
Хабр, привет! Меня зовут Кирилл Евдокимов, я директор практики Data Governance GlowByte. В области данных и аналитики работаю уже около 20 лет, последние 7 лет основной фокус – это Data Governance.
Осенью, выступая на конференции по управлению данными с докладом и общаясь с представителями компаний, в очередной раз осознал, что история с управлением данными всё ещё остается terra incognita, и многие, начиная программы и проекты по внедрению Data Governance, совершают типовые ошибки, которых можно было бы избежать. После этого родилась идея поделиться опытом и написать эту статью про наиболее частые проблемы, с которыми приходится сталкиваться компаниям, вступающим на тернистый путь управления данными (далее по тексту буду использовать также аббревиатуру УД).
Итак, начну с того, как и когда управление данными появляется в повестке. Есть достаточно простой факт: последний десяток лет (даже больше) крупные компании инвестируют очень большие деньги в аналитические системы и хранилища данных, чтобы развивать свой бизнес и получать дополнительную ценность данных (монетизировать). Однако, к сожалению, это не всегда приводит к желаемому результату.
Единое хранилище, которое когда-то представлялось эталоном, идеальной моделью, оказалось слишком несовершенным: медленный time-to-market, высокие затраты на управление комплексной моделью, ограниченная пригодность к использованию в решении задач аналитики больших данных (в том числе из-за ограничения в виде структурной модели) – это далеко не полный список проблем, которые мешают хранилищу быть “серебряной пулей” на все случаи жизни. По сути, это идеальный вариант для небольшой организации, который теряет свою “идеальность” при росте, который порождает новые вызовы и требования к функционалу и возможностям аналитических систем, которые практически невозможно сложить в единую “идеальную” платформу. Как следствие, растёт сложность ландшафта, что рано или поздно приводит к пониманию необходимости выстраивать процессы управления данными.
Развитие аналитики, или Когда приходит время для УД
Наглядно опишу, что я имею в виду и какую картину часто можно наблюдать в компаниях.
На старте в небольшой организации есть достаточно ограниченный набор аналитических задач: в основном – финансовая и операционная отчётность, которые необходимы для работы бизнеса. Можно сказать, что компания только начинает заниматься аналитикой. Для решения подобных задач создаётся единый источник, который используется для всей аналитики в компании, – хранилище или прообраз хранилища данных, которого на данном этапе вполне достаточно:

В этой архитектуре нет особой потребности в каких-то процессах, связанных с УД, потому что в типовом сценарии за развитие хранилища, его модели (если она есть) и витрин отвечает одна команда, она же загружает данные из всех источников, которых на данном этапе развития достаточно немного. Простая архитектура, относительно простая аналитика, централизация экспертизы и фактически отсутствие потребности в явных и формализованных процессах управления данными.
Что происходит дальше:

Компания растёт. Понимание ценности аналитики становится более очевидным – бизнес уже не довольствуется простыми операционными и финансовыми показателями и стремится перейти к анализу причин и взаимосвязей на основе данных и пытается строить прогнозы. Как следствие, увеличивается количество отчётов, появляются дополнительные данные, которые бизнес часто использует в формате Excel (либо вспомогательных таблиц), начинают оформляться новые потребности в части анализа данных, и, как ответ на эти требования, появляются специализированные аналитические решения (обычно первыми идут управление кампаниями, таргетирование коммуникаций или оптимизация производственных процессов).
Усложнение ландшафта приводит к появлению проблем с качеством данных: к консистентности данных между системами, расхождениям в отчётности, ручным корректировкам. И это является первой точкой, когда компания начинает задумываться, что было бы неплохо начать строить процессы УД.
Если мы говорим о крупных компаниях, то их аналитический ландшафт выглядит вот так:

И это достаточно стандартная история, которую можно наблюдать практически в каждой второй, а то и первой крупной компании. Это огромное количество аналитических решений: Hadoop для исследования данных и Data Science, хранилища для регламентной отчётности, отдельные силосы в разных подразделениях для решения специфических задач, в том числе решения для рисков (если говорить о финансовой сфере), и так далее. Компания решает достаточно комплексные задачи, оперирует прогнозами, строит сложные модели, фокусируется на получении ценности из данных – максимальной монетизации информации, чтобы иметь конкурентные преимущества.
При этом такое количество источников информации, обилие потоков обмена данными между ними порождает проблемы, связанные и с качеством данных, и с поиском информации, и с ответственностью за эти данные, потому что фактически уже нет той одной идеальной команды, которая могла бы за всё отвечать и к которой можно было бы приходить с любыми вопросами. Это тот момент, когда управление данными становится критичным.
Цели управления данными
Что собственно такое управление данными? Определений очень много. На мой вкус, наиболее понятное, простое, лаконичное: подход к управлению данными, который определяет данные как основной актив организации и требует внедрения специфических ролей, процессов и решений для управления данными как ценным активом.
А теперь хочу привести в пример один из выводов исследований Gartner: при внедрении процессов УД 80% инициатив, направленных на построение и развитие системы УД, не приводят к ожидаемым результатам.
Шокирующе, правда? Из-за чего это происходит?
Как я и говорил в начале статьи, есть ряд причин или типовых ошибок, из-за которых не получается достигнуть успеха. Далее разберём наиболее распространённые из них.
И начнём с самой базовой причины. На этапе старта инициативы по УД важно понимать цель и ожидания – то, какую конкретно задачу необходимо решить. Это звучит банально, но, к сожалению, достаточно часто приходится сталкиваться со случаями, когда об этом не задумываются – внедрение Data Governance начинается потому, что это современно, актуально и “в тренде”.
Я позволю себе некую аналогию 5-летней давности, когда компании активно начинали внедрять Agile – была массовая “эджайлизация”, внедряли все, не обращая внимание на то, где он действительно полезен, а где эффективность достаточно сомнительна (на всякий случай уточню, что в данном контексте я говорю об Agile в сугубо прикладном смысле – в виде фреймворков Scrum, Kanban, LeSS и пр., полезность Agile как культуры разработки сомнений не вызывает). В последние два-три года этот же подход можно наблюдать в отношении Data Governance с той разницей, что отдельные области (например, качество данных) актуальны всегда.
Поэтому первое, с чем нужно определиться: какую задачу вы хотите решить, какую проблему адресовать? С этого важно начать, потому что, если не формализована цель, результат будет недостижим.
Например, можно начать с того, что типовые ожидания от УД достаточно простые:
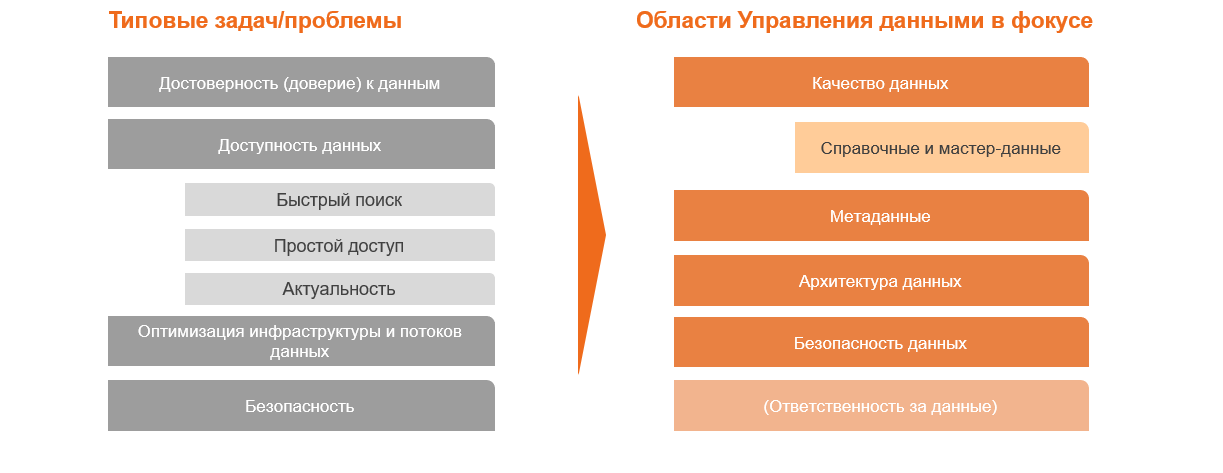
Остановлюсь на нескольких моментах подробно.
Достоверность (доверие) к данными. Самый очевидный пункт – если в двух отчётах, которые содержат одинаковые по смыслу метрики, мы видим разные цифры, то о каком доверии может идти речь? И, с точки зрения пользователя, не важно, в чём проблема (в качестве исходных данных, разнице в реализации алгоритмов, или ошибка в том, что их метрики просто названы одинаково), – в любом случае расхождения всегда приводят к кризису доверия.

Доступность данных. Реальный случай в одной финансовой организации: маркетинг очень долго сидел и думал, как было бы здорово иметь данные из кредитного бюро, что это позволило бы улучшить таргетинг кампаний. При этом почему-то никому в голову не приходило, что у рисков эти данные давно есть, хранятся, просто нужно пойти и взять их. Пример банальный, но в крупной компании в силу сложности коммуникации и большого количества команд такие казусы не редкость.

Я не буду расписывать всё, скажу лишь, что компании часто недооценивают оптимизацию инфраструктуры. Вспомните картину из начала статьи: сложный ландшафт на практике – это огромные затраты на поддержку всех интеграционных процессов и на хранение данных (зачастую избыточных копий этих данных).
Как можно видеть на этих примерах, разные проблемы и задачи могут требовать фокуса на разных областях управления данными. Это не значит, что остальное не важно или не востребовано, это то, что определяет приоритетное направление – базовую задачу.
Стратегия и фокус
Если первый вопрос, который должна задать себе компания, что нужно решить с помощью УД, то второй – как это нужно сделать и с чего начать. Стратегия и фокус – ключевой момент в УД.
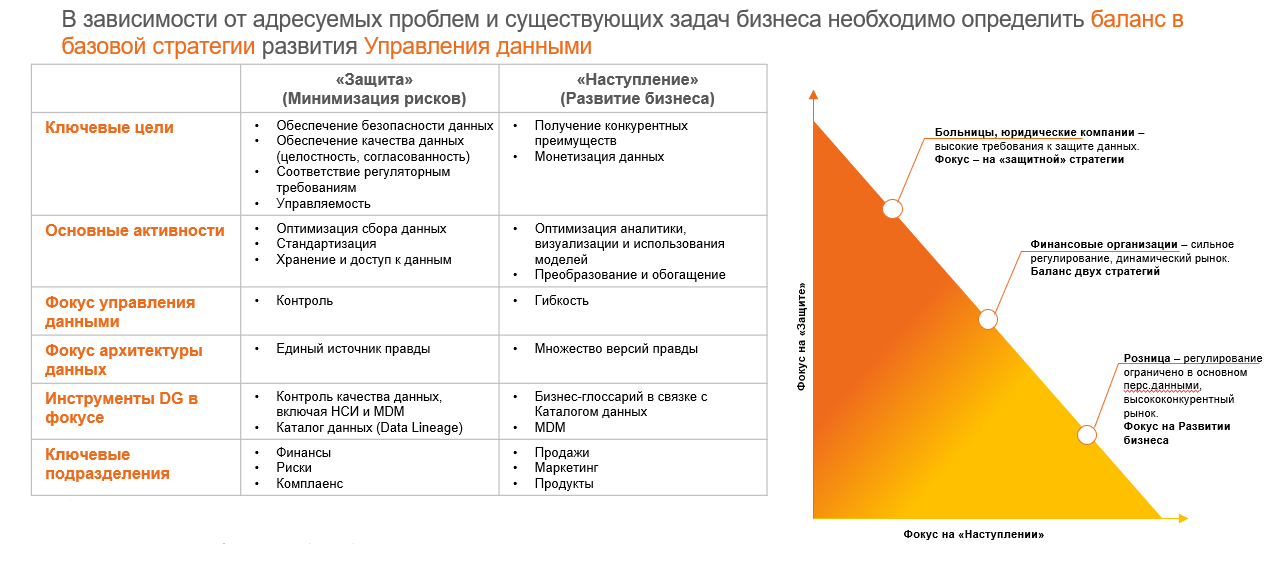
В целом можно выделить две базовые стратегии: минимизация рисков и развитие бизнеса. Они предполагают разные фокусы.
При первой стратегии ключевое – обеспечение безопасности данных, качество данных, управляемость всех процессов в целом. При этом необходимо оптимизировать сбор данных, стандартизировать их, обеспечить хранение. Это история, нацеленная на построение единого хранилища и централизованной функции УД. Фокус УД при этом – контроль. Основная цель – единый источник правды. Потребители такой стратегии – риски, финансы, комплаенс.
Во втором варианте (“Развитие бизнеса”) ключевой фокус смещается на монетизацию: быстрая проверка гипотез, получение ценности из данных, их демократизация. Фокус – гибкость, множество представлений правды. Это не означает, что не может быть единого источника правды, но должно быть много точек зрения на правду. Ключевые инструменты – глоссарий в связке с каталогом, нормализация семантического слоя, увеличение доступности данных для пользователей. Метаданные в данном случае критичны – если мы допускаем множество взглядов на правду, то мы должны убедиться, что эти взгляды как-то выровнены, иначе получится хаос.
Отличный пример
В качестве иллюстрации важности управления метаданными приведу простой пример: понятие “активного клиента” в банковской сфере. Это достаточно многогранный термин: для комплаенса – это количество клиентов, имеющих активный договор с банком, для продукта – количество клиентов, использующих продукт (со всеми нюансами и условиями, которые могут скрываться под словом “использующий”), для канала – количество тех, которые им пользуются и т. д. И всё это разные цифры. А теперь представим, что вы видите отчёт (набор отчётов) с количеством активных клиентов в качестве метрики, но с разными измерениями – каналы, продукты, сегменты и пр. В таких отчётах даже общая сумма может не сходиться, и, если нет описания методик или пояснений по расчёту, ответить на вопрос “а сколько же активных клиентов?” будет крайне сложно.
Обе стратегии важны, и ни одна из них не исключает другую. Они могут изменяться по мере потребностей и в зависимости от ситуации, специфики бизнеса и пр. Поэтому, выбрав цель, необходимо определить стратегию.
По опыту, существуют определённые базовые паттерны, характерные индустрии (см. рисунок ниже). При этом, повторюсь, не следует считать, что розница всегда идёт только по пути развития – в определённые моменты всегда идёт переключение на стратегию контроля. Это цикличный процесс.
Реализация системы управления данными
Теперь от стратегии к практике. Существует распространённое заблуждение, что, если компания внедрит классное решение, например, по контролю качества данных, построит индикаторы и наладит проверки, всё будет сразу хорошо. Или на примере метаданных: если внедрить каталог метаданных, описать там всё, то пользователи будут жить в прекрасном мире. Такие истории в подавляющем большинстве случаев (по опыту, почти всегда) не заканчиваются успехом. Давайте разберём причины.
Рассмотрим первую ситуацию (качество данных). Итак, внедрили систему, создали индикаторы (проверки), настроили их по расписанию – с техникой всё хорошо. Но есть открытые вопросы: кто отвечает за решение инцидентов? кто выявляет и анализирует системные проблемы? как определить достаточный уровень качества данных?
К сожалению, ни одно техническое решение не даст ответа на эти вопросы, а типовой подход “пусть инциденты падают в общую систему инцидент-менеджмента” по умолчанию не очень эффективен, поскольку ориентирован на исправление проблем с системами, а не с данными – ИТ-специалист не полезет в первичные документы клиента, чтобы исправить опечатку...
Вторая история – каталог метаданных. Его внедрили, приложили усилия, описали данные – на первый взгляд, всё хорошо. Но со временем информация начинает устаревать – системы изменяются, и бизнес тоже не стоит на месте. Думаю, многие сталкивались с такой историей в крупных компаниях: есть конфлюенс, где хранится куча документов, которые написаны пять лет назад и с тех пор не обновлялись, а всё, что изменилось, частично есть в задачах, частично в головах людей, что-то зафиксировано в JIRA, и, как итог, любая работа по системе всё равно начинается с reverse-инжиниринга. Такая же история с большой вероятностью ждёт и каталог метаданных.
Я веду к тому, что фокусироваться нужно в первую очередь не на инструментах, а на процессах и организационной структуре, которая будет поддерживать эти процессы. Технические инструменты важны как средства автоматизации процессов УД, но они не заменят процессы и оргструктуру. Если фокуса на этом нет, то, вероятнее всего, история с УД закончится ничем.

Остановлюсь подробнее на оргструктуре и процессах.
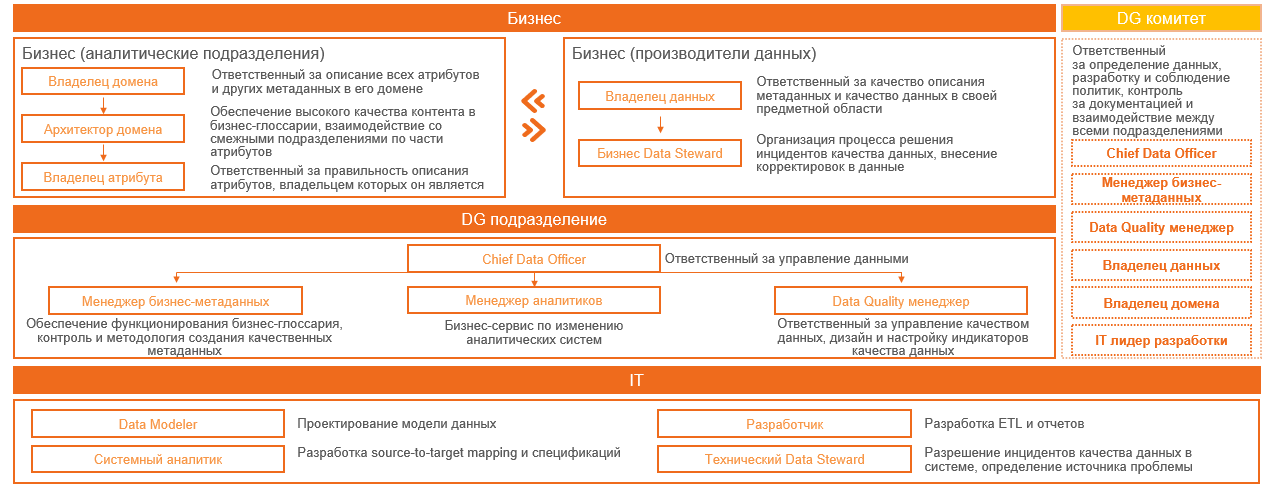
В большинстве книг (DAMA, DCAM и пр.) написано, что для УД нужны две ключевые роли: владелец данных и дата-стюард, остальным ролям отводится гораздо меньше фокуса. На практике мне ни разу не приходилось видеть (ни в России, ни в ряде европейских компаний), чтобы модель УД, опирающаяся только на эти две роли без дополнительных ролей, работала бы эффективно. Могу предположить, что такое возможно в небольших организациях, но, как писал в начале, это в целом особая история, где потребность в УД не очень критична в силу простоты ландшафта и относительно небольшого числа взаимодействий. В крупных компаниях в теории это возможно только при очень высокой зрелости организации.
Причина достаточно простая. Для того, чтобы работала модель двух ролей, необходима или высокая зрелость владельца данных, который, наиболее вероятно, также ещё должен являться владельцем продукта и воспринимать данные как второй продукт своей команды, либо серьезная перестройка бизнес-процессов компании с учётом потребностей в УД, на что решатся не многие. В большинстве случаев именно процессы УД необходимо подстраивать под/встраивать в процессы компании. Следствием этого является то, что нет некой идеальной модели, которая универсальна для всех и будет работать в любой компании. На практике всегда всё индивидуально: список ролей, разделение зон ответственности, порядок контроля, набор KPI и пр., хотя, конечно, общая канва остаётся схожей, поскольку вытекает из схожих целей и задач. Поэтому при внедрени УД нужно быть готовыми, с одной стороны, к изменениям, с другой – что всё будет не так, как в книжке.
Приведу пример и специально возьму достаточно “больную” тему, о которой не любят говорить в части методологии, поскольку именно на ней чаще всего возникают сбои у “идеальных” моделей УД. Это история с клиентскими данными (далее – КД). Это один из самых важных и значимых наборов данных для для большинства отраслей.
КД вводятся, изменяются, модифицируются, обогащаются, как правило, в очень большом количестве систем. Если взять, например, банки, то клиент может подать обновлённые данные во фронт-офисе, мобильном банке, через сайт, через заявку на кредит у партнёров и пр. – большое количество вариантов.
Можно ли найти человека в компании, который способен и будет отвечать за все данные клиентов во всех системах? Достаточно сомнительная история (за исключением примера, который я приведу далее). Часто эту роль начинают фиксировать на уровне систем. Что приводит к картине, которая приложена ниже:

Решает ли такая схема проблемы пользователей? Скорее нет, чем да, поскольку пользователю приходится в том или ином виде общаться с большинством “владельцев”, каждый из которых отвечает за данные лишь отчасти – только в пределах изменений в его системе, а остальное наследует от предыдущих “владельцев” в цепочке. Это не самая эффективная схема, пусть даже и является рабочим вариантом.
Есть ли другое решение? Да, и не одно. Например, есть интересный, но не универсальный вариант – внедрение MDM-системы как единого источника правды и назначение ответственного за эту систему владельцев данных по клиентам. Его задача – обеспечивать консолидацию и реализацию требований всех потребителей к составу КД, выстраивать сбор “золотой записи” из первичных систем, обеспечивать работу механизма решения конфликтов, а также контролировать качество данных и ставить задачи по исправлению проблем ответственным за системы-источники и дата-стюардам.
Для выполнения этих задач ему потребуется собственная команда, которая, помимо технических специалистов, будет включать аналитиков данных (роль УД), назначенных дата-стюардов, которые непосредственно будут отвечать за коррекцию данных, и владельцев первичных систем (по природе это же стюарды, но иного типа), которые будут отвечать за решение системных проблем на уровне своих источников.

В этом варианте тоже есть несколько стратегий, например, в части определения стюардов, отвечающих за коррекции первичных данных (в КД это достаточно частое явление). Типовых сценария два.
Первый вариант – формирование некой централизованной команды, которая исправляет все данные. Этот вариант хорошо подходит, например, для корпоративного бизнеса в финансовом секторе, потому что объём данных относительно небольшой, процессы бэк-офиса по юрлицам чаще всего в той или иной мере уже централизованы, соответственно, эта функция хорошо на них ложится. Для физлиц такой вариант уже не эффективен, поскольку для его обеспечения требуется большая команда, которая будет править данные в большом количестве систем. Потому тут лучшая стратегия – децентрализация.
Я так много уделяю этому внимания, потому что при назначении одних и тех же ролей всё в каждом случае происходит по-разному. Могут быть выделенные команды, а могут быть дополнительные обязанности тех людей, которые уже есть в компании. Это как раз пример того, о чём я уже говорил выше: процессы УД должны адаптироваться под бизнес.
Закрывая тему оргструктуры, в качестве примера покажу, как может выглядеть реальная организационная структура с ролями в компании (это не референсная модель, а просто пример работающей модели из реальной жизни):
Следующая проблема, которая часто встречается, – это ситуация, когда Data Governance пытаются внедрить методом Big Bang, написав кучу документов с лозунгом: “Мы написали классную методологию, нарисовали оргструктуру, определили роли – несём в массы! Все должны работать, как описано!”. В этой истории есть несколько проблем: и то, что процессы, описанные только на бумаге, в целом не всегда хорошо работают на практике, и то, что Big Bang не учитывает обратной связи и специфики конкретных процессов и функций, и ряд других вещей. В целом это классическая попытка “натянуть сову на глобус”, в большинстве случаев с вполне ожидаемым итогом.
Более продуктивный вариант – двигаться итеративно: от одной функциональной области к другой, от одного бизнес-процесса к другому, фокусируясь на тех областях, где есть проблемы. Сейчас в эпоху развития Agile-культуры, мне кажется, что нет необходимости пояснять и приводить примеры, почему это более корректный подход. Вместо этого приведу пример итеративного алгоритма для процесса управления качеством данных, сопряжённого с назначением владельцев:
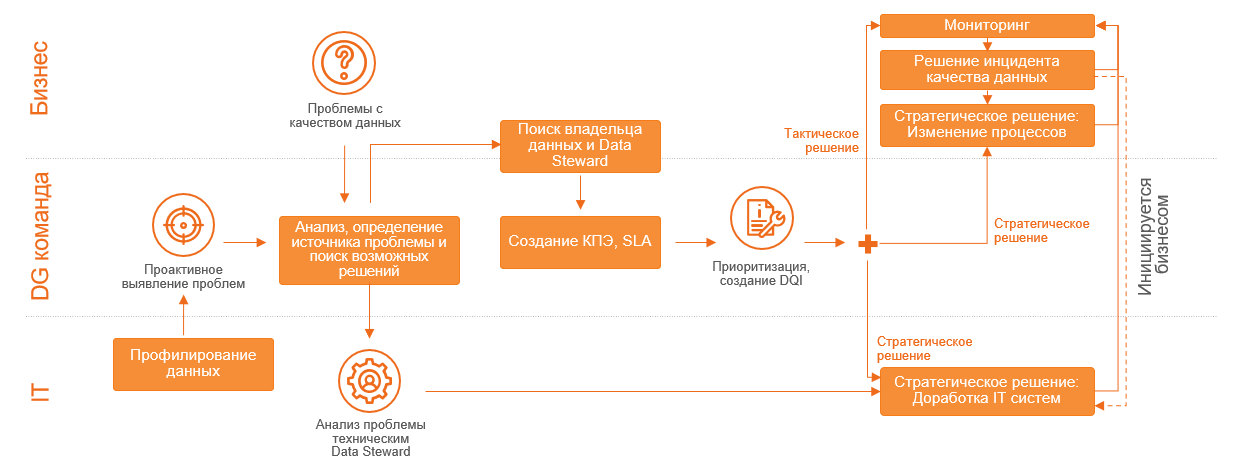
Описывать его в деталях в этой статье не буду, но, если у читателей будет интерес, напишу про него отдельную статью.
Управление данными – задача ИТ?
Следующая проблема – это уверенность в том, что управление данными – задача ИТ. Часто позиция бизнес-подразделений выглядит так: “Дайте нам хорошие данные, мы используем их в аналитике, бизнес-процессах, отчётности. Это же ваша техника, базы данных, разберитесь с ними, а нас не трогайте”.
На практике для ИТ управление данными – это достаточно прикладная задача. Для примера возьмём качество данных. Для ИТ первоочередная задача – стабильность работы систем, работоспособность интеграций, штатных функций и оперативное решение любых инцидентов и сбоев. С точки зрения метаданных, например, критичным для ИТ считается то, что способствует решению этих задач, позволяет предотвращать инциденты, то есть выполнять анализ влияния, оптимизировать собственные расходы (излишних потоков данных, излишнего хранения), документировать информацию о системе на техническом уровне. Как ИТ это закрывает? Техническими контролями, корректностью интеграции, отслеживанием аномалий.
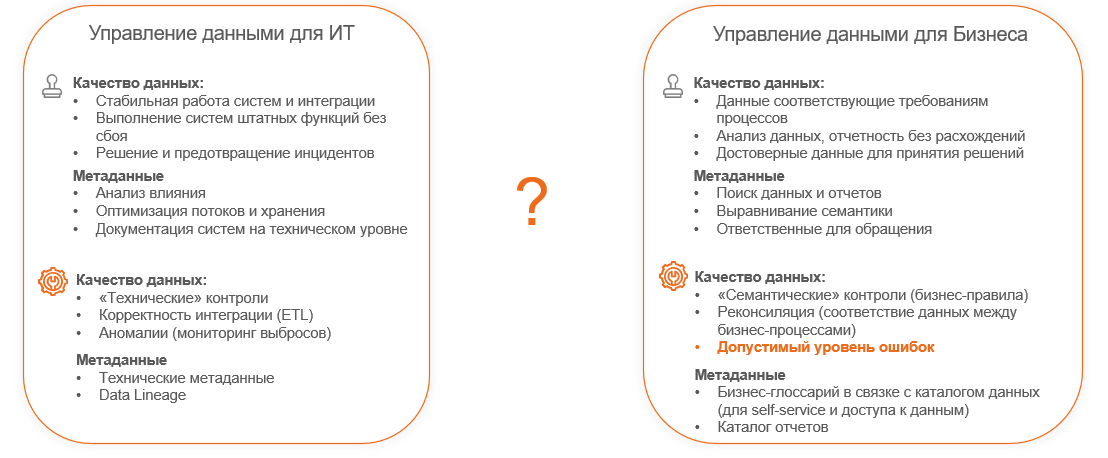
При этом у бизнеса взгляд иной. То, над чем думает ИТ, для бизнеса – банальный “гигиенический минимум”, то есть априори все исходят из того, системы работают, инциденты решаются, всё хорошо и стабильно.
На качество данных бизнес смотрит иначе – как на соответствие данных требованиям бизнес-процессов, отсутствие расхождений, достоверность, достаточность и актуальность данных для принятия решений. И с точки зрения метаданных фокус настроен на монетизацию. То есть важным является скорость поиска новой информации, чтобы те же дата-сайентисты могли обогатить какими-то фичами свойства системы, наличие контактов (к кому бежать, если нашли ошибку), выравнивание семантики.
Последнее, напомню, крайне важно (вспомним пример про понятие “активный клиент”), и это те вещи, которые могут дать именно бизнес-правила. Если бизнес не участвует в выстраивании качества данных, IT эти правила не придумает, равно как и дата-офис.
Вовлечённость бизнес-подразделений в управление данными – это критичный фактор.
Чтобы проиллюстрировать этот аспект, приведу ещё один пример – оценка допустимого уровня ошибок. Это важный критерий, поскольку в отношении качества данных правило Парето работает не хуже, чем в других областях: 20% усилий решают 80% проблем, а для решения оставшихся 20% требуется как 80% усилий, т. е. нередкими являются случаи, когда улучшение качества данных с 95% до 96-97% требует больших затрат, чем достижение изначальных 95%. Поэтому важно понимать, какой уровень качества данных является реально необходимым для бизнеса.
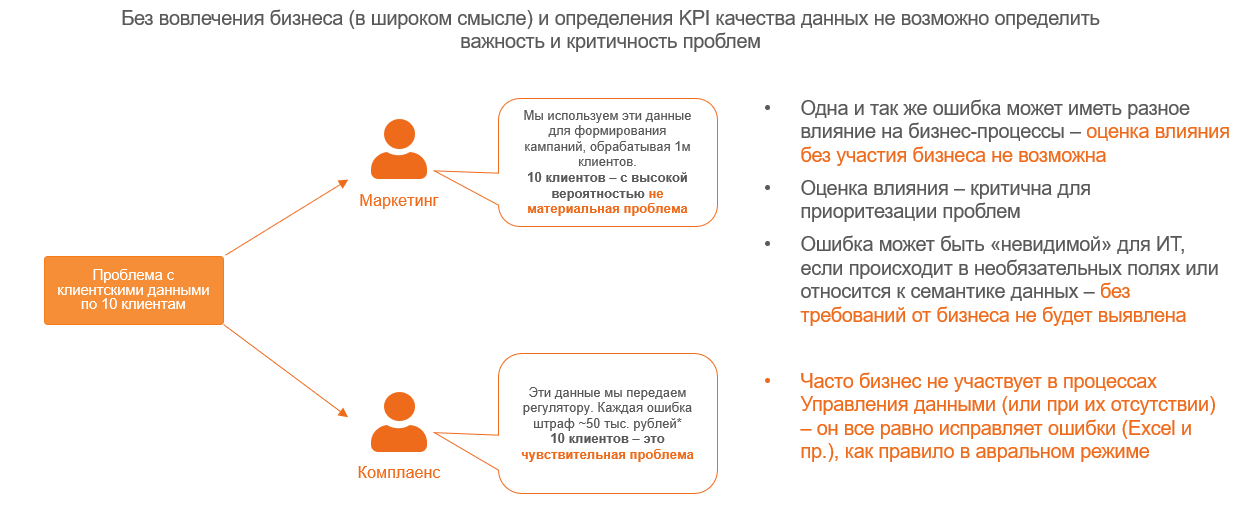
Представим, что есть проблема с данными по десятку клиентов. Для маркетинга, который оперирует статистическими профилями, определяя аудиторию для кампании, 10 проблемных записей по клиентам при общем количестве клиентов в миллион или несколько миллионов – это капля в море. Проблемные особо не повлияют на точность модели, даже если этих десятерых выкинуть совсем. Если же говорить о комплаенсе, то 10 потерянных клиентов могут стать большой проблемой – риски штрафов (некорректные данные в отчёте надзорному органу), фрода и пр. Эффективно оценить такие зависимости могут только бизнес-эксперты.
Драйверы для реализации инициатив
Когда я обсуждаю в разных компаниях предыдущий пункт с представителями офиса данных или ИТ, всегда возникает вопросы: а как вовлечь бизнес? что делать, если они не хотят? Поэтому закончить эту статью я хочу примерами драйверов, которые могут быть использованы в качестве аргументации для вовлечения бизнеса или обоснования инициатив по развитию УД. Не все из этих драйверов актуальны для любой компании – тут тоже, к сожалению, нет “серебряной пули”, но, возможно, они смогут дать направление для тех, кто начинает внедрять УД.
В основе большинства драйверов лежит простая мысль: чтобы вовлечь кого-то в процессы и помочь их поддержать, нужно объяснить ценность истории, т. е. зачем и для чего это делается и что будет, если этого не сделать.
Набор типовых драйверов в определённой мере зависит от отрасли (в начале статьи я говорил о разнице в стратегиях, тут есть прямая зависимость). Например, для финансовой сферы актуальны регуляторные требования, хотя, по личному опыту, могу сказать, что регуляторные правила – в принципе не лучший драйвер, поскольку это принуждение и то, что банк обязан их выполнять, не приносит прямой ценности.
Также эффективность драйверов по реализации инициатив зависит от зрелости процессов компании, а также фокуса стратегии по УД. Хорошим драйвером являются задачи, которые позволяют получить результат максимально быстро, тем самым показав бизнесу практический эффект от внедрения процессов.
Наиболее часто используемые драйверы:
Регуляторные требования (характерно для финансового сектора), которые относятся к качеству данных и обеспечению прозрачности потоков данных – могут быть эффективны либо при наличии существенных рисков, либо дополнительных возможностей, например, потенциала снижения нагрузки на капитал (ПВР).
Проблемы с качеством данных, имеющие материальный эффект (обычно индикация подобных проблем характерна для рисков (финансовый сектор), логистики (розница, производство), финансов (все отрасли), реже – маркетинга, CRM. Тут требуется чёткий расчёт с бизнес-экспертом на основе ретроспективного анализа с построением прогноза потерь или дополнительной прибыли в случае нерешения или решения проблем, соответственно.
Существенные повторяющиеся затраты на реализацию инициатив, основанных на данных, например, реализация новых типов отчётов или процессов (ретроспективная оценка, проведённая в одном из банков, показала, что около 40% трудозатрат подавляющего большинства проектов для рисков и финансов за 5 лет была вызвана необходимостью поиска и очистки данных – часто схожих блоков, необходимых для разных нужд).
Повышение эффективности Data Science и проверки гипотез за счёт снижения трудозатрат на поиск и очистку данных (по статистике эта часть занимает до 80-90% времени DS, потенциал – сокращения на 10-20%).
Оптимизация потоков данных – снижение затрат на сопровождение за счёт идентификации схожих потоков и рефакторинга.
Оптимизация затрат на избыточное хранение данных – выявление и оптимизация избыточных копий данных, а также неиспользуемых или слабо используемых исторических данных.
Внутренняя оптимизация аллокации расходов за счёт отслеживания использования данных.
