
Приветствую тебя! Меня зовут Дмитрий и я работаю в Lad.
Сегодня я поведаю историю о том, как эволюционировал скидочный сервис одного из наших проектов. Пройдя путь от всеми нелюбимого, "тормозящего" сервиса, до сервиса,
который имеет наилучшие показатели на недельных графиках SLA.
Рассказ делится на четыре части, первая из которых это краткая вводная о том, что из себя представляет скидочный сервис и как он справлялся (нет) с нагрузкой до рефакторинга. Во второй, более технической части, я делюсь опытом рефакторинга, в частности говорю про те трудности с которыми пришлось столкнуться и какие шаги были предприняты для того, чтобы исправить печальную ситуацию с производительностью. В третьей части поговорим о достигнутых результатах. В завершающей, четвертой части приводятся некоторые мысли о возможных улучшениях.
Часть первая - историческая справка
Немного о проекте
Заказчик - крупная сеть розничных магазинов обуви, одежды и аксессуаров,
насчитывающая порядка 1500 магазинов, большая часть из которых находится в России.
Несмотря на то, что основной упор делается на розничную торговлю (POS),
так же имеется свой интернет магазин и отдельные приложения под Android/iOS.
Акция как сущность
Что из себя представляет акция? Она состоит из пяти основных частей:
Поля информационного характера
Общие настройки, такие как регион проведения, срок действия и прочее
Необязательный список акций, с которыми данная акция может быть применена совместно (согласно указанным приоритетам)
Триггер, который выступает в роли предварительного фильтра и позволяет понять применима ли акция к конкретному состоянию корзины
Алгоритм, описывающий механику отдельных видов акций (например скидка на группу позиций), а так же содержащий саму скидку
Скидочный сервис
Исторически так сложилось, что основной язык используемый на бэкенде это Node.js "приправленный" TypeScript, но местами встречаются C++/Java и другие языки.
Применяется подход с микросервисной архитектурой (на момент написания статьи кол-во микросервисов было близким к 150). Одним из таких микросервисов является герой данной статьи - скидочный сервис, клиентами которого являются как POS, так и другие сервисы нашей системы. Все эти клиенты порождают запросы, время ответа которых косвенно, а иногда и напрямую зависит от скорости расчета скидок.
Скидки рассчитываются в момент запроса исходя из содержимого корзины и текущих настроек акций. Настройка акций происходит через отдельную админ-панель,
которая в свою очередь состоит из настройки пересечений, триггера и алгоритма согласно которому будет применена скидка. Условия в триггере и алгоритме описываются с помощью кастомного DSL. Изменения в настройках акций напрямую отражаются на поведении скидочного сервиса. С таким подходом, как не трудно догадаться, очень легко выстрелить себе в ногу, но у него есть и свои плюсы (а теперь даже два).
На проекте я не с самого его начала, поэтому не знаю почему был выбран именно такой "реактивный" подход, но избавиться от него, с учетом всех зависимых сервисов, даже на момент рефакторинга было бы очень непросто. Да и заказчику полюбилась та гибкость которой он обладал.
Нулевая итерация
В нулевой итерации, парсинг и вычисление условий выполнялись силами Node.js, реализовано это было весьма наивным образом, с множеством тяжелых (де)сериализаций, да и сами алгоритмы лежащие в основе оставляли желать
лучшего. При каждом обращении к сервису выполнялся поход в БД чтобы достать нужные акции и их условия. С таким подходом сервис выдерживал порядка 10 RPS даже при небольшом кол-ве активных акций, что никуда не годится.
Перекладываем сложность вычислений на БД
Последующая итерация не заставила себя долго ждать. Одним из разработчиков была предложена идея вынести всю сложность с фильтрацией акций (шаг с триггером)
и позиций из корзины попадающих под условие акции (шаг с алгоритмом) на плечи БД.
Я считаю что идея была весьма удачной и на то время даже спасительной.
Вместо того, чтобы вычислять условия в самом сервисе, да еще и в единственном потоке, не имея для этого хорошей структуры данных для построения индекса, расчет скидок теперь выглядел следующим образом:
На каждый запрос в сервис происходила вставка корзины в отдельную коллекцию MongoDB (с In-Memory Storage Engine)
Из условий триггеров и алгоритмов генерировался запрос в БД на поиск подходящих акций
Если что-то находилось на предыдущем шаге, то рассчитывались скидки
Вставленные на первом шаге записи удалялись из коллекции
Не заметили ничего странного? Получилось как бы наизнанку, вместо того, чтобы использовать корзину как аргумент для некой абстрактной функции расчета скидок, теперь в качестве аргумента используются условия. Возможно, если бы была выбрана БД с поддержкой хранимых процедур, такой инверсии удалось бы избежать. В таком случае, можно было бы построить тело процедуры исходя из условий акции, затем сохранить эту процедуру в БД и использовать ее совместно с ранее сохраненными процедурами, поочередно в цикле, но это уже отдельная тема для размышлений.
После этих доработок, с каждым инстансом сервиса, поднимался отдельный инстанс MongoDB, с in-memory хранилищем. Это позволило сервису преодолеть планку в 50 RPS.
В часы пиковой нагрузки кол-во инстансов доходило до более чем 20, каждый из которых потреблял почти гигабайт RAM, четверть ядра CPU, а так же сильно грузил сеть, стягивая акции напрямую из БД.
Несмотря на все эти недостатки, сервис прожил в такой имплементации несколько лет обзаведясь при этом немалым числом клиентов.
Часть вторая - рефакторинг
Тучи сгущаются
Время шло, нагрузка росла, а с ней и кол-во инстансов. Если возникала какая-нибудь проблема, почти наверняка к ней был причастен скидочный сервис. Команда DevOps матерясь, как от сердца отрывала последние ресурсы, заказчик хмурил брови. Так больше не могло продолжаться. С позволения заказчика было принято решение переписать сервис. Этот эпик, как вы уже могли догадаться, достался мне.
К тому моменту на проекте я успел проработать почти год, наслушаться кучи баек про скидочный сервис, в том числе о том, что пару разработчиков сошло с ума уволилось, после тщетных попыток рефакторинга. Все усложнялось тем, что для клиентов данного сервиса ничего не должно было измениться. Контракты менять нельзя, это повлекло бы за собой очень масштабные и дорогие переделки в куче других сервисов.
Приступаем
В глаза сразу бросилось отсутствие кеширования. Развивая эту тему и
прикинув среднее кол-во активных акций, а так же их теоретический предел, стало ясно что все данные без труда умещаются в RAM. Минусы кеширования на уровне сервиса в том, что нужно каким-то образом синхронизировать состояние, сервис перестает быть stateless. Если выполнять кеширование до сервиса, например с использованием Redis, тогда придется тянуть данные по сети и выполнять десериализацию,
а этого хотелось бы избежать, особенно с учетом того, что условия отдельных акций занимали около 500KB. Исходя из этих рассуждений, было принято решение все хранить в RAM. Благодаря использованию in-memory БД, удалось распараллелить вычисления в рамках одного инстанса. Это свойство так же не хотелось терять, при том, что от использования БД в конечном итоге желательно было отказаться.
Получился следующий список проблем которые необходимо было решить:
Избавиться от in-memory MongoDB и при этом сохранить многопоточность
Научиться передавать удобным образом данные от Node.js к C++
Упростить и облегчить DSL
Подобрать структуру данных для представления условий
Ускорить вычисление условий
Реализовать синхронизацию изменений
Обо всем по порядку.
Многопоточность
Node.js это runtime построенный поверх движка Chrome V8. Несмотря на то, что по своей природе Node.js является однопоточным и в большей степени рассчитан на I/O bound приложения, некоторые блокирующие системные вызовы и криптографические операции выполняются в отдельных потоках. Такая возможность доступна благодаря libuv на котором основан V8 и его внутреннему thread pool. В большинстве случаев это происходит прозрачно для прикладного программиста, на отдельных стадиях event loop'а. При этом имеется несколько способов задействовать thread pool явно, один из которых - использовать C++ API предоставляемое node-addon-api.
Помимо node-addon-api, существует еще один, ныне уже устаревший способ, прямого включения node/v8 .h файлов на стороне C++. Данный подход подвержен проблеме ABI-совместимости, рассматривать его в данной статье я не буду.
В Node.js так же имеется Worker threads API, позволяющее порождать отдельные процессы с изолированным рантаймом. Эти процессы в отличие от обычных процессов могут иметь разделяемую память. Запуск отдельного процесса достаточно тяжелая операция и может быстро превратиться в узкое место, сгладить это можно созданием пула из воркеров (не путать с libuv thread pool). На мой взгляд, такого рода параллелизм больше подходит для долгих CPU-bound задач, поэтому от данного варианта я решил отказаться в пользу node-addon-api.
Примеры кода и другую полезную информацию о node-addon-api, можно найти в официальной документации. Так же имеется отдельный репозиторий с примерами кода - node-addon-examples.
Рекомендую сразу позаботится о разделении нативного C++ кода и той части кода которая использует napi (там где это возможно). Это упростит как последующую поддержку аддона, так и его тестирование. Так же не помешает обзавестись набором хелперов для приведения Napi::Value-значений к нативным C++ типам данных и наоборот.
Для сборки аддона я выбрал node-gyp, альтернативы оказались менее привлекательными. node-gyp позволяет описать процесс сборки исходя из архитектуры хост системы. В моем случае аддон поставляется как npm-пакет, поэтому сборка происходит в момент его установки.
Вернемся к многопоточности. Для того чтобы ей воспользоваться необходимо написать C++ addon. В простейшем варианте, это выглядит следующим образом:
#include "napi.h"
class DeepThought final : public Napi::Addon<DeepThought> {
public:
DeepThought(Napi::Env env, Napi::Object exports) {
DefineAddon(exports, {InstanceMethod<&DeepThought::Compute>("compute")});
}
private:
Napi::Value Compute(Napi::CallbackInfo const& cb_info) {
ThoughtProcess* worker = new ThoughtProcess(cb_info.Env());
worker->Queue();
return worker->AsPromise();
}
};
NODE_API_ADDON(DeepThought)
Давайте разбираться. В примере выше определяется класс аддона, который затем регистрируется через макрос NODE_API_ADDON. В конструкторе класса DeepThought, с помощью вызова метода DefineAddon (унаследованного от Napi::Addon) перечисляются методы которые будут доступны при импорте. В данном случае это единственный метод Compute, который будет доступен под именем compute на стороне Node.js.
В методе Compute создается экземпляр класса Napi::AsyncWorker, благодаря которому у нас имеется возможность выполнять C++ код в одном из потоков libuv thread pool. Далее, у воркера вызывается метод Queue, чтобы добавить "задачу" (тело метода Execute из примера далее) в очередь на выполнение, а затем возвращается Promise.
Заглянем в код воркера:
#include <chrono>
#include <thread>
#include "napi.h"
using namespace std::chrono_literals;
class ThoughtProcess final : public Napi::AsyncWorker {
public:
ThoughtProcess(Napi::Env env)
: AsyncWorker(env), deferred_(Napi::Promise::Deferred::New(env)) {}
~ThoughtProcess() = default;
void Execute() override {
std::this_thread::sleep_for(7'500'000ns);
}
void OnOK() override {
Napi::HandleScope scope(Env());
deferred_.Resolve(Napi::Number::New(Env(), 42));
}
void OnError(Napi::Error const& err) override {
deferred_.Reject(err.Value());
}
Napi::Promise AsPromise() const {
return deferred_.Promise();
}
private:
Napi::Promise::Deferred deferred_;
};
Как можно заметить, он достаточно прост. Метод Execute будет выполнен в отдельном потоке, при успешном завершении которого, будет вызван OnOK, а при неудачном OnError, с Resolve и Reject соответственно. Так как Deferred должен пережить вызов метода Compute, необходимо сохранить его в воркере. Чтобы иметь возможность получить Promise которым владеет Deferred, был добавлен отдельный метод AsPromise.
Чтобы не указывать относительный путь до аддона, а импортировать его по имени, используется npm-пакет bindings. При условии, что target_name в .gyp файле указан как thinker, импортировать и использовать аддон на стороне Node.js можно следующим образом:
const thinker = require('bindings')('thinker');
async function main() {
try {
const answer = await thinker.compute();
console.info(answer);
} catch (err) {
console.error(err);
}
}
main();
Размер пула регулируется с помощью переменной окружения UV_THREADPOOL_SIZE (по умолчанию 4).
Для контроля конкурентных обращений к разделяемым данным я решил использовать std::shared_mutex (C++ имплементация MRSW lock). Проблема с отсутствием многопоточности решена, движемся дальше.
Передача данных от Node.js к C++
Хотелось бы каким-то образом связать JS-объект с C++ ресурсом, чтобы избежать ручного освобождения ресурсов. К счастью такой способ существует:
#include "napi.h"
class Hint final : public Napi::ObjectWrap<Hint> {
public:
static void Setup(Napi::Env env, Napi::Object exports) {
Napi::Function ctor = DefineClass(env, "Hint", {});
exports.Set("Hint", ctor);
}
Hint(Napi::CallbackInfo const& cb_info) : Napi::ObjectWrap<Hint>(cb_info) {
value_ = cb_info[0].As<Napi::String>().Utf8Value();
}
std::string const& Peek() const {
return value_;
}
private:
std::string value_;
};
Napi::ObjectWrap как и следует из названия, "оборачивает" нативный C++ класс. Каждый раз при создании экземпляра JS-класса, также будет создаваться экземпляр C++ класса. Срок жизни экземпляра будет привязан к сроку жизни JS объекта.
При вызове метода C++ аддона и передаче созданного экземпляра в качестве аргумента, фактически передается указатель на него:
const thinker = require('bindings')('thinker');
const { Hint } = thinker;
async function main() {
const hint = new Hint('The answer is a natural number');
const answer = await thinker.compute(hint);
}
main();
Чтобы получить указатель на экземпляр обернутого C++ класса, необходимо вызвать метод Unwrap в уже знакомом вам методе Compute:
Napi::Value Compute(Napi::CallbackInfo const& cb_info) {
Hint* hint = Napi::ObjectWrap<Hint>::Unwrap(cb_info[0].As<Napi::Object>());
ThoughtProcess* worker = new ThoughtProcess(cb_info.Env(), hint);
worker->Queue();
return worker->AsPromise();
}
На стороне Node.js работа с экземпляром класса Hint ничем не отличается от работы с обычным экземпляром JS-класса и это прекрасно. На очереди DSL.
DSL для описания условий
Исходный DSL был слишком громоздким, а его неоднородная структура усложняла парсинг. Было принято решение спроектировать его с нуля, при этом написав адаптер, чтобы условия в БД продолжали храниться в старом формате и в админ-панели не пришлось ничего дорабатывать. За основу было взято небольшое подмножество MongoDB DSL. На данный момент поддерживается следующий набор операторов:
Операторы сравнения (
$eq,$ne,$gt,$gte,$lt,$lte)Логические операторы (
$and,$or,$not)Операторы принадлежности множеству (
$in,$nin)Вхождение в диапазон значений (
$between)
При этом, ничего не мешает расширить этот набор, если в этом есть необходимость.
Представим следующее выражение с помощью нового DSL:

const expression = {
$and: [
{
sku: {
$in: {
values: ['134174510', '133211893'],
type: ValueType.STRING,
},
},
},
{
$or: [
{
hasLoyaltyCard: {
$eq: {
value: true,
type: ValueType.BOOLEAN,
},
},
},
{
cartTotal: {
$gt: {
value: '2999.99',
type: ValueType.DECIMAL,
},
},
},
],
},
],
};
Чтобы правильным образом интерпретировать значение при парсинге, используется дополнительное поле type. Это выражение парсится на стороне C++, с помощью самописного recursive descent парсера. Далее я расскажу о том, что получается на выходе.
Представление условий
Результат парсинга представлен в виде дерева, внутренние узлы которого являются операторами, а листовые операндами. Идея имплементации была заимствована из Halide. Иерархия классов выглядит следующим образом:
struct NodeBase {
explicit NodeBase(NodeType my_type) : node_type(my_type) {}
virtual ~NodeBase() = default;
virtual void Accept(Visitor* visitor) const = 0;
mutable ReferenceCounter reference_counter;
NodeType node_type;
};
struct ExpressionBase : public NodeBase {
explicit ExpressionBase(NodeType my_type) : NodeBase(my_type) {}
virtual Expr Mutate(Mutator* mutator) const = 0;
DType dtype;
};
template<typename T>
struct ExpressionNode : public ExpressionBase {
ExpressionNode() : ExpressionBase(T::node_type_hint) {}
~ExpressionNode() override = default;
void Accept(Visitor* visitor) const override;
Expr Mutate(Mutator* mutator) const override;
};
struct Decimal final : public ExpressionNode<Decimal> {
static NodeType const node_type_hint = NodeType::kDecimal;
static Expr Make(std::string_view raw_value);
Decimal64 value;
};
Рассмотрим каждый класс по отдельности. NodeBase как и следует из названия, является базовым классом для любого узла, помимо типа узла в экземпляре так же содержится счетчик ссылок (подробнее о нем далее). ExpressionBase это базовый класс для всех выражений, содержащий тип данных DType. На самом деле ExpressionBase можно упразднить и смержить с NodeBase, если все узлы являются выражениями (вычисляются в какое то значение). Следующим в цепочке наследования идет шаблон класса ExpressionNode, позволяющий реализовать идиому CRTP. Завершает цепочку наследования класс конкретного выражения, для примера был выбран Decimal. Для создания экземпляра конкретного выражения используется метод Make, если присмотреться, то можно заметить, что он возвращает некий Expr, которого нет в представленной выше иерархии классов, это не опечатка, о нем я расскажу далее.
struct Handle : public IntrusivePointer<NodeBase const> {
Handle() = default;
Handle(NodeBase const* ptr) : IntrusivePointer(ptr) {}
template<typename T>
T const* As() const {
if (!ptr_ || ptr_->node_type != T::node_type_hint) {
return nullptr;
}
return static_cast<T const*>(ptr_);
}
};
struct Expr final : public Handle {
Expr() = default;
Expr(ExpressionBase const* ptr) : Handle(ptr) {}
explicit Expr(std::string_view raw_value) : Handle(Decimal::Make(raw_value)) {}
};
Класс Handle является интрузивным указателем на узел дерева,
именно он занимается подсчетом ссылок с помощью ReferenceCounter (который находится в NodeBase), наследуя эту функциональность от IntrusivePointer. При желании, ReferenceCounter и IntrusivePointer можно заменить на std::enable_shared_from_this, пример такой имплементации можно подсмотреть у pytorch JIT.
Вы, наверное, задаетесь вопросом: "В чем смысл"? Отвечаю. Экземпляр класса Expr содержит единственный член данных - указатель на NodeBase, это делает копирование Expr сравнимым по стоимости, с копированием скалярного типа данных, такого как int64_t. Благодаря этому Expr можно оптимальным образом передавать по значению. Таким образом, получается весьма гибкая схема, позволяющая из "голого" указателя, безопасно сделать каст к нужному типу выражения, вызвав метод As. В дополнение к этому, CRTP весьма удачно сочетается с паттерном Visitor.
Новая фича под названием Deducing This, которая станет доступной в C++ 23, позволит реализовать CRTP не прибегая к шаблонам, подробности можно узнать в этом видео.
Вычисление условий
Изначально, идея заключалась в компиляции дерева, представляющего выражение, в отдельную функцию, получая при этом всевозможные оптимизации C++ компилятора и последующем ее подключении как DLL, но до этого дело не дошло (подробнее об этом в четвертой части). В нашем случае, более простой имплементации, с вычислением результата через обход дерева, оказалось более чем достаточно.
Внимательный читатель мог обратить внимание на методы Visit и Mutate которые определены в классе ExpressionNode. Благодаря CRTP их реализация сводится к одной строчке кода:
visitor->Visit(static_cast<T const*>(this));
Метод Mutate реализуется аналогично. Класс Visitor используется для read-only операций над деревом, например для построения визуализации, в то время как Mutator используется для модификации структуры дерева.
Как следствие, над деревом можно выполнять оптимизации, например упрощать выражение. В качестве одной из таких оптимизаций я удаляю оператор $not, с последующей заменой вышестоящего оператора на обратный ему, сокращая тем самым кол-во узлов.
Для вычисления выражений используется специальный подкласс Mutator, называемый ExpressionSolver. Результатом его работы является единственное значение типа bool.
Рассмотрим процесс вычисления, на примере следующего выражения:
const expression = {
answer: {
$eq: {
value: 42,
type: ValueType.INTEGER,
},
},
};
Далее представлена упрощенная имплементация класса ExpressionSolver:
template <typename O, typename F>
Expr solve_relational(Mutator* mutator, O&& op, F&& binary_func) {
Expr lhs = op->lhs->GetPtr()->Mutate(mutator);
Expr rhs = op->rhs->GetPtr()->Mutate(mutator);
auto lhs_dtype = lhs.GetDType();
assert(lhs_dtype.IsSameAs(rhs.GetDType()));
if (lhs_dtype.IsInt()) {
auto lhs_int = lhs.As<Int>();
auto rhs_int = rhs.As<Int>();
return Boolean::Make(binary_func(lhs_int->value, rhs_int->value));
}
unreachable();
}
template <typename T>
class ExpressionSolver : public Mutator {
public:
explicit ExpressionSolver(T const& eval_ctx) : eval_ctx_(eval_ctx) {};
~ExpressionSolver() override = default;
bool Solve(Expr const& expr) {
Expr result = expr.GetPtr()->Mutate(this);
auto result_bool = result.As<Boolean>();
assert(result_bool != nullptr);
return result_bool->value;
}
private:
Expr Visit(Variable const* var) override {
Expr substitution = eval_ctx_.Get(var->id);
return substitution.GetPtr()->Mutate(this);
}
Expr Visit(Equals const* expr) override {
return solve_relational(this, expr, std::equal_to<>());
}
Expr Visit(Int const* expr) {
return expr;
}
private:
T const& eval_ctx_;
};
Непосредственное использование ExpressionSolver выглядит так:
ExpressionSolver solver(eval_ctx);
bool success = solver.Solve(expression);
При обращении в сервис, создается экземпляр корзины, который используется как контекст для подстановки переменных. Подстановка выполняется в момент посещения узла с типом Variable. Внутри вспомогательной функции solve_relational выясняются типы операндов и вызывается переданная функция для выполнения сравнения. По схожему принципу выполняются все остальные вычисления.
В качестве оптимизации логических бинарных операций, таких как $and и $or,
применяется short circuit evaluation:
bool is_short_circuited = logical_binary_func(true, false)
? rhs_bool->value
: !rhs_bool->value;
if (is_short_circuited) {
return Boolean::Make(rhs_bool->value);
}
С вычислением условий разобрались, переходим к синхронизации изменений.
Синхронизация изменений
С течением времени появляется необходимость в создании новых акций, а также в изменении или удалении существующих. Необходимо своевременно реагировать на изменение состояния коллекции, в которой хранятся акции, чтобы приводить условия акций в консистентное состояние. Вариантов не так много:
Периодические запросы в БД с целью отдать акции, время изменения которых (
updatedAt) больше, ранее сохраненной временной меткиСлушать события изменения коллекции используя change streams
Следующий вопрос заключается в том, где разместить данный механизм:
В каждом инстансе скидочного сервиса
В отдельном сервисе координаторе
Получается 4 комбинации:
Сервис координатор выполняющий polling
Сервис координатор слушающий события изменения
Скидочный сервис выполняющий polling
Скидочный сервис слушающий события изменения
Так как MongoDB поддерживает удобную push-модель с помощью change streams, pull-модель я решил не рассматривать. Change streams - это абстракция над oplog, который используется для синхронизации реплик, находящихся в replica set. События в этом логе упорядочены. Так же имеется возможность запрашивать события из прошлого (оффсет ограничен настройками самого oplog), это удобно при старте сервиса и исходной инициализации.
Имея сервис-координатор можно опрашивать все инстансы скидочного сервиса, проверяя их состояние, используя для этого merkle tree (например). Координатор позволяет управлять тем, когда будут видны изменения и более подконтрольно приводить инстансы в консистентное состояние. Несмотря на свои возможные преимущества, вариант с координатором более сложен в реализации. Не стоит забывать, что являясь единственным источником истины, он так же является единой точкой отказа.
Вариант с подпиской на изменения в свою очередь страдает от потенциально длительных рассинхронизаций отдельных инстансов, так как изменения применяются каждым инстансом независимо от остальных. Вопреки этим недостаткам, заказчика устроил такой вариант. К тому же большая часть акций создается заранее, со сроком начала действия указанным в будущем, к этому моменту состояние в рамках этих акций почти наверняка будет консистентным.
В итоге, в каждом инстансе скидочного сервиса есть свой, независимый "слушатель" событий изменения, его запуск выглядит примерно следующим образом:
const since = new Date().toISOString();
const promotions = await promotionsRepository.find({ isEnabled: true });
await engine.initWith(promotions);
await watcher.startWatching(since);
Так как инициализация занимает какое то время, в этом окне могут происходить события и чтобы их не потерять слушатель получает изменения с даты предшествующей инициализации.
Отлично, перейдем к достигнутым результатам.
Часть третья - результаты
Долгожданный релиз
Вот и настало время релиза. В целом релиз прошел гладко, но было несколько моментов, которые пришлось с горящим задом спешно исправлять.
Графики после релиза (при этом разницу по ресурсам надо умножить на кол-во инстансов):
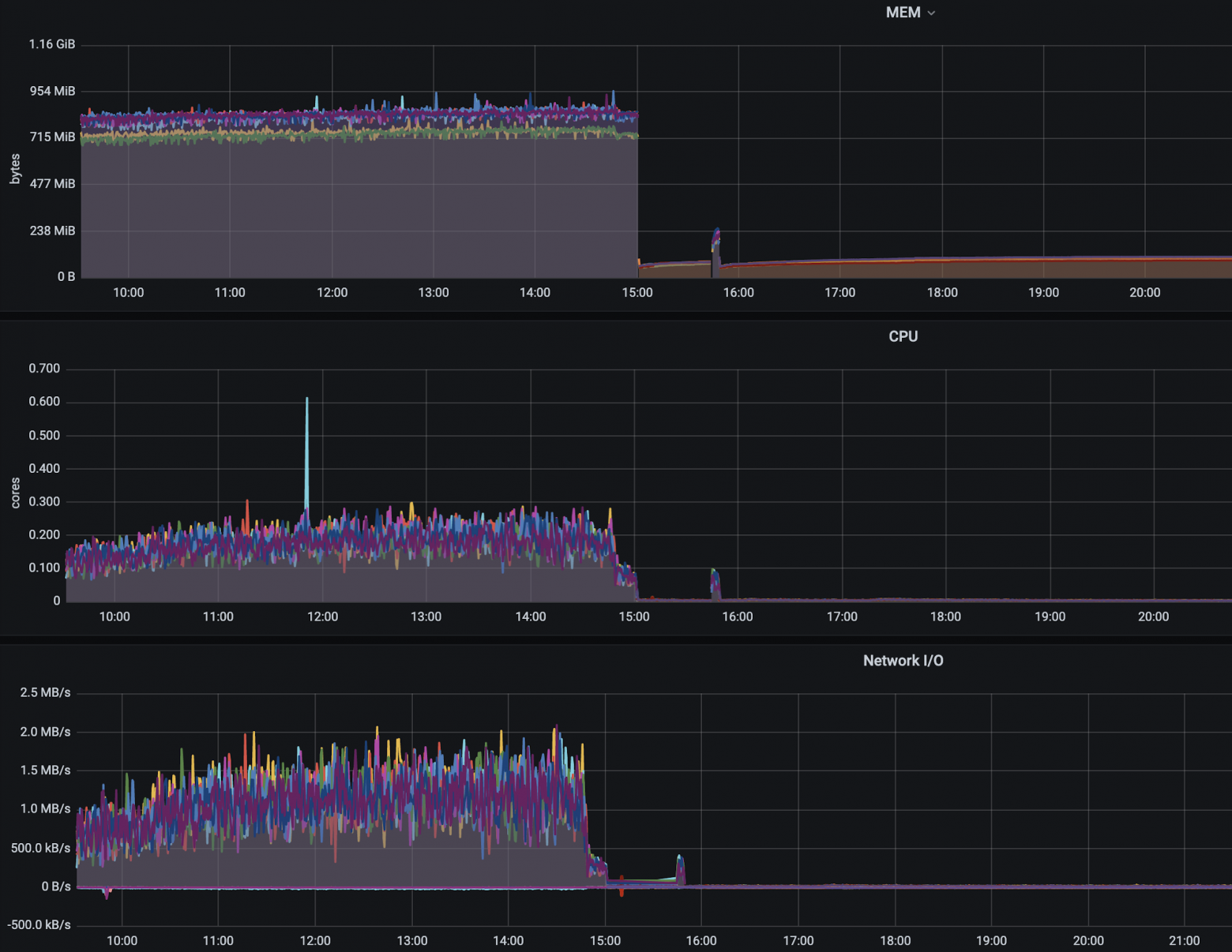
P.S. всплеск около 16:00 - следующий за релизом "традиционный" хотфикс.
Немного о числах
Среднее время обработки запроса сократилось примерно в 500 раз! Некоторые запросы выполняются быстрее чем за миллисекунду (без учета накладных расходов http).
Объем RAM потребляемый каждым инстансом снизился с ~900 МБ до ~150МБ (при более чем 300 активных акциях). Косвенно, уменьшили время ответа и стабильность других сервисов, зависящих от расчета скидок. Разгрузили CPU и сеть, что так же положительно сказывается на системе в целом и на кошельке заказчика :)
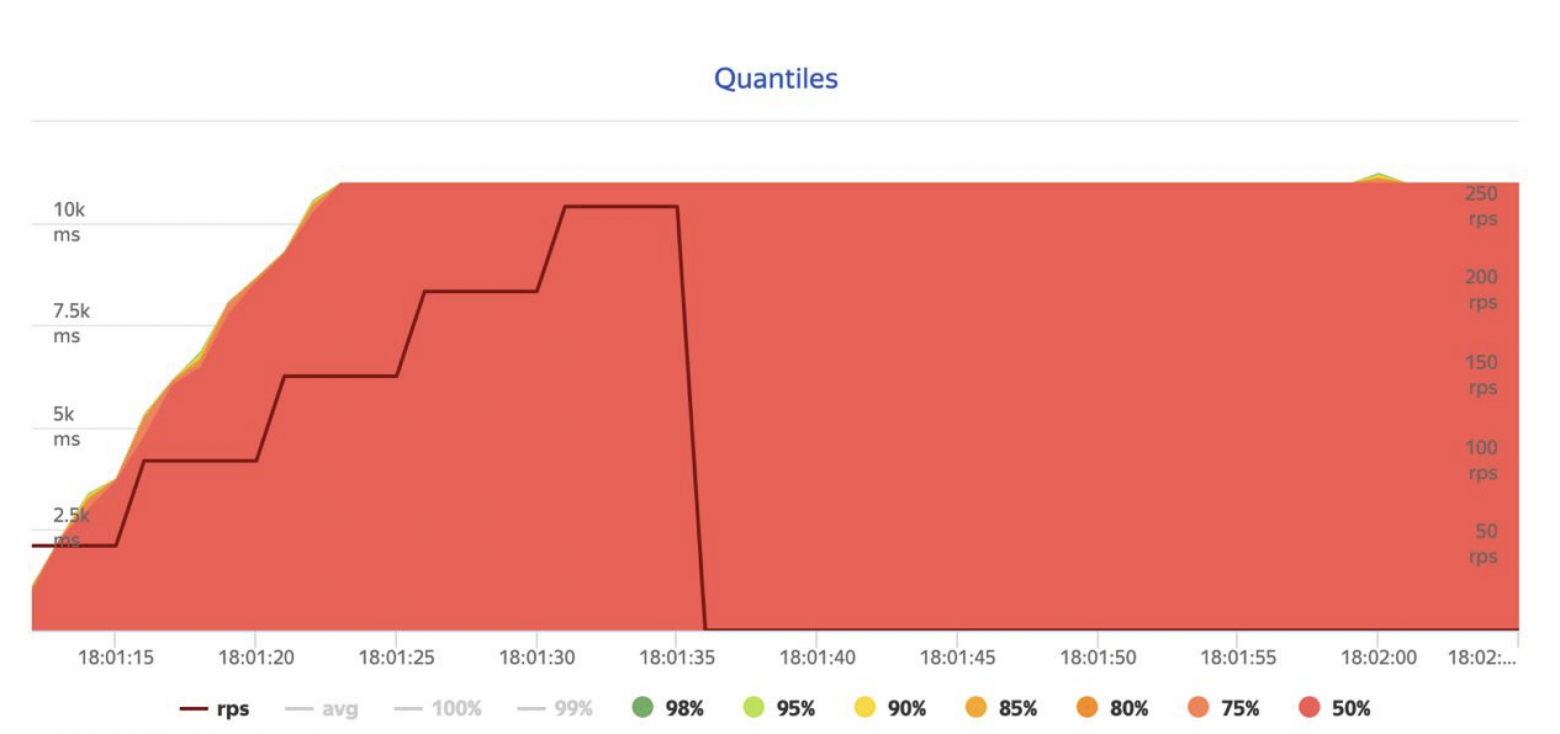
Обстрел из Yandex.Tank одного инстанса:

Несмотря на то, что запросы выполнялись через http-gate, это дает понять примерную картину. Пэйлоады для обстрела были подобраны тяжелее средних.
Для сравнения привожу результат обстрела старого сервиса (тем же набором входных данных):
Часть четвертая - идеи
Protobuf вместо JSON
Альтернативный вариант передачи данных на сторону C++ это Napi::Buffer. Особенно удачно он сочетается с Protobuf. Napi::AsyncWorker имеет одно очень серьезное ограничение, внутри метода Execute можно выполнять лишь нативный C++ код, NAPI в нем использовать нельзя.
Если отказаться от Napi::ObjectWrap в пользу класса сгенерированного Protobuf, тогда, экземпляр такого класса можно будет создать в отдельном потоке. Это поможет еще больше разгрузить основной поток, потенциально повысив пропускную способность. Эту идею нужно проверять, из-за того, что расчет скидок, происходит очень быстро, узким местом может стать частое переключение контекста.
Удаление узлов-дубликатов
Отдельные части независимых выражений зачастую повторяются. Вместо того, чтобы дублировать их, можно попытаться из дерева сделать ориентированный граф. Каждая вершина такого графа, будет содержать счетчик, хранящий кол-во ссылающихся на это подвыражение акций.
Чтобы понять, что подвыражения совпадают, в момент вставки можно использовать хеширование. При большом кол-ве условий это может потенциально сэкономить RAM.
Основной минус такого подхода, это более сложная реализация.
Компиляция условий
Логическим продолжением идеи описанной в данной статье, будет компиляция условий в функции, с последующим их подключением как DLL.
Похожий подход используется в (к сожалению уже заброшенной)
ViyaDB.
Уменьшение размера полезной нагрузки
По возможности следует сократить кол-во данных, которое проходит через основной поток. Возможно вы удивитесь (а может и нет), но при больших размерах пейлоада, большая часть ресурсов CPU может уходить именно на сериализацию и десериализацию.
В моем случае такая возможность появилась относительно недавно, но оно того стоило. Максимальный RPS вырос практически вдвое (размер пейлоада при этом был уменьшен в 3-4 раза).
Использование индекса
Если честно я не уверен что существует эффективная структура данных для индексирования булевых выражений (если вы о ней знаете, то обязательно оставьте комментарий).
Вся эта история с булевыми выражениями очень похожа на NP-полную задачу B-SAT, но как минимум можно попробовать применить Bloom-фильтр.
Продвинутое управление памятью
В процессе вычисления условий, создаются отдельные узлы с типом Boolean. Это влечет за собой частые аллокации небольших участков памяти, что может негативно сказаться на производительности. В качестве решения, можно использовать Region-based memory management или проще говоря arena.
Если заглянуть в недра LLVM IR, то можно увидеть, что для решения подобной проблемы, они используют кастомный аллокатор, привязанный к контексту в котором создается узел. Можно последовать их примеру.
Отказ от контейнеризаци
Все наши сервисы запускаются в виде Docker-контейнеров, скидочный сервис не стал исключением. Дополнительный слой виртуализации имеет свою цену. При локальном замере производительности, использование Docker-контейнера замедляет приложение примерно в 4-5 раз.
