
Upd. 11.06.2022 Многие заинтересовались генерацией изображений нейросетями. Вот Colab (интерактивная среда для запуска кода) для рисования картинок в стиле pixel art по текстовому описанию. Просто запускайте, ближе к концу увидете ячейку для ввода текста. Примеры картинок из Colab'а в комментариях.
Два года назад я начал делать небольшой проект, связанный с обработкой текстов на иностранных языках. Он постепенно развивался и стал использоваться лингвистами в НКРЯ, а энтузиасты сохранения малых языков используют его для расширения своих параллельных корпусов.
Сегодня же я расскажу как при помощи него создать полноценную параллельную книгу на разных языках. Книга будет красиво сверстана в PDF, иметь содержание, обложку и две выровненные по смыслу колонки текста. Такие книги служат отличным подспорьем при изучении иностранного языка. Найти их, однако, не так просто, и скорее всего это будут книги для детей или избранная классика. Полный пример готовой книги можно посмотреть здесь. Под капотом у приложения NLP модели, поддерживаемых языков более ста.
Проект открытый и любой может в нем поучаствовать. Во многом благодаря сообществу и вашему участию он за несколько лет дошел до сегодняшнего дня. В общем штука годная, давайте уже посмотрим, что к чему.
1. Выравнивание
Ранее я писал о том, как подготавливать и выравнивать тексты при помощи Lingtrain Studio, поэтому пройдусь по этим пунктам вскользь, а на новых вещах остановлюсь подробней. Для наглядности я записал видео подсказку, которая поможет вам разобраться с интерфейсом. Актуальная версия программы (в видео скачивается через docker) — lingtrain/studio:v7.2.
Разметка текстов
Имея на руках два текста, чистим их от лишней информации — номеров страниц, сносок и т.п. Оставим только текст и метаданные — имя автора, заглавия и эпиграфы, если они есть. Чтобы эти дополнительные данные не участвовали в процессе выравнивания мы их пометим специальными метками, — так при создании выравнивания они отделятся от текстов и будут использованы только при оформлении книги.
Основные метки такие:
| Метка | Значение | Пример |
|---|---|---|
| %%%%%author. | Автор | Лю Ци Синь%%%%%author. |
| %%%%%title. | Название | Задача трёх тел%%%%%title. |
| %%%%%qtext. | Цитата | Тот, кто спасает одну жизнь, спасает весь мир.%%%%%qtext. |
| %%%%%qname. | Подпись под цитатой | Народная мудрость%%%%%qname. |
| %%%%%h2. | Заголовок | Глава 1%%%%%h2. |
С расставленными метками тексты выглядят примерно так:
Франц Кафка%%%%%author.
Замок%%%%%title.
К. прибыл поздно вечером. Деревня тонула в глубоком снегу. Замковой горы не было видно. Туман и тьма закрывали ее, и огромный Замок не давал о себе знать ни малейшим проблеском света. Долго стоял К. на деревянном мосту, который вел с проезжей дороги в Деревню, и смотрел в кажущуюся пустоту.
Потом он отправился искать ночлег. На постоялом дворе еще не спали, и хотя комнат хозяин не сдавал, он так растерялся и смутился приходом позднего гостя, что разрешил К. взять соломенный тюфяк и лечь в общей комнате. К. охотно согласился. Несколько крестьян еще допивали пиво, но К. ни с кем не захотел разговаривать, сам стащил тюфяк с чердака и улегся у печки. Было очень тепло, крестьяне не шумели, и, окинув их еще раз усталым взглядом, К. заснул.
...И второй:
Franz Kafka%%%%%author.
Das Schloss%%%%%title.
Es war spät abends, als K. ankam. Das Dorf lag in tiefem Schnee. Vom Schloßberg war nichts zu sehen, Nebel und Finsternis umgaben ihn, auch nicht der schwächste Lichtschein deutete das große Schloß an. Lange stand K. auf der Holzbrücke, die von der Landstraße zum Dorf führte, und blickte in die scheinbare Leere empor.
Dann ging er, ein Nachtlager suchen; im Wirtshaus war man noch wach, der Wirt hatte zwar kein Zimmer zu vermieten, aber er wollte, von dem späten Gast äußerst überrascht und verwirrt, K. in der Wirtsstube auf einem Strohsack schlafen lassen. K. war damit einverstanden. Einige Bauern waren noch beim Bier, aber er wollte sich mit niemandem unterhalten, holte selbst den Strohsack vom Dachboden und legte sich in der Nähe des Ofens hin. Warm war es, die Bauern waren still, ein wenig prüfte er sie noch mit den müden Augen, dann schlief er ein.
...Выравнивание
Давайте теперь выровняем эти тексты. Нужно запустить Lingtrain Studio, для этого придется применить некоторые технические навыки. Если что-то будет не понятно, то смело пишите к нам в группу, разберемся.
Для запуска приложения у себя на компьютере поднадобится docker. Выполним следующие команды:
#эта команда скачает образ с приложением
docker pull lingtrain/studio:v7.2#эта команда подключит к образу папки и запустит его
docker run -v E:\lingtrain\data:/app/data -v E:\lingtrain\img:/app/static/img -p 80:80 lingtrain/studio:v7.2В данном примере у вас на компьютере должны быть папки E:\lingtrain\data и E:\lingtrain\img, в которых будут храниться выравнивания. Контейнер с приложением и моделями скачается из интернета и запустится на 80-м порту. Откроем приложение в браузере по адресу localhost.
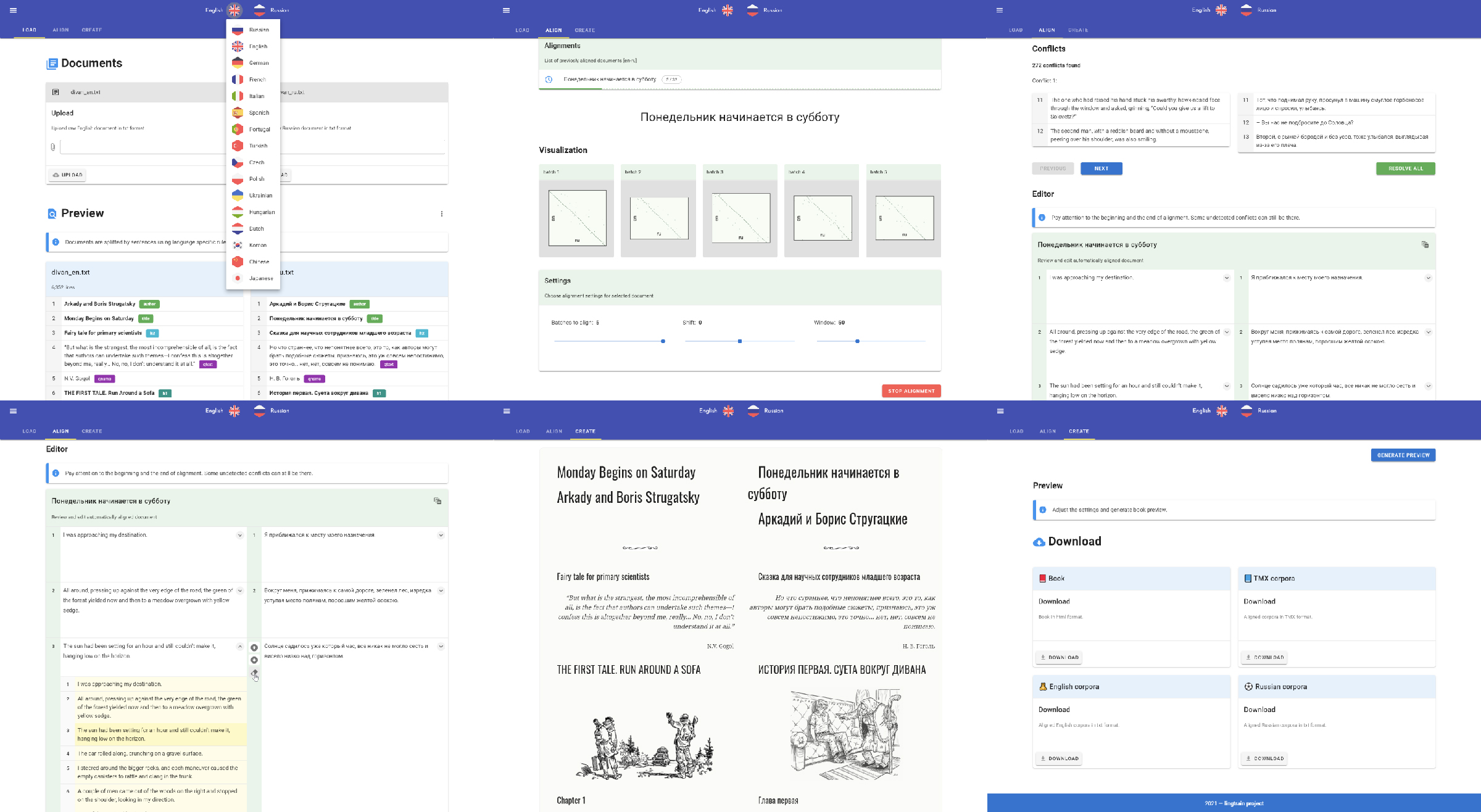
Более подробно про интерфейс приложения и как им пользоваться можно почитать здесь, а про технические детали здесь.
Экспорт в различные форматы
На последней вкладке мы можем скачать наше выравнивание в различных форматах.
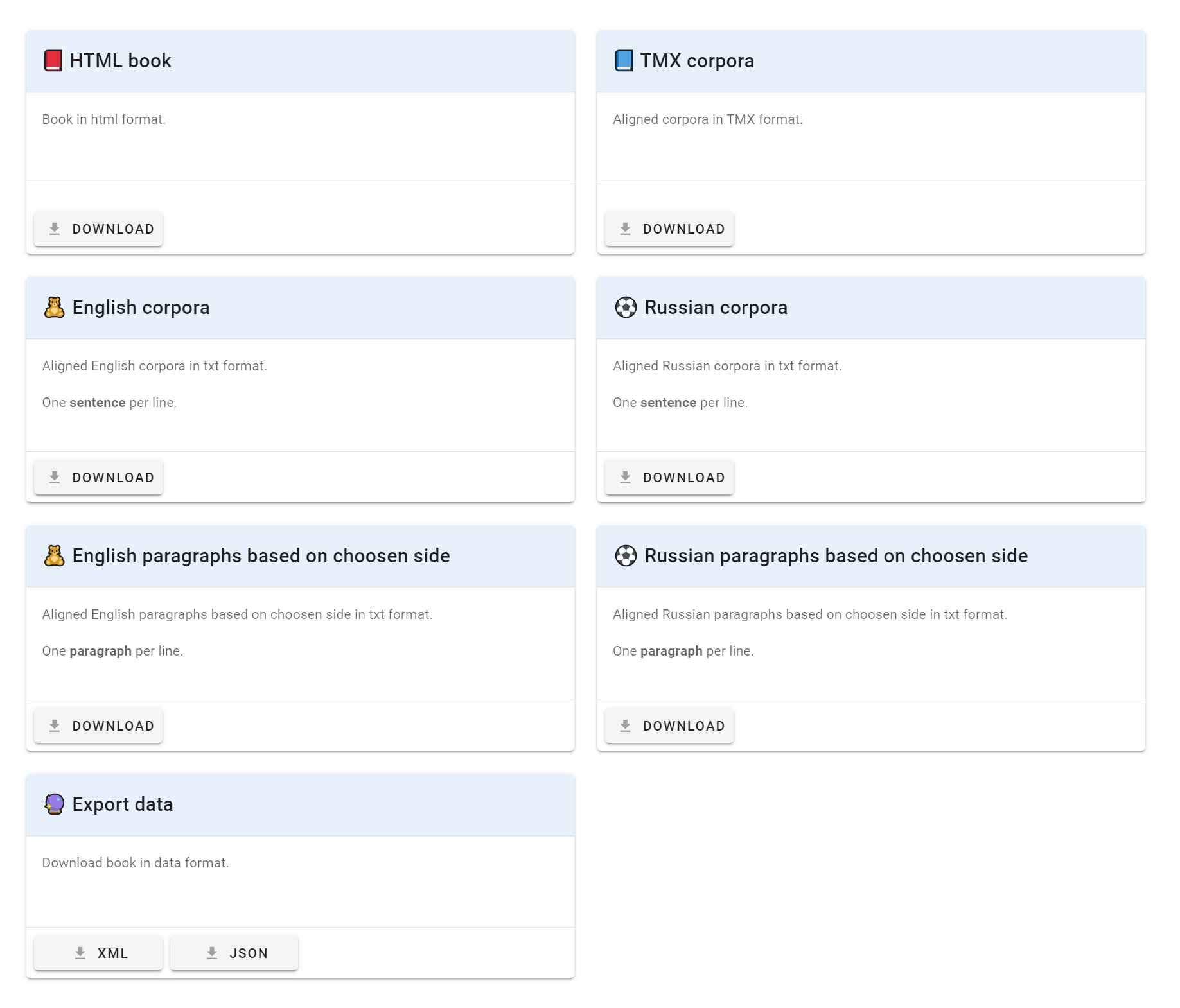
Скачаем HTML. Экспорт в этот формат поддерживает все наши метки и позволяет добавить подсветку соответствующих предложений. Можно выбрать на какой стороне листа будет какой язык и на основе какого исходного текста формировать абзацы параллельного текста.
Готовая веб-страничка выглядит так:

Или так:

Дальше мы посмотрим как можно стилизовать нашу книжку.
2. PDF
Теперь новое, — поговорим о том, как из извлеченных параллельных данных сгенерировать красивую книгу в PDF формате. Для этого скачаем из Lingtrain Studio данные в виде XML.

Ограничения
На данный момент для PDF поддерживается не вся доступная разметка. Как и прежде обязательно должны быть метки автора и названия; метки заголовков должны быть только вида %%%%%h2., из них будут генерироваться содержание и колонтитулы. Поддержка полной разметки (эпиграфы, цитаты и картинки) появится в ближайшем будущем.
Инструменты
Верстка в PDF происходит следующим образом. Сначала из данных (XML) генерируется веб-страничка (HTML). Затем к ней добавляются стили (CSS), и все это идет на вход замечательной библиотеке weasyprint. Она умеет оптимально верстать и экспортировать в PDF формат в отличие печати в PDF из браузера. Финальная книга будет с обложкой, работающими ссылками в содержании (если была h2 разметка), иметь колонтитулы и вообще выглядеть красиво.
Для начала надо установить библиотеки и их зависимости. Проще всего делать это так (опять же, если возникнут трудности, то не стесняйтесь, пишите в канал):
sudo apt install libpango1.0-dev libjpeg-dev zlib1g-dev default-jre
sudo apt install libsaxonb-java
python3 -m pip install weasyprint==52.5Если вы пользуетесь Windows, то вам понадобится WSL, а пользователи Linux, думаю, разберутся во всем без подсказок.
Верстка
Следующим шагом нужно заглянуть в репозиторий с проектом, в папке tools/pdf есть необходимые нам скрипты и примеры их использования.
Свой xml файл, полученный из выравнивателя, для удобства положите в папку data.
Теперь можно воспользоваться скриптом create_pdf.sh. Пару слов о нем, это просто bash скрипт, который автоматизирует создание книги. В шаблонах зашиты переменные для включения цветовой подсветки, путь к картинке для обложки, подсказки для японского и китайского и некоторые другие. Скрипт переопределяет эти настройки и запускает генерацию.
Параметры генерации:
| Аргумент | Описание | Пример |
|---|---|---|
| -i | Путь к XML файлу. | ./data/puaro_zh.xml |
| -o | Путь к итоговому PDF. | ./puaro_zh.pdf |
| -s | CSS стили | ./book.css |
| -x | XSLT трансформация. | ./book2html.xslt |
| -p | Путь к обложке (путь должен быть относительным к xml файлу). | ./covers/mycover.jpg |
| -c | Включить подсветку | |
| -t | Включить фонетические подсказки (японский и китайский языки) |
Трансформацию и стили можно не указывать, тогда будут использоваться файлы, лежащие в папке со скриптом. Путь к обложке надо указать относительно XML файла, так как этот путь попадет в промежуточный HTML. Формат книги А4, поэтому картинка для обложки должна быть примерно такого же размера.
Про картинки
Замечу, что картинки для обложки можно генерировать нейросетями. Сейчас это очень популярное направление, недавно вышли релизы Imagen и DALL-E 2, но в открытом доступе их пока что нет. Из доступных есть ruDALL-E. Также есть компания midjourney, которая предоставляет бесплатный доступ к бета версии своих моделей. В любом случае, в папке data/covers есть несколько примеров, можете взять их или добавить свою картинку.
Вот так сейчас рисуют нейросети:

Иллюстрация к роману "Пикник на обочине" Стругацких.
Создание книги
Для примера запустим следующий скрипт (все эти файлы есть в репозитории). Рекомендую сначала запустить его, а когда получится, можете класть в папку data свой XML файл с книгой и запускать генерацию.
./create_pdf.sh -i ./data/schloss.xml -o ./examples/schloss.pdf -p ./covers/schloss.jpg -cВ зависимости от размера файла процесс может занимать от нескольких секунд, до пары минут.
#началась генерация
-----------------------------------------------------------------------------------------------------
Book parameters:
- Input file: ./data/schloss.xml
- Output file: ./examples/schloss.pdf
- XSLT tranformation: ./book2html.xslt
- CSS styles: ./book.css
- Cover image: ./covers/schloss.jpg (path is relative to input file).
- Color highlighting: true
- Tips (zh, jp langs): false
-----------------------------------------------------------------------------------------------------
Replacing parameters in xslt...
Generating html file ./data/schloss.xml.html...
Creating PDF ./examples/schloss.pdf...
Removing temp files...
Done.Стилизуй для себя
Настройки форматирования книги находятся в файле book.css. Можете поиграться с настройками и отформатировать книгу как вам хочется. Кроме того в этом файле можно настроить ширину левой и правой колонки. Это особенно важно для иероглифических текстов с подсказками, так как они занимают гораздо больше пространства.
Вот идеи по настройке форматирования под себя:
- отступы
- цвета подсветки
- шрифты
- ширина колонок
- расстояния и размеры заголовков
Результат
На выходе получаем вот такую книгу:


Если бы в выравнивании были метки %%%%%h2., то сгенерировалось бы содержание с работающими ссылками:

3. Не только лишь книги
Как я уже говорил, применение проекта не ограничивается книгами. Из Lingtrain Studio можно экспортировать параллельные корпуса и TMX файлы. Параллельные корпуса затем можно использовать для дообучения моделей машинного перевода. Кроме того, благодаря энтузиастам, любящим свои родные языки, появилась возможность дообучения модели под более редкие языки. Про результаты можно почитать в этой статье.
4. Продолжение
Проект выравнивателя развивается несколько лет и вырос из соревнования на машинный китайско-русский перевод, которое организовал madrugado. Благодаря команде русско-китайского параллельного корпуса НКРЯ он получил дополнительный стимул к развитию. Сейчас наше небольшое сообщество обрастает любителями языков и подпитывает проект идеями, поэтому приглашаю к нему присоедиться, ссылка в конце статьи.
Для интересующихся тонкостями машинного обучения и новостями из мира ИИ я веду еще один канал.
Если есть идеи, критика или слова поддержки, — жду от вас весточки!
Ссылки
- Канал проекта — сюда все вопросы по генерации и языкам.
- Канал про ML — рассказываю про новости машинного обучения, делюсь опытом.
- GitHub — код проекта (заводите issue, ставьте звездочки).
