Привет, Хабр! Мы продолжаем цикл статей по Progressive Web Apps. В прошлый раз мы познакомили вас с опытом разработчиков из Airberlin, ну а сегодня у нас в виртуальных гостях Jan Lehnardt, человек, стоящий за такими штуками, как Hoodie, Apache CouchDB и Greenkeeper i/o.
И пусть вас не смущает аббревиатура PWA (Progressive Web Apps): несмотря на то, что в заголовке есть Apps, принципы и технологии, используемые в PWA, применимы в целом к вебу и к приложениям. Лучшим вступлением к статье будет просмотр видео с Google I/O 2016, в котором Джейк Арчибальд рассказывает о PWA.
Я очень рекомендую посмотреть его, прежде чем продолжать читать статью, особенно если эта тема для вас в новинку.
В сентябре 14 года я написал в твиттер вот такую штуку: «Friends don’t let friends build their own {CRYPTO, SYNC, DATABASE}.» Что я имел в виду? Ну тут всё просто. Сделать эти вещи правильно очень сложно. А сделав их «как-нибудь», вы расстроите кучу людей: как разработчиков, которым придётся работать с этими костылями, так и пользователей, которым потом всё это применять на практике. Проще говоря, некоторые вещи лучше доверить профессионалам. Однако… Рано или поздно у нас закончатся имеющиеся специалисты по этим темам, и никто не сможет разработать качественную криптографию, синхронизацию или базу данных просто потому, что никто этого не пытался сделать и не знает, как это делать, не набил шишек и не имеет опыта. А это значит, что в правиле могут быть исключения. Например, вы.
Давайте попробуем стать экспертами в одном из этих направлений. Ну а так как мы затрагиваем тему PWA, то работать мы будем в области синхронизации… ну или вы можете рассматривать эти статьи не как обучающие, а, скажем, как аналитические — мы рассматриваем ряд проблем и их решений, которые относятся к сфере «сделать данные доступными офлайн». Как-то так. Поехали?
После просмотра вступительного ролика вам может показаться, что PWA — это такое «безоблачное будущее» (но с облачными технологиями, ага), причём не только для сайтов-одностраничников и простых сервисов, но и суровых контент-провайдеров, таких как the Guardian, например. Но если вы по каким-то причинам не разделяете наше убеждение, что PWA — это то, как будет развиваться веб в ближайшее время, то по меньшей мере можете быть заинтересованы, куда ведёт дорожка PWA и какие технологии будут развиваться в этом направлении. И это мы тоже обсудим.
Если вы знакомы с постом от разработчиков AirBerlin, то уже знаете, как хранить элементы вашего сайта в кэше ServiceWorker’а. Скорее всего, также у вас есть некоторые представления о том, как хранить в индексной базе данных актуальный контент, поступивший с сервера. Ну и ещё вы можете догадываться о том, что пользовательские данные (введённые поля, формы, заметки, контакты, координаты, практически что угодно) можно также хранить в БД или в localStorage, чтобы отправить их на сервер при первой возможности. Например, когда смартфон подключится к WiFi в отеле при отключенной передаче данных в роуминге.
Ещё немного побуду Кэпом и выделю вот такие сценарии:
Прежде чем мы будем изобретать велосипеды, предлагаю пошагово проанализировать все три случая и мысленно наступить на все грабли, которые можно собрать.
Во вступительном ролике Джейк показывал пример приложения с чатом. Забегая вперёд скажу, что он использовал Background Sync Api для отправки новых сообщений «потом», как только браузер посчитает, что он действительно получил доступ к интернет-подключению (а не просто подключился к сети, в которой интернета может и не быть, как, например, до авторизации в сети московского метрополитена).
Это отличный пример хорошего интерфейса. Взаимодействие происходит как только пользователь подключается к сети. До этого момента все сообщения помечены специальным образом: пользователь понимает, что они ещё не доставлены получателю, но уже не потеряются и будут отправлены при первом случае, и от него (пользователя) ничего не требуется.
В этом же ролике Джейк объяснял, что мобильные ОС (и браузеры, так как работают в этих ОС) не всегда могут надёжно определить, действительно ли устройство подключено к интернету или нет. Максимум данных, которые они могут получить, — это информация о подключении к сотовой вышке или к WiFi-роутеру. А между тем, от вышки или роутера до веб-сервера множество отрезков сети, на каждом из которых может что-нибудь пойти не так. Начиная с оборудования вашего интернет-провайдера, прозрачного прокси-сервера или магистрального оборудования, заканчивая чем-нибудь типа спутникового канала передачи данных или глобального файрвола, по типу китайского.
Представьте себе, что вы используете чат Джейка и пытаетесь отправить сообщение «позвоню в 7:30 вечера», но поезд движется очень быстро и через сеть длинных тоннелей с небольшими отрезками на открытом воздухе. Или вы подключены к публичному хот-споту с авторизацией, но авторизацию не прошли. Или находитесь на хакатоне, а вместе с вами здесь сотня человек. А лучше — на концерте, который собрал целый стадион, и почти у каждого с собой мобильник, который пытается что-то передавать через сеть оператора. В общем, ситуаций миллион, а суть одна: наш телефон хочет что-то отправить или получить. Для этого он вызывает сервис Background Sync, а тот, в свою очередь, пытается доставить наше сообщение. Даже если к этому моменту «окно» для подключения пропало, нам беспокоиться не о чем: Background Sync будет ждать следующего и повторит попытку. Вам как пользователю уже не интересно, что станет с сообщением, достаточно знать, что оно рано или поздно будет доставлено. Теперь давайте заглянем под капот этой технологии.
Сколько бы прыжков по серверам и прочим элементам сети ваши пакеты ни сделали (а на каждом может что-то пойти не так, и вы получите одну из HTTP-ошибок), в общем случае остаётся только два значимых процесса. Запрос и ответ. Сломаться может и тот, и другой, так что у нас получается два сценария:
И если первый случай почти полностью покрывается возможностями Background Sync, то что делать со вторым? Представьте себе вот такой случай: вы отправили сообщение, сервер его принял и переслал конечному получателю. А вашему устройству сообщил, что всё в порядке и сообщение обработано.
А теперь подумайте, что будет, если на этапе от «сервер принял и переслал» до самого конца где-нибудь произойдёт разрыв соединения. Что тогда? Background Sync не получит подтверждения о том, что сообщение ушло корректно, и постарается переслать его повторно при первой же возможности. Сервер снова примет его, снова перешлёт получателю. И теперь у получателя таких сообщений два. Нехорошо вышло. Ну а если нам сказочно везёт, и ответ не успел / не смог пройти и в этот раз, то BS отправит сообщение ещё. И ещё. И ещё. А у вашего собеседника будет нескончаемый поток одинаковых сообщений (из-за чего он может подумать о вас чего нехорошего, или вообще забанить).
Теперь давайте подумаем, как избежать данной неприятности.
На самом деле, самым простым решением будет какая-нибудь серверная проверка, но её мы введём позже. Ну а пока просто посмотрим, как решить эту проблему на более общем уровне. Так мы сможем применить полученное решение не только к текстовым сообщениям, а вообще к любым вопросам рассинхронизации.
Вновь немного поработаю кэпом. В программировании подобных штук давно и прочно сложился тренд на применение ООП. В общем — всё есть объект, и все данные перемещаются внутри контейнеров-объектов. И если мы хотим повторно сослаться на тот или иной объект, нам необходимо уметь однозначно идентифицировать его. Иногда это означает присвоение объекту имени (например, автоматически генерируемый ID с увеличивающимся числом), а иногда мы можем получить имя объекта напрямую из его свойств.
Банальный пример — список контактов вашего телефона. Предположим, у людей никогда не бывает одинаковых ФИО (предположение так себе, но для наглядного примера сойдёт). Идентификатором (ID’шником, если по-простому) может служить связка «Имя_Фамилия». В среде разработчиков БД подобное явление известно как «естественный ключ».
Преимущества естественных ключей в том, что вам не требуется хранить никаких дополнительных данных. Часть объекта и есть его идентификатор. Недостатки тоже есть. Во-первых, могут быть проблемы с уникальностью (пример выше с «условностью» о неповторяемости ФИО тому подтверждение), во-вторых, ключи иногда могут меняться, и с этим надо что-то делать.
Предположим, вы выбрали в качестве естественного ключа поле с адресом электронной почты. Пользователь меняет в своём профиле электронную почту, и у вас на сервере меняется ID’шник пользователя. С одной стороны — всё хорошо, автоматизация, актуальность информации… А с другой — остальные объекты (например, хранилище документов, привязанных к этой почте) все ещё содержат ссылки на старый ID, а значит, им необходимо обновить зависимости. Если такие изменения происходят сравнительно нечасто — проблем особых не возникнет, но существуют натуральные ключи, которые обновляются гораздо чаще, и нагрузки по обновлению зависимостей в БД могут стать как минимум ощутимыми.
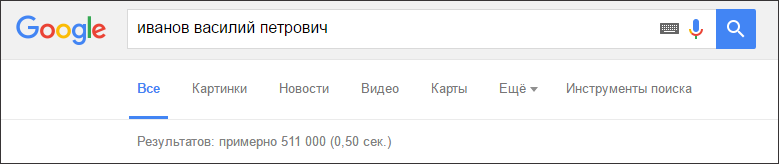
Вернёмся к примеру с телефонной книгой. Людей с ФИО «Иванов Василий Петрович» может быть несколько, и какой из объектов по ID Василий_Иванов нам вернётся по запросу?
Для избавления ото всех этих проблем придуманы суррогатные ключи. Они могут быть просты (хоть увеличивающимся натуральным числом), могут быть сложны (хэш от ряда изначальных параметров объекта при создании + соль), у них нет проблем с уникальностью или изменением. Недостаток суррогатных ключей — их непрозрачность. Без вызова объекта узнать, что скрывается за ID 43135, вы не сможете, даже если внутри записаны все те же данные, что и в объекте Василий_Иванов. Компьютеру-то наплевать, он и запрос сделает, и объект декодирует, если надо. Беда в том, что суррогатные ключи иногда прорываются в наш с вами мир, и с ними приходится взаимодействовать людям. Запоминать их, передавать, обрабатывать… За примером далеко ходить не надо: номер телефона — типичный суррогатный ключ для вас как для абонента. Или серия и номер паспорта.
Ещё один недостаток суррогатных ключей — сложность в дебаге или составлении логов. Представьте, что у вас в телефоне есть 20 пропущенных вызовов с разных номеров. А записная книжка только на бумаге. Чтобы выяснить, кто и когда вам звонил, придётся составить таблицу соответствия телефонов и абонентов, а уже после этого анализировать данные. А теперь экстраполируйте полученный опыт на краш-репорты с мегабайтом данных и вот таких «непрозрачных» ключей. Выявить в них закономерность, не декодируя ключи в понятные человеку значения… мягко говоря затруднительно.
С теорией мы более-менее разобрались, вернёмся к нашей проблеме. Так как мы хотим сделать наши данные доступными офлайн, это автоматом означает, что данные будут находиться и на сервере, и на клиентском устройстве. То есть у нас будет несколько копий одинаковых данных, и мы должны быть уверены, что любые операции с этими данными могут однозначно идентифицировать объект, с которыми производятся манипуляции.
Когда мы создаём новый объект, мы присваиваем ему уникальный ID. Как мы уже обсуждали выше, естественные ключи не могут обеспечить нам уникальность: на сервере и клиенте могут быть два объекта Василий_Иванов, и это создаст кучу проблем при общении, особенно если у одного из них пропало соединение с сетью. Поэтому натуральные ключи используются тогда, когда их недостатки не могут причинить нам неудобств. А вот во всех остальных случаях мы используем суррогатные ключи, а если быть более точным — универсальные уникальные идентификаторы (UUID).
Если быть честным, то UUID не совсем уникальные. Повтор может случиться, но его вероятность настолько мала, что проще выиграть в лотерею миллион или квартиру, купив единственный билетик, чем наткнуться на два одинаковых UUID в массиве из 1015 ключей. Этой вероятностью можно смело пренебречь и считать, что данные с разными UUID на устройствах являются однозначно идентифицируемыми.
Что ж, с проблемой идентификации мы разобрались, но перед нами встала другая: у нас есть несколько наборов данных, которые могут отличаться, а могут и не отличаться друг от друга. Причём отличия могут быть разными для всех наборов на разных устройствах. Давайте разберёмся, что делать в такой ситуации, что синхронизировать, как это делать и в каком направлении проводить синхронизацию, чтобы всё работало, как часы.
Снова включим нашу фантазию. Допустим, у нас есть мобильное приложение для чтения новостей и сервер, на котором они хранятся. В реальности есть блоги и RSS — они тоже хороший пример, если у кого с фантазией так себе. Так вот, допустим, пользователь запускает наше приложение впервые, и на устройстве не хранится никаких данных — читать нечего. Приложение обращается к серверу: «Пришли-ка мне подборку свежих статей». В результате пользователь получает контент, который хотел.
Спустя некоторое время приложение запускают повторно, оно снова просит у сервера порцию свежачка, и тут, если мы хороший разработчик и делаем всё по уму, у нас встречается первая интересная задачка: надо сделать так, чтобы имеющиеся статьи повторно не пересылались на пользовательское устройство. Почему мы так делаем? Здесь причин сразу несколько:
В целом все эти причины приводят к двум не очень желательным штукам — затратам и ожиданию. К слову, одно из неписанных правил юзабилити звучит примерно так: «Не позволяйте пользователям находиться в бесцельном ожидании, а то они расстроятся и перестанут пользоваться вашим продуктом». Так что же мы предпримем?
Ну если говорить простым языком, то надо сделать запрос к серверу, который будет понят им так: «У меня есть все статьи на такое-то время, так что пришли мне что-нибудь НОВЕНЬКОЕ». Разницу между «все статьи» и «все статьи, что есть на пользовательском устройстве» мы будем называть дельтой (то есть по сути разницей). В данном случае дельта и будет искомым контентом, который мы хотим получить с сервера.
Для эффективного вычисления дельты нам нужны две составляющих:
Самая простая реализация серверной части будет выглядеть примерно так: сервер собирает статьи из базы данных, а прежде чем отправить их на устройство, он сортирует их по дате публикации в оперативной памяти. Если запрос от устройства содержит закладку — то пересылаем только те материалы, что идут после неё.
Работать это будет, но об эффективности подобного решения даже говорить не хочется. Оно грубое, как топор. А нам нужно что-то вроде хорошего шефского ножа, а лучше — скальпель. Оптимизации напрашиваются очевидные. Неплохо бы, чтобы статьи в БД были изначально отсортированы как надо, а не загружались всем объёмом в память и сортировались в ней. Потому что топорное решение будет отлично работать на маленьких статейках с десятком пользователей, а если у вас статьи по много килобайт, а пользователей — десятки тысяч? В общем, нам нужен масштабируемый, надёжный и эффективный подход. А значит, как и все нормальные разработчики, мы добавим к базе статей ещё и индекс.
Бонусы от индексации статей очевидны. Во-первых, их можно упорядочить. Если статьи будут храниться на диске в упорядоченном виде (по дате публикации, от старых к новым) — мы и к диску обращаться будем быстрее, и последовательное чтение выполнять без лишних перемещений головки диска, и вообще значительно ускорим работу. Ну а во-вторых, нам будут доступны выборки. Прочитать только часть статей, скажем, с такой-то даты по такую-то — куда лучше, чем загружать всю базу в память и потом в ней ковыряться с каждой статьёй по отдельности.
Скорее всего, БД уже имеет автоматически увеличивающееся число в качестве первичного ключа. То есть каждая новая статья в БД будет иметь номер, который на единичку выше, чем предыдущая. Отлично подойдёт в качестве ID’шника: легко хранить, удобно использовать.
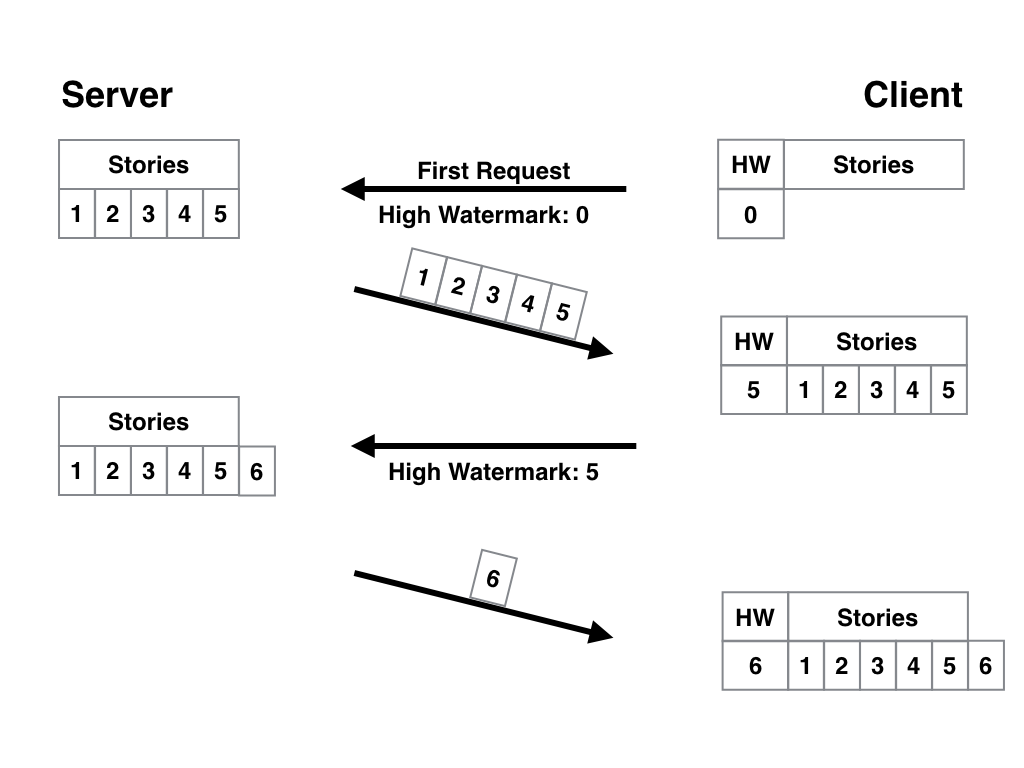
С таким ID и правильно организованной БД алгоритм работы приложения становится намного проще. Устройство делает первый запрос к серверу с закладкой, равной 0, и получает все актуальные статьи. В качестве закладки хранится только ID последней полученной записи. В следующий запрос к серверу включается хранящийся в закладке ID (пусть будет статья №5), и сервер присылает нам только то, что новее пятой статьи. Вот наглядная схема:
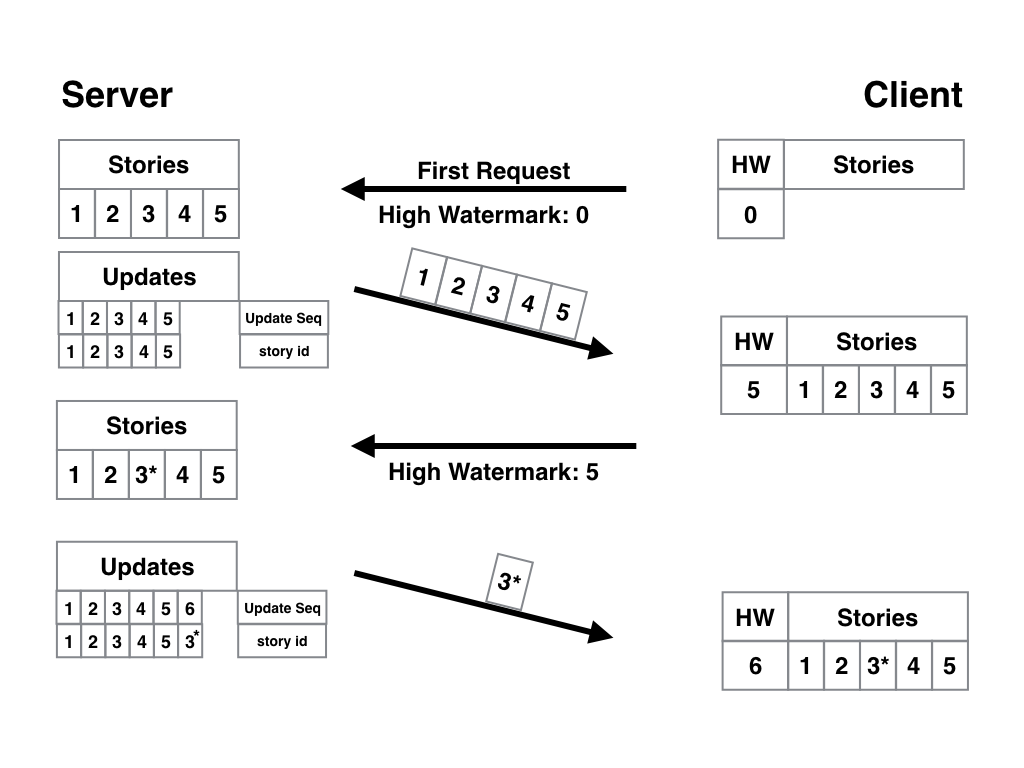
В статьях бывают опечатки. Или непроверенные факты. Или вообще надо дописать обновление или опровержение. Исправить-то на сервере мы их можем, а у пользователей статьи на устройствах уже есть. С нашей предыдущей системой они не обновятся — так как в закладке будет указано, что они уже есть, и сервер новые версии старых материалов нам не пришлёт. Для того чтобы грамотно разрулить ситуацию, одних автоувеличивающихся ID мало. Добавим в базу данных не только список статей, но и отдельную табличку, в которой будет содержаться только два значения — ID статьи и время её последнего обновления, превращённое в ещё одно простое число. В качестве закладки будет использоваться не ID статьи, а ID обновления. И если у вас есть пять статей, и в третью вы внесли правки, то её ID обновления будет уже 6, так что при следующем запросе клиент получит актуальную версию вместе с новыми статьями, если такие вообще будут. В общем, всё просто работает и не содержит критических недостатков, которые были у первых версий:
На первый взгляд всё хорошо — клиент получает новые материалы, обновления к старым, неизменные статьи никто не трогает… А что будет, если мы возьмём всё ту же статью №3 и обновим её дважды? Её ID обновления также вырастет дважды:
Получается, что вычисленная дельта содержит статью 3 дважды? Одну актуальную, а другую уже не очень актуальную, но всё ещё лучше той, что лежит у пользователя на устройстве? В случае с пятью статьями, конечно, некритично, но мы уже говорили, архитектуру надо планировать так, чтобы она хорошо масштабировалась. Пользователей, как и статей, может быть много тысяч, обновлений и наших статей — десятки (пусть это будут прямые репортажи с мест событий). А мы будем отправлять неактуальные версии и тратить ресурсы серверов, нагружать сети и заставлять пользователей платить за трафик и ждать то, что уже потеряло актуальность? Нехорошо это.
Индекс обновлений, который мы использовали, называют инкрементальным. Это означает, что больше чем один элемент определяет и диапазон индекса, и сортировку в нём. В нашем случае у нас есть автоматически увеличивающийся ID обновления и статический ID с номером статьи.
Для решения многократных обновлений одной и той же статьи нам достаточно внести одно простое изменение — сделать так, чтобы ID статьи был уникальным ключом таблицы. То есть каждый раз, как мы будем записывать в таблицу связку ID изменения + ID статьи, мы будем выполнять проверку, а есть-ли у нас что-нибудь ещё, связанное с этой статьёй? Если такая строка найдётся — мы её удаляем. Таким образом ID обновления будет только один — с самой последней версией статьи. Вот наглядная схема:
В принципе, по ней и так всё понятно, но на всякий случай поясню. Между первым и вторым запросом редактор дважды исправил статью №3. Так как её ID уникален, в таблице обновлений может быть только одна запись с такой статьёй, а значит, и первая строка, которая была актуальна на момент написания статьи, и вторая, с первым обновлением, — исчезли, и осталась лишь строка с ID обновления == 7 и статья с двумя правками. PROFIT! Ну и для полного удовлетворения нам осталось разобраться с последним аспектом работы такого алгоритма — удалением статей из базы и с пользовательского устройства.
Допустим, какой-то горе-шутник в рассылку по бизнес-аналитике добавил статью с подборкой смешных котят. Редактор решил, что надо это дело быстренько затереть, пока никто не заметил, и… что надо реализовать программисту?
С точки зрения данных, удаление может мало чем отличаться от обновления записи — просто пометим как удаленную, но фактически не уничтожим. Ну а для нас с вами удаление вообще может быть равносильно правке статьи — мы можем хоть строчку «извините, статья удалена» вписать вместо текста. Работает технически всё идентично — в таблице обновлений появляется новый ID, с которым связана статья «удалённая 4». Клиентское устройство при следующем запросе получает обновление, в котором сказано, что статья 4 удалена. А там уже вопрос «как обрабатывать» — на вашей совести. Самое простое, что можно сделать (правда, это точно понравится не всем пользователям), — удалять статью и из локального хранилища. Как-то так:
На сегодня у нас всё, во второй части статьи мы рассмотрим более сложную ситуацию: двустороннюю работу такого сервиса по синхронизации контента, когда не только сервер, но и клиент может работать с контентом. С одной стороны, это всё можно отнести к базовым знаниям, а с другой — без таких вот знаний не построить грамотную архитектуру с нуля. В общем, вот вам задание — подумайте о том, какие проблемы могут быть с таким сервисом и как их решать, а потом проверьте себя: всё ли вы нашли, и схоже мы мыслим или нет.
Кроме того, много интересно вас ждет и на онлайн конференции PWA Day, которая состоится 11 октября.
Источники:
И пусть вас не смущает аббревиатура PWA (Progressive Web Apps): несмотря на то, что в заголовке есть Apps, принципы и технологии, используемые в PWA, применимы в целом к вебу и к приложениям. Лучшим вступлением к статье будет просмотр видео с Google I/O 2016, в котором Джейк Арчибальд рассказывает о PWA.
Я очень рекомендую посмотреть его, прежде чем продолжать читать статью, особенно если эта тема для вас в новинку.

В сентябре 14 года я написал в твиттер вот такую штуку: «Friends don’t let friends build their own {CRYPTO, SYNC, DATABASE}.» Что я имел в виду? Ну тут всё просто. Сделать эти вещи правильно очень сложно. А сделав их «как-нибудь», вы расстроите кучу людей: как разработчиков, которым придётся работать с этими костылями, так и пользователей, которым потом всё это применять на практике. Проще говоря, некоторые вещи лучше доверить профессионалам. Однако… Рано или поздно у нас закончатся имеющиеся специалисты по этим темам, и никто не сможет разработать качественную криптографию, синхронизацию или базу данных просто потому, что никто этого не пытался сделать и не знает, как это делать, не набил шишек и не имеет опыта. А это значит, что в правиле могут быть исключения. Например, вы.
Становимся исключением из правил
Давайте попробуем стать экспертами в одном из этих направлений. Ну а так как мы затрагиваем тему PWA, то работать мы будем в области синхронизации… ну или вы можете рассматривать эти статьи не как обучающие, а, скажем, как аналитические — мы рассматриваем ряд проблем и их решений, которые относятся к сфере «сделать данные доступными офлайн». Как-то так. Поехали?
Будущее уже здесь
После просмотра вступительного ролика вам может показаться, что PWA — это такое «безоблачное будущее» (но с облачными технологиями, ага), причём не только для сайтов-одностраничников и простых сервисов, но и суровых контент-провайдеров, таких как the Guardian, например. Но если вы по каким-то причинам не разделяете наше убеждение, что PWA — это то, как будет развиваться веб в ближайшее время, то по меньшей мере можете быть заинтересованы, куда ведёт дорожка PWA и какие технологии будут развиваться в этом направлении. И это мы тоже обсудим.
Немного очевидного
Если вы знакомы с постом от разработчиков AirBerlin, то уже знаете, как хранить элементы вашего сайта в кэше ServiceWorker’а. Скорее всего, также у вас есть некоторые представления о том, как хранить в индексной базе данных актуальный контент, поступивший с сервера. Ну и ещё вы можете догадываться о том, что пользовательские данные (введённые поля, формы, заметки, контакты, координаты, практически что угодно) можно также хранить в БД или в localStorage, чтобы отправить их на сервер при первой возможности. Например, когда смартфон подключится к WiFi в отеле при отключенной передаче данных в роуминге.
Ещё немного побуду Кэпом и выделю вот такие сценарии:
- Данные отправляет только сервер (например, новости);
- Данные отправляет только клиент (заметки в облако, ага);
- Клиент и сервер обмениваются данными (да та же электронная почта, сервисы типа Dropbox или Google Drive, в общем, вы поняли).
Прежде чем мы будем изобретать велосипеды, предлагаю пошагово проанализировать все три случая и мысленно наступить на все грабли, которые можно собрать.
Во вступительном ролике Джейк показывал пример приложения с чатом. Забегая вперёд скажу, что он использовал Background Sync Api для отправки новых сообщений «потом», как только браузер посчитает, что он действительно получил доступ к интернет-подключению (а не просто подключился к сети, в которой интернета может и не быть, как, например, до авторизации в сети московского метрополитена).
Это отличный пример хорошего интерфейса. Взаимодействие происходит как только пользователь подключается к сети. До этого момента все сообщения помечены специальным образом: пользователь понимает, что они ещё не доставлены получателю, но уже не потеряются и будут отправлены при первом случае, и от него (пользователя) ничего не требуется.
В этом же ролике Джейк объяснял, что мобильные ОС (и браузеры, так как работают в этих ОС) не всегда могут надёжно определить, действительно ли устройство подключено к интернету или нет. Максимум данных, которые они могут получить, — это информация о подключении к сотовой вышке или к WiFi-роутеру. А между тем, от вышки или роутера до веб-сервера множество отрезков сети, на каждом из которых может что-нибудь пойти не так. Начиная с оборудования вашего интернет-провайдера, прозрачного прокси-сервера или магистрального оборудования, заканчивая чем-нибудь типа спутникового канала передачи данных или глобального файрвола, по типу китайского.
Представьте себе, что вы используете чат Джейка и пытаетесь отправить сообщение «позвоню в 7:30 вечера», но поезд движется очень быстро и через сеть длинных тоннелей с небольшими отрезками на открытом воздухе. Или вы подключены к публичному хот-споту с авторизацией, но авторизацию не прошли. Или находитесь на хакатоне, а вместе с вами здесь сотня человек. А лучше — на концерте, который собрал целый стадион, и почти у каждого с собой мобильник, который пытается что-то передавать через сеть оператора. В общем, ситуаций миллион, а суть одна: наш телефон хочет что-то отправить или получить. Для этого он вызывает сервис Background Sync, а тот, в свою очередь, пытается доставить наше сообщение. Даже если к этому моменту «окно» для подключения пропало, нам беспокоиться не о чем: Background Sync будет ждать следующего и повторит попытку. Вам как пользователю уже не интересно, что станет с сообщением, достаточно знать, что оно рано или поздно будет доставлено. Теперь давайте заглянем под капот этой технологии.
Цикличность (веб)бытия
Сколько бы прыжков по серверам и прочим элементам сети ваши пакеты ни сделали (а на каждом может что-то пойти не так, и вы получите одну из HTTP-ошибок), в общем случае остаётся только два значимых процесса. Запрос и ответ. Сломаться может и тот, и другой, так что у нас получается два сценария:
- Запрос не прошёл;
- Запрос прошёл, а ответ не прошёл.
И если первый случай почти полностью покрывается возможностями Background Sync, то что делать со вторым? Представьте себе вот такой случай: вы отправили сообщение, сервер его принял и переслал конечному получателю. А вашему устройству сообщил, что всё в порядке и сообщение обработано.
А теперь подумайте, что будет, если на этапе от «сервер принял и переслал» до самого конца где-нибудь произойдёт разрыв соединения. Что тогда? Background Sync не получит подтверждения о том, что сообщение ушло корректно, и постарается переслать его повторно при первой же возможности. Сервер снова примет его, снова перешлёт получателю. И теперь у получателя таких сообщений два. Нехорошо вышло. Ну а если нам сказочно везёт, и ответ не успел / не смог пройти и в этот раз, то BS отправит сообщение ещё. И ещё. И ещё. А у вашего собеседника будет нескончаемый поток одинаковых сообщений (из-за чего он может подумать о вас чего нехорошего, или вообще забанить).
Теперь давайте подумаем, как избежать данной неприятности.
На самом деле, самым простым решением будет какая-нибудь серверная проверка, но её мы введём позже. Ну а пока просто посмотрим, как решить эту проблему на более общем уровне. Так мы сможем применить полученное решение не только к текстовым сообщениям, а вообще к любым вопросам рассинхронизации.
Идентификация
Вновь немного поработаю кэпом. В программировании подобных штук давно и прочно сложился тренд на применение ООП. В общем — всё есть объект, и все данные перемещаются внутри контейнеров-объектов. И если мы хотим повторно сослаться на тот или иной объект, нам необходимо уметь однозначно идентифицировать его. Иногда это означает присвоение объекту имени (например, автоматически генерируемый ID с увеличивающимся числом), а иногда мы можем получить имя объекта напрямую из его свойств.
Банальный пример — список контактов вашего телефона. Предположим, у людей никогда не бывает одинаковых ФИО (предположение так себе, но для наглядного примера сойдёт). Идентификатором (ID’шником, если по-простому) может служить связка «Имя_Фамилия». В среде разработчиков БД подобное явление известно как «естественный ключ».
Преимущества естественных ключей в том, что вам не требуется хранить никаких дополнительных данных. Часть объекта и есть его идентификатор. Недостатки тоже есть. Во-первых, могут быть проблемы с уникальностью (пример выше с «условностью» о неповторяемости ФИО тому подтверждение), во-вторых, ключи иногда могут меняться, и с этим надо что-то делать.
Изменение ключей
Предположим, вы выбрали в качестве естественного ключа поле с адресом электронной почты. Пользователь меняет в своём профиле электронную почту, и у вас на сервере меняется ID’шник пользователя. С одной стороны — всё хорошо, автоматизация, актуальность информации… А с другой — остальные объекты (например, хранилище документов, привязанных к этой почте) все ещё содержат ссылки на старый ID, а значит, им необходимо обновить зависимости. Если такие изменения происходят сравнительно нечасто — проблем особых не возникнет, но существуют натуральные ключи, которые обновляются гораздо чаще, и нагрузки по обновлению зависимостей в БД могут стать как минимум ощутимыми.
Уникальность
Вернёмся к примеру с телефонной книгой. Людей с ФИО «Иванов Василий Петрович» может быть несколько, и какой из объектов по ID Василий_Иванов нам вернётся по запросу?

Суррогатные ключи
Для избавления ото всех этих проблем придуманы суррогатные ключи. Они могут быть просты (хоть увеличивающимся натуральным числом), могут быть сложны (хэш от ряда изначальных параметров объекта при создании + соль), у них нет проблем с уникальностью или изменением. Недостаток суррогатных ключей — их непрозрачность. Без вызова объекта узнать, что скрывается за ID 43135, вы не сможете, даже если внутри записаны все те же данные, что и в объекте Василий_Иванов. Компьютеру-то наплевать, он и запрос сделает, и объект декодирует, если надо. Беда в том, что суррогатные ключи иногда прорываются в наш с вами мир, и с ними приходится взаимодействовать людям. Запоминать их, передавать, обрабатывать… За примером далеко ходить не надо: номер телефона — типичный суррогатный ключ для вас как для абонента. Или серия и номер паспорта.
Ещё один недостаток суррогатных ключей — сложность в дебаге или составлении логов. Представьте, что у вас в телефоне есть 20 пропущенных вызовов с разных номеров. А записная книжка только на бумаге. Чтобы выяснить, кто и когда вам звонил, придётся составить таблицу соответствия телефонов и абонентов, а уже после этого анализировать данные. А теперь экстраполируйте полученный опыт на краш-репорты с мегабайтом данных и вот таких «непрозрачных» ключей. Выявить в них закономерность, не декодируя ключи в понятные человеку значения… мягко говоря затруднительно.
С теорией мы более-менее разобрались, вернёмся к нашей проблеме. Так как мы хотим сделать наши данные доступными офлайн, это автоматом означает, что данные будут находиться и на сервере, и на клиентском устройстве. То есть у нас будет несколько копий одинаковых данных, и мы должны быть уверены, что любые операции с этими данными могут однозначно идентифицировать объект, с которыми производятся манипуляции.
Когда мы создаём новый объект, мы присваиваем ему уникальный ID. Как мы уже обсуждали выше, естественные ключи не могут обеспечить нам уникальность: на сервере и клиенте могут быть два объекта Василий_Иванов, и это создаст кучу проблем при общении, особенно если у одного из них пропало соединение с сетью. Поэтому натуральные ключи используются тогда, когда их недостатки не могут причинить нам неудобств. А вот во всех остальных случаях мы используем суррогатные ключи, а если быть более точным — универсальные уникальные идентификаторы (UUID).
Если быть честным, то UUID не совсем уникальные. Повтор может случиться, но его вероятность настолько мала, что проще выиграть в лотерею миллион или квартиру, купив единственный билетик, чем наткнуться на два одинаковых UUID в массиве из 1015 ключей. Этой вероятностью можно смело пренебречь и считать, что данные с разными UUID на устройствах являются однозначно идентифицируемыми.
Что ж, с проблемой идентификации мы разобрались, но перед нами встала другая: у нас есть несколько наборов данных, которые могут отличаться, а могут и не отличаться друг от друга. Причём отличия могут быть разными для всех наборов на разных устройствах. Давайте разберёмся, что делать в такой ситуации, что синхронизировать, как это делать и в каком направлении проводить синхронизацию, чтобы всё работало, как часы.
Копнём чуть глубже
Снова включим нашу фантазию. Допустим, у нас есть мобильное приложение для чтения новостей и сервер, на котором они хранятся. В реальности есть блоги и RSS — они тоже хороший пример, если у кого с фантазией так себе. Так вот, допустим, пользователь запускает наше приложение впервые, и на устройстве не хранится никаких данных — читать нечего. Приложение обращается к серверу: «Пришли-ка мне подборку свежих статей». В результате пользователь получает контент, который хотел.
Спустя некоторое время приложение запускают повторно, оно снова просит у сервера порцию свежачка, и тут, если мы хороший разработчик и делаем всё по уму, у нас встречается первая интересная задачка: надо сделать так, чтобы имеющиеся статьи повторно не пересылались на пользовательское устройство. Почему мы так делаем? Здесь причин сразу несколько:
- Эти статьи УЖЕ есть на устройстве, так что действия избыточны;
- Отправка лишних данных стоит нам серверного времени;
- Отправка лишних данных стоит пользователям трафика;
- Чем больше данных — тем больше задержки. Никто не любит задержки.
В целом все эти причины приводят к двум не очень желательным штукам — затратам и ожиданию. К слову, одно из неписанных правил юзабилити звучит примерно так: «Не позволяйте пользователям находиться в бесцельном ожидании, а то они расстроятся и перестанут пользоваться вашим продуктом». Так что же мы предпримем?
Решаем проблемы
Ну если говорить простым языком, то надо сделать запрос к серверу, который будет понят им так: «У меня есть все статьи на такое-то время, так что пришли мне что-нибудь НОВЕНЬКОЕ». Разницу между «все статьи» и «все статьи, что есть на пользовательском устройстве» мы будем называть дельтой (то есть по сути разницей). В данном случае дельта и будет искомым контентом, который мы хотим получить с сервера.
Вычисляем дельту
Для эффективного вычисления дельты нам нужны две составляющих:
- Наше приложение должно уметь сохранять сведения о своём состоянии где-нибудь, то есть знать, какие статьи у него уже есть. Мы будем называть эти сведения "закладка" (прим. пер.: в оригинале — High Watermark, но устоявшегося термина нет, а «закладка» в контексте книжной штуковины, отмечающей последнюю страницу — вполне подходит), почему оно так называется — потом поймёте. В случае с нативным приложением эта информация может храниться в локальной БД или просто в конфигурационном файле, ну а если у вас сайт или веб-приложение, данные можно оставить на хранение браузеру, в конце концов для этого придуманы localStorage и IndexDB;
- Серверу нужен список всех статей, отсортированный по дате публикации. Желательно, чтобы этот список строился максимально эффективно, а сервер мог отправить клиенту любую выборку статей с указанной даты по текущую.
Самая простая реализация серверной части будет выглядеть примерно так: сервер собирает статьи из базы данных, а прежде чем отправить их на устройство, он сортирует их по дате публикации в оперативной памяти. Если запрос от устройства содержит закладку — то пересылаем только те материалы, что идут после неё.
Прим. пер.: По смыслу получается примерно то же самое, что читать книгу, которую автор ещё пишет. Вы прочитали все написанные главы, забыли о книге, скажем, на месяц. А после запрашиваете ещё. Сервер присылает вам электронные версии только тех глав, что вышли после вашей «закладки», а не всё произведение целиком.
Работать это будет, но об эффективности подобного решения даже говорить не хочется. Оно грубое, как топор. А нам нужно что-то вроде хорошего шефского ножа, а лучше — скальпель. Оптимизации напрашиваются очевидные. Неплохо бы, чтобы статьи в БД были изначально отсортированы как надо, а не загружались всем объёмом в память и сортировались в ней. Потому что топорное решение будет отлично работать на маленьких статейках с десятком пользователей, а если у вас статьи по много килобайт, а пользователей — десятки тысяч? В общем, нам нужен масштабируемый, надёжный и эффективный подход. А значит, как и все нормальные разработчики, мы добавим к базе статей ещё и индекс.
Индексация
Бонусы от индексации статей очевидны. Во-первых, их можно упорядочить. Если статьи будут храниться на диске в упорядоченном виде (по дате публикации, от старых к новым) — мы и к диску обращаться будем быстрее, и последовательное чтение выполнять без лишних перемещений головки диска, и вообще значительно ускорим работу. Ну а во-вторых, нам будут доступны выборки. Прочитать только часть статей, скажем, с такой-то даты по такую-то — куда лучше, чем загружать всю базу в память и потом в ней ковыряться с каждой статьёй по отдельности.
Скорее всего, БД уже имеет автоматически увеличивающееся число в качестве первичного ключа. То есть каждая новая статья в БД будет иметь номер, который на единичку выше, чем предыдущая. Отлично подойдёт в качестве ID’шника: легко хранить, удобно использовать.
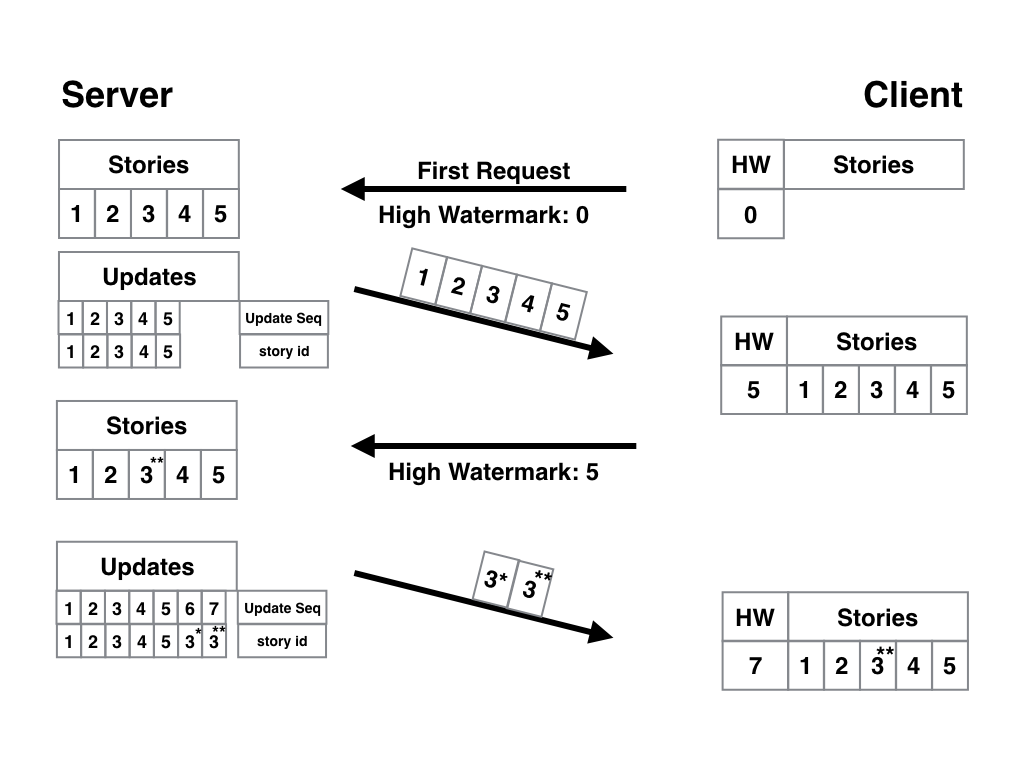
С таким ID и правильно организованной БД алгоритм работы приложения становится намного проще. Устройство делает первый запрос к серверу с закладкой, равной 0, и получает все актуальные статьи. В качестве закладки хранится только ID последней полученной записи. В следующий запрос к серверу включается хранящийся в закладке ID (пусть будет статья №5), и сервер присылает нам только то, что новее пятой статьи. Вот наглядная схема:

Обновления старых материалов
В статьях бывают опечатки. Или непроверенные факты. Или вообще надо дописать обновление или опровержение. Исправить-то на сервере мы их можем, а у пользователей статьи на устройствах уже есть. С нашей предыдущей системой они не обновятся — так как в закладке будет указано, что они уже есть, и сервер новые версии старых материалов нам не пришлёт. Для того чтобы грамотно разрулить ситуацию, одних автоувеличивающихся ID мало. Добавим в базу данных не только список статей, но и отдельную табличку, в которой будет содержаться только два значения — ID статьи и время её последнего обновления, превращённое в ещё одно простое число. В качестве закладки будет использоваться не ID статьи, а ID обновления. И если у вас есть пять статей, и в третью вы внесли правки, то её ID обновления будет уже 6, так что при следующем запросе клиент получит актуальную версию вместе с новыми статьями, если такие вообще будут. В общем, всё просто работает и не содержит критических недостатков, которые были у первых версий:

Дальше — больше
На первый взгляд всё хорошо — клиент получает новые материалы, обновления к старым, неизменные статьи никто не трогает… А что будет, если мы возьмём всё ту же статью №3 и обновим её дважды? Её ID обновления также вырастет дважды:

Получается, что вычисленная дельта содержит статью 3 дважды? Одну актуальную, а другую уже не очень актуальную, но всё ещё лучше той, что лежит у пользователя на устройстве? В случае с пятью статьями, конечно, некритично, но мы уже говорили, архитектуру надо планировать так, чтобы она хорошо масштабировалась. Пользователей, как и статей, может быть много тысяч, обновлений и наших статей — десятки (пусть это будут прямые репортажи с мест событий). А мы будем отправлять неактуальные версии и тратить ресурсы серверов, нагружать сети и заставлять пользователей платить за трафик и ждать то, что уже потеряло актуальность? Нехорошо это.
Исправляем это недоразумение
Индекс обновлений, который мы использовали, называют инкрементальным. Это означает, что больше чем один элемент определяет и диапазон индекса, и сортировку в нём. В нашем случае у нас есть автоматически увеличивающийся ID обновления и статический ID с номером статьи.
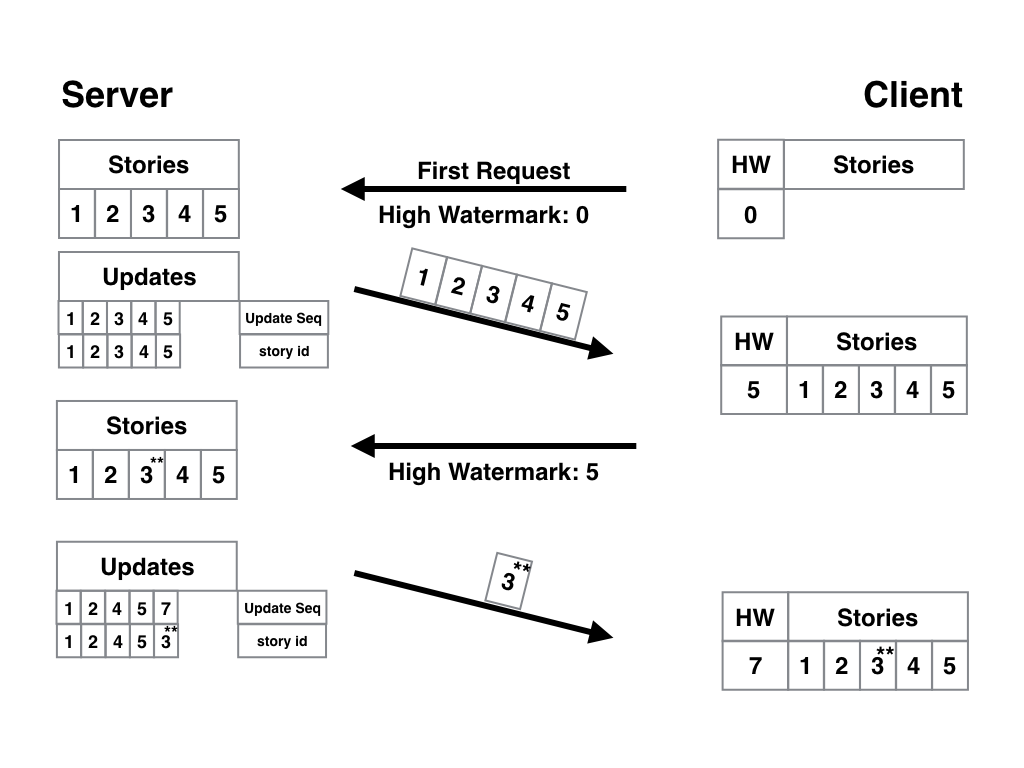
Для решения многократных обновлений одной и той же статьи нам достаточно внести одно простое изменение — сделать так, чтобы ID статьи был уникальным ключом таблицы. То есть каждый раз, как мы будем записывать в таблицу связку ID изменения + ID статьи, мы будем выполнять проверку, а есть-ли у нас что-нибудь ещё, связанное с этой статьёй? Если такая строка найдётся — мы её удаляем. Таким образом ID обновления будет только один — с самой последней версией статьи. Вот наглядная схема:
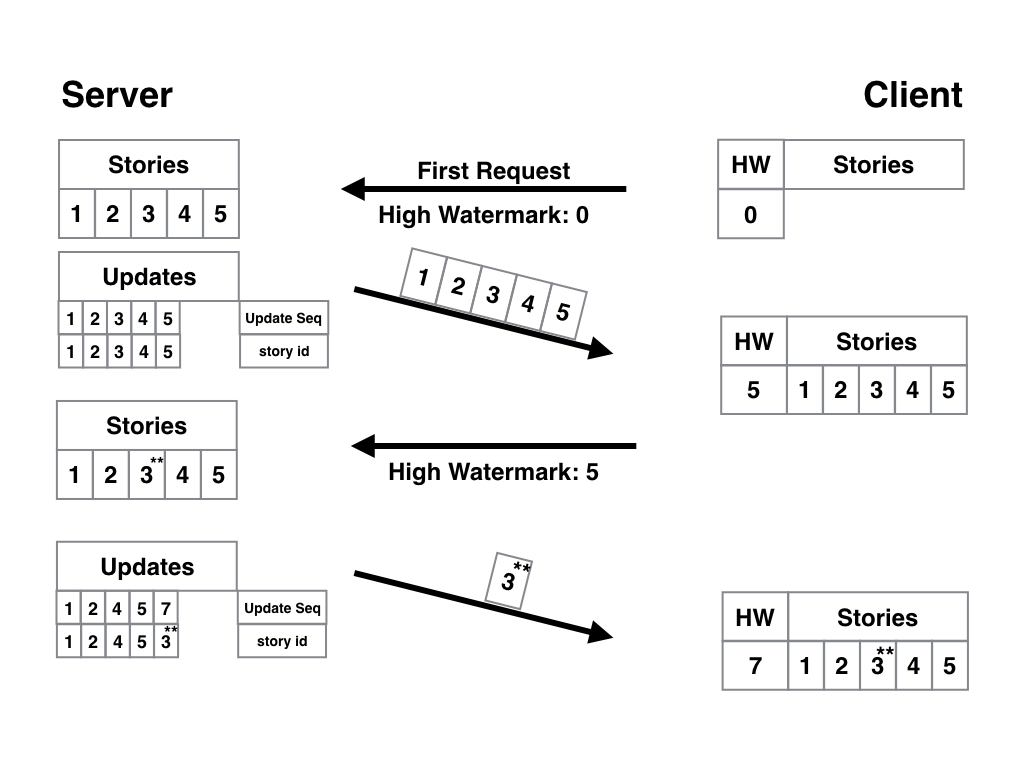
В принципе, по ней и так всё понятно, но на всякий случай поясню. Между первым и вторым запросом редактор дважды исправил статью №3. Так как её ID уникален, в таблице обновлений может быть только одна запись с такой статьёй, а значит, и первая строка, которая была актуальна на момент написания статьи, и вторая, с первым обновлением, — исчезли, и осталась лишь строка с ID обновления == 7 и статья с двумя правками. PROFIT! Ну и для полного удовлетворения нам осталось разобраться с последним аспектом работы такого алгоритма — удалением статей из базы и с пользовательского устройства.
Чистки
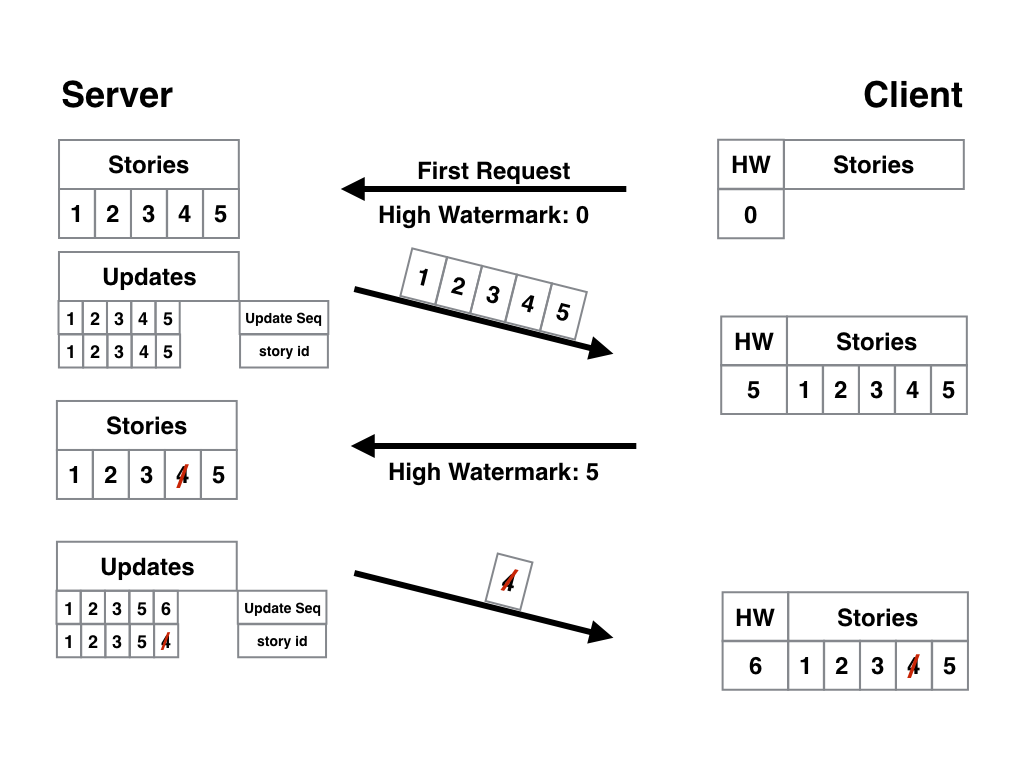
Допустим, какой-то горе-шутник в рассылку по бизнес-аналитике добавил статью с подборкой смешных котят. Редактор решил, что надо это дело быстренько затереть, пока никто не заметил, и… что надо реализовать программисту?
С точки зрения данных, удаление может мало чем отличаться от обновления записи — просто пометим как удаленную, но фактически не уничтожим. Ну а для нас с вами удаление вообще может быть равносильно правке статьи — мы можем хоть строчку «извините, статья удалена» вписать вместо текста. Работает технически всё идентично — в таблице обновлений появляется новый ID, с которым связана статья «удалённая 4». Клиентское устройство при следующем запросе получает обновление, в котором сказано, что статья 4 удалена. А там уже вопрос «как обрабатывать» — на вашей совести. Самое простое, что можно сделать (правда, это точно понравится не всем пользователям), — удалять статью и из локального хранилища. Как-то так:

На сегодня у нас всё, во второй части статьи мы рассмотрим более сложную ситуацию: двустороннюю работу такого сервиса по синхронизации контента, когда не только сервер, но и клиент может работать с контентом. С одной стороны, это всё можно отнести к базовым знаниям, а с другой — без таких вот знаний не построить грамотную архитектуру с нуля. В общем, вот вам задание — подумайте о том, какие проблемы могут быть с таким сервисом и как их решать, а потом проверьте себя: всё ли вы нашли, и схоже мы мыслим или нет.
Кроме того, много интересно вас ждет и на онлайн конференции PWA Day, которая состоится 11 октября.
Источники:
