
Этот материал посвящён продвинутым возможностям PWA (Progressive Web Application, прогрессивное веб-приложение), основанным на некоторых современных API. А именно, здесь мы поговорим о разработке веб-проекта, поддерживающего распознавание лица и голоса. Тем, что раньше было доступно только в обычных приложениях, теперь можно воспользоваться и в PWA. Это открывает веб-разработчикам множество новых возможностей.

Приложение, о котором пойдёт речь, основано на PWA, разработка которого подробно описана в этом материале. Здесь мы уделим основное внимание следующим двум API:
Мы добавим поддержку этих API в существующее PWA и оснастим его функционалом создания «селфи». Благодаря возможностям по распознаванию лица приложение сможет выяснить эмоциональное состояние, пол и возраст того, кто делает «селфи». А снабдить снимок подписью можно будет, воспользовавшись Web Speech API.
Вышеописанные API будут работать только в том случае, если включить в браузере Google Chrome флаг

Включение флага Experimental Web Platform features
Начнём работу с клонирования следующего репозитория:
После завершения клонирования нужно перейти в директорию проекта:
Далее — установим зависимости и запустим проект:
Открыть приложение можно, перейдя по ссылке
Приложение в браузере
Есть много способов для организации доступа к
Установим ngrok:
Выполним в терминале следующую команду:
Она выдаст общедоступный URL для проекта. Теперь его можно будет открыть на обычном мобильном телефоне, воспользовавшись браузером Google Chrome.
Распознавание лица — это один из самых распространённых способов применения технологий искусственного интеллекта. В последние годы можно наблюдать рост масштабов использования соответствующих механизмов.
Здесь мы расширим существующее PWA, оснастив его возможностью распознавания лиц. Причём, эти возможности будут работать даже в браузере. Мы будем определять эмоциональное состояние, пол и возраст человека, основываясь на его «селфи». Для решения этих задач мы будем использовать библиотеку face-api.js.
Эта библиотека включает в себя API, предназначенный для организации распознавания лиц в браузере. В основе этого API лежит библиотека tensorflow.js.
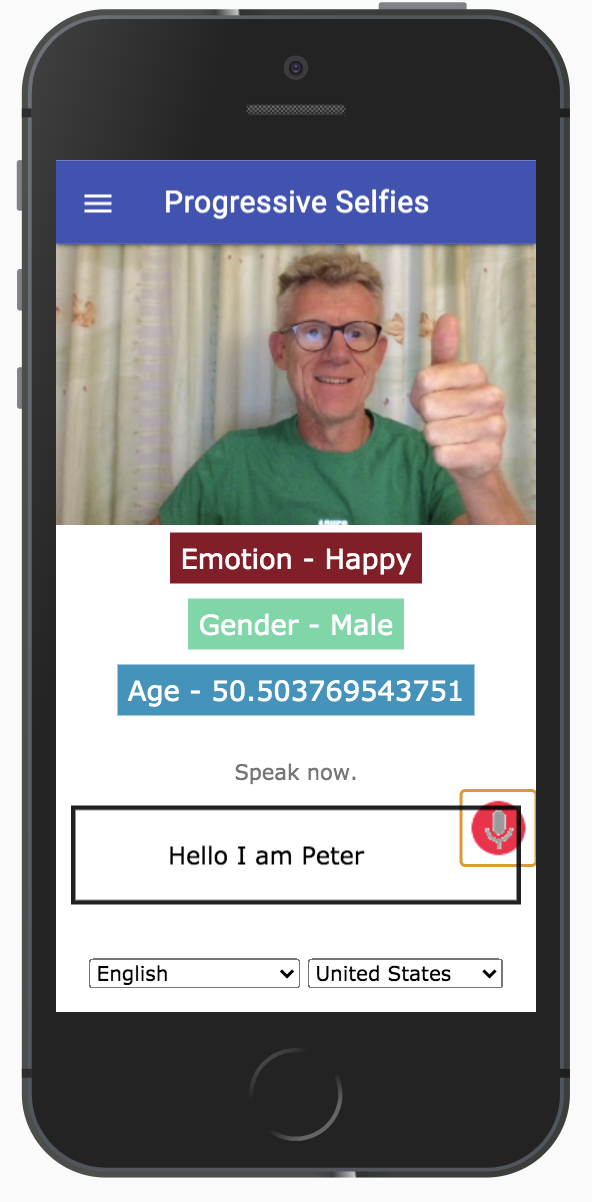
Результаты работы приложения могут выглядеть примерно так, как показано на следующем рисунке.

Результаты работы приложения
Вот пошаговый план работы над возможностями приложения по распознаванию лица.
Библиотека face-api.js, как уже было сказано, предоставляет приложению API для организации распознавания лиц в браузере. Эта библиотека уже имеется в нашем проекте, она находится в папке
Модели — это предварительно подготовленные данные, которыми мы будем пользоваться для анализа «селфи» и определения интересующих нас признаков. Модели находятся в папке
В файле
В файл
Затем, сразу под тегом
Тут мы используем существующий тег
Далее, нужно поместить следующий фрагмент кода в нижней части
Здесь мы создаём в существующем файле
В файле
Поговорим о функциях Face Detection API, которыми мы будем пользоваться в приложении:
Следующий код нужно поместить в файл
Вышеописанные функции используются здесь для решения задач распознавания лица.
Тут мы, в первую очередь, подключаем к
Переменная
Затем создаётся элемент
Функция
Ниже показан интерфейс, который мы собираемся создать для работы с Web Speech API. Как видите, на экране есть поле, в которое можно вводить текст. Но этот текст можно и надиктовать приложению, воспользовавшись значком микрофона.
Ниже поля ввода имеются элементы управления, позволяющие выбрать язык.
Интерфейс, используемый для решения задач распознавания речи
Разберём, как и прежде, пошаговый план реализации соответствующих возможностей.
Импортируем в
Сначала импортируем стили:
Потом разместим следующий код сразу после тега
Здесь, в разделе
Обработчик события
Обработчик события
Следующий код нужно разместить в нижней части
Ниже показан код, который должен быть размещён в файле
Тут, в первую очередь, осуществляется проверка на предмет доступности API
Если
Затем осуществляется настройка следующих свойств API:
Мы используем следующие обработчики событий:
Следующий код, ответственный за запуск распознавания речи с помощью кнопки, нужно добавить в верхнюю часть файла
Запуск распознавания речи осуществляется с помощью функции
С каждым днём веб становится всё сложнее и сложнее. В распоряжении создателей проектов, рассчитанных на работу в браузере, оказывается всё больше возможностей, доступных ранее лишь разработчикам обычных приложений. Среди причин этого можно назвать то, что количество веб-пользователей гораздо больше, чем тех, кто применяет обычные приложения. При этом получается так, что возможности обычных приложений, доступные в веб-проектах, создают знакомую среду для тех пользователей, которые привыкли к подобным возможностям, работая с обычными приложениями. В результате таким пользователям нет необходимости возвращаться к обычным приложениям.
В этом репозитории можно найти полный код проекта, которым мы занимались. Если вы освоили данный материал и хотите попрактиковаться в работе с различными возможностями PWA — загляните сюда.
Планируете ли вы пользоваться инструментами для распознавания лица и голоса в своих веб-проектах?

Приложение, о котором пойдёт речь, основано на PWA, разработка которого подробно описана в этом материале. Здесь мы уделим основное внимание следующим двум API:
- Face Detection API, который предназначен для реализации возможностей по распознаванию лица в браузере.
- Web Speech API, который позволяет преобразовывать речь в текст и «озвучивать» обычные тексты.
Мы добавим поддержку этих API в существующее PWA и оснастим его функционалом создания «селфи». Благодаря возможностям по распознаванию лица приложение сможет выяснить эмоциональное состояние, пол и возраст того, кто делает «селфи». А снабдить снимок подписью можно будет, воспользовавшись Web Speech API.
О работе с экспериментальными возможностями веб-платформы
Вышеописанные API будут работать только в том случае, если включить в браузере Google Chrome флаг
Experimental Web Platform features. Найти его можно по адресу chrome://flags.Включение флага Experimental Web Platform features
Подготовка проекта
Начнём работу с клонирования следующего репозитория:
git clone https://github.com/petereijgermans11/progressive-web-app
После завершения клонирования нужно перейти в директорию проекта:
cd pwa-article/pwa-app-native-features-rendezvous-init
Далее — установим зависимости и запустим проект:
npm i && npm start
Открыть приложение можно, перейдя по ссылке
http://localhost:8080.Приложение в браузере
Общедоступный URL для приложения, к которому можно обратиться с мобильного устройства
Есть много способов для организации доступа к
localhost:8080 с мобильных устройств. Например, для этого можно воспользоваться ngrok.Установим ngrok:
npm install -g ngrok
Выполним в терминале следующую команду:
ngrok http 8080
Она выдаст общедоступный URL для проекта. Теперь его можно будет открыть на обычном мобильном телефоне, воспользовавшись браузером Google Chrome.
Распознавание лица средствами JavaScript
Распознавание лица — это один из самых распространённых способов применения технологий искусственного интеллекта. В последние годы можно наблюдать рост масштабов использования соответствующих механизмов.
Здесь мы расширим существующее PWA, оснастив его возможностью распознавания лиц. Причём, эти возможности будут работать даже в браузере. Мы будем определять эмоциональное состояние, пол и возраст человека, основываясь на его «селфи». Для решения этих задач мы будем использовать библиотеку face-api.js.
Эта библиотека включает в себя API, предназначенный для организации распознавания лиц в браузере. В основе этого API лежит библиотека tensorflow.js.
Результаты работы приложения могут выглядеть примерно так, как показано на следующем рисунке.
Результаты работы приложения
Вот пошаговый план работы над возможностями приложения по распознаванию лица.
▍Шаг 1: библиотека face-api.js
Библиотека face-api.js, как уже было сказано, предоставляет приложению API для организации распознавания лиц в браузере. Эта библиотека уже имеется в нашем проекте, она находится в папке
public/src/lib.▍Шаг 2: модели
Модели — это предварительно подготовленные данные, которыми мы будем пользоваться для анализа «селфи» и определения интересующих нас признаков. Модели находятся в папке
public/src/models.▍Шаг 3: файл index.html
В файле
index.html выполняется импорт следующих материалов:- Уже имеющийся в проекте файл
facedetection.css, используемый для стилизации приложения. - Файл
face-api.min.js, представляющий Face Detection API, используемый для обработки данных моделей и для извлечения из снимков интересующих нас признаков. - Файл
facedetection.js, в котором мы будем писать код, реализующий логику приложения.
В файл
index.html сначала нужно импортировать стили:<link rel="stylesheet" href="src/css/facedetection.css">
Затем, сразу под тегом
<div id="create-post">, в файл нужно поместить следующий код:<video id="player" autoplay></video>
<div class="container-faceDetection">
</div>
<canvas id="canvas" width="320px" height="240px"></canvas>
<div class="result-container">
<div id="emotion">Emotion</div>
<div id="gender">Gender</div>
<div id="age">Age</div>
</div>
Тут мы используем существующий тег
<video>, применяя его для создания «селфи». В теге с классом result-container мы выводим результаты определения эмоционального состояния человека, его пола и возраста.Далее, нужно поместить следующий фрагмент кода в нижней части
index.html. Это позволит нам пользоваться API для распознавания лиц:<script src="src/lib/face-api.min.js"></script>
<script src="src/js/facedetection.js"></script>
▍Шаг 4: импорт моделей в PWA
Здесь мы создаём в существующем файле
feed.js отдельную функцию, предназначенную для запуска потоковой передачи видео. А именно, переместим следующий код из функции initializeMedia() в функцию startVideo(), ответственную за потоковую передачу видео:const startVideo = () => {
navigator.mediaDevices.getUserMedia({video: {facingMode: 'user'}, audio: false})
.then(stream => {
videoPlayer.srcObject = stream;
videoPlayer.style.display = 'block';
videoPlayer.setAttribute('autoplay', '');
videoPlayer.setAttribute('muted', '');
videoPlayer.setAttribute('playsinline', '');
})
.catch(error => {
console.log(error);
});
}
В файле
feed.js мы используем Promise.all для асинхронной загрузки моделей, используемых API для распознавания лица. После того, как модели будут загружены, мы вызываем только что созданную функцию startVideo():Promise.all([
faceapi.nets.tinyFaceDetector.loadFromUri("/src/models"),
faceapi.nets.faceLandmark68Net.loadFromUri("/src/models"),
faceapi.nets.faceRecognitionNet.loadFromUri("/src/models"),
faceapi.nets.faceExpressionNet.loadFromUri("/src/models"),
faceapi.nets.ageGenderNet.loadFromUri("/src/models")
]).then(startVideo);
▍Шаг 5: реализация логики проекта в файле facedetection.js
Поговорим о функциях Face Detection API, которыми мы будем пользоваться в приложении:
faceapi.detectSingleFace— эта функция использует систему распознавания лиц SSD Mobilenet V1. Функции передают объектvideoPlayerи объект с параметрами. Для того чтобы наладить распознавание нескольких лиц —detectSingleFaceнадо заменить наdetectAllFaces.withFaceLandmarks— данная функция применяется для нахождения 68 ключевых точек (ориентиров) лица.withFaceExpressions— эта функция находит на изображении все лица и определяет выражения лиц, возвращая результаты работы в виде массива.withAgeAndGender— данная функция тоже находит на изображении все лица, определяет возраст и пол людей и возвращает массив.
Следующий код нужно поместить в файл
facedetection.js ниже того кода, который там уже есть.videoPlayer.addEventListener("playing", () => {
const canvasForFaceDetection = faceapi.createCanvasFromMedia(videoPlayer);
let containerForFaceDetection = document.querySelector(".container-faceDetection");
containerForFaceDetection.append(canvasForFaceDetection);
const displaySize = { width: 500, height: 500};
faceapi.matchDimensions(canvasForFaceDetection, displaySize);
setInterval(async () => {
const detections = await faceapi
.detectSingleFace(videoPlayer, new faceapi.TinyFaceDetectorOptions())
.withFaceLandmarks()
.withFaceExpressions()
.withAgeAndGender();
const resizedDetections = faceapi.resizeResults(detections, displaySize);
canvasForFaceDetection.getContext("2d").clearRect(0, 0, 500, 500);
faceapi.draw.drawDetections(canvasForFaceDetection, resizedDetections);
faceapi.draw.drawFaceLandmarks(canvasForFaceDetection, resizedDetections);
if (resizedDetections && Object.keys(resizedDetections).length > 0) {
const age = resizedDetections.age;
const interpolatedAge = interpolateAgePredictions(age);
const gender = resizedDetections.gender;
const expressions = resizedDetections.expressions;
const maxValue = Math.max(...Object.values(expressions));
const emotion = Object.keys(expressions).filter(
item => expressions[item] === maxValue
);
document.getElementById("age").innerText = `Age - ${interpolatedAge}`;
document.getElementById("gender").innerText = `Gender - ${gender}`;
document.getElementById("emotion").innerText = `Emotion - ${emotion[0]}`;
}
}, 100);
});
Вышеописанные функции используются здесь для решения задач распознавания лица.
Тут мы, в первую очередь, подключаем к
videoPlayer обработчик события playing. Он срабатывает в ситуации, когда активна видеокамера.Переменная
videoPlayer даёт доступ к HTML-элементу <video>. Видеоматериалы будут выводиться именно в этом элементе.Затем создаётся элемент
canvasElement, который представлен константой canvasForFaceDetection. Он используется для распознавания лица. Этот элемент размещается в контейнере faceDetection.Функция
setInterval() осуществляет вызовы faceapi.detectSingleFace с интервалом в 100 миллисекунд. Эта функция вызывается асинхронно, с применением конструкции async/await. В итоге результаты распознавания лица выводятся в полях с идентификаторами emotion, gender и age.Распознавание речи средствами JavaScript
Ниже показан интерфейс, который мы собираемся создать для работы с Web Speech API. Как видите, на экране есть поле, в которое можно вводить текст. Но этот текст можно и надиктовать приложению, воспользовавшись значком микрофона.
Ниже поля ввода имеются элементы управления, позволяющие выбрать язык.
Интерфейс, используемый для решения задач распознавания речи
Разберём, как и прежде, пошаговый план реализации соответствующих возможностей.
▍Шаг 1: файл index.html
Импортируем в
index.html следующие материалы:- Уже имеющиеся в проекте стили из файла
speech.css. - Файл
speech.js, в котором мы реализуем логику, необходимую для распознавания речи.
Сначала импортируем стили:
<link rel="stylesheet" href="src/css/speech.css">
Потом разместим следующий код сразу после тега
<form>:<div id="info">
<p id="info_start">Click on the microphone icon and begin speaking.</p>
<p id="info_speak_now">Speak now.</p>
<p id="info_no_speech">No speech was detected. You may need to adjust your
<a href="//support.google.com/chrome/bin/answer.py?hl=en&answer=1407892">
microphone settings</a>.</p>
<p id="info_no_microfoon" style="display:none">
No microphone was found. Ensure that a microphone is installed and that
<a href="//support.google.com/chrome/bin/answer.py?hl=en&answer=1407892">
microphone settings</a> are configured correctly.</p>
<p id="info_allow">Click the "Allow" button above to enable your microphone.</p>
<p id="info_denied">Permission to use microphone was denied.</p>
<p id="info_blocked">Permission to use microphone is blocked. To change,
go to chrome://settings/contentExceptions#media-stream</p>
<p id="info_upgrade">Web Speech API is not supported by this browser.
Upgrade to <a href="//www.google.com/chrome">Chrome</a>
version 25 or later.</p>
</div>
<div class="right">
<button id="start_button" onclick="startButton(event)">
<img id="start_img" src="./src/images/mic.gif" alt="Start"></button>
</div>
<div class="input-section mdl-textfield mdl-js-textfield mdl-textfield--floating-label div_speech_to_text">
<span id="title" contenteditable="true" class="final"></span>
<span id="interim_span" class="interim"></span>
<p>
</div>
<div class="center">
<p>
<div id="div_language">
<select id="select_language" onchange="updateCountry()"></select>
<select id="select_dialect"></select>
</div>
</div>
Здесь, в разделе
<div id ="info">, выводятся информационные сообщения, имеющие отношение к использованию Web Speech API.Обработчик события
onclick кнопки с идентификатором start_button используется для запуска системы распознавания речи.Обработчик события
onchange поля select_language позволяет выбирать язык.Следующий код нужно разместить в нижней части
index.html. Он позволит нам пользоваться возможностями Web Speech API.<script src="src/js/speech.js"></script>
▍Шаг 2: реализация возможностей распознавания речи
Ниже показан код, который должен быть размещён в файле
speech.js. Он отвечает за инициализацию Web Speech Recognition API — системы, ответственной за распознавание речи:if ('webkitSpeechRecognition' in window) {
start_button.style.display = 'inline-block';
recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = () => {
recognizing = true;
showInfo('info_speak_now');
start_img.src = './src/images/mic-animate.gif';
};
recognition.onresult = (event) => {
let interim_transcript = '';
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
title.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
recognition.onerror = (event) => {
// код обработки ошибок
};
recognition.onend = () => {
// код, выполняемый при завершении распознавания речи
};
}
Тут, в первую очередь, осуществляется проверка на предмет доступности API
webkitSpeechRecognition в объекте window. Этот объект представляет окно браузера (JavaScript является частью этого объекта).Если
webkitSpeechRecognition в window имеется, создаётся объект webkitSpeechRecognition с использованием конструкции recognition = new webkitSpeechRecognition();.Затем осуществляется настройка следующих свойств API:
recognition.continuous = true— это свойство позволяет задать для каждого сеанса распознавания речи непрерывный возврат результатов.recognition.interimResults = true— это свойство указывает на то, нужно ли возвращать промежуточные результаты распознавания речи.
Мы используем следующие обработчики событий:
recognition.onstart— этот обработчик запускается при запуске системы распознавания речи. После этого выводится текст, предлагающий пользователю начать говорить (Speak now), и отображается анимированный значок микрофона (mic-animate.gif).recognition.onresult— этот обработчик срабатывает при возврате результатов распознавания речи. Результаты представлены в виде двумерного массиваSpeechRecognitionResultList. СвойствоisFinal, проверка которого осуществляется в цикле, указывает на то, каким именно является результат — окончательным или промежуточным. Свойствоtranscriptдаёт доступ к строковому представлению результата.recognition.onend— данный обработчик выполняется при завершении операции распознавания речи. При его выполнении не выводится никакого текста. Он лишь выполняет замену значка микрофона на стандартный.recognition.onerror— этот обработчик вызывается при возникновении ошибок. Тут выводятся сообщения о возникших ошибках.
▍Запуск процесса распознавания речи
Следующий код, ответственный за запуск распознавания речи с помощью кнопки, нужно добавить в верхнюю часть файла
speech.js:const startButton = (event) => {
if (recognizing) {
recognition.stop();
return;
}
final_transcript = '';
recognition.lang = select_dialect.value;
recognition.start();
ignore_onend = false;
title.innerHTML = '';
interim_span.innerHTML = '';
start_img.src = './src/images/mic-slash.gif';
showInfo('info_allow');
start_timestamp = event.timeStamp;
};
Запуск распознавания речи осуществляется с помощью функции
recognition.start(). Эта функция вызывает событие start, которое обрабатывается в обработчике событий recognition.onstart(), код которого рассмотрен выше. Тут, кроме того, системе распознавания речи передаётся язык, выбранный пользователем. Здесь же выводится анимированный значок микрофона.Итоги
С каждым днём веб становится всё сложнее и сложнее. В распоряжении создателей проектов, рассчитанных на работу в браузере, оказывается всё больше возможностей, доступных ранее лишь разработчикам обычных приложений. Среди причин этого можно назвать то, что количество веб-пользователей гораздо больше, чем тех, кто применяет обычные приложения. При этом получается так, что возможности обычных приложений, доступные в веб-проектах, создают знакомую среду для тех пользователей, которые привыкли к подобным возможностям, работая с обычными приложениями. В результате таким пользователям нет необходимости возвращаться к обычным приложениям.
В этом репозитории можно найти полный код проекта, которым мы занимались. Если вы освоили данный материал и хотите попрактиковаться в работе с различными возможностями PWA — загляните сюда.
Планируете ли вы пользоваться инструментами для распознавания лица и голоса в своих веб-проектах?
