Содержание:
Вспоминаем, что вначале у нас была задана схема:
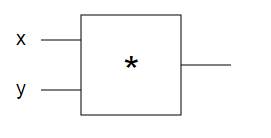
Наша схема имеет один логический элемент * и несколько определенных исходных значений (например, x = -2, y = 3). Логический элемент вычисляет результат (-6) и мы хотим изменить x и y, чтобы сделать результат больше.
То, что мы собираемся сделать, выглядит следующим образом: Представьте себе, что вы взяли выходное значение, которое получается из схемы, и тянете его в положительном направлении. Это положительное натяжение будет, в свою очередь, передаваться через логический элемент и прилагать силы на исходные значения x и y. Силы, которые сообщат нам, как должны измениться x и y, чтобы увеличить результирующее значение.
Как такие силы могут выглядеть на нашем непосредственном примере? Мы можем предположить, что сила, оказанная на x, также должна быть положительной, так как небольшое увеличение x улучшает результат схемы. Например, увеличение с x = -2 на x = -1 даст в результате -3, что намного больше, чем -6. С другой стороны, на y должна оказываться отрицательная сила, которая заставит его уменьшиться (так как более низкое значение y, например, y = 2, по сравнению с изначальным y = 3, сделает результат выше: 2 x -2 = -4, что опять же больше, чем -6). Этот принцип в любом случае нужно запомнить. Когда мы будем двигаться дальше, окажется, что силы, которые я описал, фактически будут производной выходных значений по отношению к их исходным значениям (x и y). Вы наверняка уже слышали этот термин.
Как мы на самом деле можем оценить эту силу (производную)? Оказывается, для этого есть довольно простая процедура. Мы будем работать в обратном направлении: вместо растягивания результата схемы, мы будем изменять каждое исходное значение по очереди, увеличивать по чуть-чуть, и смотреть, что происходит с результатом. Число изменения выходного значения и есть производная. Но пока достаточно теории. Давайте рассмотрим математическое определение. Мы можем записать производную для нашей функции по отношению к исходным значениям. Например, производная по отношению к x может рассчитываться следующим образом:
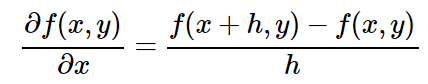
Где h – это небольшое значение изменения. Кроме того, если вы не особо знакомы с этим методом расчета, обратите внимание, что в левой части вышеуказанного уравнения горизонтальная линия не означает деление. Целый символ (∂f(x,y))/∂x является единым элементом: производной функции f(x,y) по отношению к x. Горизонтальная линия в правой части является делением. Я знаю, что это сложно, но это стандартное обозначение. В любом случае, я надеюсь, что это выглядит не слишком страшно.
Схема выдала определенный изначальный результат f(x,y), после чего мы изменили одно из исходных значений на небольшое число h и получили новый результат f(x+h,y). Вычитание этих двух значений показывает нам изменение, а деление на h просто приводит это изменение к (произвольному) значению изменения, использованному нами. Другими словами, это выражает именно то, что я описал выше, и переводит это в такой код:
напомним, что функция forwardMultiplyGate(x, y) возвращает произведение аргументов
Давайте пройдемся по примеру для x. Мы превратили x в x + h, и схема ответила нам более высоким значением (опять же, обратите внимание, что -5.9997 > -6). Деление на h (в формуле производной) выполняется для приведения результата схемы к (произвольному) значению h, которое мы решили в данном случае использовать. Технически нам нужно, чтобы значение h было бесконечно малым (точное математическое определение градиента выражается как предел выражения при h стремящемся к нулю), но на практике h=0.00001 или подобное значение отлично подходит для большинства случаев, в которых нужно получить хорошее приближение. Теперь мы видим, что производная относительно x равна +3. Я специально указал знак плюса, так как он показывает, что схема тянет x в сторону более высокого значения. Фактическое значение 3 можно интерпретировать, как силу такого натяжения.
Кстати, обычно мы говорим о производной по отношению к одному исходному значению, или о градиенте по отношению ко всем таким значениям. Градиент состоит из производных всех исходных значений, соединенных в вектор (т.е. список). Самое главное, если мы позволим исходным значениям отвечать на натяжение небольшим значением, следующим за градиентом (т.е. мы добавим производную только в верхнюю точку каждого исходного значения), мы сможем увидеть, что оно увеличивается, как мы и ожидали:
Как и ожидалось, мы изменили исходные значения на градиент, и схема теперь выдает более высокое значение (-5.87 > -6.0). Это было намного проще, чем пытаться произвольно изменять x и y, правда? Факт в том, что если выполнить расчеты, можно доказать, что градиент фактически является направлением резкого увеличения функции. Нет необходимости плясать с бубном, пытаясь подставить произвольные значения, как мы делали в стратегии №1. Для оценки градиента требуется только три оценки прохода схемы вместо сотни, и мы получаем оптимальный толчок, на который мы могли рассчитывать (локально), если мы заинтересованы в увеличении значения выхода.
Больше не всегда значит лучше. Позвольте мне немного пояснить. Обратите внимание, что в этом простейшем примере использование размера шага (step_size) больше, чем 0,01, всегда дает лучший результат. Например, step_size = 1.0 дает в результате -1 (больше, лучше!), а действительно бесконечный размер шага может дать бесконечно хороший результат. Важно понять, что как только наши схемы станут значительно более сложными (например, целые нейронные сети), функции от исходных до выходных значений будут более хаотичными и «кучерявыми». Градиент гарантирует, что если у вас очень маленький (по сути, бесконечно малый) размер шага, тогда вы определенно получите большее число, если проследуете в его направлении, и для такого бесконечного малого размера шага нет другого направления, которое работало бы так же хорошо. Но если вы будете использовать больший шаг (например, step_size = 0.01), все потеряет смысл. Причина, по которой мы можем с успехом использовать больший шаг, вместо бесконечного малого, заключается в том, что наши функции обычно относительно однородные. Но на самом деле мы скрещиваем пальцы и надеемся на лучшее.
Аналогия с восхождением на вершину. Я как-то слышал одну аналогию, что выходное значение нашей схемы подобно вершине холма, а мы пытаемся взобраться на нее с завязанными глазами. Мы ощущаем крутизну склона холма под ногами (градиент), поэтому, если мы будем понемногу переставлять ноги, мы взберемся наверх. Но если мы сделаем большой и слишком уверенный шаг, мы можем попасть в яму.
Надеюсь, я убедил вас, что числовой градиент – это действительно очень полезная штука для оценки, к тому же довольно простая. Но. Оказывается, мы можем еще больше, о чем и поговорим в следующей части.
Глава 1: Схемы реальных значений
Часть 1:
Часть 2:
Часть 3:
Часть 4:
Часть 5:
Часть 6:
Введение
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: Произвольный локальный поиск
Часть 2:
Стратегия №2: Числовой градиент
Часть 3:
Стратегия №3: Аналитический градиент
Часть 4:
Схемы с несколькими логическими элементами
Обратное распространение ошибки
Часть 5:
Шаблоны в «обратном» потоке
Пример "Один нейрон"
Часть 6:
Становимся мастером обратного распространения ошибки
Глава 2: Машинное обучение
Вспоминаем, что вначале у нас была задана схема:
Наша схема имеет один логический элемент * и несколько определенных исходных значений (например, x = -2, y = 3). Логический элемент вычисляет результат (-6) и мы хотим изменить x и y, чтобы сделать результат больше.
То, что мы собираемся сделать, выглядит следующим образом: Представьте себе, что вы взяли выходное значение, которое получается из схемы, и тянете его в положительном направлении. Это положительное натяжение будет, в свою очередь, передаваться через логический элемент и прилагать силы на исходные значения x и y. Силы, которые сообщат нам, как должны измениться x и y, чтобы увеличить результирующее значение.
Как такие силы могут выглядеть на нашем непосредственном примере? Мы можем предположить, что сила, оказанная на x, также должна быть положительной, так как небольшое увеличение x улучшает результат схемы. Например, увеличение с x = -2 на x = -1 даст в результате -3, что намного больше, чем -6. С другой стороны, на y должна оказываться отрицательная сила, которая заставит его уменьшиться (так как более низкое значение y, например, y = 2, по сравнению с изначальным y = 3, сделает результат выше: 2 x -2 = -4, что опять же больше, чем -6). Этот принцип в любом случае нужно запомнить. Когда мы будем двигаться дальше, окажется, что силы, которые я описал, фактически будут производной выходных значений по отношению к их исходным значениям (x и y). Вы наверняка уже слышали этот термин.
Производную можно рассматривать в качестве силы, воздействующей на каждое исходное значение по мере того, как мы увеличиваем результирующее значение
Как мы на самом деле можем оценить эту силу (производную)? Оказывается, для этого есть довольно простая процедура. Мы будем работать в обратном направлении: вместо растягивания результата схемы, мы будем изменять каждое исходное значение по очереди, увеличивать по чуть-чуть, и смотреть, что происходит с результатом. Число изменения выходного значения и есть производная. Но пока достаточно теории. Давайте рассмотрим математическое определение. Мы можем записать производную для нашей функции по отношению к исходным значениям. Например, производная по отношению к x может рассчитываться следующим образом:
Где h – это небольшое значение изменения. Кроме того, если вы не особо знакомы с этим методом расчета, обратите внимание, что в левой части вышеуказанного уравнения горизонтальная линия не означает деление. Целый символ (∂f(x,y))/∂x является единым элементом: производной функции f(x,y) по отношению к x. Горизонтальная линия в правой части является делением. Я знаю, что это сложно, но это стандартное обозначение. В любом случае, я надеюсь, что это выглядит не слишком страшно.
Схема выдала определенный изначальный результат f(x,y), после чего мы изменили одно из исходных значений на небольшое число h и получили новый результат f(x+h,y). Вычитание этих двух значений показывает нам изменение, а деление на h просто приводит это изменение к (произвольному) значению изменения, использованному нами. Другими словами, это выражает именно то, что я описал выше, и переводит это в такой код:
напомним, что функция forwardMultiplyGate(x, y) возвращает произведение аргументов
var x = -2, y = 3;
var out = forwardMultiplyGate(x, y); // -6
var h = 0.0001;
// расчет производной по отношению к x
var xph = x + h; // -1.9999
var out2 = forwardMultiplyGate(xph, y); // -5.9997
var x_derivative = (out2 - out) / h; // 3.0
// расчет производной по отношению к y
var yph = y + h; // 3.0001
var out3 = forwardMultiplyGate(x, yph); // -6.0002
var y_derivative = (out3 - out) / h; // -2.0
Давайте пройдемся по примеру для x. Мы превратили x в x + h, и схема ответила нам более высоким значением (опять же, обратите внимание, что -5.9997 > -6). Деление на h (в формуле производной) выполняется для приведения результата схемы к (произвольному) значению h, которое мы решили в данном случае использовать. Технически нам нужно, чтобы значение h было бесконечно малым (точное математическое определение градиента выражается как предел выражения при h стремящемся к нулю), но на практике h=0.00001 или подобное значение отлично подходит для большинства случаев, в которых нужно получить хорошее приближение. Теперь мы видим, что производная относительно x равна +3. Я специально указал знак плюса, так как он показывает, что схема тянет x в сторону более высокого значения. Фактическое значение 3 можно интерпретировать, как силу такого натяжения.
Производную по отношению к какому-либо исходному значению можно рассчитать путем подстройки такого исходного значения на небольшое число и наблюдения за изменение выходного значения.
Кстати, обычно мы говорим о производной по отношению к одному исходному значению, или о градиенте по отношению ко всем таким значениям. Градиент состоит из производных всех исходных значений, соединенных в вектор (т.е. список). Самое главное, если мы позволим исходным значениям отвечать на натяжение небольшим значением, следующим за градиентом (т.е. мы добавим производную только в верхнюю точку каждого исходного значения), мы сможем увидеть, что оно увеличивается, как мы и ожидали:
var step_size = 0.01;
var out = forwardMultiplyGate(x, y); // раньше было: -6
x = x + step_size * x_derivative; // x становится -1.97
y = y + step_size * y_derivative; // y становится 2.98
var out_new = forwardMultiplyGate(x, y); // -5.87!
Как и ожидалось, мы изменили исходные значения на градиент, и схема теперь выдает более высокое значение (-5.87 > -6.0). Это было намного проще, чем пытаться произвольно изменять x и y, правда? Факт в том, что если выполнить расчеты, можно доказать, что градиент фактически является направлением резкого увеличения функции. Нет необходимости плясать с бубном, пытаясь подставить произвольные значения, как мы делали в стратегии №1. Для оценки градиента требуется только три оценки прохода схемы вместо сотни, и мы получаем оптимальный толчок, на который мы могли рассчитывать (локально), если мы заинтересованы в увеличении значения выхода.
Больше не всегда значит лучше. Позвольте мне немного пояснить. Обратите внимание, что в этом простейшем примере использование размера шага (step_size) больше, чем 0,01, всегда дает лучший результат. Например, step_size = 1.0 дает в результате -1 (больше, лучше!), а действительно бесконечный размер шага может дать бесконечно хороший результат. Важно понять, что как только наши схемы станут значительно более сложными (например, целые нейронные сети), функции от исходных до выходных значений будут более хаотичными и «кучерявыми». Градиент гарантирует, что если у вас очень маленький (по сути, бесконечно малый) размер шага, тогда вы определенно получите большее число, если проследуете в его направлении, и для такого бесконечного малого размера шага нет другого направления, которое работало бы так же хорошо. Но если вы будете использовать больший шаг (например, step_size = 0.01), все потеряет смысл. Причина, по которой мы можем с успехом использовать больший шаг, вместо бесконечного малого, заключается в том, что наши функции обычно относительно однородные. Но на самом деле мы скрещиваем пальцы и надеемся на лучшее.
Аналогия с восхождением на вершину. Я как-то слышал одну аналогию, что выходное значение нашей схемы подобно вершине холма, а мы пытаемся взобраться на нее с завязанными глазами. Мы ощущаем крутизну склона холма под ногами (градиент), поэтому, если мы будем понемногу переставлять ноги, мы взберемся наверх. Но если мы сделаем большой и слишком уверенный шаг, мы можем попасть в яму.
Надеюсь, я убедил вас, что числовой градиент – это действительно очень полезная штука для оценки, к тому же довольно простая. Но. Оказывается, мы можем еще больше, о чем и поговорим в следующей части.
