Комментарии 20
С моей, как физика, точки зрения обучать роботов на визуальных примерах плохая идея. Миллиарды людей миллионы лет наблюдали физические явления и не продвинулись далеко пока огромными усилиями лучших умов человечества не были сформулированы законы в математическом виде. Существуют и очень широко используются программные движки физики в компьютерных играх и системах симуляции роботов. Вполне достаточно добавить такой движок в ПО робота для адекватной оценки обстановки и планирования поведения.
Насчёт обучения роботов физике Nvidia создала серию моделей Cosmos. Я бы не стал использовать существующие движки физики для игр, т.к. эти движки - набор хаков, которые годятся только для имитации
Движки физики разные бывают. Некоторые действительно только для простейших игр, но есть и очень продвинутые для точной симуляции и инженерных расчетов. Я оспорил принципе обучения роботов на визуальных примерах. Вытащить точные законы динамики и кинематики из них сложно. Куда проще зафиксировать уже готовые формулы. Нынешняя тенденция ML бери как можно больше данных и считай на как можно более быстрых GPU не кажется мне оправданной во всех случаях жизни. Конкретно с Nvidia Cosmos я не знаком, но думаю, что это более верный путь.
Да не проще. Кошка, прыгая на шкаф, формулы не использует, но учитывает очень много всего. Жидкость или газы попробуйте симулировать для сложных форм. Сколько на это ресурсов уйдет и какой будет результат? Нейросети уже это делают неплохо. Закладывать в них законы физики с одной стороны просто некуда, это же нейросети, а не императивный код, с другой - это как обучать шахматную программу на человеческих шахматных партиях. Может играть, но как человек, вперёд не продвинется. Только когда сама стала обучаться, появились сверхчеловеческие результаты. Интуитивное понимание физических законов есть у многих видов, а у нейросетей и роботов с этим плохо. Вот хотя бы для этого пусть смотрят видео и пробуют повторять. Аналитические же методы работы с физическими данными тоже нужны, но это другого типа задачи и они тоже должны сами этому обучаться, а не по чётким указаниям.
как раз Вы ошибаетесь! Делать кодовые вставки с математическими формулами расчета механики в готовые нейронные модели управления роботами не сложно. Как пример - добавление RAG (Retrieval Augmented Generation) дополнительной информации из внешних источников к LLM. В нашем случае это будут не новые данные, а готовые рассчитанные значения из физического движка.
я не против создания нейросетевых моделей физики, но их очень разумно дополнит готовыми и проверенными моделям движков физики. Как вариант они идеально ложатся на методы RL (reinforcement learning) обучения с подкреплением.
Как раз, шахматы наглядно доказывают, что вы неправы. Stockfish - самый сильный движок. То есть сочетание нейросетки с заложенными человеком правилами сильнее любой нейросетки.
Вовсе нет, поизучайте вопрос. Stockfish - довольно посредственный движок по сравнению с AlphaZero. "Из 100 игр с нормального начального положения AlphaZero выиграл 25 партий белыми, 3 чёрными и свёл вничью оставшиеся 72." В другом исследовании "Из 1000 партий AlphaZero выиграл 155 партий, 6 проиграл, остальные закончились вничью. В серии игр с заданными начальными положениями AlphaZero выиграл 95 партий из 100."
При этом AlphaZero знает только правила игр (кроме шахмат ещё и Го, сёги) и обучался, играя сам с собой, без каких-либо человеческих игр и указаний. Это даёт большое преимущество, так как следование шаблонам сильно ограничивает. В игре против чемпиона мира Ли Седоля AlphaGo (предыдущая, более специализированная на Го версия) сделала совершенно нелогичный с точки зрения человека 37-й ход, но он в итоге привёл к победе. Обучайся она только на человеческих партиях, она бы никогда так не пошла.
Это обучение - просто эксперимент в рамках исследования, а не решение какой-то прикладной задачи.
да я то не возражаю, а просто выражаю свое мнение. Ситуация будет полностью повторять проблемы с галлюцинациями GPT, а это совершенно не применимо в производстве! Цель Nvidia продать как можно больше, как можно более дорогих карт GPU но она противоречит успешному развитию робототехники!
Это Nvidia тормозит развитие робототехники? Вы явно не в курсе их разработок.
Сами Nvidia GPU очень полезны для ИИ, но чрезмерное увлечение сложными алгоритмами обучения на огромных корпусах видео данных, требующих огромных вычислительных ресурсов, не всегда оптимальны. Часто есть куда более простые и эффективные решения. В частности изобретать велосипед для создания нейронных моделей механики роботов не имеет смысла. Есть готовые, абсолютно точные формулы, не требующие вообще никаких вычислительных затрат. Использовать Nvidia GPU для расчета динамики и кинетики это стрелять из пушки по воробьям. С другой стороны нейронные модели не обладают ясностью, понятностью и вытащить из них простые зависимости положения, масс конечностей для расчета нужных движений будет не просто. Я поддерживаю исследования в области эволюционного моделирования движений искусственных созданий для создания паттернов вместо прямого копирования движений людей и животных.
У них создание роботов и перевод целых заводов на роботизированное управление с обучением всего в виртуальной реальности это основное направление сейчас. https://www.nvidia.com/en-us/industries/robotics/ Про проектs Eureka, Omniverse почитайте https://www.nvidia.com/en-us/omniverse/
Уж наверное, им виднее, что лучше для создания роботов.
Жалко, что писатели новостей уже забыли слово ИИ. Очередная нехорошая тенденция.
Извините, что влез.
Эти результаты ставят под сомнение фундаментальное предположение, выдвинутое некоторыми исследователями в области AI: что системам требуются заранее запрограммированные «базовые знания» о физических законах. V-JEPA показывает, что эти знания можно получить только путём наблюдения — подобно тому, как младенцы, приматы и даже молодые птицы могут развивать своё понимание физики.
В мозге младенцев и детенышей животных заложены некоторые априорные знания о свойствах среды обитания, и главное, способности к обучению. Дети с рождения знают об объектах, их константности, приблизительном числе, и многое другое (неполный обзор). Эти базовые способности предаются фактически наследственно, и развивается в ходе обучения. Средневековые представления об обучение с "чистого листа" давно не актуальна в этой области. Детеныши антилоп на равнинах пользуются такими скрытыми знаниями о среде почти сразу же после рождения. Через час они уже двигаются, маневрируют, прячутся, и тп, без особого обучения. Иначе на просторах стерпи или саванны они сразу же могут стать жертвами хищников. Человеку и другим млекопитающим, например, детеныши которых растут в норах, сразу двигаться не обязательно, но взаимодействовать с родителями необходимо. Это частично инстиктивное поведение, но в немалой степени, приобретенное во внутриутробном развитии мозга.
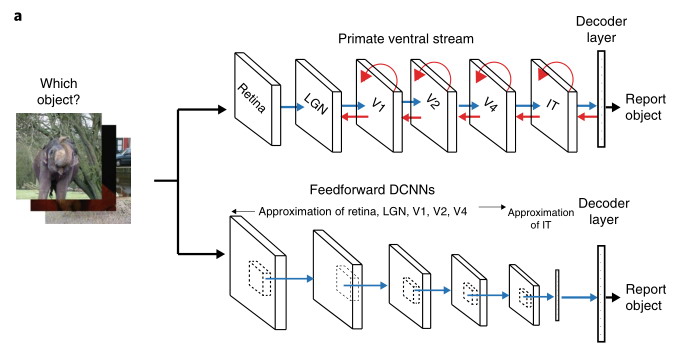
Нечто подобное закладывается и в архитектуру ИНС. Пример тому распознавание объектов с помощью сверточных сетей. Архитектура таких систем подобна строению вентрального тракта зрительной системы приматов. Т.е. в них уже заложена способность к распознаванию изображений, выделению объектов, фона, и др. Лекун сам занимался ими когда-то и ориентировался на нейробиологию, подзабыл)
{kind=link}
{kind=link}
Поэтому, на самом деле, нет сомнений, что в описываемой архитектуре такие способности к обучению также заложены, фрагмент статьи
Вместо того, чтобы генерировать идеальные с точки зрения пикселей прогнозы, V-JEPA делает прогнозы в абстрактном пространстве представлений — ближе к тому, как, по мнению Лекуна, человеческий мозг обрабатывает информацию.
Исследователи позаимствовали из психологии развития эффективный метод оценки под названием «нарушение ожиданий». Изначально этот подход использовался для проверки понимания детьми законов физики. Он показывает испытуемым две похожие сцены — одну физически возможную, а другую невозможную, например, как мяч катится сквозь стену. Измеряя реакцию удивления на эти нарушения законов физики, исследователи могут оценить базовое понимание физики.
Если архитектура разрабатывалась под такие возможности, то она уже содержит априорную информацию о входе, о способе обработки при обучении, и выводе. Хотя биологические сети мозга не только организованы структурно при рождении, но и частично настроены в процессе эмбрионального развития благодаря их спонтанной активности (здесь подробнее на эту тему).
Ну вот из статьи не понятно, как они борятся с тем, что сеть может сойтись к тривиальному решению, при котором семантическое представления (на схеме это блок extract representations) обнуляется и разница между предсказанным и вычисленным значениями тогда тоже становится равным нулю (в этом случае функция потерь минимизируется). Нашел пока для этого хороший термин : «коллапсом представлений».
Искусственный интеллект учится понимать физику: как AI развивает интуитивные знания о мире