
Микросервисы сейчас — это новый черный. Все больше и больше компаний переходят именно на микросервисную архитектуру. И при переходе ловят самые разные ошибки. Самая популярная происходит из-за того, что люди просто не готовы к тому, что их приложения начинают активно использовать сеть. Потому что IPC и RPC-запросы — это абсолютно разные вещи.
Я техлид в команде Авито в проекте SLA. Сегодня расскажу, как мы оптимизировали сетевые вызовы, чтобы избежать проблем с сетью при переходе в микросервисный мир. Разговор будет про оптимизацию CURL-запросов, деградацию сервисов и FAIL-FAST-подходы.

Разработчики любят оптимизировать и зарубаться за лишние 100 мс, чтобы памяти поменьше использовалось. Но от продакта можно услышать: «Зачем тратить деньги на сетевую оптимизацию? Зачем в принципе оптимизировать код, если сейчас мы живем нормально? Давайте фичи пилить!» Эти два человека не всегда могут договориться, и тогда они приходят к аналитику, который предложит просто посчитать.
Примерно такой диалог произошел у нас в Авито, и мы провели большой А/В тест. В течение нескольких месяцев мы искусственно замедляли загрузку страниц на разное время (1с, 2с, 3с, 5с, 10с) и смотрели, как от скорости нашего ответа меняются продуктовые метрики. В ряде случаев мы даже специально оптимизировали код, чтобы посмотреть, как уменьшение времени ответа влияет на метрики.
В итоге мы получили, во-первых, 20%-ый рост количества отказов, когда пользователь просто не дождался загрузки и ушел со страницы. Вторым результатом стала 5-20%-ая потеря целевых действий. Это достаточно субъективная, подходящая именно под Авито метрика — когда мы ждем, что пользователь перешел по объявлению в поиске. В тесте пользователи стали реже переходить по объявлениям, просматривать телефонные номера и писать в мессенджере.
И в третьих, мы увидели, что ускорение загрузки на 1с увеличило поток целевых действий на 4%. В масштабах Авито это огромные деньги и большой прирост всех продуктовых показателей. Выводы из теста получились вполне ожидаемыми:
Зависимость продуктовых метрик от скорости ответа — нелинейная. То есть, увеличив скорость в 2 раза, мы не получим в 2 раза больше денег — но зависимость есть.
Чем быстрее мы отвечаем, тем меньше шанс отказа, что пользователь просто не дождется ответа и уйдет.
Чем быстрее мы отвечаем, тем лучше ключевые продуктовые метрики страницы и тем больше целевых действий совершают пользователи на странице.
Выводы дали нам вполне работающую модель, которая позволила понять, что оптимизация скорости действительно оправдана и важна. В определенных пределах, и, чтобы понимать, где имеет смысл оптимизировать скорость, а где это не сработает, мы начали смотреть, что можно сделать для ускорения.
Реализуем асинхронность в PHP-приложении
Возьмем максимальной искусственный пример, чтобы проиллюстрировать проблему перехода в микросервисный мир микросервисного приложения. Любые компании, которые идут туда, скорее всего, придут к такой ситуации:
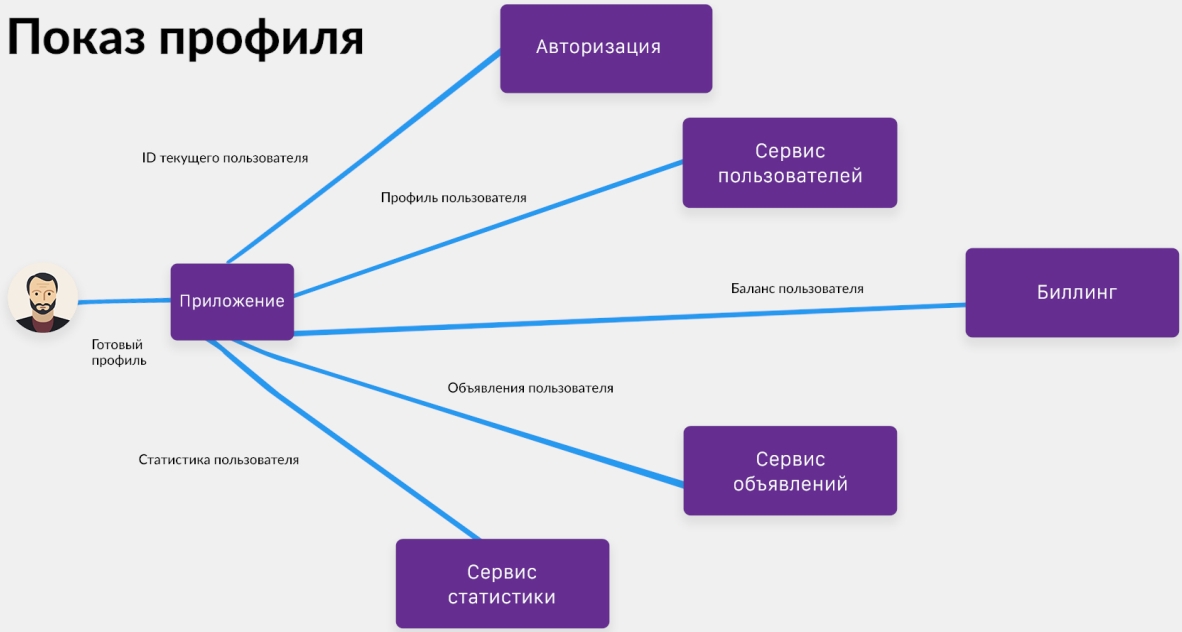
Страница профиля в первой итерации запрашивает пять сервисов:
Сервис авторизации (мы его к тому моменту уже сделали), чтобы получить ID пользователя.
Сервис пользователей, чтобы получить данные о данном конкретном пользователе.
Сервис биллинга, чтобы человек мог получить ответ на вопрос: «Какое у меня состояние баланса, сколько у меня денег?»
Сервис объявлений, чтобы увидеть все свои объявления.
Сервис статистики, чтобы посмотреть, например, сколько денег было заработано или потрачено за последний месяц?»
Но какой SLA будет у такой системы из 5 сервисов?

Что здесь можно запараллелить? Например, некоторые сервисы запрашивают только ID, и в нашем случае это четыре сервиса (выделены розовым):
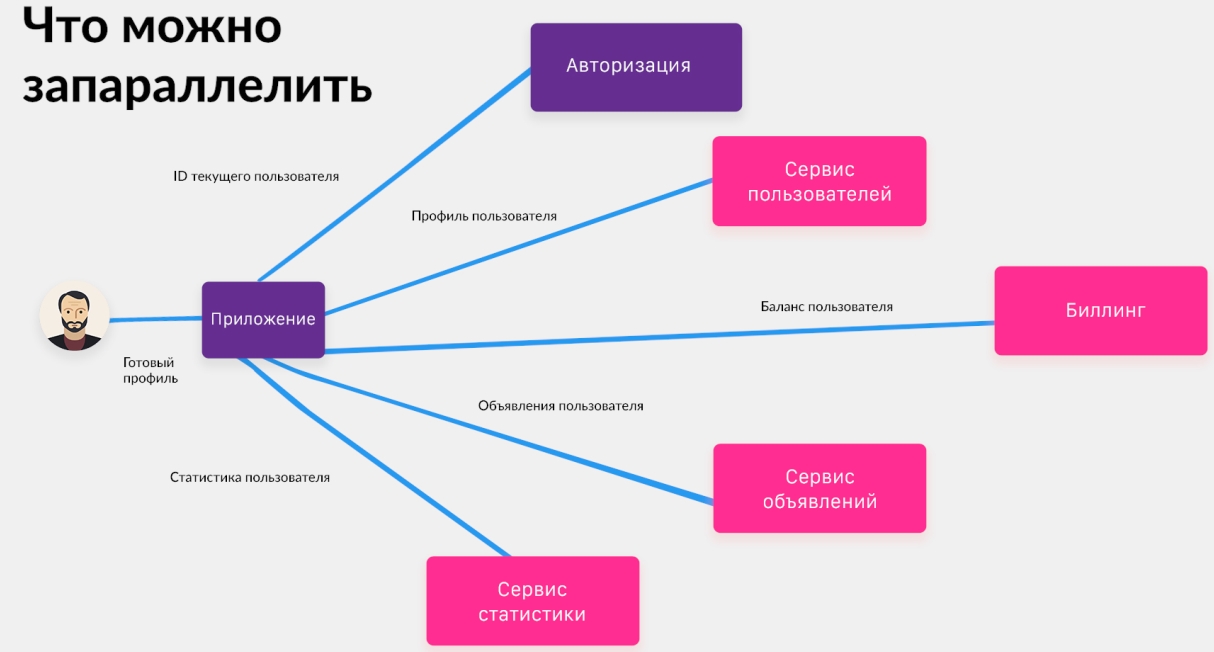
Если их поставить в параллель, то можно хорошо сэкономить. Но PHP не умеет работать в многопоточности (ждем PHP 8.1). Но пока мы нашли решение для таких задач.
Curl_multi_exec и Guzzle
Если посмотреть код curl_multi_exec, то там всё достаточно просто. Он позволяет за один раз получить ответы от нескольких сервисов. То есть запросы выполняются параллельно и с зачетом по последнему, что и решает нашу задачу:

Но при использовании curl_multi_exec мы поняли, что такой код плохо читается, с ним неудобно работать. Тогда мы обернули curl и curl_multi_exec с помощью Guzzle, и тот же самый вызов из предыдущего примера стал выглядеть так:

Guzzle-код гораздо более понятный, компактный, лучше читается. Здесь ровно то же самое — есть два запроса, и мы резолвим результаты. Стоит обратить внимание, что в реальности все запросы будут выполнены в момент вызова promise1, а в promise2 будут данные, что мы уже получили во время выполнения promise1.
Guzzle дал нам так называемую «параллельность» и так называемую «асинхроничность». Но в больших проектах внедрять подобный подход будет очень дорого.
Когда асинхронность не работает
Когда у вас большой проект с dependency injection, то существует ненулевая вероятность, что вы можете создать разные guzzle-клиенты. И тогда можно забыть о параллельности — она не будет работать, так как вы схлопнете запросы в рамках только одного guzzle-клиента. В этом случае может иметь смысл оставить guzzle-клиент как singleton в вашем приложении (на уровне DI конечно-же, не кидайтесь тапками) в вашем приложении.
Другая история, когда guzzle вам с синхронностью не поможет, стара как мир. Например, пользователь ищет сиамских котов, в результате чего сервис поиска получает по ним запрос и список из 10 ID-объявлений. Чтобы получить данные по этим объявлениям, вы схлопнете одиночные запросы к сервису объявлений под один guzzle запрос, и для PHP это будет выглядеть как один сетевой запрос. Но ваш сервис получит сразу 10(!!!!) сетевых запросов в один момент времени!

Чтобы это решить, мы стараемся использовать только batch-запросы и строим концепцию API наших сервисов именно под эти запросы. У нас нет возможности получить одно объявление — только пачкой. Вы не можете получить один профиль пользователя — только batch-запрос (пусть и с 1-м ID).
Когда вы вводите концепцию batch-запросов, это стимулирует разработчика реализовывать их и заранее в процессе написания кода продумать проброс айдишников. Пробрасывает, получает batch запроса — и всё прекрасно работает.
Выводы
Даже однопоточный РНР можно научить работать с параллельными запросами и получать данные параллельно. Для этого мы используем curl_multi_exec или его «обёртку» в виде guzzle;
Лучше один batch-запрос, чем 10 через guzzle. Это поможет разработчикам оптимизировать код заранее.
Оптимизация curl
Curl — это, наверное, основной способ работы сети для PHP-приложений. И мы решили понять, можем ли мы его оптимизировать.
Разберём фазы работы curl:

Из этих четырех фаз три — служебные. И только Transfer несет реальную пользу, передавая payload в запросах и ответах. Пройдем по первым трем фазам и посмотрим, можно ли каждую из них как-либо оптимизировать.
Namelookup
На этой фазе нам нужно получить из path\host IP адрес. Как правило, это обычный DNS запрос. Как можно избавится от него? Мы перебрали несколько вариантов:
Вместо host можно использовать IP-сервиса, по которым мы ходим, но получится не очень удачный вариант, особенно если у вас Kubernetes с динамическими IP-адресами.
Можно использовать алиас из /etc/hosts, а в /etc/hosts, например, оркестратором доставлять апдейты. Вариант тоже так себе.
Но если использовать алиас из локальной reverse-proxy, то локальная reverse-proxy все за нас резолвит. Бинго! Так мы и сделали.
Connect
На этой фазе мы устанавливаем tcp/ip соединение с сервисом. Чтобы сэкономить время\ресурсы и не подключаться каждый раз, мы просто поддерживаем постоянное tcp/ip-соединение на reverse-proxy.
Pretransfer
На этой фазе мы уже устанавливаем HTTP соединение (уровня L7 модели OSI). Обмениваемся сертификатами, делаем SSL-handshake. Если использовать reverse-proxy + http 1.1, то мы получим замечательный keep-alive. То есть наше соединение не будет закрываться в тот момент, когда мы завершили запрос.
А если использовать http вместо https то избежим толстых и дорогих handshake (безопасно делать только если вы явно разграничиваете приватный и публичный контуры).
Reverse-proxy
Выше мы несколько раз явно упоминали про reverse-proxy и то, как мы оптимизируемся через него. Расскажу подробнее про использование Reverse-proxy. Это некоторый промежуточный слой балансеров или сервисов, который проксирует запрос от пользователя к вам.

Ваши балансеры трафика (например, по регионам) — это тоже в своем роде reverse-proxy. Таких слоев можно вставлять сколько угодно, в зависимости от того, какие задачи вы решаете.
Иногда reverse-proxy может быть локальным и стоять рядом с каждым инстансом вашего PHP-приложения. Пользователь шлет запрос к нему, а reverse-proxy процессит запрос в ваше PHP-приложение.
Я покажу примеры reverse-proxy в виде nginx, хотя примеров его использования достаточно много (например, traefik или envoy). Nginx хорошо тем, что отлично себя показывает в связке с PHP, уже подключён как фронт у большинства приложений, надёжен, как швейцарские часы, имеет хорошую производительность и скриптуется через LUA.
Мы хотим. Чтобы из nginx, который лежит локально рядом с нашим PHP-приложением, сделать reverse-proxy, прописывам в /etc/hosts алиас:

Далее — index.php. Это то, как будет выглядеть proxy. Обратите внимание на строку с url нашего сервиса:

Мы поменяли адрес на алиас из hosts, добавили префикс к URL, и в результате DNS для резолва уже не используется:

service-proxy: алиас, который прописан в /etc/hosts как 127.0.0.1.:8888: порт, который был выбран специально — он 100% не смотрит в интернет и открыт только для local-хоста./service-user: имя сервиса. У нас ведь их больше одного, а мы строим универсальную конфигурацию./get-user: непосредственно имя метода в сервисе, что мы вызываем.
В самом nginx мы описываем локации для каждого сервиса, у нас это service-user- После чего выполняем rewrite, где вырезаем service-user и оставляем только имя метода:

Дальше процессим его в виртуальную локацию (service-user):

Обратите внимание на элементы конфигурации, они важны для концепции reverse-proxy:
Заголовок сервиса, в который мы идём, то есть конкретный хост. Если раньше мы ходили в сервис service-user.your-domain.com, то и здесь мы его проставляем.
proxy_pass (об этом чуть позже).
timeout на подключение, пересылку, приём и отправку.
keep-alive, о котором мы говорили выше. Он позволяет не устанавливать соединение каждый раз.
И вишенка на торте — X-Forwarded-Host. Это не самый стандартный, но очень полезный заголовок, чтобы на принимающем сервисе (service-user) мы могли идентифицировать того, кто запрос отправил.
Вернемся к reverse-proxy. Следующим шагом будет upstream, в котором есть keepalive и keepalive_request — то есть определяем, сколько мы поддерживаем keepalive и запросов:

Обратите внимание на две секции server: service-user1 и service-user2. Я их добавил специально, чтобы показать, как можно обойтись без балансеров в двух инстансах вашего сервиса Но если у вас есть свои балансеры, то вам это не нужно — будет просто одна секция.
Также здесь указываем два очень важных параметра для настройки reverse-proxy:
max_fails=5 — он показывает, через сколько запросов этот сервер будет помечен как недоступный (сеть все-таки не даёт надёжной гарантии доступности).
fail_timeout=1s — на сколько секунд (в данном случае, на одну) мы помечаем этот сервис битым.
Выводы
Reverse-proxy, в итоге, нам помог:
Сэкономить на трёх из четырёх этапов curl. Про четвертый я не говорю, потому что предполагается, что фаза Transfer, когда вы отправляете payload — это ваш внешний публичный контракт, и их мы не пытаемся оптимизировать таким образом.
Добавить надёжность, внедрив keep-alive. (Так как мы не переустанавливали каждый раз tcp/ip соединение, мы не тратили время на его установление)
Более эффективно использовать сеть, потому что мы отказались для внутренних запросов от https в пользу http.
Не тратить лишнее время процессоров на handshake.
Graceful degradation
Это был наш следующий этап оптимизации, который точно стоит пройти. Концепция Graceful degradation позволяет заранее подумать, что делать, если наш сервис, который мы только что оптимизировали с reverse-proxy — не ответил. И ответ этот не очень простой: надо хорошо подумать, как жить дальше без этих данных.
Покажу на примере объявления с Авито о продаже реактивного двигателя от МИГа. Красными блоками я подсветил не ответившие сервисы: здесь нет данных от сервиса пользователей и сервиса статистики:

То есть даже без этих данных объявление приемлемо для нас как для пользователя: в нём есть номер телефона, по которому можно позвонить или написать, а также есть фотографии. В первом случае больше данных, но во втором мы не упали — и это важно. Вот что такое Graceful degradation.
Выводы
Каким бы классным не был Graceful Degradation, он тем не менее — очень сложная штука, и его реально долго и дорого внедрять. Каждый раз вам придется договариваться с бизнесом. Потому что когда вы предлагаете продакту статистики: «Дружище, ты отвечаешь за статистику, а давай я ее иногда не буду показывать?» — то он вам ответит, что для него статистика — основной продукт, и он категорически против ее не показывать.
Graceful degradation увеличивает сложность и так непростой бизнес-логики в PHP-контроллерах. В каждом случае вам потребуется делать разные ветвления, если вы не можете получить данные статистики или пользователя — и в каждом месте кода для каждой странички это делается по-разному.
И вдобавок эта концепция требует проработки для каждого бизнес-сценария отдельно. Потому что один и тот же сервис — например, service-user — абсолютно по-разному деградирует на разных страницах:

На поисковой выдаче, если вдруг мы не знаем Васю или Петю, мы можем показать пустой блок, и последствий будет минимум. На странице объявлений не получить данные по Service-user будет достаточно важным, и мы покажем бабл «Попробовать еще раз». А страницу пользователя мы вообще не сможем отобразить, если не знаем ничего о пользователе. Поэтому Graceful degradation сложно реализуется в коде.
Retry
Следующим нашим шагом в оптимизации приложений был retry — это попытки выполнить запрос ещё раз. Retry позволяет побороть кратковременные проблемы с сетью и поднимает надёжность работы бизнес-сценариев.
Однако у него есть и минусы:
Retry увеличивает время ответа. Например, если у вас деградирует сервис graceful и вы сделали retry, то ваши ответы будут приходить чуть дольше.
Retry позволяет вам совершить DDOS-атаку на собственное приложение.
Retry не работает для не идемпотентных запросов.
Стратегии retry
Retry можно использовать по-разному. Есть много стратегий его использования — мгновенная, фиксированная, инкрементальная и экспоненциальная итд. Остановимся более подробно на некоторых из них.
Мгновенный retry
Когда мы делаем мгновенный retry, то повторный запрос происходит сразу. Это удобно, если, например, мы совершили ошибку — её тут же можно заретраить. Такой приём позволяет нивелировать кратковременные проблемы с сетью.
Мгновенный retry подходит для интерактивных, интерфейсных задач. Например, когда нужно отобразить элемент интерфейса в рамках пользовательского запроса. Но лучше не делать retry более двух раз. Хотя это не железное правило, но в Авито мы его ввели.
Фиксированный retry
Он так называется, потому что между попытками отправки приходится ждать фиксированное время. Такой retry лучше сглаживает проблемы с сетью или сервисом, чем мгновенный. Он тоже подходит для интерактивных, интерфейсных задач — тут всё зависит от выбора фиксированной дельты.
Инкрементальный retry
Эта стратегия увеличивает задержку между попытками (1с, 2с, 3с и т.д.) и больше подходит для фоновых задач. Однако инкрементальный retry может дать больше попыток на retry, чем фиксированный.
Экспоненциальный retry
Для него характерен экспоненциальный рост задержки перед следующим повтором вплоть до больших цифр, но нужно сразу ограничить максимальное время ожидания. Экспоненциальный retry идеален для фоновых процессов и в случае падения сервиса.
Мы в Авито делаем retry на reverse-proxy примерно так:

Описание виртуальной локации (или service-user) содержит две строчки, в которых указано, в каких случаях мы делаем retry (error и timeout) и максимальное количество попыток retry.
В nginx retry есть много разных условий, его всегда можно настроить под разные типы запросов для вашего сервиса.
Но базово не ретраятся неидемпотентные запросы: POST, LOCK, PATCH. Будьте внимательны и не забудьте также про условие non_idemponent, если у вас RPC внутри.
И помните, что для любых типов retry мы ограничиваем максимальное количество попыток и максимальное время выполнение запроса.
Мы ретраим на слое reverse-proxy, а не в коде, потому что мы используем guzzle\curl_multi_exec. То есть пока вся пачка запросов не отработает целиком, ретраить нам будет дорого и невкусно.
Как retry всё сломал
Retry может быть опасен. Покажу на реальном нашем кейсе, как он может сломать всё.
Сначала разработчики мобильного приложения решили, что экран биллинга для них — очень важный экран. В процессе тестирования они словили его флакующее поведение, и решили, что его следует отретраить, потому что продакты и тестировщики на регрессе экран не пропускали. Они добавили retry, и все тесты прошли прекрасно.
Одновременно с ними наши DevOps-инженеры проверяли одну из своих гипотез и для идемпотентных запросов внутри сети добавили дополнительный retry.
И в этот же время мы пытались ретраить запрос, в котором через guzzle делался обход 10 сервисов.
Казалось бы, что могло пойти не так? Но нагрузка выросла в 4 раза! Потому что слегка выросло время ответа одного сервиса, а в пачке их было 10. Сервис временами перестал укладываться в timeout и стал валить пользовательский экран. Упавший запрос ретраился нашей инфраструктурой и клиентом, а guzzle на всякий случай ретраил все 10 запросов:

Сайд-эффекты микросервисов
Это другая история, которая у нас произошла с retry, и 100% это может случиться с любым микросервисным PHP-приложением.
Предположим, у вас есть приложение в 50 FPM-воркеров, вы в среднем отвечаете за 100 мс на 99 перцентиле и вытягиваете 500 RPS без деградаций и задержек. Это пиковая нагрузка, но и реально у вас 250 RPS . То есть вы имеете 2кратный запас производительности и ресурсов.
Чтобы быть надежней и пореже падать, вы делаете до 3 retry страницы профиля (service-user).
Но в какой-то момент времени приложение внезапно ведет себя иначе:

Теперь, несмотря на то, что у вас раньше был двукратный запас по производительности, всего из-за одного сервиса вы деградировали, и приложение перестало справляться. Пользовательские запросы висят в очереди на обработку, новые запросы не обрабатываются, а время ответа растет, как и увеличивается error-rate:

Выводы
Не используйте автоматический retry на клиенте. Но если решите использовать, то — только под конкретные случаи, анонсируя на всю компанию и ведя учет всем таким сценариям.
Вместо retry отдавайте предпочтение graceful-degradation — после внедрения у вас будет гораздо меньше артефактов.
Используйте retry только для данных, которые очень критичны для вашего бизнес-сценария, без которых совесм нельзя. И, конечно, вам будет нужно договориться об этом с вашими продактами.
Fail Fast
Следующей стратегией оптимизации сетевого обмена у нас стала Fail Fast стратегия. Её обычно применяют в приложениях при оптимизации сети, у нее много разновидностей, и я расскажу о трех для примера.
Во-первых, для всех своих микросервисов мы обязательно указываем connect_timeout, чтобы понимать, как долго ждать ответа от сервера. Наша практика показала, что нет смысла ставить connect_timeout равным 100 мс, если вы не смогли установить соединение за 20 мс (возможно, у вас будут другие цифры) — если не получилось за 20 мс, то оно не установится никогда. Для нас число 20 подошло великолепно, в нее укладываются 99,99% запросов.
При этом проверьте, сколько точно времени уходит на ответы сервисов, и пропишите реальные таймауты. При переходе в микросервисы мы столкнулись с тем, что у всех микросервисов timeout стоял 1с, несмотря на то, что кто-то отвечал за 30 мс, а кто-то — за 900 мс.
Третья история — circuit breaker или аварийный выключатель. Он нужен, чтобы «больные» сервисы как можно быстрее падали. Реализовать его можно на nginx, как и reverse-proxy. Но есть и решения в PHP-коде, и на базе других reverse-proxy (например, envoy).
Circuit breaker детектит «здоровье» сервиса, и даже не пытается отправлять запрос, если сервис «заболел». Если бы в наших история с retry использовали circuit breaker, то получили бы «отлуп» от service-user за всего 1 мс. Схема работы circuit breaker очень простая:

Если мы на первый запрос получаем ответ с некоторым опозданием, то следующий запрос падает в timeout. Если приходит еще ответ с ошибками, то срабатывает circuit breaker, который мгновенно сообщает, что service-user недоступен.
Заключение
Подводим итоги. С чем вы можете уйти сегодня:
Используйте curl_multi_exec и guzzle.
Reverse-proxy (nginx, envoy) прекрасно справляется с тем, что базовый PHP делает не очень хорошо. Он держит соединение между PHP-приложением и сервисами, ретраит запросы и делает за вас keep-alive.
Прорабатывайте сценарии graceful degradation.
Используйте retry только по необходимости и, по возможности — не на клиенте.
При работе с микросервисамми придерживайтесь fail-fast-стратегий.
На самом деле микросервисы гораздо сложнее, чем кажется на первый взгляд. Видео моего выступления по этой теме на конференции PHP Russia 2021:
Открыт прием докладов на конференцию PHPRussia 2022. Она пройдет 12 и 13 сентября 2022 года в Москве.
9 декабря в 14:00 будет онлайн-встреча с Программным комитетом- Вы сможете задать вопросы членам ПК, например: какую тему лучше выбрать для доклада, как упаковать в питч ваши достижения, понравится ли тема аудитории и что можно улучшить. Регистрация.
