
Современные текстовые редакторы умеют не только бибикать и не давать выйти из программы. Оказывается, внутри них кипит очень сложный метаболизм. Хотите узнать, какие ухищрения предпринимаются для быстрого пересчета координат, как к тексту приделываются стили, фолдинги и софтврапы и как это всё обновляется, при чем тут функциональные структуры данных и очереди с приоритетами, а также как обманывать пользователя — добро пожаловать под кат!

В основе статьи — доклад Алексея Кудрявцева с Joker 2017. Алексей уже лет 10 пишет Intellij IDEA в JetBrains. Под катом вы найдете видео и текстовую расшифровку доклада.
Чтобы понять, как устроен редактор, давайте его напишем.

Всё, наш простейший редактор готов.
Внутри редактора текст легче всего хранить в массиве символов, ну или, что то же самое (в смысле организации памяти), в Java-классе StringBuffer. Чтобы получить какой-нибудь символ по смещению, мы вызываем метод StringBuffer.charAt(i). А чтобы вставить в него символ, который мы напечатали на клавиатуре, вызовем метод StringBuffer.insert(), который вставит символ куда-то в середину.
Что самое интересное, несмотря на всю простоту и идиотичность этого редактора, — это самое хорошее представление, которое только можно выдумать. Оно и просто и почти всегда быстро.
К сожалению, с этим редактором возникает проблема масштаба. Представим, что мы напечатали в нём очень много текста и собираемся вставить в середину еще одну букву. Произойдет следующее. Нам срочно нужно освободить для этой буквы какое-то пространство, сдвинув все остальные буквы на один символ вперёд. Для этого мы сдвигаем эту букву на одну позицию, потом следующую и так далее, до самого конца текста.
Вот как это будет выглядеть в памяти:
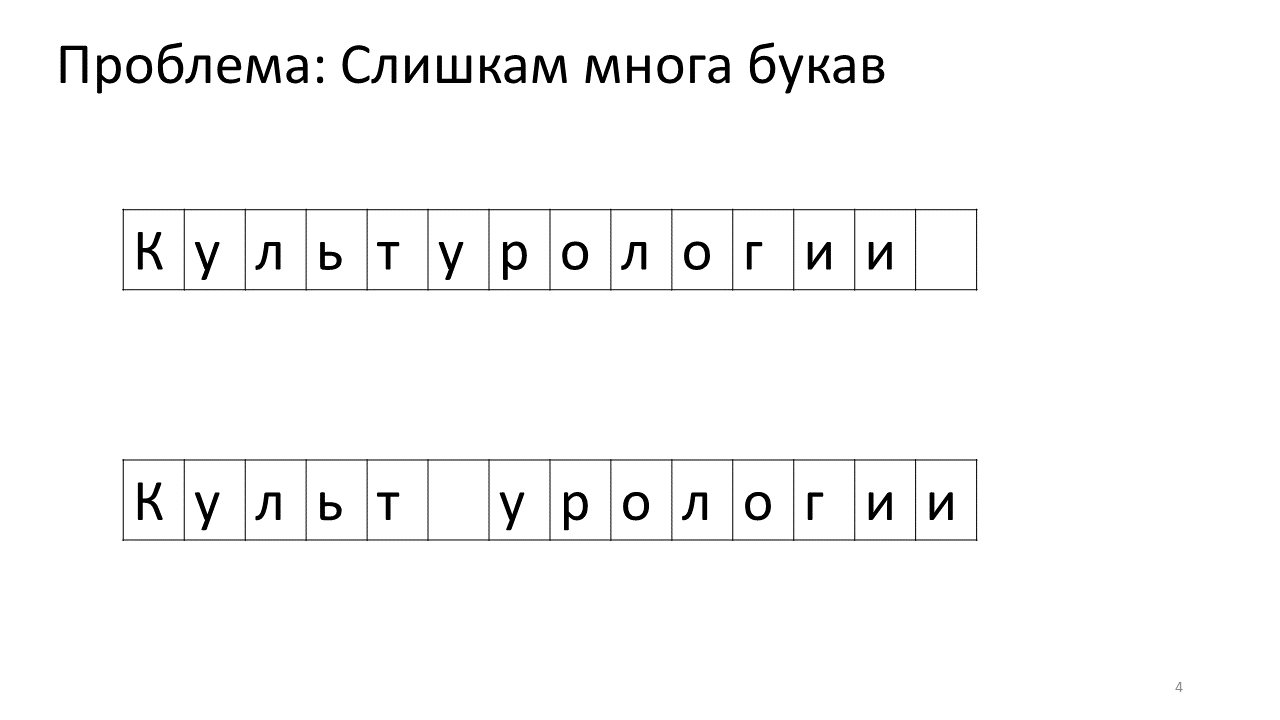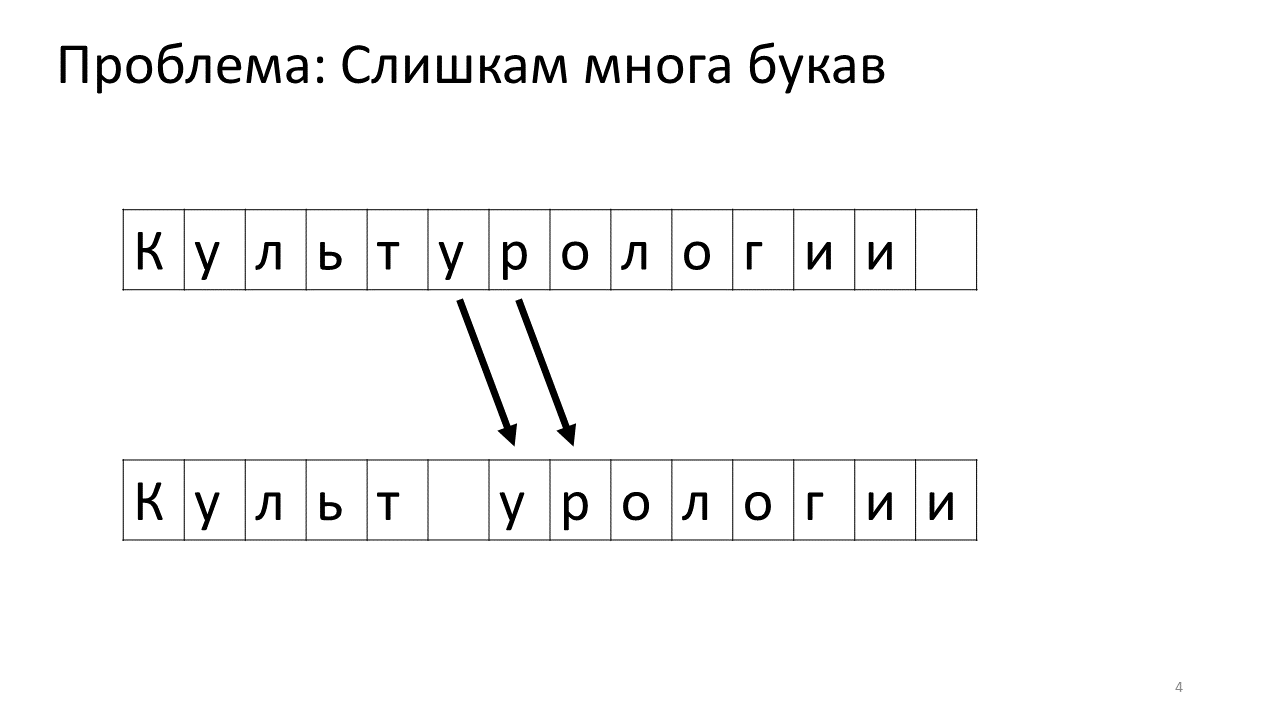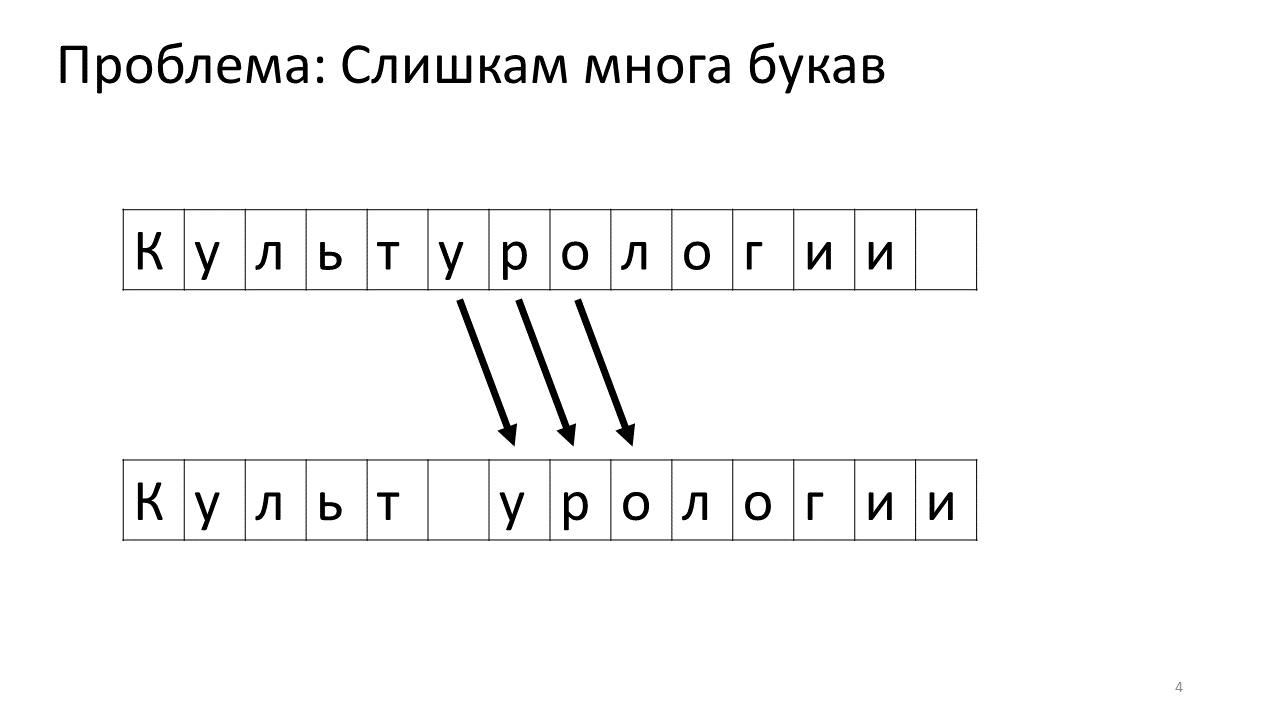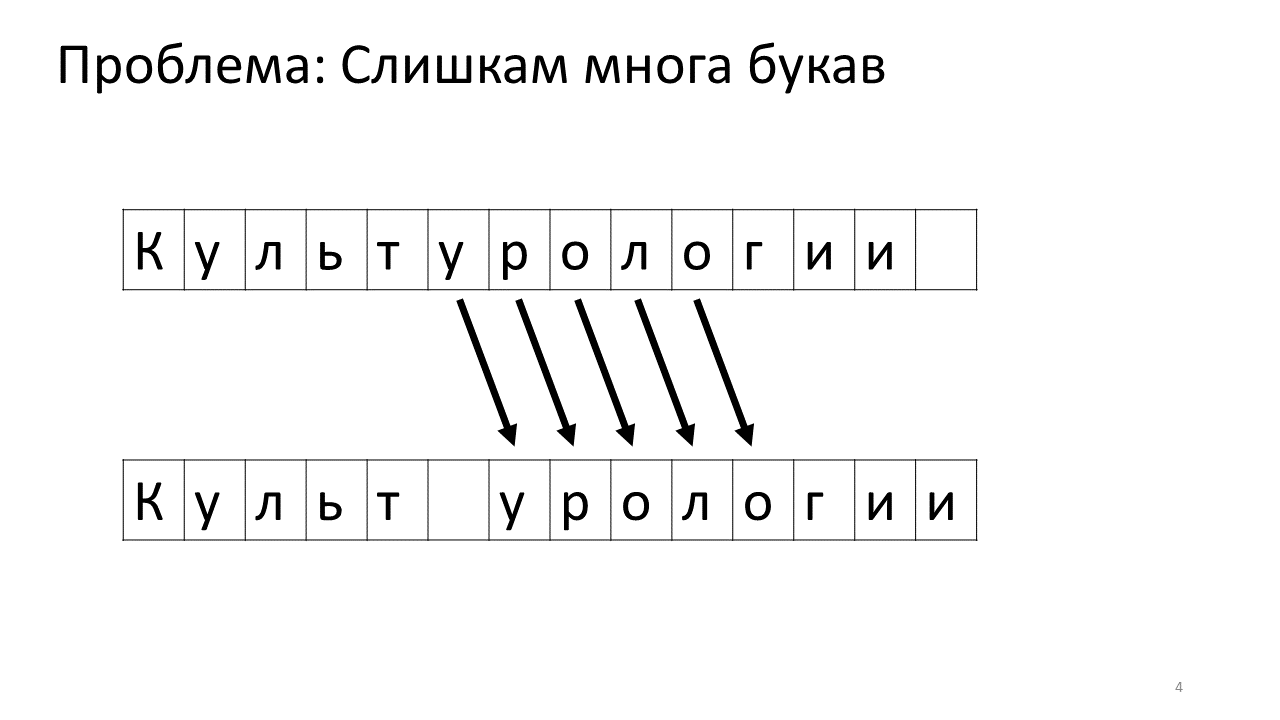
Сдвигать все эти многочисленные мегабайты не очень хорошо: это медленно. Конечно, для современного компьютера это плёвое дело — какие-то жалкие мегабайты подвигать туда-сюда. Но для очень активного изменения текста это может быть заметно.
Чтобы решить эту проблему вставки символа в середину, давным-давно придумали обходной манёвр под названием «Gap Buffer».
Gap — это зазор. Buffer — это, как вы догадываетесь, буфер. Структура данных «Gap Buffer» — это такой пустой буфер, который мы храним посередине нашего текста, на всякий случай. Если нам потребовалось что-то напечатать, мы используем этот текстовый маленький буфер для быстрого впечатывания.

Структура данных у нас немножко поменялась — массив остался на месте, но появились два указателя: на начало буфера и на его конец. Чтобы взять символ из редактора по какому-то смещению, нам нужно понять, находится ли он до или после этого буфера и немножечко подправить смещение. А чтобы вставить символ, нам нужно сначала пододвинуть Gap Buffer к этому месту и заполнить его этими символами. И, конечно, если мы вышли за пределы нашего буфера, его как-то пересоздать. Вот как это выглядит на картинке.

Как видно, мы сначала долго двигаем на маленький gap-buffer (синенький прямоугольник) к месту редактирования (просто меняя местами символы с его левого и правого края по очереди). Потом мы используем этот буфер, впечатывая туда символы.
Как можно заметить, никакого передвижения мегабайт символов нет, вставка происходит очень быстро, за константу времени, и вроде все счастливы. Кажется, всё хорошо, но если у нас процессор очень медленный, то на перемещение туда-сюда gap-buffer и текста тратится довольно заметное время. Особенно это было заметно во времена очень маленьких мегагерц.
Как раз в это время корпорация под названием Microsoft писала текстовый редактор Word. Они решили применить у себя другую идею для ускорения редактирования под названием «Piece Table», то есть «Таблица Кусочков». И они предложили текст редактора сохранять в этом же самом простейшем массиве символов, который меняться не будет, а все его изменения складывать в отдельную таблицу из этих самых отредактированных кусочков.

Таким образом, если нам нужно найти какой-то символ по смещению, нам нужно найти этот кусочек, который мы поредактировали, и извлечь из него этот символ, а если его там нет, то пойти в оригинальный текст. Вставка символа становится легче, нам всего лишь нужно этот новый кусочек создать и добавить в таблицу. Вот как это выглядит на картинке:
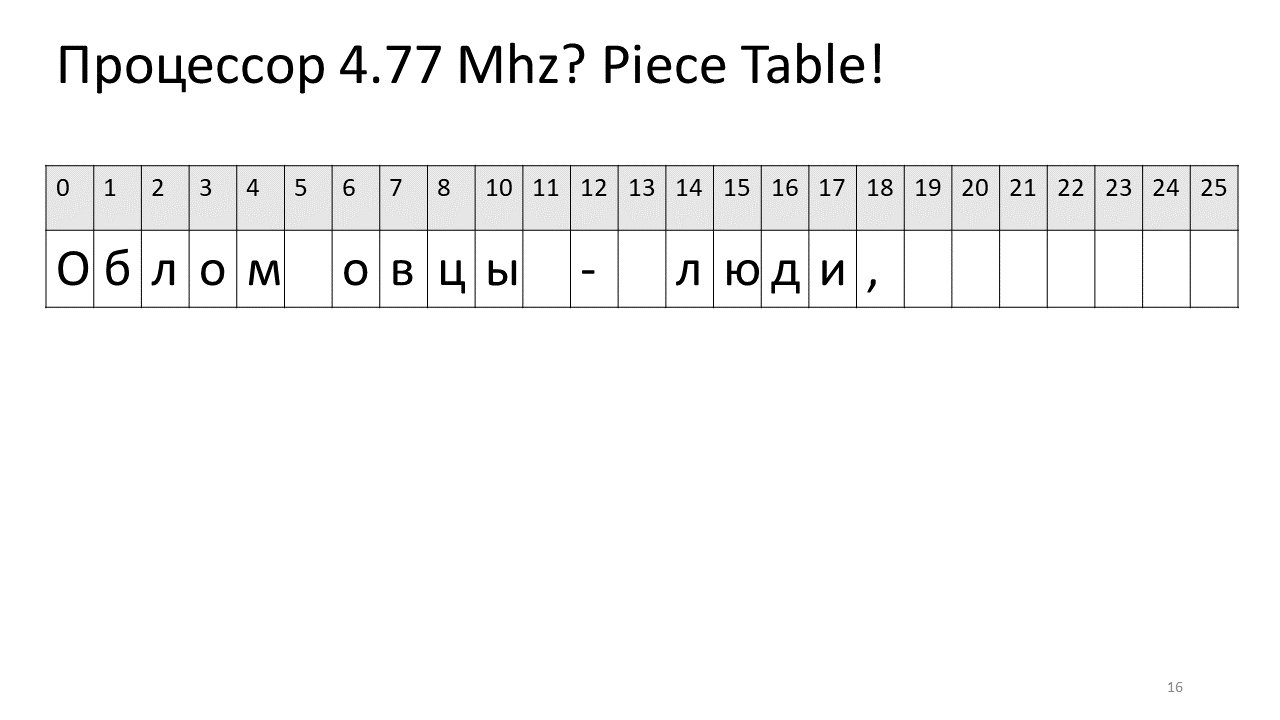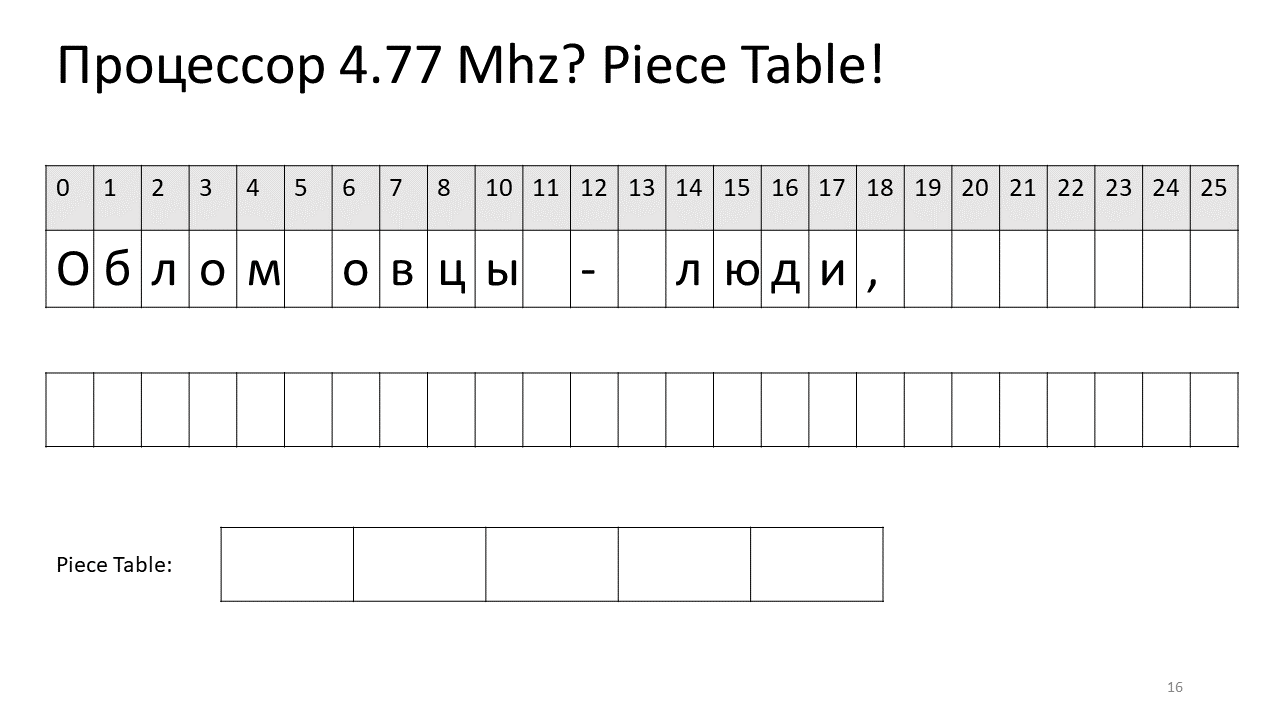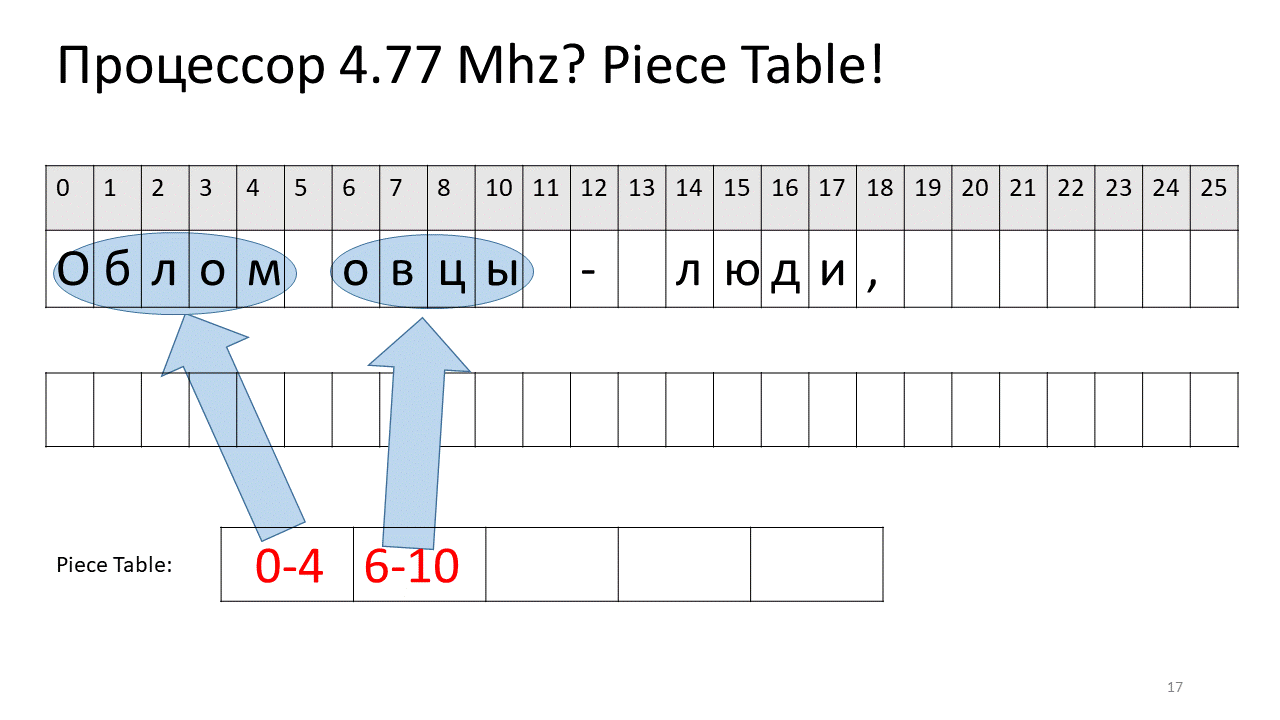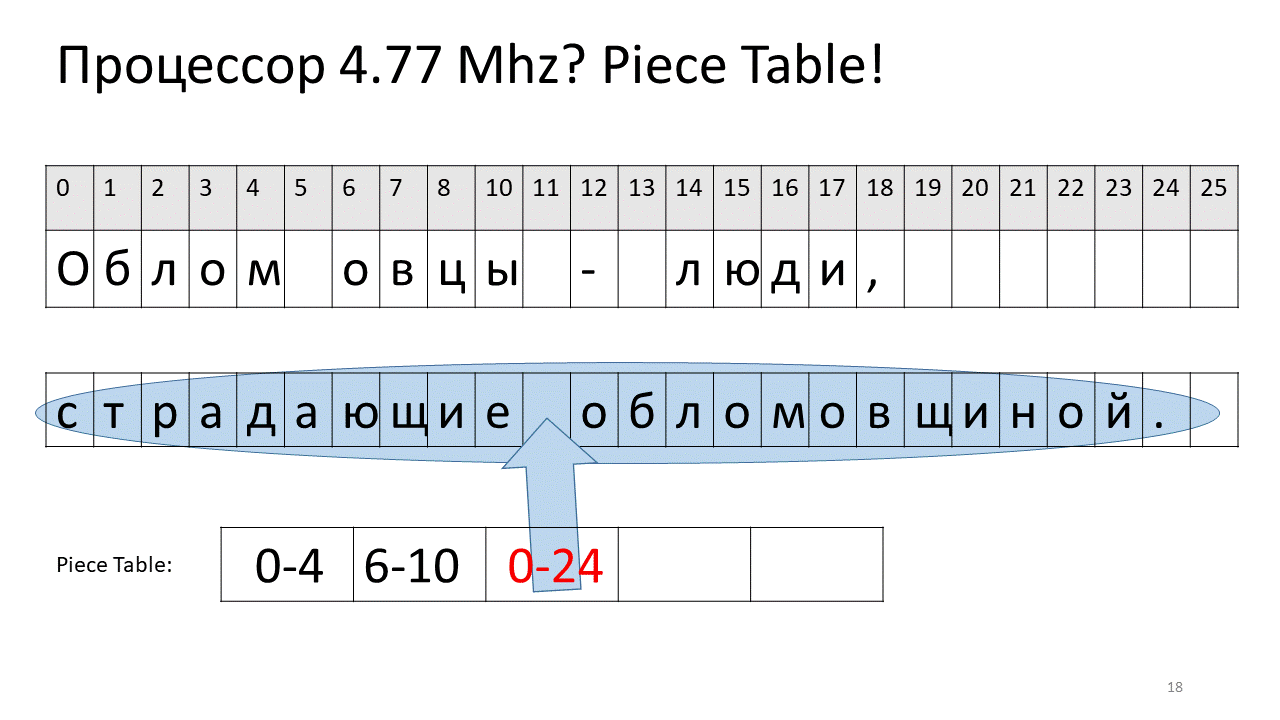
Здесь мы захотели удалить пробел по смещению 5. Для этого мы добавляем в таблицу кусочков два новых кусочка: один указывает на первый фрагмент («Облом»), а второй указывает на фрагмент после редактирования («овцы»). Получается, что пробел из них исчезает, эти два кусочка склеиваются, и у нас получается новый текст уже без пробела: «Обломовцы». Потом добавляем новый текст («страдающие обломовщиной») в конец. Используем дополнительный буфер и добавляем в таблицу кусочков (piece table) новый кусочек, который указывает на этот самый новый добавленный текст.
Как видите, никаких перемещений туда-сюда не происходит, весь текст остаётся на месте. Плохо то, что становится сложнее добраться до символа, потому что перебирать все эти куски довольно тяжело.
Подведем итоги.
Что хорошо в Piece Table:
Что плохо:
Давайте посмотрим, кто у нас вообще обычно что использует.
NetBeans, Eclipse и Emacs используют Gap Buffer — молодцы! Vi не заморачивается и использует просто список строчек. Word использует Piece Table (недавно они выложили свои древние сорцы и там даже можно что-то понять).
С Atom интереснее. До недавнего времени они не заморачивались и использовали JavaScript-список строчек. А потом решили всё переписать на C++ и наворотили довольно сложную структуру, которая вроде как похожа на Piece Table. Но вот эти кусочки у них хранятся не в списке, а в дереве, причём в так называемом splay tree — это дерево, которое саморегулируется при вставке в него, чтобы недавние вставки были быстрее. Очень сложную штуку они наворотили.
Что использует Intellij IDEA?
Нет, не gap-buffer. Нет, вы тоже не правы, не piece table.
Да, совершенно верно, свой собственный велосипед.
Дело в том, что у IDE требования к хранению текста немного другие, нежели в обычном текстовом редакторе. Для IDE нужна поддержка разных хитрых вещей вроде конкуррентности, то есть параллельного доступа к тексту из редактора. Например, чтобы много разных испекшенов могли его читать и что-то делать. (Инспекшн — маленький кусочек кода, анализирующий программу тем или иным образом, — например, ищущий места, выбрасывающие NullPointerException). Также для IDE нужна поддержка версий редактируемого текста. Несколько версий одновременно лежат в памяти, пока вы работаете с документом, с тем, чтобы эти долгие процессы продолжали анализировать старую версию.
Для того, чтобы поддержать параллельность, операции с текстом обычно оборачивают в «synchronized», или в Read-/Write-локи. К сожалению, это всё не очень хорошо масштабируется. Другой подход — Immutable Text, то есть неизменяемое хранилище текста.

