
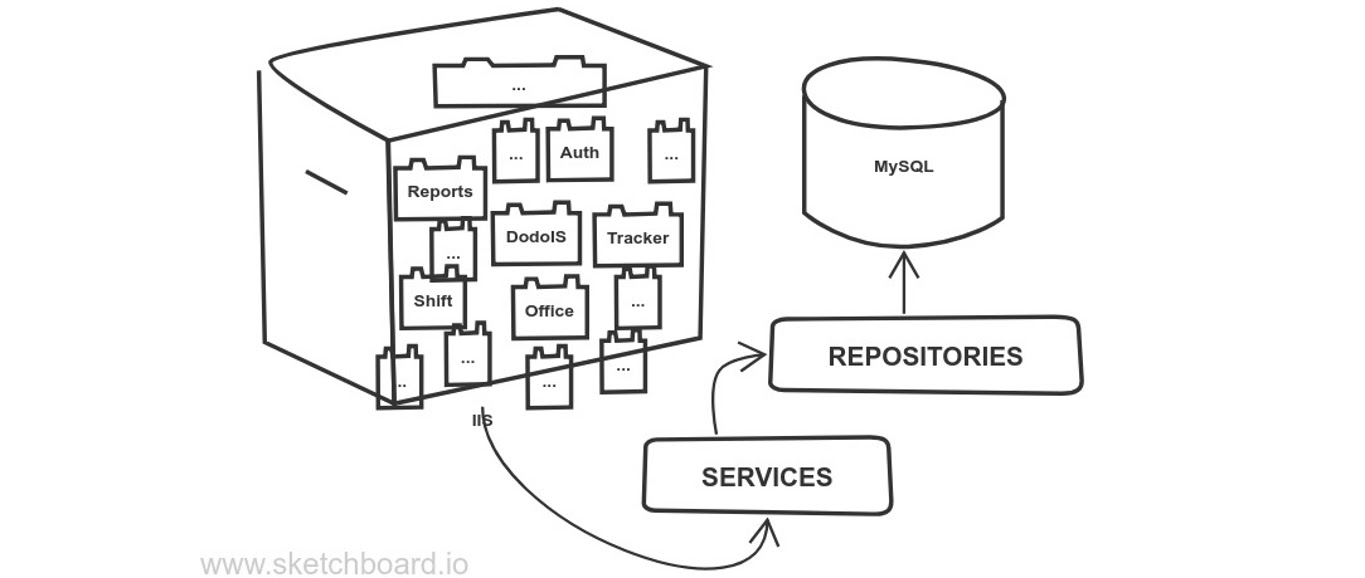
Многие проекты на Django начинаются просто: есть база данных и к приложению, которое крутится на сервере, идут обращения. Например, так начиналась Dodo IS (информационная система компании Додо Пицца, где работал автор сегодняшней статьи). Но если использовать Django из коробки, можно натворить много бед и встретить пачку антипаттернов. Возможно, вы встречали такое на старых legacy-проектах.
Евгений Пешков развивает сообщество DDD-практиков, рассказывая, какие проблемы решает Domain-Driven Design (предметно-ориентированное проектирование) в современном мире. На конференции Russian Python Week 2020 он выступил с рассказом об этом. Кстати, 19 августа пройдет встреча DDDevotion-сообщества, присоединяйтесь, будем о чем поговорить.
В сегодняшней статье будет его рассказ про то, как устроен Domain-Driven Design и какие инструменты использует, чтобы наиболее точно описать требования бизнеса и сам бизнес.

Мы привыкли начинать проект с базы данных, хотя она может стать одним из источников проблем для бизнес-приложения. Потому что бизнес растет, и вслед за ним повышается сложность системы. Появляются новые приложения, их становится всё больше. И самое плохое, что в итоге может произойти — все сущности переплетутся, даже если вы используете разделение по слоям.
И это даже не про долгий деплой. Это полбеды — мы знаем, как с этим бороться. Гораздо хуже, что код получается запутанным — вы не сможете взять кусочек системы и обособленно его развивать. Трогая какие-нибудь отчеты, вы совершенно неожиданно можете затронуть бэк-офис. Очень неприятно с таким работать.
Другая большая проблема такого подхода — это универсальные модели. Во-первых, каждый раз вы используете только ее часть. Вы, конечно, можете выбрать только те поля, которые нужны в application-сервисе. Но модель к вам уже пришла целиком, а вы не использовали ее в полную силу.
Во-вторых, непонятно, где ждать Null Reference Exception. Потому что вы не знаете, заполнил ли предыдущий разработчик модель достаточно хорошо, или где-то остановился и вам надо вчитываться в код, или покрывать тестами, или еще что-то делать.
Но даже если разработчики все хорошо заполнили, всё равно непонятно, сколько лишних аллокаций памяти мы сделали для того, чтобы этот объект у нас появился в приложении. И надо ли оно? Потому что иногда это сильно влияет на перформанс.
И самое плохое, что у такого объекта нет границ и нет контракта. Мы не можем написать для него какие-то инварианты, потому что он слишком размазанный. Делая новую фичу, вам придется добавлять новые поля, и в какой-то момент у вас может появиться толерантность к плохому проектированию.
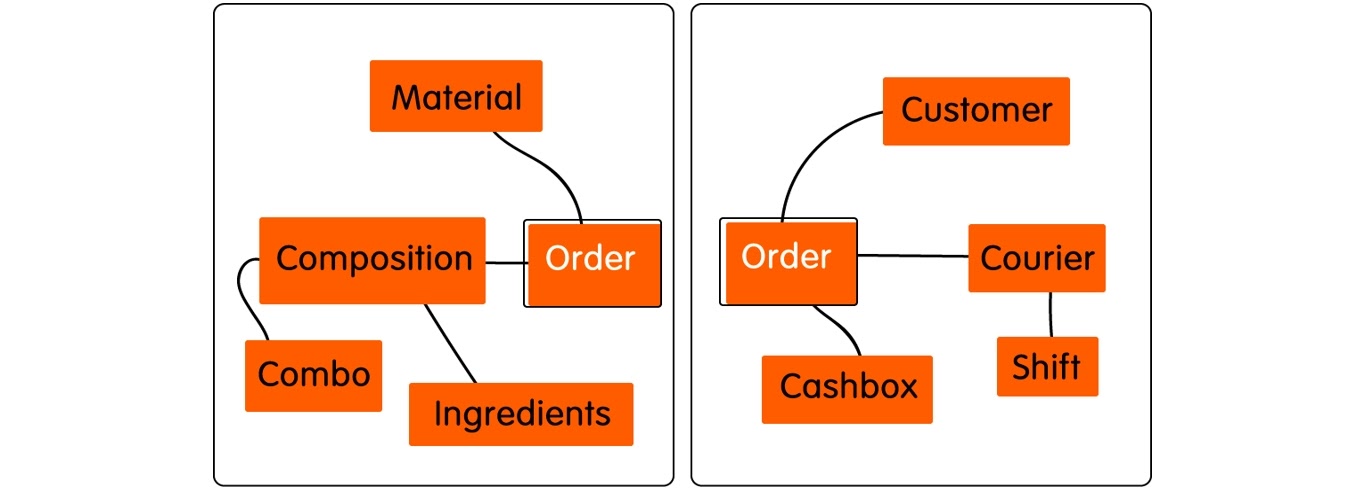
Например, мы начали автоматизировать заказ с кассы ресторана, чтобы вы могли заказать пиццу, а мы — учесть ваш заказ. Для кассы мы определяем какие-то поля. Потом мы переходим к доставке, и в сущность заказа снова добавляем поля. Адрес и время доставки с номером телефона не нужны ресторану, но у нас — общая модель заказа.
Дальше появляется учет, потом мы развиваемся и пилим новые фичи, в какой-то момент реализуем требования государства и т.д. Всё это опять добавляет нам новые поля. Наша модель становится монструозной, как лестница Эшера: в ней 30 полей, но непонятно, кому они нужны и как на это смотреть.
Решением будет разделить заказ на три части, так мы избавимся от мусорных полей. Конечно, у нас будут сквозные поля — ID, сумма, например. Но при этом поля, специфичные для одной области знания, не будут засорять другие.

Bounded Context. Стратегический дизайн

Как искать границы
Bounded Context — это ограниченная часть системы, в которой мы реализуем нашу бизнес-логику. Границы обычно ищутся эмпирически. Нет единого алгоритма нахождения идеальных границ. Более того, на разных этапах развития вашего приложения они могут плавать, и это нормально. Например, если Bounded Context в вашей CRM связан с продажами, то со временем его можно разделить на продажи и маркетинг.
Для определения границ объекта нам могут помочь данные — не сами по себе, а их источник. Если данные приходят из двух разных источников, то, скорее всего, здесь два Bounded Context, две модели. Также проанализируйте этапы бизнес-процесса. Как только мы повезли заказ куда-то, он сразу становится другой моделью. И тогда для курьера заказ будет иным, чем для пользователя на веб-сайте.
Если для разных частей нашей универсальной модели мы привлекаем совершенно разных доменных экспертов, скорее всего, граница будет там. Также посмотрите на оргструктуру организации — она тоже может показать, где искать ограничения. И последний параметр — действующие лица. Они могут подключаться на разных этапах, и исходя из этого, мы тоже можем очерчивать границы.
Например, когда мы говорим с бухгалтером, он понимает про заказ пиццы какие-то свои вещи, и не надо его грузить временем или адресом доставки. И, наоборот, когда мы говорим про заказ в контексте доставки, нам не важно, сколько грамм теста и сыра мы списали на заказ.
В результате ограниченный контекст показывает нам, что заказ должен быть разделен на две части. У нас получается две модели заказов:
И чтобы разработчики всегда могли договориться с бизнесом и экспертами о какой модели мы говорим, в Domain-Driven Design используется единый язык.
Единый язык (Ubiquitous Language)
Эрик Эванс начинает описание Domain-Driven Design в своей книге именно с него. Вся суть DDD — использовать единый язык и работать с экспертами в доменной области, чтобы максимально точно отразить бизнес-цели.
Единый язык включает в себя термины, понятия, и даже фразы для общения в команде. Основной инструмент — это Event storming. Основные строительные блоки, которые мы видим в Domain-Driven Design — это агрегат, команда и доменное событие.

Если кратко, то для физического Event storming нужны: большая стена (10 м), стикеры, маркеры, команда разработчиков и доменные эксперты, которые отвечают на вопросы. На выходе мы получаем модель с агрегатами, с командами, с Bounded Context и доменами. Ее размер будет зависеть от того, насколько большая система и сколько различных людей мы позвали, насколько глубоко нам надо ее проработать.
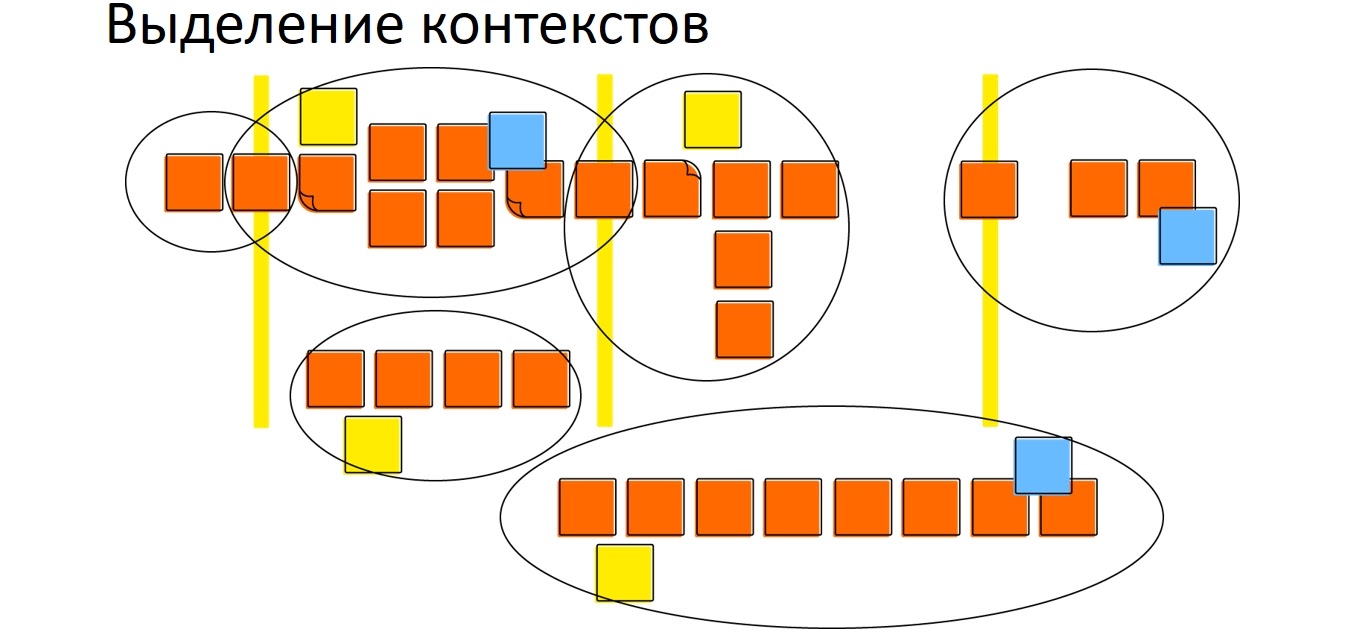
В Domain-Driven Design это называется стратегическим дизайном или стратегическими паттернами. Но сегодня я хотел бы быть чуть ближе к коду, и поговорить о тактическом дизайне.
Тактический дизайн Domain-Driven Design
Domain-Driven Design — не первый подход, который поднимает проблему анемичных и дырявых моделей. Анемичные модели говорят о том, что у объекта нет бизнес-логики, то есть это такая DTO, которая содержит только данные. И такой объект, разумеется, должен быть дырявым, чтобы какой-то внешний Application Services мог его менять.
Это достаточно стандартный подход, многие так делали. У нас тоже есть монолит, который мы начали писать много лет назад, и большая часть его логики реализована таким образом. Сервисы передают объекты друг другу, заполняя попутно какие-то поля или возвращая из себя новые объекты, но, тем не менее, эти объекты — дырявые.
К чему это приводит? Во-первых, очень сложно зафиксировать какие-то бизнес-правила. Различные Application Services и команды меняют объект, добавляя ему мусорных полей. Иногда эти мусорные поля неправильно понимаются другими людьми, и туда начинают попадать несоответствующие данные. Все это приводит к тому, что объект рано или поздно приходит в несогласованное состояние. Если бы мы как-то умели проверять инвариант объекта, мы бы часто видели, что объект не отвечает своему инварианту.
Это всё порождает связанность (coupling) и одновременно слабую кохезию (cohesion), то есть мы не понимаем без полного прочтения кода, что и как взаимосвязано в этой системе. Так как кодовая база у больших legacy-проектов со временем становится огромной, то в итоге вообще никто не понимает этих связей.
В противовес этому Domain-Driven Design предлагает использовать Rich Domain Model — богатую доменную модель, когда объект помимо данных содержит в себе и бизнес-логику. И добавить к этому агрегаты.
Агрегаты
Что такое агрегат? Чтобы ответить на этот вопрос, необходимо сначала сказать, что такое сущность. У Эванса есть два типа объектов, которые он описывает: Value Object и сущность.
Сущность имеет уникальный идентификатор. Если у вас есть два Ивановых Алексея, то они будут двумя разными людьми, даже если у них совпадают поля. Value Object — например, деньги — может содержать валюты и amount. И если эти два поля совпадают, вы считаете, что это одинаковые вещи.
Сущности и Value Objects в Domain-Driven Design принято объединять в агрегат. При этом агрегат доступен извне как API вашего объекта. Например, есть какой-то объект, и с ним связан наш заказ, у которого есть модель адреса. Идея в том, чтобы установить адрес можно было только через сам заказ.
Как определить размер агрегата
Есть соблазн запихать все в один большой агрегат, потому что он всегда будет консистентным. Это можно сделать, но в DDD есть негласное правило. Вон Вернон настаивает, что агрегат должен сохраняться транзакционно. Для планировщика, который работает внутри смартфона, это возможно. Доступ однопользовательский, мы считали состояние системы с какого-то хранилища, разложили по объектам и работаем с ним. При выходе также целиком сохранили. Но в веб мы так делать не можем, особенно когда доступ не одно-, а многопользовательский.
Представим, что мы написали свой Фейсбук, и там каждый пост — это агрегат, а лайк — часть этого агрегата. При каждом лайке нам пришлось бы перезаписывать нашу модель. Не говорим о нагрузке на железо. Проблема больше в том, что будет очень сложно соблюсти consistency нашего объекта. Если было поставлено 5 тысяч лайков, мы в итоге хотим увидеть на вьюшке именно столько. Если же мы начнем перезаписывать, получится concurrency-доступ, и мы можем неудачно затереть предыдущие изменения.
Поэтому агрегат важно сохранять в транзакциях, потому что он является хранителем целостности, инварианта объекта. Он отвечает за всю бизнес-логику и бизнес-правила, которые есть в системе. Если мы будем записывать наш список дел, например, не в один заход, а в несколько, при лаге сети мы часть объекта просто не запишем, и при вычитке получим неконсистентный объект.
Или, например, мы не хотим каждый раз читать список задач, пробегая по объектам и спискам. Мы их прикапываем, чтобы быстро выводить на вьюшки, но при сохранении планировщика с 10 тысячами задач мы реально сохраним, например, 9999. Такое можно видеть в соцсетях, когда у вас есть три поставленных лайка/notification, а заходишь в notification — и их там нет. Эта неконсистентность возникает, если сохранять объект не в транзакциях.
Но проблема в том, что транзакции — это очень дорого. И здесь мы можем использовать подход Outbox Pattern в рамках Eventual Consistency (конечной согласованности), чтобы сохранять не весь объект сразу, а только его часть, отправляя уведомление через нашу шину другим Bounded Context.
Подход Outbox Pattern
Посмотрим на примере scheduler´а. Например, TODO-листы в нем лежат отдельно, и есть два сервиса: один занимается выдачей расписания, другой — выдачей TODO-листов. Два сервиса — это не обязательно про микросервисную архитектуру. Это может быть даже внутри одного инстанса, но они должны быть не связаны ни по storage, ни по коду, или связаны минимально. Если мы свяжем их по базе, то рано или поздно кто-то что-то перетрет, и это приведет к их неконсистентности.
Поэтому существует Outbox Pattern. Его достаточно простая реализация заключается в том, что у scheduler, помимо своей БД, есть еще RabbitMQ. Типичная реализация — мы положили объект в свою базу, и кинули какое-то доменное событие в RabbitMQ. Рано или поздно сеть моргнет, своя БД станет недоступна на какое-то время, и мы получим несогласованное состояние.
Поэтому мы в одной транзакции пишем в БД не только состояние объекта, но и событие, доменный ивент, которое хотели кинуть в RabbitMQ. Потом мы обращаемся к RabbitMQ. Если он не доступен, то есть еще дополнительный publisher, промежуточный слой, который смотрит, что неотправленного есть в БД, и отправляет.
Естественно, здесь периодически будет происходить дупликация событий, то есть мы не всегда однозначно знаем, отправили мы в RabbitMQ или не отправили. Иногда еще будет происходить reordering, то есть мы будем не в том порядке писать.
Есть несколько подходов, которые позволяют с этим бороться. RabbitMQ частично умеет делать редупликацию и reordering. Но наш подход — это при использовании RabbitMQ позволить событиям приходить в разном порядке, в двойном избыточном размере и сделать так, чтобы для нас каждое событие было идемпотентным и коммутативным. Мы не смотрим на порядок и количество, а работаем, как есть. Это возможно достичь различными путями — использованием, например, correlation key.
CQRS
Заметим, что чтение и запись данных могут сильно отличаться в различных приложениях. Например, в социальных сетях люди больше читают, чем пишут. И БД обычно оптимизированы под что-то одно. Либо мы позволяем людям быстро писать, но тогда нам сложно вычитывать это все и отдавать людям. Либо мы оптимизированы под быстрое чтение, но долго записываем. Это такой trade-off в современных storage. Какие-то storage решают эту задачу успешнее, какие-то менее успешно.
В результате модель разделили на две: Write и Read. Так появился CQRS.
Это механизм, который позволяет нам подружить обе модели, и Write, и Read. Например, когда из приложения команды на запись попадают в одно приложение, а читаем мы из другого. С помощью CQRS мы разделяем команды на запись и запросы на чтение. И в этом случае мы можем эти две модели оптимизировать по очереди. Если у нас очень много чтения, то мы можем масштабировать модель Read — например, поставить рядом несколько серверов. Так с помощью бизнес-логики можно обновить Read-модель и оптимизировать производительность наших приложений.
Event Sourcing
Здесь идея тоже простая. Мы храним не объект и не state нашего объекта целиком, а отдельные события, которые этот state меняют. Очень явно можно увидеть этот подход в бухгалтерском учете. Там мы никогда не меняем состояние. Мы работаем в режиме append-only и получаем от этого кучу бенефитов. Во-первых, мы видим не только конечный state, но и как мы к этому state пришли. Если у нас есть какой-то аккаунт, мы хотим видеть не просто, что на нем лежит 100 рублей, а каким образом эти деньги накопились.
Event Sourcing предлагает хранить все эти маленькие изменения, как отдельный шаг. Дальше происходит достаточно простая вещь: когда нам надо объект отобразить, мы вычитываем все события, которые с ним произошли.
Как мы конструируем потом объект? На запрос какого счета обычном подходе мы просто вычитываем его баланс и отдаем наружу. В подходе Event Sourcing мы вычитываем не баланс, а эвенты. То есть мы подаем какие-то эвенты на вход и реализуем код, который эти эвенты перепроигрывает на голом объекте.
Таким образом мы меняем баланс, но этот баланс только внутренняя переменная в памяти. Мы нигде никогда не храним баланс как число, а просто каждый раз его рассчитываем. Да, по перформансу это не очень эффективно, но позволяет, во-первых, легко реагировать на ошибки. Мы видим всю историю, можем в любой момент понять, что пошло не так. На самом деле это очень классно, особенно когда начинаешь траблшутить, ты знаешь, как и что происходило. У тебя не просто какие-то логи, а прямо конструкция твоего кода.
А во-вторых, мы получаем от Event Sourcing легкое исправление ошибок. Я с таким сталкивался. Например, кто-то ошибся и написал в коде минус вместо плюса. В обычном подходе, где мы пишем state и баланс в базу, мы бы устали вычищать эту ошибку. Нам бы пришлось поднимать первичные документы, высчитывать руками данные каждого человека, и потом только отображать.
Если у нас Event Sourcing, мы можем легко исправить эту ошибку – достаточно поправить код и развернуть приложение заново. Потому что события у нас правильные, но мы их обрабатывали неправильно. Так как код мы исправили, то и отображаемое состояние объекта тоже становится правильным. Это очень крутой бенефит.
Очевидно, что у Event Sourcing есть один большой недостаток — это перформанс. Если банковская система с миллиардом транзакций каждый раз будет вычитывать эвенты, пусть даже партиционированно, шардировано по клиенту, это будет всё равно дорого. А если мы делаем High Performance Trading, где миллиарды транзакций могут происходить в течение очень короткого промежутка времени, то таких событий по каждому клиенту будет огромное количество.
Строить такие объекты тяжело, и в DDD прижилась идея склеить Event Sourcing и CQRS.
CQRS и Event Sourcing
Вернемся к моделям чтения и записи. Write-модель — это те события, которые падают из приложения. Баланс пополнили, осуществился перевод, сняли деньги, клиент получил штраф, оплатил комиссию, еще что-то. Это всё сыпется непрерывным потоком в какое-то append-only хранилище. Зачастую это даже не реляционная база данных, а что-то оптимизированное под запись, например, Kafka. Она позволяет писать большое количество событий и очень хорошо с этим справляется.
Дальше есть некоторый код, который перекладывает наши ивенты через свою бизнес-логику уже в Read-модель. Так мы получаем быстрые и запись, чтение. Единственный недостаток — в Event Sourcing и CQRS почти никогда не работает read-your-own-writes, то есть чтение своей записи. Лаг между записью и чтением самого себя может быть очень большим, потому что между этими моделями eventual consistency, то есть код, который перекладывает запись в чтение.
Пример
У нас работает код консьюмера, который подписан на какое-то брокер-сообщение — на топик Kafka или на очередь в RabbitMQ. Оттуда ему прилетают уведомления о новых событиях. Предположим, прилетело событие перемещение. Это не совсем событие, но логика такая же.
Что мы делаем? Из Read модели вычитываем агрегат, то есть у нас есть код, который работает через репозиторий и получает наш агрегат. Предположим, что речь идет о заказе. Мы добавляем в модель два поля: версию и IsDirty — потрогали ли мы объект.
Дальше мержим событие с нашим агрегатом. Попутно мы формируем еще одно событие для паттерна Outbox Pattern. Оно сохранится, чтобы и другие модели Bounded Context тоже могли поменяться. После этого мы сохраняем агрегат и событие.
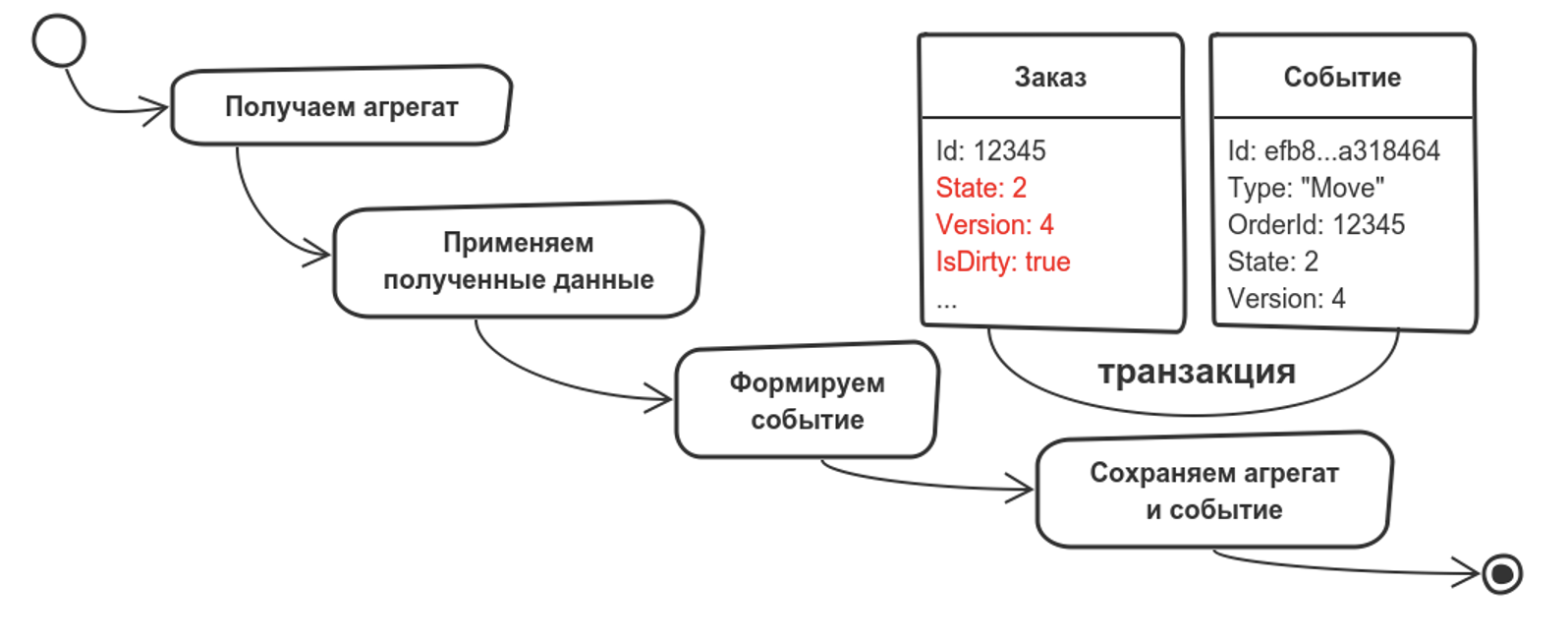
Что может пойти не так? У событий может быть тоже версионность. Но эта версионность позволит нам решать, обрабатывать это событие или просто его выкидывать.
Из Read модели вычитываем агрегат, мержим его с новым событием по какой-то бизнес-логике, откидываем старое, делая дедупликацию и соблюдая идемпотентность, а потом сохраняем агрегат обратно.

Помните о concurrency. В нагруженных системах хендлер точно будет не один. Если вы про это не подумаете, то всё просто разъедется. Например, вы затрете последним апдейтом предыдущие изменения.
Поэтому мы либо явно лочим нашу запись, используя pessimistic concurrency, либо используем optimistic concurrency, и тогда перед сохранением проверяем версию объекта. То есть мы сохраняем в базу и говорим, что апдейтим только объект с версией 4. Если вдруг в базе лежит уже 5 или 6 версия, мы падаем с exception optimistic concurrency (это мы так в коде реализовали), и цикл повторяется заново.
В новом цикле мы вычитываем агрегат заново, уже с версией 6, и опять мержим событие. Причем если первый раз оно нормально замержилось, то во второй раз всё может пойти по-другому, потому что состояние поменялось, и может быть, его уже нельзя мержить. В зависимости от бизнес-логики, мы можем его пропустить или сделать что-то еще. И сохраняем опять, проверяя, а шестую ли версию мы обновляем? Если да, ОК, сохранили. Если нет (у нас все быстро меняется), то повторяем.
Рано или поздно мы успеваем между изменениями сохранить. У нас не такой перформанс, как в Badoo, например, где миллион событий может в один объект прилетать. У нас в системе мало людей меняют множество объектов, а точнее, каждый конкретный объект меняют 1-2 человека. Соответственно, у нас такие проблемы редки, но мы о них помним.
Цели
Чем нам вообще поможет подход Bounded Context? Во-первых, он снижает когнитивную нагрузку от разных доменов. Особенно если у вас система достаточно большая. Например, у нас Dodo IS сейчас отвечает за 30-50 разных сервисов. Я не знаю их все, к тому же постоянно появляются новые. Но используя Bounded Context, я снижаю пятно контакта, и за счет этого более сфокусировано работаю.
Второй профит. Когда у вас понятный агрегат с ясными инвариантами, вы можете обсудить с бизнесом или экспертами конкретную часть из своего фокуса. Так вы создадите меньше ошибок в бизнес-логике.
И наконец, Domain-Driven Design и всего его тактические паттерны позволяют сделать рост стоимости не уходящим в потолок при создании новой фичи, а растущим постепенно. От роста стоимости вы совсем не избавитесь, потому что у вас появляются консьюмеры, связанность по коду и бизнес-логике. Но можно добиться хотя бы не экспоненциального роста.
Профессиональная конференция для Python-разработчиков пройдет 27 и 28 сентября в Москве. Расписание уже готово, выбрать самые интересные доклады можно уже сегодня.
Билеты можно купить здесь. До встречи в офлайн-сентябре!

{kind=link}