Мы все любим Ansible, но Ansible – это YAML. Для конфигурационных файлов существует масса форматов: списки значений, пары «параметр-значение», INI-файлы, YAML, JSON, XML и множество других. Однако по нескольким причинам из всех них YAML часто считается особенно трудным. В частности, несмотря на его освежающий минимализм и впечатляющие возможности для работы с иерархическими значениями, синтаксис YAML может раздражать своим Python-образными подходом к отступам.

Если вас бесит YAML, вы можете – и должны! – предпринять 10 следующих шагов, чтобы снизить свое раздражение до приемлемого уровня и полюбить YAML. Как и положено настоящему списку, наша десятка советов будет нумероваться с нуля, медитацию и духовные практики добавляем по желанию ;-)
Неважно, какой у вас текстовый редактор – для него наверняка существует хотя бы один плагин для работы с YAML. Если у вас такого нет, немедленно найдите и установите. Потраченное на поиск и настройку время будет многократно окупаться каждый раз, когда вам придется редактировать YAML.
Например, редактор Atom поддерживает YAML по умолчанию, а вот для GNU Emacs придется установить дополнительные пакеты, например, yaml-mode.

Emacs в режиме YAML и отображения пробелов.
Если в вашем любимом редакторе нет режима YAML, то часть проблем можно решить, поработав с настройками. Например, штатный для GNOME текстовый редактор Gedit не имеет режима YAML, но по умолчанию подсвечивает синтаксис YAML и позволяет настроить работу с отступами:

Настройка отступов в Gedit.
А плагин drawspaces для Gedit отображает пробелы в виде точек, устраняя неясности с уровнями отступа.
Иными словами, потратьте время на изучение своего любимого редактора. Выясните, что он сам или его сообщество разработки предлагают для работы с YAML, и используйте эти возможности. Вы точно об этом не пожалеете.
В идеале языки программирования и языки разметки используют предсказуемый синтаксис. Компьютеры хорошо справляются с предсказуемостью, поэтому еще в 1978 году возникла концепция линтера. Если за 40 лет своего существования она прошла мимо вас и вы до сих пор не пользуетесь YAML-линтером, то самое время попробовать yamllint.
Установить yamllint можно с помощью штатного менеджера пакетов Linux. Например, в Red Hat Enterprise Linux 8 или Fedora это делается так:
Затем вы просто запускаете yamllint, передавая ему YAML-файл для проверки. Вот как это выглядит, если передать линтеру файл с ошибкой:
Цифры слева – это не время, а координаты ошибки: номер строки и столбца. Описание ошибки может вам ни о чем не говорить, зато вы точно знаете, где она находится. Просто посмотрите на это место в коде, и, скорее всего, все станет ясно.
Когда yamllint не находит ошибок в файле, на экран ничего не выводится. Если вас пугает такая тишина и хочется немного больше обратной связи, то можно запускать линтер с условной командой echo через двойной амперсанд (&&), вот так:
В POSIX двойной амперсанд срабатывает тогда и только тогда, когда предшествующая команда возвращает 0. А yamllint как раз возвращает количество найденных ошибок, поэтому вся эта условная конструкция и работает.
Если вас реально бесит YAML, просто не пишите на нем, в буквальном смысле. Бывает, что YAML – это единственный формат, который воспринимается приложением. Но и в этом случае необязательно создавать YAML-файл. Пишите на том, что вам нравится, а потом конвертируйте. Например, для Python есть отличная библиотека pyyaml и целых два способа конвертирования: самоконвертирование и конвертирование через скрипты.
В этом случае файл с данными заодно является и Python-скриптом, который генерирует YAML. Этот способ лучше всего подходит для небольших наборов данных. Вы просто пишите JSON-данные в переменную Python, предваряете это директивой import, а в конце файла добавляете три строчки для реализации вывода.
Теперь запускаем это файл на Python-е и на выходе получаем файл output.yaml:
Это абсолютно корректный YAML, но yamllint выдаст предупреждение, что он не начинается с ---. Что ж, это можно легко поправить вручную или слегка доработать Python-скрипт.
В этом случае сначала пишем на JSON-е, а затем запускаем конвертор в виде отдельного Python-скрипта, который на выходе дает YAML. По сравнению с предыдущим этот способ лучше масштабируется, поскольку конвертирование отделено данных.
Для начала создадим JSON-файл example.json, например, его можно взять на json.org:
Затем создадим простой скрипт-конвертор и сохраним его под именем json2yaml.py. Этот скрипт импортирует оба модуля — YAML и JSON Python, а также загружает указанный пользователем файл JSON, выполняет конвертирование и пишет данные в файл output.yaml.
Сохраните этот скрипт в system path и запускайте по мере необходимости:
Иногда на проблему полезно взглянуть под другим углом. Если вам трудно представить взаимосвязи между данными в YAML, можно временно преобразовать их в нечто более привычное.
Например, если вам удобно работать со словарными списками или с JSON, то YAML можно преобразовать в JSON всего двумя командами в интерактивной оболочке Python. Допустим, у вас есть YAML-файл mydata.yaml, тогда вот как это будет выглядеть:
На эту тему можно найти массу других примеров. Кроме того, в наличии множество онлайн-конвертеров и локальных парсеров. Так что не стесняйтесь переформатировать данные, когда видите в них только непонятную мешанину.
Возвращаясь к YAML после долгого перерыва, полезно зайти на yaml.org и перечитать спецификации (спеки). Если у вас трудности с YAML, но до спецификации руки так и не дошли, то пора эту ситуацию исправлять. Спеки на удивление легко написаны, а требования к синтаксису иллюстрируются большим количеством примеров в Главе 6.
При написании книги или статьи всегда полезно сперва набросать предварительный план, хотя бы в виде оглавления. Так же и с YAML. Скорее всего, вы представляете, какие данные надо записать в файл YAML, но не очень понимаете, как связать их друг с другом. Поэтому прежде чем ваять YAML, нарисуйте псевдоконфиг.
Псевдоконфиг похож на псевдокод, где не надо заботиться о структуре или отступах, отношениях «родитель-потомок», наследовании и вложенности. Так и здесь: вы рисуете итерации данных по мере того, как они возникают у вас в голове.

Псевдоконфиг с перечислением программистов (Martin и Tabitha) и их навыков (языков программирования: Python, Perl, Pascal и Lisp, Fortran, Erlang, соответственно).
Нарисовав псевдоконфиг на листе бумаги, внимательно проанализируйте его и, если все в порядке, оформите в виде валидного YAML-файла.
Вам придется решить дилемму «табуляция или пробелы?». Не в глобальном смысле, а лишь на уровне вашей организации, или хотя бы проекта. Неважно, будет ли при этом использоваться пост-обработка скриптом sed, настройка текстовых редакторов на машинах программистов или же поголовное взятие расписок о строгом соблюдении указаний линтера под угрозой увольнения, но все члены вашей команды, которые так или иначе касаются YAML, в обязательном порядке должны использовать только пробелы (как того требует спецификация YAML).
В любом нормальном текстовом редакторе можно настроить автозамену табуляции на заданное количество пробелов, поэтому бунта приверженцев клавиши Tab можно не бояться.
Как хорошо известно каждому ненавистнику YAML, на экране не видно разницы между табуляцией и пробелами. А когда чего-то не видно, об этом, как правило, вспоминают в последнюю очередь, после того, как перебрали, проверили и устранили все остальные возможные проблемы. Час времени, убитый на поиск кривой табуляции или блока пробелов, просто вопиет о том, что вам над срочно создать политику использования того или другого, а затем реализовать железобетонную проверку ее соблюдения (например, через Git-хук для принудительного прогона через линтер).
Некоторые люди любят писать на YAML, поскольку он подчеркивает структуру. При этом они активно используют отступы, чтобы выделять блоки данных. Это такое своего рода жульничество для имитации языков разметки, в которых используются явные разделители.
Вот пример такой структурированности из документации Ansible:
Кому-то такой вариант помогает разложить в голове структуру YAML, других он наоборот раздражает массой ненужных, на их взгляд, отступов.
Но если вы являетесь владельцем YAML-документа и отвечаете за его сопровождение, то вы и только вы должны определять, как использовать отступы. Если вас раздражают большие отступы, сведите их к минимуму, который только возможен согласно спецификации YAML. Например, вышеприведенный файл из документации Ansible без каких бы то ни было потерь можно переписать вот так:
Если при заполнении файла YAML вы постоянно повторяете одни и те же ошибки, имеет смысл вставить в него шаблон-заготовку в виде комментария. Тогда в следующий раз можно будет просто скопировать эту заготовку и вписать туда реальные данные, например:
Если приложение не держит вас мертвой хваткой, то, возможно, стоит сменить YAML на другой формат. Со временем конфигурационные файлы могут перерастать себя и тогда лучше преобразовать их в простые скрипты на Lua или Python.
YAML – отличная штука, которую многие любят за минимализм и простоту, но это далеко не единственный инструмент в вашем арсенале. Так что иногда от него можно отказаться. Для YAML легко найти библиотеки парсинга, поэтому, если вы предложите удобные варианты миграции, ваши пользователи относительно безболезненно переживут такой отказ.
Если же без YAML никак не обойтись, то возьмите на вооружение эти 10 советов и победите свою неприязнь к YAML раз и навсегда!

Если вас бесит YAML, вы можете – и должны! – предпринять 10 следующих шагов, чтобы снизить свое раздражение до приемлемого уровня и полюбить YAML. Как и положено настоящему списку, наша десятка советов будет нумероваться с нуля, медитацию и духовные практики добавляем по желанию ;-)
0. Заставьте ваш редактор работать
Неважно, какой у вас текстовый редактор – для него наверняка существует хотя бы один плагин для работы с YAML. Если у вас такого нет, немедленно найдите и установите. Потраченное на поиск и настройку время будет многократно окупаться каждый раз, когда вам придется редактировать YAML.
Например, редактор Atom поддерживает YAML по умолчанию, а вот для GNU Emacs придется установить дополнительные пакеты, например, yaml-mode.
Emacs в режиме YAML и отображения пробелов.
Если в вашем любимом редакторе нет режима YAML, то часть проблем можно решить, поработав с настройками. Например, штатный для GNOME текстовый редактор Gedit не имеет режима YAML, но по умолчанию подсвечивает синтаксис YAML и позволяет настроить работу с отступами:
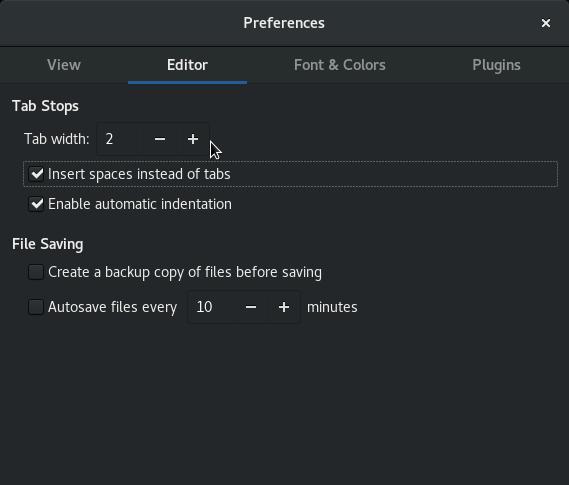
Настройка отступов в Gedit.
А плагин drawspaces для Gedit отображает пробелы в виде точек, устраняя неясности с уровнями отступа.
Иными словами, потратьте время на изучение своего любимого редактора. Выясните, что он сам или его сообщество разработки предлагают для работы с YAML, и используйте эти возможности. Вы точно об этом не пожалеете.
1. Используйте линтер (linter)
В идеале языки программирования и языки разметки используют предсказуемый синтаксис. Компьютеры хорошо справляются с предсказуемостью, поэтому еще в 1978 году возникла концепция линтера. Если за 40 лет своего существования она прошла мимо вас и вы до сих пор не пользуетесь YAML-линтером, то самое время попробовать yamllint.
Установить yamllint можно с помощью штатного менеджера пакетов Linux. Например, в Red Hat Enterprise Linux 8 или Fedora это делается так:
$ sudo dnf install yamllint
Затем вы просто запускаете yamllint, передавая ему YAML-файл для проверки. Вот как это выглядит, если передать линтеру файл с ошибкой:
$ yamllint errorprone.yaml
errorprone.yaml
23:10 error syntax error: mapping values are not allowed here
23:11 error trailing spaces (trailing-spaces)
Цифры слева – это не время, а координаты ошибки: номер строки и столбца. Описание ошибки может вам ни о чем не говорить, зато вы точно знаете, где она находится. Просто посмотрите на это место в коде, и, скорее всего, все станет ясно.
Когда yamllint не находит ошибок в файле, на экран ничего не выводится. Если вас пугает такая тишина и хочется немного больше обратной связи, то можно запускать линтер с условной командой echo через двойной амперсанд (&&), вот так:
$ yamllint perfect.yaml && echo "OK"
OK
В POSIX двойной амперсанд срабатывает тогда и только тогда, когда предшествующая команда возвращает 0. А yamllint как раз возвращает количество найденных ошибок, поэтому вся эта условная конструкция и работает.
2. Пишите на Python, а не на YAML
Если вас реально бесит YAML, просто не пишите на нем, в буквальном смысле. Бывает, что YAML – это единственный формат, который воспринимается приложением. Но и в этом случае необязательно создавать YAML-файл. Пишите на том, что вам нравится, а потом конвертируйте. Например, для Python есть отличная библиотека pyyaml и целых два способа конвертирования: самоконвертирование и конвертирование через скрипты.
Самоконвертирование
В этом случае файл с данными заодно является и Python-скриптом, который генерирует YAML. Этот способ лучше всего подходит для небольших наборов данных. Вы просто пишите JSON-данные в переменную Python, предваряете это директивой import, а в конце файла добавляете три строчки для реализации вывода.
#!/usr/bin/python3
import yaml
d={
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}
f=open('output.yaml','w')
f.write(yaml.dump(d))
f.close
Теперь запускаем это файл на Python-е и на выходе получаем файл output.yaml:
$ python3 ./example.json
$ cat output.yaml
glossary:
GlossDiv:
GlossList:
GlossEntry:
Abbrev: ISO 8879:1986
Acronym: SGML
GlossDef:
GlossSeeAlso: [GML, XML]
para: A meta-markup language, used to create markup languages such as DocBook.
GlossSee: markup
GlossTerm: Standard Generalized Markup Language
ID: SGML
SortAs: SGML
title: S
title: example glossary
Это абсолютно корректный YAML, но yamllint выдаст предупреждение, что он не начинается с ---. Что ж, это можно легко поправить вручную или слегка доработать Python-скрипт.
Конвертирование через скрипты
В этом случае сначала пишем на JSON-е, а затем запускаем конвертор в виде отдельного Python-скрипта, который на выходе дает YAML. По сравнению с предыдущим этот способ лучше масштабируется, поскольку конвертирование отделено данных.
Для начала создадим JSON-файл example.json, например, его можно взять на json.org:
{
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}
Затем создадим простой скрипт-конвертор и сохраним его под именем json2yaml.py. Этот скрипт импортирует оба модуля — YAML и JSON Python, а также загружает указанный пользователем файл JSON, выполняет конвертирование и пишет данные в файл output.yaml.
#!/usr/bin/python3
import yaml
import sys
import json
OUT=open('output.yaml','w')
IN=open(sys.argv[1], 'r')
JSON = json.load(IN)
IN.close()
yaml.dump(JSON, OUT)
OUT.close()
Сохраните этот скрипт в system path и запускайте по мере необходимости:
$ ~/bin/json2yaml.py example.json
3. Парсите много и часто
Иногда на проблему полезно взглянуть под другим углом. Если вам трудно представить взаимосвязи между данными в YAML, можно временно преобразовать их в нечто более привычное.
Например, если вам удобно работать со словарными списками или с JSON, то YAML можно преобразовать в JSON всего двумя командами в интерактивной оболочке Python. Допустим, у вас есть YAML-файл mydata.yaml, тогда вот как это будет выглядеть:
$ python3
>>> f=open('mydata.yaml','r')
>>> yaml.load(f)
{'document': 34843, 'date': datetime.date(2019, 5, 23), 'bill-to': {'given': 'Seth', 'family': 'Kenlon', 'address': {'street': '51b Mornington Road\n', 'city': 'Brooklyn', 'state': 'Wellington', 'postal': 6021, 'country': 'NZ'}}, 'words': 938, 'comments': 'Good article. Could be better.'}
На эту тему можно найти массу других примеров. Кроме того, в наличии множество онлайн-конвертеров и локальных парсеров. Так что не стесняйтесь переформатировать данные, когда видите в них только непонятную мешанину.
4. Читайте спеки
Возвращаясь к YAML после долгого перерыва, полезно зайти на yaml.org и перечитать спецификации (спеки). Если у вас трудности с YAML, но до спецификации руки так и не дошли, то пора эту ситуацию исправлять. Спеки на удивление легко написаны, а требования к синтаксису иллюстрируются большим количеством примеров в Главе 6.
5. Псевдоконфиги
При написании книги или статьи всегда полезно сперва набросать предварительный план, хотя бы в виде оглавления. Так же и с YAML. Скорее всего, вы представляете, какие данные надо записать в файл YAML, но не очень понимаете, как связать их друг с другом. Поэтому прежде чем ваять YAML, нарисуйте псевдоконфиг.
Псевдоконфиг похож на псевдокод, где не надо заботиться о структуре или отступах, отношениях «родитель-потомок», наследовании и вложенности. Так и здесь: вы рисуете итерации данных по мере того, как они возникают у вас в голове.
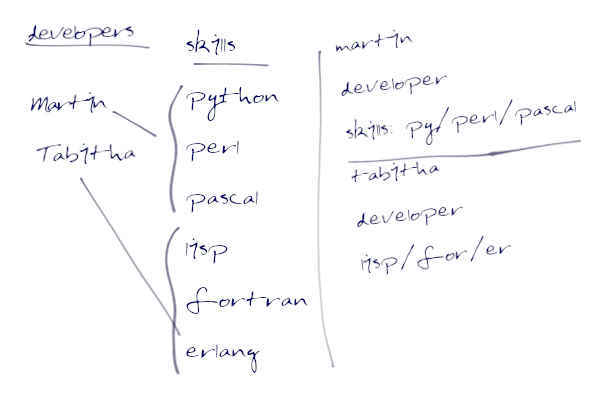
Псевдоконфиг с перечислением программистов (Martin и Tabitha) и их навыков (языков программирования: Python, Perl, Pascal и Lisp, Fortran, Erlang, соответственно).
Нарисовав псевдоконфиг на листе бумаги, внимательно проанализируйте его и, если все в порядке, оформите в виде валидного YAML-файла.
6. Дилемма «табуляция или пробелы»
Вам придется решить дилемму «табуляция или пробелы?». Не в глобальном смысле, а лишь на уровне вашей организации, или хотя бы проекта. Неважно, будет ли при этом использоваться пост-обработка скриптом sed, настройка текстовых редакторов на машинах программистов или же поголовное взятие расписок о строгом соблюдении указаний линтера под угрозой увольнения, но все члены вашей команды, которые так или иначе касаются YAML, в обязательном порядке должны использовать только пробелы (как того требует спецификация YAML).
В любом нормальном текстовом редакторе можно настроить автозамену табуляции на заданное количество пробелов, поэтому бунта приверженцев клавиши Tab можно не бояться.