Вот как выглядит редактор с неизменяемым документом в качестве поддерживающей структуры данных.
Как устроена сама структура данных?
Вместо массива символов у нас будет новый объект типа ImmutableText, хранящий текст в виде дерева, где в листах хранятся маленькие подстрочки. При обращении по какому-то смещению он пытается в этом дереве дойти до самого нижнего листа, и у него уже спросить символ, к которому мы обращались. А при вставке текста он создает новое дерево и сохраняет его в старом месте.

К примеру, у нас есть документ с текстом «Бескалорийный». Он реализован как дерево с двумя листами из подстрочек «Бес» и «калорийный». Когда мы хотим вставить в середину строчку «довольно», то создается новая версия нашего документа. И именно, создается новый корень, к которому привязываются уже три листа: «Бес», «довольно» и «калорийный». Причём два из этих новых листов могут ссылаться на первую версию нашего документа. А для листа, в который мы вставили строчку «довольно», отводится новая вершина. Тут и первая версия, и вторая версии доступны одновременно и они все иммутабельные, неизменяемые. Всё выглядит хорошо.
Кто же использует какие хитрые структуры?

Вот, например, в GNOME какой-то их стандартный виджет использует структуру под названием Rope. Xi-Editor — это новый блестящий редактор от Рафа Левиена — использует Persistent Rope. А Intellij IDEA использует этот самый Immutable Tree. За этими всеми названиями, на самом деле, скрывается более-менее одна и та же структура данных с древовидным представлением текста. За исключением того, что GtkTextBuffer использует Mutable Rope, то есть дерево с изменяемыми вершинами, а Intellij IDEA и Xi-Editor — Immutable.
Следующая вещь, которую нужно учитывать при разработке хранилища символов в современных IDE, называется «мультикаретки». Эта фича позволяет печатать сразу в несколько мест, используя несколько кареток.

Мы можем что-то печатать и одновременно в нескольких местах документа у нас вставляется то, что мы туда напечатали. Если мы посмотрим, как наши структуры данных, которые мы рассмотрели, реагируют на мультикаретки, мы увидим кое-что интересное.

Если мы вставляем символ в наш самый первый примитивный редактор, для этого потребуется, естественно, линейное количество времени, чтобы сдвинуть туда-сюда кучу символов. Это записывается в виде O(N). Для редактора на основе Gap Buffer’а, в свою очередь, требуется уже константное время, для этого он и был придуман.
Для immutable-дерева время зависит логарифмически от размера, потому что надо сначала пройти от вершины дерева до его листа — это логарифм, а потом для всех вершин на пути создать новые вершины для нового дерева — это опять логарифм. Для Piece Table тоже требуется константа.
Но все немножко меняется, если мы попробуем померять время вставки символа в редактор с мульти-каретками, то есть, вставки одновременно в несколько мест. С первого взгляда, время вроде как должно пропорционально увеличиться в C раз — число мест, куда вставляется символ. Всё так и происходит, за исключением Gap Buffer’а. В его случае время, вместо C раз, неожиданно увеличивается какое-то непонятное C*L раз, где L — среднее расстояние между каретками. Почему так происходит?
Представим, что нам надо вставить строчку «, на» в два места в нашем документе.
Вот что происходит в редакторе в это время.
Чувствуете, к чему все идет?
Да, получается, что из-за этих многочисленных телодвижений буфера туда-сюда наше общее время увеличивается. Честно говоря, не то чтобы оно прямо ужас как увеличилось, — подвинуть жалкие мега-, гигабайты туда-сюда для современного компьютера не проблема, но всё равно интересно, что эта структура данных в случае мультикареток работает радикально по-другому.
Какие еще есть проблемы в обычном текстовом редакторе? Самая сложная проблема — это скроллинг, то есть перерисовка редактора во время передвигания каретки на следующую строчку.

Когда редактор скроллится, мы должны понять, с какой строчки, с какого символа нам нужно начинать отрисовывать текст в нашем маленьком окошке. Для этого нам нужно быстро понять, какой строчке какое смещение соответствует.
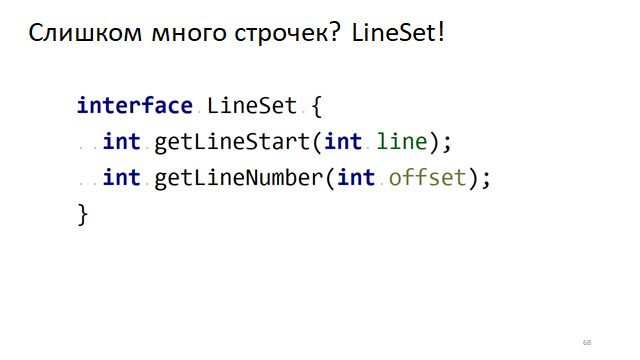
Для этого есть очевидный интерфейс, когда мы по номеру строчки должны понять её смещение в тексте. И наоборот, по смещению в тексте понять, в какой строчке оно находится. Как это можно быстро сделать?
Например, так:
Организовать эти строчки в дерево и каждую вершину этого дерева разметить смещением начала строки и смещением конца строки. И тогда, чтобы по смещению понять, в какой строке оно находится, просто нужно запустить логарифмический поиск в этом дереве и найти его.
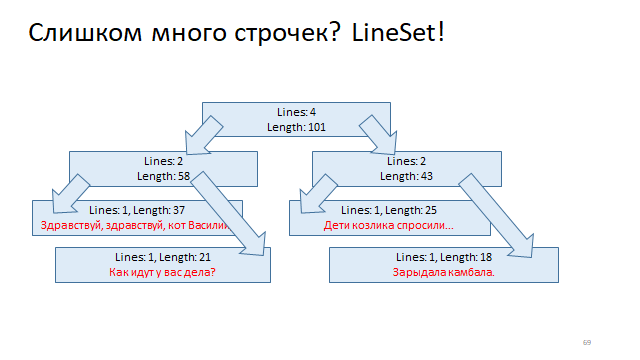
Другой способ ещё проще.
Записать в таблицу смещение начала строчек и конца строчек. И тогда, чтобы по номеру строки найти смещение начала и конца, нужно будет обратиться по индексу.
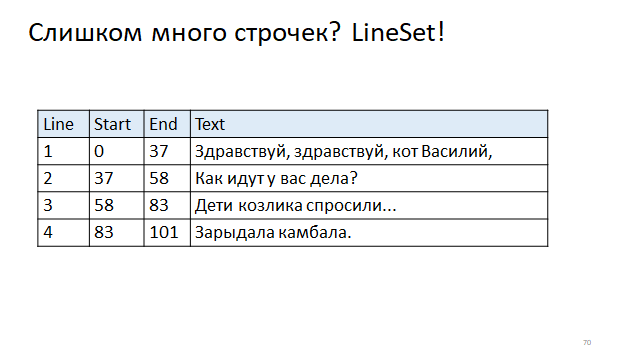
Что интересно, в реальном мире используется и тот, и другой способ.

Например, Eclipse использует такую деревянную структуру, которая, как видно, работает за логарифмическое время и на чтение, и на обновление. А IDEA использует табличную структуру, для которой чтение — это быстрая константа, — это обращение по индексу в таблице, но зато перестроение — довольно медленное, потому что нужно всю таблицу перестроить при изменении длины какой-то строчки.
Что ещё есть плохого, на что натыкаются в текстовых редакторах? Например, фолдинги. Это кусочки текста, которые можно «схлопнуть» и показать вместо них что-то другое.

Вот эти вот многоточия на зелёном фоне на картинке скрывают позади себя много символов, но, если нам их смотреть неинтересно (как в случае, например, длиннейших скучных Java-doc’ов или импорт-листов), мы их скрываем, схлопываем в это самое многоточие.
И тут опять нужно понять, когда заканчивается и когда начинается регион, который нам нужно показать, и как это всё быстро обновлять? Как это организовано, расскажу чуть позже.

Также современные редакторы не могут жить без Soft wrap. На картинке видно, что разработчик открыл JavaScript-файл после минимизации и сразу об этом пожалел. Вот эта огроменнейшая JavaScript-строка, когда мы её пытаемся показать в редакторе, ни в какой экран не влезет. Поэтому soft wrap ее принудительно разрывает на несколько строчек и впихивает в экран.
Как это организовано — позже.

И, наконец, хочется ещё в текстовых редакторах навести красоту. Например, подсветить некоторые слова. На картинке выше ключевые слова подсвечены синим жирным, какие-то static методы италиком, какие-то аннотации — тоже другим цветом.
Так как же все-таки хранить и обрабатывать фолдинги, софт-врапы и хайлайтинги?
Оказывается, что всё это, в принципе, — одна и та же задача.

Чтобы поддержать все эти фичи, всё, что нам нужно уметь — это по данному смещению в тексте прилепить какие-то текстовые атрибуты, например, цвет, шрифт или текст для фолдинга. Причем эти текстовые атрибуты надо всё время обновлять на этом месте, чтобы они переживали всякие вставки и удаления.
Как это обычно реализуется? Естественно, в виде дерева.

Вот, например, у нас тут есть несколько жёлтых подсветок, которые мы хотим сохранить в тексте. Мы складываем интервалы этих хайлайтингов в дерево поиска, так называемое интервальное дерево. Это то же самое дерево поиска, но немного хитрее, потому что нам надо хранить интервалы вместо числа.
А так как есть как здоровые, так и маленькие интервалы, то как их сортировать, друг с другом сравнивать и складывать в дерево — довольно нетривиальная задача. Хотя и очень широко известная в computer science. Посмотрите потом как-нибудь на досуге, как оно устроено. Так вот, берём и складываем все наши интервалы в дерево, и потом каждое изменение текста где-нибудь посередине приводит к логарифмическому изменению этого дерева. Например, вставка символа должна привести в обновлению всех интервалов справа от этого символа. Для этого мы находим все доминантные вершины для этого символа и указываем, что все их подвершины надо отодвинуть на один символ вправо.

Ещё есть такая страшная штуковина — лигатуры, которую тоже бы хотелось поддержать. Это разные красоты вроде того, как знак «!=» рисуется в виде большого глифа «не равно» и так далее. К счастью, тут мы рассчитываем на свинговый механизм поддержки этих лигатур. И, по нашему опыту, он, видимо, работает наипростейшим образом. Внутри шрифта хранится список всех этих пар символов, которые, соединяясь вместе, образуют какую-то хитрую лигатуру. Потом, при отрисовке строчки, Swing просто перебирает все эти пары, находит нужные и рисует их соответствующим образом. Если у вас в шрифте очень много лигатур, то, видимо, отображение его будет пропорционально тормозить.
И самое главное — ещё одна проблема, которая встречается, в современных сложных редакторах — это оптимизация тайпинга, то есть, нажатия на клавиши и отображения результата.

Если залезть внутрь Intellij IDEA и посмотреть, что происходит при нажатии какой-то кнопки, то там происходит, оказывается, следующий ужас:
Ура!
Черт, нет, это не всё. Удалить символ, если наш буфер переполнился. Например, в консоли вызвать listener для того, чтобы все знали, что что-то поменялось. Отскроллить editor view. Вызвать какие-то ещё дурацкие listener’ы.
И что теперь происходит в редакторе, когда он узнал, что документ-то у нас поменялся и вызвался DocumentListener?
В Editor.documentChanged() происходит вот что:
Этот repaint() — это просто указание для Swing, что данный регион на экране должен быть перерисован. Настоящая перерисовка произойдет, когда событие Repaint будет обработано очередью сообщений Swing.
То есть где-то через полчаса подойдет очередь обработки нашего события, вызовется метод repaint у соответствующей компоненты, который будет делать следующее:

Вызывается куча разных paint-методов, которые рисуют всё, что только возможно на свете в этом случае.
Ну что, может, соптимизируем это всё?

Это всё, мягко говоря, довольно сложно. Поэтому мы в Intellij IDEA решили обмануть пользователя.

Перед всякими этими ужасами, которые что-то пересчитывают и что-то записывают, мы вызываем маленький метод, который рисует эту несчастную букву прямо на том месте, куда пользователь её впечатывает. И всё! Пользователь счастлив, потому что он думает, что уже всё поменялось, а на самом-то деле — нет! Под капотом всё ещё только начинается, но буковка-то уже перед ним горит. И поэтому все довольны. Эта фича у нас называется «Zero latency typing».
Сейчас есть такая модная штука — так называемые коллаборативные редакторы.
Что это такое? Это когда один пользователь сидит в Индии, другой — в Японии, они пытаются в один и тот же Google Docs что-то напечатать и хотят какого-то предсказуемого результата.
Что особенного:
Особенность тут такая, что огромное число пользователей это может делать одновременно, и сигнал очень долго может идти из Индии в Японию.
И из-за этого обычно в коллаборативных редакторах используют новомодные вещи вроде иммутабельности. И придумали разные вещи, как убедиться, что всё работает как нужно. Это несколько критериев. Первый критерий — это сохранение интенции, «intention preservation». Это значит, что если кто-то впечатал символ, то рано или поздно символ из Индии приплывёт в Японию, и японец увидит именно то, что задумал индиец. И второй критерий — конвергенция. Это значит, что символы из Индии и Японии рано или поздно преобразуются во что-то одно и то же и для Японии, и для Индии.

Первый алгоритм, который был придуман для поддержки этой штуковины, называется «operation transformation». Он работает так. Сидят индиец и японец, что-то печатают: один удаляет с конца букву, другой пририсовывает букву в начало. Фреймворк Operation transformation посылает эти операции во все другие места. Он должен понять, как нужно смержить операции, приходящие к нему, чтобы получилось хоть что-нибудь здравомыслящее. Например, когда у вас одновременно буква удалилась и появилась. Он должен и там, и там отработать более-менее консистентно и прийти к одной и той же строчке. К сожалению, как видно из моего путаного объяснения, это дело довольно сложное.
Когда стали появляться первые реализации этого фреймворка, изумленные разработчики обнаружили, что есть универсальный пример, который все ломает. Этот злополучный пример назвали «TP2 puzzle».

Один пользователь пририсовывает в начало строчки какие-то символы, другой всё это удаляет, а третий пририсовывает в конец. После того, как это всё Operation transformation пытается слить в одно и то же, то должна, по идее, получиться вот эта строчка («ДАНА»). Однако некоторые имплементации делали вот такую («НАДА»). Потому что непонятно, куда вставлять нужно. На картинке выше видно, на каком уровне находится вся эта наука про Operation transformation, если из-за такого примитивного примера у них всё ломалось.
Но несмотря на это некоторые люди всё равно это делают, вроде Google Docs, Google Wave и какого-то распределённого редактора Etherpad. Они используют Operation transformation несмотря на перечисленные проблемы.
Люди тут пораскинули мозгами и решили: «Давайте сделаем проще, чем OT!» Число всяких хитрых сочетаний операций, которые нужно обрабатывать и сливать вместе, растет квадратично. Поэтому, вместо того, чтобы обрабатывать все сочетания, мы будем просто отправлять своё состояние вместе с операцией всем другим хостам таким образом, чтобы можно было с гарантией 100% это всё слить в один и тот же текст. Это называется «CRDT» (Conflict-free replicated data type).

Чтобы это работало, нужно состояние и функция, которая из двух состояний вместе с операцией делает новое состояние. Причем, эта функция должна быть коммутативной, ассоциативной, идемпотентной и монотонной. И тогда понятно, что всё будет работать просто и железобетонно. Из-за этих драконовских ограничений на функцию нам теперь не страшны нарушения порядка (функция ж коммутативна), приоритета (ассоциативна) и потери пакетов в сети (идемпотентность и монотонность).

Есть ли в природе такие функции и как их можно применить?
Да. Например, для случая так называемых G-counter’ов, то есть счетчиков, которые только растут. Можно написать для этого счетчика функцию, которая действительно будет монотонной и так далее. Потому что если у нас есть операция «+1» из Японии, другая «+1» из Индии, понятно, как из них сделать новое состояние — просто прибавить «2». Но оказывается, что таким же образом можно делать ещё и произвольный счетчик, который можно инкрементировать и декрементировать. Для этого достаточно взять один G-counter, который растёт всё время вверх, и все операции инкремента применять к нему. А все декременты применять к другому G-counterу, который будет расти вниз. Чтобы получить актуальное состояние, нужно просто вычесть их содержимое, и у нас получится та самая монотонность. Это всё возможно распространить на произвольные множества. Но самое главное — на произвольные строки. Да, редактирование произвольных строк тоже можно сделать CRDT. Оказывается, это довольно легко.

Сначала, поименуем все символы в документе, чтобы всегда были однозначно были идентифицируемы, даже после всяких редактирований. Ну, например, вместе с каждой буквой будем хранить уникальное число.
Теперь вместо того, чтобы отправлять всем людям информацию, что мы вставляем по какому-то смещению какой-то символ, мы, вместо этого, будем говорить, между какими именно символами мы будем это вставлять. И тогда понятно, что никаких разночтений быть не может, куда бы мы ни вставляли, мы точно будем знать место, даже после всяких других операций. Вот, например, вместо того, чтобы посылать операцию о том, что мы по смещению 2 мы хотим вставить «РЖУ», мы будем посылать информацию, что между этой «У» и этой «Й» мы вставляем «РЖУ».

