Привет, Хабр! Меня зовут Александр Зинин, я разработчик платформы управления данными киберразведки R-Vision Threat Intelligence Platform (TIP).
В проекте TIP мы используем актуальный стек технологий: React для фронта, Node.js и TypeScript для не особо нагруженного бэкенда, Rust для тех мест, где важна предсказуемость и скорость. В части БД у нас достаточно стандартный набор: PostgreSQL, Redis, RocksDB, ClickHouse.
В статье я поделюсь нашей внутренней кухней, расскажу, как с архитектурной точки зрения у нас работает логика загрузки и хранения различных сущностей, помогающих расследовать инциденты безопасности.

Идем на сторону: как различные сущности попадают в систему
По сути R-Vision TIP — это база знаний, но довольно специфическая и с широкими возможностями автоматизации действий с собираемыми данными. Данные киберразведки, или threat intelligence, для управления которыми предназначена система, — это знания об угрозах. Для эффективного использования этих данных в дальнейшем нам нужно разложить их по детерминированным сущностям нашей внутренней модели (схемы) данных. Если упростить, то можно выделить следующие типы сущностей:
Индикаторы компрометации — объекты, которые указывают на вероятность проникновения злоумышленника в наблюдаемую систему, то есть факт её компрометации. Например, IP-адрес, с которого была зафиксирована рассылка управляющих команд в ботнет-сеть, или хеш-сумма файла вируса-вымогателя.
Контекст — объекты, описывающие доступный контекст для анализа индикаторов компрометации. Контекст помогает ИБ-специалистам рассмотреть подробности возможной угрозы и на основании этих данных эффективнее разработать комплекс мер по её предотвращению или ликвидации. Например, это может быть отчет исследовательской группы или информация об уязвимом программном обеспечении. Подробнее про контекст можно почитать в одной из статей нашего цикла про Threat Intelligence.
Если еще проще, то индикаторы компрометации позволяют технически обнаружить факт произошедшей (происходящей) атаки, а контекст — ответить на вопросы «кто атакует?», «почему атакует?» (какая мотивация), «как атакует?» (техники, тактики и процедуры злоумышленника).
Перечисленные сущности не являются статичными объектами. Поставщики могут изменить или удалить данные, к тому же эта информация может попросту устареть. Важно следить за всеми изменениями, чтобы сохранять актуальность данных. При этом мы имеем десятки и более источников TI , которые могут не только предоставлять уникальные данные, но и дополнять друг друга.
Один из основных вызовов, который стоит перед нами, — это предоставление удобной и производительной платформы для обеспечения загрузки, хранения, доступа и редактирования всех сущностей системы. Удобство заключается в возможности сокращать время реагирования на инциденты безопасности и получать актуальную картину угроз. Производительность нужна для оперативного получения актуальных данных киберразведки, количество которых может перевалить за десяток миллионов сущностей.
Путь TI-сущностей в системе начинается с их загрузки из внешних источников. В TIP основными источниками являются каналы данных — тематические подборки индикаторов компрометации и контекста (чаще можно встретить термин «фид» — мы писали об этом в одной из статей цикла про TI). В свою очередь, каналы объединены в группы, которые называются «Поставщики данных». Представьте, что существует площадка для обмена данными киберразведки Threat Data Sharing Platform, которая позволяет пользователям создавать собственные списки с различными сущностями. В этом случае Threat Data Sharing Platform будет поставщиком данных, а пользовательские списки в TIP будут представлены как каналы.
Пути получения данных из каналов могут быть различными. Обычно это простая загрузка zip-архива, внутри которого находится один JSON-файл, либо получение данных через HTTP API, но бывают и достаточно специфические кейсы вроде загрузки и парсинга PDF-файлов из почтовых ящиков.
За загрузку данных у нас отвечает микросервис providers. Он написан на Node.js и TypeScript. Node.js имеет классные инструменты для работы с сетью, хорошо перерабатывает данные в потоке и позволяет быстро разрабатывать новые загрузчики. TypeScript же дает нам возможность избавиться от ошибок формата «TypeError: some is null» и структурировать код.
