Комментарии 103
Мы решили тестировать все решения на 10 000 блоков (это миллион слов).
А счастье было так близко.
Ну тут есть ещё и практический смысл: тестировать на значительно большем числе блоков пришлось бы очень долго.
Да, надо было добавить какие то ограничения, хотя бы количество блоков.
Если бы мы заранее зафиксировали количество блоков, то могли бы столкнуться с ситуацией, когда решения лидеров показывают практически неразличимые результаты. Тогда тоже был бы скандал, требования выдать приз каждому, пересчитать по-новому, протесты и т.п.
У кого есть суперкомпьютер, помогите Hola посчитать)
Рад, что у меня в результате стабильные 77% как и при моем тестировании до отправки решения :-) Пошел смотреть какой результат минимальный.
> Это не только сделало бы этот нехитрый приём «волшебной палочкой»
Пробежавшись по 40 случайно выбранным решениям я увидел 2 обучения. Пусть я пропустил половину и их 4. Т.е. в районе 10%.
Вы называете это «волшебной палочкой», в комментариях были высказывания в духе «читерство» и «легкий путь». Хотелось бы сказать что, во-первых, этот путь совсем не легкий и не лежит на поверхности. Иначе бы его применили не 10% участников, а значительно больше. Тот факт что организаторы сами этого не предусмотрели является дополнительным доводом «простоты» и «волшебности». До него действительно нужно додуматься, и, мне кажется, это чуть труднее чем взять предложенный в комментариях фильтр Блума, оказавшийся одним из лучших вариантов решения задачи. Во-вторых качественная имплементация обучения, опять же по моему мнению, ничуть не проще Блума. Таким образом, лично я не вижу никакой «волшебной палочки».
> но и создало бы для жюри проблему выбора между несколькими обучающимися решениями
В коментариях к своему решению я предлагл один из возможных вариантов решения этой проблемы: запускать обучающиеся алгоритмы по времени. Кто смог обработать большее кол-во слов за час и лучше на них обучится (а в обучении всегда есть сильный трейдофф скорость-память-качество), тот и лучший.
Да, я с самого начала понимал что истинная задача конкурса — разработать лучшее, в том числе по занимаемой памяти, решение для задачи проверки орфографии пользовательского ввода в браузере. Но условия задачи формализуют ее в несколько другом аспекте, довольно далеком от реальной задачи. И обучение удовлетворяет *всем* формальным условиям задачи. Для полной честности, осталось признать что вы изменили условия задачи в пункте «столько тестов, сколько потребуется». Почему-то в тексте этой фразы нет.
Напоследок хотелось бы вспомнить Джордано Бруно, пострадавшего лишь за то, что он изучил все имеющиеся факты и сделал непротиворечивое заявление. Но оно, на тот день, никого не интересовало.
Спасибо за конкурс…
Пробежавшись по 40 случайно выбранным решениям я увидел 2 обучения. Пусть я пропустил половину и их 4. Т.е. в районе 10%.
Вы называете это «волшебной палочкой», в комментариях были высказывания в духе «читерство» и «легкий путь». Хотелось бы сказать что, во-первых, этот путь совсем не легкий и не лежит на поверхности. Иначе бы его применили не 10% участников, а значительно больше. Тот факт что организаторы сами этого не предусмотрели является дополнительным доводом «простоты» и «волшебности». До него действительно нужно додуматься, и, мне кажется, это чуть труднее чем взять предложенный в комментариях фильтр Блума, оказавшийся одним из лучших вариантов решения задачи. Во-вторых качественная имплементация обучения, опять же по моему мнению, ничуть не проще Блума. Таким образом, лично я не вижу никакой «волшебной палочки».
> но и создало бы для жюри проблему выбора между несколькими обучающимися решениями
В коментариях к своему решению я предлагл один из возможных вариантов решения этой проблемы: запускать обучающиеся алгоритмы по времени. Кто смог обработать большее кол-во слов за час и лучше на них обучится (а в обучении всегда есть сильный трейдофф скорость-память-качество), тот и лучший.
Да, я с самого начала понимал что истинная задача конкурса — разработать лучшее, в том числе по занимаемой памяти, решение для задачи проверки орфографии пользовательского ввода в браузере. Но условия задачи формализуют ее в несколько другом аспекте, довольно далеком от реальной задачи. И обучение удовлетворяет *всем* формальным условиям задачи. Для полной честности, осталось признать что вы изменили условия задачи в пункте «столько тестов, сколько потребуется». Почему-то в тексте этой фразы нет.
Напоследок хотелось бы вспомнить Джордано Бруно, пострадавшего лишь за то, что он изучил все имеющиеся факты и сделал непротиворечивое заявление. Но оно, на тот день, никого не интересовало.
Спасибо за конкурс…
Конечно же, можно было запускать с ограничением по времени или ещё как-то. Но всё это было бы изменением по сравнению с заявленными правилами конкурса.
> Для полной честности, осталось признать что вы изменили условия задачи в пункте «столько тестов, сколько потребуется».
Не понял, что Вы имеете в виду. Что конкретно мы изменили?
> Для полной честности, осталось признать что вы изменили условия задачи в пункте «столько тестов, сколько потребуется».
Не понял, что Вы имеете в виду. Что конкретно мы изменили?
Я имел ввиду ваш комментарий
>вопрос к организаторам — а вы можете сказать какое будет минимальное кол-во блоков для тестирования?
>>Такое, какое потребуется, чтобы увидеть уверенную разницу между лидерами.
Я считаю что на 1М тестов уверенную разницу между лидерами увидеть нельзя. Более того, такое кол-во тестов даже не позволяет этих лидеров выявить. Руководствуясь описанными в посте посылами, можно было установить лимит на 1000 тестов, или на 10. Это точно так же не позволило бы ни выявить лидеров, ни выявить уверенную разницу между ними.
Не могли бы вы еще раз, для непонятливых, привести причины выбора именно 1М тестов, кроме уже описанной проблемы ограниченности ядер 3ГГц.
>вопрос к организаторам — а вы можете сказать какое будет минимальное кол-во блоков для тестирования?
>>Такое, какое потребуется, чтобы увидеть уверенную разницу между лидерами.
Я считаю что на 1М тестов уверенную разницу между лидерами увидеть нельзя. Более того, такое кол-во тестов даже не позволяет этих лидеров выявить. Руководствуясь описанными в посте посылами, можно было установить лимит на 1000 тестов, или на 10. Это точно так же не позволило бы ни выявить лидеров, ни выявить уверенную разницу между ними.
Не могли бы вы еще раз, для непонятливых, привести причины выбора именно 1М тестов, кроме уже описанной проблемы ограниченности ядер 3ГГц.
Среди необучающихся программ стабилизация тройки лидеров произошла уже на 1 500 блоках. Дальнейшее увеличение объёмов уточняло лишь сотые доли процента, не меняя расстановки сил. Нет никаких оснований полагать, что далеко после 10 000 блоков произошло бы что-то неожиданное.
>Нет никаких оснований полагать, что далеко после 10 000 блоков произошло бы что-то неожиданное.
Ну, например на 200 000 блоков мое решение бы показало 90%. Согласен, ничего неожиданного и вполне предсказуемо.
Еще можно было определить «параметр стабилизации: если за 1000 блоков результат улучшился менее 0,1% значит результат стабилен». Кажется даже никаких условий конкурса не меняем.
Хорошо, сойдемся на дискриминации по признаку применения обучения =)
В каком-нибудь параллельном мире ваша фраза могла бы выглядеть как
«Среди всех программ стабилизация тройки лидеров произошла уже на 150 000 блоках. Дальнейшее увеличение объёмов уточняло лишь сотые доли процента, не меняя расстановки сил.» Постараюсь найти мощности для проверки этого утверждения и время для написания статьи.
Еще раз: ваша мотивация понятна, претензий не имею. Небольшой укор за умершие от волнительного ожидания нервные клетки, но в целом за конкурс спасибо.
Ну, например на 200 000 блоков мое решение бы показало 90%. Согласен, ничего неожиданного и вполне предсказуемо.
Еще можно было определить «параметр стабилизации: если за 1000 блоков результат улучшился менее 0,1% значит результат стабилен». Кажется даже никаких условий конкурса не меняем.
Хорошо, сойдемся на дискриминации по признаку применения обучения =)
В каком-нибудь параллельном мире ваша фраза могла бы выглядеть как
«Среди всех программ стабилизация тройки лидеров произошла уже на 150 000 блоках. Дальнейшее увеличение объёмов уточняло лишь сотые доли процента, не меняя расстановки сил.» Постараюсь найти мощности для проверки этого утверждения и время для написания статьи.
Еще раз: ваша мотивация понятна, претензий не имею. Небольшой укор за умершие от волнительного ожидания нервные клетки, но в целом за конкурс спасибо.
а можно ссылочку на вашу работу. спасибо :)
https://github.com/hola/challenge_word_classifier/tree/master/submissions/5747c9f463905b3a11d97c3a
Но вряд ли вы найдете там что-то интересное. Сплошное читерство и волшебствопалочничество. Примерно того же уровня, как если бы я придумал как скачать словарь из интернета. Хоть не дисквалифицировали, уже спасибо =)
Кстати, запрошенные 200 000 блоков мое решение обрабатывает менее чем за час. А в полную силу начинает работать только после 40 000 блоков. Немного утрируя, можно сказать что в озвученных условиях тестирования запускается только половина кода.
Но вряд ли вы найдете там что-то интересное. Сплошное читерство и волшебствопалочничество. Примерно того же уровня, как если бы я придумал как скачать словарь из интернета. Хоть не дисквалифицировали, уже спасибо =)
Кстати, запрошенные 200 000 блоков мое решение обрабатывает менее чем за час. А в полную силу начинает работать только после 40 000 блоков. Немного утрируя, можно сказать что в озвученных условиях тестирования запускается только половина кода.
Многие решения работают быстро, и протестировать их на большом количестве блоков не было бы проблемой. Однако есть решения, работающие на порядки медленнее Вашего.
Не удержусь промолчать в последний раз.
Вы в любом случае пришли к мысли
>Самые медленные из них, похоже, нам придётся остановить досрочно и использовать результаты частичного прогона тестов.
Теоретически, ничего не мешало сделать все тоже самое на гораздо большем кол-во блоков. Алгоритмы, не сумевшие обработать 100М слов за 2 недели между окончанием конкурса и объявлением результатов — извините, ваш результат по итогам частичной проверки. 100М за 2 недели это по 100 слов в секунду, полный неуд на мой взгляд. А если нужно проверить 3000 слов, скопированных в текстовое поле? Подождите 30 секунд, мы проверяем?
Кстати, если аудитория браузера составляет 50'000 ежедневных пользователей, и каждый из них пишет хотя бы 10 слов в день, то за год набирается 180М слов. Цифры то вполне из реального мира. Почему бы не делать проверку орфографии онлайн? Тот же хром иногда подчеркивает слово спустя секунды после написания, ничего критичного.
Вы в любом случае пришли к мысли
>Самые медленные из них, похоже, нам придётся остановить досрочно и использовать результаты частичного прогона тестов.
Теоретически, ничего не мешало сделать все тоже самое на гораздо большем кол-во блоков. Алгоритмы, не сумевшие обработать 100М слов за 2 недели между окончанием конкурса и объявлением результатов — извините, ваш результат по итогам частичной проверки. 100М за 2 недели это по 100 слов в секунду, полный неуд на мой взгляд. А если нужно проверить 3000 слов, скопированных в текстовое поле? Подождите 30 секунд, мы проверяем?
Кстати, если аудитория браузера составляет 50'000 ежедневных пользователей, и каждый из них пишет хотя бы 10 слов в день, то за год набирается 180М слов. Цифры то вполне из реального мира. Почему бы не делать проверку орфографии онлайн? Тот же хром иногда подчеркивает слово спустя секунды после написания, ничего критичного.
Спасибо еще раз за ссылочку. Я думал это написать используя hidden markov model, но увы лень,проекты — не успел.
PS:
let parts = [], cnt = ~~(word.length / window) + (word.length % window ? 1 : 0);Любите вы изощренность :)
Почитал ваше решение. Правильно понимаю, вы не учитывали тот факт, что для 20-30к «не слов» вероятность обнаружения в тестовой выборке не ниже чем для «корректных слов»? Если не учитывает, то ваш алгоритм не сойдется никогда в 100%, максимум в 95%.
Я анализировал подобные выбросы генератора. Слова из одной, двух и трех букв встречаются аномально часто.
Таких слов 27 + 27**2 + 27**3 = 20'439, из них вроде бы 12к неправильные.Думаю вы имеете ввиду именно их. Я просто перечислил все ложные двойки и настоящие тройки. В коде смотреть banned2 и allowed3 соот-но.
Количество четверок уже сравнимо с количеством слов, 531'441 и их мат. ожидание не превышает мат. ожидания корректного слова.
После 63 040 400 тестов база знает 99,9% корректных слов. Оставшиеся 0,01% превышения это абсолютно правильная дисперсия хорошего рандома: https://habrahabr.ru/company/hola/blog/282624/#comment_8878212
В начале обучения мы точно допускаем ошибки, чистые 100% в любом случае не достижимы.
Таких слов 27 + 27**2 + 27**3 = 20'439, из них вроде бы 12к неправильные.Думаю вы имеете ввиду именно их. Я просто перечислил все ложные двойки и настоящие тройки. В коде смотреть banned2 и allowed3 соот-но.
Количество четверок уже сравнимо с количеством слов, 531'441 и их мат. ожидание не превышает мат. ожидания корректного слова.
После 63 040 400 тестов база знает 99,9% корректных слов. Оставшиеся 0,01% превышения это абсолютно правильная дисперсия хорошего рандома: https://habrahabr.ru/company/hola/blog/282624/#comment_8878212
В начале обучения мы точно допускаем ошибки, чистые 100% в любом случае не достижимы.
Не совсем. Я имел в виду, что вероятность встретить «не слова», такие как «under's» или «dising» примерно в 20 раз выше, чем встретить слово из словаря. И таких слов достаточно много. Например «blenesses» и «unreproof» встречаются также часто как и словарные слова. Видимо, это связано с природой марковского генератора.
То есть, при таком подходе, после 60 млн тестов база будет включать определенный процент (по моим оценкам около 5%) ложноположительных слов.
То есть, при таком подходе, после 60 млн тестов база будет включать определенный процент (по моим оценкам около 5%) ложноположительных слов.
Я просто хотел обратить внимание на то, что в тестовых данных множество «не слов» имеет неравномерное распределение, что требуется учитывать, чтобы получить решение, которое сходится в 99%. Чтобы не быть голословным, я прогнал ваше решение через датасет в 110 млн тестовых слов. Предел для вашего решения — это 96-97% точности не зависимо от количества тестовых данных
Графики тут 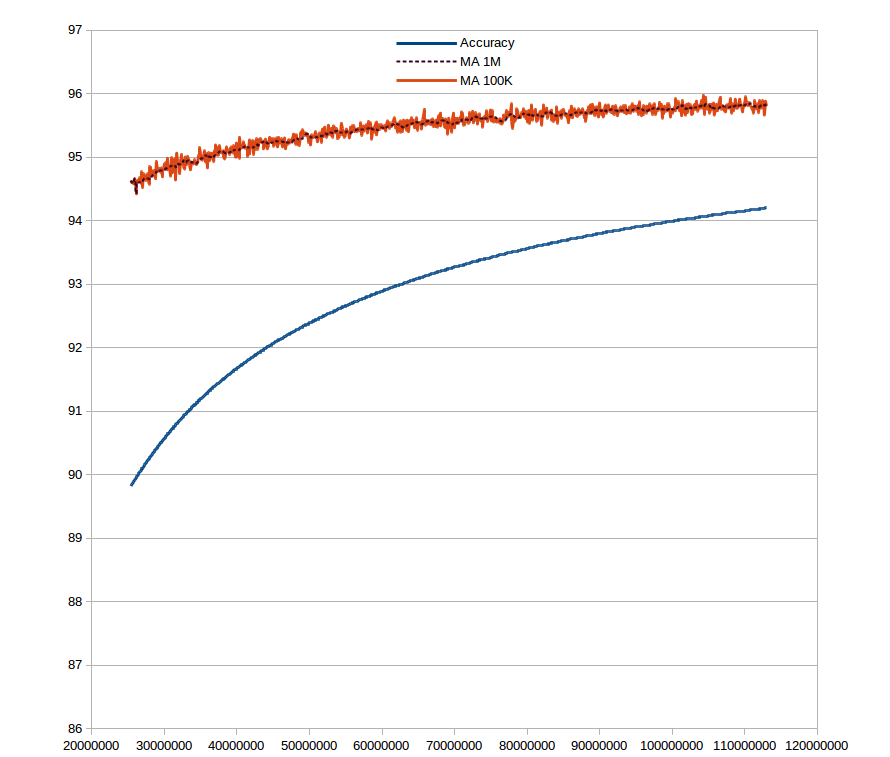
Accuracy — это точность решения на заданном количестве данных
MA 100K и MA 1M — это скользящее среднее для точности на 100тыс и 1 млн соответственно.

Accuracy — это точность решения на заданном количестве данных
MA 100K и MA 1M — это скользящее среднее для точности на 100тыс и 1 млн соответственно.
Да, забавная статистика. До такой особенности генератора я не добрался, у меня был датасет на 6М слов, все тесты сверх этого производились на локальном генераторе из предпослыки что больше сюрпризов в конкурсном генераторе нет.
Вы как-то решали эту проблему? Все так же перечислением выбросов?
Вы как-то решали эту проблему? Все так же перечислением выбросов?
Нет, в опубликованном решении я не использовал обучения вообще. Это я постфактум анализировал статистику — пытался сделать обучающееся решение, которое бы сходилось в 99+%. В принципе, реализуемо, просто приходится в блюм-фильтре хранить 40-60 тыс популярных «не слов».
В основном решении, у меня нет ничего особенно оригинального: стемминг, блюм-фильтр, триграммы. Описание моего решения тут.
В основном решении, у меня нет ничего особенно оригинального: стемминг, блюм-фильтр, триграммы. Описание моего решения тут.
А как был сгенерирован data-файлик?
В src есть все генерирующие скрипты.
Что-то там парсер некого tranio.ru
Не тот файл оказывается прикрепил. Извините.
В data.gz, помимо коротких слов на исключение (ветка обсуждения чуть выше) так же лежат популярные тройки\четверки с учетом позиции. Код их генерации большого интереса не представляет. Идея взята из алгоритма HmSearch http://www.cse.unsw.edu.au/~weiw/files/SSDBM13-HmSearch-Final.pdf Алгоритм разработан для быстрого поиска всех слов с заданным hamming distance от исходного. В нашем случае вырожденный случай hm=0. Результатв 75%, насколько я могу судить по некоторым запущенным мной реализациям, довольно близок к чистому портеру, так что баш на баш.
В data.gz, помимо коротких слов на исключение (ветка обсуждения чуть выше) так же лежат популярные тройки\четверки с учетом позиции. Код их генерации большого интереса не представляет. Идея взята из алгоритма HmSearch http://www.cse.unsw.edu.au/~weiw/files/SSDBM13-HmSearch-Final.pdf Алгоритм разработан для быстрого поиска всех слов с заданным hamming distance от исходного. В нашем случае вырожденный случай hm=0. Результатв 75%, насколько я могу судить по некоторым запущенным мной реализациям, довольно близок к чистому портеру, так что баш на баш.
Если б словарь почистили от чепухи всякой, которая английскими словами не является
toddite, synapsidan, ursid, cycadales, nebbishy, gypsophilous, cowfish, haboobs, archhead, impulsed, otiorhynchinae, twankies, olympio, besra, bankroll's, godsends, colymbidae, reefier, hobbie's, sagittid's, souldan, sap's, nevada, bushlike, hexastigm, baptizee, bonnibell, aldose, pilows, barkhan, redshank's, lucerne, baulkier, pocill, corday, unsaddle, waxbill, unbudged, horsehair, bamboula, parkward's, farnsworth's, zealotry, plumbed, khios's, millsboro's, otyak, enkernel, massif's, revkah…
то процент ошибки у всех уменьшился бы раза в два, потому что некоторых этих слов даже Google не знает. А то по условию конкурса вам нужна программа, которая отличает «слова английского языка», но победит программа, которая отличают «определенную херню, захардкоженную по пьяни».
toddite, synapsidan, ursid, cycadales, nebbishy, gypsophilous, cowfish, haboobs, archhead, impulsed, otiorhynchinae, twankies, olympio, besra, bankroll's, godsends, colymbidae, reefier, hobbie's, sagittid's, souldan, sap's, nevada, bushlike, hexastigm, baptizee, bonnibell, aldose, pilows, barkhan, redshank's, lucerne, baulkier, pocill, corday, unsaddle, waxbill, unbudged, horsehair, bamboula, parkward's, farnsworth's, zealotry, plumbed, khios's, millsboro's, otyak, enkernel, massif's, revkah…
то процент ошибки у всех уменьшился бы раза в два, потому что некоторых этих слов даже Google не знает. А то по условию конкурса вам нужна программа, которая отличает «слова английского языка», но победит программа, которая отличают «определенную херню, захардкоженную по пьяни».
Словарик вполне официальный, в условиях была ссылка откуда он сформирован
https://github.com/hola/challenge_word_classifier/blob/master/blog/01-rules.md
http://wordlist.aspell.net/
В общем, там помимо академического английского еще и диалекты — американский, канадский, британский и т.д.
https://github.com/hola/challenge_word_classifier/blob/master/blog/01-rules.md
For the purposes of this problem, we define an English word as a word from the list included here as words.txt. (If you're interested, it's the SCOWL “insane” dictionary with flattened diacritics.) Membership in the dictionary is case-insensitive. You have to write a program that can answer whether a given word is English.
http://wordlist.aspell.net/
В общем, там помимо академического английского еще и диалекты — американский, канадский, британский и т.д.
НЛО прилетело и опубликовало эту надпись здесь
НЛО прилетело и опубликовало эту надпись здесь
порадовали со 2 по 5 решения в submissions =))
abuse — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720eba193f2f29d3c9acbad
optimist — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720ebb893f2f29d3c9acbae
pessimist — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720ebd293f2f29d3c9acbaf
pofigist — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720ed5393f2f29d3c9acbb0
abuse — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720eba193f2f29d3c9acbad
optimist — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720ebb893f2f29d3c9acbae
pessimist — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720ebd293f2f29d3c9acbaf
pofigist — https://github.com/hola/challenge_word_classifier/tree/master/submissions/5720ed5393f2f29d3c9acbb0
optimist, pessimist и pofigist мы сами заслали.
А вообще десятки из присланных решений относятся к трём типам: return true, return false и return Math.random()<0.5.
А вообще десятки из присланных решений относятся к трём типам: return true, return false и return Math.random()<0.5.
Жаль генератор редко выдаёт (или вообще не выдаёт) неправильные слова построенные как «правильное слово» + 's. Думаю это «просадило» бы многие решения.
для повторяемости логичнее хэш считать SomeHash(str)
Поскольку слов в словаре меньше 700 000, а разнообразие псевдослучайных не-слов гораздо шире, то слово, встретившееся дважды, с большей вероятностью является словом, чем не-словом.Очень грубое описание решений подобного вида. Более 1/4 не-слов встречаются более 1 раза (на 20М тестов).
Для того, чтобы заработало статистическое решение, 1М слов недостаточно.
А еще можно грамотно объединить несколько решений, чтобы нивелировать «провал» статистики на малых объемах данных…
В общем, на мой взгляд, называть это «нехитрым приёмом» несколько неоправданно…
Чорд, галку gzip в форме не проставил.
Судя по всему не я один
$ file */data | grep gzip
5745740063905b3a11d97bd5/data: gzip compressed data, was "data", last modified: Wed May 25 09:24:43 2016, from NTFS filesystem (NT)
57466eb863905b3a11d97bed/data: gzip compressed data, was "data", last modified: Wed May 25 14:58:12 2016, max compression, from NTFS filesystem (NT)
57469a9263905b3a11d97bf0/data: gzip compressed data, was "temp.json", last modified: Tue May 24 19:37:25 2016, max compression, from FAT filesystem (MS-DOS, OS/2, NT)
57487c4363905b3a11d97c72/data: gzip compressed data, from FAT filesystem (MS-DOS, OS/2, NT)
5748ab4963905b3a11d97caa/data: gzip compressed data, last modified: Fri May 27 20:00:37 2016, max compression, from Unix
5748dda963905b3a11d97d06/data: gzip compressed data, from UnixСпасибо, что обратили на это наше внимание. Эта галочка в форме — usability bug. В следующий раз в подобной ситуации будем смотреть на суффикс в имени закачиваемого файла.
Для этих шести решений файл
Для этих шести решений файл
data будет переименован в data.gz, а результаты — пересчитаны.НЛО прилетело и опубликовало эту надпись здесь
Тем не менее, во всех шести случаях, упомянутых выше, суффикс был.
НЛО прилетело и опубликовало эту надпись здесь
В следующий раз вообще подумаем над тем, как улучшить процесс отправки. Тут ещё было несколько таких, которые вообще забыли приложить файл данных, но тут уж медицина бессильна.
НЛО прилетело и опубликовало эту надпись здесь
А вот это уже неправильно. В дополнение к задаче всех еще раз предупредили про эту галку. Давайте теперь еще и поправим пару решений, который не так экспортируют функции. Ну или которые работают с данными из файла как со строкой, а не с буфером. Я бы тоже хочет кое-что поправить в своем решении, можно?
Выставление галочек не имеет ничего общего с умением программировать, а экспорты имеют. Кроме того, правильное заполнение формы — это единственное, что невозможно было проверить с помощью тестовой программы.
Тем не менее, это было одно из условий проведения конкурса.
Кстати, в письме которое присылается в ответ на submission есть подтверждение того, что галка была проставлена. Внимательность в не меньшей степени относится к умению программировать. Но спорить на эту тему лучше не будем. Я неоднократно участвовал во всевозможных конкурсах по программированию. Никогда там не делали скидки на то, что кто-то неправильно указал имя входного файла с параметрами или, к примеру, ошибся в формате разделителя дробных чисел. Все были в равных условиях, даже несмотря на такие нелепые ошибки. Кстати, из-за подобных ошибок падают космические корабли, пусть даже это и «не имеет ничего общего с умением программировать».
Наверное, на тех конкурсах не было ситуации, когда участник узнаёт о неправильном формате в отправленном решении прямо перед оглашением результатов.
> Кстати, в письме которое присылается в ответ на submission есть подтверждение того, что галка была проставлена.
Это Вы знаете только потому, что получили такое письмо. В отсутствие галочки нет и никакого указания на то, что её нет.
В общем, мы проводим конкурс интересных решений, а не «зоркий глаз». Впрочем, ни одно из решений, для которых мы сделали эту поправку, не претендует на призовое место.
Это Вы знаете только потому, что получили такое письмо. В отсутствие галочки нет и никакого указания на то, что её нет.
В общем, мы проводим конкурс интересных решений, а не «зоркий глаз». Впрочем, ни одно из решений, для которых мы сделали эту поправку, не претендует на призовое место.
Я всего лишь хочу объективного судейства. Ряд решений которые использовали статистические методы (в дополнение к остальным) вы принципиально зарезали, в том числе и мое. Хорошо, таким образом вы решили проблему тестирования, и этот момент я не собираюсь осуждать. Но теперь вы берете 6 решений и добавляете их в общий зачет, хотя они были отосланы не верно. Я сам не сторонник формализма (подразумеваю эту злосчастную галочку), но все же надо быть последовательными в своих решениях. Этих пустим, этих не пустим — так нельзя. И раз это конкурс «интересных решений», то нельзя не признать, что решения со статистикой весьма интересны, учитывая то, что и сами организаторы не задумывались о таком методе. Тем не менее их не пустили в зачет. Не вижу причин пускать в зачет решения которые были отосланы не верно.
Протестил свое, 81.17%
Tested 10000 of 10000 blocks
Total W NW NW[0] NW[1] NW[2] NW[3] NW[4] NW[5] NW[6] NW[7] NW[8]
1000k 500672 499328 92206 69134 74631 78793 75506 56814 30604 14427 7213
Correct F- F+ F+[0] F+[1] F+[2] F+[3] F+[4] F+[5] F+[6] F+[7] F+[8] ms/100w
.
81.17% 8.54% 29.16% 2.45% 15.04% 18.55% 24.48% 38.76% 59.27% 72.12% 70.80% 63.51% 8Нормально. Не 83, но нормально :)
У меня почти столько же — 81.25% (5747e9eb63905b3a11d97c45)
81.44
Tested 10000 of 10000 blocks
Total W NW NW[0] NW[1] NW[2] NW[3] NW[4] NW[5] NW[6] NW[7] NW[8]
1000k 500672 499328 92206 69134 74631 78793 75506 56814 30604 14427 7213
Correct F- F+ F+[0] F+[1] F+[2] F+[3] F+[4] F+[5] F+[6] F+[7] F+[8] ms/100w
submissions/5748dda963905b3a11d97d06/
81.44% 3.78% 33.38% 4.72% 21.86% 29.06% 33.77% 41.36% 54.37% 67.08% 74.49% 76.54% 9
Только из подробной статистики стало видно, на сколько мало я уделил внимания отсеиванию простых моделей.
82.11% (5745fc8163905b3a11d97be3)
Tested 10000 of 10000 blocks
Total W NW NW[0] NW[1] NW[2] NW[3] NW[4] NW[5] NW[6] NW[7] NW[8]
1000k 500672 499328 92206 69134 74631 78793 75506 56814 30604 14427 7213
Correct F- F+ F+[0] F+[1] F+[2] F+[3] F+[4] F+[5] F+[6] F+[7] F+[8] ms/100w
D:\projects\english_words\solution\
82.11% 2.36% 33.47% 4.58% 29.99% 39.08% 40.47% 41.37% 43.59% 46.77% 49.64% 50.02% 42
интересно, зная алгоритм генерации, насколько можно улучшить решение?
Интересно было бы увидеть полную таблицу по всем 312 участникам.
А ещё интересней, своё место в этом рейтинге.
А ещё интересней, своё место в этом рейтинге.
Возьму на себя смелость выложить результаты моего грубого тестирования, которые я получил самостоятельно проверкой submissions, которые вчера выложили организаторы. Результат, в общем, не претендует на достоверность и не гарантирует точности.
Результаты под, Осторожно, Спойлером!
N SUBMISSION ACCURACY 1 5747452a63905b3a11d97c13 83.67 2 5748dc6363905b3a11d97d03 83.11 3 57581ef1bb50d92eb4000001 83.03 4 57483bab63905b3a11d97c5c 83.00 5 57487e6a63905b3a11d97c73 82.16 6 5748dc5763905b3a11d97d02 81.62 7 5748a0a363905b3a11d97c96 81.59 8 5745fc8163905b3a11d97be3 81.53 (*) 9 5748df1c63905b3a11d97d0f 81.51 10 5748dda963905b3a11d97d06 81.44 11 5748dded63905b3a11d97d0a 81.30 12 5748c16c63905b3a11d97cd0 81.29 13 5747e9eb63905b3a11d97c45 81.25 14 5747dbba63905b3a11d97c3d 81.25 15 5748a0fe63905b3a11d97c99 81.20 16 574893e463905b3a11d97c85 81.20 17 57485c0f63905b3a11d97c65 81.17 18 574713ca63905b3a11d97c03 80.60 (*) 19 5735b994a6200f187771219a 80.41 20 5746978e63905b3a11d97bee 80.19 21 5748a78563905b3a11d97ca3 80.13
О методике моего грубого тестировании
Для предварительного тестирования я использовал собственный скрипт, который я прогнал на 312 решениях на выборке из 1000 слов. В результате:
- 5 решений тестировались очень медленно и вообще не выдали результата за 30 секунд на 1000 слов. Я эти решения прервал и далее не тестировал
- 5 решений тестировались отностительно медленно (более 10 секунд на 1000 слов), выдали не очень большие результаты. Далее я эти решения не тестировал
- 44 решений завершились ошибкой. Я их далее не тестировал не разбираясь с причинами
- 258 решений прошли предварительное тестирование, были перетестированы мной на 10 тыс слов. На основании 10К тестирования я выбрал топ решений, которые преодолели 80% рубеж на 10000 слов. Всего получилось 21 такое решение. После этого перетестировал топ 21 с помощью скрипта организаторов. Два таких решения (помечены звездочкой) тестировались медленно, и я прервал тестирование, а в качестве оценки точности данных решений использовал результат, полученный на 10К тестовых слов
топ5 — стем и блюм
6е место самообучающийся алгоритм (плюс стем и блюм)
3е место подало заявку последним
6е место самообучающийся алгоритм (плюс стем и блюм)
3е место подало заявку последним
57581ef1bb50d92eb4000001 участвует вне конкурса и на приз не претендует.
тогда разница в топ3 лидерах очень убедительна
кстати, интересен комментарий 7го места по поводу рекламы конкурса и мотивации
кстати, интересен комментарий 7го места по поводу рекламы конкурса и мотивации
About the challenge promotion: I think the russian page which allow comments is a lot better for motivation than the english github page. I would probably have stopped a lot sooner if I didn't go to the russian page and used google translation on the comments to have an idea of what was achievable
Я не вижу здесь своего решения, 5748c99463905b3a11d97cdb, оно на 10'000 блоков набирает около 80.71%
Также я не вижу чтобы между 2,3,4 позициями была заметна «стабилизация тройки лидеров». Вот серьезно, что покажет тестовая система если прогнать результаты первой четверки не на 10 тыс. блоках, а на 20, 30, 50? На 50 тысячах и мое решение уверенно набирает 83.85%.
Также я не вижу чтобы между 2,3,4 позициями была заметна «стабилизация тройки лидеров». Вот серьезно, что покажет тестовая система если прогнать результаты первой четверки не на 10 тыс. блоках, а на 20, 30, 50? На 50 тысячах и мое решение уверенно набирает 83.85%.
5748dc5763905b3a11d97d02 решение утверждает что доходит до 84.7% на 20к блоков (и 87.7% на 50)
У Вас на 10 000 блоках 79.06%.
Будет отдельный пост о решениях с обучением, между ними проведём отдельное сравнение и, наверное, вручим автору лучшего из них спецприз.
Как я писал, моя таблица не предендует на полноту, достоверность и абсолютную точность. Ваше решения не прошло в топ 21, поскольку не набрало 80% при тестировании на 10К слов (детали моей методики тестирования описаны в предыдущем посте)
Немалый труд проделан, спасибо за предварительный результат. Хоть и не попал в десятку, но 13 место из 312 тоже неплохо.
Это в целом совпадает с теми результатами, которые у нас уже готовы.
Я бы организаторам предложил сделать отдельный зачет для статистов, как минимум с 50К тестами. Или до тех пор, пока кто-нибудь не наберет 90%.
На 50К уже успевает набраться необходимая статистика и подобные решения вполне могут уйти за 85% правильных ответов.
На 50К уже успевает набраться необходимая статистика и подобные решения вполне могут уйти за 85% правильных ответов.
В скрипте generator.js есть такие строки:
let item = this.data.get(prefix.slice(-this.order));
if (!item)
return this.prev(prefix);
Насколько я смог понять — это либо баг либо какая то неточность: во первых this.prev — это объект марковской модели меньшего порядка из чего следует что его нельзя вызывать как функцию (или я что то не знаю про ES6 ?) Из чего сразу следует во вторых — это условие никогда не выполняется (this.data — генерируется примерно таким же кодом и в нем присутствуют все запрашиваемые ключи включая пустую строку) Поясните пожалуйста какая здесь задумывалась логика? Должна ли на этом месте все же вызываться модель меньшего порядка? Правильно ли что матрица частот повторений букв (this.data) содержит не только строки длины order но и меньшей длины включая пустую?
PS: Сам в конкурсе не участвовал но читал статьи и стало интересно каким именно алгоритмом генерируются псевдо-слова.
let item = this.data.get(prefix.slice(-this.order));
if (!item)
return this.prev(prefix);
Насколько я смог понять — это либо баг либо какая то неточность: во первых this.prev — это объект марковской модели меньшего порядка из чего следует что его нельзя вызывать как функцию (или я что то не знаю про ES6 ?) Из чего сразу следует во вторых — это условие никогда не выполняется (this.data — генерируется примерно таким же кодом и в нем присутствуют все запрашиваемые ключи включая пустую строку) Поясните пожалуйста какая здесь задумывалась логика? Должна ли на этом месте все же вызываться модель меньшего порядка? Правильно ли что матрица частот повторений букв (this.data) содержит не только строки длины order но и меньшей длины включая пустую?
PS: Сам в конкурсе не участвовал но читал статьи и стало интересно каким именно алгоритмом генерируются псевдо-слова.
--text 'Lady Gaga has accompanied Mario Andretti in a two-seater race car at #Indy500 today!'
у меня у одного не запускается с одинарными кавычками? )) с двойными работает…
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Конкурс по программированию на JS: Классификатор слов (о ходе тестирования)