Как хорошо известно каждому ненавистнику YAML, на экране не видно разницы между табуляцией и пробелами. А когда чего-то не видно, об этом, как правило, вспоминают в последнюю очередь, после того, как перебрали, проверили и устранили все остальные возможные проблемы. Час времени, убитый на поиск кривой табуляции или блока пробелов, просто вопиет о том, что вам над срочно создать политику использования того или другого, а затем реализовать железобетонную проверку ее соблюдения (например, через Git-хук для принудительного прогона через линтер).
7. Лучше меньше да лучше (или больше – это меньше)
Некоторые люди любят писать на YAML, поскольку он подчеркивает структуру. При этом они активно используют отступы, чтобы выделять блоки данных. Это такое своего рода жульничество для имитации языков разметки, в которых используются явные разделители.
Вот пример такой структурированности из документации Ansible:
# Employee records
- martin:
name: Martin D'vloper
job: Developer
skills:
- python
- perl
- pascal
- tabitha:
name: Tabitha Bitumen
job: Developer
skills:
- lisp
- fortran
- erlang
Кому-то такой вариант помогает разложить в голове структуру YAML, других он наоборот раздражает массой ненужных, на их взгляд, отступов.
Но если вы являетесь владельцем YAML-документа и отвечаете за его сопровождение, то вы и только вы должны определять, как использовать отступы. Если вас раздражают большие отступы, сведите их к минимуму, который только возможен согласно спецификации YAML. Например, вышеприведенный файл из документации Ansible без каких бы то ни было потерь можно переписать вот так:
---
- martin:
name: Martin D'vloper
job: Developer
skills:
- python
- perl
- pascal
- tabitha:
name: Tabitha Bitumen
job: Developer
skills:
- lisp
- fortran
- erlang
8. Используйте заготовки
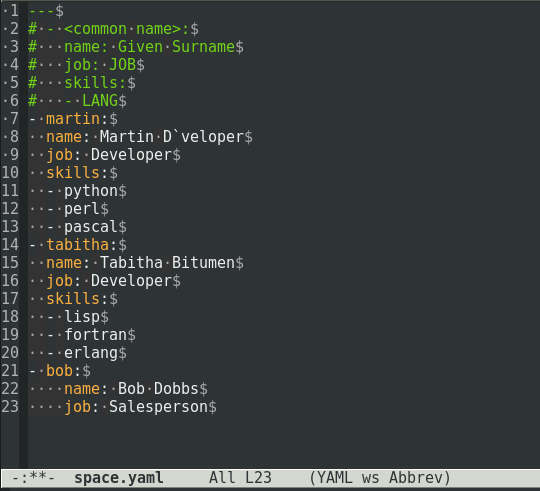
Если при заполнении файла YAML вы постоянно повторяете одни и те же ошибки, имеет смысл вставить в него шаблон-заготовку в виде комментария. Тогда в следующий раз можно будет просто скопировать эту заготовку и вписать туда реальные данные, например:
---
# - <common name>:
# name: Given Surname
# job: JOB
# skills:
# - LANG
- martin:
name: Martin D'vloper
job: Developer
skills:
- python
- perl
- pascal
- tabitha:
name: Tabitha Bitumen
job: Developer
skills:
- lisp
- fortran
- erlang
9. Используйте что-то другое
Если приложение не держит вас мертвой хваткой, то, возможно, стоит сменить YAML на другой формат. Со временем конфигурационные файлы могут перерастать себя и тогда лучше преобразовать их в простые скрипты на Lua или Python.
YAML – отличная штука, которую многие любят за минимализм и простоту, но это далеко не единственный инструмент в вашем арсенале. Так что иногда от него можно отказаться. Для YAML легко найти библиотеки парсинга, поэтому, если вы предложите удобные варианты миграции, ваши пользователи относительно безболезненно переживут такой отказ.
Если же без YAML никак не обойтись, то возьмите на вооружение эти 10 советов и победите свою неприязнь к YAML раз и навсегда!
