
Наш клиент cybersport.ru — один из самых популярных информационно-новостных порталов про киберспорт в СНГ. По данным Similarweb, в октябре 2021 года у сайта было 16,5 млн посещений.
Обычно нагрузка на cybersport.ru даже во время значимых событий не превышает 400 RPS (requests per second). Так было до недавнего времени, точнее — до The International 10. Турнир вернулся после годичного перерыва из-за пандемии, что подогрело интерес к нему. Ажиотажа добавило и успешное выступление российских команд. В итоге во время турнира нагрузка достигала небывалых для сайта 2300 RPS.

Серверы и сайт выдержали в основном за счет оперативного масштабирования ресурсов. И в этом, конечно, нет ничего необычного — рядовая задача для инженеров эксплуатации. Однако, чтобы всё четко отработало во время The International 10, нашей команде пришлось провести подготовительные работы, в том числе кубернетизацию инфраструктуры cybersport.ru.
В этом посте расскажем:
зачем cybersport.ru нужно было переезжать в Kubernetes и о сопутствующих трудностях;
почему пришлось сменить IaaS-провайдера;
почему было сложно во время The International 10, и как мы с этим справились;
почему автоматическое масштабирование ресурсов — не лучший выход для cybersport.ru (и вообще, для веб-ресурсов с таким же характером нагрузки).
Переезд в Kubernetes
Сайт cybersport.ru — часть киберспортивного холдинга ESforce, в который также входит самая титулованная киберспортивная команда России Virtus.pro. «Флант» уже более 3 лет поддерживает инфраструктуру ESforce.
")
До того, как мы подключились к проектам ESforce, инфраструктура всех проектов, включая cybersport.ru, была развернута на облачных серверах одного из ведущих западных провайдеров. Простейший CI/CD был организован на базе Ansible и управлялся через Ansible Tower. Разработчикам не хватало гибкости инфраструктуры, она была плохо адаптирована к cloud native-среде. Поэтому мы предложили перенести все важные сервисы в Kubernetes, настроить CI/CD и организовать review-окружения.
При миграции в K8s наши SRE-/DevOps-инженеры тесно взаимодействовали с разработчиками ESforce. Всё прошло без больших задержек и серьезных проблем. Небольшие трудности возникали только во время построения CI/CD-процесса, но они оперативно решались.
Чехарда с провайдерами
Переезд в Kubernetes состоялся еще в облаке зарубежного поставщика, но от него в итоге пришлось отказаться. Основные причины:
конфликт Telegram и Роскомнадзора: когда РКН стал блокировать пулы адресов, — включая те, что принадлежат провайдеру, — под угрозой оказались и сайты ESforce;
требования 152-ФЗ: российские веб-проекты должны хранить данные на территории РФ;
дороговизна по сравнению с ценами на российские облака.
Этап 1. Переезд в российское облако
Благодаря унифицированной и кубернетизированной инфраструктуре, миграция к одному из российских провайдеров прошла легко и быстро. Однако впоследствии мы столкнулись с проблемой, которой не было у западного провайдера: CPU steal time.
Если кратко, CPU steal time — задержка, которая вызвана перегруженностью гипервизоров при оверселлинге CPU. Виртуальные машины (ВМ) начинают конкурировать за выделение ресурсов; та ВМ, которая недополучает ресурсы, начинает сильно замедляться. Это в свою очередь приводит к проблемам в работе ОС и приложений.
Ниже — архивный график с данными нашей системы мониторинга. На нем видно, насколько высоким был уровень CPU steal time:
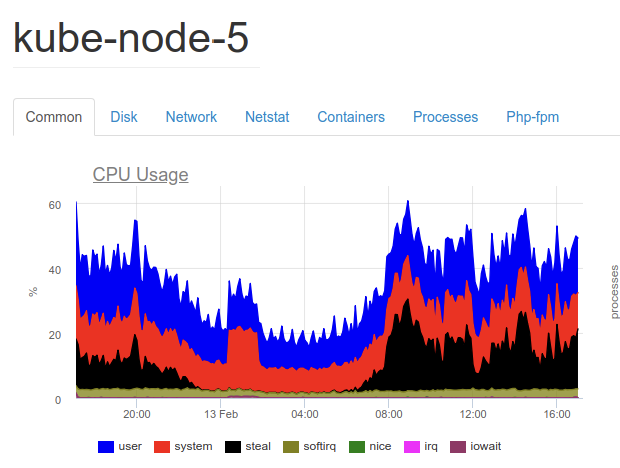
Проблема привела к тому, что инфраструктура стала нестабильной, постоянно сбоила; снизился SLA. Посыпались новые неприятности — даже такие, с которыми мы раньше не сталкивались. В такой обстановке не могло быть и речи об оптимизации инфраструктуры и кода, поскольку сложно было определить первопричину сбоев в работе приложения.
Этап 2. Переезд на «железные» серверы
В 2019 году не все российские облачные поставщики гарантировали отсутствие CPU steal time. Поэтому мы решили переехать к другому провайдеру, на «железные» серверы.
После переезда, в ходе оптимизации инфраструктуры и приложения, обнаружился ряд узких мест.
1. Redis. Изучив данные APM-системы (Application Performance Monitoring), мы выявили некорректное взаимодействие приложения и Redis. Количество подключений к сервису достигало 1,2 млн запросов в минуту; объем Set/Get-операций был слишком высок. В итоге Redis отвечал долго, сайты работали медленно.
Ниже — графики с результатами нагрузочного тестирования:


")
Вместе с разработчикам нам удалось оперативно обнаружить причину. Оказалось, что дело в неправильно настроенном процессе кэширования, из-за которого в кэш помещались постоянно обновляемые данные.
2. Нагрузка на PostgreSQL. Приложение создавало сетевую нагрузку на Postgres в 1 Гбит/с. Это было потолком для «железных» серверов в текущей конфигурации и приводило к недоступности cybersport.ru.
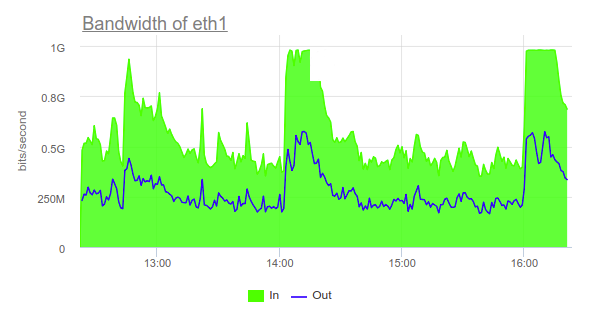
Как мы решили проблему:
Перевели проект на 10 Гбит/с;
Оптимизировали запросы к БД со стороны кода.
Этап 3. Обратно в облако
Популярность cybersport.ru росла, нагрузка — тоже. Сайту требовалось больше вычислительных ресурсов, которые можно было бы оперативно наращивать. Вдобавок, за соответствие 152-ФЗ у текущего поставщика приходилось доплачивать. То есть нужен был cloud-провайдер с гарантированным ресурсом по CPU и приемлемым ценником за 152-ФЗ. И в 2021 году cybersport.ru наконец-таки обосновались в облаке российского провайдера, который удовлетворял обоим критериям.
Влияние пандемии
К моменту переезда к новому провайдеру все более или менее значимые киберспортивные мероприятия отменили. У cybersport.ru не было реальной возможности оценить отказоустойчивость инфраструктуры во время пиковых нагрузок, кроме как с помощью синтетических тестов. Но для таких веб-сервисов синтетические тесты малополезны: они далеки от поведения реальных пользователей. Тем не менее, других вариантов не было, и мы готовились к The International 10 как могли — «в теории»…
И на старте турнира возникли некоторые проблемы.
The International 10. Проверка боем
В реальных условиях не всё пошло гладко. Сперва даже относительно невысокая нагрузка — в 600 RPS — приводила к тому, что сайт падал. Основные причины:
«разумная экономия» и, как следствие, ограничение количества заказываемых ресурсов под возрастающую нагрузку;
характер самой нагрузки, ее пиковость — мы быстро упирались в доступный объем ресурсов, а пока заказывали новые, серверы «пятисотили».

Небольшое отступление: автомасштабирование в Kubernetes
И в идеальном случае, т. е. когда нет финансовых и технических ограничений, желательно обеспечить несколько уровней горизонтального масштабирования и резервирования приложения — на уровне Pod’ов (количества экземпляров приложения) и на уровне кластера (количества узлов).
Автомасштабирование Pod’ов:
выбираем метрику, на основе которой будут масштабироваться Pod’ы. В случае с PHP-приложениями ориентируемся на количество занятых php-fpm-процессов (детальнее об этом — ниже);
выбираем количество
min/maxReplicasна основе предварительных нагрузочных тестов — если гипотетические уровни нагрузки еще неизвестны;настраиваем Cluster Autoscaler, где
min/maxтакже выставляется на основе тестов и с некоторым запасом поmax.
Автомасштабирование узлов:
используем standby-узлы для ситуаций с резкими и непредсказуемыми всплесками трафика. Они вроде «горячего резерва», который позволяет пережить первый наплыв пользователей и не ждать дозаказа обычных узлов при масштабировании Pod’ов;
настраиваем триггеры и алерты на желаемые значения, чтобы контролировать траты на дозаказ узлов.
Но случай с cybersport.ru был особый.
Почему мы ограничили автомасштабирование
С помощью Kubernetes-платформы Deckhouse легко настраивать гибкое автоматическое масштабирование узлов. Более того, Deckhouse сама умеет заказывать дополнительные ВМ у провайдера. Однако в случае с cybersport.ru автомасштабирование оказалось не самым оптимальным решением.
В проекте была необходимость строго соблюдать бюджет на инфраструктуру. При этом нетипичная нагрузка на сайт приходит хотя и резко, но редко и прогнозируемо. Например, во время старта значимого турнира RPS всего за несколько секунд может вырасти с 300 до 2000.
Вместе с клиентом мы решили пойти на компромисс и выработали особый подход: масштабировать инфраструктуру с помощью изменения пары параметров в манифесте. При этом в 100% случаев изменение затрат на инфраструктуру — например, дозаказ ВМ — контролирует инженер (согласуя с менеджером проекта).
Суть в том, чтобы заранее выставить оправданные и достаточные min/max-значения для HPA/CA и подготовить нужное количество standby-узлов; это занимает буквально несколько минут, весь остальной процесс — автоматический. После чего запуск новых Pod’ов происходит самостоятельно и в достаточном объеме для приходящей нагрузки. Всё остальное время количество ВМ можно держать на минимуме, не переплачивая за простаивающие ВМ. По такой схеме мы и действовали во время The International 10 — правда, в чуть более стрессовом режиме, чем планировали, поскольку недооценили нагрузки, которые предстоит принять.
Пример настройки HPA (Horizontal Pod Autoscaler)
Вот пример конфига, который отвечает за автомасштабирование Pod’ов — аналогичный тому, что мы использовали для Cybersport.ru:
apiVersion: deckhouse.io/v1alpha1
kind: PodMetric
metadata:
name: php-fpm-active-worker
spec:
query: round(sum by(<<.GroupBy>>) (phpfpm_processes_total{state="active",<<.LabelMatchers>>}) / sum by(<<.GroupBy>>) (phpfpm_processes_total{<<.LabelMatchers>>}) * 100)
---
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2beta2
metadata:
name: backend-fpm-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: backend
minReplicas: {{ pluck .Values.global.env .Values.fpm_hpa.min_replicas | first | default .Values.fpm_hpa.min_replicas._default }}
maxReplicas: {{ pluck .Values.global.env .Values.fpm_hpa.max_replicas | first | default .Values.fpm_hpa.max_replicas._default }}
metrics:
- type: Pods
pods:
metric:
name: php-fpm-active-worker
target:
type: AverageValue
averageValue: 60Примечание
В документации Deckhouse есть примеры с настройками кастомных метрик для HPA и конфигурации узлов кластера.
Кратко — о ключевых параметрах этой конфигурации:
1. Выбираем важные метрики. Прежде всего, необходимо определиться со спецификой приложения, которое мы собираемся масштабировать. Многое зависит от того, как правильно определять его загруженность. В случае с PHP-приложением, которое работает на php-fpm, идеальная метрика — загруженность child’ов (количество idle или active). По этой метрике легко определить, сколько child’ов в запасе. Отталкиваясь от этого, решаем — увеличивать или уменьшать количество реплик.
2. Настраиваем масштабирование. Для HPA создаем специальную метрику, измеряющую процент занятых child’ов. Затем в самом манифесте HPA ссылаемся на эту метрику и выставляем желаемые пороги срабатывания (averageValue). В нашем случае 60% занятых процессов, приводят к появлению новых Pod’ов, чтобы снизить этот средний процент.
Также два ключевых параметра, которыми мы можем управлять, — это minReplicas и maxReplicas, то есть желаемое минимальное и максимальное количество Pod’ов.
Ну, и в конечном счете направляем действие HPA на нужный контроллер через спецификацию scaleTargetRef.
Важный момент. Сразу после запуска HPA необходимо забыть о ручной регулировке количества реплик через deployment scale. Если этот параметр не будет совпадать с «мнением» HPA, то вызовет ненужное создание или пересоздание Pod’ов — это может негативно сказаться на пользователях.
От 600 до 2300 RPS
Как выяснилось, 600 RPS — это не предел: нагрузка росла ежедневно и достигла пика в последний день The International — 17 октября.
То, что происходило с сайтом во время турнира, лучше всего описал Павел Вирский, тимлид команды разработки cybersport.ru (приводим фрагмент поста Павла из корпоративного Slack’а нашей DevOps-команды):

Павел Вирский, тимлид команды разработки cybersport.ru
«Закончился The International, который был большим испытанием для нашего сайта и серверов и не меньшим вызовом и для нас и для вас. Начиналось всё 8 октября, когда 600 rps укладывали сайт на лопатки. Затем рекорд побивали ещё несколько раз, но с каждым разом всё более подготовленными. И закончилось сегодня, когда при (невероятных для меня) 2300 rps сайт работал. А нагрузка в 1200-1400 стала настолько рядовой, что мы спокойно выкладывали обновления...»
Подытожим
Сейчас инфраструктура cybersport.ru оптимизирована. Единственное, что требуется для принятия нагрузки, — своевременный дозаказ ресурсов. Но это не значит, что улучшать больше нечего. Что еще можно сделать:
Разместить Redis на выделенных узлах кластера. Если во время резкого роста нагрузки Redis окажется на нагруженном узле, это может негативно повлиять на инфраструктуру: Redis будет «аффектиться» и вызывать проблемы в работе всех сайтов, которые с ним взаимодействуют. В идеале для сервиса нужно выделить отдельную группу узлов.
Увеличить количество slave-узлов для PostgreSQL. Чтобы БД не «упиралась» по скорости чтения в возможности диска, для гипотетических ситуаций можно добавить slave-узлов. По сути, основная нагрузка во время мероприятий создается операциями чтения в базу. Она достаточно легко масштабируется добавлением новых slave-узлов для репликации и перераспределении нагрузки.
Сейчас cybersport.ru такая оптимизация не нужна, и в обозримом будущем потребность в ней вряд ли не возникнет.
Главное, что благодаря Kubernetes, отлаженному CI/CD, а также четкому взаимодействию инженеров «Фланта» и разработчиков наш клиент достиг важных для себя результатов:
Инфраструктура стала надежнее: обновления можно деплоить даже под большой нагрузкой.
… и гибче: нет технических ограничений для своевременного масштабирования.
Появилась независимость от поставщика инфраструктуры: K8s-кластеры можно легко перенести в новое облако, на bare metal, куда угодно.
Приложение оптимизировано и лучше адаптировано для работы в cloud native-среде.
P.S.
Читайте также в нашем блоге:
