

Всем привет!
На связи Михаил, и я продолжаю делиться историями про рефакторинг одного из сервисов облачной платформы #CloudMTS. В прошлый раз я рассказывал о том, как мы аккуратно раскладывали по папочкам код в соответствии с принципами чистой архитектуры. Сегодня поговорим о решении, которое позволяет нам распиливать монолит по кусочкам без простоев.
Вместо дисклеймера
Переход от монолита к микросервисной архитектуре — задача непростая. Особенно когда приложение уже в продуктиве. Пускаться в эту историю, потому что микросервисы — это стильно и молодежно, плохая затея. Стартуйте только тогда, когда преимущества трансформации будут очевидны и перевесят возможные издержки.
Наши причины перехода были следующими:
- В монолите концентрировалось большое количество бизнес-процессов, которые охватывали сразу несколько потребителей: пользователей облачной платформы, сейлз-менеджеров (через CRM-систему), администраторов, обработчиков метрик. Получилась такая одна большая точка отказа сразу для 4 групп бизнес-процессов.
- Каждый бизнес-процесс потребляет свой объем ресурсов. Например, для обработки метрик нужно 5 подов (чтобы запараллелить и ускорить обработку), для администрирования хватит и одного. Так как у нас все в одном сервисе, при масштабировании монолита мы будем ориентироваться на самый «прожорливый» бизнес-процесс. Часть ресурсов будет просто простаивать.
- Хотелось добиться гранулярности, чтобы независимо писать и деплоить код для каждого бизнес-процесса. И не переживать, что какие-то изменения в одном бизнес-процессе неожиданно отрикошетят в соседний.
Сестра, скальпель
Вытащить какой-то из доменов целиком за раз было нереально: они большие, связаны сразу с несколькими бизнес-процессами и перенос даже одного домена занял бы много времени. Потратить столько времени на рефакторинг мы не могли себе позволить. Поэтому мы ели слона по частям — отрезали домен по маленьким кусочкам (по одному endpoint, http-хендлеру) и добавляли его на фронтенд. Такой подход также упрощал тестирование перенесенных бизнес-процессов.
Получилось так, что часть бизнес-логики остается на старом сервисе, а часть уже живет на новом. Оба сервиса пишут данные в свои базы, и сервисам нужно как-то синхронизироваться.
Так у нас появилась задача синхронизации данных между двумя сервисами. Вот как мы ее решали.
Сервис А (монолит) в качестве базы данных использует MongoDB, сервис Б (микросервис) — PostgreSQL. Обмен изменениями происходит через Apache Kafka.
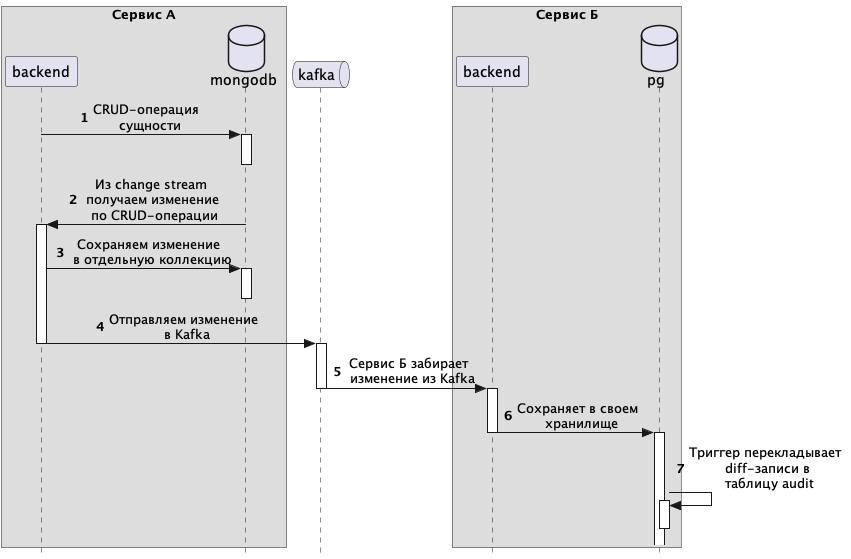
- На стороне сервиса А мы подключаемся к change stream коллекции нужной нам сущности.
- Изменение из change stream перекладываем в отдельную коллекцию и оттуда отправляем в Kafka. Отдельная коллекция нужна для аудита изменений и отправки в Kafka тех событий, которые не были отправлены по какой-либо причине.
- Consumer на стороне сервиса Б забирает данные из Kafka и перекладывает их в свое хранилище, PostgreSQL. Таким образом происходит передача данных для синхронизации из сервиса А в сервис Б.
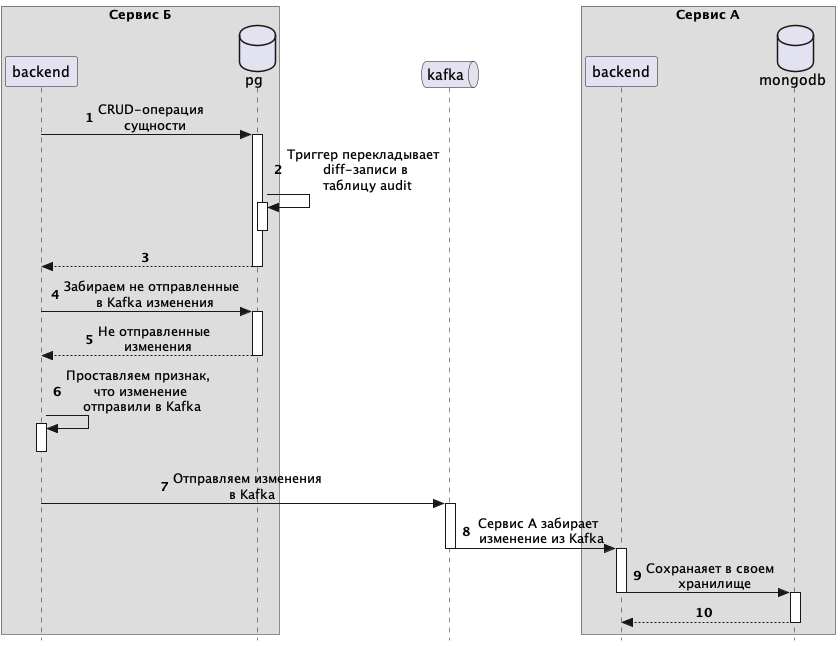
Похожий процесс происходит и в обратном направлении, разница лишь в том, что там не MongoDB, а PostgreSQL и другой инструментарий.
- Для каждой таблицы в PostgreSQL, которой нужна синхронизация, мы добавляем триггер:
Код под спойлеромcreate function on_table_row_change() returns trigger as $$ declare changed_fields text[]; changesCnt numeric; begin if TG_OP = 'INSERT' then insert into audit (table_name, val_id, operation, new_val) values (TG_RELNAME, new.id::text, TG_OP, row_to_json(new)::jsonb); return new; elsif TG_OP = 'UPDATE' then changed_fields = akeys(hstore(new.*) - hstore(old.*)); changesCnt = coalesce(array_length(changed_fields, 1), 0); if changesCnt = 0 or (changesCnt = 1 and coalesce(array_position(changed_fields, 'updated_at'), 0) > 0) then return new; end if; insert into audit (table_name, val_id, operation, old_val, new_val, changed_fields) values (TG_RELNAME, new.id::text, TG_OP, row_to_json(old)::jsonb, row_to_json(new)::jsonb, changed_fields); return new; elsif TG_OP = 'DELETE' then insert into audit (table_name, val_id, operation, old_val) values (TG_RELNAME, old.id::text, TG_OP, row_to_json(old)::jsonb); return old; end if; end; $$ language 'plpgsql';
Этот триггер записывает в отдельную таблицу audit все изменения, включая информацию о сделанной операции и предыдущем значении.
- В самих бизнес-процессах есть точки, в которых мы триггерим перекладывание изменений из таблички audit в топик Kafka. Например, такой триггерной точкой является успешное завершение CRUD-операций над бизнес-сущностями.
- На стороне сервиса А есть Consumer, который слушает топик Kafka с изменениями из сервиса Б и перекладывает эти изменения в MongoDB.
Оба сервиса отправляют и получают изменения из одного и того же топика. Чтобы сервис А не получал свои же сообщения, у сообщения есть поле source.
Общая схема движения данных из сервиса А в Б
Общая схема движения данных из сервиса Б в А
Последовательность упражнений, которые мы проделываем до начала переноса бизнес-логики.
- Описываем контракт топика Kafka, по которому будем передавать изменения. У всех сущностей он примерно одинаковый.
Код под спойлеромsyntax = "proto3"; import "google/protobuf/timestamp.proto"; message ChangeEvent { // Тип события enum EventType { UNKNOWN_EVENT_TYPE = 0; // Неизвестный тип CREATED = 1; // Создание сущности UPDATED = 2; // Изменение сущности DELETED = 3; // Удаление сущности } // Измененное поле enum Field { UNKNOWN_FIELD = 0; // Неизвестное поле FIELD_1 = 1; // Какое-то поле 1 FIELD_2 = 2; // Какое-то поле 2 } // Источник события enum EventSource { UNKNOWN_EVENT_SOURCE = 0; // Неизвестный источник SERVICE_A = 1; // Сервис А SERVICE_B = 2; // Сервис Б } // Бизнес модель message Model { string field_1 = 1; // Какое-то поле 1 string field_2 = 2; // Какое-то поле 2 } string id = 1; // ИД бизнес сущности EventType type = 2; // Тип события Model new_val = 3; // Состояние после события repeated Field changed_fields = 4; // Список полей который изменился EventSource source = 5; // Источник события google.protobuf.Timestamp changed_at = 6; // Время возникновения события }
- В сервисе Б создаем миграцию на добавление таблички. В ней будем хранить данные, которые переливаем в сервис А. Описываем все, как в конечном варианте: используем все необходимые constraint, foreign key, enum. На табличку вешаем триггер, который будет сохранять изменения в отдельной табличке audit.
- В сервисе Б пишем producer и consumer на топик с изменениями.
- В сервисе А пишем producer и consumer на топик с изменениями.
- Пишем интеграционные тесты на синхронизацию в обе стороны.
- Деплоим на прод, следим за алертами, consumer lag.
Когда убеждаемся, что синхронизация работает как часы, начинаем переносить бизнес-логику в сервис Б. Следом переключаем трафик на новый сервис.
Важные моменты
- Прежде чем браться за перенос бизнес-логики в новый сервис, нужно тщательно настроить и протестировать транспорт между сервисами через Kafka, настроить мониторинг и алертинг для ошибок. Речь идет об ошибках на уровне бизнес-логики, например, нет зависимой сущности, на которую имеется foreign key. Они обычно не исчезают сами по себе после ретраев, как ошибки, связанные с инфраструктурой (потеря связи с БД, например).
Такие ошибки могут вызвать скопление большого количества необработанных сообщений в топике Kafka и стать причиной рассинхронизации данных. Чтобы этого не произошло, настраиваем алертинг. Например, у нас настроено так, что Grafana присылает алерт в Telegram, если consumer lag больше 1 от 30 секунд до 1 минуты. - Consumer и Producer у нас реализованы на Go. У Go есть дефолтные значения (zero value) определенных типов данных. Например, для строки — это пустая строка, для слайса -nil. Возникает следующая небольшая, но сложность: как понять — мы имеем тут дело с zero value или это изменение с какого-то значения на пустую строку. Consumer сложно отличить первую ситуацию от второй. Чтобы Consumer понимал, с чем он имеет дело, мы передаем дополнительный массив строк, в которых мы указываем, какие поля изменились. Благодаря этому списку Consumer отличает zero value от значения, которое выставил пользователь.
- Нужно синхронизировать последовательность передаваемых изменений, чтобы не получилось так, что Consumer обработал изменение, которое произошло позже, раньше. Для этого ключом топика Kafka мы выбираем ID сущности.
- После возникновения изменения и до отправки его в Kafka мы иногда сталкиваемся со следующими ситуациями:
- мы получили изменение из change stream, но не смогли переложить его в коллекцию для аудита;
- мы переложили изменение в коллекцию для аудита, но не смогли отправить в Kafkа.
Чтобы преодолеть их, мы делаем следующее: когда сохраняем изменение в коллекцию для аудита, мы сохраняем сразу со статусом «изменение успешно отправлено в Kafkа« и в той же горутине отправляем изменение в Kafka. Если в Kafka отправить не получилось, то сбрасываем признак. Если сбросить признак не получилось, то это исключительная ситуация, алерт, на который необходимо реагировать.
Отдельно есть worker, который с определенным интервалом отправляет все неотправленные изменения после последнего успешного. Мы пока отказались от транзакций и более сложных реализаций гарантированной доставки в пользу более быстрой доставки изменений.
Какие еще варианты рассматривали для синхронизации данных?
Использовать готовые CDC. Мы писали свое решение на Go, но есть готовые инструменты, которые позволяют подключаться к БД, создавать события по триггеру и перекладывать их в Kafka. Например, Debezium. У него есть расширения для PostgreSQL и MongoDB. Также можно было бы использовать Confluent CLI как PostgreSQL Kafka Connector.
Любое из этих решений создало бы несколько проблем:
- Усложняется архитектура решения. При смене главного узла в кластере PostgreSQL нам придется дополнительно следить за Debezium: какие данные туда уходят, работает ли репликация, работает ли репликация после switchover/failover. Для этого придется допиливать мониторинг СРК, смотреть, как это влияет на производительность.
- Сложности при обновлении PostgreSQL. При обновлении баз данных, при смене мажорной версии протокол репликации и формат WAL-файлов могут меняться. Вплоть до полной несовместимости.
Ходить в базу напрямую. Мы создаем новый сервис, переносим туда бизнес-логику, но этот сервис продолжает ходить в БД старого сервиса, монолита. Это самый быстрый, но самый ненадежный вариант, так как связываем сервисы общей БД. У БД получается два потребителя. Если мы поменяем что-то у основного владельца этой базы (например, схему данных), то второй сервис перестанет работать. Получается, надо поддерживать любые изменения сразу в двух сервисах.
Заключение
Получилось рабочее решение. С одной стороны, у нас появилась история изменения данных, которая помогает в разборе инцидентов. С другой, есть двухсторонняя синхронизация данных между сервисами, которая помогает по более мелким кусочкам переносить бизнес-логику. Но также есть и проблема, которую мы пока не решили и не уверены, что будем решать: изменение из сервиса Б снова возвращается в сервис Б. Рабочей схеме оно никак не мешает, а сама конструкция — все-таки временное решение на период переноса бизнес-логики из монолита в микросервисы.


