
Какой смысл в BIG DATA и аналитических моделях машинного обучения, если информация вовремя не попадает к разработчикам, бизнес-аналитикам и руководителям? Если в вашей компании время передачи информации к специалистам по тестированию, развертыванию и поддержке занимает дни, а не секунды, пришла пора задуматься о внедрении практик DataOps (DATA Operations, датаопс).
Чтобы ближе познакомить вас с современными инструментами обработки и передачи информации, мы подготовили перевод ключевых тезисов из статьи «DataOps — что это такое и почему вам это должно быть интересно?».
Что такое DataOps и почему он звучит так похоже на DevOps?
DevOps — это набор принципов, лучшие практики и инструменты, которые помогают компаниям быстро разрабатывать и доставлять ПО. Суть этого подхода заключается в максимальной автоматизации продуктового жизненного цикла — создания, тестирования, развертывания и т. д.
Ключевые термины здесь: непрерывная интеграция (CI) и непрерывная доставка (CD) ПО, используя ИТ-ресурсы по мере надобности (инфраструктура-как-код). Отсюда и название — «DEVelopment» + «OPerationS»/IT.
DataOps описывают как DevOps, только применительно к данным. Продукты данных (data product) добавляют больше переменных в процессы, относящиеся к доставке ценности, а не к ПО.
Разберемся в этом подробнее.
Да, наша цель всё та же: доставлять ценность быстро, предсказуемо и надежно. Однако DataOps решает проблемы не только с помощью доставки в виде версионированного кода ваших задач по поглощению и преобразованию данных, моделей и аналитики, но и с помощью самих данных. Этот подход помогает найти баланс между гибкостью и управлением — одна ускоряет доставку, а другая обеспечивает безопасность, качество и доставляемость ваших данных.
Отметим несколько моментов, важных с точки зрения смены восприятия разных компонентов конвейера данных:
- Извлечение, загрузка, преобразование (Extract, load, transform — ELT). Данные нужно загружать как есть, без ненужных преобразований внутри хранилища или озера данных. Это ускоряет загрузку и упрощает задачи поглощения информации. Также наша задача — не отбросить то, что позднее может оказаться ценным, сохраняя исходную версию данных вместе с преобразованной и подготовленной к анализу. В некоторых случаях не избежать определенных преобразований по требованию регулятора — тогда вы увидите аббревиатуру EtLT. Если рассуждать в том же ключе, то данные вообще не удаляют. Как вариант, их сохраняют в относительно недорогих хранилищах.
- CI/CD. Знакомым с DevOps спецам будет в новинку концепция жизненного цикла объектов из базы данных. Современные платформы данных вроде Snowflake предлагают продвинутые возможности, например, функции time travel и zero-copy clone. Также есть решения для версионирования и ветвления озера данных, например, lakeFS.
- Архитектура и поддерживаемость кода. Речь о маленьких, повторно используемых фрагментах кода в виде компонентов, модулей, библиотек и прочего, что фреймворки предлагают в виде атомарных кодовых сущностей. По сути, каждая компания будет создавать свой репозиторий из таких компонентов и превращать их в стандарт для всех внутренних проектов.
- Управление средами. В DataOps очень важна возможность создавать из веток и эффективно поддерживать долгосрочные и краткосрочные среды.
В манифесте DataOps перечислено 18 общих принципов, которые выглядят как смесь принципов Agile и DevOps. Но чтобы применить всё это к конвейеру данных, придется сильно поменять мышление и начать думать о ваших данных как о продукте.
Чем отличается «продукт данных»?
Обычно какую-то новую работу, которая приносит бизнесу некую ценность, называют проектом. В некотором смысле конвейер данных и всё, что его окружает и связано с поддержкой поглощения данных, их потреблением, обработкой, визуализацией и анализом является набором маленьких проектов. Хотя правильнее было бы называть их продуктами. В чем ключевые различия этих понятий:
- Проект разрабатывается и управляется командой в течение какого-то времени, и когда проект доставляют, он заканчивается. А продуктом владеет какая-то команда, которая его поддерживает без конечной даты.
- У проекта есть область применения и цель, его могут выпустить несколько раз, пока он не достигнет своей цели. Когда это произошло, проект считается завершенным. А в продукт инвестируют, его развивают, получают обновления, делают обзоры и постоянно улучшают (как принято в Agile).
- Тестирование проекта ограничено определенным формализованным объемом. Тестирование продукта – это лишь часть процесса его выпуска; оно бывает модульное, регрессионное и интеграционное.
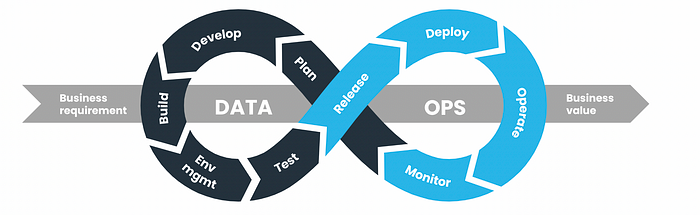
Если вы введете в поисковике запрос «DataOps», то найдёте вот такую диаграмму или ее варианты. Она хорошо иллюстрирует бесконечность процесса — планирование, разработка, тестирование и доставка кода. Также диаграмма говорит о необходимости сотрудничества с бизнесом (с заинтересованным лицами, имеющими отношение к продукту) на разных стадиях и о получении практичной обратной связи для использования в следующей итерации.
Как разобраться в обилии инструментов, фреймворков и языков?
Для создания продукта данных приходится использовать более крупные наборы технологий, чем в случае с отдельным программным продуктом. Они формировались естественным образом по мере того, как разные команды аналитиков, специалистов по обработке данных, инженеров по данным и разработчиков ПО искали лучшие варианты, которые удовлетворяли бы бизнес-требованиям и помогали им самим учиться и подниматься по карьерной лестнице.
Все инструменты и фреймворки так или иначе генерируют какой-то код. По крайней мере, если соблюдаются все принципы, у вас есть версионирование конфигураций и всё настроено так же, как и в любом другом программном проекте.
Трудности возникают при проектировании системы. Обычно данные поступают из разных источников и часто перемещаются по системе нелинейно, к тому же многие процессы могут исполняться параллельно.
DataOps помогает упростить это с помощью концепции центрального репозитория, который служит единым источником истины для любого кода и конфигурации в вашей системе — обычно это называют конвейером данных.
Если у нас есть такой всезнающий репозиторий с автоматической оркестрацией данных и обрабатывающих процессов, то выпустить изменение можно одним кликом мышки. Более того, становится значительно легче сотрудничать и отслеживать, кто и что делает, если мы сразу видим любые изменения, вносимые командами в разработку. Это снижает риск ошибок из-за недопонимания и повышает качество продукта данных.
Давайте посмотрим, как элементы DataOps собираются в единое целое с помощью «волшебного» репозитория.
Конвейеры
В DataOps есть два возможных типа конвейеров:
- Разработка и развертывание. Всё это вам знакомо из DevOps: CI/CD-конвейер для сборки, тестирования и выпуска контейнеров платформы данных, API, библиотек и т. д.
- Данные. Это конвейер, управляющий всеми компонентами (будь то запланированные задачи, постоянно работающие веб-сервисы или что-нибудь другое), который перемещает данные из пункта А в пункт Б и выполняет всю необходимую обработку. Возможно и весьма вероятно, что у компании будет немного таких конвейеров.
Задачи
Здесь больше всего переменных. Существует множество видов задач, в зависимости от того:
- какие технологии используются — Snowflake, Airflow, Python, HTTP…;
- что их инициирует — расписание, выполнение условия, непрерывное исполнение;
- где они исполняются — на собственном сервере, в частном облаке, в малоизвестной сторонней среде;
- как они обрабатывают ошибки;
- что определяет успешность.
Каталог данных
Количество и виды инструментов и сервисов в конвейере не имеет значения, важно лишь, чтобы они могли добавлять и понимать метаданные. Это своеобразный язык, на котором программные компоненты обрабатывают данные, взаимодействуя друг с другом, а также отличный источник отладочной и бизнес-информации.
Сотруднику, отвечающему за сопровождение конвейера, метаданные помогают определять, какие данные содержатся в системе, отслеживать их движение и диагностировать неполадки. Также метаданные позволяют бизнесу узнавать, какие данные ему доступны и как их использовать.
