Приветствуем вас на страницах блога iCover! Для того, чтобы развить мощь интеллекта, позволившего Google AlphaGo добиться впечатляющей победы над чемпионом мира по игре Го Ли Седолем, ИИ потребовались тысячи чипов и долгие дни обучения. Между тем инженеры компании IBM уже сегодня реализуют концепцию, которая позволит вместить подобные и ещё более впечатляющие интеллектуальные возможности всего в одну энергоэффективную микросхему.

Сотрудники Исследовательского центра Уотсона компании IBM Тайфун Гокмен (Tayfun Gokmen) и Юрий Власов разработали новый чип Resistive Processing Unit (RPU), сочетающий в себе центральный процессор и энергонезависимую память и способный обеспечить существенное ускорение процесса глубокого обучения нейросетей (Deep Neural Networks, GNN) в сравнении с существующими процессорами при сравнительно меньших значениях энергопотребления.
“Системе, которая состоит из кластера ускорителей RPU окажутся под силу задачи больших данных, обрабатывающих одновременно триллионы параметров. В качестве примера таких массивов можно привести распознавание и перевод естественной речи между всеми языковыми парами, существующими в мире, аналитику интенсивных потоков научной и деловой информации в режиме реального времени или анализ мультимодальных потоков данных, поступающих от колоссального числа сенсоров IoT”, — комментируют событие исследователи на страницах ресурса arxiv.org.
На протяжении последних нескольких десятилетий достигнут внушительный прогресс в скорости машинного обучения. Это стало возможным благодаря использованию графических процессоров, массивов программируемой логики FPGA и специализированных микросхем (ASIC). Сегодня обеспечить дальнейшее ощутимое ускорение процесса, по мнению авторов разработки, позволит использование концепции параллельности и локальности алгоритмов обработки информации. Базой для успешной реализации таких концепций в лаборатории IBM стали принципы, реализованные в технологиях энергонезависимой памяти следующего поколения — фазовой (PCM) и резистивной (RRAM).
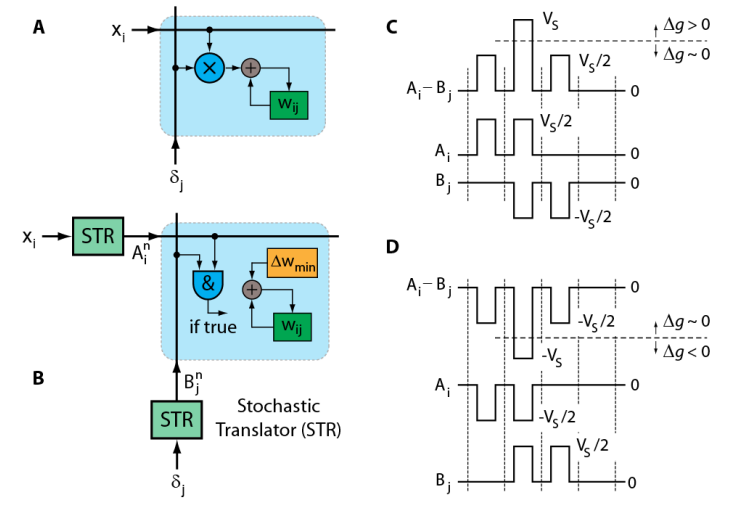
Schematics of original weight update rule of Eq.1 performed at each cross-point. (B) Schematics of stochastic update rule of Eq.2 that uses simple AND operation at each cross-point. Pulsing scheme that enables the implementation of stochastic updates rule by RPU devices for © up and (D) down conductance changes.
Сама по себе предложенная память позволяет ускорить DNN (процесс глубокого машинного обучения) в 27–2140 раз, но исследователи убеждены, что, сняв некоторые конструкционные ограничения запоминающих ячеек, им удастся обеспечить ещё более впечатляющие результаты. Как утверждает объединенная команда специалистов, работающая над инновационной технологией, чип, базирующийся на новой энергонезависимой памяти, созданный по разработанным ими спецификациям, позволит обеспечить прирост скорости работы алгоритма в сравнении с самыми мощными микропроцессорами в 30 тыс. раз.
Как полагают Власов и Гокмен, реализовать такие чипы возможно будет на базе традиционных КМОП-технологий. Вместе с тем, воплотить описанную концепцию на уровне коммерческих решений, скорее всего, удастся не ранее, чем через несколько лет, когда указанные технологии памяти «дотянутся» до рынка. Проведенные IBM исследования и достигнутые в теории результаты, по мнению экспертов уже сегодня выглядят очень многообещающе, поскольку открывают путь к новым качественным и количественным возможностям в освоении технологий машинного обучения.
Важно, что помимо самой IBM, совместная разработка специалистов T.J. Watson Research Center, вероятнее всего, окажется в центре внимания Google и других IT-гигантов, уже включившихся в многолетнюю гонку за право первыми обуздать возможности искусственного интеллекта. И это, в свою очередь, станет дополнительным мощным стимулом для скорейшего внедрения технологии на уровне коммерческих продуктов.
Источник
Техническое обоснование (pdf)
Уважаемые читатели, мы всегда с удовольствием встречаем и ждем вас на страницах нашего блога. Мы готовы и дальше делиться с вами актуальными новостями, обзорными материалами и другими публикациями, и постараемся сделать все возможное для того, чтобы проведенное с нами время было для вас полезным. И, конечно, не забывайте подписываться на наши рубрики.
Другие наши статьи и события
Сотрудники Исследовательского центра Уотсона компании IBM Тайфун Гокмен (Tayfun Gokmen) и Юрий Власов разработали новый чип Resistive Processing Unit (RPU), сочетающий в себе центральный процессор и энергонезависимую память и способный обеспечить существенное ускорение процесса глубокого обучения нейросетей (Deep Neural Networks, GNN) в сравнении с существующими процессорами при сравнительно меньших значениях энергопотребления.
“Системе, которая состоит из кластера ускорителей RPU окажутся под силу задачи больших данных, обрабатывающих одновременно триллионы параметров. В качестве примера таких массивов можно привести распознавание и перевод естественной речи между всеми языковыми парами, существующими в мире, аналитику интенсивных потоков научной и деловой информации в режиме реального времени или анализ мультимодальных потоков данных, поступающих от колоссального числа сенсоров IoT”, — комментируют событие исследователи на страницах ресурса arxiv.org.
На протяжении последних нескольких десятилетий достигнут внушительный прогресс в скорости машинного обучения. Это стало возможным благодаря использованию графических процессоров, массивов программируемой логики FPGA и специализированных микросхем (ASIC). Сегодня обеспечить дальнейшее ощутимое ускорение процесса, по мнению авторов разработки, позволит использование концепции параллельности и локальности алгоритмов обработки информации. Базой для успешной реализации таких концепций в лаборатории IBM стали принципы, реализованные в технологиях энергонезависимой памяти следующего поколения — фазовой (PCM) и резистивной (RRAM).
Schematics of original weight update rule of Eq.1 performed at each cross-point. (B) Schematics of stochastic update rule of Eq.2 that uses simple AND operation at each cross-point. Pulsing scheme that enables the implementation of stochastic updates rule by RPU devices for © up and (D) down conductance changes.
Сама по себе предложенная память позволяет ускорить DNN (процесс глубокого машинного обучения) в 27–2140 раз, но исследователи убеждены, что, сняв некоторые конструкционные ограничения запоминающих ячеек, им удастся обеспечить ещё более впечатляющие результаты. Как утверждает объединенная команда специалистов, работающая над инновационной технологией, чип, базирующийся на новой энергонезависимой памяти, созданный по разработанным ими спецификациям, позволит обеспечить прирост скорости работы алгоритма в сравнении с самыми мощными микропроцессорами в 30 тыс. раз.
Как полагают Власов и Гокмен, реализовать такие чипы возможно будет на базе традиционных КМОП-технологий. Вместе с тем, воплотить описанную концепцию на уровне коммерческих решений, скорее всего, удастся не ранее, чем через несколько лет, когда указанные технологии памяти «дотянутся» до рынка. Проведенные IBM исследования и достигнутые в теории результаты, по мнению экспертов уже сегодня выглядят очень многообещающе, поскольку открывают путь к новым качественным и количественным возможностям в освоении технологий машинного обучения.
Важно, что помимо самой IBM, совместная разработка специалистов T.J. Watson Research Center, вероятнее всего, окажется в центре внимания Google и других IT-гигантов, уже включившихся в многолетнюю гонку за право первыми обуздать возможности искусственного интеллекта. И это, в свою очередь, станет дополнительным мощным стимулом для скорейшего внедрения технологии на уровне коммерческих продуктов.
Источник
Техническое обоснование (pdf)
Уважаемые читатели, мы всегда с удовольствием встречаем и ждем вас на страницах нашего блога. Мы готовы и дальше делиться с вами актуальными новостями, обзорными материалами и другими публикациями, и постараемся сделать все возможное для того, чтобы проведенное с нами время было для вас полезным. И, конечно, не забывайте подписываться на наши рубрики.
Другие наши статьи и события
- Gator Caref Watch. Забота о вашем ребенке
- Весенние скидки от KitchenAid
- Распродажа полезных гаджетов и интересных штук
- Jawbone UP3 vs. Xiaomi Mi Band 1S Pulse — битва за наши сердца!
- Выбор умных часов сегодня. Что изменилось?
- ТОП 10 самых популярных гаджетов в iCover
- Как чехол не спас мой iPhone. Выбирай правильно
