
Привет! Меня зовут Асхат Нурыев, я ведущий инженер по автоматизации в компании DINS.
Я работаю в Dino Systems последние 7 лет. За это время пришлось заниматься разными задачами: от написания автоматических функциональных тестов до тестирования производительности и высокой доступности. Постепенно я стал больше заниматься организацией тестирования и оптимизацией процессов в целом.
В этой статье я расскажу:
- Что делать, если баги уже просочились на продакшн?
- Как побороться за качество системы, если ошибок уже руками не счесть и глазами не пересмотреть?
- Какие подводные камни встречаются при автоматической обработке ошибок?
- Какие бонусы можно получить от анализа статистики запросов?
DINS — это центр разработки компании RingСentral, лидера рынка среди облачных провайдеров Unified Communications. RingСentral предоставляет все для бизнес-коммуникаций начиная с классической телефонии, смс, митингов и заканчивая функциональностью контакт-центров и продуктов для сложного командного взаимодействия (а-ля Slack). Это облачное решение расположено в собственных дата-центрах, и клиенту нужно только оформить подписку на сайте.
Система, в разработке которой мы участвуем, обслуживает 2 млн активных пользователей и обрабатывает более 275 млн запросов в сутки. Команда, в которой я работаю разрабатывает API.
У системы довольно сложный API. С его помощью можно отправлять смс, совершать звонки, собирать видеоконференции, настраивать аккаунты и даже отправлять факсы (привет, 2019 год). В упрощенном виде схема взаимодействия сервисов выглядит как-то так. Я не шучу.

Понятно, что такая сложная и высоконагруженная система создает большое количество ошибок. К примеру, год назад мы получали десятки тысяч ошибок в неделю. Это тысячные доли процента относительно общего числа запросов, но все равно столько ошибок — непорядок. Мы их вылавливали благодаря развитой службе поддержки, тем не менее эти ошибки влияют на пользователей. При этом система постоянно развивается, число клиентов растет. И число ошибок — тоже.
Сперва мы пытались решать проблему классическим образом.
Мы собирались, запрашивали логи с продакшена, что-то исправляли, что-то забывали, создавали дашборды в Kibana и Sumologic. Но в целом это не помогало. Баги все равно просачивались, пользователи жаловались. Стало ясно, что-то идет не так.
Автоматизация
Конечно, мы стали разбираться и увидели, что 90% времени, которое уходит на исправление ошибки, тратится на сбор информации по ней. Вот на что конкретно:
- Получить недостающую информацию от других департаментов.
- Изучить журналы серверов.
- Исследовать поведение нашей системы.
- Понять, ошибочно ли то или иное поведение системы.
И только оставшиеся 10% мы тратили непосредственно на разработку.
Мы подумали — а что, если сделать систему, которая сама найдет ошибки, проставит им приоритет и покажет все нужные для исправления данные?
Надо сказать, что сама идея такого сервиса вызывала некоторые опасения.
Кто-то говорил: «Если мы найдем все баги сами, то зачем нам QA?».
Другие говорили обратное: «Вы утонете в этой куче багов!».
Одним словом, сделать сервис стоило хотя бы для того, чтобы понять, кто из них прав.
спойлер
(ошиблись обе группы скептиков)
Готовые решения
В первую очередь мы решили посмотреть, какие из аналогичных систем уже есть на рынке. Оказалось, что их немало. Можно выделить Raygun, Sentry, Airbrake, есть и другие сервисы.
Но ни один из них нас не устроил, и вот почему:
- Одни сервисы требовали от нас слишком больших изменений существующей инфраструктуры, в том числе изменений на сервере. Для Airbrake.io пришлось бы дорабатывать десятки, сотни компонентов системы.
- Другие собирали данные о наших собственных ошибках и отправляли их куда-то на сторону. Наша политика безопасности не позволяет такого — данные о пользователях и ошибках должны оставаться у нас.
- Ну а еще они стоят довольно дорого.
Делаем свое
Стало очевидно, что нам стоит сделать свой сервис, тем более что у нас уже была построена очень хорошая инфраструктура для него:
- Все сервисы уже писали логи в единое хранилище — Elastic. В логах были прокинуты единые идентификаторы запросов через все сервисы.
- Статистика исполнения дополнительно записывалась в Hadoop. Мы работали с логами с помощью Impala и Metabase.
Из всех ошибок сервера (по классификации HTTP статус кодов), код 500 — наиболее перспективен с точки зрения анализа ошибок. В ответ на ошибки 502, 503 и 504 можно в некоторых случаях просто повторить запрос через какое-то время даже не показывая ответ пользователю. А согласно рекомендациям к RC Platform API, пользователи должны обращаться в службу поддержки, если получают статус код 500 в ответ на вызов.
Первая версия системы собирала логи исполнения запроса, все возникшие стек-трейсы, данные о пользователе и заносила баг в трекер, в нашем случае это была JIRA.
Сразу после тестового запуска мы заметили, что система создает значительное количество ошибок-дубликатов. Однако среди этих дубликатов многие имели почти одинаковые стек-трейсы.
Нужно было менять способ выявления одинаковых ошибок. От анализа чисто статистических данных перейти к поиску первопричины, вызвавшей ошибку. Стек-трейсы хорошо характеризуют проблему, но их достаточно сложно сравнивать между собой — от версии к версии меняются номера строк, в них же попадают пользовательские данные и прочий шум. Кроме того, они не всегда попадают в лог — для некоторых упавших запросов их просто нет.
В чистом виде стек-трейсы неудобно использовать для отслеживания ошибок.
Нужно было выделить паттерны, шаблоны стек-трейсов, и очистить их от информации, которая часто менялась. После ряда экспериментов мы решили использовать регулярные выражения для очистки данных.
В итоге мы выпустили новую версию, в ней ошибки идентифицировались по этим уникальным шаблонам, если стек-трейсы были доступны. А если не были доступны — то по-старому, по http-методу и группе API.
И после этого дубликатов практически не осталось. Однако и уникальных ошибок было найдено немало.
Следующий шаг — понять, как приоритизировать ошибки, какие из них нужно исправлять раньше. Мы приоритизировали по:
- Частоте появления ошибки.
- Числу пользователей, которых она касается.
На основе собранной статистики мы стали публиковать недельные отчеты. Выглядят они вот так:
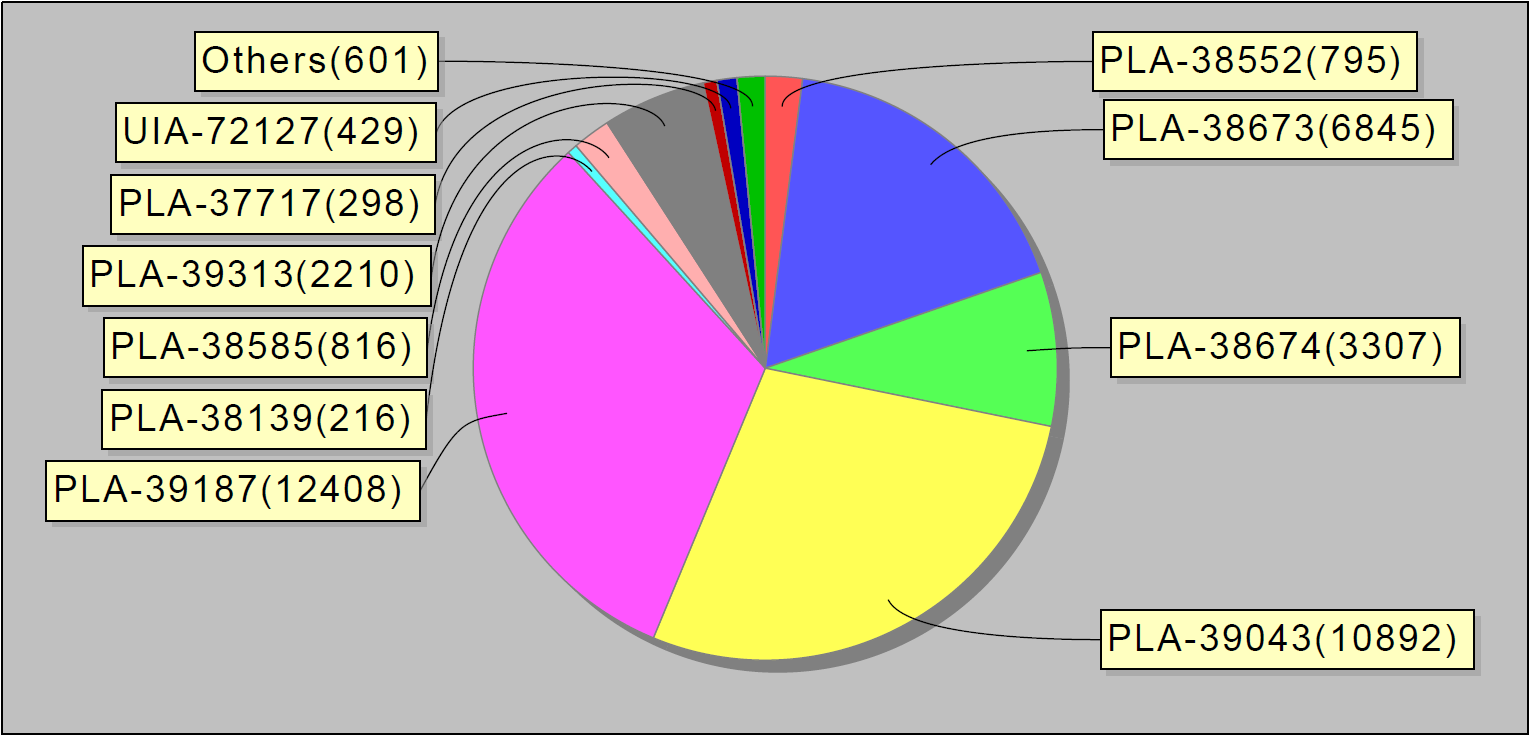
Или вот, к примеру, топ-10 ошибок за неделю. Занятно, что на эти 10 багов в jira приходилось 90% ошибок сервиса:

Такие отчеты мы рассылали разработчикам и тимлидам.
