Ещё не предел: 4 000 ручных проверок интерфейсов в день
Невозможно зайти в мобильное приложение, записаться к врачу, оплатить покупку в интернет-магазине, не работают кассы, подрядчик нарушает SLA по доступности сервисов, а инженеры поддержки приступают к поиску проблем после жалоб пользователей и проверяют вручную десятки, а иногда и сотни информационных систем – типичный процесс эксплуатации в быстро развивающихся и сильно зависящих от стабильной работы IT крупных компаниях. Инженерам сложно выполнять KPI по доступности и проактивно работать со сбоями, а бизнес несет финансовые и репутационные потери.
Один из принципов организации зонтичного мониторинга заключается в том, что оценка состояния IT-окружения и его влияния на стабильность бизнеса становятся приоритетными задачами для команды мониторинга и поддержки IT-инфраструктуры и бизнес-сервисов. В этом контексте, важность взгляда на сервисы со стороны пользователей поднимается на один уровень с традиционными инструментами мониторинга.
Помочь справиться с валом ручных проверок пользовательских интерфейсов в растущих и разнородных инфраструктурах может синтетический мониторинг. Именно он позволяет создавать и автоматизированно выполнять сценарии и тесты, имитирующие действия реальных пользователей. После чего результаты таких тестов анализируются, выявляя возможные проблемы и узкие места в инфраструктуре и приложениях до того, как они начнут массово влиять на конечных пользователей.
Рассказываем, как устроен синтетический мониторинг в платформе зонтичного мониторинга Monq – и как с его помощью клиент, который проверял вручную 80 информационных систем по пяти сценариям (это давало в общей сложности 400 сценариев для обработки, которые запускали вручную минимум 10 раз в день; в сумме получалось 4 000 ежедневных ручных проверок; на каждую проверку уходило минимум 20 минут; на проверках были заняты 50 инженеров и 22 подрядчика) – смог полностью автоматизировать тестирование интерфейсов.
Принципы автотестирования в Monq
Monq не имеет собственной среды тестирования и работает только с внешними. Однако платформа умеет:
выступать в роли планировщика;
принимать отчеты;
обрабатывать их результаты;
визуализировать взаимосвязи;
создавать Сигналы в случае провала сборок;
на основе Сигналов выполнять уведомления, запускать скрипты, выполнять другую автоматизацию.
У платформы есть два вида взаимодействия с внешней средой тестирования:
Автономные проекты. В этом случае у среды тестирования есть собственный планировщик (как например GitLab CI, Travis, Jenkins и др.). Конфигурация и выполнение тестов – по какому расписанию запускать, какие библиотеки для тестов и отчетов использовать – происходит там. Monq в этом случае только принимает отчет, сгенерированный и отправленный по API системой тестирования.
Управляемые проекты, когда в качестве планировщика синтетического мониторинга выступает агент Monq, установленный на сервер среды тестирования. В таком случае расписание заданий, переменные среды окружения и команда запуска задаются в самой платформе и выполняются с помощью её агента.
В обоих случаях среда тестирования после выполнения теста должна сгенерировать zip-отчет и по API отправить его в Monq.
Рассмотрим подробнее, как настраиваются Управляемые проекты в Monq.
Исходим из того, что у нас уже есть настроенная среда тестирования с использованием Selenium WebDriver, фреймворка отчётов автотестов Allure и написан pytest для проверки доступности сайта документации.
1. Первый шаг: конфигурация автотест-проекта. В проекте необходимо написать задание на YAML.
Это может быть как простейшая CMD/SH-команда, указывающая, какой скрипт на тест-сервере необходимо запустить, так и более сложное задание, с указанием переменных, которые необходимо передать в удаленный скрипт, а также последовательность шагов. Пример такого задания может иметь следующий вид:

Далее, поскольку в управляемом проекте планировщиком выступает сам Monq, необходимо задать расписание запуска. Оно указывается в формате CRON. Допустим, тест будет выполняться каждые полчаса: в 15 и 45 минут:

Затем нужно указать метку агента, предварительно установленного на сервер тестирования. Именно он и будет выполнять описанное задание.

Далее - указать, к какой Конфигурационной Единице на карте РСМ будет привязываться результат теста.

2. Второй шаг: настройка сценария парсинга. Независимо от типа проекта в систему будут поступать отчеты. Чтобы обрабатывать их содержимое, необходимо на low-code движке автоматизации создать сценарий парсинга. Готовый демонстрационный сценарий парсинга для отчетов в формате Allure можно импортировать из нашего GitHub-канала и после импорта его нужно будет только скомпилировать и активировать.

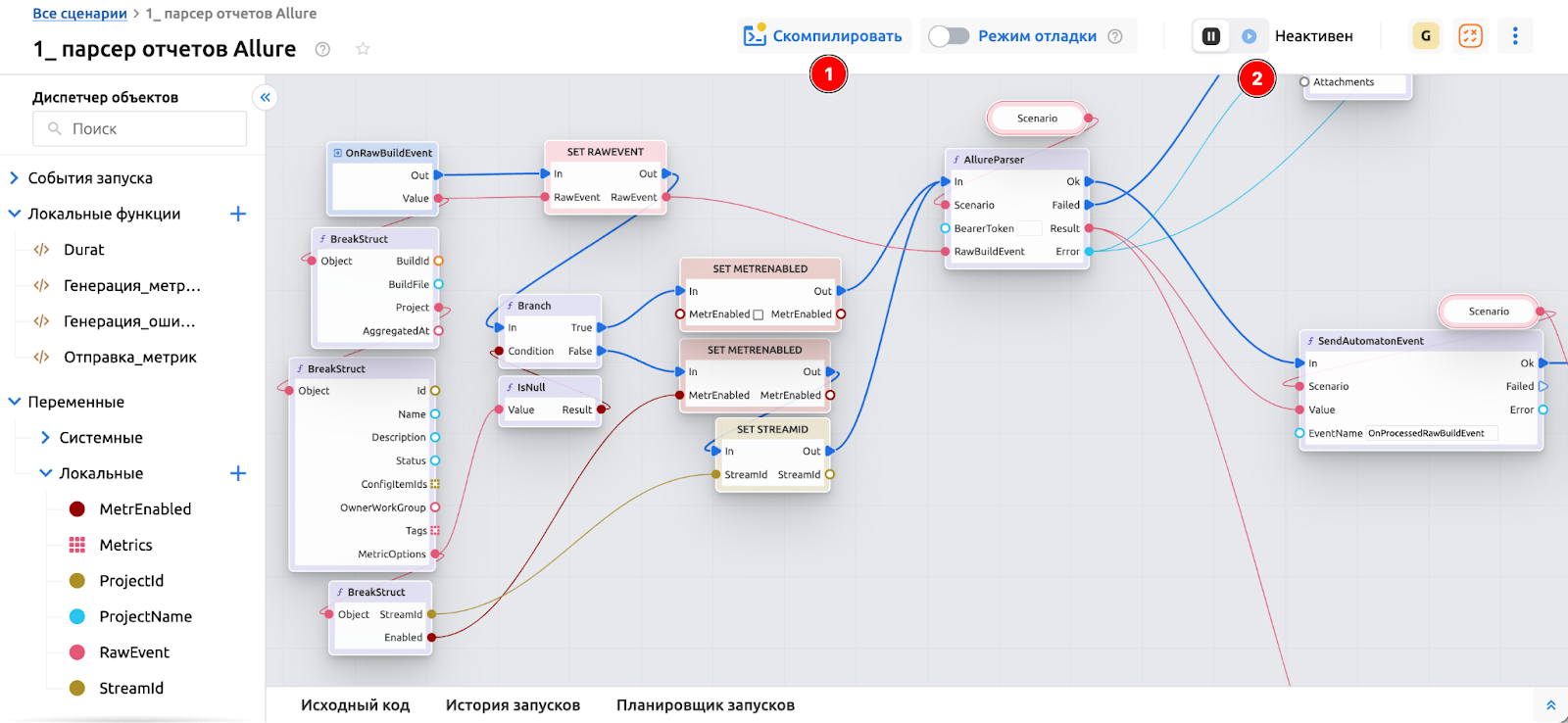
Уже с этими минимальными настройками система начнет принимать, обрабатывать и отображать результаты сборок.

3. Шаг третий: генерация Сигналов. Для любой автоматизации, будь то уведомление на почту, заведение заявки во внешней Сервис-деск системе или запуск автохилинг-скрипта – необходим Сигнал. Чтобы в случае провального теста открывался соответствующий сигнал, необходим второй сценарий: создания сигналов. Его также можно импортировать из готовых примеров на GitHub.


Теперь, если в сборке автотестов будет присутствовать провальный шаг, в системе будет открываться соответствующий сигнал.
На этом базовая настройка завершена. Теперь создаваемые Сигналы будут привязываться к той же Конфигурационной Единице, к которой мы прикрепили Автотест-проект. Здоровье этой КЕ будет снижаться в случае поврежденного zip-отчета, проваленного шага/кейса/теста, а если на карте РСМ настроены связи влияния, то наша автотест-КЕ снизит здоровье зависимых.
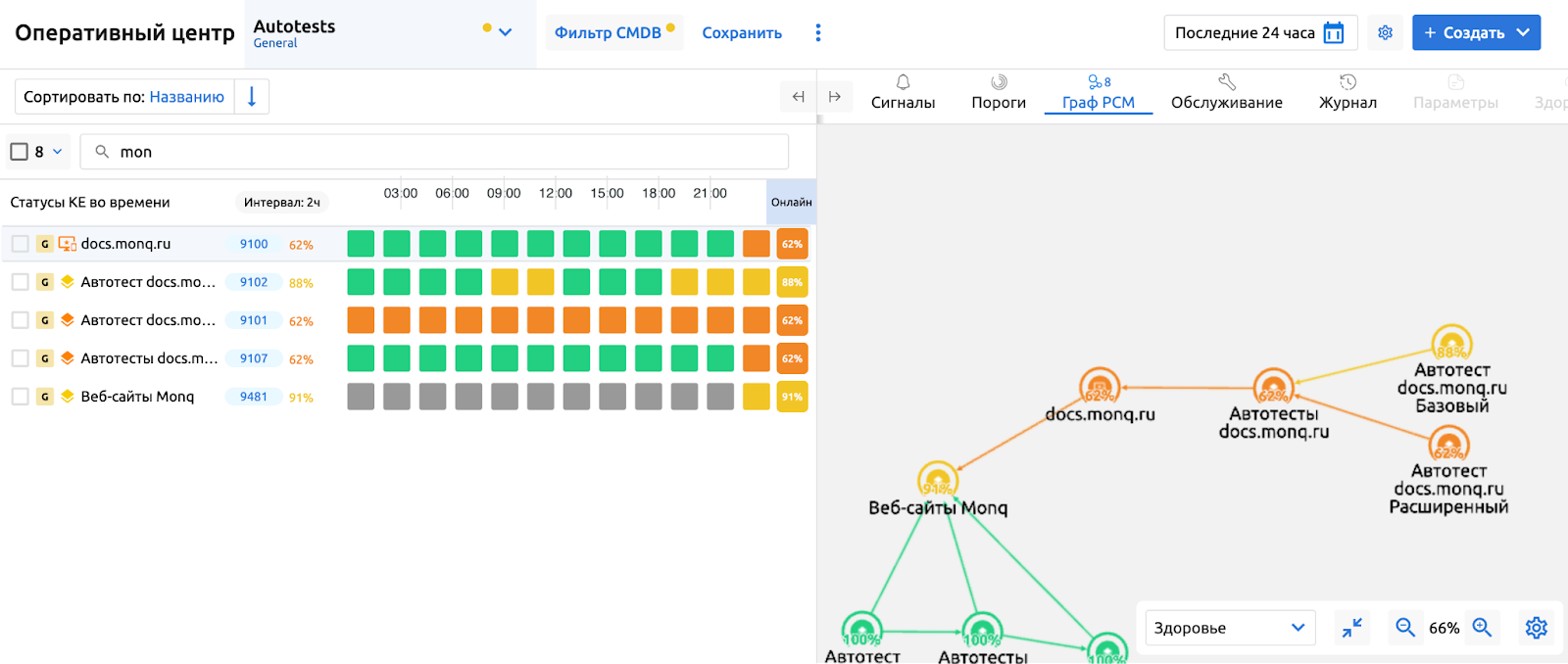

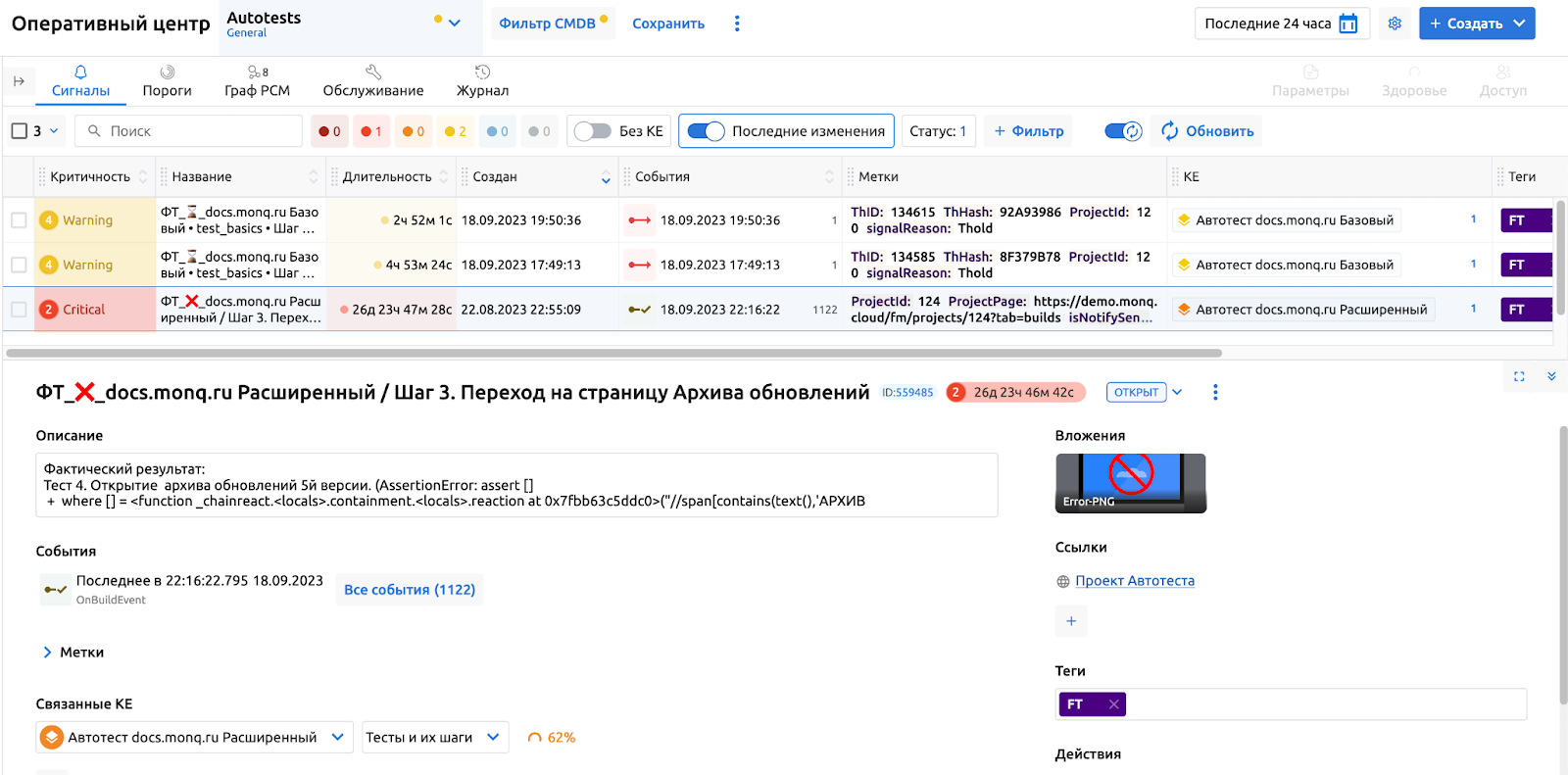
На этом можно остановиться. А можно настроить:
Правила, при выполнении условий которых будут выполняться…
Действия, такие, как запуск скриптов или отправка уведомлений на любые поддерживающие API системы.
Это может быть как извещение ответственных за сервис команд, так и открытие кейса во внешней сервис-деск системе, webhook-запрос или запуск скрипта рестарта службы, расположенного на удаленном сервере.

При желании можно пойти еще дальше: допилить low-code сценарий парсинга, добавить еще несколько других (также готовых демонстрационных) и настроить Правила порогов метрик – и тогда из автотестов, помимо прочей информации, можно будет еще и генерировать метрики/временные ряды (например, времени выполнения шагов тестов). И уже по ним создавать отдельные сигналы, тоже привязывать к КЕ и получать еще более обогащенную модель информационной системы.

Информация об этом есть на нашем YouTube-канале: тут и тут, а также в этой статье.
Результаты тестирования каких интерфейсов можно обрабатывать с помощью Monq?
Monq принимает и обрабатывает результаты любых внешних систем тестирования без ограничений – веб-интерфейсов, CRM, мобильных приложений, телефонии и др.
От ручного тестирования к полной автоматизации
Клиент, чьи инженеры ранее тратили массу времени на ручное тестирование 87 информационных систем, теперь нашел эффективное решение в лице Monq. Он полностью автоматизировал процесс мониторинга пользовательских интерфейсов. Как именно это было достигнуто?
к платформе подключили все ИС и связку Zabbix+Jenkins+Selenium+Allurе;
запустили автоматическое тестирование: в среднем 3-7 тестов по 10 шагов на каждую систему;
настроили более 7 000 метрик и более 2600 триггеров;
настроили автоэскалацию событий, их автоматическую регистрацию в ITSM,
настроили оповещение ответственных команд, подсказки для инженеров по разрешению проблем;
настроили скрипты автохилинга для рутинных задач.
Интересно отметить, что в начале проекта мониторинг был нацелен на простые внешние и внутренние системы, включая тестирование авторизации, доступности контента и прочих базовых функций. Однако по мере развития проекта были успешно подключены и более сложные системы, требующие проверки ЭЦП и состава документов в формате Word.
В результате этой трансформации, их инженеры переключились на проактивное и оперативное решение проблем, что позволило значительно повысить эффективность мониторинга и обеспечить более стабильную работу информационных систем.
Кстати
Функционал синтетического мониторинга в Monq бесплатный – получить бесплатный ключ можно по ссылке.
Если есть вопросы - добро пожаловать в комментарии или в коммьюнити.
