В стратегиях большинства компаний все чаще упоминается цифровизация: одни компании пытаются внедрять современные технологии (например, Big Data, IoT, AI, blockchain), другие — повсеместно автоматизируют свои внутренние процессы. Несмотря на растущие усилия и инвестиции во внедрение систем, многие считают результаты посредственными. В идеале современным организациям надо уметь быстро создавать новые цифровые продукты или интегрироваться с популярными сторонними сервисами; выводить процессы за пределы своей организации; уметь эффективно взаимодействовать с партнерами, сохраняя при этом обособленность своих процессов. Также надо уметь не только собирать данные, но и быстро получать к ним доступ и управлять ими. Тем не менее даже «зрелые» компании сталкиваются со сложностью преобразования и управления данными, с постоянной конкуренцией бизнес-приоритетов. Что же мешает им достичь совершенства?
Опыт нашей команды DTG в создании цифровых продуктов и сервисов позволяет утверждать — решению перечисленных задач мешает проблема трех монолитов: монолита приложений, интеграционного монолита и монолита данных. Они являются результатом унаследованных парадигм традиционной архитектуры, культуры полагаться на имеющиеся данные и работать в «слоеной» системе, где обособленность IT-департамента и бизнеса ведет к потере данных и знаний о них. Решением же данной проблемы мы видим переход от традиционных подходов разработки и управления к распределенным, что предполагает серьезные технические и культурные изменения в организации.
Но обо всем по порядку. Опишем кратко, что представляют из себя пресловутые монолиты, а затем перейдем к предлагаемым нами решениям для преодоления порождаемых монолитами сложностей.

Одна из трех архитектурных проблем при создании enterprise-решений — это монолит приложений, который появляется по мере добавления все новых и новых функций в существующее приложение. Спустя годы приложение превращается в «монстра» с большим количеством переплетенного функционала и созависимых компонентов, влекущих за собой следующие негативные моменты:
Преодолеть описанные проблемы помогают микросервисы. Смысл подхода заключается в том, что монолитное приложение разбивается на несколько маленьких приложений, состоящих из группы сервисов.

В отличие от монолитных приложений это обеспечивает гораздо большую масштабируемость, чем монолитный подход, поскольку становится возможным по мере необходимости масштабировать высоконагруженные сервисы, а не все приложение. Микросервисы позволяют нескольким командам в организации работать независимо и выпускать новые функции по своему усмотрению.
Хотя идея модульности существует уже много лет, архитектура микросервисов обеспечивает гораздо большую гибкость, позволяя организациям быстрее реагировать на меняющиеся рыночные условия.
Но не стоит наивно полагать, что микросервисы полностью избавят вашу ИТ-среду от сложности. С появлением микросервисов возникает компромисс повышения гибкости разработки при одновременном увеличении сложности управления, разработки и поддержки по причине их децентрализации. Более того, не каждое приложение в корпоративной среде подходит для архитектуры микросервисов.
Вторая архитектурная проблема, интеграционный монолит, связана с использованием интеграционной корпоративной шины (Enterprise Service Bus, ESB). Это архитектурный паттерн с единым для всего enterprise-слоем взаимодействия, обеспечивающим централизованный и унифицированный событийно-ориентированный обмен сообщениями.

В этом традиционном подходе интеграция рассматривается как промежуточный слой между слоями источников данных и их потребителей. ESB предоставляет сервисы, которые используются многими системами в рамках разных проектов. Управляет ESB только одна интеграционная команда, которая должна быть очень квалифицированной. К тому же ее трудно масштабировать. Вследствие того, что команда ESB является «бутылочным горлышком» проекта, возникает сложность выдачи изменений и растущая очередь доработок:
В монолитных архитектурах данные «покоятся». Но весь бизнес строится на потоковых событиях и требует быстрых изменений. А там, где все очень быстро меняется, использование ESB неуместно.
Решить эти проблемы помогает подход Agile Integration, который не предполагает одного централизованного интеграционного решения на всю компанию или единую команду интеграции. С его использованием появляется несколько кросс-функциональных команд разработки, которые знают, какие данные им нужны и какого качества они должны быть. Да, при таком подходе выполняемые работы могут дублироваться, но он позволяет уменьшить зависимость между различными командами и помогает вести преимущественно параллельную разработку разных сервисов.
Третья, но не менее важная архитектурная проблема — проблема монолита данных, связана с использованием централизованного корпоративного хранилища данных (Enterprise Data Warehouse, EDW). Решения с использованием EDW дорогие, они содержат данные в каноническом формате, который в силу специфических знаний поддерживает и понимает лишь одна команда специалистов, которая обслуживает всех. Данные в EDW поступают из различных источников. Команда EDW выверяет их и преобразовывает в канонический формат, который должен удовлетворить потребности различных групп потребителей внутри организации, а команда загружена. К тому же данные, преобразованные в некий канонический формат не могут быть удобны всем и всегда. Итог — требуется слишком много времени на выполнение работы с данными. Соответственно, быстро выводить новый цифровой продукт на рынок не получается.

Подобная ориентация на центральный компонент, его зависимость от изменений окружающих систем является настоящей проблемой при разработке новых цифровых процессов планировании их доработок. Изменения могут быть конфликтующими, и их согласование с другими командами еще больше замедляет работу.
Для решения проблемы монолита данных было придумано хранилище неструктурированных данных, Data Lake. Его основное отличие в том, что в Data Lake загружаются «сырые» данные, единой команды по работе с ними нет. Если бизнесу нужно получить какие-то данные для решения своей задачи, формируется команда, которая извлекает нужные для определенной задачи данные. Рядом то же самое может делать другая команда для другой задачи. Таким образом, Data Lake был введен для того, чтобы несколько команд могли одновременно работать над своим продуктом. Этот подход подразумевает, что данные могут быть дублированы в различных доменах, поскольку команды преобразуют их в форму, подходящую для разработки именно их продукта. Здесь возникает проблема — команде нужно обладать компетенциями для работы с различными форматами данных. Однако данный подход, хоть и несет в себе риск дополнительных расходов, дает бизнесу новое качество и позитивно влияет на скорость создания новых цифровых продуктов.
И лишь немногие среди продвинутых организаций используют в работе с данными еще более «зрелый» подход — Data Mesh, который наследует принципы двух предыдущих, но устраняет их недостатки. Преимуществами Data Mesh являются анализ данных в реальном времени и снижение затрат на управление инфраструктурой больших данных. Подход выступает в пользу потоковых обработок и подразумевает, что внешняя система предоставляет поток данных, который становится частью API решения-источника. За качество данных отвечает команда владельца системы, генерирующей эти данные. Чтобы максимально использовать этот подход, требуется более строгий контроль за тем, как данные обрабатываются и применяются, чтобы избежать «попадания людей в кучу бессмысленной информации». А это требует изменения мышления руководства и команды относительно того, как выстраивается взаимодействие ИТ с бизнесом. Этот подход хорошо работает в продукто-ориентированной модели, а не в проектно-ориентированной.
Подобная инфраструктура данных открывает совсем иную перспективу и способствует переходу из состояния «сохраняющей данные» в состояние «реагирующей на данные». Потоковая обработка позволяет цифровому бизнесу незамедлительно реагировать на события при генерировании данных, предоставляя интуитивно понятные средства получения аналитических данных и настроек продуктов или услуг в реальном времени, которые помогут организации идти на шаг впереди своих конкурентов.
Если обобщить, то решение проблем всех перечисленных монолитов заключается в:
В формировании ИТ-инфраструктуры современной организации не существует простых решений. А переход от традиционной архитектуры к распределенной является не только техническим преобразованием, но и культурным. Он требует изменений в мышлении относительно взаимодействия бизнеса и информационных систем. И если в организации раньше существовали монолитные приложения, то сейчас работают тысячи сервисов, которыми надо управлять, поддерживать и сопоставлять в части интерфейсов и данных. Это увеличивает расходы, увеличивает требования к квалификации людей и управлению проектами. ИТ-отдел и бизнес должны взять на себя дополнительные обязанности, и если они научатся управлять этой сложностью, то такая инфраструктура позволит бизнесу реагировать на вызовы рынка с новым более высоким качеством.
А теперь о том, что же конкретно мы в DTG используем в качестве решения «проблемы монолитов» при оптимизации цифровых процессов наших заказчиков и их интеграции в экосистему партнеров? Наш ответ – платформа класса Digital Business Technology Platform (смотрите классификацию аналитической компании Gartner). Мы назвали ее GRANUM и, по традиции, построили на комбинации open source технологий, что позволяет нам быстро и легко создавать сложные распределенные системы в корпоративной среде. Более подробно технологий мы коснемся чуть ниже. Что же стало проще и быстрее? С использованием платформы мы существенно ускорили интеграцию существующих ИТ-платформ заказчика, систем взаимодействия с клиентами, управления данными, IoT и аналитикой, смогли быстро интегрировать системы заказчика с партнерами по экосистеме для обработки бизнес-событий и принятия совместных решений для создания общей ценности. Также использование open source технологий помогло нам ответить на запросы клиентов, связанные с уходом от лицензионного ПО.
С технической точки зрения, в ходе цифровизации процессов за счет использования распределенной архитектуры (микросервисов и подхода DataMesh) нам удалось уменьшить взаимозависимость компонентов, решить проблему сложной и длительной разработки. Кроме того, мы смогли обрабатывать потоковые события в режиме реального времени, сохраняя качество данных, а также создавать доверенную среду для взаимодействия с партнерами.
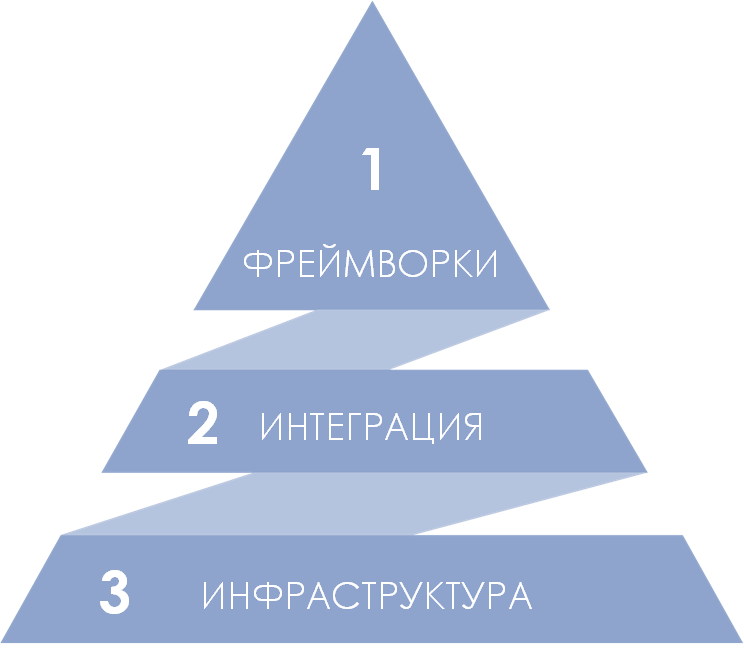
Платформу можно разбить на три логических слоя.
Расскажем более конкретно о выбранных нами open-source технологиях. Какие из них используют в своих best practice такие ведущие интернет-компании, как Netflix, LinkedIn, Spotify. Для борьбы с монолитом приложений и построения микросервисной архитектуры и работы с ней, а также в погоне за гибкостью и скоростью изменений выбирают технологии Kubernetes, Jenkins, Keycloak, Spring Boot, Fluentd, Grafana, Prometheus. Для ухода от монолитной архитектуры в рамках подхода Agile Integration обычно используют Apache Camel, NiFi, WSO2 API Manager. И, наконец, для решения проблемы монолита данных, его разбиения и перехода к анализу данных в реальном времени с использованием подхода Data Mesh полезны Kafka, Flink, Salase Event Portal.
Иллюстрация ниже представляет набор технологий, которую в результате экспериментов мы в DTG сочли оптимальным для решения проблемы трех монолитов.

Практическое применение описанной платформы мы начали около года назад и сегодня уже можем сделать выводы о том, что, независимо от отраслевой принадлежности, подобное решение вызывает интерес организаций, которые задумываются о снижении издержек на исполнение своих бизнес-процессов, повышении эффективности взаимодействия с партнерами, создании новых цепочек ценности. Такие компании нацелены на быстрые цифровые эксперименты, поставленные на поток (тестирование гипотезы, интеграцию, оперативный вывод на рынок и, в случае локального успеха, глобальное внедрение), а также позволит открыть новые каналы коммуникаций с клиентами и построить более интенсивное общение с ними в цифровом мире.
В нашей группе компаний всегда открыты интересные вакансии. Ждём вас!
Опыт нашей команды DTG в создании цифровых продуктов и сервисов позволяет утверждать — решению перечисленных задач мешает проблема трех монолитов: монолита приложений, интеграционного монолита и монолита данных. Они являются результатом унаследованных парадигм традиционной архитектуры, культуры полагаться на имеющиеся данные и работать в «слоеной» системе, где обособленность IT-департамента и бизнеса ведет к потере данных и знаний о них. Решением же данной проблемы мы видим переход от традиционных подходов разработки и управления к распределенным, что предполагает серьезные технические и культурные изменения в организации.
Но обо всем по порядку. Опишем кратко, что представляют из себя пресловутые монолиты, а затем перейдем к предлагаемым нами решениям для преодоления порождаемых монолитами сложностей.

Монолит приложений
Одна из трех архитектурных проблем при создании enterprise-решений — это монолит приложений, который появляется по мере добавления все новых и новых функций в существующее приложение. Спустя годы приложение превращается в «монстра» с большим количеством переплетенного функционала и созависимых компонентов, влекущих за собой следующие негативные моменты:
- наличие единой точки отказа (в случае сбоя в одном из модулей приложения отказывает все приложение и останавливается работа всех сотрудников, работающих с этим приложением);
- сложность в обеспечении требуемого качества разрабатываемого продукта, необходимость проведения объемного регрессионного тестирования;
- одна монолитная команда, расширять которую нецелесообразно, так как это не ускорит и не облегчит процесс разработки;
- редкие релизы и множество внутренних заказчиков в организации со своими приоритетными задачами, которым приходится выстраиваться в очередь для включения в релиз; растет как негатив со стороны заказчика, так и напряжение со стороны разработки;
- невозможность использования различных технологических стеков (а это становится все более важным в гибридных ИТ-средах). Приходится создавать и запускать целое приложение с одними и теми же языками программирования, инструментами и платформами по причине, что «так уже сделано». Да и в самом приложении обновление текущей библиотеки или переход на новую превращается в нетривиальную и высокорисковую задачу;
- сложность в масштабировании.
Преодолеть описанные проблемы помогают микросервисы. Смысл подхода заключается в том, что монолитное приложение разбивается на несколько маленьких приложений, состоящих из группы сервисов.

В отличие от монолитных приложений это обеспечивает гораздо большую масштабируемость, чем монолитный подход, поскольку становится возможным по мере необходимости масштабировать высоконагруженные сервисы, а не все приложение. Микросервисы позволяют нескольким командам в организации работать независимо и выпускать новые функции по своему усмотрению.
Хотя идея модульности существует уже много лет, архитектура микросервисов обеспечивает гораздо большую гибкость, позволяя организациям быстрее реагировать на меняющиеся рыночные условия.
Но не стоит наивно полагать, что микросервисы полностью избавят вашу ИТ-среду от сложности. С появлением микросервисов возникает компромисс повышения гибкости разработки при одновременном увеличении сложности управления, разработки и поддержки по причине их децентрализации. Более того, не каждое приложение в корпоративной среде подходит для архитектуры микросервисов.
Интеграционный монолит
Вторая архитектурная проблема, интеграционный монолит, связана с использованием интеграционной корпоративной шины (Enterprise Service Bus, ESB). Это архитектурный паттерн с единым для всего enterprise-слоем взаимодействия, обеспечивающим централизованный и унифицированный событийно-ориентированный обмен сообщениями.

В этом традиционном подходе интеграция рассматривается как промежуточный слой между слоями источников данных и их потребителей. ESB предоставляет сервисы, которые используются многими системами в рамках разных проектов. Управляет ESB только одна интеграционная команда, которая должна быть очень квалифицированной. К тому же ее трудно масштабировать. Вследствие того, что команда ESB является «бутылочным горлышком» проекта, возникает сложность выдачи изменений и растущая очередь доработок:
- интеграция возможна только через шину в рамках очередного релиза, подавать заявку в который из-за большого потока лучше за несколько месяцев;
- любые изменения могут вноситься только при согласовании их с другими потребителями, так как не все декомпозировано и изолировано. Накапливается технический долг, который со временем только увеличивается.
В монолитных архитектурах данные «покоятся». Но весь бизнес строится на потоковых событиях и требует быстрых изменений. А там, где все очень быстро меняется, использование ESB неуместно.
Решить эти проблемы помогает подход Agile Integration, который не предполагает одного централизованного интеграционного решения на всю компанию или единую команду интеграции. С его использованием появляется несколько кросс-функциональных команд разработки, которые знают, какие данные им нужны и какого качества они должны быть. Да, при таком подходе выполняемые работы могут дублироваться, но он позволяет уменьшить зависимость между различными командами и помогает вести преимущественно параллельную разработку разных сервисов.
Монолит данных
Третья, но не менее важная архитектурная проблема — проблема монолита данных, связана с использованием централизованного корпоративного хранилища данных (Enterprise Data Warehouse, EDW). Решения с использованием EDW дорогие, они содержат данные в каноническом формате, который в силу специфических знаний поддерживает и понимает лишь одна команда специалистов, которая обслуживает всех. Данные в EDW поступают из различных источников. Команда EDW выверяет их и преобразовывает в канонический формат, который должен удовлетворить потребности различных групп потребителей внутри организации, а команда загружена. К тому же данные, преобразованные в некий канонический формат не могут быть удобны всем и всегда. Итог — требуется слишком много времени на выполнение работы с данными. Соответственно, быстро выводить новый цифровой продукт на рынок не получается.

Подобная ориентация на центральный компонент, его зависимость от изменений окружающих систем является настоящей проблемой при разработке новых цифровых процессов планировании их доработок. Изменения могут быть конфликтующими, и их согласование с другими командами еще больше замедляет работу.
Для решения проблемы монолита данных было придумано хранилище неструктурированных данных, Data Lake. Его основное отличие в том, что в Data Lake загружаются «сырые» данные, единой команды по работе с ними нет. Если бизнесу нужно получить какие-то данные для решения своей задачи, формируется команда, которая извлекает нужные для определенной задачи данные. Рядом то же самое может делать другая команда для другой задачи. Таким образом, Data Lake был введен для того, чтобы несколько команд могли одновременно работать над своим продуктом. Этот подход подразумевает, что данные могут быть дублированы в различных доменах, поскольку команды преобразуют их в форму, подходящую для разработки именно их продукта. Здесь возникает проблема — команде нужно обладать компетенциями для работы с различными форматами данных. Однако данный подход, хоть и несет в себе риск дополнительных расходов, дает бизнесу новое качество и позитивно влияет на скорость создания новых цифровых продуктов.
И лишь немногие среди продвинутых организаций используют в работе с данными еще более «зрелый» подход — Data Mesh, который наследует принципы двух предыдущих, но устраняет их недостатки. Преимуществами Data Mesh являются анализ данных в реальном времени и снижение затрат на управление инфраструктурой больших данных. Подход выступает в пользу потоковых обработок и подразумевает, что внешняя система предоставляет поток данных, который становится частью API решения-источника. За качество данных отвечает команда владельца системы, генерирующей эти данные. Чтобы максимально использовать этот подход, требуется более строгий контроль за тем, как данные обрабатываются и применяются, чтобы избежать «попадания людей в кучу бессмысленной информации». А это требует изменения мышления руководства и команды относительно того, как выстраивается взаимодействие ИТ с бизнесом. Этот подход хорошо работает в продукто-ориентированной модели, а не в проектно-ориентированной.
Подобная инфраструктура данных открывает совсем иную перспективу и способствует переходу из состояния «сохраняющей данные» в состояние «реагирующей на данные». Потоковая обработка позволяет цифровому бизнесу незамедлительно реагировать на события при генерировании данных, предоставляя интуитивно понятные средства получения аналитических данных и настроек продуктов или услуг в реальном времени, которые помогут организации идти на шаг впереди своих конкурентов.
Распределенные подходы
Если обобщить, то решение проблем всех перечисленных монолитов заключается в:
- разделении системы на отдельные блоки, ориентированные на бизнес-функции;
- выделении независимых команд, каждая из которых может создавать и эксплуатировать бизнес-функцию;
- распараллеливании работ между этими командами с целью повышения масштабируемости, скорости.
В формировании ИТ-инфраструктуры современной организации не существует простых решений. А переход от традиционной архитектуры к распределенной является не только техническим преобразованием, но и культурным. Он требует изменений в мышлении относительно взаимодействия бизнеса и информационных систем. И если в организации раньше существовали монолитные приложения, то сейчас работают тысячи сервисов, которыми надо управлять, поддерживать и сопоставлять в части интерфейсов и данных. Это увеличивает расходы, увеличивает требования к квалификации людей и управлению проектами. ИТ-отдел и бизнес должны взять на себя дополнительные обязанности, и если они научатся управлять этой сложностью, то такая инфраструктура позволит бизнесу реагировать на вызовы рынка с новым более высоким качеством.
А теперь о том, что же конкретно мы в DTG используем в качестве решения «проблемы монолитов» при оптимизации цифровых процессов наших заказчиков и их интеграции в экосистему партнеров? Наш ответ – платформа класса Digital Business Technology Platform (смотрите классификацию аналитической компании Gartner). Мы назвали ее GRANUM и, по традиции, построили на комбинации open source технологий, что позволяет нам быстро и легко создавать сложные распределенные системы в корпоративной среде. Более подробно технологий мы коснемся чуть ниже. Что же стало проще и быстрее? С использованием платформы мы существенно ускорили интеграцию существующих ИТ-платформ заказчика, систем взаимодействия с клиентами, управления данными, IoT и аналитикой, смогли быстро интегрировать системы заказчика с партнерами по экосистеме для обработки бизнес-событий и принятия совместных решений для создания общей ценности. Также использование open source технологий помогло нам ответить на запросы клиентов, связанные с уходом от лицензионного ПО.
С технической точки зрения, в ходе цифровизации процессов за счет использования распределенной архитектуры (микросервисов и подхода DataMesh) нам удалось уменьшить взаимозависимость компонентов, решить проблему сложной и длительной разработки. Кроме того, мы смогли обрабатывать потоковые события в режиме реального времени, сохраняя качество данных, а также создавать доверенную среду для взаимодействия с партнерами.

Платформу можно разбить на три логических слоя.
- Нижний слой — инфраструктурный. Предназначен для обеспечения базовых сервисов. Туда входит безопасность, мониторинг и анализ логов, управление контейнерами, сетевая маршрутизация (балансировка нагрузки), девопс.
- Интеграционный слой — поддерживает распределенную архитектуру (подход DataMesh, микросервисы и стриминговую обработку данных).
- Слой фреймворков — в нем находится полезный для бизнеса функционал. В нашей платформе уже представлены фреймворки для отслеживания продукции (track&trace), межкорпоративного взаимодействия, маркировки и другие решения. Этот слой планируется расширять другими фреймворками.
Расскажем более конкретно о выбранных нами open-source технологиях. Какие из них используют в своих best practice такие ведущие интернет-компании, как Netflix, LinkedIn, Spotify. Для борьбы с монолитом приложений и построения микросервисной архитектуры и работы с ней, а также в погоне за гибкостью и скоростью изменений выбирают технологии Kubernetes, Jenkins, Keycloak, Spring Boot, Fluentd, Grafana, Prometheus. Для ухода от монолитной архитектуры в рамках подхода Agile Integration обычно используют Apache Camel, NiFi, WSO2 API Manager. И, наконец, для решения проблемы монолита данных, его разбиения и перехода к анализу данных в реальном времени с использованием подхода Data Mesh полезны Kafka, Flink, Salase Event Portal.
Иллюстрация ниже представляет набор технологий, которую в результате экспериментов мы в DTG сочли оптимальным для решения проблемы трех монолитов.

Практическое применение описанной платформы мы начали около года назад и сегодня уже можем сделать выводы о том, что, независимо от отраслевой принадлежности, подобное решение вызывает интерес организаций, которые задумываются о снижении издержек на исполнение своих бизнес-процессов, повышении эффективности взаимодействия с партнерами, создании новых цепочек ценности. Такие компании нацелены на быстрые цифровые эксперименты, поставленные на поток (тестирование гипотезы, интеграцию, оперативный вывод на рынок и, в случае локального успеха, глобальное внедрение), а также позволит открыть новые каналы коммуникаций с клиентами и построить более интенсивное общение с ними в цифровом мире.
В нашей группе компаний всегда открыты интересные вакансии. Ждём вас!
