Неделю назад я делал здесь обзор существующих алгоритмов рекомендаций. В этой статье я продолжу данный обзор: расскажу об item-based варианте коллаборативной фильтрации, о методах, основанных на матричных разложениях, проблемах тестирования, а также о менее «раскрученных» (но не менее интересных) алгоритмах.

Подход Item-based является естественной альтернативой классическому подходу User-based, описанному в первой части, и почти полностью его повторяет, за исключением одного момента — применяется он к транспонированной матрице предпочтений. Т.е. ищет близкие товары, а не пользователей.
Напомню, пользовательская коллаборативная фильтрация (user-based CF) ищет для каждого клиента группу наиболее похожих на него (в терминах предыдущих покупок) клиентов и усредняет их предпочтения. Эти усредненные предпочтения и служат рекомендациями для пользователя. В случае же с товарной коллаборативной фильтрацией (item-based CF) ближайшие соседи ищутся на множестве товаров — столбцов матрицы предпочтений. И усреднение происходит именно по ним.
Действительно, если продукты содержательно похожи, то скорее всего они либо одновременно нравятся, либо одновременно не нравятся. Поэтому когда мы видим, что у двух товаров оценки сильно коррелируют, это может говорить о том, что это товары-аналоги.
Преимущества Item-based перед User-based:
В остальном алгоритм почти полностью повторяет User-based вариант: то же косинусное расстояние как основная мера близости, та же необходимость нормализации данных. Число соседних товаров N обычно выбирают в районе 20.
Из-за того, что корреляция продуктов считается на большем количестве наблюдений, не так критично ее пересчитывать после каждой новой оценки и можно это делать периодически в батчевом режиме.
Несколько возможных усовершенствований алгоритма:
При использовании item-based подхода рекомендации имеют тенденцию быть более консервативными. Действительно, разброс рекомендаций получается меньше и следовательно меньше вероятность показать нестандартные товары.
Если в матрице предпочтений в качестве рейтинга мы используем просмотр описания товара, то рекомендуемые товары скорее всего будут аналогами — товарами, которые часто смотрят вместе. Если же рейтинги в матрице предпочтений мы рассчитываем на основании покупок, то скорее всего рекомендуемые товары будут аксессуарами — товарами, которые часто покупают вместе.
Тестирование рекомендательной системы — процесс непростой и всегда вызывающий множество вопросов, главным образом из-за неоднозначности самого понятия «качество».
Вообще, в задачах машинного обучения есть два основных подхода к тестированию:
Оба этих подхода активно применяются при разработке рекомендательных систем. Начнем с offline тестирования.
Основное ограничение, с которым приходится сталкиваться — оценить точность прогноза мы можем только на тех товарах, которые пользователь уже оценил.
Стандартный подход — это кросс-валидация методами leave-one-out и leave-p-out. Многократное повторение теста с усреднением результатов позволяет получить более устойчивую оценку качества.
Все метрики качества можно условно разделить на три категории:
К сожалению, не существует единой рекомендуемой метрики на все случаи жизни и каждый, кто занимается тестированием рекомендательной системы, подбирает её под свои цели.
Когда рейтинги оцениваются по непрерывной шкале (0-10), как правило, достаточно метрик класса Prediction Accuracy.
Метрики класса Decision Support работают с бинарными данными (0 и 1, да и нет). Если в нашей задаче рейтинги изначально откладываются по непрерывной шкале, их можно перевести в бинарный формат, применив решающее правило — скажем, если оценка меньше 3.5, считаем оценку «плохой», а если больше, то «хорошей».
Как правило, рекомендации выводятся списком из нескольких позиций (сначала топовая, затем в порядке убывания приоритета). Метрики класса Rank Accuracy измеряют насколько правилен порядок показа рекомендаций в отсортированном списке.
Если мы возьмем рекомендательные системы в онлайн бизнесе, то они, как правило, преследует две (иногда противоречивые) цели:
Как и в любой модели, направленной на мотивацию пользователя к действию, оценивать следует только инкрементальный прирост целевого действия. Т.е., например, при подсчете покупок по рекомендации нам нужно исключить те, которые пользователь и так сам бы совершил без нашей модели. Если этого не сделать, эффект от внедрения модели будет сильно завышен.
Lift — показатель того, во сколько раз точность модели превосходит некий baseline алгоритм. В нашем случае baseline алгоритмом может быть просто отсутствие рекомендаций. Данная метрика хорошо отлавливает долю инкрементальных покупок и это позволяет эффективно сравнивать разные модели.
 Источник
Источник
Поведение пользователя вещь плохо формализуемая и ни одна метрика в полной мере не опишет мыслительные процессы в его голове при выборе товара. На решение влияет множество факторов. Переход по ссылке с рекомендуемым товаром еще не есть его высокая оценка или даже интерес. Частично понять логику клиента помогает онлайн тестирование. Ниже приводится пара сценариев такого тестирования.
Первый и самый очевидный сценарий — анализ событий сайта. Мы смотрим, что пользователь делает на сайте, обращает ли внимание на наши рекомендации, переходит ли по ним, какие фичи системы пользуются спросом, какие — нет, какие товары лучше рекомендуются, какие хуже. Чтобы понять какой из алгоритмов в целом работает лучше или просто попробовать новую перспективную идею, делаем A/B тестирование и собираем результат.
Второй сценарий — это получение фидбека от пользователей в виде опросов и голосований. Как правило, это общие вопросы для понимания, как клиенты пользуются сервисом — что важнее: релевантность или разнообразие, можно ли показывать повторяющиеся продукты, или это слишком раздражает. Преимущество сценария — он дает прямой ответ на все эти вопросы.
Подобное тестирование штука сложная, но для крупных рекомендательных сервисов она просто необходима. Вопросы могут быть и более сложными, например, «какой из списков вам кажется более релевантным», «насколько лист выглядит цельным», «будете ли вы смотреть этот фильм/читать книгу».
В начале своего развития рекомендательные системы применялись в сервисах, где пользователь явно оценивает товар путем выставления ему рейтинга — это и Amazon, и Netflix и прочие сайты интернет торговли. Однако с ростом популярности рекомендательных систем возникла потребность применять их ещё и там, где никаких рейтингов нет — это могут быть банки, автомастерские, ларьки с шаурмой и любые другие сервисы, где по какой-то причине невозможно наладить систему оценивания. В этих случаях интересы пользователя можно вычислить лишь по косвенным признакам — о пользовательских предпочтениях говорят определенные действия с товаром, например, просмотр описания на сайте, добавление товара в корзину и т.д. Здесь используется принцип «купил — значит любит!». Такая система неявного оценивания называется Implicit Ratings.
Неявные рейтинги очевидно работают хуже явных, поскольку вносят на порядок больше шума. Ведь пользователь мог купить товар в подарок жене или зайти на страницу с описанием товара, только чтобы оставить там комментарий в стиле «какая же все-таки это гадость» или удовлетворить свое природное любопытство.
Если в случае с явными рейтингами мы вправе ожидать, что хоть одну отрицательную оценку нет-нет да и поставит, то отрицательную оценку мы ниоткуда не возьмем. Если пользователь не купил книгу «Пятьдесят оттенков серого», он мог это сделать по двум причинам:
Но у нас нет никаких данных, чтобы отличить первый случай от второго. Это плохо, потому что обучая модель, мы должны подкреплять её на положительных кейсах и штрафовать на отрицательных, а так будем почти всегда штрафовать, и в итоге модель будет смещенной.
Второй кейс — это возможность оставлять только положительные оценки. Яркий пример — это кнопка Like в соцсетях. Рейтинг здесь проставляется уже явно, но так же как и в предыдущем примере, у нас нет отрицательных примеров — мы знаем, какие каналы пользователю нравятся, но не знаем, какие не нравится.
В обоих примерах задача превращается в задачу Unary Class Classification.
Самый очевидный вариант решения — идти по простому пути и считать отсутствие оценки отрицательной оценкой. В некоторых случаях это более оправдано, в некоторых — менее. Например, если мы знаем, что пользователь товар скорее всего видел (например, мы ему его показывали в списке товаров, а он перешел на товар, идущий за ним), то отсутствие перехода действительно может говорить об отсутствии интереса.
 Источник
Источник
Было бы здорово описать интересы пользователя более «крупными мазками». Не в формате «он любит фильмы X, Y и Z», а в формате «он любит современные российские комедии». Помимо того, что это увеличит обобщаемость модели, это еще решит проблему большой размерности данных — ведь интересы будут описываться не вектором товаров, а существенно меньшим вектором предпочтений.
Такие подходы еще называют спектральным разложением или высокочастотной фильтрацией (поскольку мы убираем шум и оставляем полезный сигнал). В алгебре существует много различных разложений матриц, и одно из наиболее часто используемых называется SVD-разложением (singular value decomposition).
Метод SVD применялся в конце 80-х для выборки похожих по смыслу, но не по содержанию страниц, а затем стал использоваться и в задачах рекомендаций. В основе метода — разложение исходной матрицы рейтингов ® в произведение 3 матриц:
 , где размеры матриц
, где размеры матриц  , а r —
, а r —
ранг разложения — параметр, характеризующий степень детализации разложения.
Применяя данное разложение к нашей матрице предпочтений, мы получаем две матрицы факторов (сокращенных описаний):
U — компактное описание предпочтений пользователя,
S — компактное описание характеристик продукта.
Важно, что при таком подходе мы не знаем, какие именно характеристики соответствуют факторам в уменьшенных описаниях, для нас они закодированы какими-то числами. Поэтому SVD является неинтерпретируемой моделью.
Для того, чтобы получить приближение матрицы предпочтений достаточно перемножить матрицы факторов. Сделав это получим оценку рейтинга для всех пар клиент-продукт.
Общее семейство подобных алгоритмов называется NMF (non-negative matrix factorization). Как правило вычисление таких разложений весьма трудоемко, поэтому на практике часто прибегают к их приближенным итеративным вариантам.
ALS (alternating least squares) — популярный итеративный алгоритм разложения матрицы предпочтений на произведение 2 матриц: факторов пользователей (U) и факторов товаров (I). Работает по принципу минимизации среднеквадратичной ошибки на проставленных рейтингах. Оптимизация происходит поочередно, сначала по факторам пользователей, потом по факторам товаров. Также для обхода переобучения к среднеквадратичной ошибке добавляются регуляризационные коэффиценты.
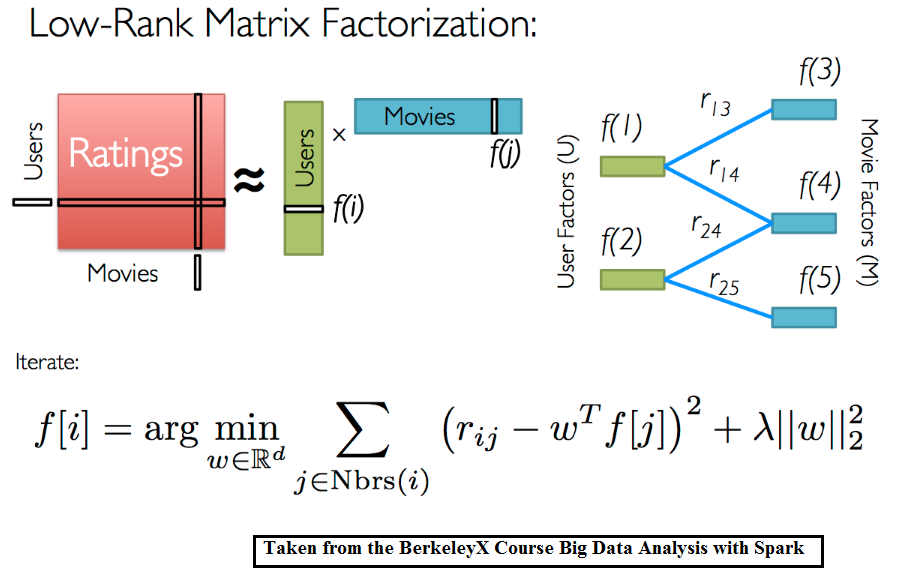
Если дополнить матрицу предпочтений новым измерением, содержащим информацию о пользователе или товаре, то мы сможем раскладывать уже не матрицу предпочтений, а тензор. Таким образом, мы задействуем больше доступной информации и возможно получим более точную модель.
Ассоциативные правила (Association Rules)
Ассоциативные правила обычно используются при анализе продуктовых корреляций (Market Basket Analysis) и выглядят примерно так «если в чеке клиента есть молоко, то в 80% случаев там будет и хлеб». То есть если мы видим, что молоко в корзину клиент уже положил, самое время напомнить о хлебе.
Это не то же самое, что анализ разнесенных во времени покупок, но если мы будем считать всю историю одной большой корзиной, то вполне можем применить данный принцип и здесь. Это может быть оправдано, когда мы, например, продаем дорогие разовые товары (кредит, полет).
RBM (restricted Bolzman Machines)
Ограниченные машины Больцмана — относительно старый подход, основанный на стохастических рекуррентных нейронных сетях. Он представляет собой модель с латентными переменными и в этом похож на SVD-разложение. Здесь также ищется наиболее компактное описание пользовательских предпочтений, которое кодируется с помощью латентных переменных. Метод не был разработан для поиска рекомендаций, но он успешно использовался в топовых решениях Netflix Prize и до сих пор применяется в некоторых задачах.
Автоэнкодеры (autoencoders)
В основе лежит все тот же принцип спектрального разложения, поэтому такие сети еще называют denoising auto-encoders. Сеть сначала сворачивает известные ей данные о пользователе в некоторое компактное представление, стараясь оставить только значимую информацию, а затем восстанавливает данные в исходной размерности. В итоге получается некий усредненный, очищенный от шума шаблон, по которому можно оценить интерес к любому продукту.
DSSM (deep sematic similiarity models)
Один из новых подходов. Все тот же принцип, но в роли латентных переменных здесь внутренние тензорные описания входных данных (embeddings). Изначально модель создавалась для матчинга запроса с документами (как и content-based рекомендации), но она легко трансформируется в задачу матчинга пользователей и товаров.
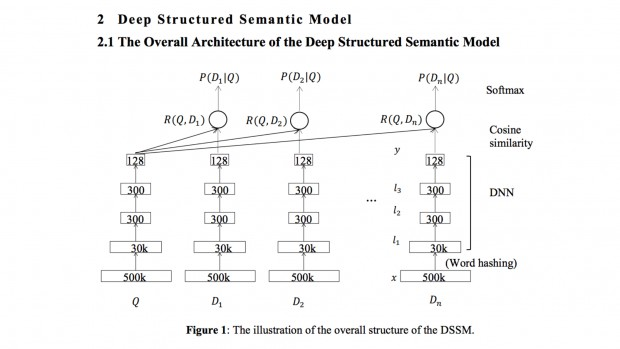
Многообразие архитектур глубоких сетей безгранично, поэтому Deep Learning предоставляет действительно широкое поле для экспериментов в области рекомендательных систем.
На практике редко используется только один подход. Как правило несколько алгоритмов комбинируются в один, чтобы достичь максимального эффекта.
Два главных преимущества объединения моделей — это увеличение точности и возможность более гибкой настройки на разные группы клиентов. Недостатки — меньшая интерпретируемость и бОльшая сложность реализации и поддержки.
Несколько стратегий объединения:
Например, используется content-based recommender, а в качестве одной из фич — результат коллаборативной фильтрации.
Feature Weighted (Linear) Stacking:
Веса обучаются на выборке. Как правило, для этого используется логистическая регрессия.
обучаются на выборке. Как правило, для этого используется логистическая регрессия.
Stacking в общем виде:

Netflix Prize — это конкурс, проводившийся в 2009 году, в котором требовалось спрогнозировать оценку пользователями фильмотеки Netflix. Неплохие призовые в 1 млн долларов вызвали ажиотаж и привлекли большое количество участников, в том числе довольно известных людей в ИИ.
Это была задача с явными рейтингами, оценки ставились по шкале от 1 до 5, а точность прогноза оценивалась по RMSE. Большинство первых мест заняли большие ансамбли классификаторов.
Победивший ансамбль использовал модели следующих классов:
В качестве мета-алгоритма, объединявшего оценки локальных алгоритмов, использовался традиционный градиентный бустинг.
Постановка задачи генерации рекомендаций очень проста — мы составляем матрицу предпочтений с известными нам оценками пользователей, если получается, дополняем эти оценки информацией по клиенту и товару, и пытаемся заполнить неизвестные значения.
Несмотря на простоту постановки, выходят сотни статей, описывающих принципиально новые методики её решения. Во-первых это связано с ростом количества собираемых данных, которые можно использовать в модели и увеличением роли implicit-рейтингов. Во-вторых, с развитием глубокого обучения и появлением новых архитектур нейронных сетей. Все это кратно увеличивает и сложность моделей.
Но в целом все это многообразие сводится к очень небольшому набору подходов, которые я и попытался описать в данной статье.

Коллаборативная фильтрация (Item-based вариант)
Подход Item-based является естественной альтернативой классическому подходу User-based, описанному в первой части, и почти полностью его повторяет, за исключением одного момента — применяется он к транспонированной матрице предпочтений. Т.е. ищет близкие товары, а не пользователей.
Напомню, пользовательская коллаборативная фильтрация (user-based CF) ищет для каждого клиента группу наиболее похожих на него (в терминах предыдущих покупок) клиентов и усредняет их предпочтения. Эти усредненные предпочтения и служат рекомендациями для пользователя. В случае же с товарной коллаборативной фильтрацией (item-based CF) ближайшие соседи ищутся на множестве товаров — столбцов матрицы предпочтений. И усреднение происходит именно по ним.
Действительно, если продукты содержательно похожи, то скорее всего они либо одновременно нравятся, либо одновременно не нравятся. Поэтому когда мы видим, что у двух товаров оценки сильно коррелируют, это может говорить о том, что это товары-аналоги.
Преимущества Item-based перед User-based:
- Когда пользователей много (почти всегда), задача поиска ближайшего соседа становится плохо вычислимой. Например, для 1 млн пользователей нужно рассчитать и хранить
 ~ 500 млрд расстояний. Если расстояние кодировать 8 байтами, это получается 4TB для одной только матрицы расстояний. Если мы делаем Item-based, то сложность вычислений снижается с
~ 500 млрд расстояний. Если расстояние кодировать 8 байтами, это получается 4TB для одной только матрицы расстояний. Если мы делаем Item-based, то сложность вычислений снижается с  до
до  , а матрица расстояний имеет размерность уже не (1 млн на 1 млн) а, например, (100 на 100) по количеству товаров.
, а матрица расстояний имеет размерность уже не (1 млн на 1 млн) а, например, (100 на 100) по количеству товаров.
- Оценка близости товаров гораздо более точная, чем оценка близости пользователей. Это прямое следствие того, что пользователей обычно намного больше, чем товаров и следовательно стандартная ошибка при расчете корреляции товаров там существенно меньше. У нас просто больше информации, чтобы сделать вывод.
- В user-based варианте описания пользователей, как правило, сильно разрежены (товаров много, оценок мало). С одной стороны это помогает оптимизировать расчет — мы перемножаем только те элементы, где есть пересечение. Но с другой стороны — сколько соседей не бери, список товаров, которые в итоге можно порекомендовать, получается очень небольшим.
- Предпочтения пользователя могут меняться со временем, но описание товаров штука гораздо более устойчивая.
В остальном алгоритм почти полностью повторяет User-based вариант: то же косинусное расстояние как основная мера близости, та же необходимость нормализации данных. Число соседних товаров N обычно выбирают в районе 20.
Из-за того, что корреляция продуктов считается на большем количестве наблюдений, не так критично ее пересчитывать после каждой новой оценки и можно это делать периодически в батчевом режиме.
Несколько возможных усовершенствований алгоритма:
- Интересная модификация — считать «похожесть» продуктов не типичным косинусным расстоянием, а сравнивая их содержание (content-based similarity). Если при этом пользовательские предпочтения никак не учитываются, такая фильтрация перестает быть «коллаборативной». При этом вторая часть алгоритма — получение усредненных оценок — никак не изменяется.
- Другая возможная модификация — при вычислении item similarity взвешивать пользователей. Например, чем больше пользователь сделал оценок, тем больший у него вес при сравнении двух товаров.
- Вместо простого усреднения оценок по соседним товарам можно подбирать веса, делая линейную регрессию.
При использовании item-based подхода рекомендации имеют тенденцию быть более консервативными. Действительно, разброс рекомендаций получается меньше и следовательно меньше вероятность показать нестандартные товары.
Если в матрице предпочтений в качестве рейтинга мы используем просмотр описания товара, то рекомендуемые товары скорее всего будут аналогами — товарами, которые часто смотрят вместе. Если же рейтинги в матрице предпочтений мы рассчитываем на основании покупок, то скорее всего рекомендуемые товары будут аксессуарами — товарами, которые часто покупают вместе.
Оценка качества системы
Тестирование рекомендательной системы — процесс непростой и всегда вызывающий множество вопросов, главным образом из-за неоднозначности самого понятия «качество».
Вообще, в задачах машинного обучения есть два основных подхода к тестированию:
- offline тестирование модели на исторических данных с помощью ретро-тестов,
- тестирование готовой модели с помощью A/B тестирования (запускаем несколько вариантов, смотрим какой дает лучший результат).
Оба этих подхода активно применяются при разработке рекомендательных систем. Начнем с offline тестирования.
Основное ограничение, с которым приходится сталкиваться — оценить точность прогноза мы можем только на тех товарах, которые пользователь уже оценил.
Стандартный подход — это кросс-валидация методами leave-one-out и leave-p-out. Многократное повторение теста с усреднением результатов позволяет получить более устойчивую оценку качества.
- leave-one-out — модель обучается на всех оцененных пользователем объектах, кроме одного, а тестируется на этом одном объекте. Так делается для всех n объектов, и среди полученных n оценок качества вычисляется среднее.
- leave-p-out — то же самое, но на каждом шаге исключается p точек.
Все метрики качества можно условно разделить на три категории:
- Prediction Accuracy — оценивают точность предсказываемого рейтинга,
- Decision support — оценивают релевантность рекомендаций,
- Rank Accuracy метрики — оценивают качество ранжирования выдаваемых рекомендаций.
К сожалению, не существует единой рекомендуемой метрики на все случаи жизни и каждый, кто занимается тестированием рекомендательной системы, подбирает её под свои цели.
Когда рейтинги оцениваются по непрерывной шкале (0-10), как правило, достаточно метрик класса Prediction Accuracy.
| Название | Формула | Описание |
|---|---|---|
| MAE (Mean Absolute Error) |  |
Среднее абсолютное отклонение |
| MSE (Mean Squared Error) |  |
Среднеквадратичная ошибка |
| RMSE (Root Mean Squared Error) |  |
Корень из среднеквадратичной ошибки |
| Название | Формула | Описание |
|---|---|---|
| Precision |  |
Доля рекомендаций, понравившихся пользователю |
| Recall |  |
Доля интересных пользователю товаров, которая показана |
| F1-Measure |  |
Среднее гармоническое метрик Precision и Recall. Полезно, когда заранее невозможно сказать, какая из метрик важнее |
| ROC AUC | Насколько высока концентрация интересных товаров в начале списка рекомендаций | |
| Precision@N | Метрика Precision, посчитанная на Top-N записях | |
| Recall@N | Метрика Recall, посчитанная на Top-N записях | |
| AverageP | Среднее значение Precision на всем списке рекомендаций |
| Название | Формула | Описание |
|---|---|---|
| Mean Reciprocal Rank |  |
На какой позиции списка рекомендаций пользователь находит первую полезную |
| Spearman Correlation | |
Корреляция (Спирмена) реального и прогнозируемого рангов рекомендаций |
| nDCG |  |
Информативность выдачи с учетом ранжирования рекомендаций |
| Fraction of Concordance Pairs |  |
Насколько высока концентрация интересных товаров в начале списка рекомендаций |
- проинформировать пользователя об интересном товаре,
- побудить его совершить покупку (путем рассылки, составления персонального предложения и т.д.).
Как и в любой модели, направленной на мотивацию пользователя к действию, оценивать следует только инкрементальный прирост целевого действия. Т.е., например, при подсчете покупок по рекомендации нам нужно исключить те, которые пользователь и так сам бы совершил без нашей модели. Если этого не сделать, эффект от внедрения модели будет сильно завышен.
Lift — показатель того, во сколько раз точность модели превосходит некий baseline алгоритм. В нашем случае baseline алгоритмом может быть просто отсутствие рекомендаций. Данная метрика хорошо отлавливает долю инкрементальных покупок и это позволяет эффективно сравнивать разные модели.
Тестирование с пользователем

Поведение пользователя вещь плохо формализуемая и ни одна метрика в полной мере не опишет мыслительные процессы в его голове при выборе товара. На решение влияет множество факторов. Переход по ссылке с рекомендуемым товаром еще не есть его высокая оценка или даже интерес. Частично понять логику клиента помогает онлайн тестирование. Ниже приводится пара сценариев такого тестирования.
Первый и самый очевидный сценарий — анализ событий сайта. Мы смотрим, что пользователь делает на сайте, обращает ли внимание на наши рекомендации, переходит ли по ним, какие фичи системы пользуются спросом, какие — нет, какие товары лучше рекомендуются, какие хуже. Чтобы понять какой из алгоритмов в целом работает лучше или просто попробовать новую перспективную идею, делаем A/B тестирование и собираем результат.
Второй сценарий — это получение фидбека от пользователей в виде опросов и голосований. Как правило, это общие вопросы для понимания, как клиенты пользуются сервисом — что важнее: релевантность или разнообразие, можно ли показывать повторяющиеся продукты, или это слишком раздражает. Преимущество сценария — он дает прямой ответ на все эти вопросы.
Подобное тестирование штука сложная, но для крупных рекомендательных сервисов она просто необходима. Вопросы могут быть и более сложными, например, «какой из списков вам кажется более релевантным», «насколько лист выглядит цельным», «будете ли вы смотреть этот фильм/читать книгу».
Неявные рейтинги и унарные данные
В начале своего развития рекомендательные системы применялись в сервисах, где пользователь явно оценивает товар путем выставления ему рейтинга — это и Amazon, и Netflix и прочие сайты интернет торговли. Однако с ростом популярности рекомендательных систем возникла потребность применять их ещё и там, где никаких рейтингов нет — это могут быть банки, автомастерские, ларьки с шаурмой и любые другие сервисы, где по какой-то причине невозможно наладить систему оценивания. В этих случаях интересы пользователя можно вычислить лишь по косвенным признакам — о пользовательских предпочтениях говорят определенные действия с товаром, например, просмотр описания на сайте, добавление товара в корзину и т.д. Здесь используется принцип «купил — значит любит!». Такая система неявного оценивания называется Implicit Ratings.
Неявные рейтинги очевидно работают хуже явных, поскольку вносят на порядок больше шума. Ведь пользователь мог купить товар в подарок жене или зайти на страницу с описанием товара, только чтобы оставить там комментарий в стиле «какая же все-таки это гадость» или удовлетворить свое природное любопытство.
Если в случае с явными рейтингами мы вправе ожидать, что хоть одну отрицательную оценку нет-нет да и поставит, то отрицательную оценку мы ниоткуда не возьмем. Если пользователь не купил книгу «Пятьдесят оттенков серого», он мог это сделать по двум причинам:
- она ему действительно не интересна (это отрицательный кейс),
- она ему интересна, но он просто не знает о ней (это пропущенный положительный кейс).
Но у нас нет никаких данных, чтобы отличить первый случай от второго. Это плохо, потому что обучая модель, мы должны подкреплять её на положительных кейсах и штрафовать на отрицательных, а так будем почти всегда штрафовать, и в итоге модель будет смещенной.
Второй кейс — это возможность оставлять только положительные оценки. Яркий пример — это кнопка Like в соцсетях. Рейтинг здесь проставляется уже явно, но так же как и в предыдущем примере, у нас нет отрицательных примеров — мы знаем, какие каналы пользователю нравятся, но не знаем, какие не нравится.
В обоих примерах задача превращается в задачу Unary Class Classification.
Самый очевидный вариант решения — идти по простому пути и считать отсутствие оценки отрицательной оценкой. В некоторых случаях это более оправдано, в некоторых — менее. Например, если мы знаем, что пользователь товар скорее всего видел (например, мы ему его показывали в списке товаров, а он перешел на товар, идущий за ним), то отсутствие перехода действительно может говорить об отсутствии интереса.

Алгоритмы факторизации
Было бы здорово описать интересы пользователя более «крупными мазками». Не в формате «он любит фильмы X, Y и Z», а в формате «он любит современные российские комедии». Помимо того, что это увеличит обобщаемость модели, это еще решит проблему большой размерности данных — ведь интересы будут описываться не вектором товаров, а существенно меньшим вектором предпочтений.
Такие подходы еще называют спектральным разложением или высокочастотной фильтрацией (поскольку мы убираем шум и оставляем полезный сигнал). В алгебре существует много различных разложений матриц, и одно из наиболее часто используемых называется SVD-разложением (singular value decomposition).
Метод SVD применялся в конце 80-х для выборки похожих по смыслу, но не по содержанию страниц, а затем стал использоваться и в задачах рекомендаций. В основе метода — разложение исходной матрицы рейтингов ® в произведение 3 матриц:
, где размеры матриц , а r — ранг разложения — параметр, характеризующий степень детализации разложения.
Применяя данное разложение к нашей матрице предпочтений, мы получаем две матрицы факторов (сокращенных описаний):
U — компактное описание предпочтений пользователя,
S — компактное описание характеристик продукта.
Важно, что при таком подходе мы не знаем, какие именно характеристики соответствуют факторам в уменьшенных описаниях, для нас они закодированы какими-то числами. Поэтому SVD является неинтерпретируемой моделью.
Для того, чтобы получить приближение матрицы предпочтений достаточно перемножить матрицы факторов. Сделав это получим оценку рейтинга для всех пар клиент-продукт.
Общее семейство подобных алгоритмов называется NMF (non-negative matrix factorization). Как правило вычисление таких разложений весьма трудоемко, поэтому на практике часто прибегают к их приближенным итеративным вариантам.
ALS (alternating least squares) — популярный итеративный алгоритм разложения матрицы предпочтений на произведение 2 матриц: факторов пользователей (U) и факторов товаров (I). Работает по принципу минимизации среднеквадратичной ошибки на проставленных рейтингах. Оптимизация происходит поочередно, сначала по факторам пользователей, потом по факторам товаров. Также для обхода переобучения к среднеквадратичной ошибке добавляются регуляризационные коэффиценты.
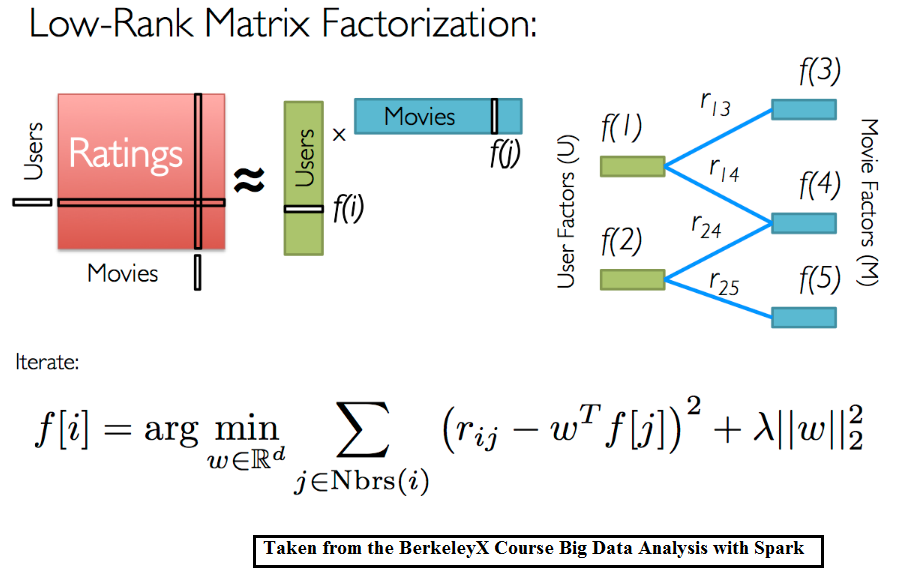
Если дополнить матрицу предпочтений новым измерением, содержащим информацию о пользователе или товаре, то мы сможем раскладывать уже не матрицу предпочтений, а тензор. Таким образом, мы задействуем больше доступной информации и возможно получим более точную модель.
Другие подходы
Ассоциативные правила (Association Rules)
Ассоциативные правила обычно используются при анализе продуктовых корреляций (Market Basket Analysis) и выглядят примерно так «если в чеке клиента есть молоко, то в 80% случаев там будет и хлеб». То есть если мы видим, что молоко в корзину клиент уже положил, самое время напомнить о хлебе.
Это не то же самое, что анализ разнесенных во времени покупок, но если мы будем считать всю историю одной большой корзиной, то вполне можем применить данный принцип и здесь. Это может быть оправдано, когда мы, например, продаем дорогие разовые товары (кредит, полет).
RBM (restricted Bolzman Machines)
Ограниченные машины Больцмана — относительно старый подход, основанный на стохастических рекуррентных нейронных сетях. Он представляет собой модель с латентными переменными и в этом похож на SVD-разложение. Здесь также ищется наиболее компактное описание пользовательских предпочтений, которое кодируется с помощью латентных переменных. Метод не был разработан для поиска рекомендаций, но он успешно использовался в топовых решениях Netflix Prize и до сих пор применяется в некоторых задачах.
Автоэнкодеры (autoencoders)
В основе лежит все тот же принцип спектрального разложения, поэтому такие сети еще называют denoising auto-encoders. Сеть сначала сворачивает известные ей данные о пользователе в некоторое компактное представление, стараясь оставить только значимую информацию, а затем восстанавливает данные в исходной размерности. В итоге получается некий усредненный, очищенный от шума шаблон, по которому можно оценить интерес к любому продукту.
DSSM (deep sematic similiarity models)
Один из новых подходов. Все тот же принцип, но в роли латентных переменных здесь внутренние тензорные описания входных данных (embeddings). Изначально модель создавалась для матчинга запроса с документами (как и content-based рекомендации), но она легко трансформируется в задачу матчинга пользователей и товаров.
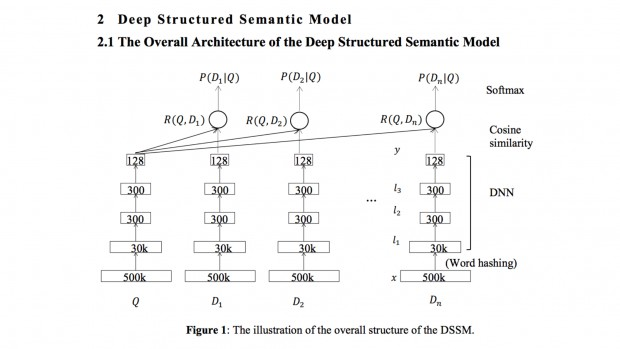
Многообразие архитектур глубоких сетей безгранично, поэтому Deep Learning предоставляет действительно широкое поле для экспериментов в области рекомендательных систем.
Гибридные решения
На практике редко используется только один подход. Как правило несколько алгоритмов комбинируются в один, чтобы достичь максимального эффекта.
Два главных преимущества объединения моделей — это увеличение точности и возможность более гибкой настройки на разные группы клиентов. Недостатки — меньшая интерпретируемость и бОльшая сложность реализации и поддержки.
Несколько стратегий объединения:
- Weighting — считать средневзвешенный прогноз по нескольким оценкам,
- Stacking — предсказания отдельных моделей являются входами другого (мета)классификатора, который обучается правильно взвешивать промежуточные оценки,
- Switching — для разных продуктов/пользователей применять различные алгоритмы,
- Mixing — вычисляются рекомендации по разным алгоритмам, а потом просто объединяются в один список.
Например, используется content-based recommender, а в качестве одной из фич — результат коллаборативной фильтрации.
Feature Weighted (Linear) Stacking:

Веса
обучаются на выборке. Как правило, для этого используется логистическая регрессия.Stacking в общем виде:

Краткое описание решения Netflix
Netflix Prize — это конкурс, проводившийся в 2009 году, в котором требовалось спрогнозировать оценку пользователями фильмотеки Netflix. Неплохие призовые в 1 млн долларов вызвали ажиотаж и привлекли большое количество участников, в том числе довольно известных людей в ИИ.
Это была задача с явными рейтингами, оценки ставились по шкале от 1 до 5, а точность прогноза оценивалась по RMSE. Большинство первых мест заняли большие ансамбли классификаторов.
Победивший ансамбль использовал модели следующих классов:
- basic model — регрессионная модель, основанная на средних оценках
- collaborative filtering — коллаборативная фильтрация
- RBM — ограниченные машины Больцмана
- random forests — предиктивная модель
В качестве мета-алгоритма, объединявшего оценки локальных алгоритмов, использовался традиционный градиентный бустинг.
Резюме
Постановка задачи генерации рекомендаций очень проста — мы составляем матрицу предпочтений с известными нам оценками пользователей, если получается, дополняем эти оценки информацией по клиенту и товару, и пытаемся заполнить неизвестные значения.
Несмотря на простоту постановки, выходят сотни статей, описывающих принципиально новые методики её решения. Во-первых это связано с ростом количества собираемых данных, которые можно использовать в модели и увеличением роли implicit-рейтингов. Во-вторых, с развитием глубокого обучения и появлением новых архитектур нейронных сетей. Все это кратно увеличивает и сложность моделей.
Но в целом все это многообразие сводится к очень небольшому набору подходов, которые я и попытался описать в данной статье.
Напоминаю про наши вакансии.

{kind=link}
{kind=link}