Есть инструменты для каталогизирования данных, составляющие каталоги с помощью машинного обучения. Эти инструменты должны уметь находить данные, отбирать, размечать, создавать семантические связи и обеспечивать простой поиск по ключевым словам среди метаданных.
Машинное обучение также может рекомендовать преобразования, автопровижининг данных и спецификации конвейера. Однако даже с помощью таких алгоритмов любой каталог хорош лишь настолько, насколько хороши данные и метаданные, с которыми он работает. Централизованно управляемый DataOps-конвейер всё «знает» о том, откуда поступает информация, как она протестирована, преобразована и обработана, где она заканчивается и т. д.
Наличие в вашем управляющем репозитории качественных метаданных и версионирования также гарантирует отслеживаемость и более высокое качество самих данных. Важно это поддерживать не только ради получаемой бизнесом ценности, но и ради внутренней культуры компании, чтобы заинтересованные лица доверяли вам.
Тестирование
Тестирование — ключевая концепция в DataOps. Оно должно быть автоматизировано и запускаться на разных стадиях до поступления кода в эксплуатацию. Важное отличие от DevOps заключается в том, что в DataOps оркестрация выполняется дважды: в первый раз применительно к инструментам, обрабатывающим данные, а во второй раз применительно к сами данным. То есть в двух конвейерах, описанных несколькими абзацами выше.
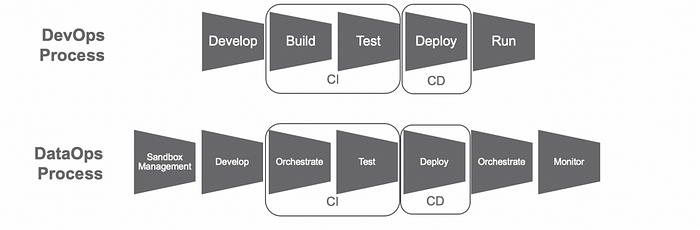
На этой схеме не показано, что для правильного регрессионного и интеграционного тестирования вам нужно выбрать репрезентативный набор данных, что само по себе нетривиальная задача, а потом его еще нужно анонимизировать.
Более того, часто возникают проблемы, которые можно отловить только на более поздних стадиях конвейера. Поэтому для интеграционного тестирования вам нужна практически сквозная система. А воспроизвести весь конвейер по состоянию на какой-то момент времени может быть слишком сложно технически и дорого. Это возможно в мире, в котором DataOps реализована в идеальном виде, но чаще всего ресурсов на не хватает. Наша цель — использовать этот подход как руководство при проектировании системы и постараться внедрить те элементы, которые принесут вам наибольшую выгоду и сэкономят больше всего времени, сил и денег.
Инструменты DataOps
В теории выглядит красиво, но как вообще подступиться к DataOps? На рынке для этого есть инструменты, которые соблюдают соответствующие принципы в той или иной степени. Самые заметные из них:
- Unravel — предлагает мониторинг и управление на основе ИИ. Проверяет код и дает рекомендации по тестированию и развертыванию. Инструмент для компаний, которые хотят сосредоточиться на повышении производительности своего конвейера.
- DataKitchen — скорее, применяется в качестве дополнения к существующему конвейеру и предоставляет обычные DevOps-компоненты вроде CI/CD, тестирования, оркестрации и мониторинга.
- DataOps.live — в дополнение к DevOps-компонентам этот инструмент предлагает некоторые элементы конвейера данных, такие как ELT/ETL, моделирование и соответствие требованиям регулятора. Если заказчики используют Snowflake, то они могут воспользоваться преимуществами версионирования базы данных и инструментов ветвления.
- Zaloni — в отличие от предыдущих двух, этот инструмент сосредоточен на конвейере данных и доставке всех его компонентов в рамках единой платформы. Нельзя сказать, что он не предлагает DevOps-компоненты. Напротив, это очень многофункциональный инструмент для компаний, работающих в условиях строгого регулирования.
И, конечно, для хранения и управления данными вы можете воспользоваться сервисами #CloudMTS: объектное хранилище, СУБД PostgreSQL и Redis, брокер сообщений Apache Kafka. С их помощью вы можете быстро, с нуля и без специфических знаний повысить качество управления бизнес-критичной информацией.

