
Сегодня хочу поговорить о том, как читать Service Level Agreement в договоре на облачные сервисы. SLA – это норма: клиенты требуют его на этапе запроса, провайдеры указывают заветные девятки во всех материалах. Отрицать не буду – без SLA плохо, но какие зоны ответственности затрагивает соглашение, не всегда понятно. Попробуем разобраться, что же это такое и когда бежать к провайдеру, размахивая договором, а когда искать проблему на месте.
Простой пример: у клиента перестает работать ВМ, клиент сразу думает, что проблема в инфраструктуре. И смотрит, что же там в SLA по поводу доступности. А может, на самом деле зависла ОС, клиентская сеть лагает, — предположить можно всё что угодно. Если проблема внутри ОС, то провайдер ресурсов тут не поможет.
Если мы не администрируем клиентские виртуальные машины, то и приложения внутри для нас – черный ящик. При этом самые частые отказы находятся как раз на стороне приложения. Может случиться что угодно: переполнятся диски, учетные записи заблокируются, DNS откажет, компоненты приложения перестанут взаимодействовать из-за неправильных настроек. А может оказаться, что системное время выставлено неверно или установилось ненужное обновление. Такие проблемы не являются нарушением SLA и решаются на стороне клиента. Так когда же он действует?
SLA – что это такое и для чего
SLA – это своего рода гарантийный талон на услугу. Но это не просто пункт с девятками в основном договоре. Это развернутое приложение, в котором фиксируются все параметры оказываемой услуги. Правильно составленное приложение страхует и клиента, и сервис-провайдера.
В SLA содержатся гарантированные значения основных параметров предоставления услуг. Важный момент: гарантированные – значит не ниже. Так, в SLA на виртуальную инфраструктуру учитываются показатели до операционной системы на клиентской ВМ. Операционная система и приложения внутри ВМ – забота администратора клиента. Если что-то сломалось, первым делом проверьте у себя. Поверьте, если поломается сама инфраструктура, то провайдер узнает об этом раньше вас через мониторинг.
В хорошем SLA на виртуальную инфраструктуру должны быть:
- Доступность виртуальных ресурсов и доступа в Интернет.
- Параметры виртуальной инфраструктуры и доступа в Интернет с допустимыми значениями.
- Способы измерения и мониторинга этих параметров.
- Приоритеты по инцидентам, запросам, краткое их описание и время на реакцию и устранение.
- Штрафные санкции при нарушении гарантированных параметров.
Начнем по порядку.
Доступность
Доступность – это те самые девятки, которые чаще всего выдаются за SLA. Проценты доступности переводятся в минуты и часы недоступности сервиса в месяц или год.
Например:
| Доступность | Простой в месяц | Простой в год |
|---|---|---|
| 99% | 7 час. 18 мин. 17,5 сек. | 3 дня 15 час. 39 мин. 29.5 сек. |
| 99,9% | 43 мин. 49,7 сек. | 8 час. 45 мин. 57 сек. |
| 99,95% | 21 мин. 54,9 сек. | 4 часа 22 мин. 58,5 сек. |
| 99,982% | 7 мин. 53,4 сек. | 1 час 34 мин. 40,3 сек. |
Все варианты можно посмотреть здесь.
Казалось бы, всё понятно, в чем же подвох?
Месяц или год. Не зря я наверху выбрал две колонки – месяц и год. Когда видите заветные девятки в SLA, обратите внимание, к какому периоду они относятся. Чаще всего провайдеры говорят о месяце. То есть при доступности 99% мы получаем 7 с лишним часов даунтайма в месяц, а не в год. Уточняйте этот момент, чтобы потом не было разочарований.
Девятки и инфраструктура. Если вам необходим определенный уровень отказоустойчивости сервиса, то и виртуальная инфраструктура должна быть построена таким образом, чтобы эту доступность обеспечивать. Так, для достижения уровня доступности 99,95% вам, как минимум, понадобится кластер active-passive. Если вы хотите перешагнуть за 99,982% (уровень доступности в дата-центрах Tier III), вам нужно строить систему, распределенную по нескольким ЦОД.
Выбирая конфигурацию виртуальной инфраструктуры, ответьте себе на вопрос: нужны ли вам пять девяток? Девятки не должны быть самоцелью. Во-первых, чем больше девяток, тем дороже для вас будет стоить система. Каждая следующая честная девятка будет добавлять нолик справа к стоимости! Во-вторых, не каждый сервис требует геораспределенного кластера.
Если вы выбираете облачные ресурсы, определитесь, какую задачу вы решаете сейчас: строите тестовую среду или холодный резерв или размещаете критические сервисы – интернет-магазин, платежную систему или CRM.