У многих поставщиков есть свой формат хранения данных киберразведки. Некоторые поставщики предоставляют данные в структурированном виде — это упрощает нам выделение явных и неявных связей, и работать с такими данными удобно. Существует и обратная ситуация: неструктурированный формат добавляет сложности с выделением объектов и отношений между ними. Данные могут приходить недостаточно нормализованными или просто в формате, в котором содержатся различные ошибки (к счастью, это бывает нечасто). Например, один из достаточно крупных поставщиков может отдавать файлы формата CSV с неэкранированными именами файлов, и мы получаем что-то вроде:
ID, Filename, MD5, ...
...
2, nachalo f,evralya.exe;d,ok-y.exe, 94005A27A06000D790AE0009D1FC701B, ...
...Обходим мы это достаточно просто: находим регуляркой значение MD5 и начинаем плясать уже не от запятых.
Формат поставщиков мы преобразуем во внутреннее представление и выделяем необходимые связи. Выбор в пользу реализации нашей собственной схемы объектов возник не просто так. При использовании, например, STIX 2.*, нашей первой проблемой был бы формат связей (relationship в терминах STIX), и нам пришлось бы менять формат. Подводных камней, которые приводили бы к изменению оригинальной схемы, была бы масса, поэтому мы сразу реализовали свой внутренний формат. Он STIX-подобен, однако содержит меньшее количество объектов и ограничений. Также внутреннее представление не ограничивает нас в выборе алгоритмов обработки данных, что хорошо сказывается на общей производительности системы.
Для каждого канала у нас существует человекочитаемое представление преобразования схемы канала в схему R-Vision TIP (маппинг) и необходимый граф связей. В общем случае это представление выглядит так:
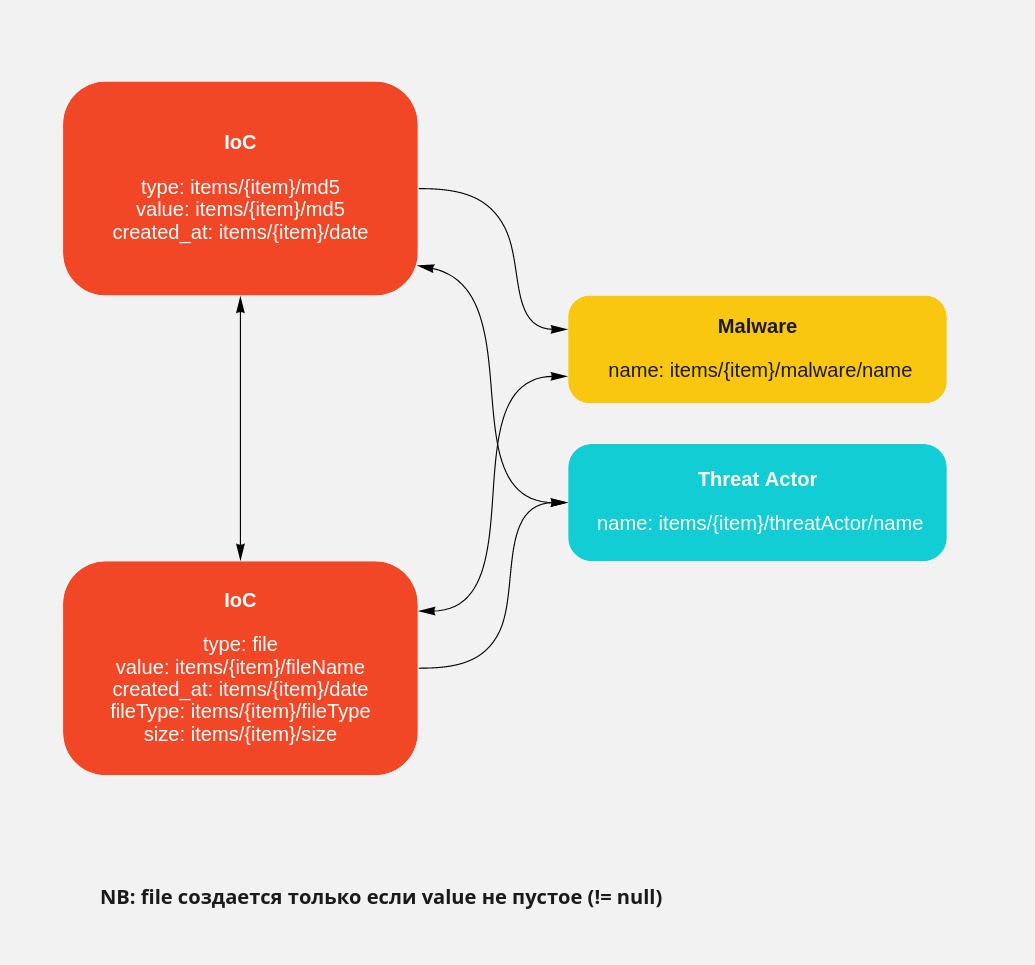
После преобразования мы упаковываем наши данные в чанки. Это JSON-объекты, которые хранят несколько вещей: уникальный ключ чанка, набор преобразованных сущностей из канала и связи между сущностями. Разделение на чанки нам нужно по достаточно простой причине: некоторые каналы могут присылать нам до 200 Мбайт чистых данных в формате JSON, а это около миллиона различных сущностей, и без адекватного разделения работать с ними, даже после преобразования, системе будет тяжело. Особенно если учесть, что на эти N сущностей может приходиться в худшем случае N*x связей.
Из сформированных чанков мы создаем файл формата JSONL, который записываем в хранилище объектов MinIO. JSONL мы выбрали, так как всегда храним в файле массив объектов, и использовать чистый JSON тут было бы несколько расточительно.
Отмечу, что ранее мы передавали чанки без промежуточной записи в MinIO, непосредственно через очередь сообщений NATS. По производительности проблем не было, но со временем появился неприятный момент: в процессе передачи больших объемов данных сервер NATS мог просто обрубить все подключения без объявления войны. Шаманства с конфигами и уменьшением порций данных помогли, но это был лишь временный костыль (который в итоге не стал постоянным!), и теперь обмен работает через MinIO.
После записи файла мы отправляем событие в сервис, отвечающий за хранение и быстрый доступ к данным, в котором и происходит основная магия.
Хранение сущностей: что за зверь intelligence-rs
После загрузки и преобразования в наш формат данные попадают в сервис хранения, который у нас называется intelligence-rs. Почему «rs»? А потому что он написан на Rust!
Изначально этот сервис был написан, как и providers, на связке TypeScript и Node.js, но мы решили уходить на Rust, и вот почему:
Rust имеет лучшую производительность — как было отмечено выше, некоторые каналы могут прислать нам около миллиона сущностей за раз, и нам нужно все это обработать за адекватное время. Продукт представляет собой on-premise решение, и мы ограничены только вертикальным масштабированием на площадках наших клиентов, да и не всегда бывают достаточные ресурсы для быстрого масштабирования.
Лучшая работа с памятью — гонять через intelligence-rs нам приходится большое количество объектов. Zero-cost абстракции вкупе с отсутствием сборщика мусора помогают нам работать с ОЗУ в более «щадящем» режиме. Это важно, так как производительность оборудования у клиентов может различаться.
Строгая типизация и, как следствие, уменьшение ошибок из разряда «undefined is not a function». TIP участвует в защите IT-инфраструктуры, и отказоустойчивость тут играет важную роль при выборе технологий. Конечно, мы использовали TypeScript, который тоже предоставляет возможности типизации, но Rust, как ни крути, будет в этом плане гораздо мощнее.
Конечно, есть еще и минусы, но, чтобы не сваливаться в обсуждение «чем же так хорош/плох Rust», поделюсь только тем, что я заметил во время перехода. Переход на Rust мы совершили достаточно резко и изначально делали силами команды, которая на 90% состояла из JS/Node-разработчиков. Получалось так, что каждый начинал работать с Rust практически с нуля. И это далеко не тот язык, на котором можно начать эффективно писать за месяц разработки. Например, я с ним был знаком исключительно по статьям на Хабре и новостям на Лоре, но, тем не менее, брал на себя сразу продуктовые задачи, и процесс «вкатывания» в язык прошел для меня… скажем так, болезненно и с большим влиянием на скорость разработки. Я работаю с Rust уже более полугода и не могу сказать, что могу на нем писать с высоким личным КПД. Но хотя бы теперь компилятор для меня друг, а не нечто, которое ругает за каждый шаг.
Когда intellingence-rs получает новый файл, в котором хранятся чанки данных, мы считываем этот файл, из каждого чанка достаем сущность и записываем её в RocksDB (если кратко, RocksDB — это быстрое key-value хранилище от Facebook) со следующим ключом:
Тип сущности (1 байт);
UUID сущности (16 байт);
Идентификаторы поставщика и канала данных (4 + 4 байт);
UUID чанка (16 байт).
Но что делать, если RocksDB уже хранит сущность с таким ключом? Тут начинает включаться механизм под названием «слияние сущностей». Слияние сущностей — это набор правил, который описывает то, как мы будем работать с конфликтующими данными у различных объектов. Например, для поля «дата публикации» алгоритм выберет самую раннюю дату. Или если мы имеем несколько массивов с различными тегами у отчета, то в агрегат попадут уникальные значения из всех объектов сущности. Типов поставщиков данных может быть несколько: канал, пользователь, внешний публичный API самого TIP, — и от них будет зависеть работа с конкретной записью. Для упрощения давайте представим, что все сущности у нас равноправны и мы просто перезаписываем данные.
Отлично, мы загрузили все файлы, обработали все чанки, записали в RocksDB все сущности, что дальше? А дальше мы должны сгенерировать снепшоты для наших сущностей.
Снепшот — это агрегация всех данных для сущности из одного канала. Генерация снепшота реализована просто: получаем все данные из RocksDB с префиксом вида [Тип сущности + UUID сущности + идентификаторы поставщика и канала данных] и при помощи правил слияния получаем итоговый объект снепшота.
После этого снепшот записываем в RocksDB под определенным ключом:
Тип сущности, который хранит снепшот (1 байт);
UUID сущности (16 байт);
Тип поставщика данных (1 байт);
Идентификаторы поставщика и канала данных (4 + 4 байт).
И вот, у нас есть снепшоты, которые являются агрегатами сущностей из одного канала. А дальше нам нужно получить самый главный агрегат, который содержит в себе данные из всех каналов.
Сборка этого финального агрегата очень похожа на сборку снепшота. Мы получаем из RocksDB все снепшоты по префиксу, а затем, применяя правила слияния, получаем готовый объект. За одним небольшим исключением: финальный агрегат содержит информацию обо всех источниках данных, которые принимали участие в сборке агрегата, тогда как сущности и снепшот хранят только своего «родителя».
Если рассматривать схематично, то вот примерный путь данных:
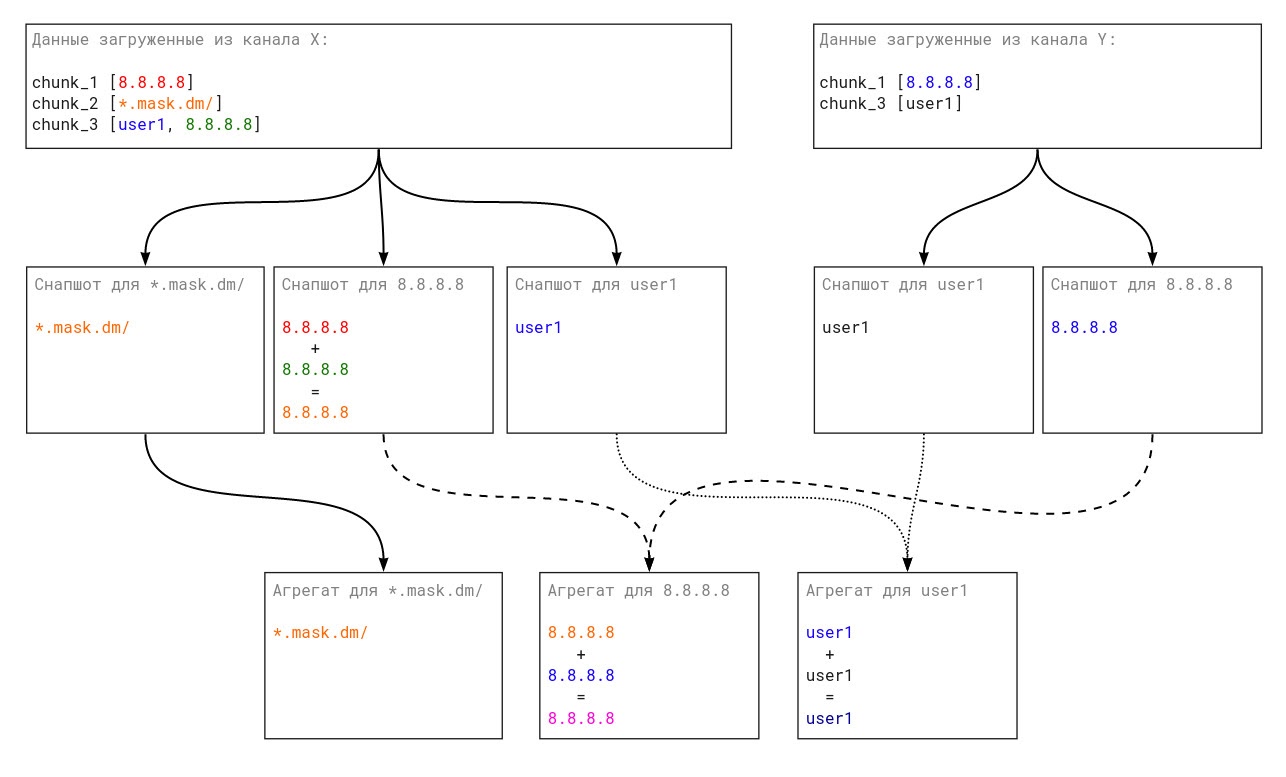
Конечно, на каждом этапе мы применяем набор определенных оптимизаций. Например, не перезаписываем и не пересчитываем данные сущностей, если они не изменились.
Форматом для хранения всех данных в RocksDB мы выбрали Cap’n Proto. JSON в этой задаче был бы избыточным и менее быстрым. После перехода как минус мы были вынуждены писать скрипты миграций при несовместимости capnp-схемы новой версии с предыдущей, но в данном случае производительность того стоит.
Если говорить про связи между сущностями, то они реализованы следующим образом: в каждом объекте сущности присутствует набор с ключом linked_entities, который содержит в себе ключи связанных сущностей, и по правилам слияния мы просто объединяем эти наборы. Все связи в системе двусторонние (то есть при наличии связи A -> B должна существовать и B -> A), поэтому при обновлении данных нам может понадобиться пересчитать снепшот или агрегат сущности для обновления списка связей, хотя данные самой сущности не изменились. Для этого у нас имеется еще один тип объекта, который похож на сущность, но отвечает только за хранение связей между объектами.
У внимательных читателей может возникнуть вопрос: а почему бы нам не отказаться от снепшотов, которые технически являются агрегатами данных от одного канала, и сразу не составлять финальный агрегат, ощутимо упростив систему хранения? Причина в том, что нам необходимо отображать пользователю детальную информацию о том, из каких данных собран конечный агрегат. Например, какая-либо сущность может иметь данные от нескольких каналов, а также данные, которые создал сам пользователь. ИБ-специалисту будет очень удобно знать, откуда, например, у индикатора компрометации появилась связь со свежей уязвимостью. Можно, конечно, отображать вместо снепшотов сырую информацию о сущностях, получаемую от поставщиков разных типов без какой-либо группировки, но это сильно снижает удобство восприятия.
Стоит отметить, что мы также храним в системе историю изменения каждой сущности системы. Раньше история содержала в себе вообще все: сырые данные от канала, дату и время, а также название канала. Из-за этого у нас возникла проблема разрастания БД с сущностями: за неделю объем данных мог вырасти до 100 Гбайт, и это могло заполнить диск у пользователя. Для уменьшения системных требований мы убрали из истории сырые данные, что позволило сократить объем данных на порядок. Следующий наш шаг — сделать систему более похожей на event sourcing и хранить только изменения.
Финальный агрегат мы храним уже не в RocksDB, а записываем в PostgreSQL. Именно его мы используем как основное хранилище агрегатов всех сущностей системы. PostgreSQL отлично справляется с этой ролью: на таблице размером около 5 миллионов сущностей различные фильтрации по полям отрабатывают за приемлемое время — чуть менее 2 секунд на 4 ядрах от процессора AMD EPYC 7502 + SSD.
Заключение
Для ИБ-специалистов TIP является вспомогательным элементом, что накладывает на нас определенные ограничения в плане системных требований. Нам требуется оперативно обрабатывать большие объемы данных, так как смягчение системных требований не приводит к снижению требований по отклику работы системы. Мы добиваемся необходимой производительности посредством архитектуры обработки и хранения данных. Сейчас наше решение показывает достаточную производительность на относительно больших объемах данных, но мы понимаем ответственность и не расслабляемся, постоянно дорабатываем наши технологические решения, чтобы предоставлять пользователям лучший опыт взаимодействия. Ведь от этого напрямую зависит безопасность IT-инфраструктуры.
