Комментарии 9
спасибо, топ контент
Я далёк от машинного обучения примерно так же, как от Луны, но решающие деревья мне стали нравиться ещё в институте своей простотой и объяснимостью результата. И примерно тогда же у меня возник вопрос.
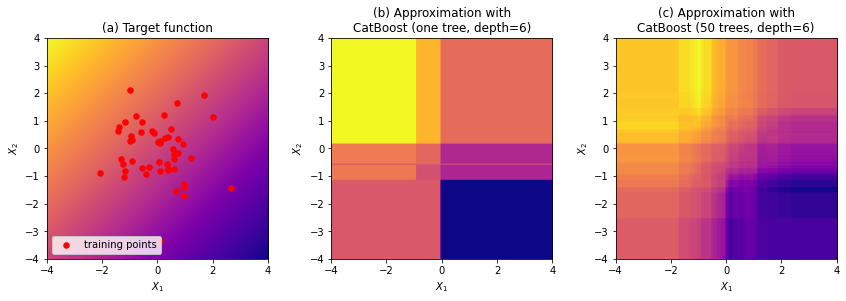
На рисунках 2б и 5б особенно хорошо видно, что в узлах дерева стоят условия вида `x > 0` и `y < -12`, что придаёт гафику/пространству/заливке характерную рублёную квадратность.
Рисунок 5
<img src="https://habrastorage.org/r/w1560/getpro/habr/upload_files/43b/6d5/97d/43b6d597daac3d2b4369fb44270e91f8.png"/>
{kind=link}
Я не справился с хабраредактором. Как переиспользовать урл картинки из статьи?..
Я вижу только полторы причины не использовать более сложные функции, хотя бы линейные и квадратичные, вместо простого сравнения с константой.
Первая – усложняется алгоритм выбора узла: вместо определения x/y координаты придётся определять вид подходящей функции и её параметры, что негативно скажется на времени обучения. (Зато на точности только положительно – примеры с рисунков 2 и 5 будет разбирать влёт, имхо.)
Половинка – затрудняется читаемость, если вдруг это дерево придётся анализировать. В силу своей далёкости от ML, не знаю, насколько это вообще востребовано.
Вопрос такой: почему я во всех примерах использования решающих деревьев вижу только сравнения с константами? И есть ли за пределами изысканий научной среды библиотеки/решения, которые используют функции чуть более высокой степени?
Привет, полностью согласен, что логично использовать более сложные разделяющие правила. Но время обучения действительно может увеличиться очень сильно, потому что придется перебирать больше вариантв разделения. Как это повлияет на обобщающую способность - не знаю, вообще не встречал нигде обсуждения этого вопроса.
Для деревьев решений есть такой родственный алгоритм детекции аномалий- Isolation Forest. Если коротко- мы для детекции аномалий нарезаем пространство на куски, но только не оптимизируя лосс, а случайно и потом строим статистику, которая будет показывать аномальность объекта. Логика проста: мы ищем объекты, которые либо слишком рано отсекаются в среднем, либо слишком поздно по глубине залегания и они и являются аномалиями.
И вот для него подобный подход с случайными (а не обучаемыми) подпространствами как раз был испробован вот в этой статье: https://arxiv.org/pdf/1811.02141.pdf
О плюсах и минусах собственно можно там же почитать.
вопрос
В итоге мы выбираем тот лист, признак и порог, для которых значение функции потерь наименьшее, и дополняем дерево новым разделяющим правилом.
Т.е. на этом листе конкретном листе минимальное значение функции потерь (теоретически 0), но мы пытаемся еще уменьшить?
Большое спасибо за статью, очень легко и интересно читается!
Все статьи про ML оперируют плоским вектором признаков. Но входные данные сами по себе имеют древовидную структуру, которая плохо укладывается в плоский вектор. Здесь конечно можно прикрутить фичу пропущенных признаков как то. Почему на эту тему практически ничего нет? Ведь в реальности мало случаев где входные данные просто плоский вектор. Растровую картинку я считаю уже банальным примером.
CatBoost, XGBoost и выразительная способность решающих деревьев