
Ссылка на часть 1: навигация и получение данных
Ссылка на часть 3: деревья специальных возможностей и рендеринга
Примечание переводчиков: статья предназначена для начинающих разработчиков и интересующихся разработкой. Здесь нет глубоких технических деталей, хотя, возможно, вы найдете что-то новое для себя.
В прошлой статье мы обсудили навигацию и получение данных. Сегодня поговорим о HTML- и CSS-парсинге и выполнении JavaScript.
Содержание:
1. HTML-Парсинг
Мы видели, как после первоначального запроса к серверу браузер получает ответ c HTML-ресурсами страницы, к которой мы пытаемся получить доступ. Это первая порция данных. Теперь задача браузера – начать парсинг данных.
Парсинг
?Анализ и преобразование программы во внутренний формат, который может запустить среда выполнения.
Другими словами, это получение HTML/CSS-кода и преобразование его в то, с чем браузер может работать. Парсинг выполняется движком браузера (не путать с движком JavaScript).
Браузерные движки
Движок браузера — основной компонент каждого крупного браузера. Его основная роль — объединить структуру (HTML) и стиль (CSS), чтобы отобразить страницу на экране. Он также отвечает за выяснение того, какие фрагменты кода интерактивны. Не думайте о нем как об отдельном ПО. Скорее, это часть более крупного ПО — в нашем случае, браузера.
В мире много таких движков. Но у большинства браузеров один из трех полных, над которыми идет активная работа:
Gecko. Разработан компанией Mozilla для браузера Firefox. Кроме него, сейчас движок Gecko используют ещё в Tor и Waterfox. Написан на C++ и Rust.
WebKit. В основном его разработала компания Apple для Safari. На нем также работают браузеры GNOME Web (Epiphany) и Otter. Интересно, что все браузеры на iOS, включая Firefox и Chrome, работают на WebKit. Он написан на C++.
Blink, часть Chromium. Разрабатывает компания Google на основе кода WebKit для браузера Chrome. На нем также работают браузеры Edge, Brave, Silk, Vivaldi, Opera и большинство других проектов браузеров, некоторые через QtWebEngine. Написан на C++.
С этим понятно. Теперь посмотрим, что произойдет после получения первого HTML-документа с сервера. Предположим, документ выглядит так:
<!doctype HTML>
<html>
<head>
<title>This is my page</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<h1>This is my page</h1>
<h3>This is a H3 header.</h3>
<p>This is a paragraph.</p>
<p>This is another paragraph,</p>
</body>
</html>Даже если HTML-код страницы запроса больше исходного пакета 14 КБ, браузер начнет парсинг и попытается отобразить результат на основе имеющихся данных.
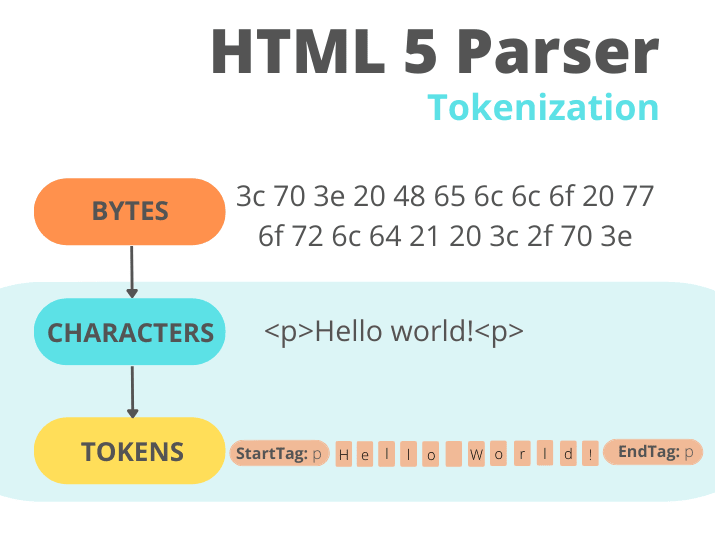
HTML-парсинг включает два этапа: токенизацию и построение DOM-дерева. Document Object Model – объектная модель документа.
Токенизация
?Лексический анализ, который преобразует некоторые входные данные в токены — базовые компоненты исходного кода. Представьте, что английский текст разделяется на слова. В этом примере слова будут токенами.
В результате токенизации получается серия из нуля или более следующих токенов: DOCTYPE, начальный тег (<tag>), конечный тег (</tag>), самозакрывающийся тег (<tag/>), имена атрибутов, значения, комментарии, символы, конец файла или текстовое содержимое элемента.
Построение DOM
После создания первого токена начинается создание древовидной структуры (объектной модели документа) на основе ранее проанализированных токенов.
?DOM-дерево описывает содержимое документа HTML. Элемент <html> — первый тег и корневой узел дерева документа. Дерево отражает отношения и иерархии между различными тегами.
Теги делятся на родительские узлы и дочерние — теги, вложенные в другие теги. Чем больше узлов, тем больше времени потребуется для построения DOM-дерева. Ниже показано DOM-дерево для примера HTML-документа, полученного с сервера:
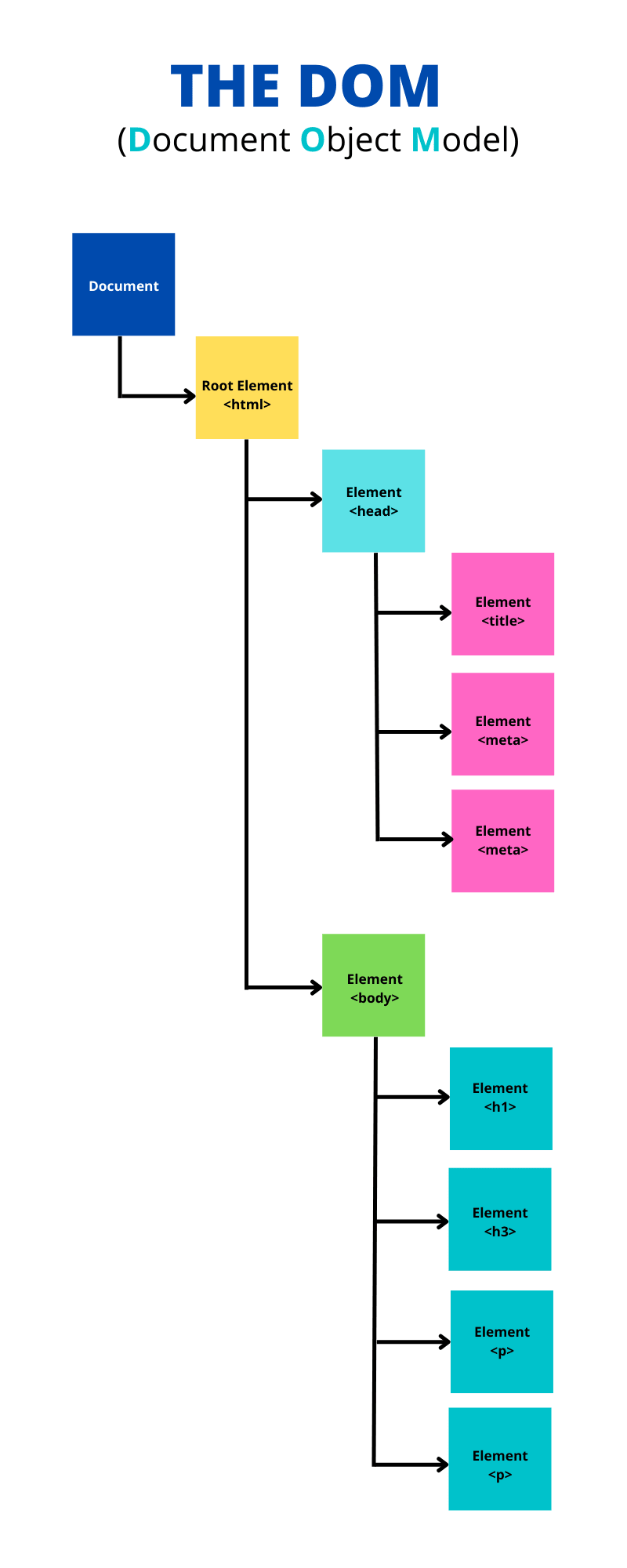
Это упрощенная схема, и в реальности DOM сложнее. О его важности мы поговорим чуть позже.
