
Если у вас есть проект с интенсивной обработкой данных глубокими моделями (или еще нет, но вы собираетесь его создать), то вам будет полезно познакомиться с приемами по повышению их производительности и уменьшению затрат на покупку / аренду вычислительных мощностей. Тем более, что многие из приемов сейчас выполняются буквально за несколько кликов мышкой, но при этом позволяют повысить производительность на порядок. В этом посте мы рассмотрим, какие оптимизации бывают, установим Docker на Windows 10 и запустим DL Workbench, измерим производительность инференса без оптимизации и с применением оных.
Введение
Перед тем, как погружаться в ускорение глубоких моделей, сначала нужно посмотреть на общую схему жизни любой глубокой модели в каком-либо проекте. В течение «жизни» глубокой модели есть этапы обучения модели и многократного вывода (инференса). Кстати, благодаря четкому разделению на тренировку и инференс модели в ее жизненном цикле, появились специализированные фреймворки только для инференса, как например ONNX runtime или OpenVINO.

Обучение модели производится один или несколько раз, и затраты на железо / электричество на ее обучение не являются фатальными (если, конечно, вы не обучаете GPT-3, для обучения которой OpenAI могла потратить до 4,6 миллиона долларов). А вот при многократном инференсе модели даже небольшие улучшения могут дать хорошую экономию бюджета. Причем для использования некоторых оптимизаций нужно приложить минимальные усилия.
Приемы оптимизации можно разделить на следующие группы:
Внедрение новых, более быстро исполняемых слоев при разработке модели. Группа объединяет приемы, которые закладываются во все модели на этапе конструирования модели. Простейший пример — использование простой и быстрой функции активации ReLU в сверточных глубоких моделях. Такие оптимизации будут за рамками данной статьи.
Оптимизация модели через модификацию некоторых слоев. К таким оптимизациям можно отнести использование слияния линейных операций (Linear Operations Fusing) модели для моделей ResNet. Такие операции применяются автоматически и незаметно при конвертации модели в OpenVINO, но про них полезно знать.
Увеличение степени параллельного исполнения через увеличение числа операций, которые можно выполнить одновременно. Сюда мы отнесем подходы с увеличением размера пачки одновременно обрабатываемых изображений (батча) и запуск на обработку нескольких изображений параллельно и независимо.
Использование типов данных меньшей точности для увеличения производительности. Сюда в первую очередь относится квантизация моделей — ускорение модели и возможное снижение ее точности за счет использования типа данных INT8. Кроме того, есть возможность сразу тренировать глубокие модели с использованием типов данных меньшей точности, но данный метод пока не очень популярен.
После небольшого теоретического экскурса можно переходить к практике. Мы рассмотрим примеры оптимизации инференса, которые мы можем «пощупать» в фрейморке DL Workbench от разработчиков OpenVINO. Intel Distribution of OpenVINO Toolkit — это набор инструментов для оптимизации и высокопроизводительного инференса глубоких моделей. В OpenVINO можно сконвертировать, оптимизировать и запустить модели в форматах Caffe, TensorFlow, MXNet, ONNX (а через формат ONNX мы можем загружать модели из всех остальных фреймворков). Для более детального знакомства с OpenVINO можно посмотреть вот эту презентацию на русском, либо посмотреть оригинальную документацию (но на английском). DL Workbench — это графический интерфейс для более удобного и наглядного взаимодействия с инструментами оптимизации.

Установка DL Workbench
Чтобы начать работать с DL Workbench, нужно его установить, но сначала нужно установить Docker. Если вы еще не пользуетесь Docker в Windows 10, то в его установке на Windows есть дополнительные шаги.
Скачать и установить обновление Windows до WSL 2;
Установить WSL 2 по умолчанию (пишут, что команду нужно выполнять в PowerShell):
wsl --set-default-version 2Скачать себе Ubuntu 20.04 через Windows Store;
Скачать и установить докер.
После установки докера запуск DL Workbench сводится к двум командам. Скачать его через docker pull и запустить через docker run.
docker pull openvino/workbench
docker run -p 127.0.0.1:5665:5665 --name workbench -it openvino/workbench:latestРабота в DL WorkBench
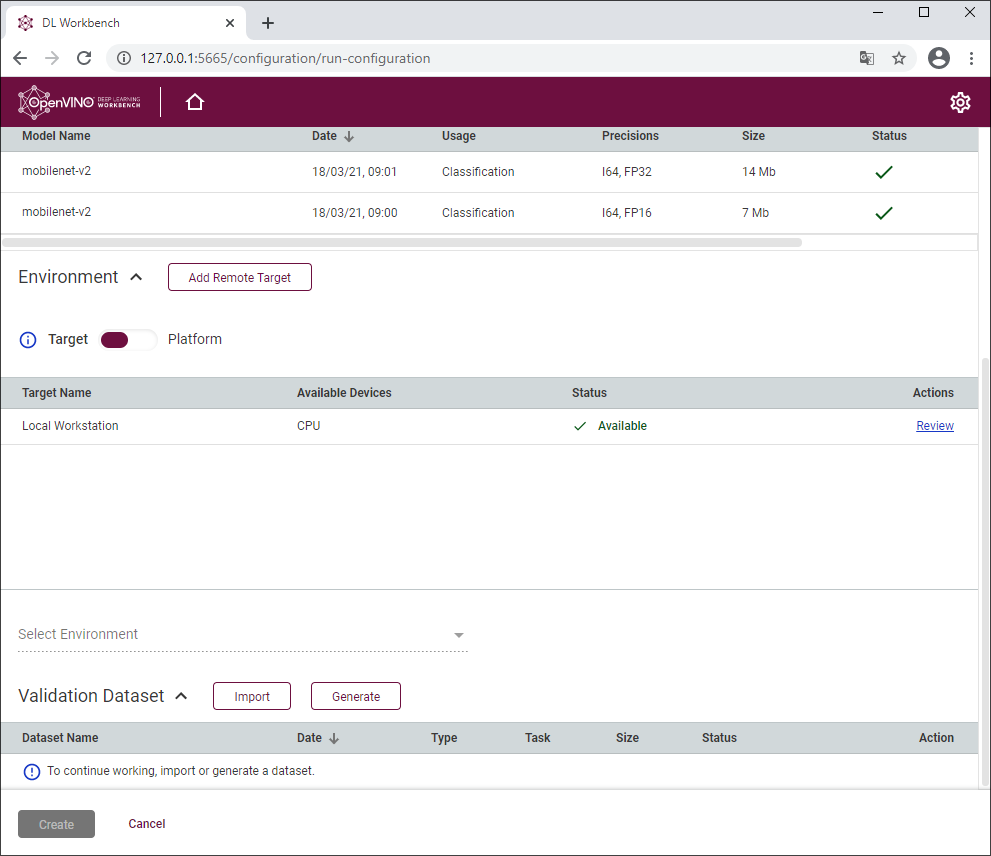
После запуска DL Workbench в браузере открывается приветственная страница, в которой нам предложат создать конфигурацию теста, состоящего из модели, устройства для инференса и датасета.
Приветственное окно DL WorkBench
Можно загрузить свою модель для оптимизации или скачать любую доступную модель из Open Model Zoo — репозитория моделей, в котором более 200 моделей из различных областей компьютерного зрения и не только. Для манипуляций в этом примере используется модель MobileNet-v2, потому что она имеет хорошее соотношение «качество работы / вес модели». Можно было бы для экспериментов взять модель ResNet-50, которая за 5 лет оккупировала все бенчмарки глубоких моделей, но MobileNet-v2 - более свежая и интересная модель.
После загрузки модели она будет сконвертирована из формата оригинального фреймворка в промежуточное представление (Intermediate representation, IR) — модель сохранится в два файла с расширениями .xml и .bin. Кроме этого, можно выбрать точность конвертации из вариантов FP32 или FP16. Как показывает практика, модель в формате FP16 работает с аналогичным качеством, что и FP32, но при этом она в 2 раза меньше и некоторые устройства работают с FP16 моделями намного быстрее. Это уже можно считать первой оптимизацией.
Импортируем модель из Open Model Zoo и конвертируем в IR
В то время, когда модель конвертировалась в IR формат, уже были применены некоторые структурные оптимизации по слиянию слоев. Например, для моделей ResNet, которые часто являются основой для трансфер лернинг и, таким образом, задействованы в большом количестве моделей из самых разных областей, производится операция слияния слоев (Linear operation Fusing), что уже дает хорошее ускорение по инференсу моделей по сравнению с фреймворками для обучения моделей. На рисунке ниже можно посмотреть, как OpenVINO оптимизирует структурный блок модели ResNet-50. Вместо 12 слоев в оригинальном фреймворке 8 в оптимизированном представлении, картинка со страницы Model Optimizer.

Более подробно про оптимизации модели во время конвертации можно прочитать на странице Model Optimizer. Там описано какие еще применяются оптимизации слоев внутри модели при конвертации.
С внутренними оптимизациями модели пока все, возвращаемся к DL Workbench и смотрим на оптимизации не самой модели, а ее инференса. Для этого нужно загрузить датасет или сгенерировать фейковый набор данных из шума, чтобы запускать тесты производительности. Во второй части статьи мы рассмотрим, как загрузить реальный датасет, когда он нам понадобится для квантизации моделей.
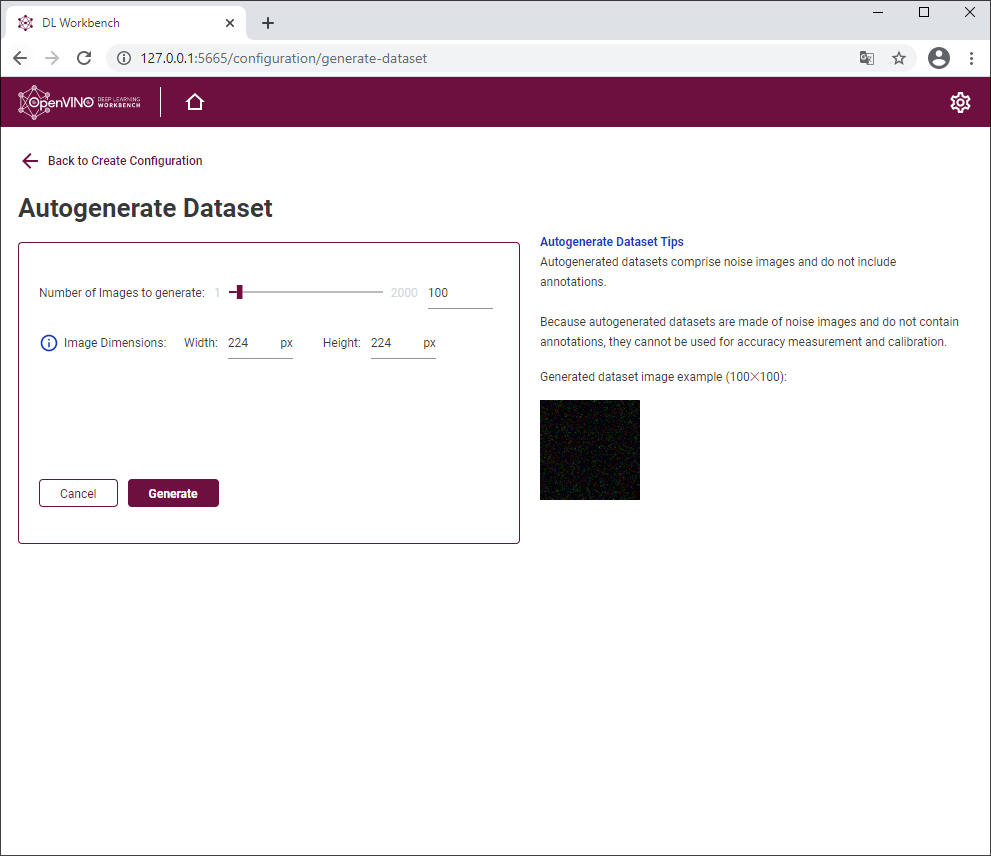
Генерируем датасет из шума для бенчмаркинга
После того, как мы выбрали и конвертировали модель, выбрали устройство для тестирования, подготовили датасет и нажали кнопку Create, можно запустить первый прогон с параметрами по умолчанию. В качестве основной метрики производительности используется среднее количество обработанных изображений (или других объектов) в секунду - FPS (Frames per Second).
Первые результаты производительности MobileNet-v2 на i5-10600

Во всех фреймворках поддерживается увеличение производительности за счет увеличения размера пачки. Размер пачки подбирается в зависимости от количества ядер экспериментально. В DL Workbench мы можем выполнить эксперименты по подбору оптимального размера пачки. Как правило, размер пачки в несколько раз превышает число физических ядер при инференсе на CPU, в нашем случае на графике ниже будет видно, что оптимальным значением является 8 картинок в пачке, при дальнейшем увеличении производительность уменьшается. По сравнению с 326 fps при размере пачки 1, 410 fps при размере пачки 8 составляют увеличение производительности на 25%, уже неплохо.
График производительности с различными размерами пачки

Можно вечно смотреть на три вещи - как горит огонь, как течет вода, и как тестится производительность сетки.
Прием с увеличением размера пачки одновременно обрабатываемых изображений универсален и может использоваться почти со всеми моделями. Но есть ситуации, в которых этот прием не подходит - например, обработка видеопотока в автономном устройстве. Если у нас есть робот с камерой в 30 или 60 FPS, то мы не можем увеличивать задержку в получении результатов обработки - эти данные быстро становятся неактуальными. Возможные оптимизации инференса для таких случаев мы рассмотрим во второй части.
