
Привет! Меня зовут Михаил, я младший разработчик в отделе разработки баз данных БФТ-Холдинга. Недавно мне поручили собрать результаты запросов в один файл. Единственное условие: эти запросы абсолютно разные. Они все агрегирующие, но с разным количеством столбцов и типами данных. Классический сценарий исполнения этих запросов выглядит так: я исполняю их через любой менеджер БД и записываю результат в один файл. Это слишком скучно и муторно, поэтому я решил написать программу, которая делала всю скучную работу за меня.
Составляем техническое задание
В начале разработки определяемся с требованиями. Скрипт должен подключаться к базе данных, выполнять запрос, записывать его в csv-файл. И так по всему списку.
Т.к. работать придется с PostgreSQL, в первую очередь надо установить psycopg2 — библиотеку для подключения к БД.
> pip install psycopg2-binary
Пишем подключение к базе данных
После установки библиотеки я приступил к настройке подключения. Для начала вспомним пару моментов:
Структура json очень похожа на
dict, поэтому их можно легко приводить друг к другуСловарь представляет пару ключ-значение
Для подключения к базе данных в библиотеке
psycopg2используется методconnect(), в который необходимо передать значения для подключения по типу ключ-значение, например user:postgres
То есть я могу использовать словарь с данными для подключения, вынесенный в отдельный файл. Назовем его config.
config.json
{
"host": "255.255.255.255",
"port": "5432",
"database": "postgres",
"user": "postgres",
"password": "TOP_SECRET"
}
Здесь очень важно, чтобы название полей были написаны прописными, а не заглавными буквами. В таком случае аргументы в psycopg2.connect() можно передавать через **kwargs. То есть выглядеть это будет как **config и для функции: host=”255.255.255.255”, port=”5432”, и т.д.
Плюсы:
Экономим 4 строчки кода
Проще редактировать данные для подключения
Безопаснее, т.к. можно добавить
config.jsonв.gitignore
Так выглядит подключение в коде:
def load_config():
# Открываем файл с конфигом в режиме чтения
with open('config.json', 'r') as config_file:
# С помощью библиотеки json читаем и возвращаем результат
return json.load(config_file)
def db_connect(config):
try:
with pg.connect(**config) as conn:
with conn.cursor() as cur:
# Здесь запрос
except Exception as e:
print('Ошибка при подключении:', e)
Что мы здесь видим? Во-первых, оболочку try/except, чтобы в случае проблем с запросом, мы получили сообщение с ошибкой в консоли. Во-вторых, двойной with, который сначала создает подключение к БД через **config (мы его читаем функцией load_config), а потом создаем курсор.
Такая конструкция экономит нам две строчки cur.close() и conn.close() и выглядит куда опрятнее, чем:
def db_conn():
conn = psycopg2.connect(user='postgres',
dbname='postgres',
host='255.255.255.255',
port=5432,
password='TOP_SECRET')
cur = conn.cursor()
# запросы
cur.close()
conn.close()
Получаем запросы из .sql файла
Мы подключились к базе данных. Теперь нам нужно получить запросы из .sql файла и передать в метод .execute().
Примерно так выглядит задание на этом этапе:
Скрипт должен по очереди выполнять SQL-запросы из файла
input.sql;Скрипт должен записывать результаты запросов в
.csvс формируемым названием: контур_система, по которой делается запрос_сегодняшняя дата;Один запрос может возвращать несколько строчек, поэтому все эти строчки должны быть объединены заголовками;
Между этими заголовками надо добавить пустую строчку.
Пример файла input.sql:
select
'table1' as table_name,
increment_id,
source_system_cd,
count(increment_id) as increment_id,
count(source_id_access_level) as source_id_access_level,
count(external_id) as external_id,
--и другие столбцы
count(source_party_type) as source_party_type,
count(_update_ts) as _update_ts
from buffer_table_access_level
where increment_id = %s
group by increment_id, source_system_cd;
select
'table2' as table_name,
increment_id,
source_system_cd,
count(source_party_type) as source_party_type,
count(source_system_cd) as source_system_cd,
count(external_id) as external_id,
--и другие столбцы
count(source_id_citizenship) as source_id_citizenship,
count(is_deleted) as is_deleted,
count(increment_id) as increment_id
from buffer_table_persons
where increment_id = %s
group by increment_id, source_system_cd;
Из input.sql мы можем понять следующее:
запросы разделены точкой с запятой,
у нас есть where, который будет меняться.
Как нам реализовать это в коде?
Сначала найдем нужные айди:
def get_increments(incur, sys):
select = '''select increment_id
from increments
where "source" like %s
order by start_load_ts desc'''
incur.execute(select, (sys,))
increments = incur.fetchall()
return [el[0] for el in increments]
Что тут происходит? Мы передаем в функцию курсор и систему, по которой производится поиск. Дальше выполняем запрос. Важно также заметить, что psycopg2 позволяет передавать переменные в запрос. За это отвечает конструкция %s, которую в .execute() мы должны обязательно передать в виде tuple. С запятой в конце: (переменная, )
Теперь, когда мы получили список айди, можем переходить к запросу:
from datetime import datetime as dt
def naming(action, system):
return f'{"uat" if action == else "prod"}_{system}_{dt.now().date()}.csv'
def exec(system, action, cur):
increment = get_increments(cur, system)
with (open('input.sql', 'r') as input_file,
open(naming(action, system), 'w', newline='') as csv_file):
queries = input_file.read().split(';')
csv_writer = csv.writer(csv_file)
for query in queries:
cur.execute(query, (0,))
csv_writer.writerow([desc[0] for desc in cur.description])
for inc in increment:
cur.execute(query, (inc,))
result = cur.fetchall()
if len(result) != 0:
csv_writer.writerows(result)
csv_writer.writerow('')
Давайте разберем код.
Импортируем библиотеку
csv, которая позволит записывать данные, которые передает методcur.fetchall()вoutput.csv.Инициализируем функцию и передаем в нее
system,action, о которых я расскажу позже. И уже известный нам cur.Открываем input и output. Заметьте, что (1) при помощи
with, можно одновременно открыть два файла и (2) output имеет динамическую генерацию названия файла.Читаем запросы из
input.sqlметодом read() и разделяем по точке с запятой методомsplit(). Получаем список запросов и передаем его в переменную queries. Вызываем методcsv_writer()из библиотекиcsv, который будет записывать наши данные в результирующую таблицу.
Первый цикл проходится по всем запросам, делает пустой запрос, собирает заголовки колонок. Так мы узнаем названия столбцов. Но также можно взять столбцы с самого первого запроса, так будет чуть быстрее.
Второй цикл проходится по рабочим данным, делает запрос уже с необходимым айди и записывает все в таблицу. После проверки на наличие данных (вернул ли execute вообще хоть что-то) csv_writer проходится по всем таплам (от слов. tuple) из списка и по очереди вписывает в csv файл.

Пишем меню для консоли
Так как этим скриптом будет пользоваться моя команда, нужно продумать способ взаимодействия пользователя с программой. Сначала я думал сделать веб-интерфейс, но в итоге остановился на командной строке.
Для начала давайте вспомним несколько правил из опыта взаимодействия с любым терминалом.
Программа задает вопрос и ждет ответ от пользователя через двоеточие;
Значение по умолчанию находится в квадратных скобках;
Желательно добавить анимацию загрузки, чтобы не было ощущения, что программа «зависла»;
Можно еще сделать вечный цикл главного меню, чтобы командная строка не закрывалась после исполнения кода.
В целом, есть и другие правила проектирования CLI-интерфейсов, их тоже было бы полезно изучить. Если интересно, я присмотрел статью на Хабре на эту тему.
А мы приступим к написанию новой функции:
def main_menu():
global stop_animation
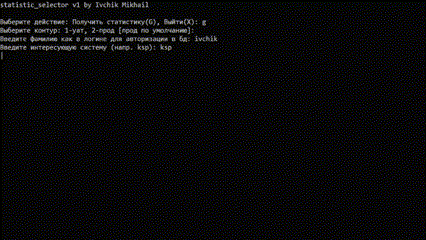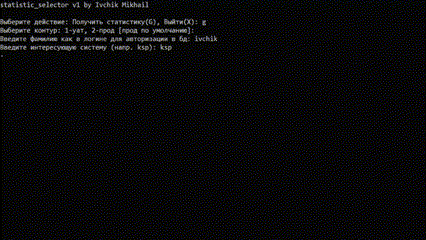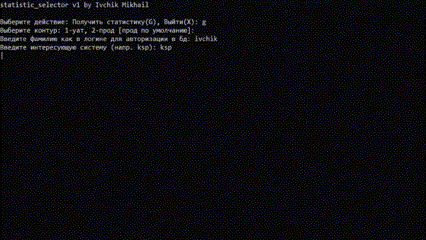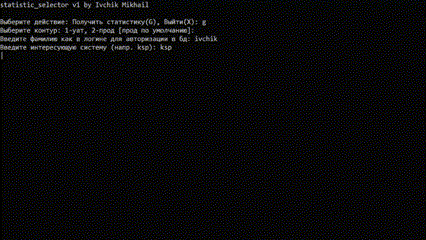
print('statistic_selector v1 by Ivchik Mikhail')
conf = load_config()
while True:
ask = input('\nВыберите действие: Получить статистику(G), Выйти(X): ')
if ask == 'G' or ask == 'g':
action = int(input('Выберите контур: 1-уат, 2-прод [прод по умолчанию]: ') or "2")
surname = input('Введите фамилию как в логине для авторизации в бд: ')
system = input('Введите интересующую систему: ')
conf['database'] = 'your_dbname1' if action == 1 else 'your_dbname2'
conf['user'] = f'{surname}_postfix1' if action == 1 else f'{surname}_postfix2'
animation_thread = threading.Thread(target=animation_func)
stop_animation = False
animation_thread.start()
db_connect(conf, system, action)
os.startfile(naming(action, system))
stop_animation = True
animation_thread.join()
continue
else:
break
if __name__ == "__main__":
main_menu()
Скрипт пошагово:
Выводим название скрипта, версию и имя разработчика;
Читаем конфиг;
Запускаем вечный цикл;
Задаем вводный вопрос пользователю. Тут обязательно прописываем возможность ввести прописную букву (хороший тон).
Кстати, конструкция int(input(‘Введите что-нибудь или введите ничего’) or ‘2’) вернет значение пользователя. Либо, если пользователь ничего не введет, вернет 2. Спрашиваем контур, логин и систему. Скрипт сам исправит значения в конфиге.
Немного про анимацию
Питон — однопоточный язык. Это значит, что пока не завершится один процесс, другой не начнется. Анимация – тоже процесс. Это значит, что, если мы выполняем какую-то функцию, например, делаем запрос, все остальные функции приостанавливаются. К примеру, если в функции запроса вставить цикл for, который бесконечно пишет «Привет», цикл начнет исполняться, то есть печатать в консоль «Привет» либо до запроса, либо после. Но не вместе с ним. Это очень важно понимать при работе с анимацией. Потому что анимация, повторюсь, тоже процесс.
Но анимация не может идти до или после запроса. Она должна отображать работу. Это простейшее правило пользовательского опыта.
Для того, чтобы запустить анимацию параллельно запросу, я использовал библиотеку threading, которая позволяет исполнять сразу несколько потоков. Сначала создаем функцию с зависимой глобальной переменной. Запускаем процесс в фоновом режиме перед запросом. Он крутится. Запрос выполняется. Мы меняем переменную на False. Анимация понимает, что крутиться больше не надо, и скрипт двигается к строчке continue.
Вот код анимации, нашел на оверфлоу:
def animation_func():
global stop_animation
animation = "|/-\\"
idx = 0
while not stop_animation:
print(animation[idx % len(animation)], end="\r")
idx += 1
time.sleep(0.1)
def run_animation():
animation_func()
В общем-то, все.
Чтобы обернуть скрипт в .exe файл со всеми зависимостями, можно воспользоваться библиотекой pyinstaller:
> pip install pyinstaller
> pyinstaller --onefile main.py
Делаем выводы
На практике такой простой скрипт может сэкономить уйму времени аналитикам или тестировщикам. Может показаться, что этот скрипт похож на union all в PostgreSQL, он имеет огромное преимущество: у вас нет ограничения в виде количества строк в запросе и возни с типами данных. Однако, скрипт требует небольшой доработки, в т.ч. можно добавить фильтрацию, графический интерфейс и оптимизировать запись столбцов. Но сама идея склейки нескольких запросов в одну таблицу, я думаю, поможет новичкам.
