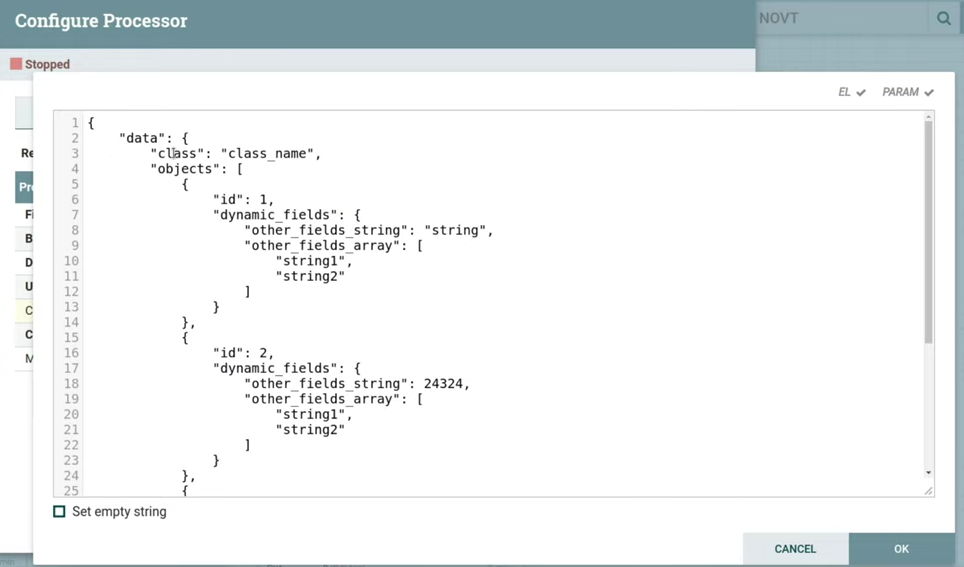
Нас интересуют объекты, которые находятся в поле objects. Внутри поля other_fields_string может приходить либо int, либо string; внутри поля fields_array — либо string, либо array<string>, также в dynamic_fields может вообще быть пусто.
Нам нужно привести все к единому виду для того, чтобы записать все в таблицу.
Мы получили флоуфайл, можем поставить UpdateAttribute, который укажет timestamp нашей загрузки или путь, по которому нужно сохранять любую нужную вам информацию. Так как мы здесь трансформируем json, я бы рекомендовал сохранить исходные данные в том виде, в котором они были загружены. Для этого я замокал process group, внутри которой можно реализовать логику сохранения сырых json в хранилище. (слайд 22.34)
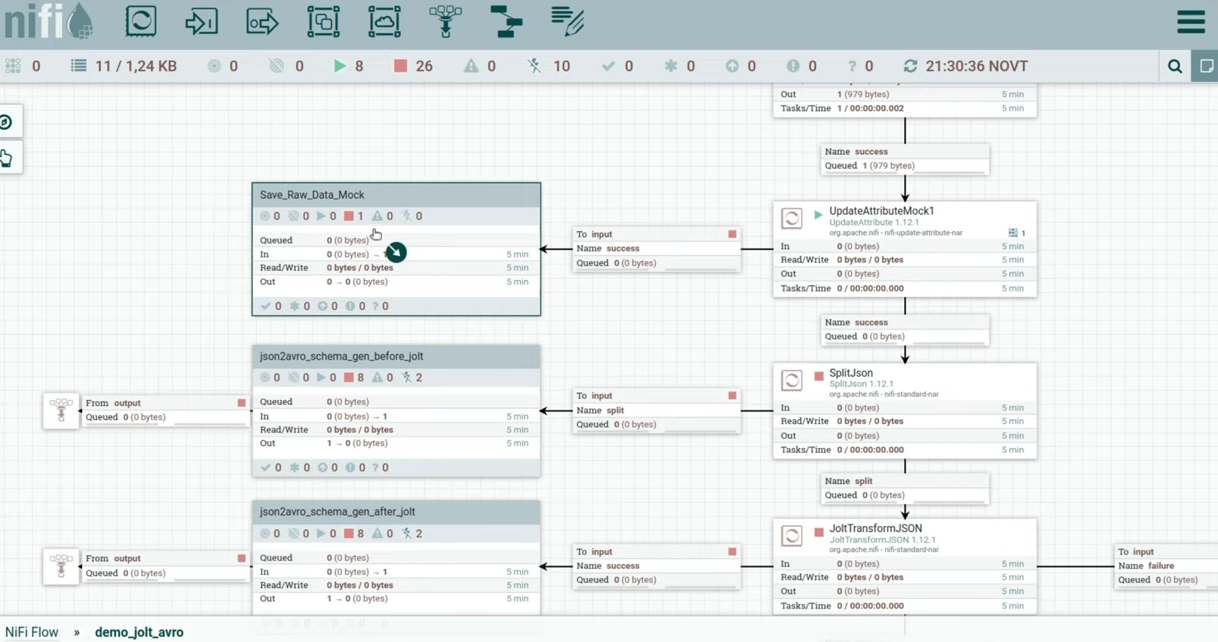
Убедившись, что наши данные сохранены и в случае чего к ним можно получить доступ, начинаем работу с json. Закидываем его в SplitJson, в котором указали, что нужно разбить на отдельные объекты и смотреть на поле objects, в котором лежит массив. После этого получается четыре json. В случае, если это json с тысячей полей, не хотелось бы пробегать глазами по каждому json и смотреть на типы. Лучше бы посмотреть, какая получится avro-схема, если сгенерировать ее для всех json. Для этого здесь есть process group, результат работы которой приведен ниже. (слайд 23.57)
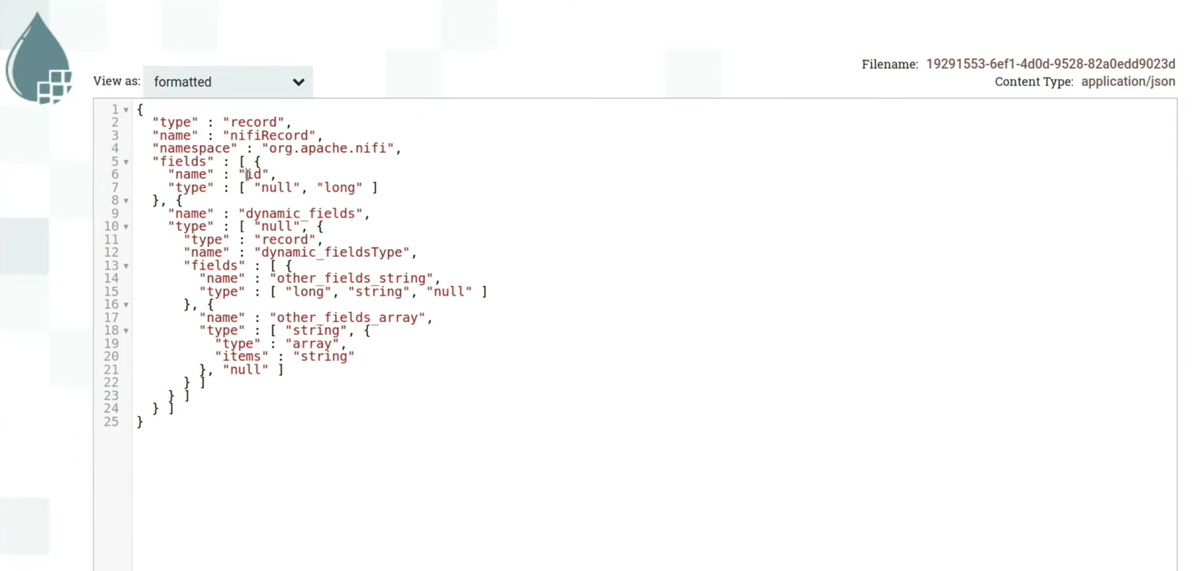
Avro-схема будет иметь такой вид. У нас будет набор полей в виде названий и типов этих полей. Так как id приходит всегда типа int, то видим здесь либо null, либо long. Null Avro всегда проставляет на случай отсутствия значения. Здесь видно поле dynamic_fields, внутри которого лежит структура из other_fields_string, принимающая либо string, либо long, либо null, и other_fields_array, принимающая string, array<string> или null. Выглядит сложновато, также непонятно, как это будет читаться в таблице. Попробуем привести это к более читаемому виду, для чего используем JoltTransformJSON.
Напишем для него спецификацию из трех действий:
Смещение, в котором мы указываем, что действия надо производить только с полями
dynamic_fields. Все поля внутриdynamic_fieldsнужно сместить на уровень выше с добавлением префиксаdynamic_fields(изarrayвdynamic_fields_array). Лежать они будут на том же уровне, что иid.После смещения мы можем применить к новым полям команду toString и преобразовать их только в строку.
После этого можем указать множественность. Нам нужно, чтобы в поле
fields_arrayвсегда был массив, поэтому указываем MANY.
Продемонстрирую изменения json’а до и после обработки. (слайды 26.51 и 26.54)


Попробуем теперь провернуть ту же операцию и сгенерировать общую avro-схему для всех json’ов. Видно, что теперь есть всего три поля, никаких структур внутри полей. Поля могут принимать типы null и long, null и string, а также null и array<string>. (слайд 27.28)
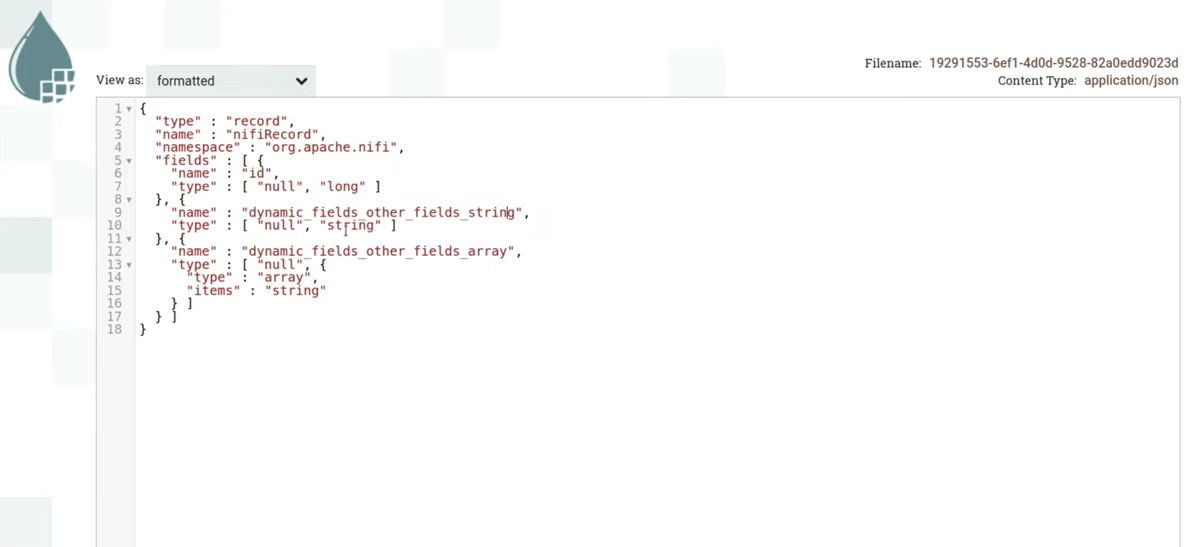
После того как мы сгенерировали эту схему, можем вписать ее в ConvertRecord — процессор, который занимается конвертацией из одного формата в другой. В данном случае используется JsonTreeReader, в нем указана avro-схема, с которой мы хотим читать json. В случае если все соответствует схеме, ConvertRecord прочитает нужной схемой эти json’ы и сериализует их в Avro. Внутри Content уже будет лежать наш avro-файл. Так как NiFi умеет десериализовывать avro, то можно форматировать контент и увидеть, что внутри лежит json в красивом виде. (слайд 29.02)
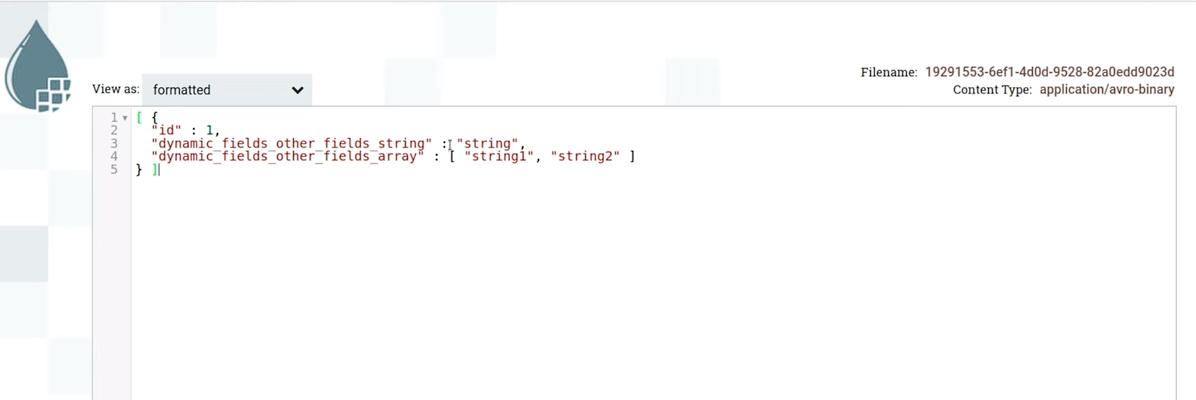
Для примера, если помните, dynamic_fields раньше был пуст. В случае с этой схемой мы увидим поля с null. То есть avro создал что-то наподобие json, указал поля из схемы и прописал им null. Когда мы будем читать это таблицей, эти поля будут null внутри, потому что в файле не было никаких значений для них. (слайд 29.35)
Дальше мы отдаем на выход в какое-нибудь наше хранилище. Замечу, что у каждого процессора есть несколько выходов, это могут быть success, failure и другие. Если упало что-то с ошибкой, мы увидим эти флоуфайлы в исходном виде и сможем провести какие-то дополнительные преобразования и отправить заново, например. Также у Jolt Transform Demo есть кнопка Advanced, где можно поэкспериментировать с различными спецификациями.
Итого
При создании нового пайплайна есть много ручника: мы должны посмотреть, какой json получается, написать спецификацию для обработки, сгенерировать или подредактировать вручную avro-схему. В текущей реализации нужно добавить мониторинг для появления в json новых полей. В примере, который я показал, если придет что-то с другими типами, это не поломает схему — он просто не прочитает это. Но если источник не хочет сообщать о новых полях и придется самим отслеживать их, тогда мониторинг нужен.
Стоит заметить, что такое решение подходит для слоя приземления данных, но требует последующей очистки и сохранение в форматах, которые лучше подходят для аналитики. В этом плане больше пригодятся колоночные типы. Также NiFi поддерживает кастомные процессоры. Разработчик может написать собственный процессор, собрать его в NAR-файл, положить под наш instance NiFi и использовать в своих пайплайнах.
