
Всем доброго времени суток. Мы решили описать построение отказоустойчивой инфраструктуры для bitrix в рамках серии статей, и сегодня публикуем первую часть. Вариант, который мы будем описывать, - не идеальный, но мы стремились к хотя бы максимально приближенному к идеальному видению данного кластера. В связи со спецификой работы bitrix-ядра, необходимо учитывать очень много факторов для построения инфраструктуры, и вы старались это учитывать.
Серия статей будет представлять собой теоретическую часть и практическую части. В сегодняшней - теоретической - части мы разберем все нюансы кластеризации и особенностей bitrix-составляющей.
Содержание:
Что такое кластер и отказоустойчивая инфраструктура?
Инфраструктура bitrix.
Инфраструктура с 0% отказоустойчивости.
bitrixVM.
Ручное развертывание на debian/ubuntu/Centos.
Почему bitrix монолиты так популярны?
Кому подходит?
Кому не подходит?
Инфраструктура с 70% отказоустойчивости.
Плюсы.
Минусы.
Кому подходит?
Кому не подходит?
Инфраструктура с 95% отказоустойчивости.
Миф о bitrix в k8s.
Инфраструктура с 90% отказоустойчивости.
Что необходимо?
Какими сервисами пользоваться для достижения вышеуказанных целей?
Схема инфраструктуры.
Об инфраструктуре.
Как все работает?
Кому подходит этот кластер?
Кому не подходит этот кластер?
Плюсы Кластера.
Минусы кластера.
Итог теоретической части.
Для начала мы бы хотели разобрать, что такое кластер, какие топологии кластеризации бывают, какие встречались на нашем опыте.
Осторожно, #многобукв!!! =)
Что такое кластер и отказоустойчивая инфраструктура?
Кластер - это объединение нескольких вычислительных систем (виртуальных/физических серверов), работающих совместно для выполнения общих задач и целей.
Кластер позволяет:
Управлять несколькими серверами с помощью одного модуля управления.
Добавлять произвольное количество рабочих серверов без остановки системы.
Синхронизировать данные между серверами.
Распределять запросы по разным серверам.
Минимизировать время простоя в случае выхода из строя одного из серверов.
Отказоустойчивая инфраструктура - это кластер, который построен по методике обеспечения высокой доступности, и гарантирует минимальное время простоя в случае выхода одного или нескольких (в зависимости от масштабов инфраструктуры) узлов кластера.
Если взять за основу данные в Wikipedia, кластер характеризуется отличительными особенностями, к которым можно отнести такие как:
Высокая доступность — наиболее распространенный уровень, ожидаемый пользователями, при котором система или приложение доступны в обозначенные требованиями дни и часы без незапланированных простоев, а о запланированных остановках в работе объявлено заранее.
Непрерывный режим работы (continuous operations) — система доступна 24 часа в сутки 7 дней в неделю без запланированных простоев.
Постоянная доступность (continuous availability) — сочетание высокой доступности с непрерывным режимом работы. Система доступна 24 часа в сутки 7 дней в неделю без запланированных или незапланированных простоев.
Более подробно можно изучить по ссылке.
Чаще всего вычислительные машины в кластере называют нодами. Например: первая нода mysql, вторая нода php, третья нода redis.
Инфраструктура bitrix.
По нашему опыту чаще всего встречаются четыре разновидности bitrix-инфраструктуры с разным процентом отказоустойчивости.
Инфраструктура с 0% отказоустойчивости.
Инфраструктура с 70% отказоустойчивости.
Инфраструктура с 90% отказоустойчивости.
Инфраструктура с 95% отказоустойчивости.
Инфраструктура с 0% отказоустойчивости.
У системных администраторов данная инфраструктура называется bitrix монолит. Инфраструктура с 0% отказоустойчивостью чаще всего выглядит так:

Имеется лишь один сервер, на котором расположены все сервисы.
Есть два варианта bitrix-монолита:
bitrixVM
Ручное развертывание на debian/ubuntu/Centos.
bitrixVM:
В RU сегменте встречается чаще всего. Примерно 80% проектов работают на данной инфраструктуре.
Что такое bitrixVM? Это настроенное решение от компании 1C-Bitrix, работающая на базе Centos Linux и использующее для настройки Ansible-роли. Включающее в себя сервисы необходимые для работы bitrix и содержащее инструментарий для их настройки.
Более подробно по ссылке.
bitrixVM имеет лишь два плюса:
В тестах производительности в админке bitrix будете брать рекорды по скорости работы.
Очень легка в настройке. Достаточно почитать гайды в интернете и уметь пользоваться стрелочками (и цифрами) на клавиатуре ^_^.
Имеет кучу минусов:
Ужасна в администрировании. Чтоб разобраться в символьных ссылках bitrixVM необходимо потратить очень много времени.
Безопасность - 0%. Все сайты, которые будут находится на сервере, будут работать от одного пользователя bitrix. Также, чаще всего bitrix-пользователей является sudo пользователем. Если взломали один сайт > взломали все сайты и получили доступ к root.
Зависимости, что плохо, если необходимо будет удалить/переустановить один или несколько пакетов. При удалении пакета можно зацепить важный пакет/библиотеку из-за зависимости со скриптами bitrixVM.
Очень сложна в обновлении и переезде - например, если необходимо мигрировать на другой сервер, можно потерять кучу данных и настроек. Чаще всего это приводит к росту времени переезда: вместо 10-12 стандартных часов bitrix-переезда время увеличивается до 20-30 часов. К тому же, если обновление пошло не по плану, то решение от bitrix не предусматривает возможности отката к предыдущей версии.
0% отказоустойчивости. Что это означает? Это означает, что любая большая DDoS-атака будет класть ваш проект на долгие часы. В случае отказа сервера это приведет к отказу всего проекта. Лег сервер = лег проект. В итоге мы получаем лишь одну картину:

Скорее всего сейчас меня не поддержит культ приверженцев bitrixVM, но мы бы не рекомендовали bitrixVM, где работают несколько сайтов одновременно. =(
Ручное развертывание на debian/ubuntu/Centos, хоть и займет больше времени при первоначальной настройке, но поможет сэкономить много времени (и нервов) в будущем.
Ручное развертывание на debian/ubuntu/Centos.
Это bitrix-проекты, развернутые вручную на debian/ubuntu/centos. Без установки bitrixVM. В данном виде инфраструктуры мы лишены первых четырех вышеуказанных минусов. Однако, как уже было сказано ранее, ручное развертывание требует больше времени для установки и настройки ПО. В обоих рассмотренных вариантах имеются разные плюсы и минусы, но в любом случае получаем 0% отказоустойчивости.
Почему bitrixVM-монолиты так популярны?
Как уже было сказано, они очень легки в развертывании. Путем нажатия трех-четырех пунктов меню bitrixVM можно развернуть весь новый проект.
Дешево. Достаточно арендовать один сервер для работы всего проекта.
Кому подходит?
Проекты, которые могут позволить себе простой от 2 до 12 часов.
Порталы, которые несут в себе только информационный ресурс.
Новостные сайты.
Кому не подходит?
Интернет-магазины, т.к. простой проекта равен потере клиентов.
Проекты, у которых посещаемость сайта превышает 10 000 в день.
Инфраструктура с 70% отказоустойчивости.


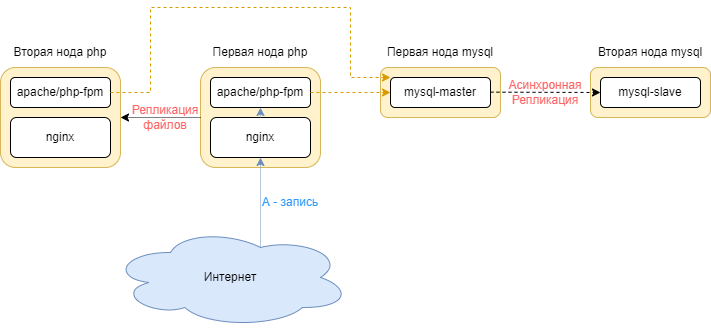
Такая инфраструктура встречается достаточно редко, исходя из личных наблюдений около 15% проектов на bitrix. Включает в себя несколько серверов.
Ноды mysql с slave-серверами.
Резервные сервера с кодом и резервными копиями.
Такой кластер уже является отказоустойчивым. В кластере реализовано ручное переключение трафика на резервные сервера:
Если у вас упадет первая нода php, можно будет переключить А-запись на вторую ноду.
Если упадет первая нода mysql, есть возможность переключить трафик на вторую ноду mysql.
Плюсы:
Ваш проект имеет несколько рабочих копий основного проекта синхронизированных между собой.
В случае выхода из строя у вас всегда будет вариант, как восстановить проект в кратчайшие сроки.
Можно будет добавлять несколько нод того или иного сервиса, будь то mysql или php.
Если у вас лицензия bitrix, вы можете настроить кластер mysql, где запросы на запись будут идти на master, а запросы на чтение - на slave, что ускоряет работы проекта. Но стоит учитывать, что данная лицензия стоит от 1 000 000 р., и позволить ее себе может не каждый.
Горизонтальное масштабирование инфраструктуры.
Минусы:
Ручное переключение трафика. В случае выхода из строя основной ноды, вам необходимо в ручную менять А-запись и менять адрес БД в коде bitrix. Это может занимать какое-то время. Например, если аварийное отключение ноды произойдет в ночное время.
Все равно уязвим для DDoS-атак. Мощная DDoS-атака может положить проект на несколько часов. Переключение А-записи в данном случае все равно не поможет.
Кому подходит:
Проекты, для которых простой в один/два часа уместен.
Проекты с посещаемостью от 10 000 до 100 000 пользователей в день.
Небольшие интернет магазины.
Кому не подходит:
Проекты, для которых простой в один/два часа не уместен.
Проекты с посещаемостью свыше 100 000 пользователей в день.
Инфраструктура с 95% отказоустойчивости.
Мистический и желанный bitrix в кубе с использованием CI/CD. Говорят, что это миф, но встречались люди, которые его видели. Эта инфраструктура близка к идеальной и поэтому практически недостижима для bitrix-проектов. Основана на k8s с использованием docker. Встречается крайне редко - меньше 1%.
Почему же она встречается крайне редко?
Она очень дорога. Построение данной инфраструктуры встанет вам в копеечку. Однако, нам приходилось наблюдать как несчастный bitrix-проект пытаются завалить DDoS-атаками 24/7, и при этом проект продолжал работать.
В связи с особенностями работы Bitrix любое изменение в странице с помощью админки bitrix приведет к полной поломке проекта на стороне серверов, т.к. bitrix вносит не только изменения в коде, но и изменение в базе данных. Необходимо приучить программистов не пользоваться админкой, а все изменения в код вносить через систему контроля версий (Например: Git). А это не так просто, как может показаться на первый взгляд (^_^).
Для перехода в k8s подходят проекты:
Которые уже давно являются кастомными. Все, что объединяет их с bitrix - это ядро bitrix.
Проекты, которые уже давно не пользуются админкой и все изменения вносят в код только через CI.
Данный вариант является самым отказоустойчивым и включает в себя несколько этапов отказоустойчивости, который включает в себя и DDoS и отказ базы данных и отказ PHP-сервера(ов).
Инфраструктура с 90% отказоустойчивости.
Вернемся с небес на землю и рассмотрим именно этот вариант. Вот что он включает в себя:
Автоматическое переключение трафика, в случае выхода из строя основных нод.
Несколько рабочих нод php и mysql.
Отличную вертикальную масштабируемость.
Что нам необходимо?
Нам необходимо развернуть:
Распределенная файловая система для кода bitrix. Чтобы любое изменение в коде проекта фиксировалось сразу на нескольких серверах.
Синхронная репликация mysql. Для распределения запросов и автоматического переключения трафика mysql.
Проксирование трафика. Для переключения трафика между серверами в случае выхода из строя одной из нод.
Проксирование трафика mysql. Для автоматического переключения трафика в базу данных между серверами в случае выхода из строя одной из нод.
Какими сервисами пользоваться для достижения выше указанных целей?
Для первой цели можно использовать Ceph либо GlusterFS. Для чего это необходимо?
bitrix умеет плодить файлы (очень много файлов), и если эти файлы будут отличаться на нескольких серверах, то будут возникать различные ошибки, связанные с отсутствием файлов на том или ином сервере, которые могут привести к критическим последствиям. Необходимо, чтобы на всех серверах был всегда актуальный код и файлы. Почему нельзя использовать синхронизацию lsync? Потому, что в синхронизации все равно могут быть задержки в отправке файлов, которые непростительны для bitrix.Для второй цели рекомендуем использовать Percona XtraDB cluster. Для чего это необходимо? Percona XtraDB cluster является самым удобным mysql cluster для администрирования. Вы забудете, что такое восстановление репликации, т.к. percona делает это все самостоятельно. Плюсом также является удобный Dashboard, который очень легко установить.
Для третьей цели рекомендуем использовать, nginx upstream, Haproxy или сервис используемый во множестве разных Дата Центрах “Network Load Balancer”. Для чего это необходимо? Нам необходимо отслеживать состояние нод php. Вышеуказанные сервисы позволяют, это сделать. Также позволяют управлять трафиком внутри кластера.
Для четвертой цели нам понадобится очень удобный ProxySQL, который легко поддается настройке и легкий в изучении. Для чего это необходимо? Т.к. в bitrix кластер mysql доступен только на дорогой лицензии. ProxySQL позволит нам обойти данное ограничение. С помощью ProxySQL мы сделаем резервные сервера и сможем управлять трафиком.
Схема инфраструктуры.
На данный момент имеются несколько вариантов схемы данной инфраструктуры, и отличаются они лишь во входе в кластер:
На входе используются proxy сервера с nginx upstream или Haproxy.
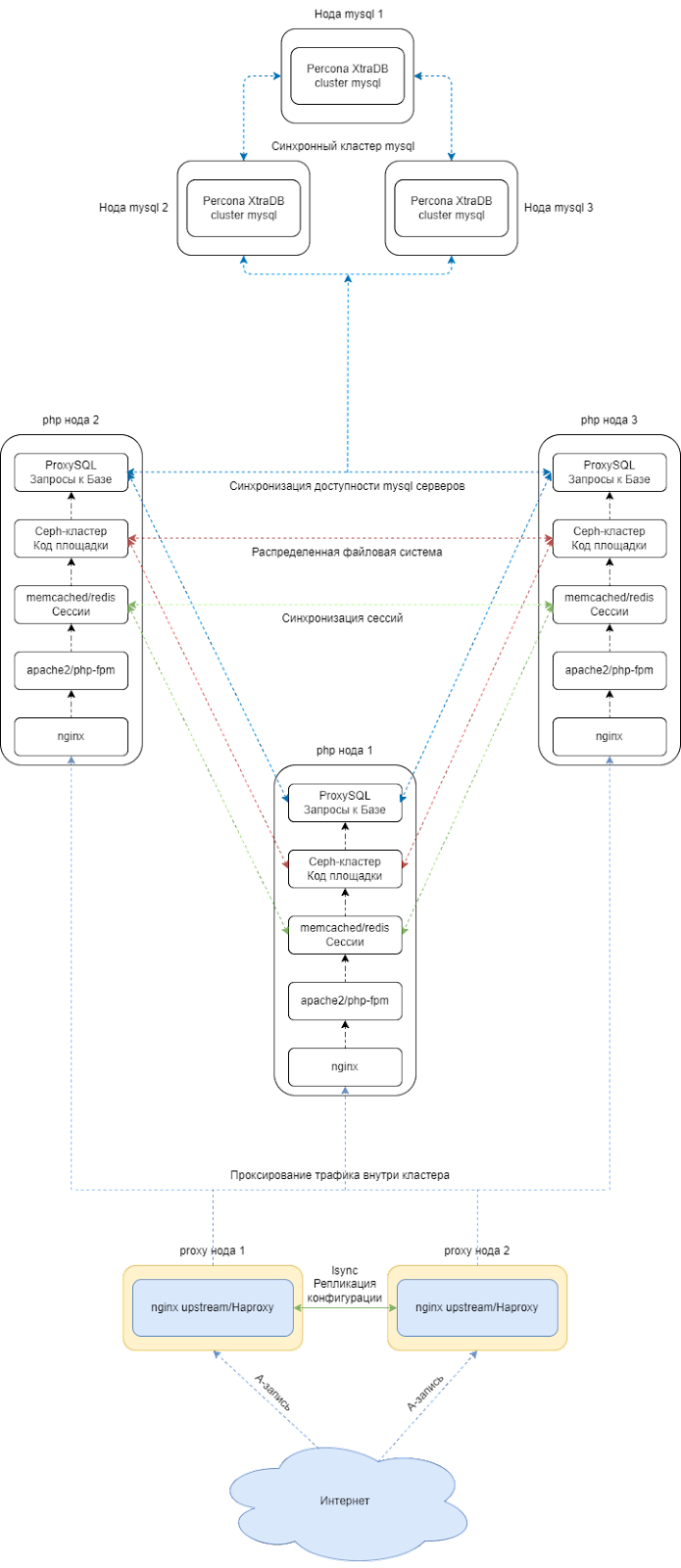
В инфраструктуру добавятся дополнительные два сервера. Стоимость их аренды будет невысока, потому как эти сервера не потребуют больших вычислительных мощностей. Однако, также есть и минусы: увеличение количества администрируемых серверов, а также некоторый рост нагрузки на системных администраторов. В данном методе А-запись ведет сразу на 2 сервера. После чего Proxy-ноды распределяют трафик по кластеру.
Более предпочтительный вариант, когда используется Load Network Balancer, т.к. по себестоимости он будет сопоставим с предыдущим, но при этом нагрузка на системных администраторов будет чуть пониже, чем в первом случае:
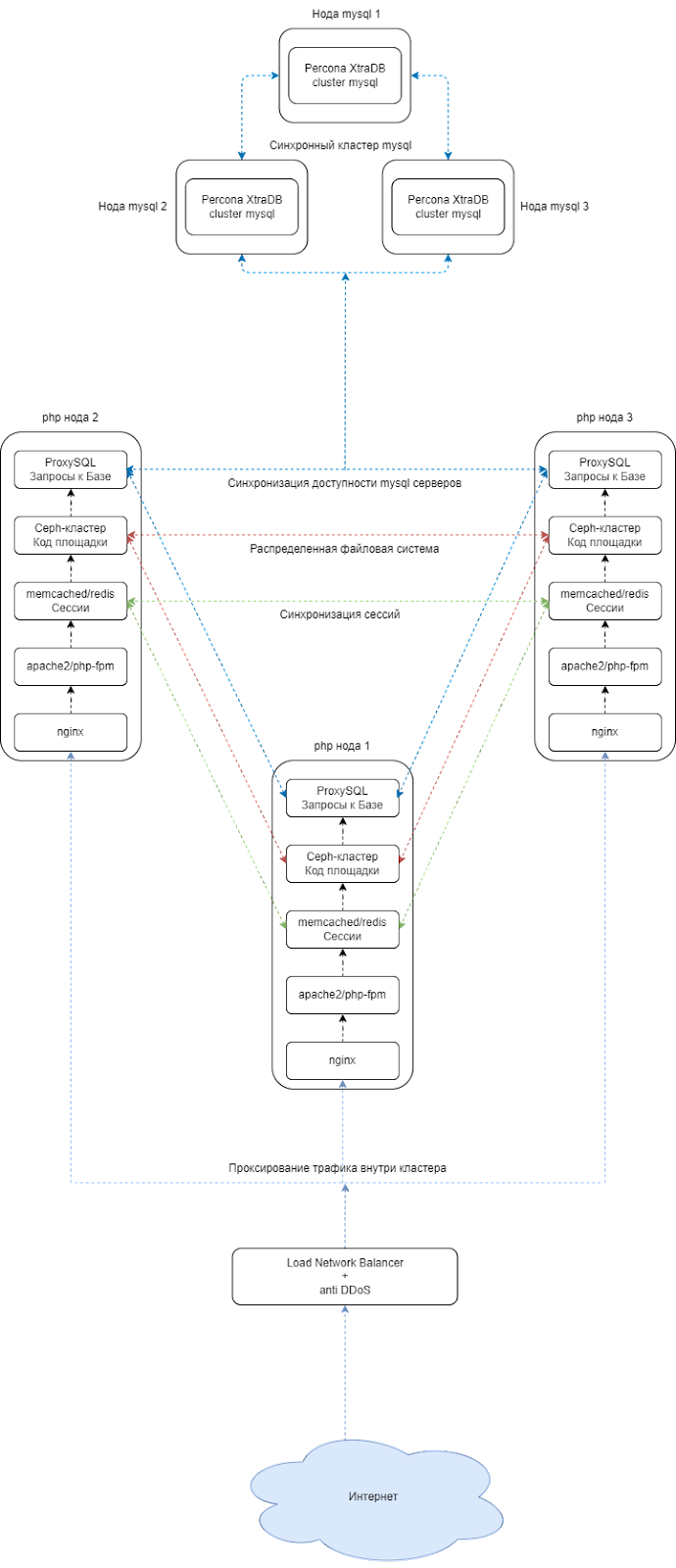
Плюсы данного решения. Это отсутствие ненужных серверов, за которыми необходимо следить.
Об инфраструктуре.
В этой инфраструктуре можно менять количество серверов. Главное - это иметь нечетное количество серверов mysql и php с ceph. Зачем это необходимо? Это необходимо для того, чтобы не было рассинхронизации данных в связи с проблемами в сети. Например, в случае проблем с сетью две ноды mysql будут считать себя главными и будут считать свои данные самыми актуальными. Когда сеть восстановится, будут проблемы и ошибки в данных, что приведет к проблемам работы проекта. Для устранения этой проблемы всегда необходимо использовать нечетное количество серверов.
Для отслеживания конфигурации сервисов на всех серверах можно использовать:
lsync-репликацию.
Управление серверами с помощью систем автоматизации (например, Ansible).
Использовать систему контроля версий Git.
В этом кластере удобно управлять серверами. Если необходимо провести работы на одной из нод, просто отключаете ее из проксирования и проводите свои работы. Также удобно добавлять новые ноды в кластер, если ваш проект вырос, и ему требуется дополнения вычислительной мощности.
Как все работает?
Трафик идет по А-записи на Load Balancer. В данном случае Load Balancer является точкой входа в кластер.
В Load Balancer трафик фильтруется с помощью встроенной защиты от DDoS, после чего легитимный трафик попадает в кластер. Load Balancer будет самостоятельно фильтровать трафик по нодам. Схему данной инфраструктуры можно масштабировать увеличивая количество нод.
Варианты фильтрации трафика на трех нодах?
50%/50%/0%.
Трафик будет идти на две ноды, а третью ноду можно использовать для cron задач или как запасной сервер для случая когда идет активная DDoS атаки или в связи с возросшим трафиков из-за распродажи.33%/33%/33%.
Трафик идет на три ноды одинаково.100%/0%/0%
Трафик идет только на одну ноду. Другие ноды будут резервные, либо ноды для тестирования конфигурации.
Рассмотрим вариант выхода из строя php ноды:
В рамках текущего примера в кластере упала нода с php под номером один. После получения 5-10 ошибок (в зависимости от настроек) со стороны ноды. Load Balancer выключит ноду из проксирования и пометит ноду как недоступную, после чего весь трафик пойдет только на рабочие ноды. Как итог, пользователи не заметят простоя.
Как происходит проверка доступности ноды? Load Balancer отправляет запросы на 80 порт каждой ноды и в случае, если он не получает какое-то количество ответов, он помечает ноду как нерабочую.
Рассмотрим вариант выхода из строя mysql-ноды: в этом случае ProxySQL пометит данную ноду как нерабочую, и все запросы перенаправит на другие ноды. Даже в случае выходы 2 нод mysql из строя, ваш проект не будет лежать, а сохранит работоспособность.
Кому подходит данный кластер?
Проекты с большой аудиторией. От 100 000 пользователей в день.
Большие интернет-магазины.
Все те, для кого простой площадок и сервисов неприемлем.
Кому не подходит данный кластер?
Маленькие проекты. Данный кластер будет для них избыточен, а также нерентабелен ввиду высокой стоимости инфраструктуры проекта.
Плюсы:
Высокий процент отказоустойчивости на различных уровнях.
В случае выхода из строя нескольких нод проект продолжит работать без простоя, даже под нагрузкой.
Легко масштабируется. Необходимо добавить диск или оперативной памяти? Просто отключаете сервер из проксирования и выполняете работы по замене.
Минусы:
Высокий уровень знаний для входа, так как мало кластер развернуть - его еще необходимо администрировать, поддерживать, мониторить и настраивать.
Данный вариант инфраструктуры очень чувствителен к ширине канала сети в Дата-центре, и потребует высокого производительных сетевых интерфейсов, т.к. Ceph и Percona XtraDB cluster очень зависит от скорости и качества работы сети.
Итог теоретической части.
Данной статьей мы хотели объяснить и рассказать вам про разные виды отказоустойчивой инфраструктуры. Какой именно вариант подойдет вашему проекту - решать конечно вам. При выборе следует руководствоваться тем, чего именно вы хотите достичь на вашем проекте. Конечно всем бы хотелось 95% отказоустойчивую инфраструктуру, но мы все понимаем, что развертывания подобной схемы потребуют больших капитальных вложений, а также усилий по настройке и поддержанию инфраструктуры. Согласитесь, было бы здорово минимизировать простой вашего сайта и обеспечить стабильную работу, за весь период эксплуатации - это чрезвычайно важно для бизнеса.
В следующей статье мы рассмотрим пример настройки кластера с 90% отказоустойчивостью. В ней постараемся обозначить все нюансы, а также основные подводные камни.
Все вопросы можете задавать в комментариях. Спасибо за уделенное нам время.
Также подписывайтесь на наш telegram-канал DevOps FM - там много полезного для DevOps-инженеров и системных администраторов.
Рекомендации для чтения:
