
Привет! Меня зовут Глеб Гончаров, и я руковожу подгруппой ИТ-инфраструктуры в СберМаркете. В работе мы широко используем Kafka как шину данных для микросервисов и не раз убедились на практике, что к инструменту важно подобрать правильный подход. Об этом сегодня и поговорим в двух частях — сначала обсудим основы, а в конце статьи будет ссылка на практические задания.
В теоретической части мы:
Предыстория
Долгое время инженеры разрабатывали программы, которые оперируют объектами реального мира и сохраняют состояние о них в базы данных. Это могли быть пользователи, заказы или товары. Представление о вещах мира как объектах широко распространено в парадигме ООП и разработке в целом. Но всё больше современных компаний оперируют не самими объектами, а событиями, которые они порождают.

Компании стремятся снизить тесную связь сервисов друг с другом и улучшить устойчивость приложений к сбоям за счёт изоляции поставщиков данных и их потребителей. Этот запрос вместе с популярностью микросервисной архитектуры как раз и популяризует событийно-ориентированный подход.
События в системах можно хранить в традиционных реляционных базах данных так же как объекты. Но делать так громоздко и неэффективно. Вместо этого мы используем структуру под названием лог, о которой и поговорим далее.
Как устроен Apache Kafka
TLDR
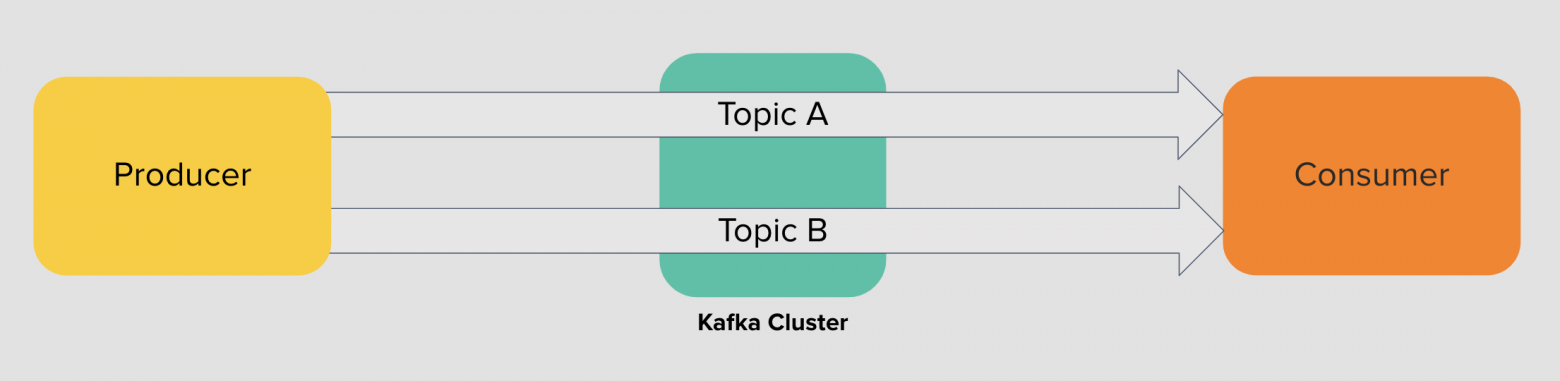
Основы кластера Kafka — это продюсер, брокер и консумер. Продюсер пишет сообщения в лог брокера, а консумер его читает.
Лог — это упорядоченный поток событий во времени. Событие происходит, попадает в конец лога и остаётся там неизменным.

Apache Kafka управляет логами и организует платформу, которая соединяет поставщиков данных с потребителями и даёт возможность получать упорядоченный поток событий в реальном времени.

Продюсеры
Для записи событий в кластер Kafka есть продюсеры — это приложения, которые вы разрабатываете.

Программа-продюсер записывает сообщение в Kafka, тот сохраняет события, возвращает подтверждение о записи или acknowledgement. Продюсер получает его и начинает следующую запись.
Брокеры
Кластер Kafka состоит из брокеров. Можно представить систему как дата-центр и серверы в нём. При первом знакомстве думайте о Kafka-брокере как о компьютере: это процесс в операционной системе с доступом к своему локальному диску.

Все брокеры соединены друг с другом сетью и действуют сообща, образуя единый кластер. Когда мы говорим, что продюсеры пишут события в Kafka-кластер, то подразумеваем, что они работают с брокерами в нём.
Кстати, в облачной среде кластер не обязательно работает на выделенных серверах — это могут быть виртуальные машины или контейнеры в Kubernetes.
Консумеры
События, которые продюсеры записывают на локальные диски брокеров, могут читать консумеры — это тоже приложения, которые вы разрабатываете. В этом случае кластер Kafka — это по-прежнему нечто, что обслуживается инфраструктурой, где вы как пользователь пишете продюсеров и консумеров. Программа-консумер подписывается на события или поллит и получает данные в ответ. Так продолжается по кругу.

Архитектура Kafka
TLDR
Кластер Kafka позволяет изолировать консумеры и продюсеры друг от друга. Продюсер ничего не знает о консумерах при записи данных в брокер, а консумер ничего не знает о продюсере данных.
Посмотрим на архитектуру Kafka более внимательно. Слева есть продюсеры, в середине брокеры, справа — консумеры. Инструмент представляет собой группу брокеров, связанных с Zookeeper-кворумом. Kafka использует Zookeeper для достижения консенсуса состояния в распределённой системе: есть несколько вещей, с которыми должен быть «согласен» каждый брокер и Zookeeper помогает достичь этого «согласия» внутри кластера.

Zookeeper — это выделенный кластер серверов для образования кворума-согласия и поддержки внутренних процессов Kafka. Благодаря этому инструменту мы можем управлять кластером Kafka: добавлять пользователей и топики, задавать им настройки.

Также Zookeeper помогает обнаружить сбои контроллера, выбрать новый и сохранить работоспособность кластера Kafka. А ещё он хранит в себе все авторизационные данные и ограничения или Access Control Lists при работе консумеров и продюсеров с брокерами.
Устройство брокеров
TLDR
Топики в Kafka разделены на партиции. Увеличение партиций увеличивает параллелизм чтения и записи. Партиции находятся на одном или нескольких брокерах, что позволяет кластеру масштабироваться.
Партиции хранятся на локальных дисках брокеров и представлены набором лог-файлов — сегментов. Запись в них идёт в конец, а уже сохранённые события неизменны.
Каждое сообщение в таком логе определяется порядковым номером — оффсетом. Этот номер монотонно увеличивается при записи для каждой партиции.
Лог-файлы на диске устаревают по времени или размеру. Настроить это можно глобально или индивидуально в каждом топике.
Для отказоустойчивости, партиции могут реплицироваться. Число реплик или фактор репликации настраивается как глобально по умолчанию, так и отдельно в каждом топике.
Реплики партициий могут быть лидерами или фолловерами. Традиционно консумеры и продюсеры работают с лидерами, а фолловеры только догоняют лидера.
Перейдём к брокерам и рассмотрим их детальнее. Начать здесь стоит с топиков, о которых вы наверняка много раз слышали.
Топики
Топик — это логическое разделение категорий сообщений на группы. Например, события по статусам заказов, координат партнёров, маршрутных листов и так далее.
Ключевое слово здесь — логическое. Мы создаём топики для событий общей группы и стараемся не смешивать их друг с другом. Например, координаты партнёров не должны быть в том же топике, что и статусы заказов, а обновлённые статусы по заказам не стоит складывать вперемешку с обновлением регистраций пользователей.
Топик удобно представлять как лог — вы пишете событие в конец и не разрушаете при этом цепочку старых событий. Общая логика:
Один продюсер может писать в один или несколько топиков
Один консумер может читать один или несколько топиков
В один топик могут писать один или более продюсеров
Из одного топика могут читать один или более консумеров
Теоретически, нет никаких ограничений на число этих топиков, но практически это ограничено числом партиций.
Партиции и сегменты
Ограничений на количество топиков в кластере Kafka нет, но есть ограничения самого компьютера. Он выполняет операции на процессоре, вводе-выводе, и в итоге упирается в свой предел. Мы не можем увеличивать мощность и производительность машин бесконечно, а потому топик следует делить на части.

