Комментарии 30
Конечно, есть еще более 30 параметров и на каком-то из серверов, возможно, что-то сработает лучше. Область обширная, эксперименты еще продолжаются, и если подскажете куда стоит посмотреть — буду благодарен.
Из операционных показателей серверов, наверное, можно анализировать так трафик.
Лучше всего таким образом анализировать бизнес метрики.
Сейчас аномалии — это «дергания» и любые резкие движения, на которые нейронная сеть реагирует, даже если параметры не доходят до порогового значения.
Про бизнес-метрики понял, еще раз спасибо.
Отслеживание аномалий и сезонность решаются статическими методами, описанными например тут. Надеялся увидеть решение для «кардиограммы».
Как мне кажется, если бы вы смогли выявлять аномалии в данных мониторинга, то в таком случае надо уже выпускать коробочный продукт.
Просто разрабатываю свой велосипед для мониторинга и понимаю, что стандартные проверки на выход за пределы критичных интервалов уже отживают — слишком многое они пропускают, как выходящее из строя оборудование, так и подозрительную активность в сети.
На рынке систем мониторинга уже начинают почесываться, напр. DataDog предлагает свой алгоритм, правда на основе статистики, у Prometheus то же похоже что-то есть. Популярный Zabbix в этом плане в аутсайдерах.
Между тем кто-то даже целый бизнес на поиске аномалий строит.
1) Интересно было бы раскрыть — почему был убран «логарифмический масштаб» по времени? Мне кажется, возможные проблемы тут — подобие anti-aliasing и большое количество масштабов. Попробуйте номинальный ряд или геометрическую прогрессию q=2.
2) Пробовали ли Вы дополнять набор данных какими-нибудь интегральными параметрами ряда (среднее, СКО, размах, тренд, % мощности спектра на разных полосах частот и т.д.) — опять же, на разных масштабах/окнах? Как убирали лишние параметры?
3) Нормировка данных — что на что нормировали, на каком окне?
4) Это один временной ряд, или несколько (многомерный ряд)? А с разреженными рядами работали?
2) Да, на мой взгляд эти дополнительные параметры как раз и есть отличный подход. Так как данные уже нормализованы, то среднее и мат. ожидания не думаю, что дадут какой-то эффект. Тренды планируется убирать, в качестве параметра не известно какой. А мощность спектра и использование FFT — да, думаю будет полезно. Думаю, что тут нет лишних параметров, просто их надо как-то еще суметь использовать. Пока не знаю — были эксперименты в песочницы, надо смотреть.
3) Нормировалось за месяц, считалось за сутки. Иногда нормировалось ровно за тот период времени, который считался — например, за неделю и считалось тоже за неделю.
4) В п. 5 — многомерный, п. 6 — одномерный. Разреженные ряды — это из области преобразований Фурье? Судя по всему — ряды не разреженные, но надо проверять, не могу сказать ничего определенно.
3) А нормировать одни масштабы на другие пробовали? Малые на большие, малые на средние, средние на большие?
4) Разреженные ряды — это когда вам лень считать скользящие средние по всем точкам, и вы считаете с неким шагом. Или когда из разных источников разная частота дискретизации.
___
Еще вопрос — инструмент ручной разметки вы сами делали, или есть какие-то готовые тублоксы?
3) Ну в каком-то смысле рис. 6 и рис. 7 — это разные масштабы. ИНС вполне может как-то с этим жить.
4) Нет, ряд всегда полный и дополняется какой-то интерполяцией. Быстрее всего просто делать как на последней таблице (если значение пропущено, то берем ближайшее предыдущее)
Если про выбор обучающего набора, то можно использовать небольшие веб-приложения пользуясь js-библиотеками типа www.flotcharts.org/flot/examples/interacting/index.html
Ну либо вручную. Если вопрос про графики, то в основном хватает стандартного matplotlib.
Прошу прощения за поздний ответ. С наступающим)
Дело в том, что в конечном-то итоге человек принимает решение о том, что делать со всей поступившей от нейронной сети информацией. У нас, например, тысячи виртуальных машин, серверов заведены как раз-таки в Zabbix — положим, в их «поведении» и правда есть аномалии, мы их даже выявили все в наилучшем виде. А дальше-то что с этим всем делать?
Основная мотивация для создания этой дополнительной системы в том, что данных действительно много и если есть хороший способ что-то среди них «увидеть» с помощью дополнительного «органа чувств», то это может оказаться полезным.
В данное время система еще в процессе интеграции, поэтому большой опыт использования еще не наработан. Использование в реальном времени требует больше ресурсов, но для некоторых серверов можно сделать исключение, а по остальным уже генерировать отчеты за определенный период.
Весь проект написан на Go и больше заточен на использование с инфраструктурой Kapacitor (от того же разработчика).
Второй упоминаемый проект (https://github.com/eleme/banshee) тоже написан на Go, и также использует статистические методы для нахождения первого типа аномалий — точечные (outlier) по метрикам. Там больше заточенность на использование в real-time и это тоже можно сказать коробочное решение.
Про Go написал два раза — не холивара ради (хорошо отношусь и к Go и к Rust), а для подчеркивания того, что это уже почти готовое решение «в коробке» завязанное на определенное окружение. Поэтому использоваться вряд ли будет, хотя на некоторые элементы можно обратить внимание, поэтому за этими проектами стоит следить. Если что-то изменится, то все возможно :)
Но многие из существующих решений ищут аномалии по принципу «найти стандартное отклонение, среднее и все, что лежит за пределами трех сигма считать аномалией». Поэтому хотелось посмотреть в сторону фундамента, на котором это все строится — математических моделей. Естественно, что велосипеды изобретать не стоит, но область обширная и интересная — надо изучать и экспериментировать.
Возможно стоит попробовать сымитировать модель мозга, упоминаемую Хокинсом в книге «Об интеллекте»: сенсорные сигналы поступают в локализованные участки, а потом агрегируются и передаются уже дальше, напр. информация с нейронов сетчатки сперва обрабатывается в участках затылочных долей, которые специализируются на выделении вертикальных-косых-горизонтальных линий и других примитивов, а только затем передается дальше в участки «принятия решений и прогнозирования». В данном случае, каждый специализированный участок можно попробовать обучить отдельным статистическим методам, подключив R. А итоговую сеть обучать уже на их итоговых результатах.
Спасибо за интерес к теме и хорошие замечания. Да, есть мысль использовать "каскад" нейронных сетей для того, чтобы отдельно выделять какие-то свои "нейронные" метрики помимо известных статистических параметров и затем уже их использовать как вход к основной нейронной сети, которая уже выделяет дополнительные аномалии. Про эксперименты с другими подходами и что из этого получилось постараюсь написать в другой раз.
Насчет зашумленности — да, это общая проблема по поводу выделения сигнала из шума. В данном случае решалось примерно так — шум снизу отрезается экспоненциальным сглаживанием используя в качестве функции — http://mathworld.wolfram.com/HanningFunction.html и окно в 12.5 минут. Это то, что использовалось в статье (в том числе при обучении сети) и видимо важно про это дополнить.
Но в целом модель подобрана видимо неудачно, т.к. на других метриках все уже не так и если использовать такой подход, то для каждой метрики будет нужна своя сеть и для своих типов аномалий.
Тем не менее, "сбитую кардиограмму" такая модель может обнаружить — ради любопытства проверил на примере из статьи [1]. Сырых данных не было, поэтому извлекал их из графика этим удобным инструментом https://automeris.io/WebPlotDigitizer/ :)
Только для таких аномалий надо предварительно обучить и показать что считать аномалией. В этом случае на искусственных кардиограммах будет обнаруживать необычные плато.
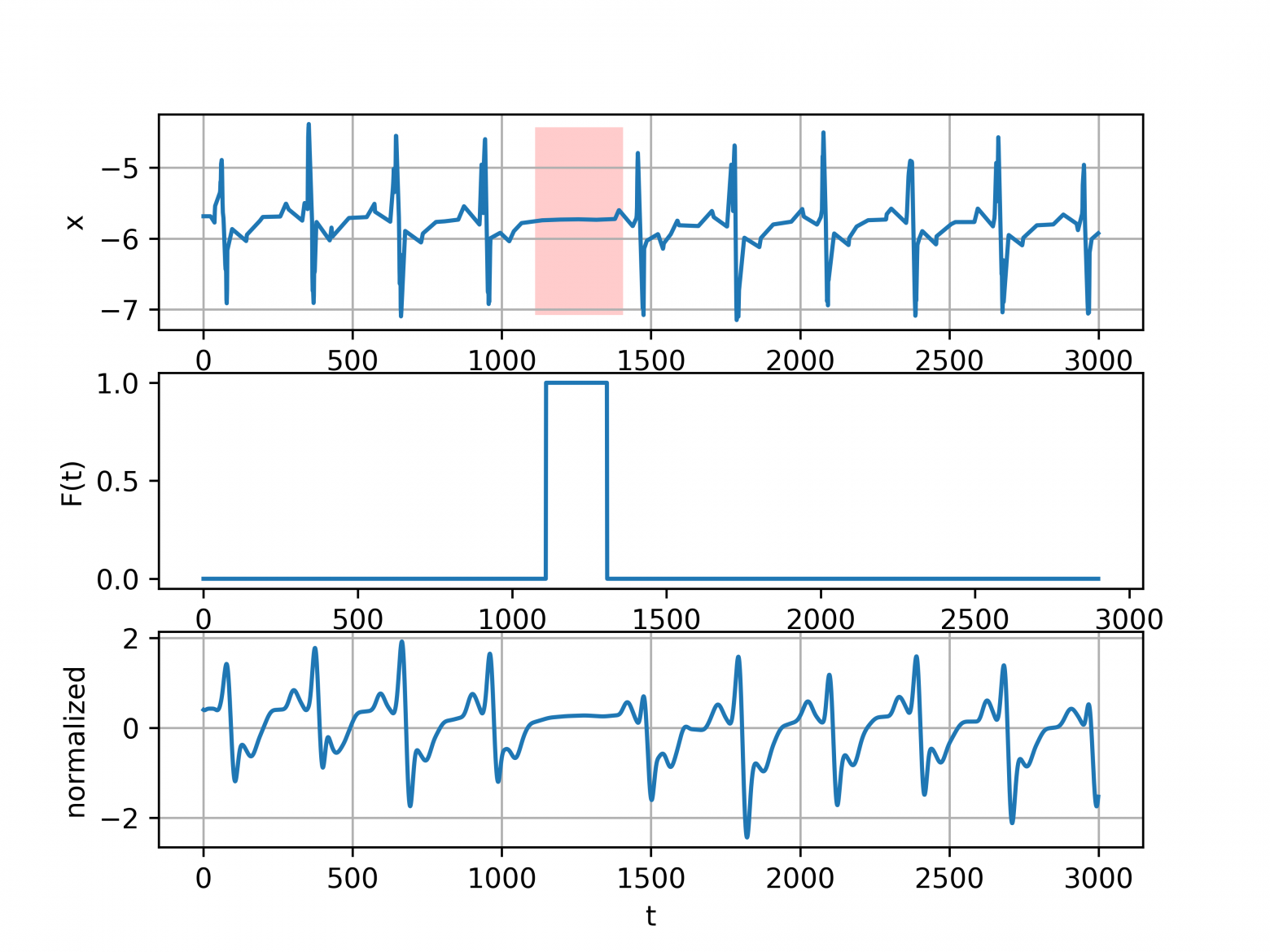
Спасибо за исследование. Занимаюсь тестированием производительности. Добавлю в копилку аномалий такую: прекратился рост метрики при сохранении роста других метрик.
Например, система под нагрузкой. Вдруг рост утилизации процессора останавливается, а интенсивность Context Switch продолжает расти или даже рост увеличивается. Тут вполне возможно, что упёрлись в ограничения cgroups в linux для архитектуры x86. Или в другие ограничения для других архитектур. Или с ростом нагрузки прекращается рост числа открытых файлов и начинает медленно расти время отклика. Причины могут быть разные — лимиты на процессор, на систему в целом, а может достигнут лимит числа потоков, и из-за этого перестал расти счётчик дескриптоторов файлов.
Это к чему. Мечтаю об автокорреляции временных рядов, которая бы находила такие аномалии — нарушения ожидаемых корреляций. Область знаний — статистика и статистические методы. Не планировал при реализации задействовать нейроные сети в качестве основы. Когда-нибудь сделаю. Пока просто набираюсь опыта, коплю обучающую выборку.
Спасибо за комментарий и описание сценария.
Если абстрагироваться от техники и перейти только к математике и числам, то действительно, для решения описанной задачи очень хорошо подойдет взаимнокорелляционная функция (CCF). Можно посмотреть описание применения CCF в поиске аномалий здесь
В вашем случае алгоритм видится примерно такой:
- (опционально) посчитать производные, если речь идет именно об одинаковом поведении роста, а не поведении самих графиков
- найти все зависимые графики и их сдвиги, найдя максимумы в их коэффициентах корреляции (хорошее описание опять же здесь)
- нормализовать зависимые графики так, чтобы они хорошо накладывались друг на друга (учесть сдвиги, найденные в предыдущем пункте и привести к одному масштабу)
- вычесть один график из другого
- в полученной разнице — найти стандартное отклонение (сигма)
- все, что выходит за пределы трех сигма считать аномалией :)
Никакой экзотики, выглядит как достаточно простой и рабочий способ. Допускаю, что даже возможно где-то упростить.
Нейронные сети — более нелинейный инструмент и даже не уверен стоит ли применять его в этой постановке, особенно если есть альтернатива попроще. Все-таки при работе с нейронными сетями как могут потребоваться хорошие обучающие и тестовые наборы, так еще потом могут возникать известные сложности типа неправильного выбора модели или обучающих параметров, ну и часто — просто сложность интерпретации того, что происходит :)
С другой стороны, нейронные сети могут оказаться полезным инструментом в случае обнаружения какой-то неявной зависимости или быть дополнительным фильтром в шаге 6.
Кибер-оракул: поиск аномалий в данных мониторинга с помощью нейросети