Всем привет! Это первая статья из цикла про разработку приложений в «ПМ».
Мы занимаемся не только информационной безопасностью в классическом представлении (мониторинг узлов, поиск уязвимостей исходного кода и т.п.), кроме этого у нас есть несколько других проектов, так или иначе связанных с ИБ. Почти все наши проекты объединяет одно — общая архитектура обработки данных. В рамках этого пула статей хотелось бы поделиться нашими наработками, услышать мнение разработчиков с бо́льшим опытом и просто помочь новичкам, которые могут почерпнуть для себя что-то новое и интересное.
Введение
Часть наших проектов — многопользовательские клиент-серверные приложения. Их специфика схожа:
Обработка запроса пользователя на совершение какого-либо действия
Проверка возможности данного пользователя выполнить данное действие
Расшаривание результатов обработки запроса остальным причастным пользователям
Данный процесс выглядит стандартным для большинства проектов, но имеет достаточно много путей реализации в зависимости от используемых инструментов. В данной статье хотелось бы рассказать о том, к чему пришли мы проходя и перепроходя этот путь несколько раз.
Стэк
Основной стэк, используемый в проектах, достаточно стандартный: Django + Vue. Кроме этого из основных пакетов:
Сервер:
DjangoRestFramework — всем известный фреймворк для создания API
drf-rw-serializers — библиотека, позволяющая представлениям использовать несколько сериализаторов (чтение/запись)
channels — использование технологии WebSocket внутри Django приложения
Клиент:
Pinia — глобальное состояние клиентской части приложения
vue-native-websocket — простой и удобный инструмент для обработки сообщений, полученных по каналу WS.
Axios — Отправка API запросов на сервер.
Кроме этого используется ещё много разных библиотек, но все они зависят от проекта. Указанные же библиотеки — это необходимый минимум, с помощью которого можно выстроить наш подход к обработке запроса.
Путь
Изначально наши проекты не были похожи друг на друга — разные команды, каждая из которых видела и реализовывала функционал по-своему: кто-то проверял права в специальных классах DRF, некоторые занимались реализацией бизнес логики внутри представлений. А кто-то даже держал логику в сериализаторах.
Каждый из этих подходов имеет место быть, также как и каждый из них со временем заставляет страдать:
Проверка возможности совершения действия внутри классов DRF
Представьте, вы сделали свой первый проект — блог. Суть проекта проста: есть авторы и статьи, авторы могут читать любые опубликованные статьи, писать/изменять и публиковать свои собственные. Ролевая модель тоже достаточно простая: читать можно всё, изменять только своё.
Пока у проекта только один интерфейс взаимодействия: API. Все проверки прав реализованы на уровне представлений, всё по инструкции DRF. Проект становится настолько успешным, что авторы хотят быть онлайн 24/7. Появляется необходимость дать пользователям возможность работать с приложением через новый интерфейс — сделать мобильное приложение или использовать тот же telegram. Вы сделали бота, научились сопоставлять локальных пользователей с пользователями платформы, добавили в бота много красивых кнопочек. На сервер приходит первое сообщение из telegram — кто-то захотел обновить название статьи. Теперь нужно проверить, есть ли у пользователя права на изменение запрошенной статьи. Проверка прав в проекте реализована внутри класса DRF, казалось бы — создаем экземпляр класса и вызываем нужный метод, но не всё так просто — классы прав в DRF завязаны на объект request, специфичный для API интерфейса. Другой вариант — дублировать логику проверки прав в каждом новом интерфейсе. О минусах такого подхода думаю не нужно много говорить, но самое очевидное — это сложно поддерживать.
Реализация бизнес-логики внутри представления
Минусы реализации логики внутри методов/классов представлений в целом те же самые, что и у проверки прав внутри представлений — сложность (а иногда и невозможность) переиспользования кода.
Логика в сериализаторах
Сериализаторы DRF — очень мощная штука, когда находятся в правильных руках. Они позволяют очень быстро описать методы создания (
create), обновления (update) сущностей. В простом проекте-блоге этого может быть достаточно, но все проекты рано или поздно развиваются, логика становится сложнее, а технологии меняются. Если появится необходимость заменить DRF сериализаторы на что-то другое (Pydantic/dataclass/что-то своё) — логику придется переносить.
Основная мысль, к которой мы пришли — не стоит завязывать логику своего приложения на сторонние библиотеки. Лучше, когда ваше приложение может быть легко портировано на любой другой стэк полностью или частично.
В двух словах
Наши приложения достаточно интерактивны — один пользователь вносит изменения, все остальные сразу видят обновленное состояние. Чтобы лучше понять за счёт чего это происходит, необходимо понять то, как мы работаем с данными:
Каждый пользователь подключается к web socket после авторизации. Каждым таким подключением управляет специальный класс Consumer.
Сразу после подключения к сокету пользователь получает минимально необходимый набор данных. Набор этих данных очень сильно зависит от самого приложения.
Клиентское приложение раскладывает полученные данные по модулям состояния.
Пользователь совершает API вызов для совершения какого-либо действия, например обновление статьи блога.
Сервер обрабатывает запрос пользователя и отправляет сигнал о совершенном действии:
post_updated.send(sender=Post, post=post).Клиентское приложение получает ответ от сервера (
response), но в 95% случаев игнорирует результат (кроме обработки ошибок).Вместе с ответом (
response) по WS каналу приходит сообщение о совершенном действии:{ "event": "post_updated", "data": {"id": 12, "title": "My first post", "text": "Lorem"} }.Обработчик WS сообщений вызывает
actionpost_updatedнужного модуля состояния, а тот, в свою очередь, обновляет данные состояния.
Таким образом, каждый экземпляр приложения получит сообщение об изменении поста, а реактивное клиентское приложение выполнит перерисовку страницы на основе новых данных состояния.
Чтобы понимать, что такое "каждый экземпляр", нужно понимать, как работают группы
WS в channels. Это может быть только 1 пользователь в нескольких вкладках браузера, множество людей, которые работают с данным объектом в данный момент или вообще все пользователи приложения.Вообще, понимание того, какие Ws группы должны быть в проекте — первый шаг к успеху. Минимально необходимый набор — группа пользователя (
user_<user_id>) и общая группа для всех пользователей (all). Первая группа нужна для отправки сообщений в сокет конкретного пользователя, вторая для сообщений, которые необходимо отправить каждому пользователю.
В картинках
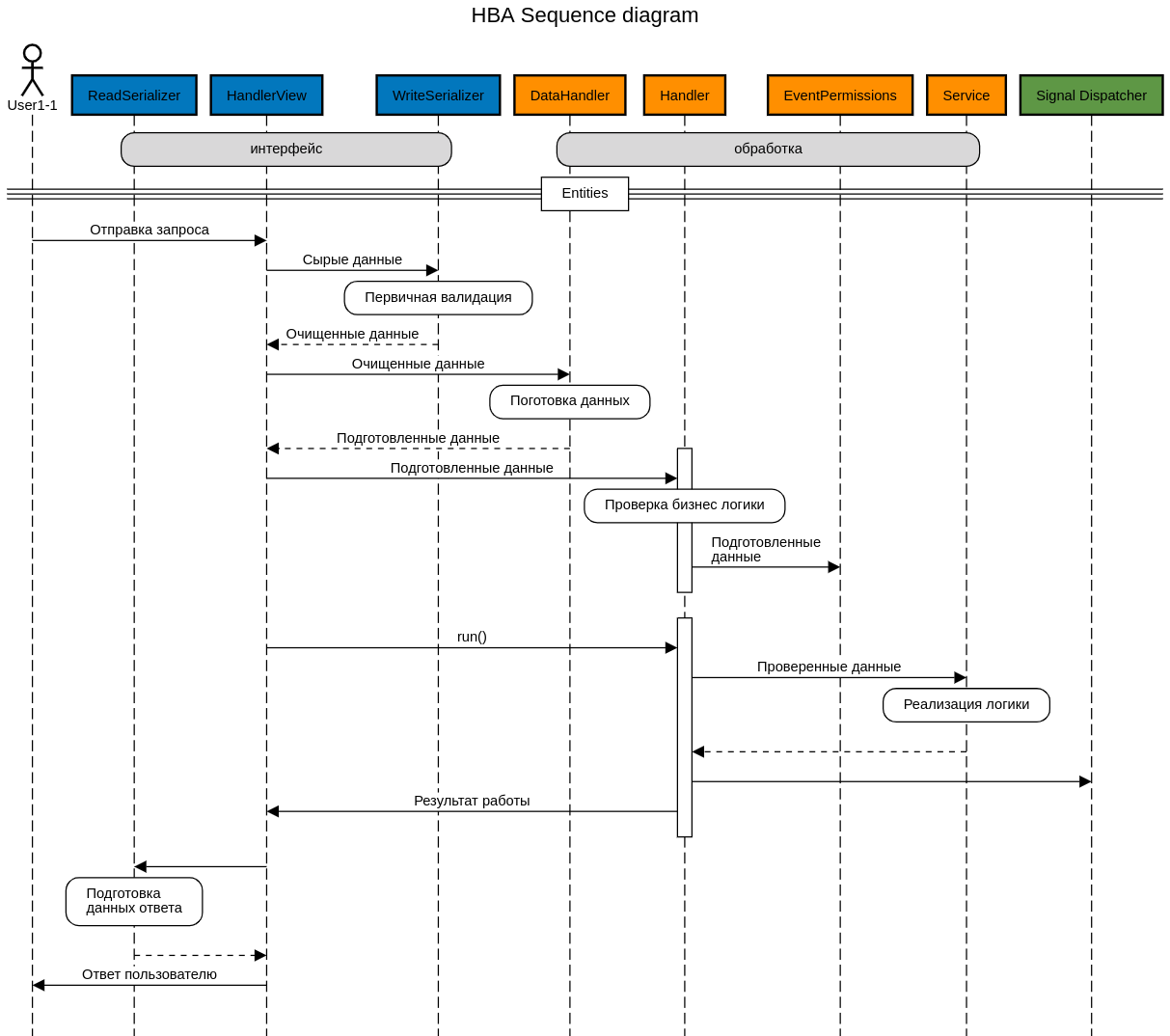
В трёх словах
Сложно рассказать обо всем, что у нас получилось, в рамках одной статьи. Здесь же хочется описать логику работы крупными штрихами. Всё описание будет касаться того же проекта-блога, чтобы было понятнее.
Первое, что происходит — это запрос пользователя на совершение действия, например, изменение статьи: PATCH /api/v1/posts/12/
Внутренности django/DRF
В данной статье мы не будем разбирать то, как запрос попадает к нам в представление. Это очень интересно и полезно знать, но эта статья о другом.
Итак, запрос попал в представление, каждое из которых представляет из себя нечто такое:
@extend_schema(tags=["Posts"])
class PostView(HandlerView):
@extend_schema(
request=WriteUpdatePostSerializer,
responses={
status.HTTP_200_OK: ReadPostSerializer,
...
},
)
def patch(self, request, *args, **kwargs):
""" Изменение записи в блоге """
self.response_code = status.HTTP_200_OK
self.serializer_class = WriteUpdatePostSerializer
self.read_serializer_class = ReadPostSerializer
self.error_text = _("Update post error")
self.handler = UpdatePostHandler
return self.handle()
# Обработка остальных HTTP операций убрана, чтобы не путать читателей =)Всё, что делает каждое новое представление — установка необходимых атрибутов обработки запроса:
response_code— код успешной обработки запроса. Есть несколько вариантов оповещения об успешности выполнения: сервер может всегда отвечать кодом 200 (сервер успешно обработал запрос) и содержать внутри тела ответа json, внутри которого будут ключи success, error, по которым клиентское приложение и поймет, всё ли ОК. Другой вариант — использовать стандартные HTTP коды для оповещения. Мы остановились на втором варианте.serializer_class— класс-обработчик входящих данных. В нем всего лишь описаны поля, их обязательность и типы. Всё, что требуется от этого сериализатора — проверить наличие обязательных атрибутов в запросе, привести типы.read_serializer_class— класс, необходимый для сериализации ответа. Тут нет ничего необычного, стандартная логика.error_text— все мы люди и нам свойственно ошибаться. Каждое необработанное исключение в коде приведет к тому, что в ответ улетит данное сообщение со статусом HTTP 500.handler— одна из основных рабочих единиц наших проектов. Внутри этого класса происходит вся обработка действия пользователя.
На последней строке метода patch нашего представления происходит вызов метода handle родительского класса. Внутри этого метода происходит много интересного:
Подготовка данных через write сериализатор
Обычно эти сериализаторы заточены под конкретный API метод и содержат в себе все атрибуты, которые могут прийти с запросом:
class WriteUpdatePostSerializer(serializers.Serializer): title = serializers.CharField(max_length=POST_NAME_MAX_LENGTH, label=_("Post title"), required=False) text = serializers.CharField(max_length=POST_TEXT_MAX_LENGTH, label=_("Post text") required=False) is_draft = serializers.BooleanField(required=False, label=_("Is draft"))Кроме атрибутов сериализатора, запрос содержит дополнительные данные — объект пользователя и идентификатор поста, который хочет обновить пользователь. Все эти данные собираются в один словарь:
{ "user": <User: ivanov>, "post_id": 12, "text": "Lorem ipsum dolor sit amet", }Преобразование данных. На этом этапе происходит получение объектов связанных с запросом из БД с помощью специального класса, указанного в классе-обработчике. Данный класс довольно большой и сложный, чтобы уместить его описание в статье. Но он достаточно хорошо описан по ссылке в репозитории.
После работы класса подготовки данных, наш словарь приобретает вид:
{ "user": <User: ivanov>, "post": <Post: My first post>, "text": "Lorem ipsum dolor sit amet", }Вы можете справедливо заметить, что лучше сначала проверить права на все объекты, которые участвуют в запросе, и только после этого получать все объекты из БД. В одной из первых итераций так и было, сначала работал класс проверки прав:
def _check_update_post(self): post_id: int = self.data.get("post_id") return Post.objects.filter(id=post_id, author=self.user).exists()Данная проверка возвращала
False, когда объект отсутствовал в БД. В результате этого класс проверки прав порождалPermissionsDeniedошибку и пользователь получал уведомление, что не имеет прав на данный объект.У каждого варианта (пост проверка или пред проверка) есть свои плюсы и минусы. Мы остановились на первом варианте исключительно для того, чтобы не вводить пользователя в заблуждение неверными причинами отказа выполнения запроса.
Следующий шаг — вызов класса-обработчика действия, указанного в представлении. Основная задача этих классов — проверка требований бизнес-логики приложения, проверка права пользователя на совершение действия, вызов сервиса, реализующего бизнес логику и отправка сигнала о совершенном действии. Обработчик нашего действия по обновлению статьи может выглядеть так:
class UpdatePostHandler(BaseHandler, SignalMixin):
signal = post_updated
signal_sender = Post
@check_permissions(event_code=Events.UPDATE_POST)
def __init__(self, user: User, post: Post, title: str, text: str,
is_draft: bool):
self.user: User = user
self.post: Post = post
self.check_is_draft()
self.title: str = title
self.text: str = text
self.is_draft: bool = is_draft
def check_is_draft(self):
if not self.post.is_draft:
raise self.exception("Нельзя обновить опубликованную запись")
def run(self) -> Post:
service: UpdatePostService = UpdatePostService()
result: Union[Ok, Error] = service(
post=self.post,
title=self.title,
text=self.text,
is_draft=self.is_draft,
)
if result.is_error():
raise self.exception(result.error)
self._send_signal(post=self.post)
return self.post
Всё довольно просто — метод __init__ принимает данные, сохраняет их на уровне экземпляра класса. Также внутри метода инициализации происходит проверка, что бизнес-логика приложения не нарушена — вызов метода check_is_draft. Этот метод может породить ошибку в случае, когда пользователь пытается обновить уже опубликованный пост. Вот такой у нас блог ;)
После того, как метод инициализации закончил работу, в работу вступает класс, скрытый за декоратором check_permissions — его задача определить, есть ли у пользователя user права на совершение действия Events.UPDATE_POST над объектом post. Класс проверки прав так же порождает ошибку, если нарушены права.
После всех проверок, базовый класс представления вызывает у класса-обработчика общий метод всех обработчиков, метод run. Его задача — вызвать сервис, обработать результат, отправить сигнал и вернуть объект, который улетит обратно по интерфейсу взаимодействия (если необходимо).
Далее поток обработки запроса попадает в сервис. Мы реализуем сервисы как обычные классы с одним отличием: каждый метод такого класса выполняется в строгом порядке до тех пор, пока все методы не выполнятся или любой из них не сообщит об ошибке:
class UpdatePostService(ServiceObject):
def update(self, context):
post: Post = context.post
for attr, value in context.params.items():
setattr(post, attr, value)
post.save()
return self.success()
@transactional
def __call__(self, post: Post, **kwargs) -> Union[Ok, Error]:
return self.success(post=post, params=kwargs) | self.update
Сервис обновления записи блога очень простой, он содержит всего 1 метод — обновление объекта в БД. Но для понимания общей логики работы этого должно быть достаточно.
После завершения работы сервиса поток возвращается в класс-обработчик, который проверяет результат: это может быть объект класса Ok (успешная работа сервиса) или Error (есть ошибки при выполнении). Если сервис завершился с ошибкой, обработчик порождает исключение с текстом, которое вернул сервис. Иначе — обработчик отправляет сигнал об изменении записи блога и возвращает обновленный объект.
Сигналы. Зачем они нужны? С помощью сигналов мы реализуем дополнительную логику, связанную с совершением события.
Важно понимать, что такое дополнительная логика. Это логика, не связанная с задачей напрямую.
В нашем запросе на обновление поста блога дополнительная логика заключается в отправке в WS канал обновленного объекта поста, уведомлении модератора блога об изменениях и т.п.
Обработчиков у сигнала может быть сколько угодно, важно помнить, что они не должны быть зависимыми друг от друга и не должна быть важна последовательность работы этих обработчиков.
Дальнейшая жизнь запроса — сериализация ответа класса-обработчика и отправка пользователю HTTP Response. На этом серверная часть обработки запроса завершается.
Клиент
Ответ от сервера попадает в клиентскую часть приложения. Здесь мы используем общий метод обработки стандартных ошибок, которые могут произойти:
HTTP 400 — либо нарушена логика, либо в данных есть ошибка. Текст ошибки передается внутри ответа, его мы и показываем пользователю в уведомлении.
HTTP 401 — уведомляем пользователя о том, что необходимо авторизоваться и перенаправляем на страницу авторизации.
HTTP 403 — у пользователя не достаточно прав на выполнение действия.
HTTP 500 — просто показываем пользователю, что произошла ошибка обработки запроса, а сами идём в Sentry смотреть что произошло =)
В любом из этих случаев ответ от сервера содержит сообщение, которое мы показываем пользователю. Обычно от кода статуса зависит только цвет уведомления.
Как уже говорилось ранее, на успешные коды HTTP 2XX приложение не реагирует. В этот момент мы просто понимаем, что наше действие было успешно обработано, а новые данные будут получены по WS каналу.
Каждое сокет сообщение обрабатывается отдельной библиотекой, задача которой вызвать нужный action нужного модуля состояния. Так наше сообщение попадает в метод:
SOCKET_post_updated(data) {
const items = this.posts
const index = items.findIndex((item) => data.id === item.id)
if (index !== -1) {
const stored = items[index]
this.posts[index] = { ...stored, ...data }
}
}Тут всё стандартно: ищем элемент в списке всех элементов, если находим — объединяем 2 объекта и обновляем состояние. После обновления состояния изменяется UI нашего приложения, это работает из коробки в современных реактивных frontend фреймворках.
Итог
В том, как работают наши приложения, нет ничего сложно, сверхнового и необычного. Все описанные сущности (классы/методы) обработки запроса являются вполне обычными вещами, которыми все пользуются каждый день при разработке.
Важны плюсы, которые мы получаем, когда придерживаемся несложных правил при написании приложения:
Высокая интерактивность приложения, где каждый участник видит изменения данных сразу после совершения действия.
Простота реализации новой фичи — каждый новый разработчик не будет думать, где расположить проверку прав или реализацию бизнес-логики. Для каждого действия есть своё четкое место.
Чистый, структурированный код. Потребуется совсем немного времени, чтобы найти логику обработки конкретного запроса.
Низкая связанность с фреймворком. Благодаря тому, что проверка прав и реализация логики расположена в нашем коде, перенести эту логику на другой стэк не станет большой проблемой.
Благодаря стандартизированному интерфейсу взаимодействия по WS появляется возможность описания методов сокета внутри Swagger документации.

Все наши наработки по описанной архитектуре мы собрали в небольшой boilerplate, расположенный на github. В нём есть более детальное описание используемых сущностей. Также есть скрипт, который поможет создать новое приложение на основе наших подходов.
Спасибо за внимание!
