Хабр, привет.
Как вы знаете, для обучения глубоких нейронных сетей оптимально использовать машины с GPU. Наши образовательные программы всегда имеют практический уклон, поэтому для нас было обязательно, чтобы во время обучения у каждого участника была своя виртуальная машина с GPU, на которой он мог решать задачи во время занятий, а также лабораторную работу в течение недели. О том, как мы выбирали инфраструктурного партнера для реализации наших планов и подготавливали среду для наших участников, и пойдет речь в нашем посте.
Планы запустить образовательную программу по Deep Learning у нас были еще с начала этого года, но к непосредственному дизайну программы мы перешли в августе. Примерно тогда же Microsoft Azure заявил, что на их платформе появились в preview формате GPU-виртуалки. Для нас это было приятной новостью, потому что на нашей основной программе по большим данным Microsoft является инфраструктурным партнером. Была идея не плодить зоопарк, и в конце ноября просто воспользоваться их готовым решением (не preview). В середине ноября стало понятно, что Microsoft не торопится выходить из preview и делать GPU доступными в рамках своей облачной экосистемы. Мы оказались перед фактом, что нужно срочно искать что-то другое.
Чуть позже нам удалось довольно оперативно договориться о сотрудничестве в этой области с облачной платформой на базе IBM Bluemix Infrastructure (ранее Softlayer), и компания IBM стала нашим инфраструктурным партнером по этой программе. Увы, без подводных камней не обошлось. Мы первый раз, на ходу, знакомились с возможностями IBM Bluemix. Изначально мы рассчитывали, что получим готовые виртуальные машины с GPU для каждого из участников. Но поскольку на Bluemix GPU доступны только в серверах Bare-metal (выделенные физические серверы), которые можно как конструктор заказать в нужной конфигурации, и получить за несколько часов, то в итоге мы получили мощный физический сервер на платформе Supermicro с двумя процессорами Intel Xeon E5-2690v3, 128 Гб памяти и с двумя карточками NVIDIA Tesla M60 (на каждой карточке по 2 чипа GM204GL поколения Maxwell и 16 Гб видеопамяти), на который мог быть предустановлен гипервизор на выбор (VMware, Xen или Hyper-V), что тоже очень неплохо! Нам оставалось только разбить это шустрое железо на нужное количество виртуалок и все. Только вот мы не планировали этого этапа с самого начала. Вот тут и возникла основная проблема, которую мы решали довольно долго.
Для проведения практических работ участникам нашей программы требовались виртуальные машины с GPU поддерживающими NVIDIA CUDA и ОС на основе GNU/Linux (мы чаще всего используем Ubuntu 14.04 LTS для наших задач, как удобный в эксплуатации и достаточно простой дистрибутив с хорошей поддержкой сообщества). Соответственно, в первую очередь необходимо было выбрать платформу виртуализации, которая поддерживала бы либо “проброс” (passthrough) видеокарт в гостевую Linux систему, либо (что интереснее) поддержку виртуальных GPU для гостевых ОС.
В первую очередь решили рассмотреть VMware Vsphere 6, как одно из лидирующих на этом рынке решений. Благо установка данного гипервизора и все требуемые лицензии доступны прямо из панели управления IBM SoftLayer, то есть установка гипервизора проводится буквально в несколько кликов мыши (не забываем, что мы работаем с выделенным сервером). В VMware заявлена поддержка технологии GRID Virtual GPU (vGPU), то есть имеется возможность разделения одного ядра видеоадаптера на несколько виртуальных и подключения такого GPU к гостевой системе. Достаточно подробно все описывается в соответствующем документе от NVidia. Данная технология по большей части ориентирована на использование в решениях VDI, где требуется ускорение 3D графики для гостевых систем на основе Windows, что в нашем случае не очень подходит. При более подробном изучении документа от NVidia можно узнать, что при использовании vGPU имеется понятие профилей vGPU, то есть по сути того, на сколько vGPU можно разделить одно ядро видеоускорителя. Профиль vGPU задает выделяемое количество видеопамяти, максимальное количество поддерживаемых дисплеев и так далее. Таким образом используя различные профили можно разбить NVidia Tesla M60 на количество виртуальных машин от 1 до 32. Интересно.
НО! Если еще более подробно вчитаться в документ, то можно обнаружить, что поддержка CUDA на гостевых Linux системах доступна только с профилем GRID M60-8Q, что по сути является просто пробросом одного из чипов GPU Tesla M60 (напомним, что Tesla M60 состоит из 2-х чипов) в одну виртуальную машину. В итоге при любом раскладе имея 2 карты Tesla M60 для работы с CUDA можно получить максимум 4 виртуалки для гостевой ОС Linux.
Отдельно стоит упомянуть, что для работы с vGPU требуется дополнительное лицензирование от NVidia (основы тут) и чтобы получить драйверы для гипервизора и гостевых систем необходимо эти лицензии получить. Также драйвера в гостевых системах требуют сервера лицензий NVidia, который необходимо установить самостоятельно, и поддерживается только ОС семейства Windows. Помимо этого vGPU поддерживается только на релизе Vsphere 6 Enterprise Plus, который мы как раз и использовали.
В итоге решено отказаться от vGPU и просто “пробросить” видеокарты в гостевые системы, таким образом можно получить 4 виртуальные машины, каждой из которых будет доступен один чип Tesla M60 с 8 Гб видеопамяти. vSphere поддерживает PCI-Passthrough, соответственно, проблем быть не должно, но они появились.
Карточки Tesla были настроены для passthrough в виртуальные машины. На одну из машин добавили PCI устройство, но при запуске машины появлялась ошибка “PCI passthrough device id invalid”, оказалась что данная проблема проявляется только в веб-интерфейсе vSphere, если использовать Windows-клиент и заново добавить устройство, такая проблема не возникает, но появляется другая, более общая, что-то вроде “starting VM … general error”. Немного изучив происхождение ошибки, мы перепробовали различные варианты:
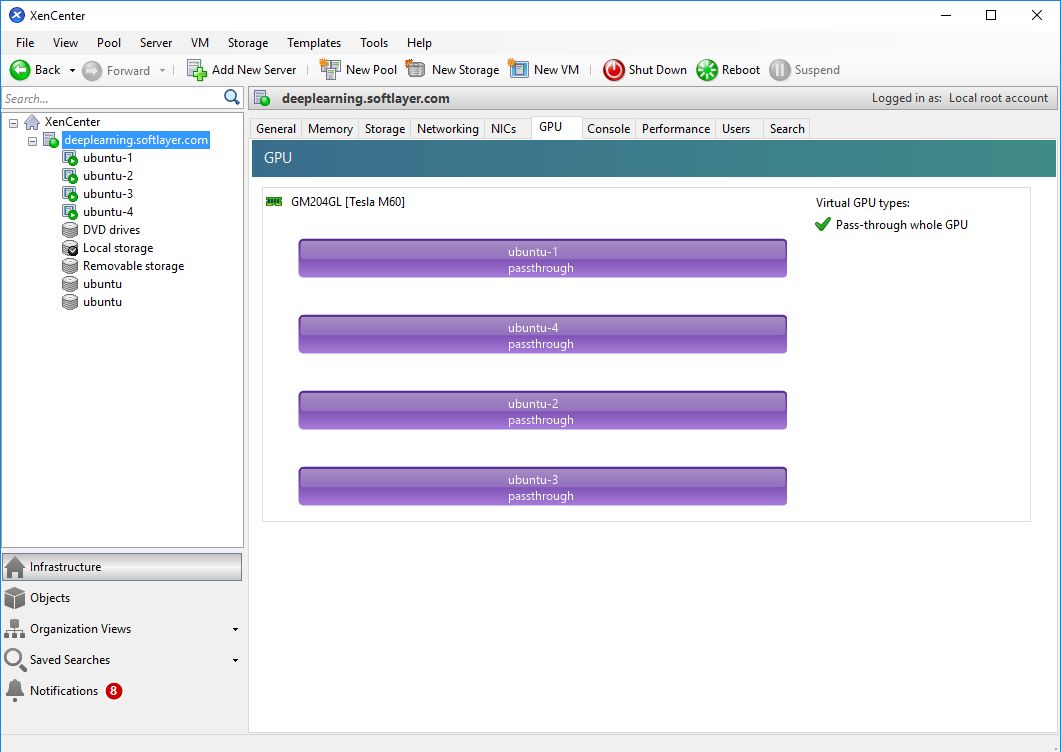
Но все тщетно. PCI Passthrough у нас не работал. Учитывая что времени было все меньше и меньше, решили прекратить наши изыскания и попробовать Citrix XenServer. Данный гипервизор широко используется для VDI решений. Благо что из панели управления SoftLayer можно одним кликом мыши запустить переустановку гипервизора и выбрать XenServer. Надо отметить что его автоматизированная установка и настройка заняла у платформы Bluemix приличное время (около 8 часов в нашем случае). Так что важно закладывать необходимое время на данную процедуру. Дальше эта история была достаточно скучной, все заработало практически сразу “из коробки”. В данном случае был доступен такой же вариант с Passthrough режимом. Каждый из 4-х чипов GM204GL из двух адаптеров Testa M60 пробросили в отдельную виртуальную машину, настроили виртуальную сеть, установили стандартные драйвера NVidia для Tesla M60 под Linux и все завелось. Для настройки XenServer удобно использовать Citrix XenCenter, вот как выглядят проброшенные видеокарты в его GUI:
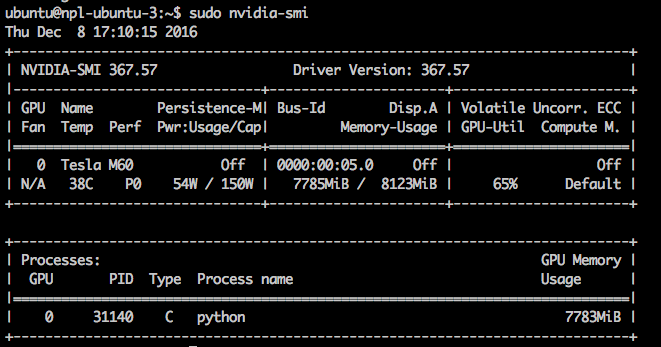
Вот так через утилиту nvidia-smi администратору можно наблюдать, что процесс python (участники использовали библиотеки Keras и Caffe) использует большую часть памяти GPU.
В связи со всеми этими внеплановыми изысканиями нарезать работающие как надо виртуалки нам удалось только к последнему из дней нашей программы. В результате неделю ребята занимались на g2.2xlarge инстансах платформы AWS, поскольку мы не могли себе позволить остаться без нужного оборудования, а нарезанные виртуалки IBM Bluemix решили дать участникам еще на неделю после окончания программы в качестве бонуса, чтобы они могли еще порешать задачи, связанные с deep learning.
Мы решили сравнить, какое из решений является более эффективным с точки зрения производительности и стоимости содержания парка.
Посчитаем, сколько, например, будут стоить оба варианта при условии использования инфраструктуры в течение двух недель, с 16 участниками. Наш use case не совсем стандартный, потому что мы хотели выдать каждому участнику отдельную виртуалку.
AWS: 0.65$ * 24ч * 15 дней * 16 участников = 3 744$
IBM Bluemix: 2961.1$/мес / 2 (2 недели) * 4 = 5 922.2$ (сервер с 2xM60) ссылка на конфигурацию
Или если взять эквивалент, более близкий к g2.2xlarge:
2096,40 $/мес / 2(2 недели) * 4 = 4192,8$ (сервер с 2хK2 (GK104) GPU — аналог AWS) ссылка на конфигурацию
В нашем варианте разница в деньгах получается существенная — почти 2 тыс. долл. При использовании более современной GPU, но и производительность во втором случае оказывается выше:
AWS: 1gpu, 8cores, 15gb ram (GK 104 на базе GRID K520)
IBM: 1 gpu, 12 cores, 32gb ram (GM 204 на базе М60)
Больше ядер, больше памяти, более современная GPU следующего поколения, да и производительность сама по себе еще выше. Провели небольшой бенчмарк, обучив сеть LeNet, распознающую рукописные цифры, при помощи Caffe на 10 тыс. итераций. На виртуалке AWS это заняло 45.5 секунд, на виртуалке IBM — 26.73 секунды, то есть в 1.7 раз быстрее. На большем промежутке времени это может быть более весомо: 24 часа против 14 часов. Или за две недели это бы дало экономию в 6 дней, которые можно было потратить на обучение чего-то еще.
Коллеги из IBM поделились еще другим сценарием использования — видео стриминг. В AWS использовались те же самые 16 машин g2.2xlarge, а в IBM только один сервер 2хM-60 для гостевых VM Windows. По производительности они были сопоставимы, обслуживая одно и то же количество видеопотоков. За те же самые 2 недели расход в IBM составит — 1 422.72$, что дешевле на более, чем 2 000 долл. конфигурации в AWS. Так что в зависимости от ваших задач, та или иная конфигурация могут быть для вас выгоднее. Также коллеги из IBM намекнули, что могут предоставить более выгодные условия, даже при аренде одного такого сервера, в AWS же скидки применяются автоматически только при значительном потреблении сервисов на десятки тысяч $.
Также важно отметить что только на платформе Bluemix сейчас доступны GPU поколения Maxwell. На момент написания поста им не было аналогов у других публичных облачных платформ. Если что, прямая ссылка на конфигуратор тут.
В нашем сравнении мы не затрагиваем тему сравнения платформы с платформой, т.к. эти сервисы представляют собой совершенно разный подход. IBM Bluemix фокусируется больше на предоставлении инфраструктурных сервисов (Softlayer) и в то же время предлагает своим клиентам сервисы PaaS Bluemix (Аналитика, большие данные, виртуальные контейнеры и т.д.). AWS сфокусирован на виртуальных сервисах и PaaS, за основу взят KVM гипервизор, Azure же в свою очередь сконцентрирован на всем стеке Microsoft.
Очевидно, что не до конца справедливо сравнивать лоб в лоб цены тех или иных решений у разных провайдеров, нужно понимать что вы получаете за эту цену! Например, если вдаваться в подробности и изучать документацию, выяснится, что AWS и Azure за каждое обращение в техническую поддержку взимает с клиента деньги, IBM Bluemix — нет. Если у вас сервисы находятся в разных географически разнесенных ЦОДах, то в случае Azure и AWS за трафик внутри сети ЦОДов оплачивает клиент, в то время как в IBM Bluemix трафик внутри сети для клиентов бесплатен и т.д. Можно еще много всяких нюансов обнаружить в функциональной, практической, и юридической плоскости. На наш взгляд, если вам нужно максимально персонализированное решение, и речь идет о значительных рабочих нагрузках, то выбор Bluemix оптимален, т.к. вы полностью администрируете и управляете ресурсами и любой сервис прозрачен, в то же время если вам нужно несколько рабочих станций максимально готовых к использованию (требуют наименьшего администрирования) и вам не критична производительность, то Azure и AWS идеально вам подойдут.
Итог таков, что несмотря на все сложности, которые мы испытывали, первый запуск программы Deep Learning можно считать успешным. По итогам нашего опроса мы получили следующие результаты:
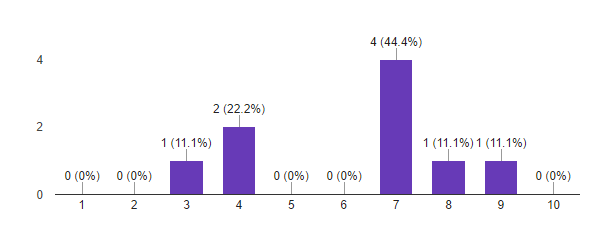
1. Насколько ваши ожидания от курса совпали с реальностью?
По шкале от 1 до 10: 1 — ожидания полностью не оправдались, 10 — курс превзошел все мои ожидания.
2. Каков главный результат вы получили от программы?

3. Как планируете применять полученные знания и навыки?

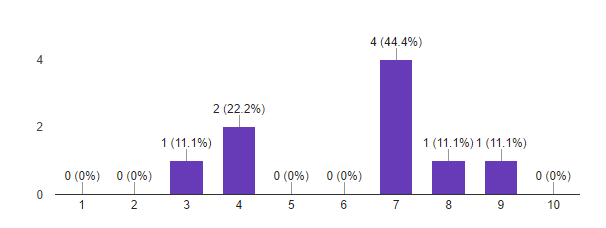
4. Насколько вам понравился формат программы: 2 очных дня с лабораторной работой?
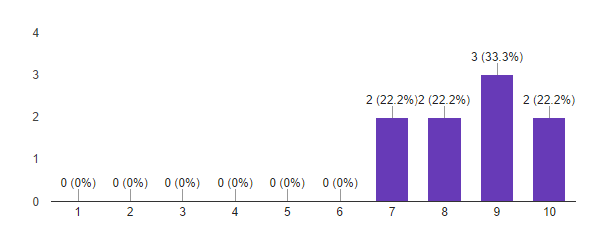
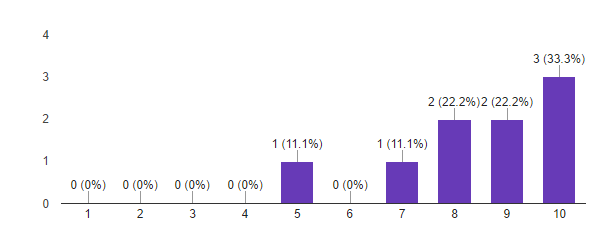
5. Насколько вероятно, что вы порекомендуете эту программу своим знакомым?
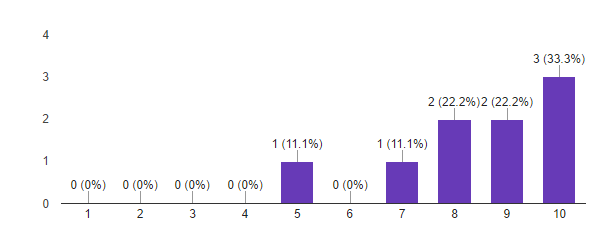
Исходя из этих данных, мы считаем первый запуск программы Deep Learning успешным. Важные для нас метрики показывают, что участники в большинстве довольны полученным результатом и готовы рекомендовать программу знакомым. Похоже, что мы не очень попали с форматом. Мы сделали выводы по пилотному запуску, и будем его модифицировать к следующему набору. Идеи есть!
Как вы знаете, для обучения глубоких нейронных сетей оптимально использовать машины с GPU. Наши образовательные программы всегда имеют практический уклон, поэтому для нас было обязательно, чтобы во время обучения у каждого участника была своя виртуальная машина с GPU, на которой он мог решать задачи во время занятий, а также лабораторную работу в течение недели. О том, как мы выбирали инфраструктурного партнера для реализации наших планов и подготавливали среду для наших участников, и пойдет речь в нашем посте.
Microsoft Azure N-series
Планы запустить образовательную программу по Deep Learning у нас были еще с начала этого года, но к непосредственному дизайну программы мы перешли в августе. Примерно тогда же Microsoft Azure заявил, что на их платформе появились в preview формате GPU-виртуалки. Для нас это было приятной новостью, потому что на нашей основной программе по большим данным Microsoft является инфраструктурным партнером. Была идея не плодить зоопарк, и в конце ноября просто воспользоваться их готовым решением (не preview). В середине ноября стало понятно, что Microsoft не торопится выходить из preview и делать GPU доступными в рамках своей облачной экосистемы. Мы оказались перед фактом, что нужно срочно искать что-то другое.
IBM Bluemix
Чуть позже нам удалось довольно оперативно договориться о сотрудничестве в этой области с облачной платформой на базе IBM Bluemix Infrastructure (ранее Softlayer), и компания IBM стала нашим инфраструктурным партнером по этой программе. Увы, без подводных камней не обошлось. Мы первый раз, на ходу, знакомились с возможностями IBM Bluemix. Изначально мы рассчитывали, что получим готовые виртуальные машины с GPU для каждого из участников. Но поскольку на Bluemix GPU доступны только в серверах Bare-metal (выделенные физические серверы), которые можно как конструктор заказать в нужной конфигурации, и получить за несколько часов, то в итоге мы получили мощный физический сервер на платформе Supermicro с двумя процессорами Intel Xeon E5-2690v3, 128 Гб памяти и с двумя карточками NVIDIA Tesla M60 (на каждой карточке по 2 чипа GM204GL поколения Maxwell и 16 Гб видеопамяти), на который мог быть предустановлен гипервизор на выбор (VMware, Xen или Hyper-V), что тоже очень неплохо! Нам оставалось только разбить это шустрое железо на нужное количество виртуалок и все. Только вот мы не планировали этого этапа с самого начала. Вот тут и возникла основная проблема, которую мы решали довольно долго.
Для проведения практических работ участникам нашей программы требовались виртуальные машины с GPU поддерживающими NVIDIA CUDA и ОС на основе GNU/Linux (мы чаще всего используем Ubuntu 14.04 LTS для наших задач, как удобный в эксплуатации и достаточно простой дистрибутив с хорошей поддержкой сообщества). Соответственно, в первую очередь необходимо было выбрать платформу виртуализации, которая поддерживала бы либо “проброс” (passthrough) видеокарт в гостевую Linux систему, либо (что интереснее) поддержку виртуальных GPU для гостевых ОС.
В первую очередь решили рассмотреть VMware Vsphere 6, как одно из лидирующих на этом рынке решений. Благо установка данного гипервизора и все требуемые лицензии доступны прямо из панели управления IBM SoftLayer, то есть установка гипервизора проводится буквально в несколько кликов мыши (не забываем, что мы работаем с выделенным сервером). В VMware заявлена поддержка технологии GRID Virtual GPU (vGPU), то есть имеется возможность разделения одного ядра видеоадаптера на несколько виртуальных и подключения такого GPU к гостевой системе. Достаточно подробно все описывается в соответствующем документе от NVidia. Данная технология по большей части ориентирована на использование в решениях VDI, где требуется ускорение 3D графики для гостевых систем на основе Windows, что в нашем случае не очень подходит. При более подробном изучении документа от NVidia можно узнать, что при использовании vGPU имеется понятие профилей vGPU, то есть по сути того, на сколько vGPU можно разделить одно ядро видеоускорителя. Профиль vGPU задает выделяемое количество видеопамяти, максимальное количество поддерживаемых дисплеев и так далее. Таким образом используя различные профили можно разбить NVidia Tesla M60 на количество виртуальных машин от 1 до 32. Интересно.
НО! Если еще более подробно вчитаться в документ, то можно обнаружить, что поддержка CUDA на гостевых Linux системах доступна только с профилем GRID M60-8Q, что по сути является просто пробросом одного из чипов GPU Tesla M60 (напомним, что Tesla M60 состоит из 2-х чипов) в одну виртуальную машину. В итоге при любом раскладе имея 2 карты Tesla M60 для работы с CUDA можно получить максимум 4 виртуалки для гостевой ОС Linux.
Отдельно стоит упомянуть, что для работы с vGPU требуется дополнительное лицензирование от NVidia (основы тут) и чтобы получить драйверы для гипервизора и гостевых систем необходимо эти лицензии получить. Также драйвера в гостевых системах требуют сервера лицензий NVidia, который необходимо установить самостоятельно, и поддерживается только ОС семейства Windows. Помимо этого vGPU поддерживается только на релизе Vsphere 6 Enterprise Plus, который мы как раз и использовали.
В итоге решено отказаться от vGPU и просто “пробросить” видеокарты в гостевые системы, таким образом можно получить 4 виртуальные машины, каждой из которых будет доступен один чип Tesla M60 с 8 Гб видеопамяти. vSphere поддерживает PCI-Passthrough, соответственно, проблем быть не должно, но они появились.
Карточки Tesla были настроены для passthrough в виртуальные машины. На одну из машин добавили PCI устройство, но при запуске машины появлялась ошибка “PCI passthrough device id invalid”, оказалась что данная проблема проявляется только в веб-интерфейсе vSphere, если использовать Windows-клиент и заново добавить устройство, такая проблема не возникает, но появляется другая, более общая, что-то вроде “starting VM … general error”. Немного изучив происхождение ошибки, мы перепробовали различные варианты:
- Проверили включен ли VT-в
- Включен ли IOMMU
- Пробовали добавить в .vmx файл:
-firmware=«efi»
-pciPassthru.use64bitMMIO=«TRUE»
-efi.legacyBoot.enabled=«TRUE»
-efi.bootOrder=«legacy»
Но все тщетно. PCI Passthrough у нас не работал. Учитывая что времени было все меньше и меньше, решили прекратить наши изыскания и попробовать Citrix XenServer. Данный гипервизор широко используется для VDI решений. Благо что из панели управления SoftLayer можно одним кликом мыши запустить переустановку гипервизора и выбрать XenServer. Надо отметить что его автоматизированная установка и настройка заняла у платформы Bluemix приличное время (около 8 часов в нашем случае). Так что важно закладывать необходимое время на данную процедуру. Дальше эта история была достаточно скучной, все заработало практически сразу “из коробки”. В данном случае был доступен такой же вариант с Passthrough режимом. Каждый из 4-х чипов GM204GL из двух адаптеров Testa M60 пробросили в отдельную виртуальную машину, настроили виртуальную сеть, установили стандартные драйвера NVidia для Tesla M60 под Linux и все завелось. Для настройки XenServer удобно использовать Citrix XenCenter, вот как выглядят проброшенные видеокарты в его GUI:

Вот так через утилиту nvidia-smi администратору можно наблюдать, что процесс python (участники использовали библиотеки Keras и Caffe) использует большую часть памяти GPU.
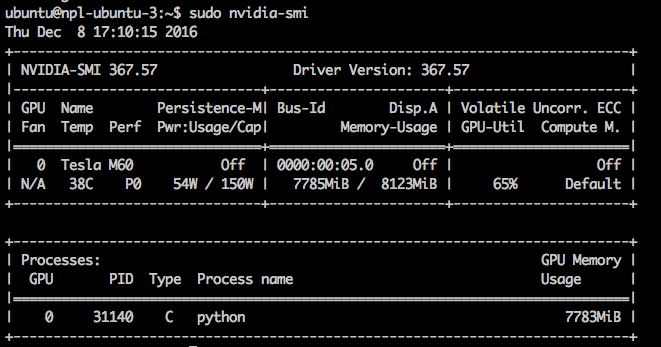
В связи со всеми этими внеплановыми изысканиями нарезать работающие как надо виртуалки нам удалось только к последнему из дней нашей программы. В результате неделю ребята занимались на g2.2xlarge инстансах платформы AWS, поскольку мы не могли себе позволить остаться без нужного оборудования, а нарезанные виртуалки IBM Bluemix решили дать участникам еще на неделю после окончания программы в качестве бонуса, чтобы они могли еще порешать задачи, связанные с deep learning.
Сравнение AWS и IBM Bluemix
Мы решили сравнить, какое из решений является более эффективным с точки зрения производительности и стоимости содержания парка.
Посчитаем, сколько, например, будут стоить оба варианта при условии использования инфраструктуры в течение двух недель, с 16 участниками. Наш use case не совсем стандартный, потому что мы хотели выдать каждому участнику отдельную виртуалку.
AWS: 0.65$ * 24ч * 15 дней * 16 участников = 3 744$
IBM Bluemix: 2961.1$/мес / 2 (2 недели) * 4 = 5 922.2$ (сервер с 2xM60) ссылка на конфигурацию
Или если взять эквивалент, более близкий к g2.2xlarge:
2096,40 $/мес / 2(2 недели) * 4 = 4192,8$ (сервер с 2хK2 (GK104) GPU — аналог AWS) ссылка на конфигурацию
В нашем варианте разница в деньгах получается существенная — почти 2 тыс. долл. При использовании более современной GPU, но и производительность во втором случае оказывается выше:
AWS: 1gpu, 8cores, 15gb ram (GK 104 на базе GRID K520)
IBM: 1 gpu, 12 cores, 32gb ram (GM 204 на базе М60)
Больше ядер, больше памяти, более современная GPU следующего поколения, да и производительность сама по себе еще выше. Провели небольшой бенчмарк, обучив сеть LeNet, распознающую рукописные цифры, при помощи Caffe на 10 тыс. итераций. На виртуалке AWS это заняло 45.5 секунд, на виртуалке IBM — 26.73 секунды, то есть в 1.7 раз быстрее. На большем промежутке времени это может быть более весомо: 24 часа против 14 часов. Или за две недели это бы дало экономию в 6 дней, которые можно было потратить на обучение чего-то еще.
Коллеги из IBM поделились еще другим сценарием использования — видео стриминг. В AWS использовались те же самые 16 машин g2.2xlarge, а в IBM только один сервер 2хM-60 для гостевых VM Windows. По производительности они были сопоставимы, обслуживая одно и то же количество видеопотоков. За те же самые 2 недели расход в IBM составит — 1 422.72$, что дешевле на более, чем 2 000 долл. конфигурации в AWS. Так что в зависимости от ваших задач, та или иная конфигурация могут быть для вас выгоднее. Также коллеги из IBM намекнули, что могут предоставить более выгодные условия, даже при аренде одного такого сервера, в AWS же скидки применяются автоматически только при значительном потреблении сервисов на десятки тысяч $.
Также важно отметить что только на платформе Bluemix сейчас доступны GPU поколения Maxwell. На момент написания поста им не было аналогов у других публичных облачных платформ. Если что, прямая ссылка на конфигуратор тут.
В нашем сравнении мы не затрагиваем тему сравнения платформы с платформой, т.к. эти сервисы представляют собой совершенно разный подход. IBM Bluemix фокусируется больше на предоставлении инфраструктурных сервисов (Softlayer) и в то же время предлагает своим клиентам сервисы PaaS Bluemix (Аналитика, большие данные, виртуальные контейнеры и т.д.). AWS сфокусирован на виртуальных сервисах и PaaS, за основу взят KVM гипервизор, Azure же в свою очередь сконцентрирован на всем стеке Microsoft.
Очевидно, что не до конца справедливо сравнивать лоб в лоб цены тех или иных решений у разных провайдеров, нужно понимать что вы получаете за эту цену! Например, если вдаваться в подробности и изучать документацию, выяснится, что AWS и Azure за каждое обращение в техническую поддержку взимает с клиента деньги, IBM Bluemix — нет. Если у вас сервисы находятся в разных географически разнесенных ЦОДах, то в случае Azure и AWS за трафик внутри сети ЦОДов оплачивает клиент, в то время как в IBM Bluemix трафик внутри сети для клиентов бесплатен и т.д. Можно еще много всяких нюансов обнаружить в функциональной, практической, и юридической плоскости. На наш взгляд, если вам нужно максимально персонализированное решение, и речь идет о значительных рабочих нагрузках, то выбор Bluemix оптимален, т.к. вы полностью администрируете и управляете ресурсами и любой сервис прозрачен, в то же время если вам нужно несколько рабочих станций максимально готовых к использованию (требуют наименьшего администрирования) и вам не критична производительность, то Azure и AWS идеально вам подойдут.
Результат
Итог таков, что несмотря на все сложности, которые мы испытывали, первый запуск программы Deep Learning можно считать успешным. По итогам нашего опроса мы получили следующие результаты:
1. Насколько ваши ожидания от курса совпали с реальностью?
По шкале от 1 до 10: 1 — ожидания полностью не оправдались, 10 — курс превзошел все мои ожидания.

2. Каков главный результат вы получили от программы?

3. Как планируете применять полученные знания и навыки?

4. Насколько вам понравился формат программы: 2 очных дня с лабораторной работой?
5. Насколько вероятно, что вы порекомендуете эту программу своим знакомым?
Исходя из этих данных, мы считаем первый запуск программы Deep Learning успешным. Важные для нас метрики показывают, что участники в большинстве довольны полученным результатом и готовы рекомендовать программу знакомым. Похоже, что мы не очень попали с форматом. Мы сделали выводы по пилотному запуску, и будем его модифицировать к следующему набору. Идеи есть!