Данная стадия построения многозадачная. Пока один токен обрабатывается, токенизатор продолжает работу над следующими. От байтов до создания DOM процесс выглядит примерно так:
?
?
?

Парсер обрабатывает строку за строкой сверху вниз. Когда он наталкивается на неблокирующие ресурсы (например, изображения), браузер запрашивает их с сервера и продолжает парсинг. Если наталкивается на блокирующие, останавливает выполнение, пока они все не загрузятся. Это могут быть таблицы стилей CSS, файлы JavaScript, добавленные в раздел <head> HTML, или шрифты, добавленные из CDN. Поэтому если работаете с JavaScript, рекомендуется добавить теги <script> в конце HTML-файла или, если хотите сохранить их в теге <head>, добавьте к ним атрибут defer или async. async разрешает асинхронность сразу после загрузки скрипта, а defer разрешает выполнение только после анализа всего документа.
Предварительные загрузчики и ускорение страницы
В браузерах Internet Explorer, WebKit и Mozilla предварительные загрузчики появились в 2008 году как способ работы с блокирующими ресурсами, особенно скриптами. Выше мы разобрали, что при столкновении с тегом скрипта HTML-парсинг прекращается, пока не загрузится и не запустится скрипт.
С предварительным загрузчиком схема выглядит так: когда браузер застревает на скрипте, второй более легкий парсер сканирует HTML на необходимые ресурсы — таблицы стилей, скрипты и т.д. Затем предварительный загрузчик извлекает ресурсы в фоновом режиме, чтобы к моменту, когда основной HTML-парсер достигнет их, их уже можно было загрузить. Если эти ресурсы уже кэшированы, этап пропускается.
2. CSS-Парсинг
Теперь проанализируем CSS (во внешних CSS-файлах и в элементах стиля) и построим CSSOM-дерево (объектная модель CSS).
Когда браузер встречает внешнюю или встроенную таблицу стилей CSS, он преобразует текст в то, что может использовать для стилизации макетов. Структура данных, в которую браузер превращает CSS, называется CSSOM. DOM и CSSOM следуют схожим концепциям в том смысле, что они оба — деревья, но это разные структуры данных. Как и построение DOM из нашего HTML, построение CSSOM из CSS считается процессом, блокирующим рендеринг.
Токенизация и построение CSSOM
Как и HTML, CSS-парсинг начинается с токенизации. Парсер берет байты и преобразует их в символы, затем в токены, узлы и, наконец, они связываются в CSSOM. Браузер производит селекторное согласование, чтобы каждый набор стилей соответствовал всем элементам на странице.