Также можно реализовать и удаление символов. Так как у нас все символы уникально переименованы, мы просто говорим точно, какой именно символ нужно удалить, вместо каких-то смещений. Но вместо того, чтобы взять и физически удалить эти символы, мы будем их помечать удалёнными. Для того, чтобы последующие параллельные вставки или удаления знали, если они затронут эти удалённые только что символы, куда именно им обращаться.
И получается, что эта вся новомодная наука работает.
И, на самом деле, CRDT даже где-то реализовано, например, в Xi-Editor, который будет вставлен в их новомодную секретную операционную систему Fuchsia. Честно говоря, других примеров я не знаю, но это точно работает.
Ещё хотел бы рассказать о штуке, которая используется в этом новом иммутабельном мире под названием «Zipper». После того, как мы свои структуры сделали неизменяемыми, появились некоторые нюансы работы с ними. Вот, к примеру, у нас есть наше иммутабельное дерево с текстом. Нам хочется его поменять, (под «поменять» здесь, как вы понимаете, я имею в виду «создать новую версию»). Причем, нам хочется его менять в каком-то определённом месте и довольно активно. В редакторах это довольно часто встречается, когда в месте курсора мы постоянно что-то печатаем, вставляем и удаляем. Для этого функциональщики придумали структуру под названием Zipper.
Она имеет понятие так называемого курсора или текущего места для редактирования, сохраняя при этом полную иммутабельность. Вот как это делается.
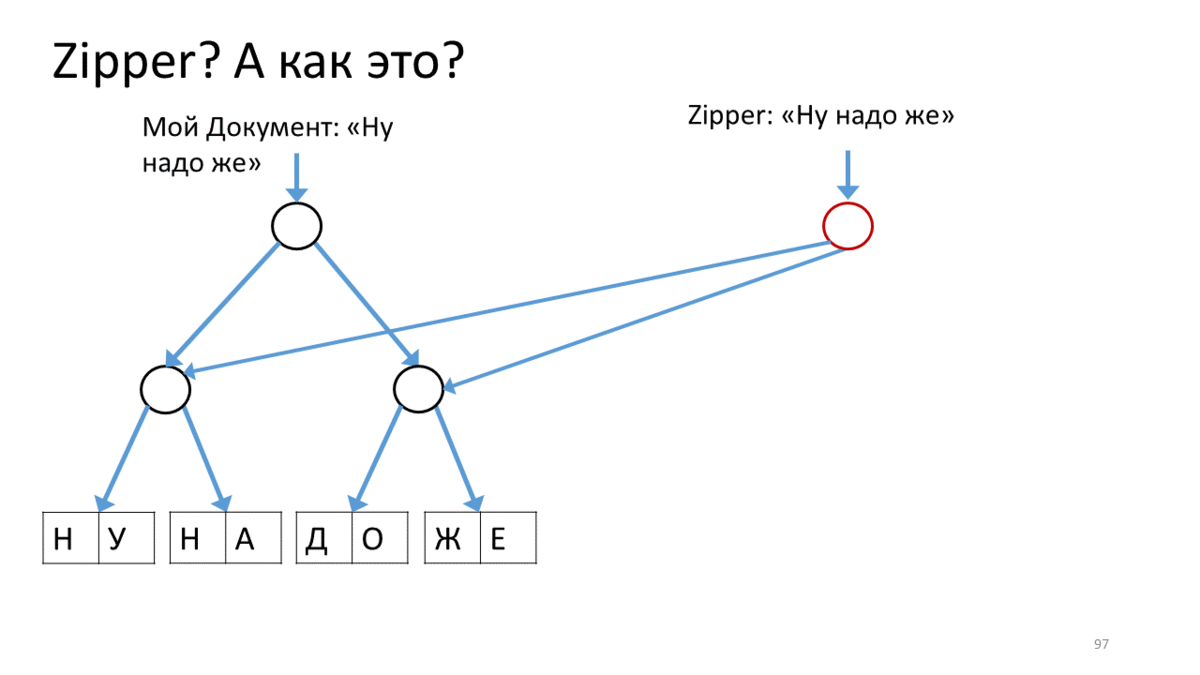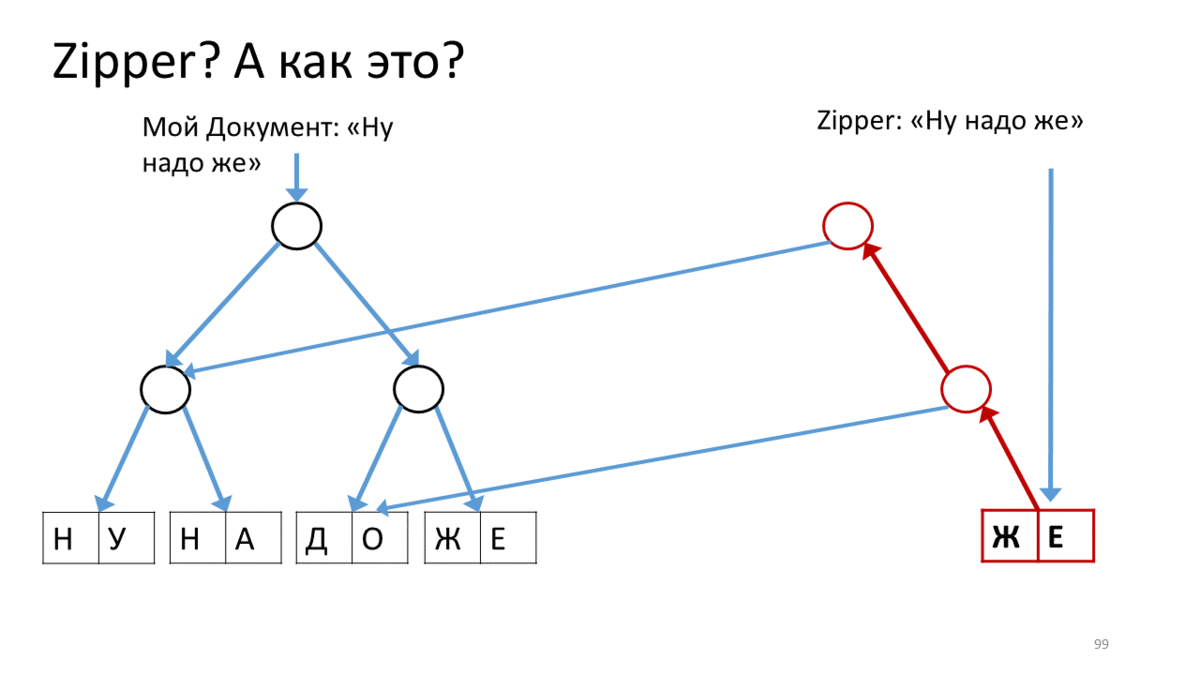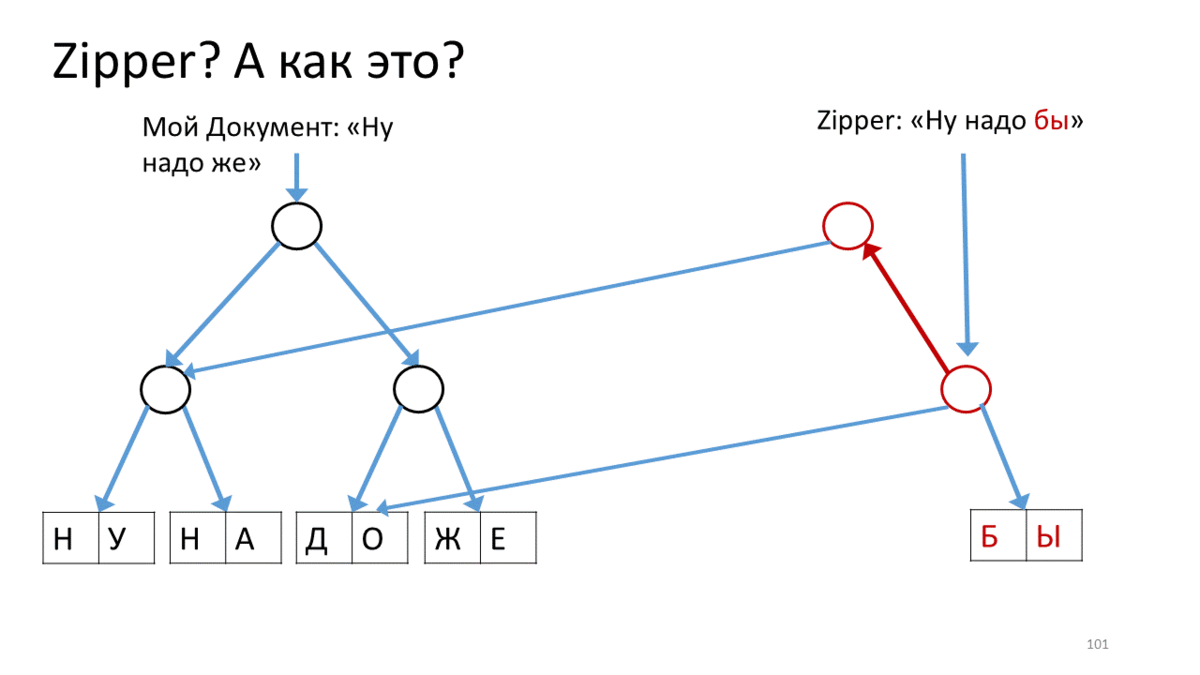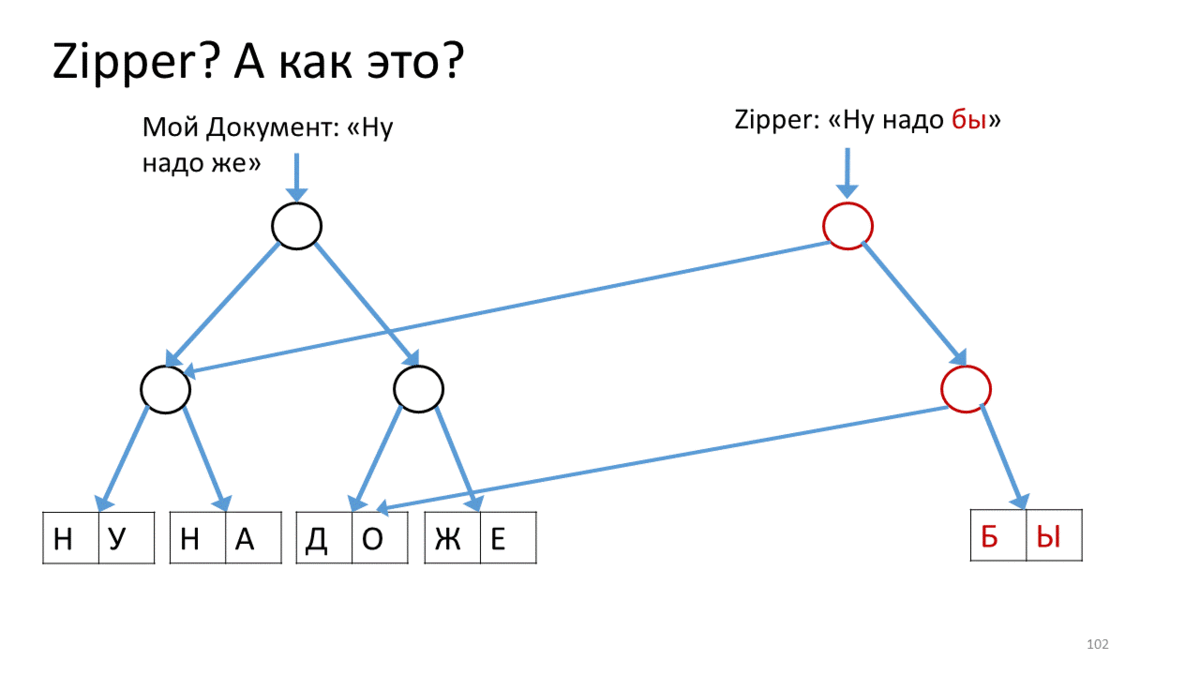
Создаём Zipper для нашего документа, который содержит строку для редактирования («Ну надо же»). Вызываем операцию на этом Zipper’е для перемещения по строке в место редактирования. В нашем случае — спуститься на вершину вправо вниз. Для этого мы создаем новую вершину (красненькую), соответствующую текущей вершине, прикрепляем к ней ссылки на дочерние вершины из нашего дерева. Теперь, чтобы переместить курсор Zipperа, мы спускаемся вправо-вниз и создаем также создаем новую вершину вместо той, на которой стояли. При этом, добавляем ссылку на вершину вверх, чтобы не забыть, откуда пришли (красные стрелки). Дойдя таким образом до места редактирования, мы создаем новый лист взамен поредактированного текста (красный прямоугольник). Теперь возвращаемся назад, идя по красным стрелкам вверх и заменяя их по пути на правильные ссылки на дочерние вершины. Когда дойдем до вершины, у нас получится новое дерево с отредактированным листом.
Обратите внимание, как курсор помогает нам редактировать текущий кусочек дерева.
Какие выводы я хотел до вас донести? Во-первых, как ни странно, в теме текстовых редакторов, несмотря на её затхлость, существуют всякие интересные вещи. Более того, в этой же теме появляются иногда новые, иногда неожиданные открытия. И в-третьих, иногда они настолько новые, что не работают с первого раза. Зато интересно и можно согреться. Спасибо.
→ Репозиторий
→ Почта
Zipper data structure
Как устроен CRDT in Xi Editor
И вообще о древовидных структурах данных для текста
Что наворотили в Атоме
После доклада прошло много времени, и Микрософт успел вспомнить о своих корнях и переписать Visual Studio Code editor на Piece Table.
И вообще, многих людей почему-то потянуло на эксперименты.
В основе статьи — доклад Алексея Кудрявцева с Joker 2017. Алексей уже лет 10 пишет Intellij IDEA в JetBrains. Под катом вы найдете видео и текстовую расшифровку доклада.
Структуры данных внутри текстовых редакторов
Чтобы понять, как устроен редактор, давайте его напишем.
Всё, наш простейший редактор готов.
Внутри редактора текст легче всего хранить в массиве символов, ну или, что то же самое (в смысле организации памяти), в Java-классе StringBuffer. Чтобы получить какой-нибудь символ по смещению, мы вызываем метод StringBuffer.charAt(i). А чтобы вставить в него символ, который мы напечатали на клавиатуре, вызовем метод StringBuffer.insert(), который вставит символ куда-то в середину.
Что самое интересное, несмотря на всю простоту и идиотичность этого редактора, — это самое хорошее представление, которое только можно выдумать. Оно и просто и почти всегда быстро.
К сожалению, с этим редактором возникает проблема масштаба. Представим, что мы напечатали в нём очень много текста и собираемся вставить в середину еще одну букву. Произойдет следующее. Нам срочно нужно освободить для этой буквы какое-то пространство, сдвинув все остальные буквы на один символ вперёд. Для этого мы сдвигаем эту букву на одну позицию, потом следующую и так далее, до самого конца текста.
Вот как это будет выглядеть в памяти:
Сдвигать все эти многочисленные мегабайты не очень хорошо: это медленно. Конечно, для современного компьютера это плёвое дело — какие-то жалкие мегабайты подвигать туда-сюда. Но для очень активного изменения текста это может быть заметно.
Чтобы решить эту проблему вставки символа в середину, давным-давно придумали обходной манёвр под названием «Gap Buffer».
Gap Buffer
Gap — это зазор. Buffer — это, как вы догадываетесь, буфер. Структура данных «Gap Buffer» — это такой пустой буфер, который мы храним посередине нашего текста, на всякий случай. Если нам потребовалось что-то напечатать, мы используем этот текстовый маленький буфер для быстрого впечатывания.
Структура данных у нас немножко поменялась — массив остался на месте, но появились два указателя: на начало буфера и на его конец. Чтобы взять символ из редактора по какому-то смещению, нам нужно понять, находится ли он до или после этого буфера и немножечко подправить смещение. А чтобы вставить символ, нам нужно сначала пододвинуть Gap Buffer к этому месту и заполнить его этими символами. И, конечно, если мы вышли за пределы нашего буфера, его как-то пересоздать. Вот как это выглядит на картинке.
Как видно, мы сначала долго двигаем на маленький gap-buffer (синенький прямоугольник) к месту редактирования (просто меняя местами символы с его левого и правого края по очереди). Потом мы используем этот буфер, впечатывая туда символы.
Как можно заметить, никакого передвижения мегабайт символов нет, вставка происходит очень быстро, за константу времени, и вроде все счастливы. Кажется, всё хорошо, но если у нас процессор очень медленный, то на перемещение туда-сюда gap-buffer и текста тратится довольно заметное время. Особенно это было заметно во времена очень маленьких мегагерц.
Piece Table
Как раз в это время корпорация под названием Microsoft писала текстовый редактор Word. Они решили применить у себя другую идею для ускорения редактирования под названием «Piece Table», то есть «Таблица Кусочков». И они предложили текст редактора сохранять в этом же самом простейшем массиве символов, который меняться не будет, а все его изменения складывать в отдельную таблицу из этих самых отредактированных кусочков.
Таким образом, если нам нужно найти какой-то символ по смещению, нам нужно найти этот кусочек, который мы поредактировали, и извлечь из него этот символ, а если его там нет, то пойти в оригинальный текст. Вставка символа становится легче, нам всего лишь нужно этот новый кусочек создать и добавить в таблицу. Вот как это выглядит на картинке:
Здесь мы захотели удалить пробел по смещению 5. Для этого мы добавляем в таблицу кусочков два новых кусочка: один указывает на первый фрагмент («Облом»), а второй указывает на фрагмент после редактирования («овцы»). Получается, что пробел из них исчезает, эти два кусочка склеиваются, и у нас получается новый текст уже без пробела: «Обломовцы». Потом добавляем новый текст («страдающие обломовщиной») в конец. Используем дополнительный буфер и добавляем в таблицу кусочков (piece table) новый кусочек, который указывает на этот самый новый добавленный текст.
Как видите, никаких перемещений туда-сюда не происходит, весь текст остаётся на месте. Плохо то, что становится сложнее добраться до символа, потому что перебирать все эти куски довольно тяжело.
Подведем итоги.
Что хорошо в Piece Table:
- Быстро вставлять;
- Легко сделать undo;
- Append-only.
Что плохо:
- Ужасно сложно обращаться к документу;
- Ужасно сложно реализовать.
Давайте посмотрим, кто у нас вообще обычно что использует.
NetBeans, Eclipse и Emacs используют Gap Buffer — молодцы! Vi не заморачивается и использует просто список строчек. Word использует Piece Table (недавно они выложили свои древние сорцы и там даже можно что-то понять).
С Atom интереснее. До недавнего времени они не заморачивались и использовали JavaScript-список строчек. А потом решили всё переписать на C++ и наворотили довольно сложную структуру, которая вроде как похожа на Piece Table. Но вот эти кусочки у них хранятся не в списке, а в дереве, причём в так называемом splay tree — это дерево, которое саморегулируется при вставке в него, чтобы недавние вставки были быстрее. Очень сложную штуку они наворотили.
Что использует Intellij IDEA?
Нет, не gap-buffer. Нет, вы тоже не правы, не piece table.
Да, совершенно верно, свой собственный велосипед.
Дело в том, что у IDE требования к хранению текста немного другие, нежели в обычном текстовом редакторе. Для IDE нужна поддержка разных хитрых вещей вроде конкуррентности, то есть параллельного доступа к тексту из редактора. Например, чтобы много разных испекшенов могли его читать и что-то делать. (Инспекшн — маленький кусочек кода, анализирующий программу тем или иным образом, — например, ищущий места, выбрасывающие NullPointerException). Также для IDE нужна поддержка версий редактируемого текста. Несколько версий одновременно лежат в памяти, пока вы работаете с документом, с тем, чтобы эти долгие процессы продолжали анализировать старую версию.
Проблемы
Конкуррентность / Версионность
Для того, чтобы поддержать параллельность, операции с текстом обычно оборачивают в «synchronized», или в Read-/Write-локи. К сожалению, это всё не очень хорошо масштабируется. Другой подход — Immutable Text, то есть неизменяемое хранилище текста.
Вот как выглядит редактор с неизменяемым документом в качестве поддерживающей структуры данных.
Как устроена сама структура данных?
Вместо массива символов у нас будет новый объект типа ImmutableText, хранящий текст в виде дерева, где в листах хранятся маленькие подстрочки. При обращении по какому-то смещению он пытается в этом дереве дойти до самого нижнего листа, и у него уже спросить символ, к которому мы обращались. А при вставке текста он создает новое дерево и сохраняет его в старом месте.
К примеру, у нас есть документ с текстом «Бескалорийный». Он реализован как дерево с двумя листами из подстрочек «Бес» и «калорийный». Когда мы хотим вставить в середину строчку «довольно», то создается новая версия нашего документа. И именно, создается новый корень, к которому привязываются уже три листа: «Бес», «довольно» и «калорийный». Причём два из этих новых листов могут ссылаться на первую версию нашего документа. А для листа, в который мы вставили строчку «довольно», отводится новая вершина. Тут и первая версия, и вторая версии доступны одновременно и они все иммутабельные, неизменяемые. Всё выглядит хорошо.
Кто же использует какие хитрые структуры?
Вот, например, в GNOME какой-то их стандартный виджет использует структуру под названием Rope. Xi-Editor — это новый блестящий редактор от Рафа Левиена — использует Persistent Rope. А Intellij IDEA использует этот самый Immutable Tree. За этими всеми названиями, на самом деле, скрывается более-менее одна и та же структура данных с древовидным представлением текста. За исключением того, что GtkTextBuffer использует Mutable Rope, то есть дерево с изменяемыми вершинами, а Intellij IDEA и Xi-Editor — Immutable.
Следующая вещь, которую нужно учитывать при разработке хранилища символов в современных IDE, называется «мультикаретки». Эта фича позволяет печатать сразу в несколько мест, используя несколько кареток.
Мы можем что-то печатать и одновременно в нескольких местах документа у нас вставляется то, что мы туда напечатали. Если мы посмотрим, как наши структуры данных, которые мы рассмотрели, реагируют на мультикаретки, мы увидим кое-что интересное.
Если мы вставляем символ в наш самый первый примитивный редактор, для этого потребуется, естественно, линейное количество времени, чтобы сдвинуть туда-сюда кучу символов. Это записывается в виде O(N). Для редактора на основе Gap Buffer’а, в свою очередь, требуется уже константное время, для этого он и был придуман.
Для immutable-дерева время зависит логарифмически от размера, потому что надо сначала пройти от вершины дерева до его листа — это логарифм, а потом для всех вершин на пути создать новые вершины для нового дерева — это опять логарифм. Для Piece Table тоже требуется константа.
Но все немножко меняется, если мы попробуем померять время вставки символа в редактор с мульти-каретками, то есть, вставки одновременно в несколько мест. С первого взгляда, время вроде как должно пропорционально увеличиться в C раз — число мест, куда вставляется символ. Всё так и происходит, за исключением Gap Buffer’а. В его случае время, вместо C раз, неожиданно увеличивается какое-то непонятное C*L раз, где L — среднее расстояние между каретками. Почему так происходит?
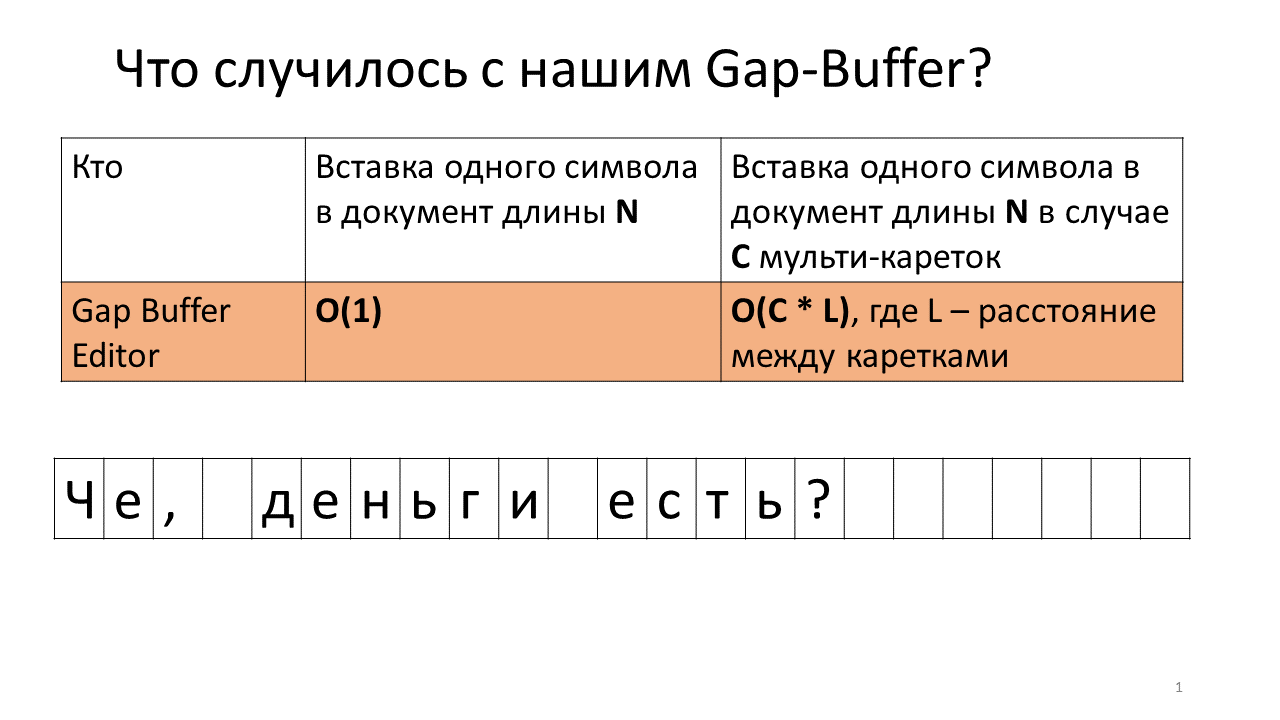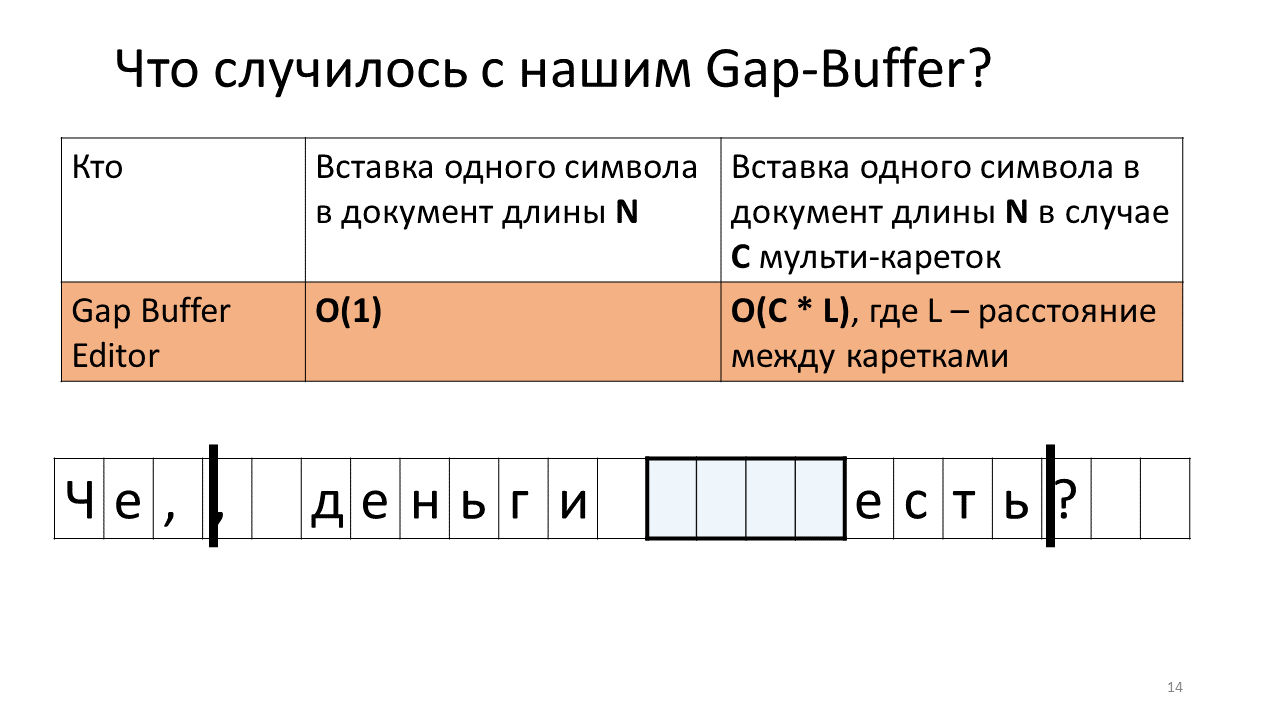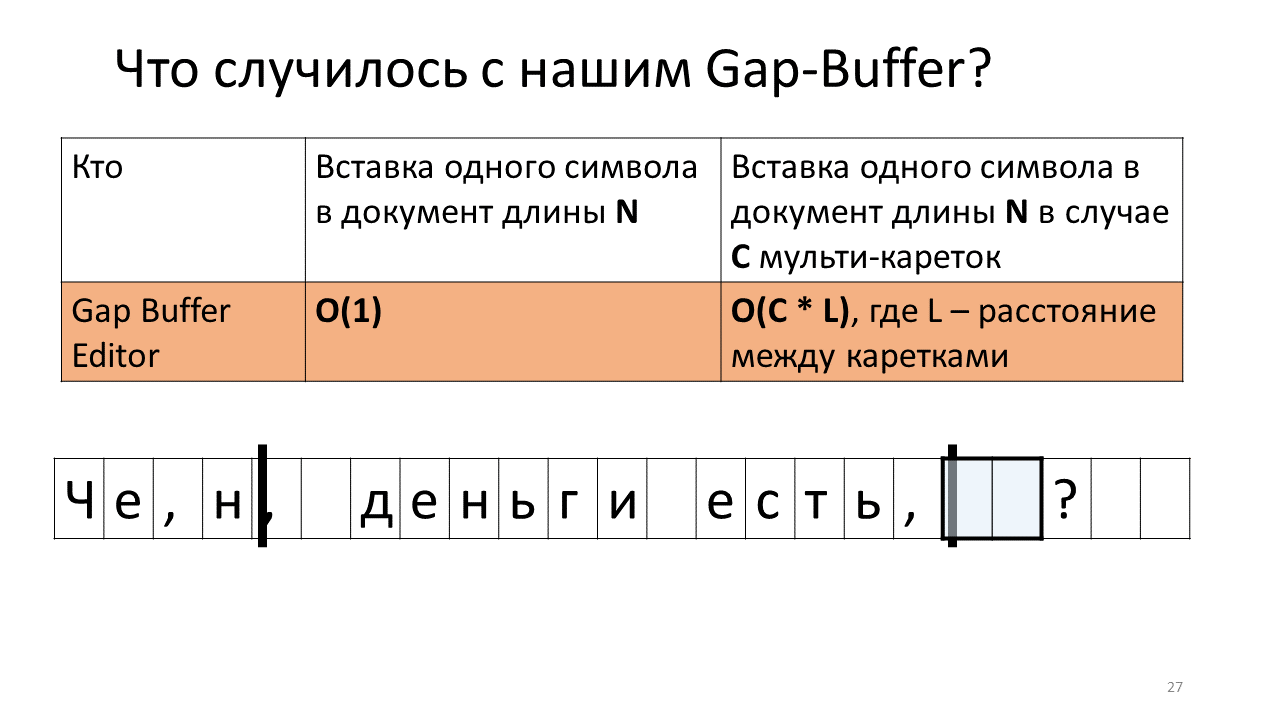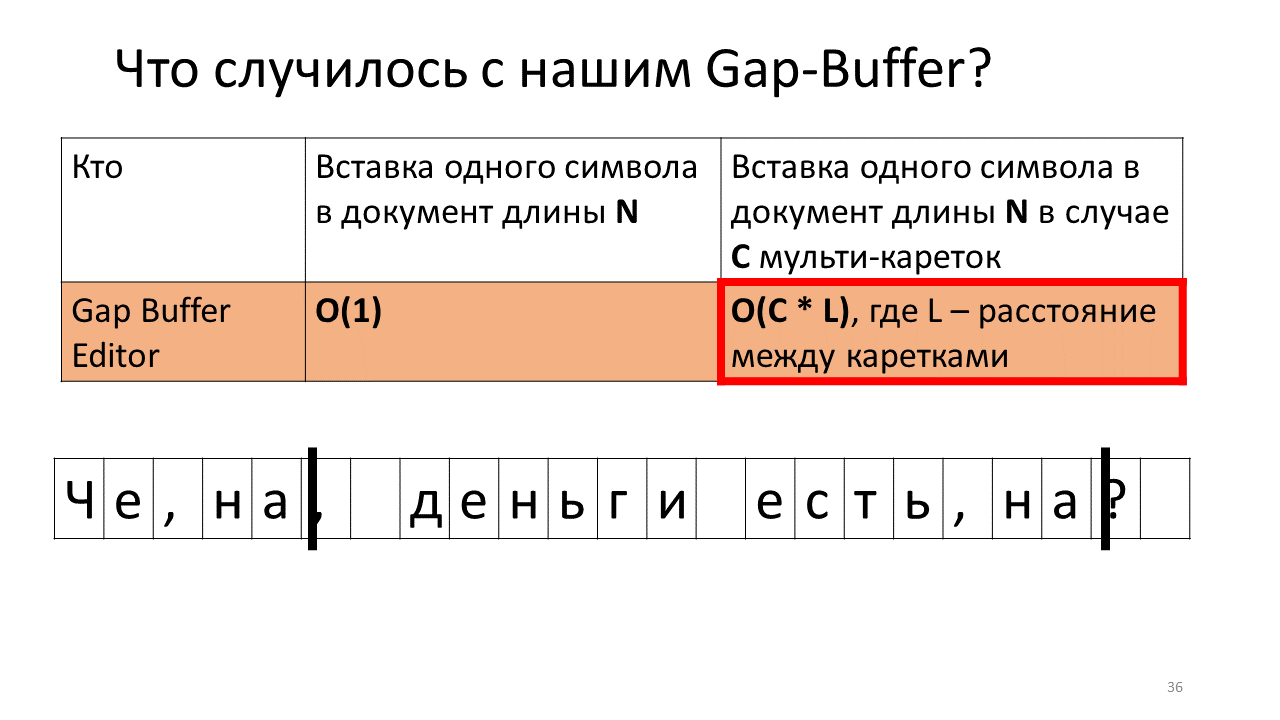
Представим, что нам надо вставить строчку «, на» в два места в нашем документе.
Вот что происходит в редакторе в это время.
- Создаем в редакторе gap-buffer (синенький прямоугольничек на рисунке);
- Заводим две каретки (черные жирные вертикальные черты);
- Пробуем печатать;
- Вставляем запятую в наш Gap Buffer;
- Должны теперь вставить её в место второй каретки;
- Для этого нам нужно пододвинуть наш Gap Buffer до положения следующей каретки;
- Впечатываем запятую во второе место;
- Теперь нужно вставить следующий символ в положение первой каретки;
- И мы должны пододвинуть наш Gap Buffer обратно;
- Вставляем букву «н»;
- И двигаем наш многострадальный буфер в место второй каретки;
- Вставляем туда нашу «н»;
- Двигаем буфер обратно, чтобы вставить следующий символ.
Чувствуете, к чему все идет?
Да, получается, что из-за этих многочисленных телодвижений буфера туда-сюда наше общее время увеличивается. Честно говоря, не то чтобы оно прямо ужас как увеличилось, — подвинуть жалкие мега-, гигабайты туда-сюда для современного компьютера не проблема, но всё равно интересно, что эта структура данных в случае мультикареток работает радикально по-другому.
Слишком много строчек? LineSet!
Какие еще есть проблемы в обычном текстовом редакторе? Самая сложная проблема — это скроллинг, то есть перерисовка редактора во время передвигания каретки на следующую строчку.
Когда редактор скроллится, мы должны понять, с какой строчки, с какого символа нам нужно начинать отрисовывать текст в нашем маленьком окошке. Для этого нам нужно быстро понять, какой строчке какое смещение соответствует.
Для этого есть очевидный интерфейс, когда мы по номеру строчки должны понять её смещение в тексте. И наоборот, по смещению в тексте понять, в какой строчке оно находится. Как это можно быстро сделать?
Например, так:
Организовать эти строчки в дерево и каждую вершину этого дерева разметить смещением начала строки и смещением конца строки. И тогда, чтобы по смещению понять, в какой строке оно находится, просто нужно запустить логарифмический поиск в этом дереве и найти его.
Другой способ ещё проще.
Записать в таблицу смещение начала строчек и конца строчек. И тогда, чтобы по номеру строки найти смещение начала и конца, нужно будет обратиться по индексу.
Что интересно, в реальном мире используется и тот, и другой способ.
Например, Eclipse использует такую деревянную структуру, которая, как видно, работает за логарифмическое время и на чтение, и на обновление. А IDEA использует табличную структуру, для которой чтение — это быстрая константа, — это обращение по индексу в таблице, но зато перестроение — довольно медленное, потому что нужно всю таблицу перестроить при изменении длины какой-то строчки.
Всё ещё слишком много строчек? Foldings!
Что ещё есть плохого, на что натыкаются в текстовых редакторах? Например, фолдинги. Это кусочки текста, которые можно «схлопнуть» и показать вместо них что-то другое.
Вот эти вот многоточия на зелёном фоне на картинке скрывают позади себя много символов, но, если нам их смотреть неинтересно (как в случае, например, длиннейших скучных Java-doc’ов или импорт-листов), мы их скрываем, схлопываем в это самое многоточие.
И тут опять нужно понять, когда заканчивается и когда начинается регион, который нам нужно показать, и как это всё быстро обновлять? Как это организовано, расскажу чуть позже.
Слишком длинные строчки? Soft wrap!
Также современные редакторы не могут жить без Soft wrap. На картинке видно, что разработчик открыл JavaScript-файл после минимизации и сразу об этом пожалел. Вот эта огроменнейшая JavaScript-строка, когда мы её пытаемся показать в редакторе, ни в какой экран не влезет. Поэтому soft wrap ее принудительно разрывает на несколько строчек и впихивает в экран.
Как это организовано — позже.
Слишком мало красоты
И, наконец, хочется ещё в текстовых редакторах навести красоту. Например, подсветить некоторые слова. На картинке выше ключевые слова подсвечены синим жирным, какие-то static методы италиком, какие-то аннотации — тоже другим цветом.
Так как же все-таки хранить и обрабатывать фолдинги, софт-врапы и хайлайтинги?
Оказывается, что всё это, в принципе, — одна и та же задача.
Слишком мало красоты? Range highlighters!
Чтобы поддержать все эти фичи, всё, что нам нужно уметь — это по данному смещению в тексте прилепить какие-то текстовые атрибуты, например, цвет, шрифт или текст для фолдинга. Причем эти текстовые атрибуты надо всё время обновлять на этом месте, чтобы они переживали всякие вставки и удаления.
Как это обычно реализуется? Естественно, в виде дерева.
Проблема: слишком много красоты? Interval tree!
Вот, например, у нас тут есть несколько жёлтых подсветок, которые мы хотим сохранить в тексте. Мы складываем интервалы этих хайлайтингов в дерево поиска, так называемое интервальное дерево. Это то же самое дерево поиска, но немного хитрее, потому что нам надо хранить интервалы вместо числа.
А так как есть как здоровые, так и маленькие интервалы, то как их сортировать, друг с другом сравнивать и складывать в дерево — довольно нетривиальная задача. Хотя и очень широко известная в computer science. Посмотрите потом как-нибудь на досуге, как оно устроено. Так вот, берём и складываем все наши интервалы в дерево, и потом каждое изменение текста где-нибудь посередине приводит к логарифмическому изменению этого дерева. Например, вставка символа должна привести в обновлению всех интервалов справа от этого символа. Для этого мы находим все доминантные вершины для этого символа и указываем, что все их подвершины надо отодвинуть на один символ вправо.
Ещё хочется красоты? Ligatures!
Ещё есть такая страшная штуковина — лигатуры, которую тоже бы хотелось поддержать. Это разные красоты вроде того, как знак «!=» рисуется в виде большого глифа «не равно» и так далее. К счастью, тут мы рассчитываем на свинговый механизм поддержки этих лигатур. И, по нашему опыту, он, видимо, работает наипростейшим образом. Внутри шрифта хранится список всех этих пар символов, которые, соединяясь вместе, образуют какую-то хитрую лигатуру. Потом, при отрисовке строчки, Swing просто перебирает все эти пары, находит нужные и рисует их соответствующим образом. Если у вас в шрифте очень много лигатур, то, видимо, отображение его будет пропорционально тормозить.
Тормозит тайпинг
И самое главное — ещё одна проблема, которая встречается, в современных сложных редакторах — это оптимизация тайпинга, то есть, нажатия на клавиши и отображения результата.
Если залезть внутрь Intellij IDEA и посмотреть, что происходит при нажатии какой-то кнопки, то там происходит, оказывается, следующий ужас:
- При нажатии кнопки мы должны посмотреть, не находимся ли мы в completion popup’е, чтобы закрыть меню для completion’а, если мы, например, впечатываем какой-нибудь «Enter».
- Нужно посмотреть, находится ли файл под какой-то хитрой системой контроля версий, вроде Perforce, которая должна сделать какие-то действия для начала редактирования.
- Проверить, есть ли какой-то специальный регион в документе, в котором нельзя печатать, вроде каких-нибудь автогенерированных текстов.
- Если документ заблокирован операцией, которая не закончилась, нужно завершить форматирование, и только потом продолжить.
- Найти injected-документ, если он имеется в этом месте, потому что язык в нём будет другой, нужно совсем по-другому всё впечатывать.
- Вызвать у всех плагинов auto popup handler, чтобы они могли впечатать, например, закрывающую и открывающую кавычку в нужном месте.
- Для параметров info обновить окошечко, чтобы оно показывало нужные параметры, если мы туда переместились. У этих плагинов вызвать selection remove, чтобы они удалили selection нужным образом, зависящим от языка. И убрать этот selection физически, удалив его из документа.
- Выбрать у всех плагинов typed handler, чтобы они обработали нужный символ для того, чтобы напечатать скобку поверх другой скобки.
- Закрывающую структурную скобку обработать.
- Запустить undo, подсчитать virtual space’ы и запустить write action.
- Наконец, вставить символ в наш документ.
Ура!
Черт, нет, это не всё. Удалить символ, если наш буфер переполнился. Например, в консоли вызвать listener для того, чтобы все знали, что что-то поменялось. Отскроллить editor view. Вызвать какие-то ещё дурацкие listener’ы.
И что теперь происходит в редакторе, когда он узнал, что документ-то у нас поменялся и вызвался DocumentListener?
В Editor.documentChanged() происходит вот что:
- Обновить error stripe;
- Пересчитать gutter size, перерисовать;
- Пересчитать editor component size, послать эвенты при изменении;
- Подсчитать измененные строки и их координаты;
- пересчитать soft wrap, если изменение его затронуло;
- Вызвать repaint().
Этот repaint() — это просто указание для Swing, что данный регион на экране должен быть перерисован. Настоящая перерисовка произойдет, когда событие Repaint будет обработано очередью сообщений Swing.
То есть где-то через полчаса подойдет очередь обработки нашего события, вызовется метод repaint у соответствующей компоненты, который будет делать следующее:
Вызывается куча разных paint-методов, которые рисуют всё, что только возможно на свете в этом случае.
Ну что, может, соптимизируем это всё?
Это всё, мягко говоря, довольно сложно. Поэтому мы в Intellij IDEA решили обмануть пользователя.
Перед всякими этими ужасами, которые что-то пересчитывают и что-то записывают, мы вызываем маленький метод, который рисует эту несчастную букву прямо на том месте, куда пользователь её впечатывает. И всё! Пользователь счастлив, потому что он думает, что уже всё поменялось, а на самом-то деле — нет! Под капотом всё ещё только начинается, но буковка-то уже перед ним горит. И поэтому все довольны. Эта фича у нас называется «Zero latency typing».
Коллаборативные редакторы
Сейчас есть такая модная штука — так называемые коллаборативные редакторы.
Что это такое? Это когда один пользователь сидит в Индии, другой — в Японии, они пытаются в один и тот же Google Docs что-то напечатать и хотят какого-то предсказуемого результата.
Что особенного:
- Тысячи пользователей;
- Большая задержка.
Особенность тут такая, что огромное число пользователей это может делать одновременно, и сигнал очень долго может идти из Индии в Японию.
И из-за этого обычно в коллаборативных редакторах используют новомодные вещи вроде иммутабельности. И придумали разные вещи, как убедиться, что всё работает как нужно. Это несколько критериев. Первый критерий — это сохранение интенции, «intention preservation». Это значит, что если кто-то впечатал символ, то рано или поздно символ из Индии приплывёт в Японию, и японец увидит именно то, что задумал индиец. И второй критерий — конвергенция. Это значит, что символы из Индии и Японии рано или поздно преобразуются во что-то одно и то же и для Японии, и для Индии.
Operation transformation
Первый алгоритм, который был придуман для поддержки этой штуковины, называется «operation transformation». Он работает так. Сидят индиец и японец, что-то печатают: один удаляет с конца букву, другой пририсовывает букву в начало. Фреймворк Operation transformation посылает эти операции во все другие места. Он должен понять, как нужно смержить операции, приходящие к нему, чтобы получилось хоть что-нибудь здравомыслящее. Например, когда у вас одновременно буква удалилась и появилась. Он должен и там, и там отработать более-менее консистентно и прийти к одной и той же строчке. К сожалению, как видно из моего путаного объяснения, это дело довольно сложное.
Когда стали появляться первые реализации этого фреймворка, изумленные разработчики обнаружили, что есть универсальный пример, который все ломает. Этот злополучный пример назвали «TP2 puzzle».
Один пользователь пририсовывает в начало строчки какие-то символы, другой всё это удаляет, а третий пририсовывает в конец. После того, как это всё Operation transformation пытается слить в одно и то же, то должна, по идее, получиться вот эта строчка («ДАНА»). Однако некоторые имплементации делали вот такую («НАДА»). Потому что непонятно, куда вставлять нужно. На картинке выше видно, на каком уровне находится вся эта наука про Operation transformation, если из-за такого примитивного примера у них всё ломалось.
Но несмотря на это некоторые люди всё равно это делают, вроде Google Docs, Google Wave и какого-то распределённого редактора Etherpad. Они используют Operation transformation несмотря на перечисленные проблемы.
Conflict-free replicated data type
Люди тут пораскинули мозгами и решили: «Давайте сделаем проще, чем OT!» Число всяких хитрых сочетаний операций, которые нужно обрабатывать и сливать вместе, растет квадратично. Поэтому, вместо того, чтобы обрабатывать все сочетания, мы будем просто отправлять своё состояние вместе с операцией всем другим хостам таким образом, чтобы можно было с гарантией 100% это всё слить в один и тот же текст. Это называется «CRDT» (Conflict-free replicated data type).
Чтобы это работало, нужно состояние и функция, которая из двух состояний вместе с операцией делает новое состояние. Причем, эта функция должна быть коммутативной, ассоциативной, идемпотентной и монотонной. И тогда понятно, что всё будет работать просто и железобетонно. Из-за этих драконовских ограничений на функцию нам теперь не страшны нарушения порядка (функция ж коммутативна), приоритета (ассоциативна) и потери пакетов в сети (идемпотентность и монотонность).
Есть ли в природе такие функции и как их можно применить?
Да. Например, для случая так называемых G-counter’ов, то есть счетчиков, которые только растут. Можно написать для этого счетчика функцию, которая действительно будет монотонной и так далее. Потому что если у нас есть операция «+1» из Японии, другая «+1» из Индии, понятно, как из них сделать новое состояние — просто прибавить «2». Но оказывается, что таким же образом можно делать ещё и произвольный счетчик, который можно инкрементировать и декрементировать. Для этого достаточно взять один G-counter, который растёт всё время вверх, и все операции инкремента применять к нему. А все декременты применять к другому G-counterу, который будет расти вниз. Чтобы получить актуальное состояние, нужно просто вычесть их содержимое, и у нас получится та самая монотонность. Это всё возможно распространить на произвольные множества. Но самое главное — на произвольные строки. Да, редактирование произвольных строк тоже можно сделать CRDT. Оказывается, это довольно легко.
Conflict-free replicated inserts
Сначала, поименуем все символы в документе, чтобы всегда были однозначно были идентифицируемы, даже после всяких редактирований. Ну, например, вместе с каждой буквой будем хранить уникальное число.
Теперь вместо того, чтобы отправлять всем людям информацию, что мы вставляем по какому-то смещению какой-то символ, мы, вместо этого, будем говорить, между какими именно символами мы будем это вставлять. И тогда понятно, что никаких разночтений быть не может, куда бы мы ни вставляли, мы точно будем знать место, даже после всяких других операций. Вот, например, вместо того, чтобы посылать операцию о том, что мы по смещению 2 мы хотим вставить «РЖУ», мы будем посылать информацию, что между этой «У» и этой «Й» мы вставляем «РЖУ».
Conflict-free replicated deletes
Также можно реализовать и удаление символов. Так как у нас все символы уникально переименованы, мы просто говорим точно, какой именно символ нужно удалить, вместо каких-то смещений. Но вместо того, чтобы взять и физически удалить эти символы, мы будем их помечать удалёнными. Для того, чтобы последующие параллельные вставки или удаления знали, если они затронут эти удалённые только что символы, куда именно им обращаться.
И получается, что эта вся новомодная наука работает.
Conflict-free replicated edits
И, на самом деле, CRDT даже где-то реализовано, например, в Xi-Editor, который будет вставлен в их новомодную секретную операционную систему Fuchsia. Честно говоря, других примеров я не знаю, но это точно работает.
Zipper
Ещё хотел бы рассказать о штуке, которая используется в этом новом иммутабельном мире под названием «Zipper». После того, как мы свои структуры сделали неизменяемыми, появились некоторые нюансы работы с ними. Вот, к примеру, у нас есть наше иммутабельное дерево с текстом. Нам хочется его поменять, (под «поменять» здесь, как вы понимаете, я имею в виду «создать новую версию»). Причем, нам хочется его менять в каком-то определённом месте и довольно активно. В редакторах это довольно часто встречается, когда в месте курсора мы постоянно что-то печатаем, вставляем и удаляем. Для этого функциональщики придумали структуру под названием Zipper.
Она имеет понятие так называемого курсора или текущего места для редактирования, сохраняя при этом полную иммутабельность. Вот как это делается.
Создаём Zipper для нашего документа, который содержит строку для редактирования («Ну надо же»). Вызываем операцию на этом Zipper’е для перемещения по строке в место редактирования. В нашем случае — спуститься на вершину вправо вниз. Для этого мы создаем новую вершину (красненькую), соответствующую текущей вершине, прикрепляем к ней ссылки на дочерние вершины из нашего дерева. Теперь, чтобы переместить курсор Zipperа, мы спускаемся вправо-вниз и создаем также создаем новую вершину вместо той, на которой стояли. При этом, добавляем ссылку на вершину вверх, чтобы не забыть, откуда пришли (красные стрелки). Дойдя таким образом до места редактирования, мы создаем новый лист взамен поредактированного текста (красный прямоугольник). Теперь возвращаемся назад, идя по красным стрелкам вверх и заменяя их по пути на правильные ссылки на дочерние вершины. Когда дойдем до вершины, у нас получится новое дерево с отредактированным листом.
Обратите внимание, как курсор помогает нам редактировать текущий кусочек дерева.
Какие выводы я хотел до вас донести? Во-первых, как ни странно, в теме текстовых редакторов, несмотря на её затхлость, существуют всякие интересные вещи. Более того, в этой же теме появляются иногда новые, иногда неожиданные открытия. И в-третьих, иногда они настолько новые, что не работают с первого раза. Зато интересно и можно согреться. Спасибо.
→ Репозиторий
→ Почта
Ссылки
Zipper data structure
Как устроен CRDT in Xi Editor
И вообще о древовидных структурах данных для текста
Что наворотили в Атоме
После доклада прошло много времени, и Микрософт успел вспомнить о своих корнях и переписать Visual Studio Code editor на Piece Table.
И вообще, многих людей почему-то потянуло на эксперименты.
Хотите ещё больше мощных докладов, в том числе и о Java 11? Тогда ждём вас на Joker 2018. В этом году выступят: Джош Лонг, Джон МакКлин, Маркус Хирт, Роберт Шольте и другие не менее крутые спикеры. До конференции осталось 17 дней. Билеты на сайте.
