Назначение std::string_view заключается в том, чтобы избежать копирования данных, которые уже чему-то принадлежат и для которых требуется только лишь неизменяемое представление. Как вы уже могли догадаться, этот пост будет посвящен производительности.
Сегодня речь пойдет об одной из главных фич C++17.
Я предполагаю, что вы уже имеет базовое представление о std::string_view. Если нет, то можете сперва прочитать мой предыдущий пост “C++17 - Что нового в библиотеке”. Строка C++ похожа на тонкую обертку, которая хранит свои данные в куче. Поэтому, когда вы имеете дело со строками в C и C++, выделение памяти - самое заурядное явление. Давайте же разберемся с этим.
Оптимизация небольших строк
Очень скоро вы увидите, почему я назвал этот абзац оптимизацией небольших строк.
// sso.cpp
#include <iostream>
#include <string>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string small = "0123456789";
std::string substr = small.substr(5);
std::cout << " " << substr << std::endl;
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(small);
getString("0123456789");
const char message []= "0123456789";
getString(message);
std::cout << std::endl;
}Я перегрузил глобальный оператор new в строках 6-9. Таким образом, вы сможете увидеть, какая операция вызывает выделение памяти. Да ладно, это проще пареной репы. Конечно же выделение памяти вызывают строки 19, 20, 28 и 29. А теперь давайте посмотрим на вывод:
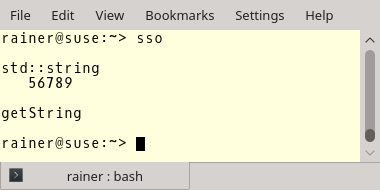
Что за ...? Я говорил, что строки хранят свои данные в куче. Но это верно только в том случае, если длина строки превышает некоторый размер, зависящий от реализации. Этот размер для std::string составляет 15 в MSVC и GCC и 23 в Clang.
Это означает, что небольшие строки на самом деле хранятся непосредственно в самом объекте строки. Поэтому выделение памяти не требуется.
Хорошо, отныне мои строки всегда будут содержать не менее 30 символов, чтобы мне не нужно было отвлекаться на оптимизацию небольших строк. Давайте начнем с начала, но на этот раз с более длинными строками.
Выделение памяти не требуется
Теперь назад к лучезарному std::string_view. В отличие от std::string, std::string_view не выделяет память. И вот тому доказательство:
// stringView.cpp
#include <cassert>
#include <iostream>
#include <string>
#include <string_view>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
void getStringView(std::string_view strView){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string large = "0123456789-123456789-123456789-123456789";
std::string substr = large.substr(10);
std::cout << std::endl;
std::cout << "std::string_view" << std::endl;
std::string_view largeStringView{large.c_str(), large.size()};
largeStringView.remove_prefix(10);
assert(substr == largeStringView);
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(large);
getString("0123456789-123456789-123456789-123456789");
const char message []= "0123456789-123456789-123456789-123456789";
getString(message);
std::cout << std::endl;
std::cout << "getStringView" << std::endl;
getStringView(large);
getStringView("0123456789-123456789-123456789-123456789");
getStringView(message);
std::cout << std::endl;
}Еще раз. Выделение памяти происходит в строках 24, 25, 41 и 43. Но что происходит в соответствующих вызовах в строках 31, 32, 50 и 51? Никакого выделения памяти не происходит!
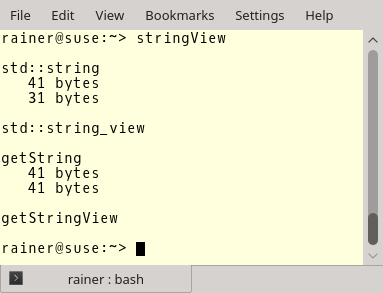
Это впечатляет. Вы можете даже не сомневаться, что это значительный прирост производительности, потому что выделение памяти — очень затратная операция. Особенно хорошо заметен этот прирост производительности, когда вы создаете подстроки на основе существующих строк.
O(n) vs. O(1)
std::string и std::string_view оба содержат метод substr. Метод std::string возвращает подстроку, а метод std::string_view возвращает представление подстроки. Это звучит не так захватывающе, но между этими методами есть существенная разница. std::string::substr имеет линейную сложность, а std::string_view::substr — константную сложность. Это означает, что производительность операции над std::string напрямую зависит от размера подстроки, а производительность операции над std::string_view — не зависит.
Вот теперь мне действительно любопытно. Давайте проведем простое сравнение производительности.
// substr.cpp
#include <chrono>
#include <fstream>
#include <iostream>
#include <random>
#include <sstream>
#include <string>
#include <vector>
#include <string_view>
static const int count = 30;
static const int access = 10000000;
int main(){
std::cout << std::endl;
std::ifstream inFile("grimm.txt");
std::stringstream strStream;
strStream << inFile.rdbuf();
std::string grimmsTales = strStream.str();
size_t size = grimmsTales.size();
std::cout << "Grimms' Fairy Tales size: " << size << std::endl;
std::cout << std::endl;
// случайные значения
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<> uniformDist(0, size - count - 2);
std::vector<int> randValues;
for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine));
auto start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTales.substr(randValues[i], count);
}
std::chrono::duration<double> durString= std::chrono::steady_clock::now() - start;
std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl;
std::string_view grimmsTalesView{grimmsTales.c_str(), size};
start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTalesView.substr(randValues[i], count);
}
std::chrono::duration<double> durStringView= std::chrono::steady_clock::now() - start;
std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl;
std::cout << std::endl;
std::cout << "durString.count()/durStringView.count(): " << durString.count()/durStringView.count() << std::endl;
std::cout << std::endl;
} Прежде чем я представлю вам результаты, позвольте мне сказать пару слов о моем тесте производительности. Основная идея этого теста производительности заключается в том, чтобы считать большой файл в качестве std::string и создать много подстрок с помощью std::string и std::string_view. Здесь меня конкретно интересует, сколько времени займет создание этих подстрок.
В качестве своего длинного файла я использовал “Сказки братьев Гримм”. А что еще мне было использовать? Строка grimmTales (строчка 24) содержит внутренности файла. Я заполняю std::vector<int> в строчке 37 с количеством access (10'000'000) значений в диапазоне [0, размер - количество - 2] (строчка 34). А теперь начинается сам тест производительности. Я создаю в строчках с 39 по 41 access подстрок фиксированной длины count. count равно 30. Следовательно, оптимизация небольших строк не будет мешаться под ногами. Я делаю то же самое в строчках с 47 по 49 с применением std::string_view.
Вот результаты. Ниже вы можете видеть длину файла, показатели для std::string::substr и std::string_view::substr, и соотношение между ними. В качестве компилятора я использовал GCC 6.3.0.
Для строк размером в 30 символов
Только из любопытства. Показатели без оптимизации.
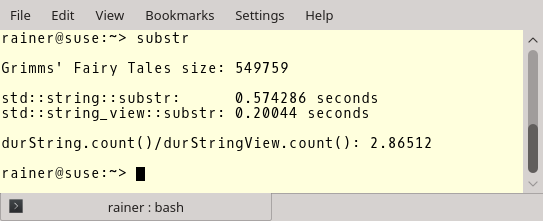
Но теперь к более важным показателям. GCC с полной оптимизацией.
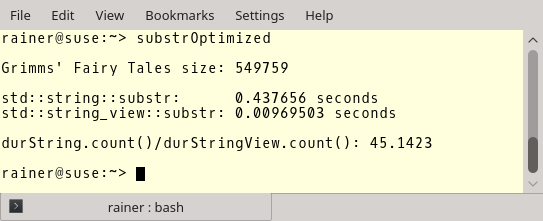
Оптимизация не имеет особого значения в случае std::string, но мы наблюдаем большую разницу в случае std::string_view. Создание подстроки с помощью std::string_view примерно в 45 раз быстрее, чем при использовании std::string. Что это, если не повод использовать std::string_view?
Для строк других размеров
Теперь мне стало еще интереснее. Что будет, если я поиграю с размером count подстроки? Разумеется, все показатели для максимальной оптимизацией. Я округлил их до 3-го знака после запятой.
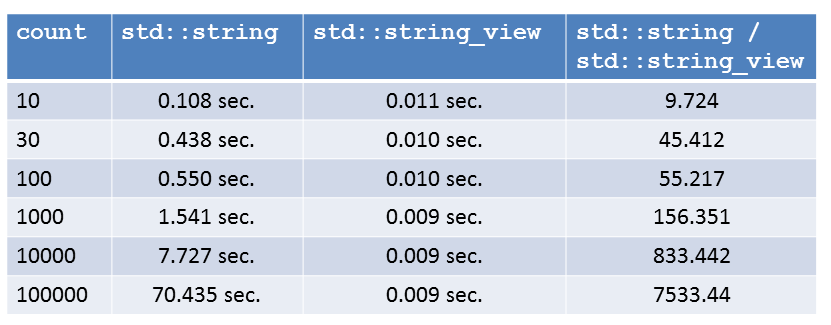
Я не удивлен, цифры отражают гарантии сложности std::string::substr в противопоставление std::string_view::substr. Сложность первого линейно зависит от размера подстроки; второй не зависит от размера подстроки. В конечном итоге, std::string_view радикальным образом превосходит std::string.
Сегодня вечером состоится открытый урок, на котором разберемся, какие основные алгоритмы включены в STL. В ходе занятия познакомимся с алгоритмами поиска и сортировки. Записаться можно на странице курса "C++ Developer. Professional".