В Kafka эти части называются партициями. Каждый топик состоит из одной или более партиций, каждая из которых может быть размещена на разных брокерах. За счёт этого Kafka может масштабироваться: пользователь может создать топик, разделить его на партиции и разместить каждую из них на отдельном брокере.
Формально партиция и есть строго упорядоченный лог сообщений. Каждое сообщение в ней добавлено в конец без возможности изменить его в будущем и как-то повлиять на уже записанные сообщения. При этом сам топик в целом не имеет никакого порядка, но порядок сообщений всегда есть в одной из его партиций.
Сами партиции физически представлены на дисках в виде сегментов. Это отдельные файлы, которые можно создать, ротировать или удалить в соответствии с настройкой устаревания данных в них. Обычно вам не приходится часто вспоминать о сегментах партиций, если вы не администрируете кластер, но важно помнить саму модель хранения данных в топиках Kafka.
Разберём детали на примере. В кластере Kafka есть три брокера: 101, 102 и 103. Топик A отмечен бирюзовым, топик B — жёлтым, C — оранжевым. На картинке у каждого топика по три партиции, но их число может быть разным и настраивается для каждого топика.
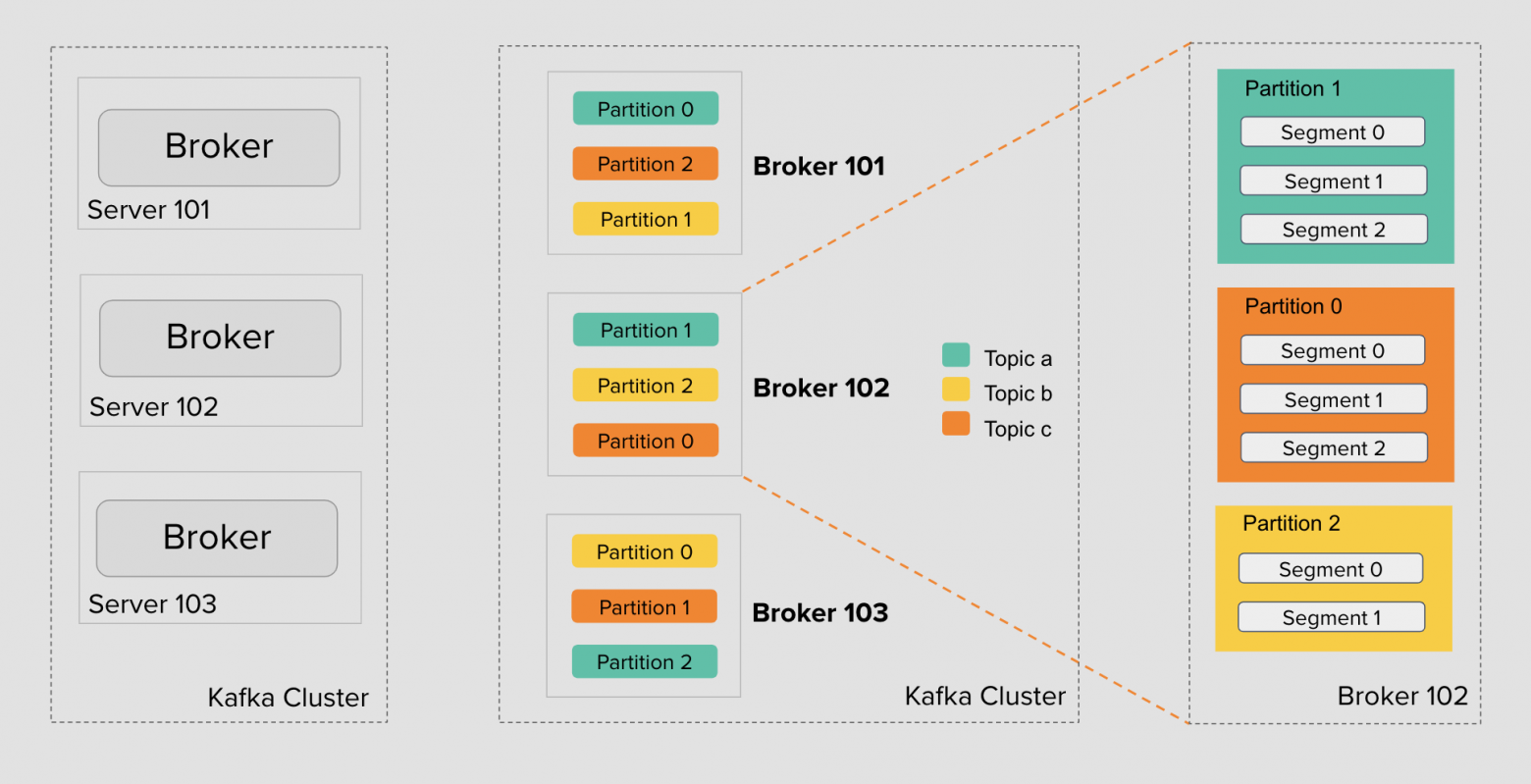
Партиции распределены между брокерами — кластер Kafka делает это автоматически при создании топика. Инструмент автоматически не следит за размером каждой партиции, не занимается ребалансировкой записи и чтения в кластере, не перемещает партиции между брокерами. Для этого уже существуют opensource-инструменты и готовые enterprise-платформы как Confluent, но сейчас для нас это не важно.
Каждая партиция на брокере представлена набором сегментов. Число сегментов у партиций тоже может быть разным. Оно варьируется в зависимости от интенсивности записи и настроек размера сегмента.
В итоге, мы можем увеличивать число брокеров в кластере и тем самым масштабировать систему. Kafka поддерживает добавление или удаление брокеров. А с помощью встроенных инструментов можно, например, переносить партиции между брокерами чтобы равномерно их распределять.
Можно также добавлять новые партиции в топике — это увеличит параллелизм записи и чтения со стороны продюсера и консумера.
Наконец, можно изменять настройки сегментов, чтобы управлять частотой и интенсивностью ротации отдельных файлов на дисках брокеров. Рассмотрим устройство сегмента подробнее
Поток данных как лог
Сегмент тоже удобно представить как обычный лог-файл: каждая следующая запись добавляется в конец файла и не меняет предыдущих записей. Фактически это очередь FIFO (First-In-First-Out) и Kafka реализует именно эту модель.
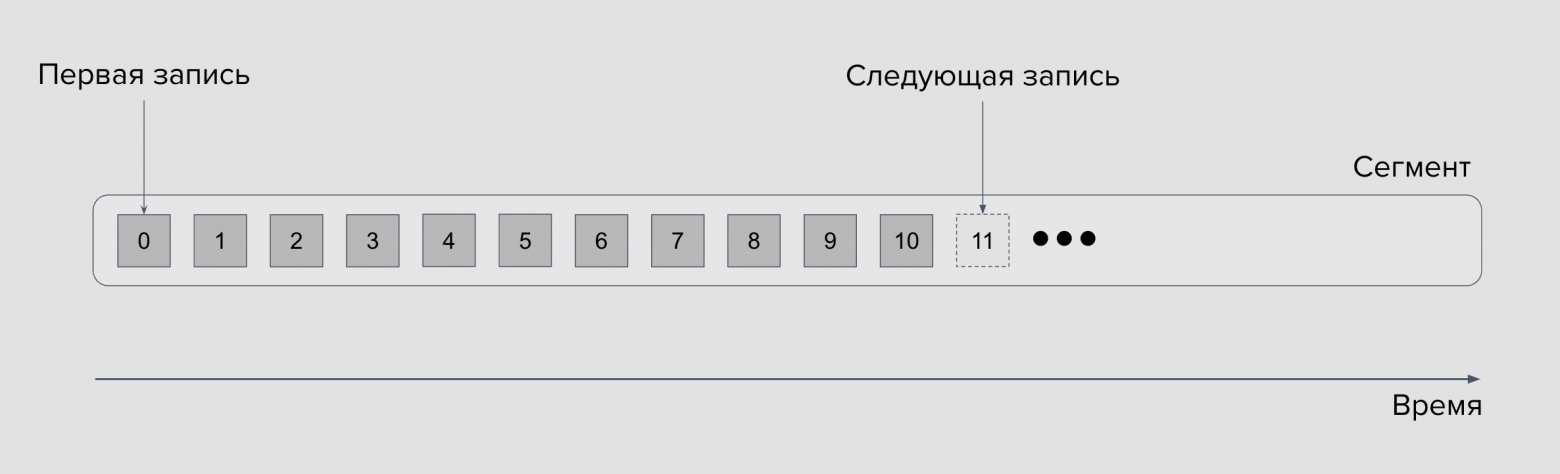
Семантически и физически сообщения внутри сегмента не могут быть удалены, они иммутабельны. Всё, что мы можем — указать, как долго Kafka-брокер будет хранить события через настройку политики устаревания данных или Retention Policy.
Числа внутри сегмента — это реальные сообщения системы, у которых есть порядковые номера или оффсеты, что монотонно увеличиваются со временем. У каждой партиции свой собственный счётчик, и он никак не пересекается с другими партициями — позиции 0, 1, 2, 3 и так далее у каждой партиции свои. Таким образом, продюсеры пишут сообщения в партиции, а брокер адресует каждое из таких сообщений своим порядковым номером.
Помимо продюсеров, что пишут сообщения, есть консумеры, которые их читают. У лога может быть несколько консумеров, которые читают его с разных позиций, и не мешают друг другу. А ещё у консумеров нет жёсткой привязки к чтению событий по времени. При желании они могут читать спустя дни, недели, месяцы, или вовсе несколько раз спустя какое-то время.

Начальная позиция первого сообщения в логе называется log-start offset. Позиция сообщения, записанного последним — log-end offset. Позиция консумера сейчас — current offset.

Расстояние между конечным оффсетом и текущим оффсетом консумера называют лагом — это первое, за чем стоит следить в своих приложениях. Допустимый лаг для каждого приложения свой, это тесно связано с бизнес-логикой и требованиями к работе системы.
Теперь пора посмотреть, из чего состоит отдельное сообщение Kafka. Если упростить, то структура сообщения представлена опциональными заголовками. Они могут быть добавлены со стороны продюсера, ключом партицирования, пэйлоадом и временем или timestamp.
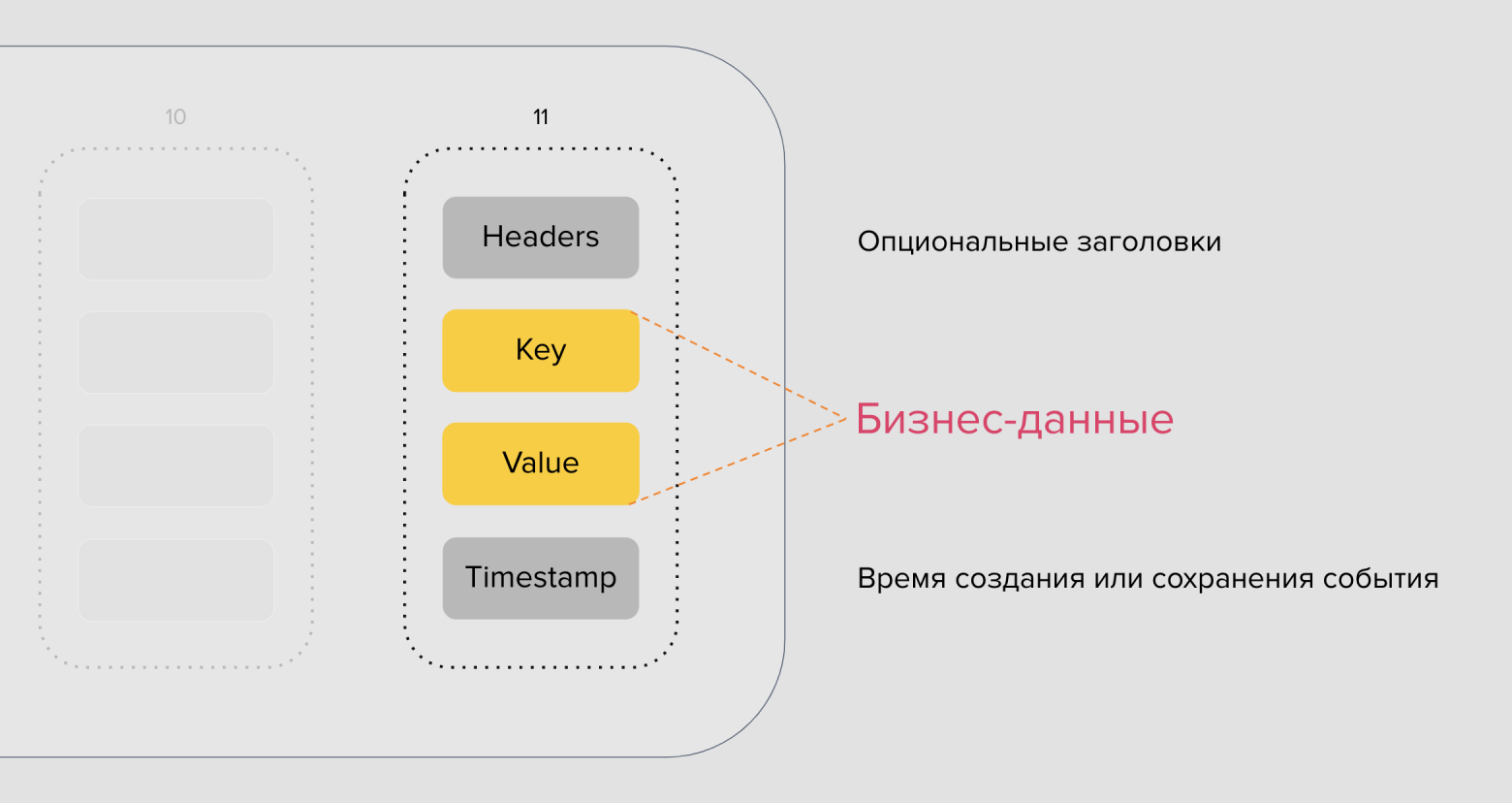
Каждое событие — это пара ключ-значение. Ключ партицирования может быть любой: числовой, строковый, объект или вовсе пустой. Значение тоже может быть любым — числом, строкой или объектом в своей предметной области, который вы можете как-то сериализовать (JSON, Protobuf, …) и хранить.
В сообщении продюсер может указать время, либо за него это сделает брокер в момент приёма сообщения. Заголовки выглядят как в HTTP-протоколе — это строковые пары ключ-значение. В них не следует хранить сами данные, но они могут использоваться для передачи метаданных. Например, для трассировки, сообщения MIME-type, цифровой подписи и т.д.
Устаревание данных
В контексте сегментов стоит вспомнить и об их ротации. Когда сегмент достигает своего предела, он закрывается и вместо него открывается новый. Сегмент, в который сейчас записываются данные, называют активным сегментом — по-сути это файл, открытый процессом брокеры. Закрытыми же называются те сегменты, в которых больше нет записи.

Максимальную длину сегмента в байтах можно настроить глобально или индивидуально на каждый топик. Его размер определяет как часто старые файлы будут сменять новые. Если вы пишете много больших сообщений, следует увеличивать размер сегмента и, наоборот, не следует использовать большие сегменты, если вы редко пишете маленькие сообщения.
Простыми словами, настроенная политика устаревания не означает, к примеру, что из топика пропадут события старше 7 дней. Kafka удаляет закрытые сегменты партиций, а число таких партиций зависит от размера сегмента и интенсивности записи в партиции.
Но ничто не мешает хранить сообщения дольше или совсем их не удалять. Для хранения исторических данных в инструменте нет никаких ограничений, кроме размера дисков и числа брокеров, чтобы эти данные хранить.
Репликация данных
Если одна партиция будет существовать на одном брокере, в случае сбоя часть данных станет недоступной. Такая система будет хрупкой и ненадёжной. Для решения проблемы Kafka представляет механизм репликации партиций между брокерами.

У каждой партиции есть настраиваемое число реплик, на изображении их три. Одна из этих реплик называется лидером, остальные — фолловерами. Продюсер подключается к брокеру, на котором расположена лидер-партиция, чтобы записать в неё данные.

Записанные в лидера данные автоматически реплицируются фолловерами внутри кластера Kafka. Они подключаются к лидеру, читают данные и асинхронно сохраняют к себе на диск. В настроенном кластере Kafka репликация обычно занимает доли секунд.
Консумеры со своей стороны также читают из лидерской партиции — это позволяет достичь консистентности при работе с данными. Задача фолловеров здесь как и в предыдущем случае сводится к копированию данных от лидера.
С версии 2.4 Kafka поддерживает чтение консумерами из фолловеров, основываясь на их взаимном расположении. Это полезно для сокращения задержек при обращении к ближайшему брокеру в одной зоне доступности. Однако, из-за асинхронной работы репликации, взамен вы получаете от фолловеров менее актуальные данные, чем они есть в лидерской партиции.

Роли лидеров и фолловеров не статичны. Kafka автоматически выбирает роли для партиций в кластере. Например, в случае сбоя брокера, роль лидера достанется одной из реплик, а консумеры и продюсеры должны получить обновления согласно протоколу и переподключиться к брокерам с новыми лидерами партиций.
Продюсеры
TLDR
Продюсеры самостоятельно партицируют данные в топиках и сами определяют алгоритм партицирования: он может быть как банальный round-robin и hash-based, так и кастомный. Важно помнить, что очерёдность сообщений гарантируется только для одной партиции.
Продюсер сам выбирает размер батча и число ретраев при отправке сообщений. Протокол Kafka предоставляет гарантии доставки всех трёх семантик: at-most once, at-least once и exactly-once.
У exactly once есть цена. Для надёжной записи вам необходимо использовать подтверждение как от лидера, так и от реплик, включить идемпотентность и использовать транзакционный API. Всё это негативно влияет на время записи.
Не забывайте, что сломаться в пути может что угодно: например, просесть сеть или сломаться сам брокер. Переходящие процессы в кластере, как выбор лидера, редкость, но это случается, и клиенты должны уметь их грамотно обрабатывать.
Если вы хотите писать в Kafka надёжно, указывайте при создании топика min.insync.replicas меньше, чем общее количество реплик. В противном случае, лишившись брокера в случай аварии вы рискуете вовсе ничего не записать, т.к. не дождётесь подтверждения записи.
Если вы указываете acks=all, то включайте и enable.idempotence. Накладных расходов на идемпотентность нет.
После брокеров логично перейти к продюсерам и понять принцип их работы. Продюсеры пишут сообщения в партиции, партиции расположены на брокерах. Возникает вопрос — как продюсер узнаёт о том, какое сообщение и в какую партицию ему записать?
Балансировка и партицирование

Программа-продюсер может указать ключ у сообщения и сама определяет номер партиции, например, разделяя вычисленный хеш на число партиций. Так она сохраняет сообщения одного идентификатора в одну и ту же партицию. Эта распространённая стратегия партицирования позволяет добиться строгой очерёдности событий при чтении за счёт сохранения сообщений в одну партицию, а не в разные.
Например, ключом может быть номер карты при установке и сброса динамического лимита. В таком случае мы гарантируем, что события по одной карте будут следовать строго в порядке их записи в партицию и никак иначе.
Если программа-продюсер не указывает ключ, то стратегия партицирования по умолчанию называется round-robin — сообщения будут попадать в партиции по очереди. Эта стратегия хорошо работает в ряде бизнес-сценариев, где важна не очерёдность событий, а равномерное распределение сообщений между партициями.
Также существуют List-based partitioning, Composite partitioning, Range-based partitioning и другие алгоритмы, каждый из которых подходит для своих задач. Вся логика реализации партицирования данных реализуется на стороне продюсера.
Дизайн продюсера
Типичная программа-продюсер работает так: пэйлоад упаковывается в структуру с указанием топика, партиции и ключа партицирования. Далее пэйлоад сериализуется в подходящий формат — JSON, Protobuf, Avro или ваш собственный формат с поддержкой схем. Затем сообщению назначается партиция согласно передаваемому ключу и выбранному алгоритму. После этого она группируется в пачки выбранных размеров и пересылается брокеру Kafka для сохранения.
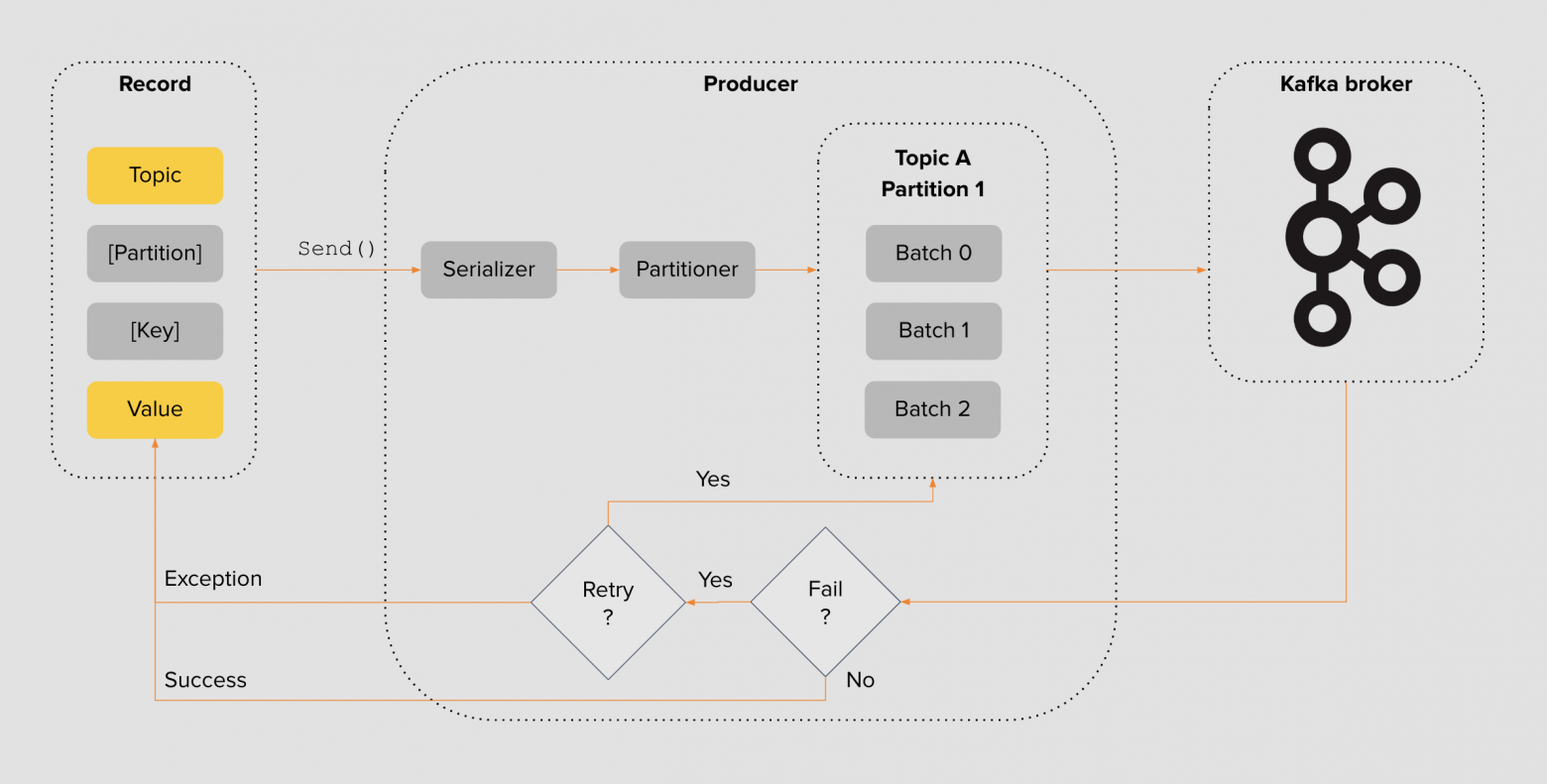
В зависимости от настроек продюсер дожидается окончания записи в кластере Kafka и ответного подтверждающего сообщения. Если продюсер не смог записать сообщение, он может попытаться отправить сообщение повторно — и так по кругу.
Каждый параметр в цепочке может индивидуально настроить каждый продюсер. Например, вы можете выбрать алгоритм партицирования, определить размер батча, оперируя балансом между задержкой и пропускной способностью, а также выбрать семантику доставки сообщений.
Семантики доставки
В любых очередях есть выбор между скоростью доставки и расходами на надёжность. Цветные квадратики на слайде — это сообщения, которые мы будем записывать в очередь, выбирая нужную из семантик.
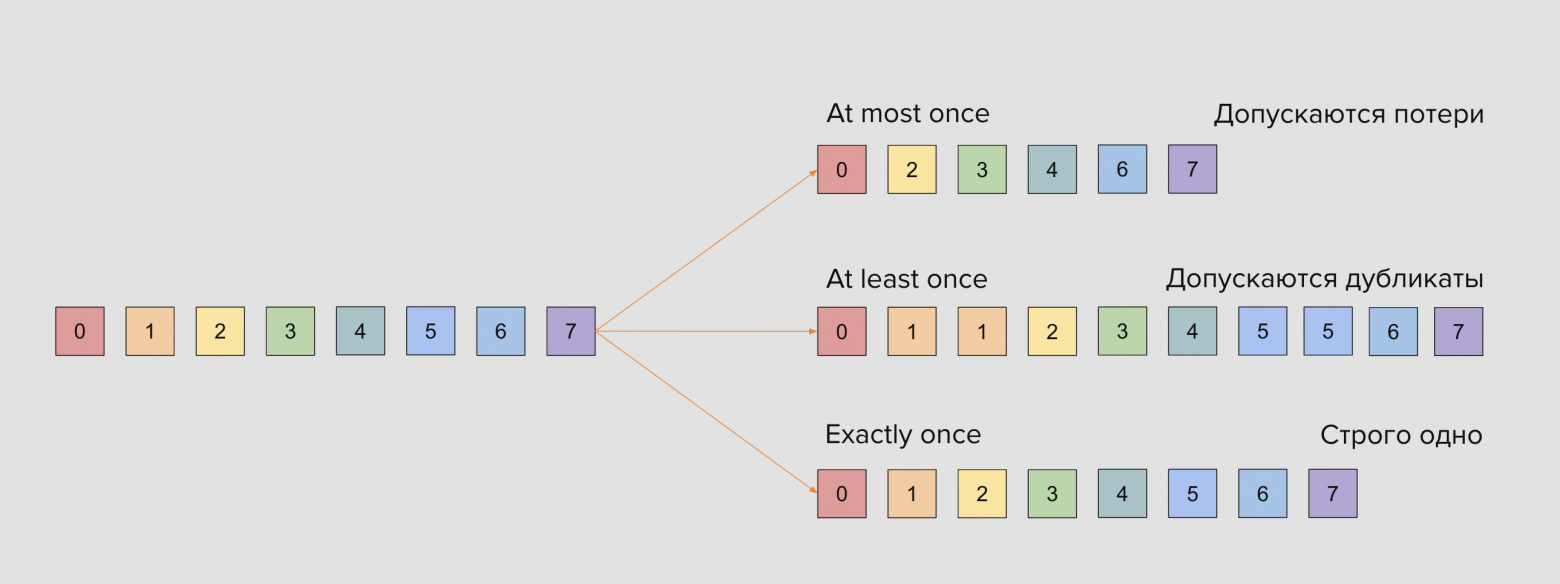
Семантика at-most once означает, что при доставке сообщений нас устраивают потери сообщений, но не их дубликаты. Это самая слабая гарантия, которую реализуют брокерами очередей
Семантика at-least once означает, что мы не хотим терять сообщения, но нас устраивают возможные дубликаты
Семантика exactly-once означает, что мы хотим доставить одно и только одно сообщение, ничего не теряя и ничего не дублируя.
На первый взгляд самой правильной для любого приложения кажется семантика exactly once, однако это не всегда так. Например, при передаче партнёрских координат вовсе не обязательно сохранять каждую точку из них, и вполне хватит at-most once. А при обработке идемпотентных событий нас вполне может и устроить дубль, если статусная модель предполагает его корректную обработку.
В распределённых системах у exactly-once есть своя цена: высокая надёжность означает большие задержки. Рассмотрим, какие инструменты предлагает Kafka для реализации всех трёх семантик доставки сообщений в брокер.
Надёжность доставки
Со стороны продюсера разработчик определяет надёжность доставки сообщения до Kafka с помощью параметра acks. Указывая 0 или none, продюсер будет отправлять сообщения в Kafka, не дожидаясь никаких подтверждений записи на диск со стороны брокера.
Это самая слабая гарантия. В случае выхода брокера из строя или сетевых проблем, вы так и не узнаете, попало сообщение в лог или просто потерялось.

Указывая настройку в 1 или leader, продюсер при записи будет дожидаться ответа от брокера с лидерской партицией — значит, сообщение сохранено на диск одного брокера. В этом случае вы получаете гарантию, что сообщение было получено по крайней мере один раз, но это всё ещё не страхует вас от проблем в самом кластере.
Представьте, что в момент подтверждения брокер с лидерской партиции выходит из строя, а фолловеры не успели отреплицировать с него данные. В таком случае вы теряете сообщение и снова не узнаёте об этом. Такие ситуации случаются редко, но они возможны.
Наконец, устанавливая acks в -1 или all, вы просите брокера с лидерской партицией отправить вам подтверждение только тогда, когда запись попадёт на локальный диск брокера и в реплики-фолловеры. Число этих реплик устанавливает настройка min.insync.replicas.
Частая ошибка при конфигурировании топика — выбор min.insync.replicas по числу реплик. При таком сценарии в случае выхода из строя брокера и потери одной реплики продюсер больше не сможет записывать сообщение в кластер, поскольку не дождётся подтверждения. Лучше предусмотрительно устанавливать min.insync.replicas на единицу меньше числа реплик.
Очевидно, что третья схема достаточно надёжна, но она требует больше накладных расходов: мало того, чтобы нужно сохранить на диск, так ещё и дождаться, пока фолловеры отреплицируют сообщения и сохранят их к себе на диск в лог.
Идемпотентные продюсеры
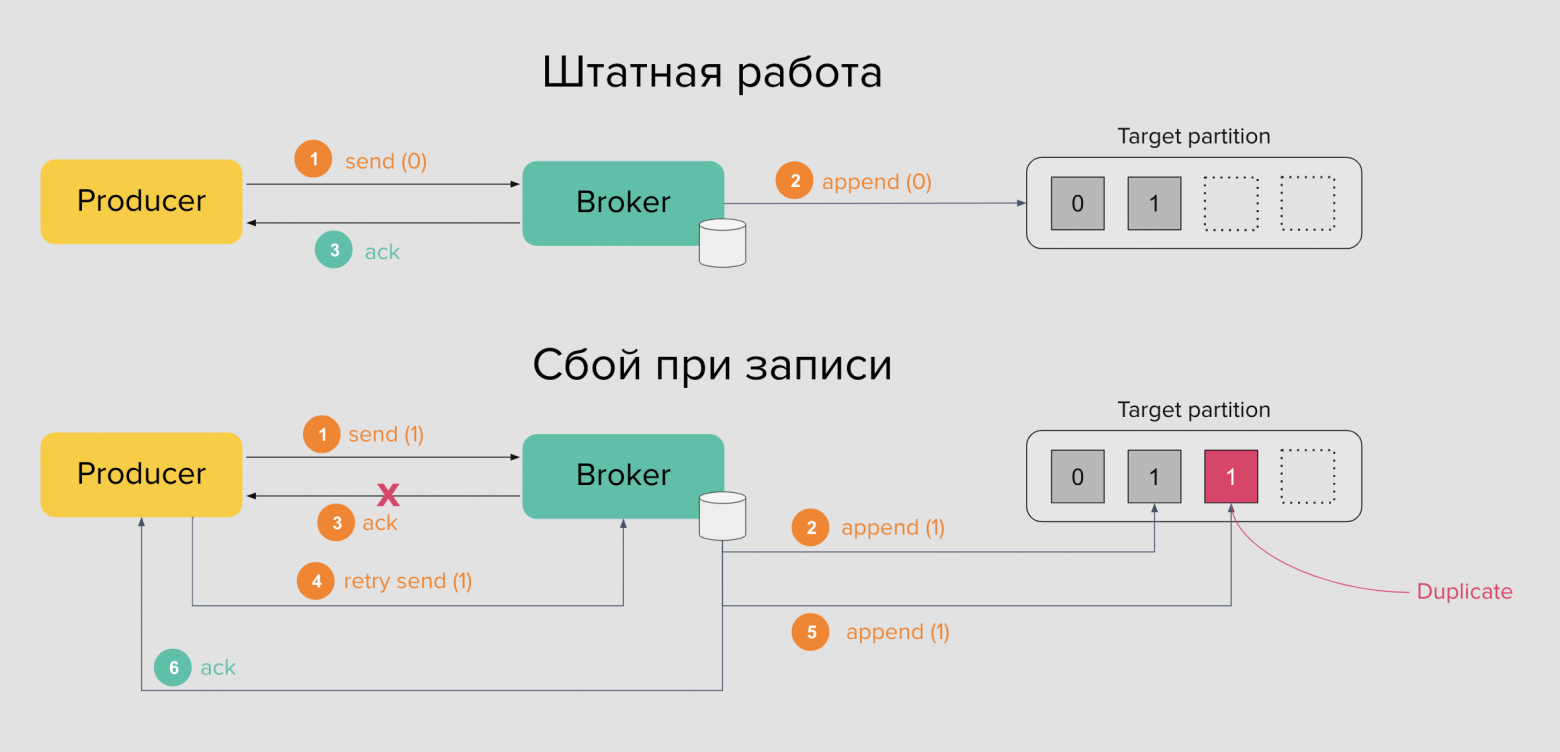
Даже с выбором acks=all возможны дубликаты сообщений. В штатном режиме работы продюсер отправляет сообщение брокеру, а тот сохраняет данные в логе на диске и отправляет подтверждение продюсеру. Последний снова формирует пачку сообщений и так далее. Но ни одна программа не застрахована от сбоев.
Что, если брокер не смог отправить подтверждение продюсеру из-за сетевых проблем? В таком случае, продюсер повторно отправляет сообщение брокеру. Брокер послушно сохраняет добавляет ещё одно сообщение в лог — появляется дубликат.
Эта проблема решается в Kafka благодаря транзакционному API и использованию идемпотентности. В брокере есть специальная опция, которая включает идемпотентность — enable.idempotence. Так каждому сообщению будет проставлен идентификатор продюсера или PID и монотонно увеличивающийся sequence number. За счёт этого сообщения-дубликаты от одного продюсера с одинаковым PID будут отброшены на стороне брокера.
Если говорить проще — когда вы используете acks=all, нет никаких причин не включать enable.idempotence для своих продюсеров. Так вы добьётесь гарантии exactly once при записи в брокер и избежите дубликатов. Но у этого могущества есть своя цена — запись будет идти дольше.
Консумеры
TLDR
Партиции в консумер-группах распределяет автоматически Group Coordinator при помощи Group leader — первого участника в группе. Каждый консумер в группе может читать одну и более партиций разных топиков. Если консумеру не достанется партиции, то он будет бездействовать, что мешает масштабированию.
Основное преимущество консумер-группы перед обычным консумером состоит в хранении оффсета партиций на стороне брокера. Это позволяет консумерам прерывать работу, а после возобновлять её с того же места, где они окончили чтение.
Для проверки живости консумеры отправляют брокеру Heartbeat-сообщение. Если консумер не успел отправить его, то может покинуть группу сам, либо брокер, который не получил подтверждение, сам удалит консумера из группы, что запустит ребалансировку.
Любая смена композиции партиций в топиках и участников в группе запускает ребалансировку. Это болезненный процесс для консумеров. В этот момент все консумеры остановят чтение и не начнут его до полной синхронизации и стабилизации группы. Есть различные алгоритмы ребалансировки, которые позволяют смягчить процесс, но по умолчанию это Stop-The-World.
В новом консумере важно правильно выбрать политику оффсета. Иногда читать с начала не нужно и достаточно «перемотать» оффсет в конец, чтобы сразу получать только новые события.
Наконец, два и более консумеров в группе не могут читать из одной и той же партиции. Чтобы не оказаться в ситуации, когда вам некуда масштабироваться при чтении, заранее установите достаточное число партиций.
Последняя часть — консумеры и то, как они читают данные из Kafka.
Дизайн консумера

Типичная программа-консумер работает так: при запуске внутри неё работает таймер, который периодически поллит новые записи из партиций брокеров. Поллер получает список батчей, связанных с топиками и партициями, из которых читает консумер. Далее полученные сообщения в батчах десериализуются. В итоге консумер, как правило, как-то обрабатывает сообщения.
В конце чтения консумер может закоммитить оффсет — запомнить позицию считанных записей и продолжить чтение новой порции данных. Читать можно как синхронно, так и асинхронно. Оффсет можно коммитить или не коммитить вовсе.
Таким образом, если консумер прочитал сообщение из партиции, обработал его, а затем аварийно завершился, не закоммитив оффсет, то следующий подключенный консумер при следующуем подключении вновь прочитает ту же порцию данных.
Главное — консумер периодически вычитывает новую порцию данных, десериализует их и следом обрабатывает.
Консумер-группы
Странно, если бы чтением всех партиций занимался только один консумер. Они могут быть объединены в кластер — консумер-группы.

Перед глазами у вас каноничная диаграмма: с левой стороны продюсеры, в середине топики, а справа расположены консумеры. Есть два продюсера, каждый из которых пишет в свой топик, у каждого топика есть три партиции.
Есть одна консумер-группа с двумя экземплярами одной и той же программы — это одна и та же программа, запущенная два раза. Эта программа-консумер читает два топика: X и Y.
Консумер подключается к брокеру с лидерской партицией, поллит изменения в партиции, считывает сообщения, наполняет буфер, а затем проводит обработку полученных сообщений.
Обратите внимание, что партиции распределены кооперативно: каждому потребителю досталось по три партиции. Распределение партиций между консумерами в пределах одной группы выполняется автоматически на стороне брокеров. Kafka старается честно распределять партиции между консумер-группами, насколько это возможно.
Каждая такая группа имеет свой идентификатор, что позволяет регистрироваться на брокерах Kafka. Пространство имён консумер-групп глобально, а значит их имена в кластере Kafka уникальны.
Наконец, самое главное: Kafka сохраняет на своей стороне текущий оффсет по каждой партиции топиков, которые входят в состав консумер-группы. При подключении или отключении консумеров от группы, чтение продолжится с последней сохранённой позиции. Это делает консумер-группы незаменимыми при работе event-driven систем: мы можем без проблем деплоить наши приложения и не задумываться о хранении оффсета на стороне клиента.
Для этого консумер в группе, после обработки прочитанных сообщений отправляет запрос на сохранение оффсета — или коммитит свой оффсет. Технически, нет никаких ограничений на то, чтобы коммитить оффсет и до обработки сообщений, но для большинства сценариев разумнее делать это после.
Ребалансировка консумер-групп
Рассмотрим сценарий, когда композиция группы меняется. В кластере Kafka консумер-группы создаются автоматически при подключении консумеров к кластеру и создавать её вручную нет необходимости, но это возможно через инструментарий. У новой группы отсутствуют сохранённые оффсеты партиций топиков и по умолчанию они равны -1.
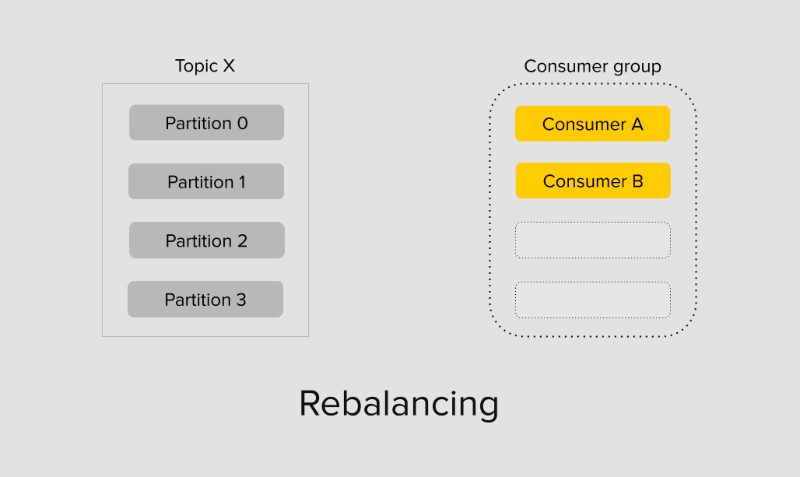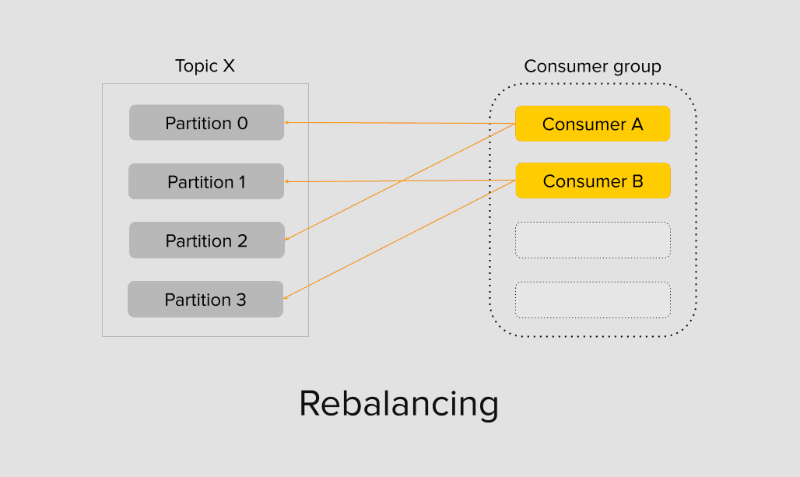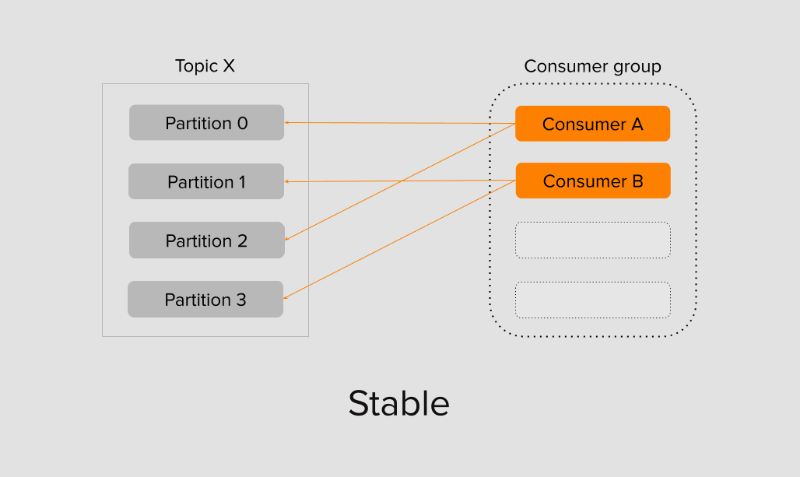
При появлении новых участников в группе JoinGroup, в специальном процессе брокера Group Coordinator первому вошедшему консумеру присваивается роль Group Leader.
Лидер группы отвечает за распределение партиций между всеми участниками группы. Процесс поиска лидера группы, назначения партиций, стабилизации и подключения консумеров в группе к брокерам называется ребалансировкой консумер-группы.
Процесс ребалансировки группы по умолчанию заставляет все консумеры в группе прекратить чтение и дождаться полной синхронизации участников, чтобы обрести новые партиции для чтения. В Kafka есть и другие стратегии ребалансировки группы, включая Static membership или Cooperative Incremental Partition Assignor, но это тема для отдельной статьи.
Как только группа стала стабильной, а её участники получили партиции, консумеры в ней начинают чтение. Поскольку группа новая и раньше не существовала, то консумер выбирает позицию чтения оффсета: с самого начала earliest или же с конца latest. Топик мог существовать несколько месяцев, а консумероявился совсем недавно. В таком случае важно решить: читать ли все сообщения или же достаточно читать с конца самые последние, пропустив историю. Выбор между двумя опциями зависит от бизнес-логики протекающих внутри топика событий.

Если в группу добавить нового участника, процесс ребалансировки запускается повторно. Новому участнику вместе с остальными консумерами в группе будут назначены партиции, а лидер группы постарается их распределить между всеми более или менее честно, согласно выбранной им настраиваемой стратегии. Затем группа вновь переходит в стабильное состояние.
Чтобы Group Coordinator в кластере Kafka знал, какие из его участников активны и работают, а какие уже нет, каждый консумер в группе регулярно в равные промежутки времени отправляет Heartbeat-сообщение. Временное значение настраивается программой-консумером перед запуском.
Также консумер объявляет время жизни сессии — если за это время он не смог отправить ни одно из Heartbeat-сообщений брокеру, то покидает группу. Брокер, в свою очередь, не получив ни одно из Heartbeat-сообщений консумеров, запускает процесс ребалансировки консумеров в группе.
Процесс ребалансировки проходит достаточно болезненно для больших консумер-групп с множеством топиков. Он вызывает Stop-The-World во всей группе при малейшей смене композиции участников или состава партиций в топиках. Например, при смене лидера партиции в случае выхода брокера из кластера при причине аварии или плановых работах, Group Coordinator также инициирует ребалансировку.
Поэтому разработчикам программ-консумеров обычно рекомендуют использовать по одной консумер-группе на топик. Также полезно держать число потребителей не слишком большим, чтобы не запускать ребалансировку много раз, но и не слишком маленьким, чтобы сохранять производительность и надёжность при чтении.
Значения интервала Heartbeat и время жизни сессии следует устанавливать так, чтобы Heartbeat-интервал был в три-четыре раза меньше session timeout. Сами значения выбирайте не слишком большими, чтобы не увеличивать время до обнаружения «выпавшего» консумера из группы, но и не слишком маленьким, чтобы в случае малейших сетевых проблем, группа не уходила в ребалансировку.

Ещё один гипотетический сценарий: партиций в топике 4, а консумеров в группе 5. В этом случае группа будет стабилизирована, однако участники, которым не достанется ни одна из партиций, будут бездействовать. Такое происходит потому, что с одной партицией в группе может работать только один консумер, а два и более консумеров не могут читать из одной партиции в группе.
Отсюда возникает следующая базовая рекомендация: устанавливайте достаточное число партиций на старте, чтобы вы могли горизонтально масштабировать ваше приложение. Увеличение партиций в моменте не принесёт вам почти никакого результата. Уже записанные в лог сообщения нельзя переместить и распределить между новыми партициями средствами Kafka, а репартицирование своими силами всегда несёт риски, связанные с очерёдностью и идемпотентностью.
🎉 Поздравляю! Вы прочитали до конца. Теперь можно закрепить теорию и перейти к практической части. Буду рад ответить на вопросы в комментариях
Tech-команда СберМаркета ведет соцсети с новостями и анонсами. Если хочешь узнать, что под капотом высоконагруженного e-commerce, следи за нами в Telegram и на YouTube. А также слушай подкаст «Для tech и этих» от наших it-менеджеров.