Через пару месяцев после того, как мы запустили систему, количество проблем стало ощутимо меньше. Даже наше небольшое MVP (минимально жизнеспособный продукт) помогло лучше разгребать ошибки.
Проблема
Возможно, на этом мы бы и остановились, если бы не одна случайность.
Однажды я пришел на работу и заметил, что система клепает баги как горячие пирожки: один за другим. После короткого расследования стало ясно, что десятки этих ошибок — с одного сервиса. Чтобы узнать в чем дело я пошел в чатик команды деплоя. В нем сидели ребята, которые занимались установкой новых версий сервисов на продакшн и следили за тем, чтобы они работали как полагается.
Я спросил: «Ребята, что такое, что случилось с этим сервисом?».
А они отвечают: «Час назад мы установили туда новую версию».
Шаг за шагом мы выявили проблему и нашли временное решение, проще говоря, перезапустили сервер.
Стало понятно, что «ошибочная» система нужна не только разработчикам и инженерам, отвечающим за качество. В ней также заинтересованы инженеры, которые отвечают за состояние серверов на продакшн, а также ребята, которые устанавливают новые версии на сервера. Разрабатываемый нами сервис покажет, какие именно ошибки происходят в продакшн во время изменений системы, таких как установка серверов, применения новой конфигурации и так далее.
И мы решили сделать еще одну итерацию разработки.
В процесс обработки ошибок добавили запись статистики воспроизведения проблем в базу данных и дашборды в Grafana. Вот так выглядит графическое распределение ошибок за день по всей системе:
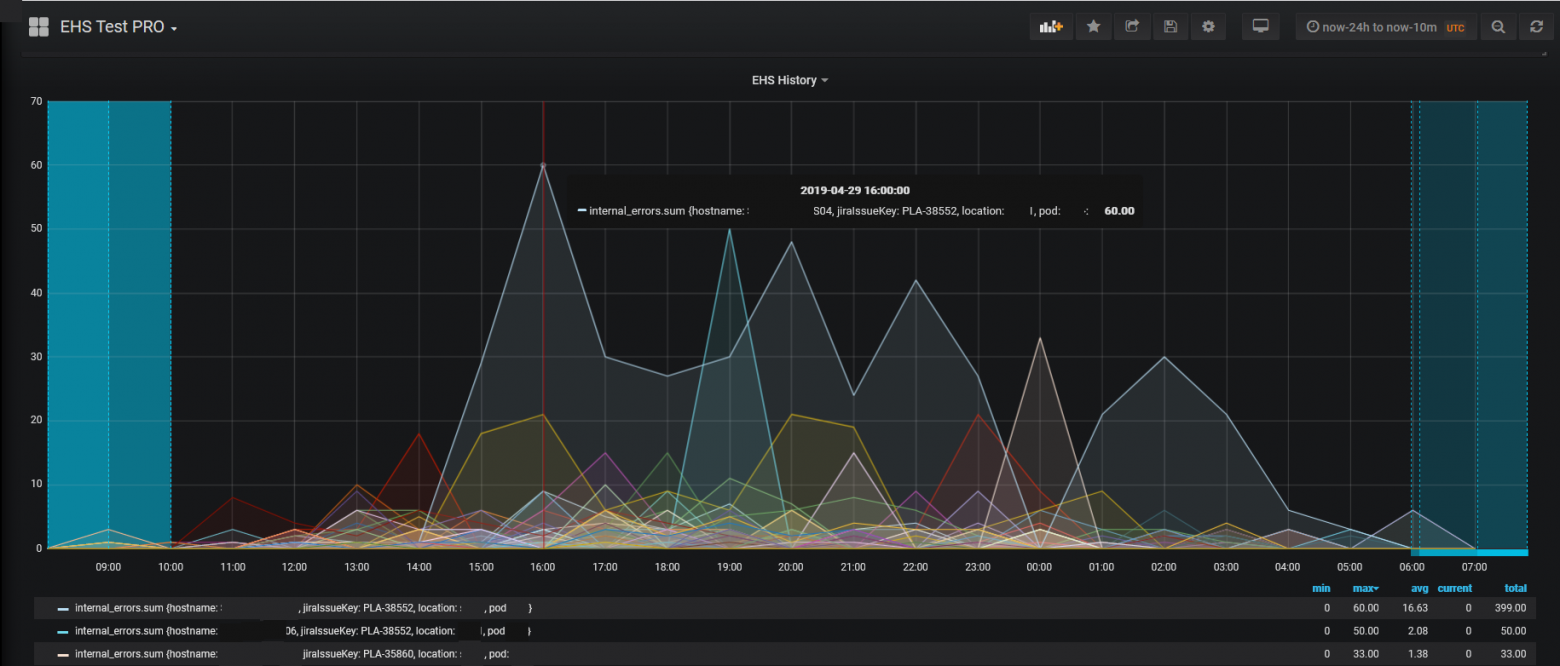
А вот так — ошибки в отдельных сервисах.

Также мы прикрутили триггеры с эскалациями ответственным командам инженеров — на случай, если ошибок становится достаточно много. Еще мы настроили сбор данных раз в 30 минут (вместо одного раза в сутки, как раньше).
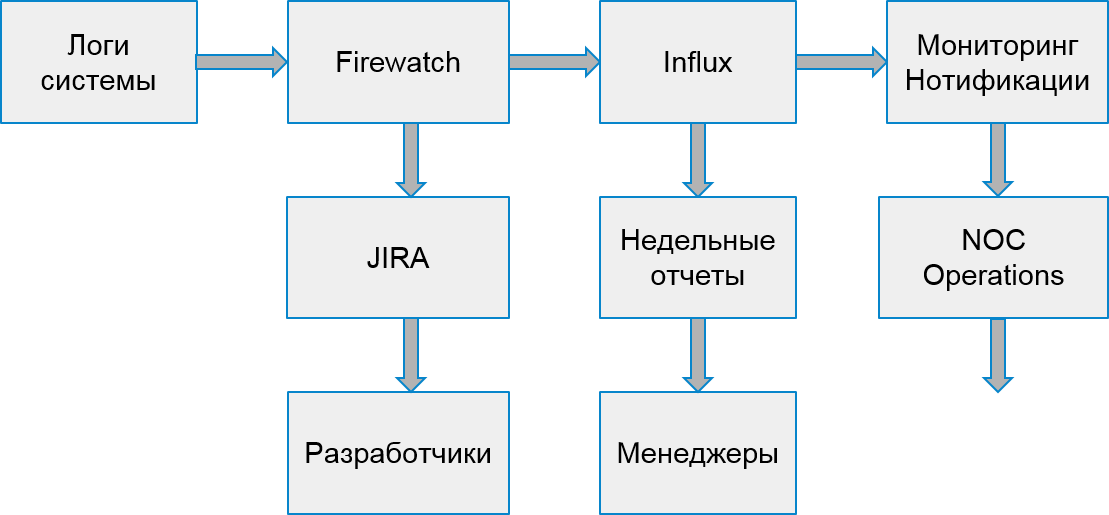
Процесс работы нашей системы стал выглядеть вот так:
Ошибки клиентов
Однако пользователи страдали не только из-за ошибок сервера. Бывало и так, что ошибка возникала из-за реализации клиентских приложений.
Чтобы обрабатывать клиентские ошибки, мы решили построить еще один процесс поиска и анализа. Для этого мы выбрали 2 типа ошибок, которые задевают компании: ошибки авторизации и ошибки троттлинга.
Троттлинг — это способ защиты системы от перегрузок. Если приложение или пользователь превышают свою квоту запросов, система возвращает код ошибки 429 и заголовок Retry-After, в значении заголовка указывается время, через которое запрос нужно повторить для успешного выполнения.
Приложения могут оставаться в состоянии троттлинга неопределенно долго, если не перестанут посылать новые запросы. Конечные пользователи не могут отличить эти ошибки от прочих. В результате это вызывает жалобы в службу поддержки.
К счастью, инфраструктура и система статистики позволяют отслеживать даже клиентские ошибки. Мы можем делать это потому, что разработчики приложений, которое использует наше API, должны предварительно зарегистрироваться и получить свой уникальный ключ. Каждый запрос от клиента должен содержать токен авторизации, иначе клиент получит ошибку. По этому токену мы и вычисляем приложение.
Вот так выглядит мониторинг ошибок троттлинга. Пики ошибок соответствуют будним дням, а в выходные — наоборот, ошибок нет:

Точно так же, как и в случае внутренних ошибок, на основе статистики из Hadoop мы нашли подозрительные приложения. Сперва — по отношению количества успешных запросов к количеству запросов, завершившихся с кодом 429. Если таких запросов мы получали больше половины, то считали, что приложение работает некорректно.
Позже мы стали анализировать поведение отдельных приложений с конкретными пользователями. Среди подозрительных приложений мы находили конкретное устройство, на котором работает приложение и смотрели, как часто оно выполняет запросы после получения первой ошибки троттлинга. Если частота запросов не уменьшалась, приложение не обрабатывало ошибку как положено.
Часть приложений разрабатывалась в нашей компании. Поэтому мы смогли сразу найти ответственных инженеров и быстро исправить ошибки. А остальные ошибки мы решили отправлять команде, которая связывалась с внешними разработчиками и помогала им починить их приложение.
Для каждого такого приложения мы:
- Создаем задачку в JIRA.
- Записываем статистику в Influx.
- Готовим триггеры для оперативного вмешательства в случае резкого увеличения числа ошибок.
Система работы с клиентскими ошибками выглядит так:

Раз в неделю мы собираем отчеты с топ-10 худших приложений по числу ошибок.
Не ловить, а предупреждать
Итак, мы научились находить ошибки в продакшн системе, научились работать как с ошибками сервера, так и с ошибками клиентов. Кажется, все хорошо, но…
Но по сути, мы реагируем слишком поздно — баги уже влияют на работу пользователей!
Почему бы не попробовать находить ошибки раньше?
Конечно, было бы круто находить все в тестовых окружениях. Но тестовые окружения — это пространства «белого шума». В них идет активная разработка, каждый день работают несколько разных версий серверов. Ловить ошибки централизованно на них — еще рано. В них слишком много ошибок, слишком часто все меняется.
Однако, в компании есть специальные окружения, где происходит интеграция всех стабильных сборок, для проверки производительности, централизованной ручной регрессии и тестирования высокой доступности. Как правило, такие окружения все еще недостаточно стабильны. Однако есть команды, заинтересованные в разборе проблем с этих окружений.
Но есть еще одно препятствие — Hadoop не собирает данные с этих окружений! Мы не можем использовать тот же способ для выявления ошибок, нужно искать другой источник данных.
После непродолжительных поисков мы решили обрабатывать статистику потоково, считывая данные из очереди, в которую пишут наши сервисы для передачи в Hadoop. Достаточно было накапливать уникальные ошибки и обрабатывать порциями, например раз в 30 минут. Благо установить систему очередей, которая поставляет данные — несложно, оставалось лишь доработать получение и обработку.
Мы стали наблюдать, как найденные ошибки ведут себя после обнаружения. Оказалось, что большая часть найденных и не исправленных ошибок появляется позже на продакшене. Значит, находим мы их правильно.
Таким образом, мы построили прообраз системы, заведения и отслеживания ошибок. Уже в текущем виде она позволяет улучшить качество системы, замечать и исправлять ошибки раньше, чем пользователи о них узнают. Если раньше мы обрабатывали десятки тысяч ошибочных запросов в неделю, то сейчас — всего 2-3 тысячи. И исправляем мы их значительно быстрее.
Что дальше
Разумеется, мы не остановимся на достигнутом и продолжим улучшение системы поиска и отслеживания ошибок. У нас в планах:
- Анализ большего числа ошибок API.
- Интеграция с функциональными тестами.
- Дополнительные возможности для расследования инцидентов в нашей системе.
Но об этом — в следующий раз.