Совокупная доступность. Если ваше приложение имеет доступность 99,5%, облако имеет доступность 99,95%, а дата-центр, где оно развернуто, – 99,982%, то на выходе вы будете иметь доступность не выше 99,5%. Так как доступность всего сервиса не может быть выше доступности самого слабого его звена. Помните об этом при выборе сервиса и не пытайтесь лечить перелом подорожником. Защищенный геораспределенный кластер не спасет падающее через день приложение.
Не доступностью единой
Доступность для ИТ-сервисов – главный параметр. Но и при стопроцентном аптайме виртуальная машина может жестко тупить из-за сетевых задержек, недостаточного количества IOPS, высокой latency СХД и прочих проблем. Поэтому в правильном SLA должны быть все качественные метрики по инфраструктуре. На что смотреть и к чему стремиться?
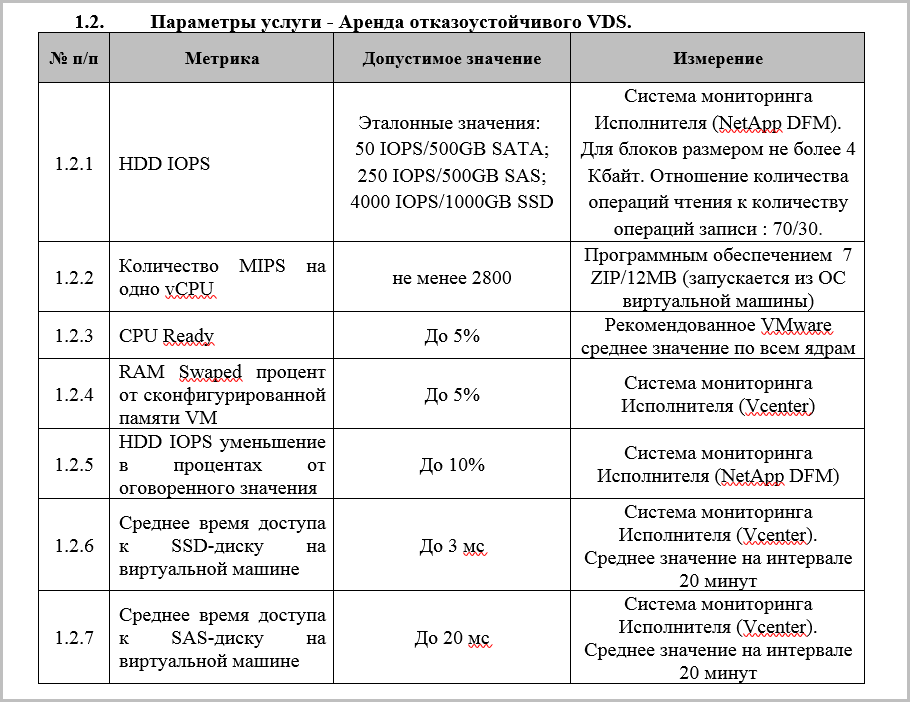
- Производительность vCPU. Определяется по числу обработанных запросов в секунду (MIPS – million instructions per second). Должно быть указано, как провайдер измеряет эти самые MIPS. По указанной величине вы можете сравнить предполагаемую производительность ядра ВМ со своим оборудованием.
- Допустимый процент размера файла подкачки (RAM Swap) от сконфигурированной памяти ВМ. Когда ваша ВМ вместо памяти получает файл на диске – это очень плохо. Этот пункт защитит ваши ВМ от критического падения производительности.
- Производительность СХД/IOPS. Измеряется, как правило, по количеству операций в секунду (IOPS – Input/Output Operations Per Second). Размер блока для чтения/записи разный у разных типов дисков. Также отличается и паттерн нагрузки: он определяется из соотношения операций чтения/записи во время теста. Тест проводится так: на диск посылается определенное количество параллельных процессов записи/чтения с определенной глубиной очереди. Результат: сколько операций ввода-вывода с блоком определенного размера СХД может обработать в один момент времени. Размер блока, количество процессов и паттерн нагрузки лучше зафиксировать в SLA для однозначности понимания параметра IOPS. Также в SLA фиксируется допустимое уменьшение IOPS от эталонного значения – не более 10%.
- Производительность СХД/Среднее время доступа к диску на виртуальной машине (latency). Этот показатель не менее важен чем IOPS. Более того, IOPS без указания latency имеет мало смысла. Представьте себе, что СХД будет отдавать на ВМ много блоков данных. Но редко. Задержки зависят от типа дисков СХД, но если они выше 50 мс, скорость работы ВМ вас не порадует, пора открывать раздел «Инциденты».
- Средняя сетевая задержка. Здесь критичным показателем будет 5 мс. Важно, что под SLA попадает только сетевая задержка в пределах сети передачи данных провайдера. Как правило, это участок до стыка с вашим телеком-провайдером.
- Процент потери пакетов. Потери пакетов – это ошибки в настройках систем или проблема в каналах связи, их быть не должно. Вместе с тем в отдельных случаях, например при бэкапе ВМ, могут возникать потери пакетов в течение ~секунды. Поэтому норма для этого параметра – в пределах от 0 до 1%. Как и в случае с сетевой задержкой, уточните у провайдера, где заканчивается его ответственность.
В SLA также следует прописать способы измерения и мониторинга по каждому параметру. Например, так:
Запросы, инциденты и технические работы
Сначала разведем понятия запрос и инцидент. Запрос – это заявки на штатные работы. Инцидент – когда что-то сломалось и не работает, например: машина сильно тупит или не пингуется. Если что-то сломалось у провайдера, то уведомление об инциденте приходит из системы мониторинга. Все запросы и инциденты разделяются по приоритетам. Это позволяет быстро реагировать на вопросы жизни и смерти и чинить все вовремя. Важно определить статус заявки на этапе ее регистрации. Как это устроено у нас, мы рассказывали в статье о службе поддержки.
Решение инцидентов. Все возможные поломки не предугадать. Но типовые причины недоступности сервиса должны быть прописаны в SLA. Еще раз отмечу, что соглашение затрагивает только неполадки на стороне провайдера и не распространяется на ошибки внутри ВМ. Все инциденты делятся по приоритетам, в зависимости от того, ведут они к полной недоступности сервиса или к частичной деградации. На каждый приоритет определяется максимальный срок устранения.
Если используете разные типы дисков, не забудьте прописать инциденты по каждому из них:

Пример инцидентов первого приоритета.
В нашем SLA на IaaS мы делим инциденты на три приоритета. Каждый обрабатывается в круглосуточном режиме, но время на исполнение разное.
Уточните у провайдера, как он считает время на исполнение инцидента, и проверьте, чтобы это было прописано в приложении. Как правило, временем исполнения считается время от уведомления клиента о регистрации инцидента и до момента его решения.
Кроме того, SLA может ограничивать число заявок, которое вы можете открыть у провайдера в месяц.
Обработка запросов. Все верно: в хорошем SLA прописано время на обработку запросов. Это нужно для того, чтобы правильно расставить приоритеты и не проморгать отключение сервиса за рутинными задачами. И защитить провайдера. Так как речь не идет об остановке сервиса, то в этот раздел часто не вчитываются, а зря. Именно здесь зафиксировано, что запросы принимаются в рабочие часы провайдера и на их решение отводится не меньше 12 часов.
Мы делим запросы на три типа, которые отличаются по характеру работ и времени исполнения:
- Запрос на обслуживание. Это работы по обслуживанию текущих ресурсов заказчика: восстановление ВМ из резервной копии, установка ОС, изменение настроек сети.
- Запрос на изменение. Работы по изменению состава услуг клиента по договору: добавление или удаление ресурсов, расширение или добавление новых ВМ. Сюда относится и изменение параметров SLA.
- Запрос на предоставление информации. Все отчеты по клиентской инфраструктуре и заявки на новые услуги.
Проведение регламентных работ и уведомление. Инфраструктура – это живой организм. Ее нужно обслуживать: апгрейдить, накатывать критические обновления, проводить плановые работы (например, обновлять прошивку на серверах). Не все работы можно сделать без остановки сервиса. Поэтому в SLA фиксируется порядок уведомления о таких работах, время проведения работ и возможное время перерыва в сервисе. Проверяйте, чтобы срок уведомления о плановых работах был достаточным и было зафиксировано максимальное время остановки сервиса.
У нас это выглядит так:

Наложение штрафных санкций. Штрафные санкции бывают двух типов: за превышение времени реакции на инцидент и за простой сервиса, в нашем случае виртуальной инфраструктуры. Чем подробнее описан порядок наложения санкций, тем безопаснее чувствуют себя и клиент, и провайдер. Если условия не понятны, задавайте провайдеру вопросы до подписания соглашения, чтобы не было сюрпризов и разочарований.
Если в SLA есть все описанные выше пункты, то вы получаете сервис с прозрачными гарантиями и уровнем доступности. Врать в SLA невыгодно, так как от штрафов отбрехаться не получится. Но и подогнать под SLA поломки из-за косных приложений или неправильной настройки ВМ не удастся.
Если есть вопросы, традиционно жду в комментариях. Здорового вам облака!