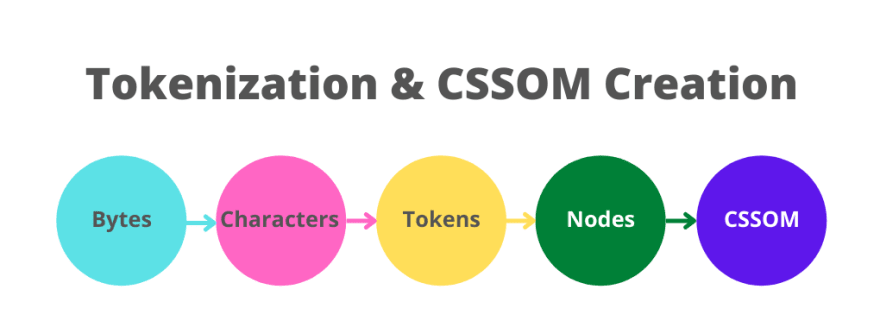
Браузер начинает с общего правила, применимого к узлу. Например: если узел — дочерний по отношению к элементу body, то он наследует все стили body. Затем браузер рекурсивно уточняет вычисляемые стили, применяя более конкретные правила. Вот почему правила стиля называют каскадными.
Для примера возьмем такой CSS:
body {
font-size: 16px;
color: white;
}
h1 {
font-size: 32px;
}
section {
color: tomato;
}
section .mainTitle {
margin-left: 5px
}
div {
font-size: 20px;
}
div p {
font-size: 8px;
color: yellow;
}CSSOM для данного кода примерно такой:

Обратите внимание, что в схеме у вложенных элементов как унаследованные, так и собственные стили.
унаследованные — от родительского, например:
h1наследует цвет отbody, аsectionнаследует размер шрифта отbodyсобственные стили могут переписывать правила, унаследованные от родительского элемента, например:
pпереписывает цвет и размер шрифта, унаследованный отdiv
Итак, у нас может быть несколько источников CSS, и они могут содержать правила, применимые к одному и тому же узлу. Поэтому браузер должен решить, какое будет применяться. Именно тогда в игру вступает специфичность.
Представьте, что вы в аэропорту ищете друга Ваню. Если хотите найти его по имени, можно крикнуть: «Ваня!». Скорее всего, в аэропорту будет несколько Вань, и они все откликнутся. Лучше позвать друга полным именем. Если крикнуть «Ваня Иванов», шансов найти друга будет больше.
Аналогично возьмем такой элемент…
<p>
<a href="https://dev.to/">This is just a link!</a>
</p>… и такие стили CSS:
a {
color: red;
}
p a {
color: blue;
}Как думаете, какое правило применится в браузере?
Ответ – второе, так как сочетания селекторов для всех тегов-якорей <a /> внутри абзаца более специфичны, чем просто селектор всех тегов-якорей. Если хотите поиграть со специфичностью, используйте калькулятор специфичности.
❗️
Правила CSS читаются справа налево, то есть если у нас есть такое:section p { color: blue; }, браузер сначала ищет все теги p на странице, а затем смотрит, есть ли у этих тегов p родительский тегsection. В таком случае применяется правило CSS.
Во время CSS-парсинга и создания CSSOM загружаются другие ресурсы, включая файлы JavaScript. Это происходит благодаря предварительному загрузчику, о котором мы говорили выше.
3. Выполнение JavaScript
Итак, после получения файла JavaScript с сервера код интерпретируется, компилируется, анализируется и выполняется. Код JS преобразуется в то, с чем компьютер может работать, и это задача движка JavaScript. В зависимости от браузера движки JS называются и работают по-разному.
Движки JavaScript
? Движок JavaScript (иногда его называют движком ECMAScript) — часть программного обеспечения, которая выполняет код JavaScript в браузере, и не только. Например, движок V8 — основной компонент среды Node.js.
Движки JavaScript, как правило — продукт деятельности разработчиков веб-браузеров. Мы говорили, что самые популярные браузеры — Chrome, Safari, Edge и Firefox. У каждого из них свой движок JavaScript:
V8. Высокопроизводительный движок JavaScript компании Google. Он написан на C++ и используется, в частности, в браузере Chrome и платформе Node.js. Реализует стандарты ECMA-262, ECMA-402 и WebAssembly.
JavaScriptCore. Встроенный движок JavaScript для WebKit, на котором работает Safari, Mail и другие приложения на macOS. В настоящее время он реализует спецификацию ECMA-262.
Chakra. Движок JavaScript, разработанный компанией Microsoft для браузера Microsoft Edge и других приложений Windows. Он реализует ECMA-262 версии 5.1 и частично поддерживает версию 6.
SpiderMonkey. Движок JavaScript и WebAssembly компании Mozilla. Он написан на C++, JavaScript и Rust и используется в Firefox, Servo и других проектах.
В начале движки JavaScript были простыми интерпретаторами. Современные браузеры проводят так называемую компиляцию Just-In-Time (JIT), сочетание компиляции и интерпретации.
Компиляция
? Процесс, когда часть ПО, называемая компилятором, берет код на языке высокого уровня и сразу преобразует его в машинный.
Создается промежуточный объектный файл, который запускается на любой машине. После выполнения этих действий код можно выполнить — сразу, когда-то в будущем или никогда.

Интерпретация
Такой тип исполнения кода используется в старых версиях JS.
Во время работы интерпретатор просматривает код JavaScript строку за строкой и немедленно выполняет его. Компиляции нет, поэтому объектный код не создается. Сам интерпретатор создает выходной код, используя внутренние механизмы.
Компиляция Just-In-Time
Такой тип исполнения кода используется в новейших версиях JavaScript.
JIT-компилятор пытается использовать как компиляцию, так и интерпретацию. Во время чистой компиляции код преобразуется до начала выполнения, при JIT-компиляции код преобразуется во время выполнения. Можно сказать, что исходный код преобразуется в машинный на лету.

Очень важный аспект JIT-компиляции — преобразование исходного кода в инструкции машинного кода работающей машины. Полученный машинный код оптимизируется для архитектуры ЦП работающей машины.
Если говорить совсем упрощенно, эти три процесса сводятся к следующему:
Компилятор преобразует код
Интерпретатор запускает код
Компилятор JIT преобразует во время выполнения кода
Сегодняшняя грань между терминами компиляция и интерпретация сильно стерлась. Если хотите узнать больше, для начала прочитайте статью на Mozilla Hacks (EN).
Обратите внимание, что я упомянул разные версии стандарта JavaScript. Браузеры, не поддерживающие новые версии языка, интерпретируют код, в то время как поддерживающие используют JIT для выполнения кода: движки V8, Chakra JavaScriptCore и SpiderMonkey. Хотя JavaScript — интерпретируемый язык и ему не нужна компиляция, большинство браузеров используют JIT-компиляцию для запуска кода, а не чистую интерпретацию.
Как обрабатывается код JavaScript
Когда код JavaScript принимает код, сначала проводится его анализ. Код считывается и одновременно преобразуется в структуру данных под названием абстрактное синтаксическое дерево AST. Код разделяется на фрагменты, имеющие отношение к языку. Например, ключевые слова function или const. Затем все эти фрагменты построят абстрактное синтаксическое дерево.
Допустим, у нас есть файл с программой, которая выполняет только одно действие — определяет переменную:
const age = 25;В этом случае абстрактное синтаксическое дерево будет выглядеть так (используется @babel/parser-7.16.12:

Если хотите преобразовать JavaScript в абстрактное синтаксическое дерево самостоятельно, используйте AST explorer. AST, полученный после записи переменной, на самом деле намного больше: в нём больше узлов, которые скрыты на снимке экрана.
После построения AST переводится в машинный код и выполняется сразу, так как современный JavaScript использует JIT-компиляцию.
Движок JavaScript выполняет этот код с использованием стека вызовов.
?Стек вызовов — механизм, с помощью которого интерпретатор JavaScript определяет, какая функция выполняется в настоящее время, какие функции вызываются из этой функции и т.д.
Ссылки на все материалы из статьи:
Другие статьи про frontend для начинающих:
Как работают браузеры: навигация и получение данных, парсинг и выполнение JS, деревья спец возможностей и рендеринга
Другие статьи про frontend для продвинутых:
