
На кластерах клиентов, которые мы обслуживаем, есть как «одноголовые» инсталляции Redis (обычно для кэшей, которые не страшно потерять), так и более отказоустойчивые решения — Redis Sentinel или Redis Cluster. По нашему опыту, во всех трех вариантах можно безболезненно переключиться с Redis на KeyDB и получить прирост производительности. Точнее, избавиться от бутылочного горлышка Redis в одно ядро. Хотя в новых версиях Redis(r) появилась обработка I/O в отдельных тредах, иногда этого бывает недостаточно.
В то же время, если мы хотим использовать отказоустойчивые решениями вроде Sentinel и Cluster, нам понадобится поддержка этих технологий на уровне библиотеки, которую приложение использует для подключения в Redis. Причем лишь немногие библиотеки умеют читать из реплик Redis — в обоих вариантах (Sentinel и Cluster) чтение, как правило, происходит с мастеров. И запись, естественно, тоже происходит в мастеры.
В итоге у нас есть несколько реплик довольно дорогого in-memory-хранилища, а в рабочем процессе используется только часть из них. Остальные — на подхвате. Хотя в большинстве кейсов операции с in-memory NoSQL DB — это именно операции чтения.
Однако если посмотреть в сторону KeyDB, то можно увидеть, что там есть киллер-фича — и даже две: я говорю о режимах Active Replica и Multi-Master. Использование этих режимов позволяет получить распределенный отказоустойчивый KeyDB, совместимый с Redis, писать в любую ноду, читать из любой ноды. И все это с точки зрения приложения выглядит как один экземпляр Redis без всяких Sentinel — то есть в коде приложения ничего менять не придется.
Звучит как фантастика? Давайте посмотрим, как это работает: сначала исследуем режимы Active Replica и Multi-Master, а потом опишем несколько историй из своей практики.
Мы ранее несколько раз (тут и тут) писали о том, как успешно переключались на KeyDB в продакшене и как нас это выручало.
Как работает режим Active Replica в KeyDB
Если коротко, то режим Active Replica позволяет получить несколько реплик KeyDB доступных для чтения и записи. Причем данные, записанные в любой из них, реплицируются дальше, на другие реплики в цепочке, если они есть.
А вот в случае с Redis данные, записанные в реплику в режиме replica-read-only=false не реплицируются.

Вырожденный случай цепочки репликации с режимом active-replica=yes — это два экземпляра, каждый из которых является репликой другого.
Что нам дает такая конфигурация?
Приложение может работать с любым экземпляром IMDB (in-memory database), как будто это «обычный Redis».
Нагрузка на чтение распределяется между двумя экземплярами без всяких изменений в коде приложения или библиотеки (если используется простой балансировщик на основе DNS или сервиса в K8s).
Можно проводить аварийное переключение (failover).
Можно обслуживать экземпляры KeyDB в любой момент, для этого необходимо только переключить DNS (в случае с запуском сервисов в K8s — сделать плавный перекат подов KeyDB).
Как это работает под капотом
Для включения режима Active Replica нужно установить параметр active-replica yes. Это автоматически включит режим replica-read-only no и позволит производить операции записи в эту реплику.
Допустим, у нас есть два сервера, A и B, оба запущены в режиме Active Repica. Тогда на сервере B надо выполнить команду replicaof [A address][A port]. После этого сервер B удалит свою базу данных и загрузит данные с сервера A. На сервере A необходимо выполнить команду replicaof [адрес B] [порт B]. После этого сервер A удалит свою базу данных и загрузит данные с сервера B (включая данные, которые он передал на предыдущем шаге). Теперь оба сервера будут передавать записи друг другу.
После этого запись может производиться в любой из экземпляров KeyDB, даже если связь между ними разорвана. А когда связь восстановится, каждая из нод попытается подгрузить изменения с соседней ноды. У всех записей есть timestamp (показывает, когда произошло изменение ключа), поэтому, если во время разрыва связи в обоих экземплярах был изменен один и тот же ключ, будет использовано самое свежее значение.
В чем недостаток режима Active Replica
Если мы сделаем цепочку из более чем двух KeyDB, чтобы распределить операции чтения, но при этом сохранить возможность записи в любой из экземпляров, то каждый из них станет точкой отказа, прерывающей репликацию, потому что данные движутся по кольцу только в одном направлении.
A ---> B ---> C
^ |
----- D <---Как работает режим Multi-Master
Решить проблему, описанную выше, помогает режим Multi-Master. По сути, он позволяет каждому экземпляру KeyDB подключиться к более чем одному мастеру и получать изменения от каждого из них. Как и в случае с Active Replica, для решения конфликтов используется timestamp записи — в реплику запишется самый свежий ключ.
Как это работает под капотом?
Когда включен этот режим (multi-master yes), при подключении к мастеру реплика не удаляет все свои данные, а добавляет данные, полученные по каналу репликации с каждого из мастеров, основываясь на timestamp.
Допустим, у нас есть экземпляр KeyDB, и мы запустили его со следующими опциями: --multi-master yes --replicaof 192.168.0.1 6379 --replicaof 192.168.0.2 6379
Первым делом KeyDB считает локальный rdb-файл (если он есть). После этого она подключится к обоим мастерам и попробует провести с них либо частичную (если ранее мы уже реплицировались с этого мастера), либо полную репликацию данных. В результате в реплике будет суперпозиция из трех источников: локальных данных, и данных, полученных с обоих мастеров — она будет состоять из самых свежих ключей.
Что нам дает такая конфигурация?
Экземпляр KeyDB может подключиться сразу к нескольким мастерам и получать изменения ото всех (обычный Redis может подключиться только к одному мастеру).
Как и в случае с Active Replica, приложение может работать с любым экземпляром KeyDB в режиме Multi-Master, как будто бы это «обычный Redis», то есть читать с него данные, а при включенном режиме Active Replica — еще и писать.
Как работает сдвоенный режим — Multi-Master + Active Replica
Это самый интересный режим — можно одновременно включить Multi-Master и Active Replica и строить сложные схемы репликации данных между инстансами KeyDB. Также этот режим при позволяет производить операции с любым из экземпляров.
Выше мы уже описывали кольцо передачи данных между KeyDB в режиме Active Replica. Если в этой схеме использовать еще и режим Multi-Master, то можно получить двунаправленное кольцо, более устойчивое к отказу нод (далее в статье мы рассматриваем вариант с full-mesh-топологией).

Пример Docker Compose с кластером из трех Multi-Master + Active Replica KeyDB
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica yes --multi-master yes --replicaof keydb-1 6379 --replicaof keydb-2 6379
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica yes --multi-master yes --replicaof keydb-0 6379 --replicaof keydb-2 6379
keydb-2:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-2
command: keydb-server --active-replica yes --multi-master yes --replicaof keydb-0 6379 --replicaof keydb-1 6379Казалось бы, вот она, серебряная пуля! Скорость, репликация, многопоточность, работа реплик в случае отказа мастера — и все это прозрачно для приложения, привыкшего работать с обычным Redis. Но на практике мы столкнулись с кучей неочевидных проблем. О них и расскажем ниже.
История № 1. Коварный инкремент
KeyDB в режиме Multi-Master/Active Replica неплохо хранит и реплицирует ключи — как-никак это key-value-база. Однако помимо обычных, очевидных, SET и GET там есть еще много различных команд, результат работы которых в режиме Multi-Master может быть неожиданным.
Рассмотрим это на примере простой команды INCR, которая увеличивает значение ключа на 1. Допустим, у нас есть два узла в разных дата-центрах, а каждый из узлов является репликой другого.
Для начала на одной из нод выполним следующую команду:
SET mykey 1
Значение ключа реплицируется на вторую ноду, и в итоге везде появится ключ mykey со значением, равным 1.
Теперь мы разорвем соединение между двумя нодами — имитируем временный разрыв связи между дата-центрами — и выполним на первом узле INCR mykey три раза. В результате значение mykey станет равным 4. На втором узле выполним INCR mykey один раз, после чего значение mykey на втором узле станет равным 2. Восстановим связь между узлами. На обоих узлах у mykey установится значение 2, потому что синхронизируются именно значения ключей (а не операции), а у ключа со значением 2 более свежий timestamp, так как эту операцию мы производили позже.
Это не совсем то, чего можно было ожидать. С другими командами наверняка могут быть похожие сюрпризы.
История № 2. Out of memory
Однажды мы решили сделать очень отказоустойчивую IMDB на основе KeyDB в двух кластерах Kubernetes, расположенных в двух разных дата-центрах. Выбор пал на KeyDB в режиме Multi-Master + Active Replica, потому что в момент разрыва связи между дата-центрами у нас бы оставалось доступное на чтение и запись in-memory-хранилище.
Приложениям при такой конфигурации будет казаться, что они могут спокойно продолжать писать и читать в обоих кластерах — то есть они не замечают никаких проблем (KeyDB использовалось для кэша). В итоге мы одновременно получили кэш, «размазанный» по двум дата-центрам, а не два отдельных кэша.
Проблема, описанная в первой истории, в этот раз нас не беспокоила, ведь приложения отправляли и обрабатывали только SET- и GET-запросы. Когда связь восстанавливалась, экземпляры KeyDB просто синхронизировались, а в кэше оказывались самые новые значения.
Мы создали по три экземпляра KeyDB в каждом дата-центре, причем у каждого из них было по пять мастеров (два в своем ДЦ, и три в соседнем), и каждый был мастером для пяти реплик. KeyDB были запущены в кластере Kubernetes как StatefulSet, а приложения ходили через сервис только в «свои» локальные экземпляры. Данные, записанные в одном из кластеров KeyDB автоматически синхронизировала с другим кластером.
После этого мы провели тестирование:
Попробовали перезапутить и выключить часть контейнеров.
Разрывали связи между дата-центрами, а потом пробовали проводить операции чтения и записи в «разорванном» кластере.
Проводили нагрузочное тестирование приложения.
Все выглядело неплохо. После перезапуска KeyDB быстро синхронизировалась, а нагрузка на чтение равномерно распределялась между подами, что не могло не радовать (в случае с Redis Sentinel такое реализовать ой как непросто).
Успешно проведя тесты, мы запустили такую конфигурацию в эксплуатацию. Но в момент очередного планового нагрузочного тестирования у нас случилось ЧП — один из подов KeyDB упал. Казалось бы, упал и упал — подумаешь, проблема! Service в Kubernetes автоматически вывел этот под из балансировки, отправив запросы в оставшиеся в этом кластере два пода KeyDB, ведь именно для таких ситуаций и была построена схема репликации. Но тут началось странное:
Приложение стало очень медленно отвечать, и проблема, похоже, была в кэше.
Упавший под KeyDB стал падать по OOM (out of memory) и не мог подняться.
Что произошло?
Дело в том, что в режиме Multi-Master под в попытках подняться пытался одновременно реплицироваться с пяти своих собратьев, чем прилично нагрузил сеть (гигабиты в секунду!). На тестах, когда в кэше было не очень много данных, эту проблему мы просто-напросто не могли заметить.
В итоге этот под получал много новых ключей, которые изменились за время его простоя: он записывал их к себе в память и ретранслировал на свои реплики. То есть на те самые пять других мастеров! Так он еще больше нагрузил сеть и CPU соседних реплик, которые транслировали RREPLAY.
Раз данные с реплик переливались одновременно, то и потребление памяти выросло в разы по сравнению с обычным состоянием, а контейнер убивало OOM. Грубо говоря, если обычно данных в KeyDB было 2 Гб и контейнеру было выделено 3 Гб, то в момент старта сначала эти самые 2 Гб считывались с rdb-файла, а потом подгружалось еще пять раз по 2 Гб с соседних нод-мастеров. Все это система пыталась смержить — и требуемая для такой операции память превышала установленный лимит в 3 Гб.

Приложения писали данные в KeyDB со скоростью десятков операций в секунду, а взрывной рост количества команд, фактически и положивших сервис, вызвала пересинхронизация.
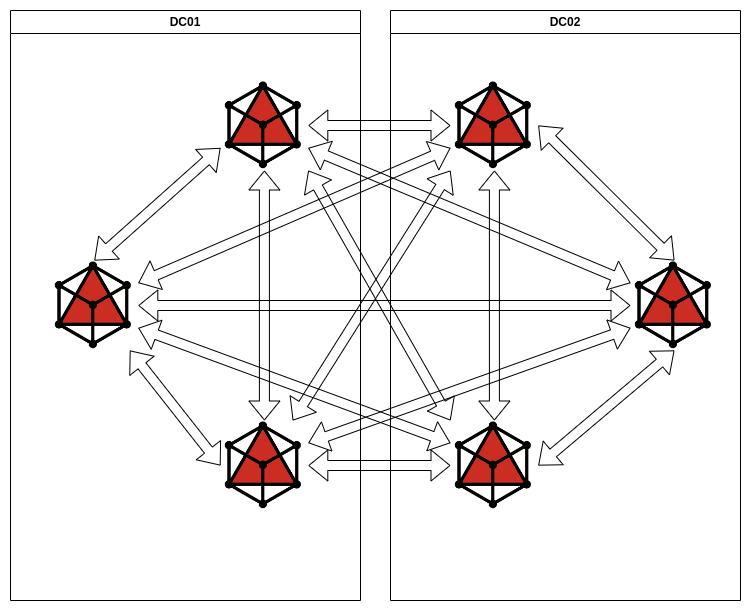
Чтобы снизить количество кросс-репликаций, но при этом не потерять такие полезные вещи как межкластерная и внутрикластерная отказоустойчивость, мы переделали схему.

В новой схеме при выходе из строя любой из нод репликация сохранялась, так как она была двунаправленной. Количество RREPLAY это снизило, но все равно при синхронизации нод их было очень много.
Более внимательно перечитав документацию KeyDB (точнее, файл с конфигом на GitHub), мы обнаружили интересный параметр multi-master-no-forward:
# Avoid forwarding RREPLAY messages to other masters?
# WARNING: This setting is dangerous! You must be certain all masters are connected to each
# other in a true mesh topology or data loss will occur!
# This command can be used to reduce multimaster bus traffic
# multi-master-no-forward noНесмотря на предупреждение об опасности, нам показалось, что это тот самый параметр, который нам нужен. Ведь изначально мы построили full-mesh, и ретрансляция нам не была нужна, так как все ноды KeyDB подключены друг к другу.
В итоге мы вернулись к схеме с full-mesh, только с включенной опцией multi-master-no-forward yes.

Как видно из описанного примера, у KeyDB есть довольно широкий набор опций для конфигурации репликации, и эти опции позволяют строить разные сложные схемы. Но не все конфигурации могут подойти под ваши нагрузки, а восстановление после падения единственной ноды может привести к неожиданным последствиям.
История № 3. Проблемы с библиотеками для Node.js
По нашему мнению, одна из важнейших особенностей KeyDB — это возможность получить реплицированное хранилище, совместимое с Redis. При этом приложение будет думать, что работает с обычным экземпляром Redis. То есть при переходе на KeyDB не нужны никакие доработки в приложении — если оно уже работало с Redis, то будет работать с KeyDB. Не нужно менять код — как в случае работы с Redis Cluster или Sentinel.
Кстати, для того, чтобы использовать Sentinel, не переделывая приложение, мы используем хитрый прием — свой форк Redis Sentinel-proxy. Мы описывали его в статье «Как я на порядок ускорил переподключение к мастер-узлу в Redis Sentinel».
Оказалось, что в случае с репликацией снова не все так просто. Конечно, у вас еще наверняка свежа в памяти «История №1», но с обычными GET- и SET-запросами проблем точно быть не должно. Если только не…
А вот, собственно, и сама история.
Вводные. В Kubernetes запущен StatefulSet KeyDB примерно такой конфигурации:

Приложение на Node.js использует его как кэш. Но в момент переката подов приложение деградирует по скорости, причем катастрофически. Мы многократно проверили свой чарт — при перекате подов сначала под выводится из балансировки, prestop-хук некоторое время ожидает, а потом завершает контейнер с KeyDB. После старта мы ожидаем, что контейнер запустится, синхронизируется и только потом readinessProbe вводит его в балансировку. И пока один из контейнеров перезапускается, остальные два продолжают обслуживать приложения. Мы проверили через Redis CLI SET/GET — все отлично, нет никакой деградации. Но тем не менее приложение не работает именно в момент перезапуска подов (или если один из подов не может запуститься в кластере K8s, потому что нет свободных ресурсов). Почему?
Во-первых, мы обнаружили аномалию — в тот момент, когда приложение «не работает», в метриках KeyDB резко подскакивает количество запросов INFO. Как выяснилось, это запросы от приложения. Мы спросили у команды разработки, зачем они делают INFO, на что получили ответ, что INFO они не делают, а для работы с кэшем используют библиотеку nuxt-perfect-cache, которая «просто работает». Расследование показало, что nuxt-perfect-cache использует библиотеку node-redis, которая при подключении к экземпляру KeyDB ожидает, что этот экземпляр готов обслуживать запросы с помощью вызова INFO.
Из документации
When a connection is established to the Redis server, the server might still be loading the database from disk. While loading, the server will not respond to any commands. To work around this, Node Redis has a "ready check" which sends the INFO command to the server. The response from the INFO command indicates whether the server is ready for more commands. When ready, node_redis emits a ready event. Setting no_ready_check to true will inhibit this check.
В node-redis такое поведение можно переопределить с помощью опции no_ready_check (по умолчанию для нее установлено значение false), а вот в nuxt-perfect-cache переопределить значение для библиотеки node-redis нельзя.
То есть когда приложение подключается к Redis (в нашем случае, к KeyDB), оно проверяет, что Redis дореплицировался. А если нет — ждет некоторое время и повторяет попытку INFO, даже не пробуя читать данные. Но этот прием с проверкой статуса репликации вызовом INFO, вероятно, корректно работающий в Redis, не подходит для KeyDB, так как там вполне себе можно читать (и писать) в реплику, которая не смогла подключиться к мастеру.
В итоге, если две из трех реплик Multi-Master KeyDB у нас полностью синхронизированы, приложение отказывается с ними работать, потому что перед чтением из экземпляра KeyDB проверяет через INFO master_link_status. Причем комичность ситуации в том, что если Redis вообще недоступен, то приложение прекрасно работает без кэша, лишь время ответа увеличивается с 300 мс до 500 мс. А если оно попадает в Multi-Master KeyDB, в котором нет одного из мастеров, то уходит в бесконечный цикл из INFO.
Аналогичная проблема присутствует и в других библиотеках Node.js для работы с кэшем, которые используют Redis Node.js (например, cache-manager-redis-store).
История № 4
В тестах «одноголового» (в одной реплике) KeyDB против «одноголового» же Redis KeyDB показывает себя как минимум не хуже конкурента. А вот при репликации картинка неожиданно меняется, причем не в пользу KeyDB.
Для примера проведем несколько тестов: сервис запускался на выделенных ядрах, бенчмарк на других выделенных ядрах, железо — ноутбук с процессором i5-11300H.
Попробуем записать в Redis ключи размером 8 Кб:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
redis-0:
image: redis:6.2.12
hostname: redis-0
command: redis-server --maxmemory 500mb --maxmemory-policy allkeys-lru --io-threads 4
cpuset: 0-3
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h redis-0'
cpuset: 6,7Получившийся результат следующий:
bench_1 | Summary:
bench_1 | throughput summary: 147950.89 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.196 0.024 0.183 0.263 0.399 85.951Теперь проверим то же самое на KeyDB:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'
cpuset: 6,7Результат сопоставимый (в пределах допустимой погрешности):
bench_1 | Summary:
bench_1 | throughput summary: 142592.33 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.216 0.032 0.207 0.295 0.407 24.271Теперь попробуем то же самое, но с репликацией.
YAML для Redis будет выглядеть следующим образом:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
redis-0:
image: redis:6.2.12
hostname: redis-0
command: redis-server --maxmemory 500mb --maxmemory-policy allkeys-lru --io-threads 4
cpuset: 0-3
redis-1:
image: redis:6.2.12
hostname: keydb-1
command: redis-server --replicaof redis-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --io-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h redis-0'
cpuset: 6,7
Полученный результат следующий:
bench_1 | Summary:
bench_1 | throughput summary: 92833.27 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.436 0.072 0.415 0.639 0.751 24.191YAML для KeyDB зададим как показано на листинге ниже:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica no --multi-master no --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica no --multi-master no --replicaof keydb-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'
cpuset: 6,7
Результат представлен следующей таблицей:
bench_1 | Summary:
bench_1 | throughput summary: 56934.64 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.808 0.040 0.383 0.815 10.583 201.983Стало заметно хуже. Почему так? Дело в том, что keydb-1 не успевает реплицировать данные с keydb-0 с той же скоростью, с которой мы пишем их туда бенчмарком. В процессе она несколько раз пытается сделать ресинхронизацию, падает, а по окончании бенчмарка делает полную пересинхонизацию с мастера.
Взглянем на лог контейнеров:
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:18.532 # Replication backlog is too small, resizing to: 2097152 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.537 # Replication backlog is too small, resizing to: 4194304 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.543 # Replication backlog is too small, resizing to: 8388608 bytes
keydb-0_1 | 1:24:M 11 Jun 2023 10:39:18.557 # Replication backlog is too small, resizing to: 16777216 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.612 # Replication backlog is too small, resizing to: 33554432 bytes
keydb-0_1 | 1:24:M 11 Jun 2023 10:39:18.668 # Replication backlog is too small, resizing to: 67108864 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:18.788 # Replication backlog is too small, resizing to: 134217728 bytes
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:19.041 # Replication backlog is too small, resizing to: 268435456 bytes
keydb-0_1 | 1:24:M 11 Jun 2023 10:39:20.192 # Client id=6 addr=172.31.0.3:41086 laddr=172.31.0.4:6379 fd=28 name= age=7 idle=0 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=40954 argv-mem=0 obl=0 oll=0 omem=268427868 tot-mem=268489332 events=rw cmd=replconf user=default redir=-1 scheduled to be closed ASAP due to exceeding output buffer hard limit.
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.193 # Connection with replica 172.31.0.3:6379 lost.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 # Connection with master lost.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * Caching the disconnected master state.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * Reconnecting to MASTER keydb-0:6379
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * MASTER <-> REPLICA sync started
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.199 * Non blocking connect for SYNC fired the event.
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.200 * Master replied to PING, replication can continue...
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.201 * Trying a partial resynchronization (request 4d55fe87f41c7ae358bc7c4c2c90379283d1b7fa:1123521824).
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.201 * Replica 172.31.0.3:6379 asks for synchronization
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.201 * Unable to partial resync with replica 172.31.0.3:6379 for lack of backlog (Replica request was: 1123521824).
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.201 * Starting BGSAVE for SYNC with target: disk
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.211 * Background saving started by pid 27
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.211 * Background saving started
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.211 * Full resync from master: 4d55fe87f41c7ae358bc7c4c2c90379283d1b7fa:1401369952
keydb-1_1 | 1:22:S 11 Jun 2023 10:39:20.211 * Discarding previously cached master state.
keydb-0_1 | 1:22:M 11 Jun 2023 10:39:20.716 # Client id=58 addr=172.31.0.3:48260 laddr=172.31.0.4:6379 fd=28 name= age=0 idle=0 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 argv-mem=0 obl=0 oll=0 omem=0 tot-mem=20512 events=r cmd=psync user=default redir=-1 scheduled to be closed ASAP due to exceeding output buffer hard limit.
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.716 # Connection with replica 172.31.0.3:6379 lost.
keydb-0_1 | 1:20:M 11 Jun 2023 10:39:20.768 * Reclaiming 267386880 replication backlog bytesЭтой проблемы нет (на текущем тестовом стенде), если KeyDB успевает синхронизировать данные. Например, если размер ключа при бенче будет не 8 Кб, а стандартные 3 байта, или если RPS будет не десятки тысяч операций SET в секунду, а просто тысячи. Тем не менее, при прочих равных Redis успевает синхронизироваться без падений репликации, а KeyDB — нет.
Давайте исправим эту проблему с помощью увеличения client-output-buffer-limit на мастере (config set client-output-buffer-limit "slave 836870912 836870912 0") и проведем тест повторно:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica no --multi-master no --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica no --multi-master no --replicaof keydb-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-cli -h keydb-0 config set client-output-buffer-limit "slave 836870912 836870912 0"; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h ke
ydb-0'
cpuset: 6,7Новые результаты следующие:
bench_1 | Summary:
bench_1 | throughput summary: 97370.98 requests per second
bench_1 | latency summary (msec):
bench_1 | avg min p50 p95 p99 max
bench_1 | 0.462 0.056 0.415 0.759 0.951 96.895KeyDB вырвался вперед (во всяком случае, догнал, и немного перегнал, Redis).
Куда более неприятная ситуация случится, если использовать KeyDB в режиме Active Replica и провести такой же бенчмарк, не увеличив буфер — реплика так и не сможет синхронизировать данные с мастера, и уйдет в бесконечную пересинхронизацию:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica yes --multi-master no --replicaof keydb-1 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica yes --multi-master no --replicaof keydb-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 8192 -t set -h keydb-0'
cpuset: 6,7
Проведем еще один тест KeyDB — проверим консистентность репликации с включенным режимом Active Replica:
Содержимое файла docker-compose.yaml
version: '3.8'
services:
keydb-0:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-0
command: keydb-server --active-replica yes --multi-master no --replicaof keydb-1 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 0-3
keydb-1:
image: eqalpha/keydb:alpine_x86_64_v6.3.3
hostname: keydb-1
command: keydb-server --active-replica yes --multi-master no --replicaof keydb-0 6379 --maxmemory 500mb --maxmemory-policy allkeys-lru --server-threads 4
cpuset: 4-7
bench:
image: redis:6.2.12
hostname: bench
command: bash -c 'sleep 5; echo "Start bench"; redis-benchmark --threads 2 -r 100000000 -n 1000000 -d 512 -t set -h keydb-0'
cpuset: 6,7
Судя по логам контейнеров, тест проходит без ошибок:

А теперь давайте посмотрим, что у нас в базах:
docker exec -it keydb_keydb-0_1 keydb-cli DBSIZE
(integer) 706117
docker exec -it keydb_keydb-1_1 keydb-cli DBSIZE
(integer) 710368Итоговое количество ключей в инстансах разное! А вот если режим Active Replica не включен, то количество ключей в мастере и в реплике на всех тестах совпадает.
Стоит отметить, что на RPS в 10-20 тысяч SET в секунду (что, согласитесь, тоже не мало) проблему рассинхронизации воспроизвести не удалось. На поверку, репликация в KeyDB оказалась не очень надежной, что при действительно высоких нагрузках на запись может привести к катастрофическим последствиям. Но мы не унываем и продолжаем исследовать вопрос репликации, чтобы получить нужный нам результат.
Мы еще раз убедились, что серебряной пули нет, а при использовании новых технологий иногда даже «семь раз отмерить проверить» бывает недостаточно — проблемы могут поджидать в совершенно неожиданных местах.
Вместо заключения
Мы проверили, что KeyDB в режиме Multi-Master + Active Replica действительно работает на не очень больших (но честно скажем — и далеко не маленьких) нагрузках и может быть удобной для ваших приложений.
При использовании full-mesh-соединения между нодами KeyDB нужно обращать внимание на межнодовый трафик, который может оказаться неожиданно огромным.
При переключении на KeyDB могут возникнуть проблемы у приложений, использующих «слишком умные» библиотеки для работы с IMDB (как у Redis Node.js).
Для высоконагруженных приложений с активной записью и чтением, вероятно, следует использовать «классический» Redis Cluster, что может потребовать дополнительных изменений в коде приложения, тюнинга библиотеки и т.д.
P. S.
Читайте также в нашем блоге:
