
Привет, Хабр! Меня зовут Саша и я backend разработчик. В свободное от работы время я изучаю ML и развлекаюсь с данными hh.ru.
Эта статья о том, как мы с помощью машинного обучения автоматизировали рутинный процесс назначения задач на тестировщиков.
В hh.ru есть внутренняя служба, на которую в Jira создаются задачи (внутри компании их называют HHS), если у кого-то что-то не работает или работает неправильно. Дальше эти задачи вручную обрабатывает руководитель группы QA Алексей и назначает на команду, в чью зону ответственности входит неисправность. Лёша знает, что скучные задачи должны выполнять роботы. Поэтому он обратился ко мне за помощью по части ML.

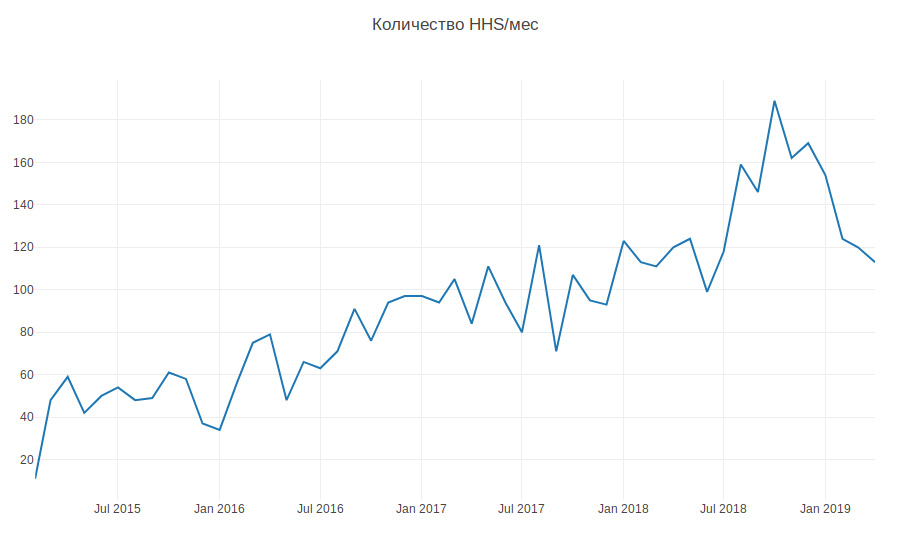
График ниже показывает количество HHS в месяц. Мы растём и количество задач растёт. Задачи в основном создаются в рабочее время по несколько штук в сутки, и на это приходится постоянно отвлекаться.

Итак, необходимо по историческим данным научиться определять команду разработчиков, к которой относится HHS. Это задача многоклассовой классификации.
В задачах с машинным обучением самое главное — это качественные данные. От них зависит исход решения проблемы. Поэтому любые задачи по машинному обучению надо начинать с изучения данных. С начала 2015 года у нас накопилось около 7000 задач, которые содержат следующую полезную информацию:
Начнем с целевой переменной. Во-первых, у каждой команды есть зоны ответственности. Иногда они пересекаются, иногда одна команда может пересекаться в разработках с другой. Решение будет строиться на предположении о том, что assignee, который остался у задачи на момент закрытия, является ответственным за её решение. Но нам нужно предсказывать не конкретного человека, а команду. К счастью, у нас в Jira хранится состав всех команд и можно смапить. Но с определением команды по человеку есть ряд проблем:
После отсеивания нерелевантных данных, обучающая выборка сократилась до 4900 задач.
Посмотрим на распределение задач между командами:

Задачи нужно распределять между 22 командами.
Summary и Description — текстовые поля.
Сначала стоит их почистить от лишних символов. Для некоторых задач имеет смысл оставлять в строках символы, несущие информацию, например + и #, чтобы различать c++ и c#, но в этом случае я решил оставить только буквы и цифры, т.к. не нашел, где иные символы могут быть полезны.
Слова нужно лемматизировать. Лемматизация — приведение слова к лемме, его нормальной (словарной) форме. Например, кошками → кошка. Также пробовал стемминг, но с лемматизацией качество было немного выше. Стемминг — это процесс нахождения основы слова. Эта основа находится за счет алгоритма (в разных реализациях они разные), например, кошками → кошк. Смысл первого и второго в том, чтобы сопоставить друг другу одни и те же слова в разных формах. Я использовал питоновскую обертку для Yandex Mystem.
Дальше текст стоит очистить от стоп-слов, не несущих полезной нагрузки. Например, «было», «мне», «ещё». Стоп-слова я обычно беру из NLTK.
Еще один подход, который я пробую в задачах работы с текстом — посимвольное дробление слов. Например, есть «поиск». Если разбивать его на составляющие по 3 символа, то получатся слова «пои», «оис», «иск». Это помогает получить дополнительные связи. Допустим, есть еще слово «искать». Лемматизация не приводит «поиск» и «искать» к общей форме, но разбиение по 3 символа выделит общую часть — «иск».
Я сделал два токенайзера. Токенайзер — метод, на вход которому подается текст, а на выходе получается список токенов — составляющих текста. Первый выделяет лемматизированные слова и числа. Второй выделяет только лемматизированные слова, которые разбивает по 3 символа, т.е. на выходе у него список трехсимвольных токенов.
Токенайзеры используются в TfidfVectorizer-е, который служит для преобразования текстовых (и не только) данных в векторное представление на основе tf-idf. На вход ему подается список строк, а на выходе получаем матрицу M на N, где M — число строк, а N — количество признаков. Каждый признак — это частотная характеристика слова в документе, где частота штрафуется, если данное слово много раз встречается во всех документах. Благодаря параметру ngram_range TfidfVectorizer я добавил в качестве признаков еще биграммы и триграммы.
Также я попробовал в качестве дополнительных признаков использовать эмбеддинги слов, полученные с помощью Word2vec. Эмбеддинг — это векторное представление слова. Для каждого текста я усреднял эмбеддинги всех его слов. Но никакого прироста это не дало, поэтому я отказался от этих признаков.
Для Labels был использован CountVectorizer. На вход ему подаются строки с тегами, а на выходе имеем матрицу, где строки соответствуют задачам, а столбцы — тегам. В каждой ячейке содержится количество вхождений тега в задаче. В моем случае, это 1 или 0.
Для Reporter подошел LabelBinarizer. Он бинаризует признаки по типу “один-против-всех”. Для каждой задачи может быть только один создатель. На вход в LabelBinarizer подается список создателей задач, а на выходе получается матрица, где строки — задачи, а столбцы соответствуют именам создателей задач. Получается, что в каждой строке стоит “1” в колонке, соответствующей создателю, а в остальных — “0”.
Для Created считается разница в днях между датой создания задачи и текущей датой.
В итоге получились следующие признаки:
Все эти признаки объединяются в одну большую матрицу (4855, 129478), на которой будет производиться обучение.
Отдельно стоит отметить имена признаков. Т.к. некоторые модели машинного обучения умеют выделять признаки, оказавшие наибольшее влияние на распознавание класса, надо этим воспользоваться. TfidfVectorizer, CountVectorizer, LabelBinarizer имеют методы get_feature_names, возвражающие список признаков, порядок которых соответствует столбцам матриц с данными.
Очень часто хорошие результаты дает XGBoost. С него и начал. Но я сгенерировал огромное количество признаков, число которых значительно превышает размер обучающей выборки. В таком случае велика вероятность переобучения XGBoost. Результат получился не очень. Высокую размерность хорошо переваривает LogisticRegression. Она показала более высокое качество.
Еще я пробовал в качестве упражнения построить модель на нейронной сети в Tensorflow по вот этой прекрасной обучалке, но получилось хуже, чем у логистической регрессии.
С гиперпараметрами XGBoost и Tensorflow я тоже игрался, но оставляю это за пределами поста, т.к. результат логистической регрессии не был превзойден. У последней я крутил все ручки, которые только можно. Все параметры в итоге остались дефолтными, кроме двух: solver='liblinear' и С=3.0
Еще один параметр, который может влиять на результат — размер обучающей выборки. Т.к. я имею дело с историческими данными, а за несколько лет история может серьезно меняться, например, ответственность за что-то может перейти в другую команду, то более свежие данные могут приносить больше пользы, а старые даже понижать качество. На этот счет я придумал эвристику — чем старее данные, тем меньший вклад они должны делать в обучение модели. В зависимости от старости данные умножаются на определенный коэффициент, который берется из функции. Я сгенерировал несколько функций для затухания данных и использовал ту, которая дала наибольший прирост на тестировании.

Благодаря этому качество классификации выросло на 3%
В задачах классификации надо задумываться, что для нас важнее — точность или полнота? В моем случае, если алгоритм ошибается, то нет ничего страшного, у нас очень хорошо шарятся знания между командами и задача будет переведена на ответственных, либо на главного в QA. К тому же, алгоритм ошибается не рандомно, а находит близкую к проблеме команду. Поэтому было решено за полноту взять 100%. А для измерения качества была выбрана метрика accuracy — доля правильных ответов, которая для итоговой модели составила 76%.
В качестве механизма валидации я сначала использовал кросс-валидацию — когда выборка разбивается на N частей и на одной части проверяется качество, а на остальных производится обучение, и так N раз, пока каждая часть не побывает в роли тестовой. Результат затем усредняется. Но в моем случае этот подход не подошел, т.к. меняется порядок данных, а как уже стало известно, от свежести данных зависит качество. Поэтому я обучался всё время на старых, а валидировался на свежих.
Посмотрим, какие команды чаще всего путает алгоритм:
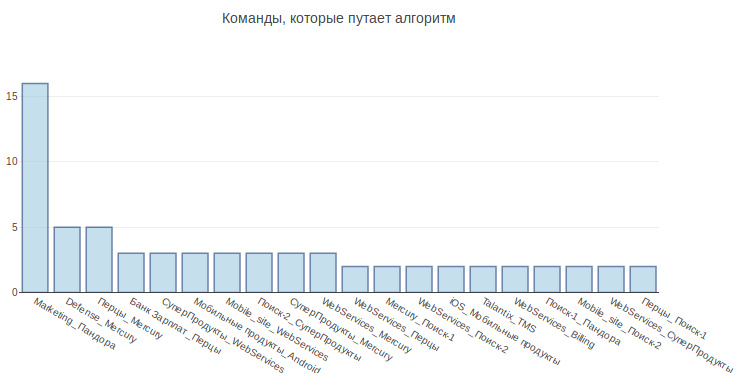
На первом месте Marketing и Пандора. Это не удивительно, т.к. вторая команда выросла из первой и забрала с собой ответственность за множество функциональностей. Если рассмотреть остальные команды, то можно так же углядеть причины, связанные с внутренней кухней компании.
Для сравнения хочется посмотреть на случайные модели. Если назначать ответственного рандомно, то качество будет около 5%, а если на самый распространенный класс, то — 29%
LogisticRegression для каждого класса возвращает коэффициэнты признаков. Чем больше значение, тем больший вклад этот признак сделал в этот класс.
Под спойлером вывод топа признаков. Префиксы означают откуда были получены признаки:
Признаки примерно отражают чем занимаются команды
На этом построение модели закончено и можно на её основе строить программу.

Программа состоит из двух Python-скриптов. Первый строит модель, а второй выполняет предсказания.
Чтобы программу было удобно разворачивать и иметь те же версии библиотек, что и при разработке, скрипты упаковываются в Docker контейнер.
В итоге мы автоматизировали рутинный процесс. Точность в 76% — не слишком большая, но в этом случае промахи не критичны. Все задачи находят своих исполнителей, и самое главное, что для этого теперь не нужно отвлекаться по несколько раз в день, чтобы вникать в суть задач и искать ответственных. Все работает автоматически! Ура!
Эта статья о том, как мы с помощью машинного обучения автоматизировали рутинный процесс назначения задач на тестировщиков.
В hh.ru есть внутренняя служба, на которую в Jira создаются задачи (внутри компании их называют HHS), если у кого-то что-то не работает или работает неправильно. Дальше эти задачи вручную обрабатывает руководитель группы QA Алексей и назначает на команду, в чью зону ответственности входит неисправность. Лёша знает, что скучные задачи должны выполнять роботы. Поэтому он обратился ко мне за помощью по части ML.

График ниже показывает количество HHS в месяц. Мы растём и количество задач растёт. Задачи в основном создаются в рабочее время по несколько штук в сутки, и на это приходится постоянно отвлекаться.
Итак, необходимо по историческим данным научиться определять команду разработчиков, к которой относится HHS. Это задача многоклассовой классификации.
Данные
В задачах с машинным обучением самое главное — это качественные данные. От них зависит исход решения проблемы. Поэтому любые задачи по машинному обучению надо начинать с изучения данных. С начала 2015 года у нас накопилось около 7000 задач, которые содержат следующую полезную информацию:
- Summary — заголовок, краткое описание
- Description — полное описание проблемы
- Labels — список тегов, связанных с проблемой
- Reporter — имя создателя HHS. Этот признак полезен, потому что люди работают с ограниченным набором функциональностей
- Created — дата создания
- Assignee — тот, на кого назначена задача. Из этого признака будет сгенерирована целевая переменная
Начнем с целевой переменной. Во-первых, у каждой команды есть зоны ответственности. Иногда они пересекаются, иногда одна команда может пересекаться в разработках с другой. Решение будет строиться на предположении о том, что assignee, который остался у задачи на момент закрытия, является ответственным за её решение. Но нам нужно предсказывать не конкретного человека, а команду. К счастью, у нас в Jira хранится состав всех команд и можно смапить. Но с определением команды по человеку есть ряд проблем:
- не все HHS связаны с техническими неполадками, а нас интересуют только те задачи, которые можно назначить на команду разработчиков. Поэтому надо выкинуть задачи, где assignee не из технического департамента
- иногда команды прекращают свое существование. Они тоже удаляются из обучающей выборки
- к сожалению, люди не работают вечно в компании, а иногда перемещаются из команды в команду. К счастью, удалось получить историю изменения состава всех команд. Имея дату создания HHS и assignee, можно найти, какая команда занималась задачей в определенное время.
После отсеивания нерелевантных данных, обучающая выборка сократилась до 4900 задач.
Посмотрим на распределение задач между командами:

Задачи нужно распределять между 22 командами.
Признаки:
Summary и Description — текстовые поля.
Сначала стоит их почистить от лишних символов. Для некоторых задач имеет смысл оставлять в строках символы, несущие информацию, например + и #, чтобы различать c++ и c#, но в этом случае я решил оставить только буквы и цифры, т.к. не нашел, где иные символы могут быть полезны.
Слова нужно лемматизировать. Лемматизация — приведение слова к лемме, его нормальной (словарной) форме. Например, кошками → кошка. Также пробовал стемминг, но с лемматизацией качество было немного выше. Стемминг — это процесс нахождения основы слова. Эта основа находится за счет алгоритма (в разных реализациях они разные), например, кошками → кошк. Смысл первого и второго в том, чтобы сопоставить друг другу одни и те же слова в разных формах. Я использовал питоновскую обертку для Yandex Mystem.
Дальше текст стоит очистить от стоп-слов, не несущих полезной нагрузки. Например, «было», «мне», «ещё». Стоп-слова я обычно беру из NLTK.
Еще один подход, который я пробую в задачах работы с текстом — посимвольное дробление слов. Например, есть «поиск». Если разбивать его на составляющие по 3 символа, то получатся слова «пои», «оис», «иск». Это помогает получить дополнительные связи. Допустим, есть еще слово «искать». Лемматизация не приводит «поиск» и «искать» к общей форме, но разбиение по 3 символа выделит общую часть — «иск».
Я сделал два токенайзера. Токенайзер — метод, на вход которому подается текст, а на выходе получается список токенов — составляющих текста. Первый выделяет лемматизированные слова и числа. Второй выделяет только лемматизированные слова, которые разбивает по 3 символа, т.е. на выходе у него список трехсимвольных токенов.
Токенайзеры используются в TfidfVectorizer-е, который служит для преобразования текстовых (и не только) данных в векторное представление на основе tf-idf. На вход ему подается список строк, а на выходе получаем матрицу M на N, где M — число строк, а N — количество признаков. Каждый признак — это частотная характеристика слова в документе, где частота штрафуется, если данное слово много раз встречается во всех документах. Благодаря параметру ngram_range TfidfVectorizer я добавил в качестве признаков еще биграммы и триграммы.
Также я попробовал в качестве дополнительных признаков использовать эмбеддинги слов, полученные с помощью Word2vec. Эмбеддинг — это векторное представление слова. Для каждого текста я усреднял эмбеддинги всех его слов. Но никакого прироста это не дало, поэтому я отказался от этих признаков.
Для Labels был использован CountVectorizer. На вход ему подаются строки с тегами, а на выходе имеем матрицу, где строки соответствуют задачам, а столбцы — тегам. В каждой ячейке содержится количество вхождений тега в задаче. В моем случае, это 1 или 0.
Для Reporter подошел LabelBinarizer. Он бинаризует признаки по типу “один-против-всех”. Для каждой задачи может быть только один создатель. На вход в LabelBinarizer подается список создателей задач, а на выходе получается матрица, где строки — задачи, а столбцы соответствуют именам создателей задач. Получается, что в каждой строке стоит “1” в колонке, соответствующей создателю, а в остальных — “0”.
Для Created считается разница в днях между датой создания задачи и текущей датой.
В итоге получились следующие признаки:
- tf-idf для Summary на словах и числах (4855, 4593)
- tf-idf для Summary на трехсимвольных разбиениях (4855, 15518)
- tf-idf для Description на словах и числах (4855, 33297)
- tf-idf для Description на трехсимвольных разбиениях (4855, 75359)
- количество вхождений для Labels (4855, 505)
- бинарные признаки для Reporter (4855, 205)
- время жизни задачи (4855, 1)
Все эти признаки объединяются в одну большую матрицу (4855, 129478), на которой будет производиться обучение.
Отдельно стоит отметить имена признаков. Т.к. некоторые модели машинного обучения умеют выделять признаки, оказавшие наибольшее влияние на распознавание класса, надо этим воспользоваться. TfidfVectorizer, CountVectorizer, LabelBinarizer имеют методы get_feature_names, возвражающие список признаков, порядок которых соответствует столбцам матриц с данными.
Выбор модели для предсказания
Очень часто хорошие результаты дает XGBoost. С него и начал. Но я сгенерировал огромное количество признаков, число которых значительно превышает размер обучающей выборки. В таком случае велика вероятность переобучения XGBoost. Результат получился не очень. Высокую размерность хорошо переваривает LogisticRegression. Она показала более высокое качество.
Еще я пробовал в качестве упражнения построить модель на нейронной сети в Tensorflow по вот этой прекрасной обучалке, но получилось хуже, чем у логистической регрессии.
Подбор гиперпараметров
С гиперпараметрами XGBoost и Tensorflow я тоже игрался, но оставляю это за пределами поста, т.к. результат логистической регрессии не был превзойден. У последней я крутил все ручки, которые только можно. Все параметры в итоге остались дефолтными, кроме двух: solver='liblinear' и С=3.0
Еще один параметр, который может влиять на результат — размер обучающей выборки. Т.к. я имею дело с историческими данными, а за несколько лет история может серьезно меняться, например, ответственность за что-то может перейти в другую команду, то более свежие данные могут приносить больше пользы, а старые даже понижать качество. На этот счет я придумал эвристику — чем старее данные, тем меньший вклад они должны делать в обучение модели. В зависимости от старости данные умножаются на определенный коэффициент, который берется из функции. Я сгенерировал несколько функций для затухания данных и использовал ту, которая дала наибольший прирост на тестировании.
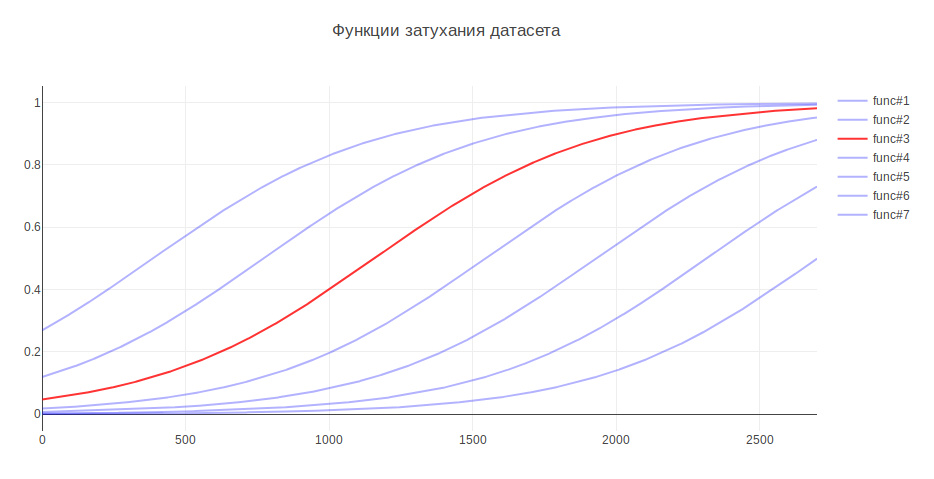
Благодаря этому качество классификации выросло на 3%
Оценка качества
В задачах классификации надо задумываться, что для нас важнее — точность или полнота? В моем случае, если алгоритм ошибается, то нет ничего страшного, у нас очень хорошо шарятся знания между командами и задача будет переведена на ответственных, либо на главного в QA. К тому же, алгоритм ошибается не рандомно, а находит близкую к проблеме команду. Поэтому было решено за полноту взять 100%. А для измерения качества была выбрана метрика accuracy — доля правильных ответов, которая для итоговой модели составила 76%.
В качестве механизма валидации я сначала использовал кросс-валидацию — когда выборка разбивается на N частей и на одной части проверяется качество, а на остальных производится обучение, и так N раз, пока каждая часть не побывает в роли тестовой. Результат затем усредняется. Но в моем случае этот подход не подошел, т.к. меняется порядок данных, а как уже стало известно, от свежести данных зависит качество. Поэтому я обучался всё время на старых, а валидировался на свежих.
Посмотрим, какие команды чаще всего путает алгоритм:

На первом месте Marketing и Пандора. Это не удивительно, т.к. вторая команда выросла из первой и забрала с собой ответственность за множество функциональностей. Если рассмотреть остальные команды, то можно так же углядеть причины, связанные с внутренней кухней компании.
Для сравнения хочется посмотреть на случайные модели. Если назначать ответственного рандомно, то качество будет около 5%, а если на самый распространенный класс, то — 29%
Наиболее значимые признаки
LogisticRegression для каждого класса возвращает коэффициэнты признаков. Чем больше значение, тем больший вклад этот признак сделал в этот класс.
Под спойлером вывод топа признаков. Префиксы означают откуда были получены признаки:
- sum — tf-idf для Summary на словах и числах
- sum2 — tf-idf для Summary на трехсимвольных разбиения
- desc — tf-idf для Description на словах и числах
- desc2 — tf-idf для Description на трехсимвольных разбиения
- lab — поле Labels
- rep — поле Reporter
Признаки
A-Team: sum_сайт(1.28), lab_отклики_и_приглашения(1.37), lab_отказ_работодателю(1.07), lab_вёрстка(1.03), sum_работа(1.04), sum_работа_сайт(1.59), lab_hhs(1.19), lab_feedback(1.06), rep_name_0(1.14), lab_brand(1.16), sum_окно(1.13), sum_сломаться(1.04), rep_name_1(1.22), lab_отклики_соискатель(1.0), lab_сайт(0.92)
API: lab_удаление_аккаунта(1.12), sum_комментарий_резюме(0.94), rep_name_2(0.9), rep_name_3(0.83), rep_name_4(0.89), rep_name_5(0.91), lab_менеджеры_вакансий(0.87), lab_комментарии_к_резюме(1.85), lab_api(0.86), sum_удаляться_аккаунт(0.86), sum_просмотр(0.91), desc_комментарий(1.02), rep_name_6(0.85), desc_резюме(0.86), sum_api(1.01)
Android: sum_android(1.77), lab_ios(1.66), sum_приложение(2.9), sum_hr_мобайл(1.4), lab_android(3.55), sum_hr(1.36), lab_мобильное_приложение(3.33), sum_мобайл(1.4), rep_name_2(1.34), sum2_рил(1.27), sum_приложение_android(1.28), sum2_при_рил_ило(1.19), sum2_при_рил(1.27), sum2_ило_лож(1.19), sum2_ило_лож_оже(1.19)
Billing: rep_name_7(3.88), desc_счет(3.23), rep_name_8(3.15), lab_billing_wtf(2.46), rep_name_9(4.51), rep_name_10(2.88), sum_счет(3.16), lab_billing(2.41), rep_name_11(2.27), lab_billing_support(2.36), sum_услуга(2.33), lab_оплата_услуг(1.92), sum_акт(2.26), rep_name_12(1.92), rep_name_13(2.4)
Brandy: lab_оценка_талантов(2.17), rep_name_14(1.87), rep_name_15(3.36), lab_clickme(1.72), rep_name_16(1.44), rep_name_17(1.63), rep_name_18(1.29), sum_страница(1.24), sum_брендированный(1.48), lab_описание_компании(1.39), sum_конструктор(1.59), lab_бренд.страницы(1.33), sum_описание(1.23), sum_описание_компания(1.17), lab_статья(1.15)
Clickme: desc_акт(0.73), sum_adv_hh(0.65), sum_adv_hh_ru(0.65), sum_hh(0.77), lab_hhs(1.27), lab_bs(1.91), rep_name_19(1.17), rep_name_20(1.29), rep_name_21(1.9), rep_name_8(1.16), sum_рекламный(0.67), sum_размещение(0.65), sum_adv(0.65), sum_hh_ua(0.64), sum_кликми_31(0.64)
Marketing: lab_регион(0.9), lab_тормозит_сайт(1.23), sum_рассылка(1.32), lab_менеджеры_вакансий(0.93), sum_календарь(0.93), rep_name_22(1.33), lab_опросы(1.25), rep_name_6(1.53), lab_производственный_календарь(1.55), rep_name_23(0.86), sum_яндекс(1.26), sum_распределение_вакансия(0.85), sum_распределение(0.85), sum_категория(0.85), sum_ошибка_переход(0.83)
Mercury: lab_услуги(1.76), sum_капча(2.02), lab_соискательские_сервисы(1.89), lab_lawyers(2.1), lab_авторизация_работодатель(1.68), lab_профориентация(2.53), lab_готовое_резюме(2.21), rep_name_24(1.77), rep_name_25(1.59), lab_рассылка_в_ка(1.56), sum_пользователь(1.57), rep_name_26(1.43), lab_модерация_вакансий(1.58), desc_пароль(1.39), rep_name_27(1.36)
Mobile_site: sum_мобильный_версия(1.32), sum_версия_сайт(1.26), lab_приложение(1.51), lab_статистика(1.32), sum_мобильный_версия_сайт(1.25), lab_мобильная_версия(5.1), sum_версия(1.41), rep_name_28(1.24), sum_страница_статистика(1.05), lab_нет(1.05), lab_jtb(1.07), rep_name_16(1.12), rep_name_29(1.05), sum_сайт(0.95), rep_name_30(0.92)
TMS: rep_name_31(1.39), lab_talantix(4.28), rep_name_32(1.55), rep_name_33(2.59), sum_вакансия_talantix(0.74), lab_поиск(0.57), lab_search(0.63), rep_name_34(0.64), lab_календарь(0.56), sum_импортироваться(0.66), lab_tms(0.74), sum_отклик_hh(0.57), lab_mailing(0.64), sum_talantix(0.6), sum2_мпо(0.56)
Talantix: sum_система(0.86), rep_name_16(1.37), sum_talantix(1.16), lab_почта(0.94), lab_xor(0.8), lab_talantix(3.19), rep_name_35(1.07), rep_name_18(1.33), lab_персональные_данные(0.79), rep_name_34(1.08), sum_талантикс(0.89), sum_происходить(0.78), lab_mail(0.77), sum_отклик_становиться_просматривать(0.73), rep_name_6(0.72)
WebServices: sum_вакансия(1.36), desc_шаблон(1.32), sum_архив(1.3), lab_шаблоны_писем(1.39), sum_номер_телефон(1.44), rep_name_36(1.28), lab_lawyers(2.1), lab_приглашение(1.27), lab_приглашение_на_вакансию(1.26), desc_папка(1.22), lab_избранные_резюме(1.2), lab_ключевые_навыки(1.22), sum_находить(1.18), sum_телефон(1.16), sum_папка(1.17)
iOS: sum_приложение(1.41), desc_приложение(1.13), lab_andriod(1.73), rep_name_37(1.05), sum_ios(1.14), lab_мобильное_приложение(1.88), lab_ios(4.55), rep_name_6(1.41), rep_name_38(1.35), sum_мобильный_приложение(1.28), sum_мобильный(0.98), rep_name_39(0.74), sum_резюме_скрывать(0.88), rep_name_40(0.81), lab_дублирование_вакансии(0.76)
Архитектура: sum_статистика_отклик(1.1), rep_name_41(1.4), lab_график_просмотров_и_откликов_вакансии(1.04), lab_создание_вакансии(1.16), lab_квоты(1.0), sum_спецпредложение(1.02), rep_name_42(1.33), rep_name_24(1.39), lab_резюме(1.52), lab_backoffice(0.99), rep_name_43(1.09), sum_зависать(0.83), sum_статистика(0.83), lab_отклики_работодатель(0.76), sum_500ка(0.74)
Банк Зарплат: lab_500(1.18), lab_авторизация(0.79), sum_500(1.04), rep_name_44(0.85), sum_500_сайт(1.03), lab_сайт(1.08), lab_видимость_резюме(1.54), lab_прайс-лист(1.26), lab_настройки_видимости_резюме(0.87), sum_error(0.79), lab_отложенные_заказы(1.33), rep_name_43(0.74), sum_ie_11(0.69), sum_500_ошибка(0.66), sum2_сай_айт(0.65)
Мобильные продукты: lab_мобильное_приложение(1.69), lab_отклики(1.65), sum_hr_мобайл(0.81), lab_applicant(0.88), lab_employer(0.84), sum_мобайл(0.81), rep_name_45(1.2), desc_d0(0.87), rep_name_46(1.37), sum_hr(0.79), sum_некорректный_работа_поиск(0.61), desc_приложение(0.71), rep_name_47(0.69), rep_name_28(0.61), sum_работа_поиск(0.59)
Пандора: sum_приходить(2.68), desc_приходить(1.72), lab_смс(1.59), sum_письмо(2.75), sum_уведомление_отклик(1.38), sum_рассылка(2.96), lab_восстановление_пароля(1.52), lab_почтовые_рассылки(1.91), lab_email(2.0), sum_проверять(1.31), lab_рассылка(1.72), lab_рассылки(3.37), desc_рассылка(1.69), desc_почта(1.47), rep_name_6(1.32)
Перцы: lab_сохранение_резюме(1.43), sum_резюме(2.02), sum_воронка(1.57), sum_воронка_вакансия(1.66), desc_резюме(1.19), lab_резюме(1.39), sum_код(1.2), lab_applicant(1.34), sum_индекс(1.47), sum_индекс_вежливость(1.47), lab_создание_резюме(1.28), rep_name_45(1.82), sum_вежливость(1.47), sum_сохранение_резюме(1.18), lab_индекс_вежливости(1.13)
Поиск-1: sum2_пои_оис_иск(1.86), sum_поиск(3.59), lab_вопросы_по_поиску(3.86), sum2_пои(1.86), desc_поиск(2.49), lab_подходящие_резюме(2.2), lab_поиск(2.32), lab_проблемы_индексации(4.34), sum2_пои_оис(1.86), sum_автопоиск(1.62), sum_синоним(1.71), sum_выборка(1.62), sum2_иск(1.58), sum2_оис_иск(1.57), lab_автообновление_резюме(1.57)
Поиск-2: rep_name_48(1.13), desc_d1(1.1), lab_премиум_в_поиске(1.02), lab_просмотры_вакансии(1.4), sum_поиск(1.4), desc_d0(1.2), lab_показать_контакты(1.17), rep_name_49(1.12), lab_13(1.09), rep_name_50(1.05), lab_поиск_вакансий(1.62), lab_отклики_и_приглашения(1.61), sum_отклик(1.09), lab_отобранные_резюме(1.37), lab_фильтр_в_откликах(1.08)
СуперПродукты: lab_контактная_информация(1.78), desc_адрес(1.46), rep_name_46(1.84), sum_адрес(1.74), lab_размещение_вакансий(1.68), lab_отобранные_резюме(1.45), lab_отклики_работодатель(1.29), sum_право(1.23), sum_размещение_вакансия(1.21), desc_квота(1.19), sum_ошибка_размещение(1.33), rep_name_42(1.32), sum_квота(1.14), desc_адрес_офис(1.14), rep_name_51(1.09)
API: lab_удаление_аккаунта(1.12), sum_комментарий_резюме(0.94), rep_name_2(0.9), rep_name_3(0.83), rep_name_4(0.89), rep_name_5(0.91), lab_менеджеры_вакансий(0.87), lab_комментарии_к_резюме(1.85), lab_api(0.86), sum_удаляться_аккаунт(0.86), sum_просмотр(0.91), desc_комментарий(1.02), rep_name_6(0.85), desc_резюме(0.86), sum_api(1.01)
Android: sum_android(1.77), lab_ios(1.66), sum_приложение(2.9), sum_hr_мобайл(1.4), lab_android(3.55), sum_hr(1.36), lab_мобильное_приложение(3.33), sum_мобайл(1.4), rep_name_2(1.34), sum2_рил(1.27), sum_приложение_android(1.28), sum2_при_рил_ило(1.19), sum2_при_рил(1.27), sum2_ило_лож(1.19), sum2_ило_лож_оже(1.19)
Billing: rep_name_7(3.88), desc_счет(3.23), rep_name_8(3.15), lab_billing_wtf(2.46), rep_name_9(4.51), rep_name_10(2.88), sum_счет(3.16), lab_billing(2.41), rep_name_11(2.27), lab_billing_support(2.36), sum_услуга(2.33), lab_оплата_услуг(1.92), sum_акт(2.26), rep_name_12(1.92), rep_name_13(2.4)
Brandy: lab_оценка_талантов(2.17), rep_name_14(1.87), rep_name_15(3.36), lab_clickme(1.72), rep_name_16(1.44), rep_name_17(1.63), rep_name_18(1.29), sum_страница(1.24), sum_брендированный(1.48), lab_описание_компании(1.39), sum_конструктор(1.59), lab_бренд.страницы(1.33), sum_описание(1.23), sum_описание_компания(1.17), lab_статья(1.15)
Clickme: desc_акт(0.73), sum_adv_hh(0.65), sum_adv_hh_ru(0.65), sum_hh(0.77), lab_hhs(1.27), lab_bs(1.91), rep_name_19(1.17), rep_name_20(1.29), rep_name_21(1.9), rep_name_8(1.16), sum_рекламный(0.67), sum_размещение(0.65), sum_adv(0.65), sum_hh_ua(0.64), sum_кликми_31(0.64)
Marketing: lab_регион(0.9), lab_тормозит_сайт(1.23), sum_рассылка(1.32), lab_менеджеры_вакансий(0.93), sum_календарь(0.93), rep_name_22(1.33), lab_опросы(1.25), rep_name_6(1.53), lab_производственный_календарь(1.55), rep_name_23(0.86), sum_яндекс(1.26), sum_распределение_вакансия(0.85), sum_распределение(0.85), sum_категория(0.85), sum_ошибка_переход(0.83)
Mercury: lab_услуги(1.76), sum_капча(2.02), lab_соискательские_сервисы(1.89), lab_lawyers(2.1), lab_авторизация_работодатель(1.68), lab_профориентация(2.53), lab_готовое_резюме(2.21), rep_name_24(1.77), rep_name_25(1.59), lab_рассылка_в_ка(1.56), sum_пользователь(1.57), rep_name_26(1.43), lab_модерация_вакансий(1.58), desc_пароль(1.39), rep_name_27(1.36)
Mobile_site: sum_мобильный_версия(1.32), sum_версия_сайт(1.26), lab_приложение(1.51), lab_статистика(1.32), sum_мобильный_версия_сайт(1.25), lab_мобильная_версия(5.1), sum_версия(1.41), rep_name_28(1.24), sum_страница_статистика(1.05), lab_нет(1.05), lab_jtb(1.07), rep_name_16(1.12), rep_name_29(1.05), sum_сайт(0.95), rep_name_30(0.92)
TMS: rep_name_31(1.39), lab_talantix(4.28), rep_name_32(1.55), rep_name_33(2.59), sum_вакансия_talantix(0.74), lab_поиск(0.57), lab_search(0.63), rep_name_34(0.64), lab_календарь(0.56), sum_импортироваться(0.66), lab_tms(0.74), sum_отклик_hh(0.57), lab_mailing(0.64), sum_talantix(0.6), sum2_мпо(0.56)
Talantix: sum_система(0.86), rep_name_16(1.37), sum_talantix(1.16), lab_почта(0.94), lab_xor(0.8), lab_talantix(3.19), rep_name_35(1.07), rep_name_18(1.33), lab_персональные_данные(0.79), rep_name_34(1.08), sum_талантикс(0.89), sum_происходить(0.78), lab_mail(0.77), sum_отклик_становиться_просматривать(0.73), rep_name_6(0.72)
WebServices: sum_вакансия(1.36), desc_шаблон(1.32), sum_архив(1.3), lab_шаблоны_писем(1.39), sum_номер_телефон(1.44), rep_name_36(1.28), lab_lawyers(2.1), lab_приглашение(1.27), lab_приглашение_на_вакансию(1.26), desc_папка(1.22), lab_избранные_резюме(1.2), lab_ключевые_навыки(1.22), sum_находить(1.18), sum_телефон(1.16), sum_папка(1.17)
iOS: sum_приложение(1.41), desc_приложение(1.13), lab_andriod(1.73), rep_name_37(1.05), sum_ios(1.14), lab_мобильное_приложение(1.88), lab_ios(4.55), rep_name_6(1.41), rep_name_38(1.35), sum_мобильный_приложение(1.28), sum_мобильный(0.98), rep_name_39(0.74), sum_резюме_скрывать(0.88), rep_name_40(0.81), lab_дублирование_вакансии(0.76)
Архитектура: sum_статистика_отклик(1.1), rep_name_41(1.4), lab_график_просмотров_и_откликов_вакансии(1.04), lab_создание_вакансии(1.16), lab_квоты(1.0), sum_спецпредложение(1.02), rep_name_42(1.33), rep_name_24(1.39), lab_резюме(1.52), lab_backoffice(0.99), rep_name_43(1.09), sum_зависать(0.83), sum_статистика(0.83), lab_отклики_работодатель(0.76), sum_500ка(0.74)
Банк Зарплат: lab_500(1.18), lab_авторизация(0.79), sum_500(1.04), rep_name_44(0.85), sum_500_сайт(1.03), lab_сайт(1.08), lab_видимость_резюме(1.54), lab_прайс-лист(1.26), lab_настройки_видимости_резюме(0.87), sum_error(0.79), lab_отложенные_заказы(1.33), rep_name_43(0.74), sum_ie_11(0.69), sum_500_ошибка(0.66), sum2_сай_айт(0.65)
Мобильные продукты: lab_мобильное_приложение(1.69), lab_отклики(1.65), sum_hr_мобайл(0.81), lab_applicant(0.88), lab_employer(0.84), sum_мобайл(0.81), rep_name_45(1.2), desc_d0(0.87), rep_name_46(1.37), sum_hr(0.79), sum_некорректный_работа_поиск(0.61), desc_приложение(0.71), rep_name_47(0.69), rep_name_28(0.61), sum_работа_поиск(0.59)
Пандора: sum_приходить(2.68), desc_приходить(1.72), lab_смс(1.59), sum_письмо(2.75), sum_уведомление_отклик(1.38), sum_рассылка(2.96), lab_восстановление_пароля(1.52), lab_почтовые_рассылки(1.91), lab_email(2.0), sum_проверять(1.31), lab_рассылка(1.72), lab_рассылки(3.37), desc_рассылка(1.69), desc_почта(1.47), rep_name_6(1.32)
Перцы: lab_сохранение_резюме(1.43), sum_резюме(2.02), sum_воронка(1.57), sum_воронка_вакансия(1.66), desc_резюме(1.19), lab_резюме(1.39), sum_код(1.2), lab_applicant(1.34), sum_индекс(1.47), sum_индекс_вежливость(1.47), lab_создание_резюме(1.28), rep_name_45(1.82), sum_вежливость(1.47), sum_сохранение_резюме(1.18), lab_индекс_вежливости(1.13)
Поиск-1: sum2_пои_оис_иск(1.86), sum_поиск(3.59), lab_вопросы_по_поиску(3.86), sum2_пои(1.86), desc_поиск(2.49), lab_подходящие_резюме(2.2), lab_поиск(2.32), lab_проблемы_индексации(4.34), sum2_пои_оис(1.86), sum_автопоиск(1.62), sum_синоним(1.71), sum_выборка(1.62), sum2_иск(1.58), sum2_оис_иск(1.57), lab_автообновление_резюме(1.57)
Поиск-2: rep_name_48(1.13), desc_d1(1.1), lab_премиум_в_поиске(1.02), lab_просмотры_вакансии(1.4), sum_поиск(1.4), desc_d0(1.2), lab_показать_контакты(1.17), rep_name_49(1.12), lab_13(1.09), rep_name_50(1.05), lab_поиск_вакансий(1.62), lab_отклики_и_приглашения(1.61), sum_отклик(1.09), lab_отобранные_резюме(1.37), lab_фильтр_в_откликах(1.08)
СуперПродукты: lab_контактная_информация(1.78), desc_адрес(1.46), rep_name_46(1.84), sum_адрес(1.74), lab_размещение_вакансий(1.68), lab_отобранные_резюме(1.45), lab_отклики_работодатель(1.29), sum_право(1.23), sum_размещение_вакансия(1.21), desc_квота(1.19), sum_ошибка_размещение(1.33), rep_name_42(1.32), sum_квота(1.14), desc_адрес_офис(1.14), rep_name_51(1.09)
Признаки примерно отражают чем занимаются команды
Использование модели
На этом построение модели закончено и можно на её основе строить программу.
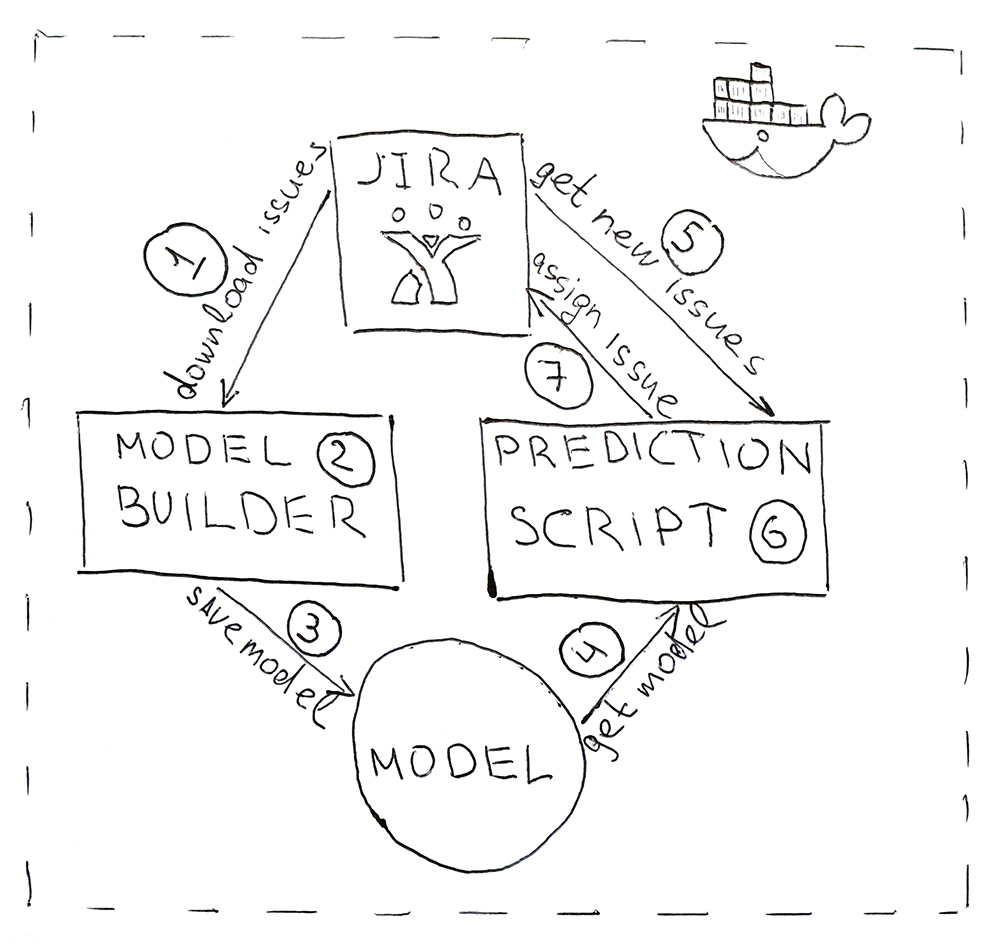
Программа состоит из двух Python-скриптов. Первый строит модель, а второй выполняет предсказания.
- Jira предоставляет API, через который можно скачать уже решенные задачи (HHS). Раз в сутки запускается скрипт и скачивает их.
- Скачанные данные преобразуются в признаки. Сначала данные бьются на тренировочные и тестовые и подаются в ML-модель для валидации, чтобы следить за тем, чтобы от запуска к запуску не начало падать качество. А затем второй раз модель обучается на всех данных. Весь процесс занимает около 10 минут.
- Обученная модель сохраняется на жесткий диск. Я использовал утилиту dill для сериализации объектов. Помимо самой модели необходимо также сохранить все объекты, которые использовались для получения признаков. Это нужно, чтобы получить признаки в том же пространстве для новых HHS
- При помощи того же dill модель загружается в скрипт для предсказания, который запускается раз в 5 минут.
- Идем в Jira за новыми HHS.
- Получаем признаки и передаем их в модель, которая вернет для каждой HHS имя класса — название команды.
- Для команды находим ответственного и назначаем ему задачу через Jira API. Им может быть тестировщик, если тестировщика у команды нет, то — тимлид.
Чтобы программу было удобно разворачивать и иметь те же версии библиотек, что и при разработке, скрипты упаковываются в Docker контейнер.
В итоге мы автоматизировали рутинный процесс. Точность в 76% — не слишком большая, но в этом случае промахи не критичны. Все задачи находят своих исполнителей, и самое главное, что для этого теперь не нужно отвлекаться по несколько раз в день, чтобы вникать в суть задач и искать ответственных. Все работает автоматически! Ура!
