Всем привет! Наступила весна, а это значит, что до запуска курса «Разработчик Python» остается меньше месяца. Именно этому курсу и будет посвящена наша сегодняшняя публикация.

Задачи:
— Узнать о внутреннем устройстве Python;
— Понять принципы построения абстрактного синтаксического дерева (AST);
— Писать более эффективный код по времени и по памяти.
Предварительные рекомендации:
— Базовое понимания работы интерпретатора (AST, токены и т.д.).
— Знание Python.
— Базовое знание С.
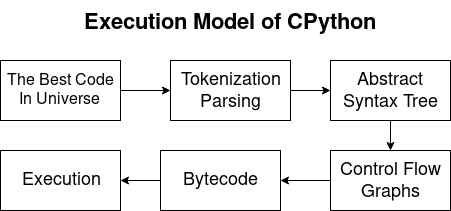
Модель выполнения CPython
Python компилируемый и интерпретируемый язык. Таким образом компилятор Python генерирует байткоды, а интерпретатор исполняет их. В ходе статьи мы рассмотрим следующие вопросы:
Парсинг и токенизация.
Грамматика.
Грамматика определяет семантику языка Python. Она также полезна в указании способа, котором парсер должен интерпретировать язык. Грамматика Python использует синтаксис подобный расширенной форме Бэкуса-Наура. Он имеет свою собственную грамматику для переводчика с исходного языка. Вы можете найти файл грамматики в директории “cpython/Grammar/Grammar”.
Далее приведен пример грамматики,
Простые выражения содержат маленькие выражения и скобки, а заканчивается команда новой строкой. Маленькие выражения выглядят как список выражений, которые импортируют…
Какие-то другие выражения:)
Токенизация (Лексический разбор)
Токенизация – это процесс получения текстового потока данных и разбиения на токены значащих (для интерпретатора) слов с дополнительными метаданными (например, где токен начинается и кончается, и каково строковое значение этого токена).
Токены
Токен – это заголовочный файл, содержащий определения всех токенов. Всего в Python 59 типов токенов (Include/token.h).
Ниже приведен пример некоторых из них,
Их вы видите, если разбиваете на токены какой-то код на Python.
Токенизация с помощью CLI
Здесь представлен файл tests.py
Дальше его мы токенезируем с помощью команды python -m tokenize и на выходе получаем следующее:
Здесь номера (например 1,4-1,13) показывают, где токен начался и где он закончился. Токен кодирования (encoding token) – это всегда самый первый токен, который мы получаем. Он дает информацию о кодировке исходного файла и если с ней есть какие-то проблемы, то интерпретатор вызывает exception.
Токенизация с помощью tokenize.tokenize
Если нужно разбить на токены файл из вашего кода, вы можете использовать модуль tokenize из stdlib.
Тип токена — это его id в заголовочном файле token.h. String– это значение токена. Start и End показывают, где токен начинается и заканчивается соответственно.
В других языках блоки обозначаются скобками или операторами begin/end, но в Python используются отступы и разные уровни. INDENT и DEDENT токены и указывают на отступы. Эти токены нужны для построения реляционных деревьев синтаксического анализа и/или абстрактных синтаксических деревьев.
Генерация парсера
Генерация парсера –процесс, который генерирует парсер по заданной грамматике. Генераторы парсера известны под названием PGen. В Cpython есть два генератора парсера. Один – оригинальный (
“Оригинальный генератор был первым кодом, который я написал для Python”
-Guido
Из вышеприведенной цитаты становится ясно, что pgen – самая важная вещь в языке программирования. Когда вы вызываете pgen (в Parser/pgen) он генерирует заголовочный файл и С-файл (сам парсер). Если вы посмотрите на сгенерированный код на С, он может показаться бессмысленным, поскольку его осмысленный вид – дело необязательное. Он содержит множество статических данных и структур. Дальше постараемся пояснить его основные компоненты.
DFA (Определенный конечный автомат)
Парсер определяет один DFA для каждого нетерминала. Каждый DFA определяется как массив состояний.
Для каждого DFA существует стартовый набор, который показывает с каких токенов может начинаться специальный нетерминал.
Состояние
Каждое состояние определяется массивом переходов/ребер (arcs).
Переходы (arcs)
В каждом массиве переходов есть два числа. Первый номер — это название перехода (arc label), он относится к номеру символа. Второе число — это точка назначения.
Названия (labels)
Это специальная таблица, которая соотносит id символа с названием перехода.
Цифра 1 соответствует всем идентификаторам. Таким образом каждый из них получает разные названия перехода даже если они все имеют одинаковое id символа.
Простой пример:
Допустим, у нас есть код, который выводит “Hi” если 1 — верно:
Парсер считает этот код как single_input.
Тогда наше дерево синтаксического анализа начинается с корневого узла разового ввода.

И значение нашего DFA (single_input) получается равным 0.
Это будет выглядеть следующим образом:
};
Здесь
Имея начальный набор

Новый DFA парсит составные высказывания (compound statements).
И у нас получается следующее:
Только первый переход может начинаться с

Дальше мы снова меняем DFA и следующее DFA парсит if’ы.
В итоге мы получаем единственный переход с обозначением 97. Он совпадает с
Когда мы переключаемся к следующему состоянию, оставаясь в том же самом DFA, следующий arcs_41_1 имеет также только один переход. Это справедливо для тестового нетерминала. Он должен начинаться с номера (например, 1).
В arc_41_2 есть только один переход, который получает токен двоеточие (:).

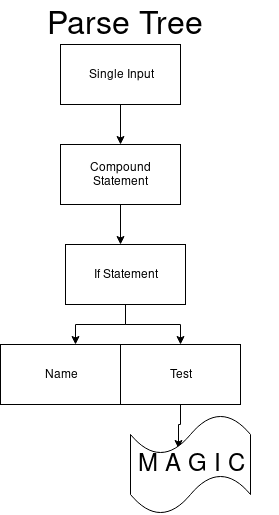
Так мы получаем набор, который может начинаться с печатного значения (print statement). Наконец, переходим к arcs_41_4. Первый переход в наборе — это выражение elif, второй — else и третий для последнего состояния. И мы получаем финальный вид дерева синтаксического анализа.

Интерфейс Python для парсера.
Python позволяет редактировать дерево синтаксического анализа для выражений, с помощью модуля, который называется parser.
Можно сгенерировать конкретное синтаксическое дерево (Concrete Syntax Tree, CST) с помощью parser.suite.
Выходным значением будет вложенный список. Каждый список в структуре имеет 2 элемента. Первый — это id символа ( 0-256 — терминалы, 256+ — нетерминалы) и второй — это строка токенов для терминала.
Абстрактное синтаксическое дерево
На самом деле абстрактное синтаксическое дерево (AST) — это структурное представление исходного кода в виде дерева, где каждая вершина обозначает различные типы конструкций языка (выражение, переменную, оператор и т.п.)
Что такое дерево?
Дерево — это структура данных, которая имеет корневую вершину, как начальную точку. Корневая вершина опускается ветвями (переходами) вниз к другим вершинам. Каждая вершина, кроме корневой, имеет одну уникальную родительскую вершину.
Между абстрактным синтаксическим деревом и деревом синтаксического анализа есть определенная разница.

Справа находится дерево синтаксического анализа выражения 2*7+3. Это буквально один к одному изображение исходного кода в виде дерева. На нем видны все выражения, слагаемые и значения. Однако такое изображение слишком сложно для простого кусочка кода, поэтому мы имеем возможность просто убрать все синтаксические выражения, которые мы должны были определять в коде для проведения вычислений.
Такое упрощенное дерево называется абстрактным синтаксическим деревом (AST). Слева на рисунке изображено именно оно для того же самого кода. Все синтаксические выражения были отброшены для упрощения понимания, но нужно помнить о том, что была потеряна определенная информация.
Пример
Python предлагает встроенный AST модуль для работы с AST. Для генерации кода из AST деревьев можно использовать сторонние модули, например Astor.
Для примера рассмотрим тот же код, что и ранее.
Для получения AST мы используем метод ast.parse.
Попробуйте использовать метод
AST в принципе считается более наглядным и удобным для понимания, чем дерево синтаксического анализа.
Граф потока управления (Control Flow Graf, CFG)
Графы потока управления – это направленные графы, которые моделируют поток программы, используя базовые блоки, которые содержат промежуточное представление.
Обычно CFG – это предыдущий шаг перед получением выходных значений кода. Код генерируется напрямую из базовых блоков с помощью обратного поиска в глубину в CFG, начиная от вершин.
Байткод
Байткод на Python – это промежуточный набор инструкций, которые работают на виртуальной машине Python’a. Когда вы запускаете исходный код, Python создает директорию, которая называется __pycache__. Она хранит скомпилированный код для того, чтобы сберечь время в случае перезапуска компиляции.
Рассмотрим простую функцию на Python в func.py.
Тип объекта
Она имеет атрибут
Объекты Кода
Объекты кода — это неизменяемые структуры данных, которые содержат инструкции или метаданные, необходимые для выполнения кода. Проще говоря, это представления кода на Python. Также можно получить объекты кода, компилируя абстрактные синтаксические деревья с помощью метода compile.
Каждый объект кода имеет атрибуты, которые содержат определенную информацию (с префиксом co_). Здесь мы упомянем лишь несколько из них.
co_name
Для начала – имя. Если существует функция, то у нее должно быть имя, соответственно, это имя будет именем функции, аналогичная ситуация с классом. В примере с AST мы используем модули, и мы точно можем сказать компилятору как мы хотим их назвать. Пускай они будут просто
co_varnames
Это кортеж, содержащий все локальные переменные, в том числе и аргументы.
co_conts
Кортеж, содержащий все литералы и константные значения, к которым мы обращались в теле функции. Здесь стоить отметить значение None. Мы не включали None в тело функции, однако Python указал его, поскольку в случае начала исполнения функции, а потом окончания без получения каких-либо возвращаемых значений, он вернет None.
Байткод (co_code)
Далее приведен байткод нашей функции.
Это не строка, это байтовый объект, то есть последовательность байт.
Первый выведенный символ это «t». Если мы запросим его числовое значение, то получим следующее.
116 – это то же самое, что и bytecode[0].
Для нас значение 116 ничего не значит. К счастью, Python предоставляет стандартную библиотеку, которая называется dis (от disassembly). Он полезна при работе с opname списком. Это список всех инструкций байткода, где каждый индекс – это имя инструкции.
Давайте создадим другую более сложную функцию.
И узнаем первую инструкцию в байткоде.
Инструкция LOAD_FAST состоит из двух элементов.
Инструкция Loadfast 0 случит для поиска имен переменных в кортеже и проталкивания элемента с нулевым индексом в кортеж в стеке исполнения.
Наш код можно дизассемблировать с помощью dis.dis и преобразовать байткод в привычный для человека вид. Здесь номера (2,3,4) – это номера строк. Каждая строка кода в Python раскрывается как множество инструкций.
Время выполнения
CPython – это стек-ориентированная виртуальная машина, а не набор регистров. Это значит, что код на Python компилируется для виртуального компьютера со стековой архитектурой.
При вызове функции Python использует два стека совместно. Первый – стек исполнения, а второй – стек блоков. Больше всего вызовов происходит в стеке исполнения; стек блоков отслеживает сколько блоков на данный момент активно, а также другие параметры, связанные с блоками и областями видимости.
Ждём ваши комментарии по материалу и приглашаем на открытый вебинар по теме: «Release it: практические аспекты выпуска надёжного софта», который проведет наш преподаватель — программист рекламной системы в Mail.Ru — Станислав Ступников.

Задачи:
— Узнать о внутреннем устройстве Python;
— Понять принципы построения абстрактного синтаксического дерева (AST);
— Писать более эффективный код по времени и по памяти.
Предварительные рекомендации:
— Базовое понимания работы интерпретатора (AST, токены и т.д.).
— Знание Python.
— Базовое знание С.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version
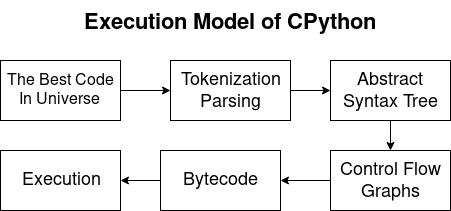
Python 3.7.0Модель выполнения CPython
Python компилируемый и интерпретируемый язык. Таким образом компилятор Python генерирует байткоды, а интерпретатор исполняет их. В ходе статьи мы рассмотрим следующие вопросы:
- Парсинг и токенизация:
- Трансформация в AST;
- Граф потока управления (CFG);
- Байткод;
- Выполнение на виртуальной машине CPython.
Парсинг и токенизация.
Грамматика.
Грамматика определяет семантику языка Python. Она также полезна в указании способа, котором парсер должен интерпретировать язык. Грамматика Python использует синтаксис подобный расширенной форме Бэкуса-Наура. Он имеет свою собственную грамматику для переводчика с исходного языка. Вы можете найти файл грамматики в директории “cpython/Grammar/Grammar”.
Далее приведен пример грамматики,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1
simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINEПростые выражения содержат маленькие выражения и скобки, а заканчивается команда новой строкой. Маленькие выражения выглядят как список выражений, которые импортируют…
Какие-то другие выражения:)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt |
import_stmt | global_stmt | nonlocal_stmt | assert_stmt)
...
del_stmt: 'del' exprlist
pass_stmt: 'pass'
flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt
break_stmt: 'break'
continue_stmt: 'continue'Токенизация (Лексический разбор)
Токенизация – это процесс получения текстового потока данных и разбиения на токены значащих (для интерпретатора) слов с дополнительными метаданными (например, где токен начинается и кончается, и каково строковое значение этого токена).
Токены
Токен – это заголовочный файл, содержащий определения всех токенов. Всего в Python 59 типов токенов (Include/token.h).
Ниже приведен пример некоторых из них,
#define NAME 1
#define NUMBER 2
#define STRING 3
#define NEWLINE 4
#define INDENT 5
#define DEDENT 6Их вы видите, если разбиваете на токены какой-то код на Python.
Токенизация с помощью CLI
Здесь представлен файл tests.py
def greetings(name: str):
print(f"Hello {name}")
greetings("Batuhan")Дальше его мы токенезируем с помощью команды python -m tokenize и на выходе получаем следующее:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py
0,0-0,0: ENCODING 'utf-8'
...
2,0-2,4: INDENT ' '
2,4-2,9: NAME 'print'
...
4,0-4,0: DEDENT ''
...
5,0-5,0: ENDMARKER ''
Здесь номера (например 1,4-1,13) показывают, где токен начался и где он закончился. Токен кодирования (encoding token) – это всегда самый первый токен, который мы получаем. Он дает информацию о кодировке исходного файла и если с ней есть какие-то проблемы, то интерпретатор вызывает exception.
Токенизация с помощью tokenize.tokenize
Если нужно разбить на токены файл из вашего кода, вы можете использовать модуль tokenize из stdlib.
>>> with open('tests.py', 'rb') as f:
... for token in tokenize.tokenize(f.readline):
... print(token)
...
TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='')
...
TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n')
...
TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n')
...Тип токена — это его id в заголовочном файле token.h. String– это значение токена. Start и End показывают, где токен начинается и заканчивается соответственно.
В других языках блоки обозначаются скобками или операторами begin/end, но в Python используются отступы и разные уровни. INDENT и DEDENT токены и указывают на отступы. Эти токены нужны для построения реляционных деревьев синтаксического анализа и/или абстрактных синтаксических деревьев.
Генерация парсера
Генерация парсера –процесс, который генерирует парсер по заданной грамматике. Генераторы парсера известны под названием PGen. В Cpython есть два генератора парсера. Один – оригинальный (
Parser/pgen) и один переписанный на python (/Lib/lib2to3/pgen2).“Оригинальный генератор был первым кодом, который я написал для Python”
-Guido
Из вышеприведенной цитаты становится ясно, что pgen – самая важная вещь в языке программирования. Когда вы вызываете pgen (в Parser/pgen) он генерирует заголовочный файл и С-файл (сам парсер). Если вы посмотрите на сгенерированный код на С, он может показаться бессмысленным, поскольку его осмысленный вид – дело необязательное. Он содержит множество статических данных и структур. Дальше постараемся пояснить его основные компоненты.
DFA (Определенный конечный автомат)
Парсер определяет один DFA для каждого нетерминала. Каждый DFA определяется как массив состояний.
static dfa dfas[87] = {
{256, "single_input", 0, 3, states_0,
"\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"},
...
{342, "yield_arg", 0, 3, states_86,
"\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"},
};Для каждого DFA существует стартовый набор, который показывает с каких токенов может начинаться специальный нетерминал.
Состояние
Каждое состояние определяется массивом переходов/ребер (arcs).
static state states_86[3] = {
{2, arcs_86_0},
{1, arcs_86_1},
{1, arcs_86_2},
};Переходы (arcs)
В каждом массиве переходов есть два числа. Первый номер — это название перехода (arc label), он относится к номеру символа. Второе число — это точка назначения.
static arc arcs_86_0[2] = {
{77, 1},
{47, 2},
};
static arc arcs_86_1[1] = {
{26, 2},
};
static arc arcs_86_2[1] = {
{0, 2},
};
Названия (labels)
Это специальная таблица, которая соотносит id символа с названием перехода.
static label labels[177] = {
{0, "EMPTY"},
{256, 0},
{4, 0},
...
{1, "async"},
{1, "def"},
...
{1, "yield"},
{342, 0},
};Цифра 1 соответствует всем идентификаторам. Таким образом каждый из них получает разные названия перехода даже если они все имеют одинаковое id символа.
Простой пример:
Допустим, у нас есть код, который выводит “Hi” если 1 — верно:
if 1: print('Hi')Парсер считает этот код как single_input.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINEТогда наше дерево синтаксического анализа начинается с корневого узла разового ввода.

И значение нашего DFA (single_input) получается равным 0.
static dfa dfas[87] = {
{256, "single_input", 0, 3, states_0,
"\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}
...
}
Это будет выглядеть следующим образом:
static arc arcs_0_0[3] = {
{2, 1},
{3, 1},
{4, 2},
};
static arc arcs_0_1[1] = {
{0, 1},
};
static arc arcs_0_2[1] = {
{2, 1},
};
static state states_0[3] = {
{3, arcs_0_0},
{1, arcs_0_1},
{1, };
Здесь
arc_0_0 состоит из трех элементов. Первый — это NEWLINE, второй — simple_stmt, и последний — compound_stmt.Имея начальный набор
simple_stmt можно заключить, что simple_stmt не может начинаться с if. Однако даже если if — это не новая строка, то compound_stmt все равно может начинаться с if. Таким образом мы переходим с последнему arc ({4;2}) и добавляем узел compound_stmt к дереву синтаксического анализа и перед тем, как перейти к номеру 2, переключаемся на новый DFA. Мы получаем обновленное дерево синтаксического анализа:
Новый DFA парсит составные высказывания (compound statements).
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmtИ у нас получается следующее:
static arc arcs_39_0[9] = {
{91, 1},
{92, 1},
{93, 1},
{94, 1},
{95, 1},
{19, 1},
{18, 1},
{17, 1},
{96, 1},
};
static arc arcs_39_1[1] = {
{0, 1},
};
static state states_39[2] = {
{9, arcs_39_0},
{1, arcs_39_1},
};
Только первый переход может начинаться с
if. Мы получаем обновленное дерево синтаксического анализа.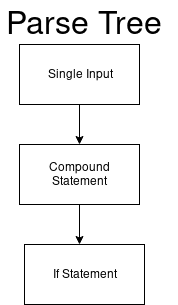
Дальше мы снова меняем DFA и следующее DFA парсит if’ы.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]В итоге мы получаем единственный переход с обозначением 97. Он совпадает с
if токеном.static arc arcs_41_0[1] = {
{97, 1},
};
static arc arcs_41_1[1] = {
{26, 2},
};
static arc arcs_41_2[1] = {
{27, 3},
};
static arc arcs_41_3[1] = {
{28, 4},
};
static arc arcs_41_4[3] = {
{98, 1},
{99, 5},
{0, 4},
};
static arc arcs_41_5[1] = {
{27, 6},
};
static arc arcs_41_6[1] = {
{28, 7},
};
...Когда мы переключаемся к следующему состоянию, оставаясь в том же самом DFA, следующий arcs_41_1 имеет также только один переход. Это справедливо для тестового нетерминала. Он должен начинаться с номера (например, 1).
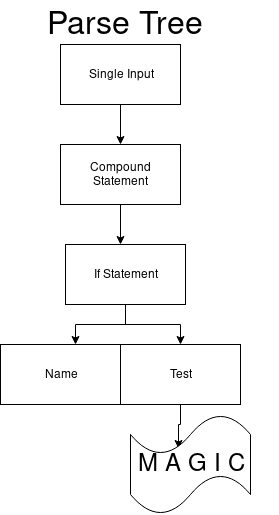
В arc_41_2 есть только один переход, который получает токен двоеточие (:).

Так мы получаем набор, который может начинаться с печатного значения (print statement). Наконец, переходим к arcs_41_4. Первый переход в наборе — это выражение elif, второй — else и третий для последнего состояния. И мы получаем финальный вид дерева синтаксического анализа.

Интерфейс Python для парсера.
Python позволяет редактировать дерево синтаксического анализа для выражений, с помощью модуля, который называется parser.
>>> import parser
>>> code = "if 1: print('Hi')"Можно сгенерировать конкретное синтаксическое дерево (Concrete Syntax Tree, CST) с помощью parser.suite.
>>> parser.suite(code).tolist()
[257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]Выходным значением будет вложенный список. Каждый список в структуре имеет 2 элемента. Первый — это id символа ( 0-256 — терминалы, 256+ — нетерминалы) и второй — это строка токенов для терминала.
Абстрактное синтаксическое дерево
На самом деле абстрактное синтаксическое дерево (AST) — это структурное представление исходного кода в виде дерева, где каждая вершина обозначает различные типы конструкций языка (выражение, переменную, оператор и т.п.)
Что такое дерево?
Дерево — это структура данных, которая имеет корневую вершину, как начальную точку. Корневая вершина опускается ветвями (переходами) вниз к другим вершинам. Каждая вершина, кроме корневой, имеет одну уникальную родительскую вершину.
Между абстрактным синтаксическим деревом и деревом синтаксического анализа есть определенная разница.
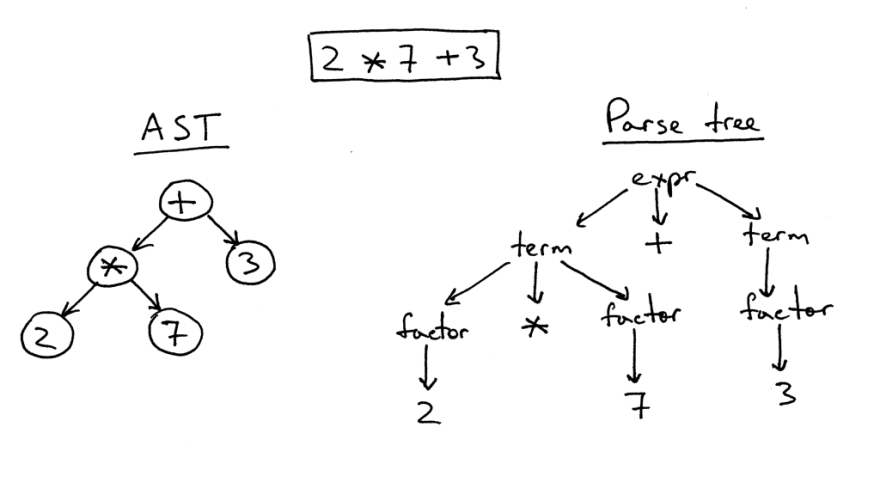
Справа находится дерево синтаксического анализа выражения 2*7+3. Это буквально один к одному изображение исходного кода в виде дерева. На нем видны все выражения, слагаемые и значения. Однако такое изображение слишком сложно для простого кусочка кода, поэтому мы имеем возможность просто убрать все синтаксические выражения, которые мы должны были определять в коде для проведения вычислений.
Такое упрощенное дерево называется абстрактным синтаксическим деревом (AST). Слева на рисунке изображено именно оно для того же самого кода. Все синтаксические выражения были отброшены для упрощения понимания, но нужно помнить о том, что была потеряна определенная информация.
Пример
Python предлагает встроенный AST модуль для работы с AST. Для генерации кода из AST деревьев можно использовать сторонние модули, например Astor.
Для примера рассмотрим тот же код, что и ранее.
>>> import ast
>>> code = "if 1: print('Hi')"Для получения AST мы используем метод ast.parse.
>>> tree = ast.parse(code)
>>> tree
<_ast.Module object at 0x7f37651d76d8>Попробуйте использовать метод
ast.dump для получения более читаемого абстрактного синтаксического дерева. >>> ast.dump(tree)
"Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"AST в принципе считается более наглядным и удобным для понимания, чем дерево синтаксического анализа.
Граф потока управления (Control Flow Graf, CFG)
Графы потока управления – это направленные графы, которые моделируют поток программы, используя базовые блоки, которые содержат промежуточное представление.
Обычно CFG – это предыдущий шаг перед получением выходных значений кода. Код генерируется напрямую из базовых блоков с помощью обратного поиска в глубину в CFG, начиная от вершин.
Байткод
Байткод на Python – это промежуточный набор инструкций, которые работают на виртуальной машине Python’a. Когда вы запускаете исходный код, Python создает директорию, которая называется __pycache__. Она хранит скомпилированный код для того, чтобы сберечь время в случае перезапуска компиляции.
Рассмотрим простую функцию на Python в func.py.
def say_hello(name: str):
print("Hello", name)
print(f"How are you {name}?")>>> from func import say_hello
>>> say_hello("Batuhan")
Hello Batuhan
How are you Batuhan?Тип объекта
say_hello – это функция. >>> type(say_hello)
<class 'function'>Она имеет атрибут
__code__. >>> say_hello.__code__
<code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>Объекты Кода
Объекты кода — это неизменяемые структуры данных, которые содержат инструкции или метаданные, необходимые для выполнения кода. Проще говоря, это представления кода на Python. Также можно получить объекты кода, компилируя абстрактные синтаксические деревья с помощью метода compile.
>>> import ast
>>> code = """
... def say_hello(name: str):
... print("Hello", name)
... print(f"How are you {name}?")
... say_hello("Batuhan")
... """
>>> tree = ast.parse(code, mode='exec')
>>> code = compile(tree, '<string>', mode='exec')
>>> type(code)
<class 'code'>Каждый объект кода имеет атрибуты, которые содержат определенную информацию (с префиксом co_). Здесь мы упомянем лишь несколько из них.
co_name
Для начала – имя. Если существует функция, то у нее должно быть имя, соответственно, это имя будет именем функции, аналогичная ситуация с классом. В примере с AST мы используем модули, и мы точно можем сказать компилятору как мы хотим их назвать. Пускай они будут просто
module. >>> code.co_name
'<module>'
>>> say_hello.__code__.co_name
'say_hello'co_varnames
Это кортеж, содержащий все локальные переменные, в том числе и аргументы.
>>> say_hello.__code__.co_varnames
('name',)co_conts
Кортеж, содержащий все литералы и константные значения, к которым мы обращались в теле функции. Здесь стоить отметить значение None. Мы не включали None в тело функции, однако Python указал его, поскольку в случае начала исполнения функции, а потом окончания без получения каких-либо возвращаемых значений, он вернет None.
>>> say_hello.__code__.co_consts
(None, 'Hello', 'How are you ', '?')Байткод (co_code)
Далее приведен байткод нашей функции.
>>> bytecode = say_hello.__code__.co_code
>>> bytecode
b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'Это не строка, это байтовый объект, то есть последовательность байт.
>>> type(bytecode)
<class 'bytes'>Первый выведенный символ это «t». Если мы запросим его числовое значение, то получим следующее.
>>> ord('t')
116116 – это то же самое, что и bytecode[0].
>>> assert bytecode[0] == ord('t')
Для нас значение 116 ничего не значит. К счастью, Python предоставляет стандартную библиотеку, которая называется dis (от disassembly). Он полезна при работе с opname списком. Это список всех инструкций байткода, где каждый индекс – это имя инструкции.
>>> dis.opname[ord('t')]
'LOAD_GLOBAL'Давайте создадим другую более сложную функцию.
>>> def multiple_it(a: int):
... if a % 2 == 0:
... return 0
... return a * 2
...
>>> multiple_it(6)
0
>>> multiple_it(7)
14
>>> bytecode = multiple_it.__code__.co_codeИ узнаем первую инструкцию в байткоде.
>>> dis.opname[bytecode[0]]
'LOAD_FASTИнструкция LOAD_FAST состоит из двух элементов.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]]
'LOAD_FAST <0>'Инструкция Loadfast 0 случит для поиска имен переменных в кортеже и проталкивания элемента с нулевым индексом в кортеж в стеке исполнения.
>>> multiple_it.__code__.co_varnames[bytecode[1]]
'a'Наш код можно дизассемблировать с помощью dis.dis и преобразовать байткод в привычный для человека вид. Здесь номера (2,3,4) – это номера строк. Каждая строка кода в Python раскрывается как множество инструкций.
>>> dis.dis(multiple_it)
2 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (2)
4 BINARY_MODULO
6 LOAD_CONST 2 (0)
8 COMPARE_OP 2 (==)
10 POP_JUMP_IF_FALSE 16
3 12 LOAD_CONST 2 (0)
14 RETURN_VALUE
4 >> 16 LOAD_FAST 0 (a)
18 LOAD_CONST 1 (2)
20 BINARY_MULTIPLY
22 RETURN_VALUEВремя выполнения
CPython – это стек-ориентированная виртуальная машина, а не набор регистров. Это значит, что код на Python компилируется для виртуального компьютера со стековой архитектурой.
При вызове функции Python использует два стека совместно. Первый – стек исполнения, а второй – стек блоков. Больше всего вызовов происходит в стеке исполнения; стек блоков отслеживает сколько блоков на данный момент активно, а также другие параметры, связанные с блоками и областями видимости.
Ждём ваши комментарии по материалу и приглашаем на открытый вебинар по теме: «Release it: практические аспекты выпуска надёжного софта», который проведет наш преподаватель — программист рекламной системы в Mail.Ru — Станислав Ступников.
