
Этот материал посвящён тому, как внутренние механизмы V8 работают со свойствами JavaScript-объектов. Если рассматривать свойства с точки зрения JavaScript, то разные их виды отличаются друг от друга не так уж и сильно. Скажем, JS-объекты обычно ведут себя как словари со строковыми ключами и произвольными объектами в качестве значений. Однако, если почитать спецификацию языка, можно выяснить, например, что свойства разных видов по-разному ведут себя при их переборе. В других случаях поведение свойств различных видов, в основном, выглядит одинаково.
Казалось бы, реализация механизма работы со свойствами, учитывая их схожесть, задача не такая уж и масштабная, однако, в недрах V8 используется несколько различных способов представления свойств. Сделано это, во-первых, для обеспечения высокой производительности, во-вторых — ради экономии памяти.

В этом материале мы хотим рассказать о том, как V8 добивается высокой производительности при обработке динамически добавляемых свойств объектов. Знание особенностей механизма работы со свойствами необходимо для понимания сущности способов оптимизации выполнения JavaScript в V8, таких, например, как встроенные кэши.
Здесь мы поговорим о том, чем в V8 различается обработка именованных свойств и свойств, индексированных целыми числами. После этого мы рассмотрим особенности функционирования скрытых классов при добавлении в объект новых именованных свойств, что позволяет быстро идентифицировать форму объекта. Затем мы продолжим рассказ о внутренних механизмах V8, покажем оптимизации, направленные, в зависимости от особенностей использования скрытых свойств, на быстрый доступ к ним, или на их быструю модификацию. Ознакомившись с последним разделом, вы узнаете о том, как V8 обрабатывает свойства, индексированные целыми числами, или элементы массива, которым назначены индексы.
Начнём с анализа очень простого объекта. Например, пусть это будет нечто вроде
На следующем рисунке показано то, как обычный объект JavaScript выглядит в памяти.

Именованные и индексированные свойства
Элементы и свойства хранятся в различных структурах данных. Это повышает эффективность операций по добавлению новых свойств и элементов и по доступу к ним для различных шаблонов работы с ними.
Элементы, в основном, используются для различных методов Array.prototype, таких, как
Позже мы расскажем о том, в каких ситуациях мы переключаемся на использование словарного механизма хранения индексированных свойств для экономии памяти. В частности, речь идёт о замене разреженных массивов на словари.
Именованные свойства хранятся похожим образом в отдельных массивах. Однако, в отличие от элементов, мы не можем использовать ключи для выяснения их позиций в хранилище свойств. Нам нужны дополнительные метаданные. В V8 у каждого объекта JavaScript есть связанный с ним скрытый класс (HiddenClass). Скрытый класс хранит информацию о форме объекта, и, кроме прочего, сведения о соответствии имён свойств индексам в хранилище свойств. Для сложных сценариев работы мы иногда используем для хранения свойств словари, а не простые массивы. В соответствующем разделе мы остановимся на этом более подробно.
После того, как мы выяснили, в чём заключается основное различие элементов и именованных свойств, нам нужно взглянуть на то, как в V8 работают скрытые классы.
Скрытые классы хранят метаинформацию об объектах, включая число свойств объекта и ссылку на его прототип. Скрытые классы концептуально похожи на классы в типичном объектно-ориентированном языке программирования. Однако, в языке, основанном на прототипах, в таком, как JavaScript, обычно нельзя заранее знать о классах объектов. В результате, в данном случае в V8, скрытые классы создаются, что называется, на лету, и динамически обновляются при обновлении объекта.
Скрытые классы служат идентификаторами для формы объекта, в результате они являются очень важной частью оптимизирующего компилятора V8 и механизма встроенных кэшей. Оптимизирующий компилятор, например, может воспользоваться встраиванием значений свойств в соответствующую структуру данных, если он может гарантировать совместимость скрытого класса со структурой объектов.
Взглянем на важные части скрытых классов.
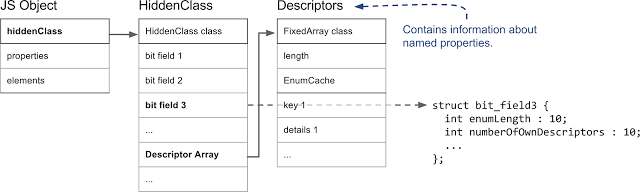
Объект JS, скрытый класс и дескрипторы, которые содержат информацию об именованных свойствах
В V8 первое поле JS-объекта указывает на скрытый класс. (На самом деле, это так для любого объекта, который находится в куче V8 и управляется сборщиком мусора). С точки зрения работы со свойствами, самое важное — это поле, обозначенное на рисунке как
Назначая объектам скрытые классы, V8 исходит из предположения, что объекты с одинаковой структурой, то есть, с одинаковыми именованными свойствами, расположенными в одинаковом порядке, будут иметь один и тот же скрытый класс. Для того, чтобы этого достичь, при добавлении к объекту нового свойства ему назначается новый скрытый класс. В следующем примере мы начинаем с пустого объекта и добавляем к нему три именованных свойства.

Создание промежуточных скрытых классов при добавлении к объекту именованных свойств
Каждый раз при добавлении нового свойства скрытый класс объекта меняется. V8 создаёт дерево переходов, которое соединяет скрытые классы. V8 знает, какой скрытый класс надо взять, когда вы добавляете, например, свойство
Следующий пример показывает, что даже если к объекту добавить простые индексируемые свойства, дерево переходов окажется одним и тем же.

Добавление к объекту именованных и индексируемых свойств
Однако, если создать новый объект, в котором будет добавлено какое-то другое именованное свойство, в данном случае —

Построение различных деревьев переходов для объектов с разным набором свойств
После того, как мы описали то, как V8 использует скрытые классы для поддержки сведений о форме объектов, поговорим о том, как, на самом деле, хранятся именованные свойства. Как показано выше, существуют два фундаментальных вида свойств: именованные и индексируемые. Тут мы подробнее поговорим об именованных свойствах.
Простой объект, такой, как
V8 поддерживает так называемые внутренние свойства объектов, которые хранятся непосредственно в самих объектах. Это — самые быстрые свойства, применяемые в V8, так как доступ к ним можно получить без выполнения дополнительных действий. Количество внутренних свойств объекта определяется исходным размером объекта. Если будет добавлено больше свойств, чем допускает пространство в объекте, они будут размещены в хранилище свойств. Хранилище свойств добавляет дополнительный уровень абстракции, но его размер может увеличиваться независимо от объекта.

Количество свойств, работа с которыми осуществляется быстрее всего, предопределено исходным размером объекта. Значения свойств, работа с которыми также осуществляется достаточно быстро, хранятся в простом массиве свойств
Следующее, на что важно обратить внимание — это различие между «быстрыми» и «медленными» свойствами. Обычно мы называем «быстрыми» свойства, которые хранятся в линейном хранилище свойств. Доступ к таким свойствам осуществляется по индексу в хранилище. Для того, чтобы перейти от имени свойства к его позиции в хранилище, нужно, как было показано выше, обратиться к массиву дескрипторов.

Словарь свойств самодостаточен, при работе с ним не нужна дополнительная метаинформация из массивов дескрипторов
Однако, если выполняется много операций добавления и удаления свойств объекта, поддержка массива дескрипторов и скрытых классов может потребовать слишком больших дополнительных затрат времени и памяти. Поэтому V8, кроме того, поддерживает так называемые медленные свойства. Объект с медленными свойствами использует в качестве хранилища свойств самодостаточный словарь. Вся метаинформация свойств больше не хранится в массиве дескрипторов в скрытом классе, вместо этого она размещается непосредственно в словаре свойств. Как результат, свойства можно добавлять и удалять, не обновляя скрытый класс. Так как встроенные кэши не работают со свойствами, которые хранятся в словаре, работа с такими свойствами обычно оказывается медленнее, чем работа с «быстрыми» свойствами.
До сих пор мы говорили об именованных свойствах, теперь пришло время разобраться со свойствами, индексируемыми целыми числами, которые обычно используются при работе с массивами. Поддержка таких свойств не менее сложна, чем поддержка именованных свойств. Индексированные свойства всегда размещаются в отдельном хранилище элементов, однако, дело усложняет то, что существует 20 различных типов элементов!
Первое основное различие в способах работы с элементами массивов заключается в том, будет ли в качестве их хранилища использоваться сплошной или разреженный массив. Пустые места, или «дырки» в хранилище будут появляться при удалении индексированных элементов, или, например, при наличии элементов, которые не были определены. Простой пример массива с «дыркой» —

Проблемы, возникающие при использовании разреженного массива для хранения элементов
Если описать это в двух словах, то оказывается, что если свойства нет в объекте, к которому мы обращаемся, нам нужно пройтись по цепочке прототипов. Учитывая то, что элементы массивов самодостаточны, то есть, мы не храним информацию о существующих индексированных свойства в скрытом классе, нам нужно специальное значение, которое называется
Следующий признак, по которому можно разделить элементы массивов — это скорость работы с ними, зависящая от их внутреннего представления. «Медленные» элементы хранятся в словаре. Работа с «быстрыми» элементами ведётся с использованием обычных внутренних массивов виртуальной машины. Здесь индекс элемента отображается на индекс в хранилище элементов. Однако, такое простое представление массивов оказывается слишком неэкономичным для очень больших разреженных массивов, в которых занятым оказывается лишь сравнительно небольшое количество ячеек. В подобных случаях мы используем представление массивов, основанное на словаре. Это позволяет экономить память ценой замедления доступа к элементам:
В этом примере выделение памяти под массив с 10000 записями окажется довольно-таки расточительным в плане использования памяти. Вместо этого V8 создаёт массив, где хранятся триплеты вида
В данном примере мы добавили в массив неконфигурируемый элемент. Эта информация хранится в той части триплета медленного словарного элемента, которая имеет отношение к дескриптору. Важно отметить, что функции объекта
В V8 быстрые элементы разграничивают ещё по одному признаку. Например, если вы храните в объекте типа
То, о чём мы говорили выше, позволило описать 7 из 20 различных видов элементов массивов. Мы, чтобы не усложнять повествование, не описывали 9 видов элементов для типизированных массивов и ещё два для обёрток строк. Кроме того, мы не говорили о двух особых видах элементов для объектов аргументов. Они, хотя упомянули мы их последними, не менее важны, чем остальные виды элементов.
Думаем, вполне понятно, что мы не очень-то стремимся к тому, чтобы переписывать на C++ все функции для объекта
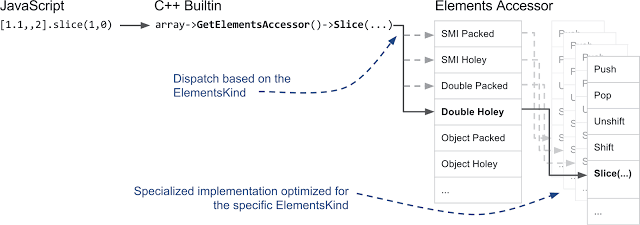
Перенаправление вызова, основанное на виде элемента и специализированная реализация, оптимизированная для конкретного вида элемента
Понимание того, как работают свойства в V8 — ключ ко многим оптимизациях. JS-разработчики не взаимодействуют напрямую с описанными здесь механизмами. Однако, знание того, как организована работа со свойствами в V8, помогает понять, почему одни шаблоны разработки дают более быстрый код, чем другие. Например, изменение типа свойства объекта или элемента массива обычно ведёт к тому, что V8 создаёт новый скрытый класс, что может привести к «засорению» типов и не даст V8 сгенерировать оптимизированный код.
Уважаемые читатели! Скажите, сталкивались ли вы с непонятным падением производительности JS-кода, которое можно объяснить и исправить, используя этот материал?
Казалось бы, реализация механизма работы со свойствами, учитывая их схожесть, задача не такая уж и масштабная, однако, в недрах V8 используется несколько различных способов представления свойств. Сделано это, во-первых, для обеспечения высокой производительности, во-вторых — ради экономии памяти.

В этом материале мы хотим рассказать о том, как V8 добивается высокой производительности при обработке динамически добавляемых свойств объектов. Знание особенностей механизма работы со свойствами необходимо для понимания сущности способов оптимизации выполнения JavaScript в V8, таких, например, как встроенные кэши.
Здесь мы поговорим о том, чем в V8 различается обработка именованных свойств и свойств, индексированных целыми числами. После этого мы рассмотрим особенности функционирования скрытых классов при добавлении в объект новых именованных свойств, что позволяет быстро идентифицировать форму объекта. Затем мы продолжим рассказ о внутренних механизмах V8, покажем оптимизации, направленные, в зависимости от особенностей использования скрытых свойств, на быстрый доступ к ним, или на их быструю модификацию. Ознакомившись с последним разделом, вы узнаете о том, как V8 обрабатывает свойства, индексированные целыми числами, или элементы массива, которым назначены индексы.
Сравнение именованных свойств и элементов массивов
Начнём с анализа очень простого объекта. Например, пусть это будет нечто вроде
{a: "foo", b: "bar"}. Этот объект имеет два именованных свойства: a и b. Целочисленных индексов для имён свойств у этого объекта нет. Индексированные свойства, более широко известные как элементы, характерны для массивов. Например, массив ["foo", "bar"] имеет два индексированных свойства: 0 со значением foo, и 1 со значением bar. Только что мы описали первое основное отличие реализации представления именованных и индексированных свойств в V8.На следующем рисунке показано то, как обычный объект JavaScript выглядит в памяти.

Именованные и индексированные свойства
Элементы и свойства хранятся в различных структурах данных. Это повышает эффективность операций по добавлению новых свойств и элементов и по доступу к ним для различных шаблонов работы с ними.
Элементы, в основном, используются для различных методов Array.prototype, таких, как
pop или slice. Учитывая то, что эти функции работают со свойствами, следующими друг за другом, их внутреннее представление в V8, в большинстве случаев, выглядит как простой массив.Позже мы расскажем о том, в каких ситуациях мы переключаемся на использование словарного механизма хранения индексированных свойств для экономии памяти. В частности, речь идёт о замене разреженных массивов на словари.
Именованные свойства хранятся похожим образом в отдельных массивах. Однако, в отличие от элементов, мы не можем использовать ключи для выяснения их позиций в хранилище свойств. Нам нужны дополнительные метаданные. В V8 у каждого объекта JavaScript есть связанный с ним скрытый класс (HiddenClass). Скрытый класс хранит информацию о форме объекта, и, кроме прочего, сведения о соответствии имён свойств индексам в хранилище свойств. Для сложных сценариев работы мы иногда используем для хранения свойств словари, а не простые массивы. В соответствующем разделе мы остановимся на этом более подробно.
▍Выводы
- Индексированные свойства хранятся в отдельном хранилище элементов.
- Именованные свойства хранятся в собственном хранилище свойств.
- Хранилища элементов и свойств могут быть либо массивами, либо словарями.
- У каждого JS-объекта есть связанный с ним скрытый класс, который хранит сведения о форме объекта.
Скрытые классы и массивы дескрипторов
После того, как мы выяснили, в чём заключается основное различие элементов и именованных свойств, нам нужно взглянуть на то, как в V8 работают скрытые классы.
Скрытые классы хранят метаинформацию об объектах, включая число свойств объекта и ссылку на его прототип. Скрытые классы концептуально похожи на классы в типичном объектно-ориентированном языке программирования. Однако, в языке, основанном на прототипах, в таком, как JavaScript, обычно нельзя заранее знать о классах объектов. В результате, в данном случае в V8, скрытые классы создаются, что называется, на лету, и динамически обновляются при обновлении объекта.
Скрытые классы служат идентификаторами для формы объекта, в результате они являются очень важной частью оптимизирующего компилятора V8 и механизма встроенных кэшей. Оптимизирующий компилятор, например, может воспользоваться встраиванием значений свойств в соответствующую структуру данных, если он может гарантировать совместимость скрытого класса со структурой объектов.
Взглянем на важные части скрытых классов.
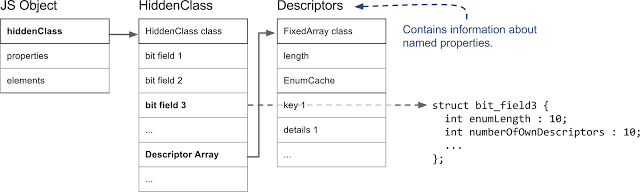
Объект JS, скрытый класс и дескрипторы, которые содержат информацию об именованных свойствах
В V8 первое поле JS-объекта указывает на скрытый класс. (На самом деле, это так для любого объекта, который находится в куче V8 и управляется сборщиком мусора). С точки зрения работы со свойствами, самое важное — это поле, обозначенное на рисунке как
bit field 3, которое хранит количество свойств и указатель на массив дескрипторов. Массив дескрипторов содержит информацию об именованных свойствах, в частности — имя свойства и позицию, где хранится значение. Обратите внимание на то, что мы не работаем тут со свойствами, индексируемыми целыми числами, поэтому в массиве дескрипторов нет соответствующей записи.Назначая объектам скрытые классы, V8 исходит из предположения, что объекты с одинаковой структурой, то есть, с одинаковыми именованными свойствами, расположенными в одинаковом порядке, будут иметь один и тот же скрытый класс. Для того, чтобы этого достичь, при добавлении к объекту нового свойства ему назначается новый скрытый класс. В следующем примере мы начинаем с пустого объекта и добавляем к нему три именованных свойства.
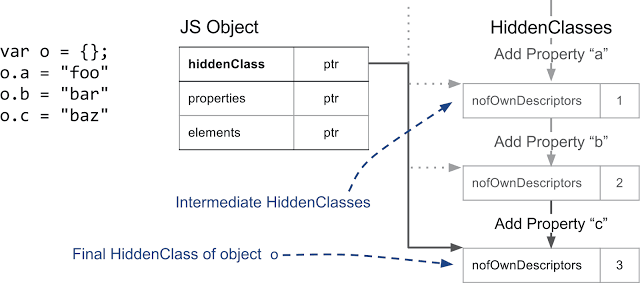
Создание промежуточных скрытых классов при добавлении к объекту именованных свойств
Каждый раз при добавлении нового свойства скрытый класс объекта меняется. V8 создаёт дерево переходов, которое соединяет скрытые классы. V8 знает, какой скрытый класс надо взять, когда вы добавляете, например, свойство
a к пустому объекту. Это дерево переходов позволяет обеспечить то, что когда объекты устроены одинаково, они получат один и тот же скрытый класс.Следующий пример показывает, что даже если к объекту добавить простые индексируемые свойства, дерево переходов окажется одним и тем же.

Добавление к объекту именованных и индексируемых свойств
Однако, если создать новый объект, в котором будет добавлено какое-то другое именованное свойство, в данном случае —
d, V8 создаст отдельную ветвь для новых скрытых классов.
Построение различных деревьев переходов для объектов с разным набором свойств
▍Выводы
- У объектов с одинаковой структурой (то есть — с одинаковыми свойствами, расположенными в одинаковом порядке), будет один и тот же скрытый класс.
- По умолчанию каждое новое добавленное к объекту именованное свойство приводит к созданию нового скрытого класса.
- При добавлении индексируемых свойств создание новых скрытых классов не происходит.
Три вида именованных свойств
После того, как мы описали то, как V8 использует скрытые классы для поддержки сведений о форме объектов, поговорим о том, как, на самом деле, хранятся именованные свойства. Как показано выше, существуют два фундаментальных вида свойств: именованные и индексируемые. Тут мы подробнее поговорим об именованных свойствах.
Простой объект, такой, как
{a: 1, b: 2}, может иметь различные внутренние представления в V8. Хотя может казаться, что поведение JS-объектов более или менее похоже на поведение простых словарей, V8 пытается избегать представления их в виде словарей, так как это затрудняет выполнение определённых оптимизаций, таких, как встроенное кэширование, которые достойны отдельного разговора.▍Сравнение внутренних и обычных свойств объектов
V8 поддерживает так называемые внутренние свойства объектов, которые хранятся непосредственно в самих объектах. Это — самые быстрые свойства, применяемые в V8, так как доступ к ним можно получить без выполнения дополнительных действий. Количество внутренних свойств объекта определяется исходным размером объекта. Если будет добавлено больше свойств, чем допускает пространство в объекте, они будут размещены в хранилище свойств. Хранилище свойств добавляет дополнительный уровень абстракции, но его размер может увеличиваться независимо от объекта.

Количество свойств, работа с которыми осуществляется быстрее всего, предопределено исходным размером объекта. Значения свойств, работа с которыми также осуществляется достаточно быстро, хранятся в простом массиве свойств
▍Сравнение быстрых и медленных свойств
Следующее, на что важно обратить внимание — это различие между «быстрыми» и «медленными» свойствами. Обычно мы называем «быстрыми» свойства, которые хранятся в линейном хранилище свойств. Доступ к таким свойствам осуществляется по индексу в хранилище. Для того, чтобы перейти от имени свойства к его позиции в хранилище, нужно, как было показано выше, обратиться к массиву дескрипторов.
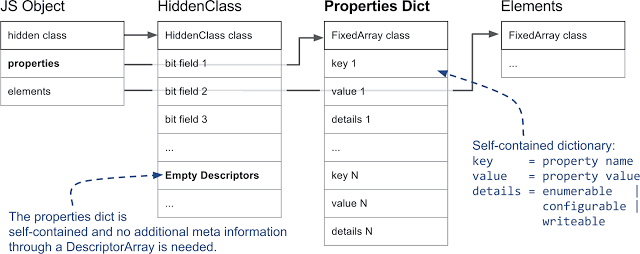
Словарь свойств самодостаточен, при работе с ним не нужна дополнительная метаинформация из массивов дескрипторов
Однако, если выполняется много операций добавления и удаления свойств объекта, поддержка массива дескрипторов и скрытых классов может потребовать слишком больших дополнительных затрат времени и памяти. Поэтому V8, кроме того, поддерживает так называемые медленные свойства. Объект с медленными свойствами использует в качестве хранилища свойств самодостаточный словарь. Вся метаинформация свойств больше не хранится в массиве дескрипторов в скрытом классе, вместо этого она размещается непосредственно в словаре свойств. Как результат, свойства можно добавлять и удалять, не обновляя скрытый класс. Так как встроенные кэши не работают со свойствами, которые хранятся в словаре, работа с такими свойствами обычно оказывается медленнее, чем работа с «быстрыми» свойствами.
▍Выводы
- Существует три вида именованных свойств: внутренние свойства объекта, быстрые свойства и медленные (словарные) свойства.
- Внутренние свойства объекта хранятся непосредственно в объекте, работа с ними осуществляется быстрее всего.
- Быстрые свойства размещаются в хранилище свойства, их метаинформация хранится в массиве дескрипторов в скрытом классе.
- Медленные свойства хранятся в самодостаточном словаре свойств, их метаинформация больше не хранится в других структурах скрытого класса.
- Медленные свойства позволяют эффективно осуществлять операции по добавлению и удалению свойств, но доступ к ним осуществляется не так быстро, как к свойствам других видов.
Элементы или индексируемые свойства
До сих пор мы говорили об именованных свойствах, теперь пришло время разобраться со свойствами, индексируемыми целыми числами, которые обычно используются при работе с массивами. Поддержка таких свойств не менее сложна, чем поддержка именованных свойств. Индексированные свойства всегда размещаются в отдельном хранилище элементов, однако, дело усложняет то, что существует 20 различных типов элементов!
▍Сплошные и разреженные массивы элементов
Первое основное различие в способах работы с элементами массивов заключается в том, будет ли в качестве их хранилища использоваться сплошной или разреженный массив. Пустые места, или «дырки» в хранилище будут появляться при удалении индексированных элементов, или, например, при наличии элементов, которые не были определены. Простой пример массива с «дыркой» —
[1,,3]. В данном случае в массиве нет второго элемента. Эту проблему иллюстрирует следующий пример:const o = ["a", "b", "c"];
console.log(o[1]); // Вывод "b".
delete o[1]; // В хранилище элементов оказывается «дырка».
console.log(o[1]); // Вывод "undefined"; свойство 1 не существует.
o.__proto__ = {1: "B"}; // Определяем свойство 1 в прототипе.
console.log(o[0]); // Вывод "a".
console.log(o[1]); // Вывод "B".
console.log(o[2]); // Вывод "c".
console.log(o[3]); // Вывод undefined
Проблемы, возникающие при использовании разреженного массива для хранения элементов
Если описать это в двух словах, то оказывается, что если свойства нет в объекте, к которому мы обращаемся, нам нужно пройтись по цепочке прототипов. Учитывая то, что элементы массивов самодостаточны, то есть, мы не храним информацию о существующих индексированных свойства в скрытом классе, нам нужно специальное значение, которое называется
the_hole, которым отмечаются несуществующие значения. Это очень плохо влияет на производительность функций объекта Array. Если нам известно, что в хранилище нет «дырок», то есть, хранилище элементов не содержит информации о пропусках значений в массиве, мы можем выполнять локальные операции без необходимости медленного поиска в цепочке прототипов.▍Быстрые и словарные элементы
Следующий признак, по которому можно разделить элементы массивов — это скорость работы с ними, зависящая от их внутреннего представления. «Медленные» элементы хранятся в словаре. Работа с «быстрыми» элементами ведётся с использованием обычных внутренних массивов виртуальной машины. Здесь индекс элемента отображается на индекс в хранилище элементов. Однако, такое простое представление массивов оказывается слишком неэкономичным для очень больших разреженных массивов, в которых занятым оказывается лишь сравнительно небольшое количество ячеек. В подобных случаях мы используем представление массивов, основанное на словаре. Это позволяет экономить память ценой замедления доступа к элементам:
const sparseArray = [];
sparseArray[9999] = "foo"; // Создание массива, элементы которого хранятся в словареВ этом примере выделение памяти под массив с 10000 записями окажется довольно-таки расточительным в плане использования памяти. Вместо этого V8 создаёт массив, где хранятся триплеты вида
ключ-значение-дескриптор. Ключ в данном случае будет 9999, значение — foo и стандартный дескриптор. Кроме того, надо отметить, что учитывая то, что у нас нет способа хранить подробности о дескрипторе в скрытом классе, V8 переходит к использованию медленного способа хранения элементов всякий раз, когда мы задаём индексированные свойства с собственным дескриптором:const array = [];
Object.defineProperty(array, 0, {value: "fixed", configurable: false});
console.log(array[0]); // Вывод "fixed".
array[0] = "other value"; // Невозможно переопределить элемент с индексом 0.
console.log(array[0]); // Снова выводится "fixed".В данном примере мы добавили в массив неконфигурируемый элемент. Эта информация хранится в той части триплета медленного словарного элемента, которая имеет отношение к дескриптору. Важно отметить, что функции объекта
Array работают значительно медленнее с массивами, элементы которых хранятся в словарях.▍Элементы Smi и Double
В V8 быстрые элементы разграничивают ещё по одному признаку. Например, если вы храните в объекте типа
Array только целые числа, а случается такое часто, сборщику мусора не надо анализировать массив, так как целые числа напрямую кодируются в так называемые маленькие целые числа (small integer, smi). Другой особый случай — это массивы, которые содержат только числа двойной точности (double). В отличие от маленьких целых чисел, числа с плавающей запятой обычно представлены в виде целого объекта, занимая несколько слов. Однако, V8 хранит обычные числа двойной точности в виде массивов типа Double для того, чтобы избежать излишней нагрузки на память и не занимать компьютер ненужными вычислениями. В следующем примере показаны четыре варианта массивов с элементами Smi и Double:const a1 = [1, 2, 3]; // Smi, сплошной массив
const a2 = [1, , 3]; // Smi, разреженный массив, нужно проверить существование элемента a2[1] в прототипе
const b1 = [1.1, 2, 3]; // Double, сплошной массив
const b2 = [1.1, , 3]; // Double, разреженный массив, нужно проверить существование элемента b2[1] в прототипе▍Некоторые другие виды элементов
То, о чём мы говорили выше, позволило описать 7 из 20 различных видов элементов массивов. Мы, чтобы не усложнять повествование, не описывали 9 видов элементов для типизированных массивов и ещё два для обёрток строк. Кроме того, мы не говорили о двух особых видах элементов для объектов аргументов. Они, хотя упомянули мы их последними, не менее важны, чем остальные виды элементов.
▍ElementAccessor
Думаем, вполне понятно, что мы не очень-то стремимся к тому, чтобы переписывать на C++ все функции для объекта
Array по 20 раз — по числу видов элементов. Именно здесь проявляются некоторые особые возможности C++. Вместо того, чтобы создавать множество функций для объекта Array, мы создали ElementAccessor, где нам, преимущественно, нужно реализовать лишь простые функции, которые получают доступ к элементам из хранилища.ElementAccessor использует технику CRTP для создания специализированных версий функций для объекта Array. Поэтому, если вы вызываете для массива что-то вроде метода slice, в V8 активируется встроенный механизм, написанный на C++ и осуществляется переход, через ElementAccessor, к специализированной версии функции: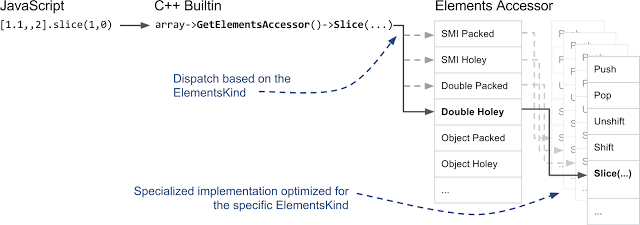
Перенаправление вызова, основанное на виде элемента и специализированная реализация, оптимизированная для конкретного вида элемента
▍Выводы
- Существуют быстрые, основанные на массивах, и более медленные, основанные на словарях, индексированные свойства.
- Быстрые свойства могут быть представлены сплошными массивами, или, при удалении элементов, разреженными массивами.
- Элементы специализированы по содержимому для ускорения функций объекта
Arrayи снижения нагрузки на систему, которую создаёт сборщик мусора.
Итоги
Понимание того, как работают свойства в V8 — ключ ко многим оптимизациях. JS-разработчики не взаимодействуют напрямую с описанными здесь механизмами. Однако, знание того, как организована работа со свойствами в V8, помогает понять, почему одни шаблоны разработки дают более быстрый код, чем другие. Например, изменение типа свойства объекта или элемента массива обычно ведёт к тому, что V8 создаёт новый скрытый класс, что может привести к «засорению» типов и не даст V8 сгенерировать оптимизированный код.
Уважаемые читатели! Скажите, сталкивались ли вы с непонятным падением производительности JS-кода, которое можно объяснить и исправить, используя этот материал?
