Здравствуйте, Хабр!
В ближайшее время читайте пост о русском переводе долгожданной книги "Создание Микросервисов" Сэма Ньюмена, которая уже отправилась в магазины. Пока же мы предлагаем почитать перевод статьи Аруна Гупты, автор которой описывает самые интересные паттерны проектирования, применимые в микросервисной архитектуре
Основные характеристики микросервисных приложений описаны в статье "Microservices, Monoliths and NoOps". Эти характеристики – функциональная декомпозиция или предметно-ориентированное проектирование, четко определенные интерфейсы, явно публикуемый интерфейс, принцип единственной обязанности и потенциальная многоязычность. Каждый сервис полностью автономный и полностековый. Соответственно, изменение реализации одного сервиса никак не сказывается на остальных, а обмен информацией происходит через четко определенные интерфейсы. У такого приложения есть ряд преимуществ, но они даром не даются, а требуют серьезной работы, связанной с NoOps.
Но предположим, что вы представляете себе масштаб этой работы, хотя бы частично, что вы действительно хотите создать такое приложение и посмотреть, что получится. Что же делать? Какова будет архитектура такого приложения?
Существуют ли паттерны проектирования, оптимизирующие взаимодействие микросервисов?

Для создания качественной микросервисной архитектуры необходимо четко разделить функции в вашем приложении и команде. Так можно достичь слабого связывания (REST-интерфейсы) и сильного сцепления (множество сервисов могут компоноваться вместе, определяя более высокоуровневые сервисы или приложение).
Создание «глаголов» (напр. Checkout) или «существительных» (Product) в составе приложения — один из эффективных способов декомпозиции имеющегося кода. Например, product, catalog и checkout могут быть реализованы как три отдельных микросервиса, а затем взаимодействовать друг с другом, обеспечивая полный функционал корзины заказов.
Функциональная декомпозиция обеспечивает гибкость, масштабируемость и прочие -ости, но наша задача – создать приложение. Итак, если отдельные микросервисы идентичны, как же скомпоновать их для реализации функционала приложения?
Об этом и пойдет речь в статье
Паттерн Агрегатор (Aggregator)
Первый и, пожалуй, наиболее распространенный паттерн проектирования при работе с микросервисами — «агрегатор».
В простейшей форме агрегатор представляет собой обычную веб-страницу, вызывающую множество сервисов для реализации функционала, требуемого в приложении. Поскольку все сервисы (Service A, Service B и Service C) предоставляются при помощи легковесного REST-механизма, веб-страница может извлечь данные и обработать/отобразить их как нужно. Если требуется какая-либо обработка, например, применить бизнес-логику к данным, полученным от отдельных сервисов, то для этого у вас может быть CDI-компонент, преобразующий данные таким образом, чтобы их можно было вывести на веб-странице.

Агрегатор может использоваться и в тех случаях, когда не требуется ничего отображать, а нужен лишь более высокоуровневый составной микросервис, который могут потреблять другие сервисы. В данном случае агрегатор просто соберет данные от всех отдельных микросервисов, применит к ним бизнес-логику, а далее опубликует микросервис как конечную точку REST. В таком случае, при необходимости, его смогут потреблять другие нуждающиеся в нем сервисы.
Этот паттерн следует принципу DRY. Если существует множество сервисов, которые должны обращаться к сервисам A, B и C, то рекомендуется абстрагировать эту логику в составной микросервис и агрегировать ее в виде отдельного сервиса. Преимущество абстрагирования на этом уровне заключается в том, что отдельные сервисы, скажем, A, B и C, могут развиваться независимо, а бизнес-логику будет по-прежнему выполнять составной микросервис.
Обратите внимание: каждый отдельный микросервис (опционально) имеет собственные уровни кэширования и базы данных. Если агрегатор – это составной микросервис, то и у него могут быть такие уровни.
Агрегатор также может независимо масштабироваться как по горизонтали, так и по вертикали. То есть, если речь идет о веб-странице, то к ней можно прикрутить дополнительные веб-серверы, а если это составной микросервис, использующий Java EE, то к нему прикручиваются дополнительные экземпляры WildFly, позволяющие удовлетворить растущие потребности.
Паттерн Посредник (Proxy)
Паттерн «посредник» при работе с микросервисами – это вариант агрегатора. В таком случае агрегация должна происходить на клиенте, но в зависимости от бизнес-требований при этом может вызываться дополнительный микросервис.
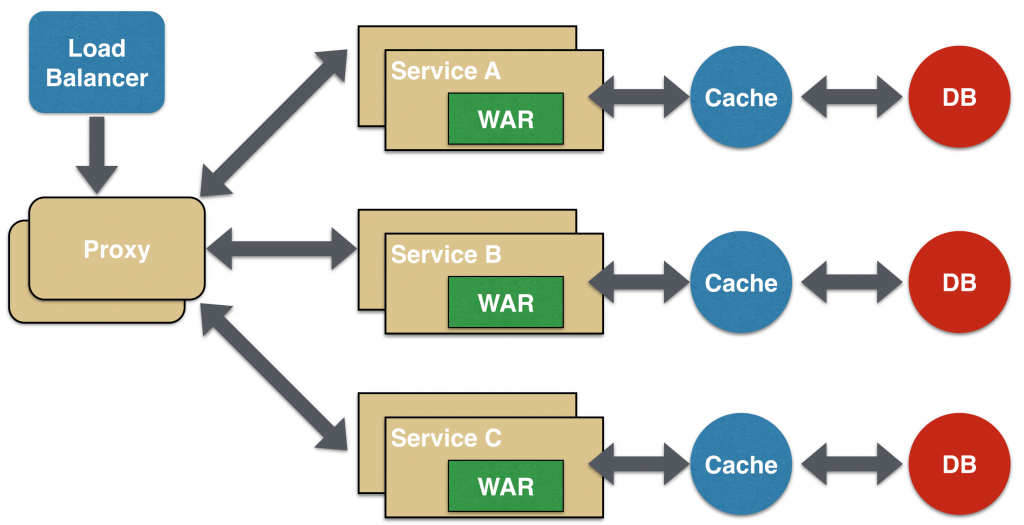
Как и агрегатор, посредник может независимо масштабироваться по горизонтали и по вертикали. Это может понадобиться в ситуации, когда каждый отдельный сервис нужно не предоставлять потребителю, а запускать через интерфейс.
Посредник может быть формальным (dumb), в таком случае он просто делегирует запрос одному из сервисов. Он может быть и интеллектуальным (smart), в таком случае данные перед отправкой клиенту подвергаются тем или иным преобразованиям. Например, уровень представления для различных устройств может быть инкапсулирован в интеллектуальный посредник.
Паттерн проектирования «Цепочка» (Chained)
Микросервисный паттерн проектирования «Цепочка» выдает единый консолидированный ответ на запрос. В данном случае сервис A получает запрос от клиента, связывается с сервисом B, который, в свою очередь, может связаться с сервисом C. Все эти сервисы, скорее всего, будут обмениваться синхронными сообщениями «запрос/отклик» по протоколу HTTP.

Здесь важнее всего запомнить, что клиент блокируется до тех пор, пока не выполнится вся коммуникационная цепочка запросов и откликов, т.е. Service <-> Service B и Service B <-> Service C. Запрос от Service B к Service C может выглядеть совершенно иначе, нежели от Service A к Service B. Аналогично, отклик от Service B к Service A может принципиально отличаться от отклика Service C к Service B. Это наиболее важно во всех случаях, когда бизнес-ценность нескольких сервисов суммируется.
Здесь также важно понять, что нельзя делать цепочку слишком длинной. Это критично, поскольку цепочка синхронна по своей природе, и чем она длиннее, тем дольше придется ожидать клиенту, особенно если отклик заключается в выводе веб-страницы на экран. Существуют способы обойти такой блокирующий механизм запросов и откликов, и они рассматриваются в следующем паттерне.
Цепочка, состоящая из единственного микросервиса, называется «цепочка-одиночка». Впоследствии ее можно расширить.
Паттерн проектирования «Ветка» (Branch)
Микросервисный паттерн проектирования «Ветка» расширяет паттерн «Агрегатор» и обеспечивает одновременную обработку откликов от двух цепочек микросервисов, которые могут быть взаимоисключающими. Этот паттерн также может применяться для вызова различных цепочек, либо одной и той же цепочки – в зависимости от ваших потребностей.

Сервис A, будь то веб-страница или составной микросервис, может конкурентно вызывать две различные цепочки – и в этом случае будет напоминать агрегатор. В другом случае сервис А может вызывать лишь одну цепочку в зависимости от того, какой запрос получит от клиента.
Такой механизм можно сконфигурировать, реализовав маршрутизацию конечных точек JAX-RS, в таком случае конфигурация должна быть динамической.
Паттерн «Разделяемые данные» (Shared Data)
Один из принципов проектирования микросервисов – автономность. Это означает, что сервис полностековый и контролирует все компоненты – пользовательский интерфейс, промежуточное ПО, сохраняемость, транзакции. В таком случае сервис может быть многоязычным и решать каждую задачу при помощи наиболее подходящих инструментов. Например, если при необходимости можно применить хранилище данных NoSQL, то лучше сделать именно так, а не забивать эту информацию в базу данных SQL.
Однако, типичная проблема, особенно при рефакторинге имеющегося монолитного приложения, связана с нормализацией базы данных — так, чтобы у каждого микросервиса был строго определенный объем информации, ни больше, ни меньше. Даже если в монолитном приложении используется только база данных SQL, ее денормализация приводит к дублированию данных, а возможно – и к несогласованности. На переходном этапе в некоторых приложениях бывает очень полезно применить паттерн «Разделяемые данные».
При этом паттерне несколько микросервисов могут работать о цепочке и совместно использовать хранилища кэша и базы данных. Это целесообразно лишь в случае, если между двумя сервисами существует сильная связь. Некоторые могут усматривать в этом антипаттерн, но в некоторых бизнес-ситуациях такой шаблон действительно уместен. Он определенно был бы антипаттерном в приложении, которое изначально создается как микросервисное.
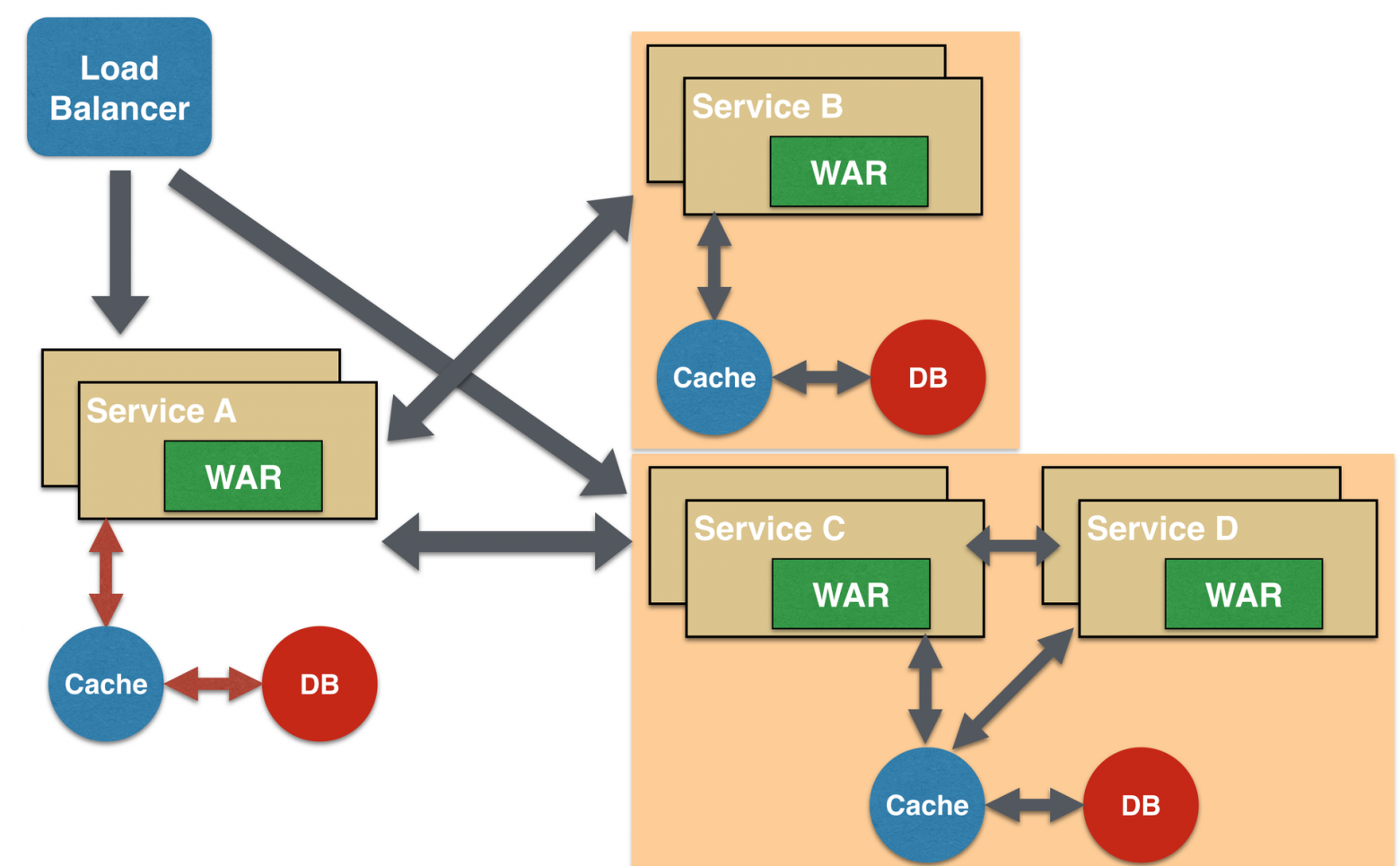
Кроме того, его можно рассматривать как промежуточный этап, который нужно преодолеть, пока микросервисы не станут полностью автономными.
Паттерн «Асинхронные сообщения» (Asynchronous Messaging)
При всей распространенности и понятности паттерна REST, у него есть важное ограничение, а именно: он синхронный и, следовательно, блокирующий. Обеспечить асинхронность можно, но это делается по-своему в каждом приложении. Поэтому в некоторых микросервисных архитектурах могут использоваться очереди сообщений, а не модель REST запрос/отклик.
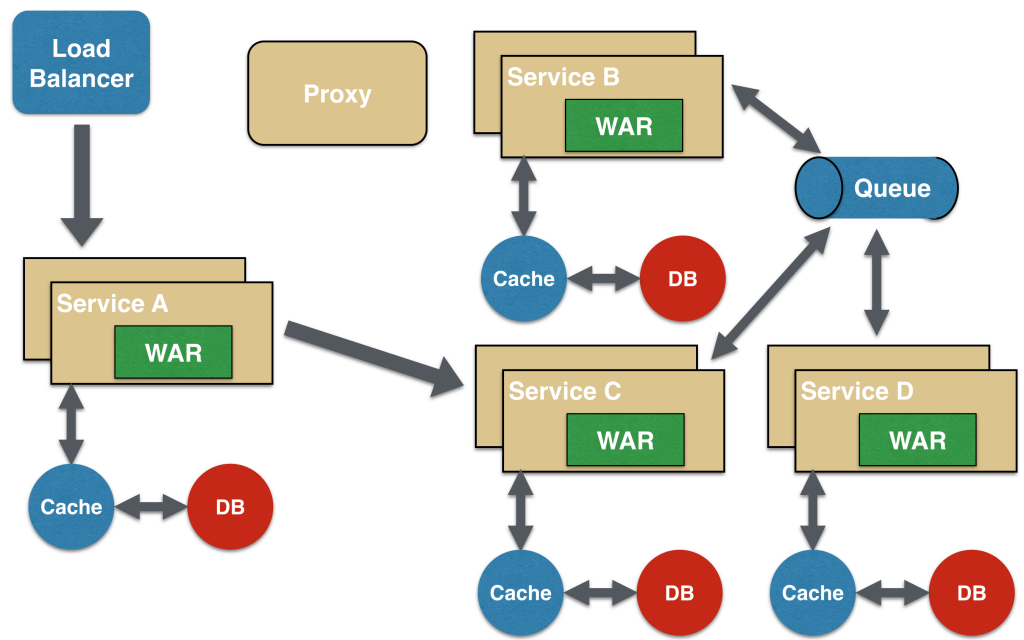
В этом паттерне сервис А может синхронно вызывать сервис C, который затем будет асинхронно связываться с сервисами B и В при помощи разделяемой очереди сообщений. Коммуникация Service A -> Service C может быть асинхронной, скажем, с использованием веб-сокетов; так достигается желаемая масштабируемость.
Комбинация модели REST запрос/отклик и обмена сообщениями публикатор/подписчик также могут использоваться для достижения поставленных целей.
Рекомендую также прочитать статью Coupling vs Autonomy in Microservices, в которой описано, какие паттерны коммуникации удобно применять с микросервисами.
В ближайшее время читайте пост о русском переводе долгожданной книги "Создание Микросервисов" Сэма Ньюмена, которая уже отправилась в магазины. Пока же мы предлагаем почитать перевод статьи Аруна Гупты, автор которой описывает самые интересные паттерны проектирования, применимые в микросервисной архитектуре
Основные характеристики микросервисных приложений описаны в статье "Microservices, Monoliths and NoOps". Эти характеристики – функциональная декомпозиция или предметно-ориентированное проектирование, четко определенные интерфейсы, явно публикуемый интерфейс, принцип единственной обязанности и потенциальная многоязычность. Каждый сервис полностью автономный и полностековый. Соответственно, изменение реализации одного сервиса никак не сказывается на остальных, а обмен информацией происходит через четко определенные интерфейсы. У такого приложения есть ряд преимуществ, но они даром не даются, а требуют серьезной работы, связанной с NoOps.
Но предположим, что вы представляете себе масштаб этой работы, хотя бы частично, что вы действительно хотите создать такое приложение и посмотреть, что получится. Что же делать? Какова будет архитектура такого приложения?
Существуют ли паттерны проектирования, оптимизирующие взаимодействие микросервисов?
Для создания качественной микросервисной архитектуры необходимо четко разделить функции в вашем приложении и команде. Так можно достичь слабого связывания (REST-интерфейсы) и сильного сцепления (множество сервисов могут компоноваться вместе, определяя более высокоуровневые сервисы или приложение).
Создание «глаголов» (напр. Checkout) или «существительных» (Product) в составе приложения — один из эффективных способов декомпозиции имеющегося кода. Например, product, catalog и checkout могут быть реализованы как три отдельных микросервиса, а затем взаимодействовать друг с другом, обеспечивая полный функционал корзины заказов.
Функциональная декомпозиция обеспечивает гибкость, масштабируемость и прочие -ости, но наша задача – создать приложение. Итак, если отдельные микросервисы идентичны, как же скомпоновать их для реализации функционала приложения?
Об этом и пойдет речь в статье
Паттерн Агрегатор (Aggregator)
Первый и, пожалуй, наиболее распространенный паттерн проектирования при работе с микросервисами — «агрегатор».
В простейшей форме агрегатор представляет собой обычную веб-страницу, вызывающую множество сервисов для реализации функционала, требуемого в приложении. Поскольку все сервисы (Service A, Service B и Service C) предоставляются при помощи легковесного REST-механизма, веб-страница может извлечь данные и обработать/отобразить их как нужно. Если требуется какая-либо обработка, например, применить бизнес-логику к данным, полученным от отдельных сервисов, то для этого у вас может быть CDI-компонент, преобразующий данные таким образом, чтобы их можно было вывести на веб-странице.
Агрегатор может использоваться и в тех случаях, когда не требуется ничего отображать, а нужен лишь более высокоуровневый составной микросервис, который могут потреблять другие сервисы. В данном случае агрегатор просто соберет данные от всех отдельных микросервисов, применит к ним бизнес-логику, а далее опубликует микросервис как конечную точку REST. В таком случае, при необходимости, его смогут потреблять другие нуждающиеся в нем сервисы.
Этот паттерн следует принципу DRY. Если существует множество сервисов, которые должны обращаться к сервисам A, B и C, то рекомендуется абстрагировать эту логику в составной микросервис и агрегировать ее в виде отдельного сервиса. Преимущество абстрагирования на этом уровне заключается в том, что отдельные сервисы, скажем, A, B и C, могут развиваться независимо, а бизнес-логику будет по-прежнему выполнять составной микросервис.
Обратите внимание: каждый отдельный микросервис (опционально) имеет собственные уровни кэширования и базы данных. Если агрегатор – это составной микросервис, то и у него могут быть такие уровни.
Агрегатор также может независимо масштабироваться как по горизонтали, так и по вертикали. То есть, если речь идет о веб-странице, то к ней можно прикрутить дополнительные веб-серверы, а если это составной микросервис, использующий Java EE, то к нему прикручиваются дополнительные экземпляры WildFly, позволяющие удовлетворить растущие потребности.
Паттерн Посредник (Proxy)
Паттерн «посредник» при работе с микросервисами – это вариант агрегатора. В таком случае агрегация должна происходить на клиенте, но в зависимости от бизнес-требований при этом может вызываться дополнительный микросервис.
Как и агрегатор, посредник может независимо масштабироваться по горизонтали и по вертикали. Это может понадобиться в ситуации, когда каждый отдельный сервис нужно не предоставлять потребителю, а запускать через интерфейс.
Посредник может быть формальным (dumb), в таком случае он просто делегирует запрос одному из сервисов. Он может быть и интеллектуальным (smart), в таком случае данные перед отправкой клиенту подвергаются тем или иным преобразованиям. Например, уровень представления для различных устройств может быть инкапсулирован в интеллектуальный посредник.
Паттерн проектирования «Цепочка» (Chained)
Микросервисный паттерн проектирования «Цепочка» выдает единый консолидированный ответ на запрос. В данном случае сервис A получает запрос от клиента, связывается с сервисом B, который, в свою очередь, может связаться с сервисом C. Все эти сервисы, скорее всего, будут обмениваться синхронными сообщениями «запрос/отклик» по протоколу HTTP.
Здесь важнее всего запомнить, что клиент блокируется до тех пор, пока не выполнится вся коммуникационная цепочка запросов и откликов, т.е. Service <-> Service B и Service B <-> Service C. Запрос от Service B к Service C может выглядеть совершенно иначе, нежели от Service A к Service B. Аналогично, отклик от Service B к Service A может принципиально отличаться от отклика Service C к Service B. Это наиболее важно во всех случаях, когда бизнес-ценность нескольких сервисов суммируется.
Здесь также важно понять, что нельзя делать цепочку слишком длинной. Это критично, поскольку цепочка синхронна по своей природе, и чем она длиннее, тем дольше придется ожидать клиенту, особенно если отклик заключается в выводе веб-страницы на экран. Существуют способы обойти такой блокирующий механизм запросов и откликов, и они рассматриваются в следующем паттерне.
Цепочка, состоящая из единственного микросервиса, называется «цепочка-одиночка». Впоследствии ее можно расширить.
Паттерн проектирования «Ветка» (Branch)
Микросервисный паттерн проектирования «Ветка» расширяет паттерн «Агрегатор» и обеспечивает одновременную обработку откликов от двух цепочек микросервисов, которые могут быть взаимоисключающими. Этот паттерн также может применяться для вызова различных цепочек, либо одной и той же цепочки – в зависимости от ваших потребностей.
Сервис A, будь то веб-страница или составной микросервис, может конкурентно вызывать две различные цепочки – и в этом случае будет напоминать агрегатор. В другом случае сервис А может вызывать лишь одну цепочку в зависимости от того, какой запрос получит от клиента.
Такой механизм можно сконфигурировать, реализовав маршрутизацию конечных точек JAX-RS, в таком случае конфигурация должна быть динамической.
Паттерн «Разделяемые данные» (Shared Data)
Один из принципов проектирования микросервисов – автономность. Это означает, что сервис полностековый и контролирует все компоненты – пользовательский интерфейс, промежуточное ПО, сохраняемость, транзакции. В таком случае сервис может быть многоязычным и решать каждую задачу при помощи наиболее подходящих инструментов. Например, если при необходимости можно применить хранилище данных NoSQL, то лучше сделать именно так, а не забивать эту информацию в базу данных SQL.
Однако, типичная проблема, особенно при рефакторинге имеющегося монолитного приложения, связана с нормализацией базы данных — так, чтобы у каждого микросервиса был строго определенный объем информации, ни больше, ни меньше. Даже если в монолитном приложении используется только база данных SQL, ее денормализация приводит к дублированию данных, а возможно – и к несогласованности. На переходном этапе в некоторых приложениях бывает очень полезно применить паттерн «Разделяемые данные».
При этом паттерне несколько микросервисов могут работать о цепочке и совместно использовать хранилища кэша и базы данных. Это целесообразно лишь в случае, если между двумя сервисами существует сильная связь. Некоторые могут усматривать в этом антипаттерн, но в некоторых бизнес-ситуациях такой шаблон действительно уместен. Он определенно был бы антипаттерном в приложении, которое изначально создается как микросервисное.
Кроме того, его можно рассматривать как промежуточный этап, который нужно преодолеть, пока микросервисы не станут полностью автономными.
Паттерн «Асинхронные сообщения» (Asynchronous Messaging)
При всей распространенности и понятности паттерна REST, у него есть важное ограничение, а именно: он синхронный и, следовательно, блокирующий. Обеспечить асинхронность можно, но это делается по-своему в каждом приложении. Поэтому в некоторых микросервисных архитектурах могут использоваться очереди сообщений, а не модель REST запрос/отклик.
В этом паттерне сервис А может синхронно вызывать сервис C, который затем будет асинхронно связываться с сервисами B и В при помощи разделяемой очереди сообщений. Коммуникация Service A -> Service C может быть асинхронной, скажем, с использованием веб-сокетов; так достигается желаемая масштабируемость.
Комбинация модели REST запрос/отклик и обмена сообщениями публикатор/подписчик также могут использоваться для достижения поставленных целей.
Рекомендую также прочитать статью Coupling vs Autonomy in Microservices, в которой описано, какие паттерны коммуникации удобно применять с микросервисами.
