Хабр, привет! В современном машинном обучении и науке о данных можно выделить несколько трендов. Прежде всего, это глубокое обучение: распознавание изображений, аудио и видео, обработка текстов на естественных языках. Еще одним трендом становится обучение с подкреплением — reinforcement learning, позволяющее алгоритмам успешно играть в компьютерные и настольные игры, и дающее возможность постоянно улучшать построенные модели на основе отклика внешней среды.
Есть и еще один тренд, менее заметный, так как его результаты для внешних наблюдателей выглядят не так впечатляюще, но не менее важный — автоматизация машинного обучения. В связи с его стремительным развитием вновь актуальным становится вопрос о том, не будут ли data scientist’ы в конце концов автоматизированы и вытеснены искусственным интеллектом.
По оценкам американской исследовательской и консалтинговой компании Gartner, к 2020 году будет автоматизировано более 40% задач в области big data и data science. Даже если эта оценка не завышена, специалистам в области больших данных и машинного обучения не о чем беспокоиться. Такого мнения придерживается большинство экспертов, в том числе и сами разработчики систем автоматизированного машинного обучения.
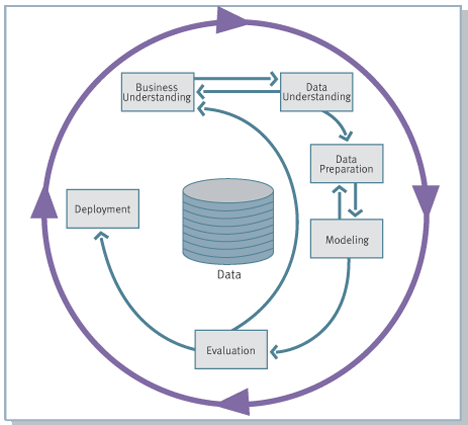
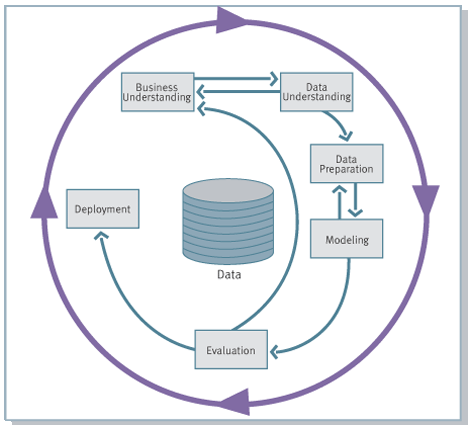
Дело в том, что роль аналитика в компании, вне зависимости от того, насколько сложными инструментами анализа он пользуется, не сводится только к применению этих инструментов. Согласно наиболее популярной методологии ведения проектов в сфере анализа данных CRISP-DM, реализация проектов в области анализа данных включает 6 фаз, в каждой из которых аналитик или data scientist принимает непосредственное участие:
Шаги 3 и 4 предполагают множество рутинной работы. Чтобы применять машинное обучение для решения конкретных кейсов, необходимо постоянно:
От этих рутинных операций, как и от части операций в подготовке и очистке данных, аналитиков или data scientist’ов можно избавить с помощью автоматизации. Однако все остальные части 3, 4 и остальных шагов CRISP-DM сохранятся, так что такое упрощение повседневной работы аналитиков не несет в себе никакой угрозы этой профессии.
Машинное обучение является только одним из инструментов data scientist’а помимо визуации, обзорного исследования данных, статистических и эконометрических методов. И даже в нем полная автоматизация невозможна. Высокая роль data scientist’а, безусловно, сохранится при решении нестандартных задач, в разработке и применении новых алгоритмов и их комбинаций. Автоматизированный алгоритм может перебрать все стандартные комбинации и выдать некоторое базовое решение, которое квалифицированный специалист сможет взять за основу и дальше улучшать. Однако во многих случаях результатов работы автоматизированного алгоритма окажется достаточно и без дополнительных улучшений, и их можно будет использовать непосредственно.
Едва ли можно ожидать, что бизнес сможет пользоваться результатами автоматизированного машинного обучения без помощи аналитиков. В любом случае понадобятся подготовка данных, интерпретация результатов и другие этапы рассмотренной выше схемы. Вместе с тем во многих компаниях сегодня работают аналитики, которые постоянно работают с данными и имеют соответствующий склад ума, глубоко разбираются в предметной области, но при этом не владеют на необходимом уровне методами машинного обучения. Отраслевой компании часто непросто привлечь высококвалифицированных и высокооплачиваемых специалистов по машинному обучению, спрос на которых растет и многократно превышает предложение. Решением здесь может быть предоставление работающим в компании аналитикам доступа к средствам автоматизированного машинного обучения. В этом и будет заключаться эффект демократизации технологий, создаваемый автоматизаций. Преимущества больших данных в перспективе станут доступны множеству компаний без формирования высокопрофессиональных команд и привлечения консалтинговых фирм.
На сегодняшний день можно выделить два наиболее результативных пакета автоматизированного машинного обучения. Оба они используют библиотеку машинного обучения sklearn языка Python и активно разрабатываются.
Первый из них — библиотека Auto-sklearn, разработанный во Фрайбургском университете. Данный пакет является победителем недавно проведенного порталом KDNuggets конкурса алгоритмов автоматизированного машинного обучения, также показал лучшие результаты в задачах auto и tweakathon соревнования ChaLearn AutoML challenge. Auto-sklearn автоматизирует выбор модели и оптимизацию гиперпараметров с помощью байесовской оптимизации, использует мета-обучение и строит ансамбли моделей, автоматизирует предварительную обработку данных, в том числе методами кодирования переменных и понижения размерности. Auto-sklearn работает только в Linux и требует установленной библиотеки sklearn. Библиотека поддерживает распределенные вычисления. Auto-sklearn можно загрузить с его официального репозитория GitHub, документацию пакета можно найти здесь. Применение классификатора Auto-sklearn к широко известному набору данных MNIST (распознавание написанных от руки цифр) занимает около часа и на выходе дает точность более 98%.
Вторым лидирующим решением в области автоматизированного машинного обучения выступает библиотека TPOT. Ее ключевые отличия от предыдущего рассмотренного пакета следующие:
Точность TPOT на том же наборе данных MNIST без каких-либо предварительных настроек составляет 98.4%.

Рассмотренные выше пакеты используются вместе с языком Python и его библиотеками, что может оказаться препятствием для части аналитиков и специалистов других профессий. Ряд крупнейших облачных сервисов, например, Amazon Machine Learning и BigML, предпринимают попытку сделать машинное обучение еще более доступным для каждого. От пользователя таких сервисов не требуется знания алгоритмов машинного обучения и предобработки данных, он получает все необходимые подсказки, пояснения и визуализации в процессе построения моделей. Такие облачные сервисы предоставляют уже развернутую и готовую к использованию инфраструктуру хранения и обработки больших массивов данных, которой в конкретной компании может не быть. Вместе с тем их недостатком является ограниченность набора используемых алгоритмов и методов оптимизации. Например, BigML делает акцент на деревьях решений, а Amazon Machine Learning использует только классификаторы на основе стохастического градиентного спуска. Такие облачные сервисы предназначены скорее для построения достаточно хороших решений стандартных задач, чем для получения лучших возможных моделей в любой ситуации.
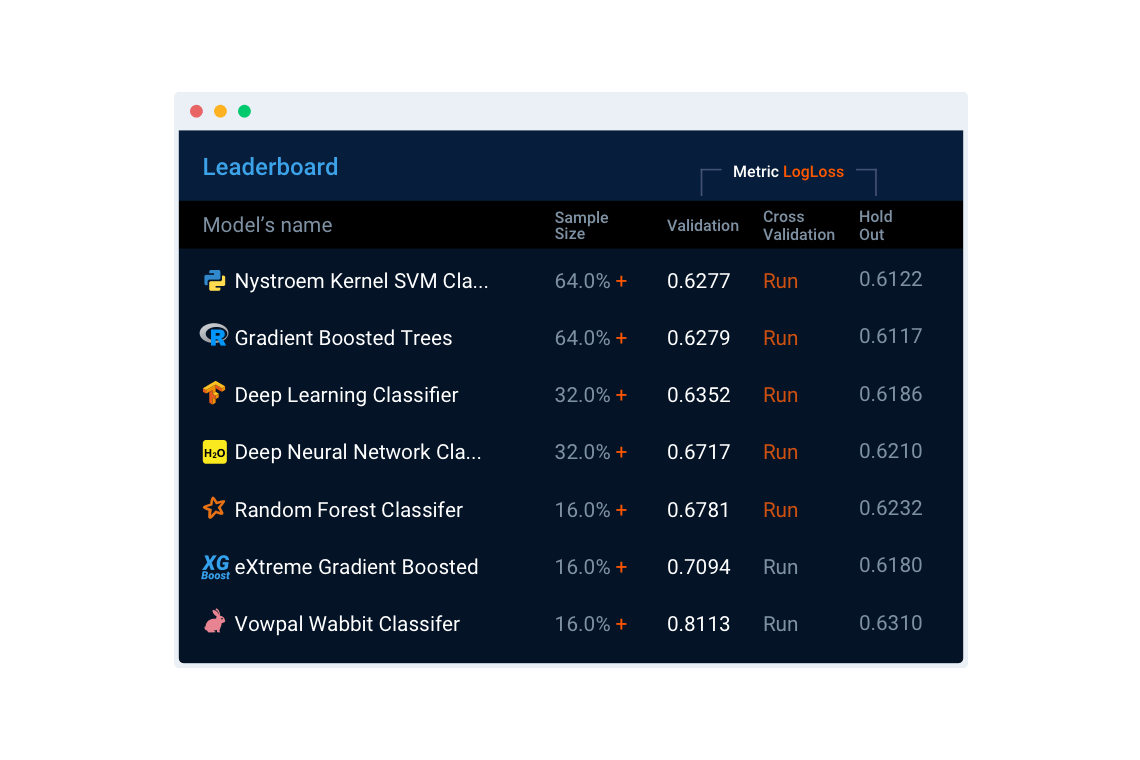
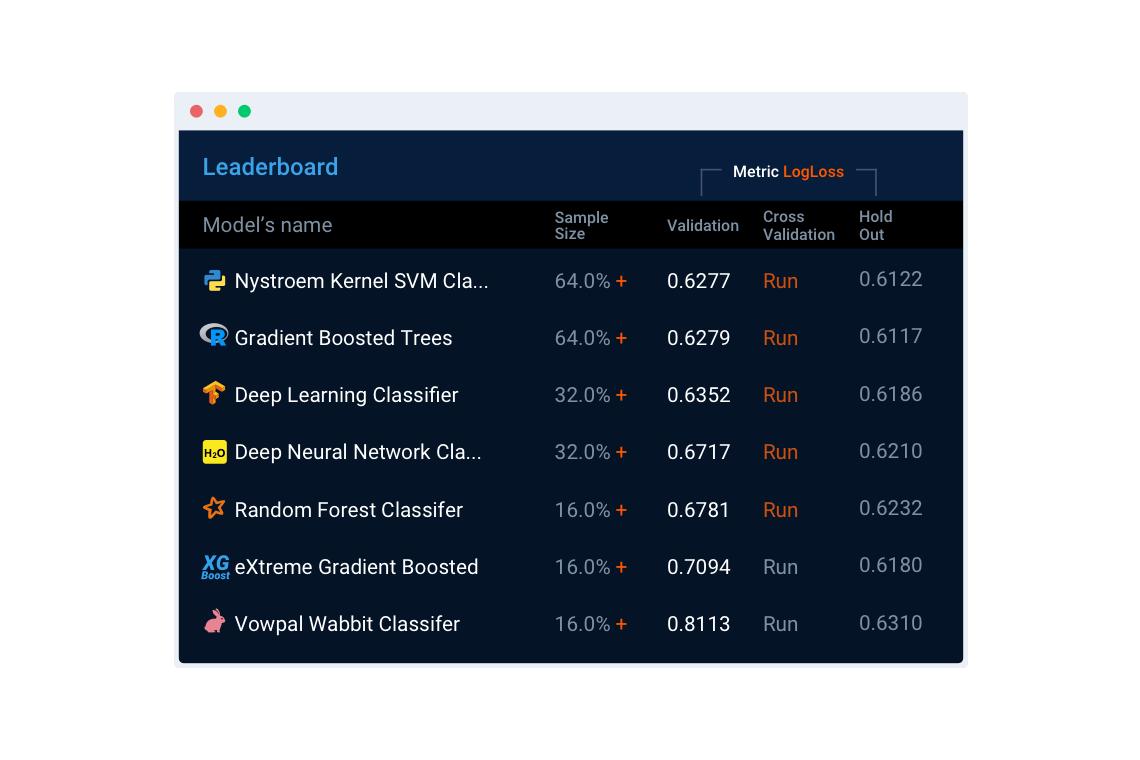
Существуют и более продвинутые облачные сервисы автоматизированного машинного обучения, близкие по возможностям к рассмотренным выше библиотекам Python. Среди них можно особенно выделить сервис DataRobot. Его преимуществами по сравнению с библиотеками автоматизированного машинного обучения Python являются интуитивно понятный веб-интерфейс, возможность сочетать в одной модели лучшие алгоритмы R, sklearn, Spark, XGBoost, H20, ThensorFlow, Vowpal Wabbit и других систем, предоставление необходимой для анализа и обработки данных инфраструктуры, визуализация этапов построения моделей и итоговых результатов. DataRobot автоматически производит статистическую обработку текстов, автоматически определяет типы переменных и при необходимости кодирует их, применяет необходимые преобразования и способен автоматически конструировать новые признаки, использует интеллектуальные методы подбора гиперпараметров и оценивает производительность моделей по широкому спектру доступных метрик. Поддерживаются параллельные вычисления, что повышает скорость обучения и применения моделей, в системе имеются средства для быстрого и легкого внедрения построенных моделей.
Сервис DataRobot является наиболее универсальным, помимо него разработано множество облачных сервисов для автоматизации и демократизации машинного обучения в конкретных предметных областях. Например, система ThingWorx Analytics предназначена для автоматизации машинного обучения в сфере Интернета вещей, прежде всего, в целях отслеживания работы оборудования, предсказания поломок, оптимизации его работы, а Context Relevant предлагает автоматизированные решения в области кибербезопасности и противодействия мошенничеству.
Будущее профессии data scientist пока еще туманно и является предметом экспертных оценок. Однако никто не мешает пользоваться результатами автоматизированного машинного обучения уже сейчас. Автоматизированное машинное обучение — легкий шаг к тому, чтобы начать применять машинное обучение на текущем месте работы или, если вы уже работаете data scientist’ом, значительно облегчить ваши повседневные обязанности.
Спрос на специалистов в области машинного обучения и анализа данных постоянно растет, и автоматизация машинного обучения, приводящая к демократизации технологий, только расширит его использование. Сегодня создать красивый сайт с помощью конструктора сайтов, такого как Ucoz, сможет практически каждый. Однако спрос на веб-дизайнеров и разработчиков с того времени, как таких конструкторов не существовало, совершенно не упал, наоборот, многократно возрос. Спектр доступных инструментов веб-разработки значительно обогатился, а сами инструменты стали сложнее и функциональнее. Если предположить, что анализ данных станет для компаний таким же доступным, как создание веб-сайтов, можно представить себе, каким будет спрос на высококлассных специалистов в этой области через несколько лет.
Напоминаем, что 16 марта у нас стартует программа «Специалист по большим данным», будем рады видеть вас.
Есть и еще один тренд, менее заметный, так как его результаты для внешних наблюдателей выглядят не так впечатляюще, но не менее важный — автоматизация машинного обучения. В связи с его стремительным развитием вновь актуальным становится вопрос о том, не будут ли data scientist’ы в конце концов автоматизированы и вытеснены искусственным интеллектом.
По оценкам американской исследовательской и консалтинговой компании Gartner, к 2020 году будет автоматизировано более 40% задач в области big data и data science. Даже если эта оценка не завышена, специалистам в области больших данных и машинного обучения не о чем беспокоиться. Такого мнения придерживается большинство экспертов, в том числе и сами разработчики систем автоматизированного машинного обучения.
Дело в том, что роль аналитика в компании, вне зависимости от того, насколько сложными инструментами анализа он пользуется, не сводится только к применению этих инструментов. Согласно наиболее популярной методологии ведения проектов в сфере анализа данных CRISP-DM, реализация проектов в области анализа данных включает 6 фаз, в каждой из которых аналитик или data scientist принимает непосредственное участие:
- Понимание бизнес-целей (Business Understanding)
- Начальное изучение данных (Data Understanding)
- Подготовка данных (Data Preparation)
- Моделирование (Modeling)
- Оценка (Evaluation)
- Внедрение (Deployment)
Шаги 3 и 4 предполагают множество рутинной работы. Чтобы применять машинное обучение для решения конкретных кейсов, необходимо постоянно:
- Настраивать гиперпараметры моделей;
- Пробовать новые алгоритмы;
- Добавлять в модели различные представления исходных признаков (стандартизация, стабилизация дисперсии, монотонные преобразования, понижение размерности, кодирование категориальных переменных, создание новых признаков из имеющихся и т.д.).
От этих рутинных операций, как и от части операций в подготовке и очистке данных, аналитиков или data scientist’ов можно избавить с помощью автоматизации. Однако все остальные части 3, 4 и остальных шагов CRISP-DM сохранятся, так что такое упрощение повседневной работы аналитиков не несет в себе никакой угрозы этой профессии.
Машинное обучение является только одним из инструментов data scientist’а помимо визуации, обзорного исследования данных, статистических и эконометрических методов. И даже в нем полная автоматизация невозможна. Высокая роль data scientist’а, безусловно, сохранится при решении нестандартных задач, в разработке и применении новых алгоритмов и их комбинаций. Автоматизированный алгоритм может перебрать все стандартные комбинации и выдать некоторое базовое решение, которое квалифицированный специалист сможет взять за основу и дальше улучшать. Однако во многих случаях результатов работы автоматизированного алгоритма окажется достаточно и без дополнительных улучшений, и их можно будет использовать непосредственно.
Едва ли можно ожидать, что бизнес сможет пользоваться результатами автоматизированного машинного обучения без помощи аналитиков. В любом случае понадобятся подготовка данных, интерпретация результатов и другие этапы рассмотренной выше схемы. Вместе с тем во многих компаниях сегодня работают аналитики, которые постоянно работают с данными и имеют соответствующий склад ума, глубоко разбираются в предметной области, но при этом не владеют на необходимом уровне методами машинного обучения. Отраслевой компании часто непросто привлечь высококвалифицированных и высокооплачиваемых специалистов по машинному обучению, спрос на которых растет и многократно превышает предложение. Решением здесь может быть предоставление работающим в компании аналитикам доступа к средствам автоматизированного машинного обучения. В этом и будет заключаться эффект демократизации технологий, создаваемый автоматизаций. Преимущества больших данных в перспективе станут доступны множеству компаний без формирования высокопрофессиональных команд и привлечения консалтинговых фирм.
На сегодняшний день можно выделить два наиболее результативных пакета автоматизированного машинного обучения. Оба они используют библиотеку машинного обучения sklearn языка Python и активно разрабатываются.
Первый из них — библиотека Auto-sklearn, разработанный во Фрайбургском университете. Данный пакет является победителем недавно проведенного порталом KDNuggets конкурса алгоритмов автоматизированного машинного обучения, также показал лучшие результаты в задачах auto и tweakathon соревнования ChaLearn AutoML challenge. Auto-sklearn автоматизирует выбор модели и оптимизацию гиперпараметров с помощью байесовской оптимизации, использует мета-обучение и строит ансамбли моделей, автоматизирует предварительную обработку данных, в том числе методами кодирования переменных и понижения размерности. Auto-sklearn работает только в Linux и требует установленной библиотеки sklearn. Библиотека поддерживает распределенные вычисления. Auto-sklearn можно загрузить с его официального репозитория GitHub, документацию пакета можно найти здесь. Применение классификатора Auto-sklearn к широко известному набору данных MNIST (распознавание написанных от руки цифр) занимает около часа и на выходе дает точность более 98%.
Вторым лидирующим решением в области автоматизированного машинного обучения выступает библиотека TPOT. Ее ключевые отличия от предыдущего рассмотренного пакета следующие:
- Вместо байесовской оптимизации используется генетическое программирование, в котором модели подвергаются чему-то вроде дарвиновского естественного отбора;
- Поддерживается известная библиотека градиентного бустинга над деревьями XGBoost;
- Нет ограничений по операционным системам;
- В отличие от Auto-sklearn, TPOT на выходе формирует не только итоговую обученную модель, но и готовый к внедрению код всех шагов построения наилучшей модели (pipeline) на языке Python.
Точность TPOT на том же наборе данных MNIST без каких-либо предварительных настроек составляет 98.4%.

Рассмотренные выше пакеты используются вместе с языком Python и его библиотеками, что может оказаться препятствием для части аналитиков и специалистов других профессий. Ряд крупнейших облачных сервисов, например, Amazon Machine Learning и BigML, предпринимают попытку сделать машинное обучение еще более доступным для каждого. От пользователя таких сервисов не требуется знания алгоритмов машинного обучения и предобработки данных, он получает все необходимые подсказки, пояснения и визуализации в процессе построения моделей. Такие облачные сервисы предоставляют уже развернутую и готовую к использованию инфраструктуру хранения и обработки больших массивов данных, которой в конкретной компании может не быть. Вместе с тем их недостатком является ограниченность набора используемых алгоритмов и методов оптимизации. Например, BigML делает акцент на деревьях решений, а Amazon Machine Learning использует только классификаторы на основе стохастического градиентного спуска. Такие облачные сервисы предназначены скорее для построения достаточно хороших решений стандартных задач, чем для получения лучших возможных моделей в любой ситуации.
Существуют и более продвинутые облачные сервисы автоматизированного машинного обучения, близкие по возможностям к рассмотренным выше библиотекам Python. Среди них можно особенно выделить сервис DataRobot. Его преимуществами по сравнению с библиотеками автоматизированного машинного обучения Python являются интуитивно понятный веб-интерфейс, возможность сочетать в одной модели лучшие алгоритмы R, sklearn, Spark, XGBoost, H20, ThensorFlow, Vowpal Wabbit и других систем, предоставление необходимой для анализа и обработки данных инфраструктуры, визуализация этапов построения моделей и итоговых результатов. DataRobot автоматически производит статистическую обработку текстов, автоматически определяет типы переменных и при необходимости кодирует их, применяет необходимые преобразования и способен автоматически конструировать новые признаки, использует интеллектуальные методы подбора гиперпараметров и оценивает производительность моделей по широкому спектру доступных метрик. Поддерживаются параллельные вычисления, что повышает скорость обучения и применения моделей, в системе имеются средства для быстрого и легкого внедрения построенных моделей.
Сервис DataRobot является наиболее универсальным, помимо него разработано множество облачных сервисов для автоматизации и демократизации машинного обучения в конкретных предметных областях. Например, система ThingWorx Analytics предназначена для автоматизации машинного обучения в сфере Интернета вещей, прежде всего, в целях отслеживания работы оборудования, предсказания поломок, оптимизации его работы, а Context Relevant предлагает автоматизированные решения в области кибербезопасности и противодействия мошенничеству.
Будущее профессии data scientist пока еще туманно и является предметом экспертных оценок. Однако никто не мешает пользоваться результатами автоматизированного машинного обучения уже сейчас. Автоматизированное машинное обучение — легкий шаг к тому, чтобы начать применять машинное обучение на текущем месте работы или, если вы уже работаете data scientist’ом, значительно облегчить ваши повседневные обязанности.
Спрос на специалистов в области машинного обучения и анализа данных постоянно растет, и автоматизация машинного обучения, приводящая к демократизации технологий, только расширит его использование. Сегодня создать красивый сайт с помощью конструктора сайтов, такого как Ucoz, сможет практически каждый. Однако спрос на веб-дизайнеров и разработчиков с того времени, как таких конструкторов не существовало, совершенно не упал, наоборот, многократно возрос. Спектр доступных инструментов веб-разработки значительно обогатился, а сами инструменты стали сложнее и функциональнее. Если предположить, что анализ данных станет для компаний таким же доступным, как создание веб-сайтов, можно представить себе, каким будет спрос на высококлассных специалистов в этой области через несколько лет.
Напоминаем, что 16 марта у нас стартует программа «Специалист по большим данным», будем рады видеть вас.
