
Привет, Хабр! Меня зовут Клоков Алексей, сегодня поговорим об алгоритмах компьютерного зрения, обработке видеопотока и методах трекинга множества объектов без разметки (unsupervised multiple object tracking) на примере пузырьков. Методичка будет полезна как опытным специалистам, перед которыми стоит похожая задача, так и начинающим энтузиастам. На основе черновика этого текста и экспериментов получилось опубликовать научную статью в Journal of Mineral and Material Science.
В тексте вы найдете:
— описание домена данных и технологического процесса флотации;
— подход к cегментации множества подобных объектов;
— существующие методы трекинга без разметки;
— подход к одновременному сопровождению множества подобных объектов;
— сравнение качества работы алгоритмов и много демонстраций
Написать статью было решено после выполнения одного из рабочих проектов в добывающей промышленности. Наша команда анализа данных занимается проектами разработки и внедрения искусственного интеллекта в промышленные цепочки Норникеля. Например, на этапе обогащения внедряются алгоритмы компьютерного зрения, которые анализируют поток пены в процессе флотации. На схеме ниже показано место флотомашин в глобальной технологической цепочке:

1. Введение, техпроцесс пенной флотации
Флотация – процесс обогащения полезных ископаемых, т.е. обработка сырья, при которой происходит отделение полезных минералов от пустой породы. Пенная флотация – один из видов флотации, при котором отделение минералов от пустой породы происходит на основе физических свойств этих минералов. В огромном резервуаре флотомашины вспенивается перетертая в порошок (0.1-0.2 мм) порода, вода и реагенты. Частицы гидрофобных полезных минералов прикрепляются к образовавшимся пузырькам маслянистой пены. Пузырьки всплывают вверх, а остальная порода — опускается вниз. Следующая иллюстрация взята из статьи.

Полное разделение полезного от всего остального – очень сложная задача, поэтому технология направлена на постепенное увеличение концентраций полезных веществ. Например, после одного цикла работы флотомашины концентрация никеля может увеличиться с 0.01% до 3%. Таких циклов может быть несколько – для этого создается каскад флотомашин, т.е. пена из одной флотомашины переливается в следующую. После работы последней флотомашины в каскаде пену отправляют на фильтрацию, сгущение и сушку. Исходник для следующей иллюстрации тоже взят из этой статьи.

Качество и вид пены отражает физические и химические процессы в резервуаре флотомашины. Наблюдая за пеной, технолог понимает, насколько хорошо идет процесс обогащения и как им управлять (добавить воды, реагента или породы). Компьютерный мониторинг характеристик пены может быть использован для упрощения работы технологов или для автоматического управления огромным цехом флотации. Поэтому над каждой флотомашиной были установлены камеры, которые ведут наблюдение за переливом:

2. Постановка задачи и данные
Итак, нужно создать систему компьютерного зрения, которая умеет обрабатывать видеопоток и определять основные характеристики пены в автоматическом режиме. Количество объектов-пузырьков на каждом кадре может достигать несколько сотен, и они не так сильно друг от друга отличаются (вот если трекать людей, то там лица и одежда хоть разные). Система должна работать real-time на нескольких десятках камер, поэтому возникает проблема оптимизации и масштабирования.
К основным компутер вижн фичам признакам пены могут относиться:
— размер пузырьков;
— количество пузырьков;
— вид и форма пузырьков;
— время жизни пузырьков;
— цветовая гамма пены;
— наличие потоков в пене;
— скорость образования пены;
— направление и скорость пеносъема;
— вид течения пены (ламинарное/турбулентное).
Для определения размера, формы и количества пузырьков подойдет семантическая сегментация, а для интерпретируемого анализа скорости/направления пены — трекинг пузырьков. Куда и на сколько смещаются пузырьки — туда и течет пена с определенной скоростью.
Трекинг — это сопровождение определенного объекта в видеопотоке. В самом простом случае, нужно распознать объект, определить его координаты на соседних кадрах, присвоить уникальный идентификатор, отследить перемещение (демка отсюда)

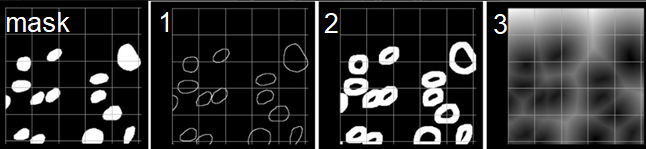
В распоряжении было много данных с разметкой для семантической сегментации: мы работали не только над получением настоящей разметки, но и над созданием синтетических данных. А вот для задачи трекинга, к сожалению, размеченных данных было очень мало: в общей сумме 30 секунд видеозаписей. Такого количества данных не хватит на обучение, но их можно использовать для оценки качества работы алгоритмов. Так выглядят размеченные маски пузырьков для задачи сегментации:

3. Краткий обзор методов unsupervised трекинга
Если нет данных для обучения, то нужно смотреть в сторону алгоритмов unsupervised трекинга. Раскидаем всё по полочкам:
- У любого объекта на картинке можно выделить признаки. Это могут быть физические размеры, гистограмма цветности или неинтерпретируемые признаки, полученные некоторым преобразованием (функцией, алгоритмом, нейронной сетью и т.д.).
- Чтобы найти объект(-ы) на картинке, можно применить машинное обучение или эвристики. Модели детекции/сегментации требуют разметки. А правила/эвристики могут быть основаны на заранее собранных признаках объекта, координатах его появления на предыдущих кадрах и понимании правил его движения.
- Если хочется трекать один объект, то всё сводится к поиску этого объекта на каждом кадре.
- Если хочется трекать множество объектов одновременно, то решение будет состоять не только из поиска всех интересующих объектов, но и сопоставления объектов на одном кадре объектам на следующем кадре.
- Сопоставление/ассоциация объектов друг другу может происходить на основе разметки (это будет называться supervised multiobject tracking — не наш случай, но тема хорошо раскрыта тут), или на основе корреляции признаков объектов без разметки.
Этот алгоритм решает задачу матчинга, т.е. сопоставляет объектам из множества X другие объекты из множества Y. Пусть на первом кадре будут n объеков с такими признаками: X1(x11,x12,…,x1d), X2(x21,x22,…,x2d), ..., Xi(xi1,xi2,…,xid), ..., Xn(xn1,xn2,…,xnd). А на втором кадре пусть будут уже m объектов с немного другими признаками: Y1(y11,y12,…,y1d), Y2(y21,y22,…,y2d), ..., Yj(yj1,yj2,…,yjd), …, Ym(ym1,ym2,…,ymd). Сначала алгоритм строит матрицу схожести объектов каждый-с-каждым на основе их признаков по некоторой выбранной метрике similarity_function(Xi,Yj) — это может быть любая кастомная функция или известные MSE, MAE, cos_distance, IoU (и их комбинации):

Далее поиск пар назначений/соответствий {Xi:Yj,...} осуществляется на основе преобразования этой матрицы и анализа максимальных элементов в ней. Прочитать более подробно этот этап можно в отличной статье. "На пальцах" венгерский алгоритм можно объяснить так: если признаки двух объектов схожи на соседних кадрах, то это есть один и тот же объект.
# Венгерский алгоритм python код
from scipy.spatial import distance
from scipy.optimize import linear_sum_assignment
# X1 = (x11,x12,...,x1d) # len(X1)=d
# ...
# Xn = (xn1,xn2,...,xnd) # len(Xn)=d
# Y1 = (y11,y12,...,y1d) # len(Y1)=d
# ...
# Ym = (ym1,ym2,...,ymd) # len(Ym)=d
# X = [X1,X2,...,Xn] # len(X)=n
# Y = [Y1,Y2,...,Ym] # len(Y)=m
matches = {}
cost_mtr = distance.cdist(X,Y, metric='euclidean') # cost_mtr.shape=(n,m)
i,j = linear_sum_assignment(cost_mtr)
for i, j in list(zip(i, j)):
matches[X[i]] = Y[j]
# matches = {Xi:Yj, ... }Важной частью работы data scientist'a является изучение данных, поиск закономерностей и паттернов. Для построения трекера нужно обратить внимание на то, как двигаются объекты в целевом домене данных. Например, машины, в основном, двигаются линейно; люди — двигаются хаотично, но только по пешеходным зонам, могут исчезнуть за временной преградой; пузырьки плывут в общем потоке, не могут "перепрыгнуть" через соседа, не могут быть перекрытыми, но могут лопнуть/соединиться.
Правилами могут являться и полноценные модели движения, например, если объект двигается прямолинейно и если известны начальная координата объекта x0, его скорость V, ускорение a: 
Для предсказания следующего положения объекта может помочь фильтр Калмана (Kalman filter), который работает на основе моделей движения и предыдущих положений. Еще он используется для уменьшения шума/погрешности в координатах сопровождаемого объекта. Более подробно о фильтре можно прочитать здесь, тут и вот тут
Simple Online and Realtime Tracking — это популярный алгоритм, который состоит из венгерского алгоритма и фильтра Калмана. Фильтр Калмана используется для предсказания потенциального положения объекта на нескольких следующих кадрах, если трек оборвался или объект временно пропал из виду. Неплохая реализация SORT на python на github.
Разновидностей SORT'а много, например, ByteTrack — который не забывает про объекты с низкой уверенностью распознания на текущем кадре. Он проводит дополнительный раунд матчинга среди таких объектов. Однако, добавление новых стадий в алгоритм (для анализа сложных сцен) приводит к увеличению времени его работы.
Команда энтузиастов создала открытое решение в коде на основе идей из статьи MCMCDA (Markov Chain Monte Carlo Data Association). Для решения задачи многообъектного трекинга без разметки используются признаки найденных объектов, метод Монте-Карло для марковских цепей и фильтр Калмана.
На основе демок в репо можно сделать вывод, что для трекинга людей может использоваться поза человека как признак. Также авторы кода пишут, что умеют решать проблему движущейся камеры с помощью перехода в неподвижную систему координат.
В основе Incremental Visual Tracker лежит PCA алгоритм, помогает автоматически выделить признаки целевого объекта, которые будут использоваться для поиска этого же объекта на следующих кадрах. Привожу цитату из статьи, которую рекомендую к прочтению:
Трекер относится к классу так называемых appearance-based трекеров. Идея appearance-based подхода состоит в том, чтобы создать или обучить признаковое описание целевого объекта на начальном кадре и отслеживать его перемещение с помощью этого описания на последующих кадрах
"На пальцах" работу можно объяснить так: подход смотрит на изменяющуюся часть кадров, ищет смещение групп пикселей, которые на одном кадре были в одном месте, а на следующем — в другом. Поэтому подходы на основе оптического потока не являются интерпретируемыми с точки зрения движения конкретных объектов. Про алгоритм оптического потока хорошо рассказано и показано тут, а про его проблемы разобрано в этой статье — в ней еще показаны методы supervised трекинга и другие классные штуки.
4. Семантическая сегментация пузырьков
Чтобы сделать трекинг пузырьков, нужно сначала распознать эти пузырьки на кадре. Наличие данных для сегментации позволяло сделать модель как сегментации, так и детекции. Выбор пал на сегментацию, так как информация о форме пузырька может быть полезной для трекинга. Наши пузырьки похожи на биологические клетки, о сегментации которых подробно написано в одной из самых известных DL статей — картинка ниже тоже оттуда.

Поэтому применяем архитектуру Unet c энкодером ResNet18 (предобученном на ImageNet). Во время обучения сильно штрафуем за ошибки в пикселях около/на границах пузырьков – чтобы сеть старалась отделять маски соседних пузырьков друг от друга. Для автоматического поиска пикселей, за которые будем давать большой штраф, можно использовать разные алгоритмы обработки бинарных масок.
Результаты применения функций кода к маске p:
import cv2
def border1(p):
p_dilate = cv2.dilate(p, np.ones((3, 3), np.uint8), iterations=1)
border = (p != p_dilate).astype(np.uint8)
return border
import torch.nn.functional as F
def border2(p):
averaged_mask = F.avg_pool2d(p.float(), (11, 11),
stride=(1, 1),
padding=(5, 5))
border = ((averaged_mask > 0.01) * (averaged_mask < 0.99)).long()
return border
from scipy.ndimage import distance_transform_edt as distance
def border3(p):
res = np.zeros_like(p)
posmask = p.astype(np.bool)
if posmask.any():
negmask = ~posmask
res = distance(negmask) * negmask - (distance(posmask) - 1) * posmask
return resОбучаем модель на кропах с различными аугментациями, а на инференсе подаем всю картинку (архитектура же fully convolution). В итоге, получаем работающую модель-сегментатор пузырьков:

5. Одновременный трекинг множества подобных пузырьков
… обучить архитектуру автоэнкодера! Энкодер-часть такой модели будет преобразовывать маску пузырька в некоторый эмбеддинг-вектор (feature vector), в котором будет храниться вся информация о форме пузырька. Эксперименты для получения хороших весов VAE помогли сделать Pashtetikus и Kadgar.
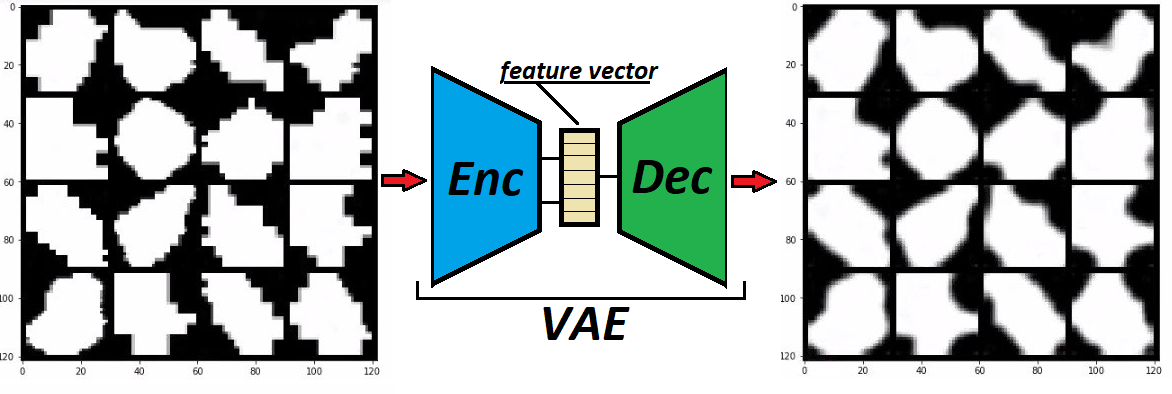
Особенность нашего домена данных — большое количество пузырьков в кадре, которые похожи друг на друга. С одной стороны, это создает определенные проблемы, а с другой — накладывает некоторые физические ограничения на движение пузырьков. Пузырьки в общем потоке не могут "перепрыгнуть" через соседа или быть перекрытыми, но могут лопнуть/соединиться. Исходя из таких закономерностей, накидаем план действий и перейдем к визуализации результата.
- С помощью модели-сегментатора получаем маски пузырьков
- На основе масок получаем признаки каждого пузырька для двух соседних кадров. Количественные признаки пузырька: координаты центра, ширину, высоту, площадь. Качественный признак пузырька: форма. Создаем из них вектор признаков каждого пузырька.
- Запускаем венгерский алгоритм, который старается каждому пузырьку Xi на первом кадре найти пару Yj из второго кадра. При этом для вычисления матрицы схожести используем взвешенную сумму нескольких метрик: для количественных признаков — MSE, для эмбеддингов формы — cos_distance. Записываем все найденные пары в словарь: {Xi: Yj, …}.
- Венгерский алгоритм может ошибаться, может сопоставить пузырек_A на первом кадре другому на втором кадре, который не является тем же самым пузырьком_A. Поэтому отфильтруем аномальные пары по следующим правилам:
- пузырек не может сдвинуться на расстояние, которое в K раз больше, чем размер самого пузырька;
- смещение пузырька не может быть в L раза больше или меньше предыдущего смещения, то есть он не может резко ускориться или замедлиться;
- пузырек не может резко поменять направление своего движения, т.е. косинусное расстояние между векторами предыдущего смещения и текущего не должно быть меньше порога G.
- Визуализируем покадровые смещения пузырьков и их траектории, длина которых больше 5 точек:



6. Сравнение алгоритмов
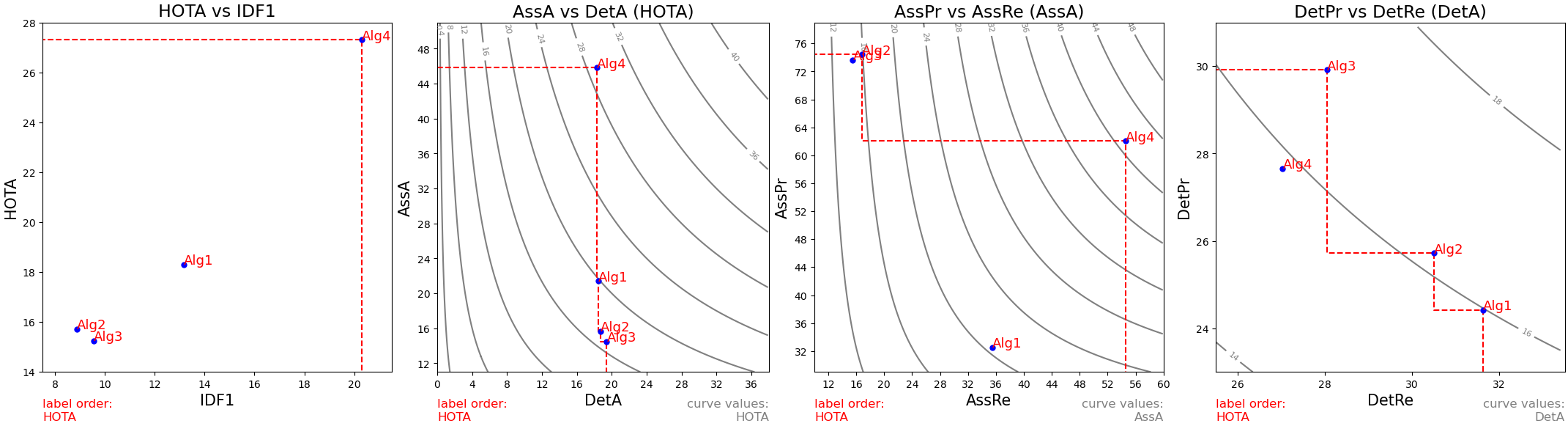
Посмотрим на следующие комбинации:
— Alg1 = венгерский алгоритм (количественные признаки)
— Alg2 = венгерский алгоритм (количественные признаки) + правила движения
— Alg3 = венгерский алгоритм (количественные признаки и форма) + правила движения
— Alg4 = венгерский алгоритм (количественные признаки) + фильтр Калмана (=SORT)
Усредненные метрики качества алгоритмов сопровождения пузырьков на небольшом количестве размеченных данных (10 видеозаписей разной пены по ~3 секунды каждый) и производительность на тестовом CPU (AMD Ryzen5 3600). На демке ниже алгоритмы расположены в такой же последовательности: [Alg1,Alg2,Alg3,Alg4].
| Метрика | Alg1 | Alg2 | Alg3 | Alg4 |
|---|---|---|---|---|
| HOTA | 18.31 | 15.72 | 15.25 | 27.32 |
| MOTP | 65.17 | 65.22 | 65.36 | 64.92 |
| OWTA | 24.41 | 20.42 | 18.69 | 33.76 |
| IDF1 | 13.16 | 8.88 | 9.54 | 20.29 |
| IDSW | 0.43 | 0.93 | 0.98 | 0.03 |
| . | . | . | . | . |
| FPS | 17.4 | 16.1 | 11.2 | 13.7 |

После усреднения перемещений пузырьков получаем скорость пены. Сравним предсказанную скорость с реальной скоростью пены. Ошибку величины скорости будем оценивать с помощью MAPE, а ошибку направления — косинусным расстоянием.
| Метрика | Alg1 | Alg2 | Alg3 | Alg4 |
|---|---|---|---|---|
| MAPE | 0.201 | 0.183 | 0.178 | 0.131 |
| COS | 0.824 | 0.868 | 0.869 | 0.882 |
Выводы: в нашем домене данных по метрикам качества лидирует Alg4, а по балансу качество-производительность — Alg2. Разница в производительности между Alg4 и Alg2 объясняется тем, что для фильтра Калмана требуется больше вычислений, чем для проверки условий в правилах движения.
7. Применение подобного трекера в другой задаче
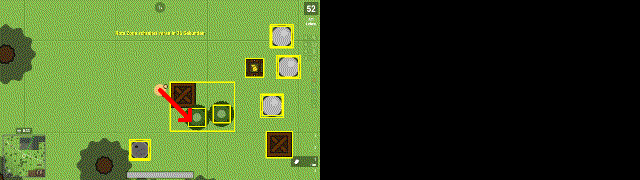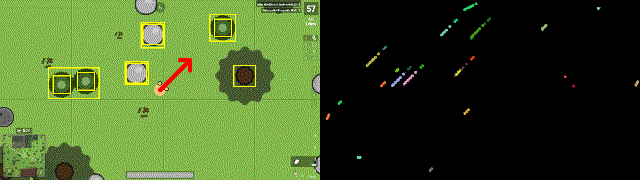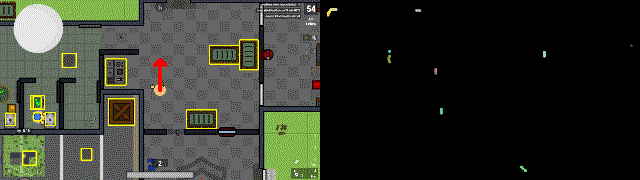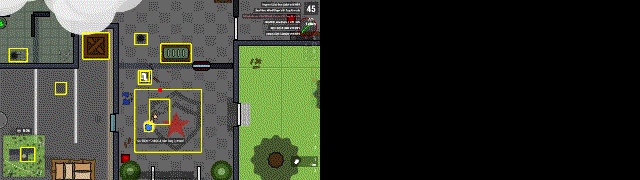
Задача из личных пет — проектов по разработке RL бота для игры surviv.io. Возникла потребность определять на видеозаписи направление движений персонажа. Для этого на соседних кадрах находим основные объекты и направление их сдвига. Если все объекты (желтые прямоугольники) на кадре сдвинулись в одну сторону, значит сам персонаж двигался в противоположную сторону (красная стрелка).
Статьи коллег моего отдела о ML в промышленности:
— Создание синтетических данных для сегментации
— Настройка графического интерфейса для демонстраций
