SAP HANA — реляционная in-memory база данных от компании SAP, в которой данные хранятся и обрабатываются исключительно в оперативной памяти. Диски используются только для логирования и хранения бэкапов, необходимых для восстановления системы. О плюсах такого решения можно найти много информации в интернете. Но сегодня мы хотим поговорить о минусах.
Мы познакомились с SAP HANA в 2014 году. С тех пор мы сталкивались со многими особенностями работы in-memory базы данных, которые оставили различные отпечатки в нашей истории. Опыт эксплуатации этой БД познакомил нас с несколькими ее недостатками:
Долгое время запуска системы.
Жесткие ограничения по объему потребляемой оперативной памяти.
Борьба с недобросовестными запросами и пользователями.
Сегодня мы поговорим о первой проблеме — долгом запуске системы. Это одна из ключевых проблем технологии. Оперативная память быстрая, расчеты делаются на лету, но при перезагрузке системы данные в эту самую память должны прогрузиться с дисков. Пока этого не произойдет, зайти в систему не получится, или она будет работать ОЧЕНЬ медленно. Со временем проблема усугубляется: чем больше база, тем дольше будет запускаться система.
Исходные данные
Продуктивный сервер: 12 TB RAM, 448 ядер, SSD-диски. Живая и активная система, в которой одновременно работают более 10 000 пользователей. Система обрабатывает наши производственные процессы, поэтому любая недоступность базы означает финансовые потери для бизнеса и негодование пользователей. Для повышения отказоустойчивости настроен кластер, репликация в котором производится каждые 15 минут.
Время перезагрузки сервера или переезда кластера с ноды на ноду составляет почти 80 минут. Это очень много для бизнеса, и каждый перезапуск вызывает сильный стресс у предприятия. Нас это не устроило, и мы начали искать способы уменьшения времени запуска.
Этап 0: энергонезависимая память Intel Optane
В 2017 году Intel анонсировал новую энергонезависимую память Optane. Преимущество достигается за счет того, что данные остаются в памяти даже после отключения питания. Для in-memory базы данных это означает значительное ускорение запуска системы.
SAP анонсировала поддержку этой памяти в версии HANA 2.0 SPS 03. Первые серверы с Intel Optane на борту стали продаваться в 2019 году, и нам удалось заполучить один из них для тестирования. Мы сравнили два сервера: с обычной памятью и с Intel Optane. Они слабее нашего продуктивного сервера, и в них меньше данных. Между собой они тоже не совсем равны, но для тестирования сгодятся.
Характеристики серверов и результат тестирования:
Обычный сервер | Сервер с памятью Optane | |
CPU(s) | 240 | 224 |
Model | 62 | 85 |
Model name | Intel® Xeon® CPU E7-8880 v2 @ 2.50GHz | Intel® Xeon® Platinum 8280M CPU @ 2.70GHz |
L1d cache | 32K | 32K |
L1i cache | 32K | 32K |
L2 cache | 256K | 1024K |
L3 cache | 38 400K | 39 424K |
Memory | 128 GB x 48 | 32 GB RDIMM x 24 |
Optane Memory | - | 128 GB x 24 |
Скорость перезагрузки | 58 минут | 9 минут 50 секунд |
Благодаря технологии Intel Optane удалось сократить время запуска БД почти в 6 раз. Достойный и очень интересный результат. Процесс организации тестирования и полные его результаты — это тема для отдельной статьи. А пока просто отметим, Intel Optane — довольно перспективная технология.
Но не зря мы назвали этот этап нулевым, несостоявшимся. Несмотря на отличные результаты, мы пока не используем Optane из-за особенностей ее работы. Чтобы перейти на эту память, нужно менять стандартные алгоритмы обработки данных. Нам такой вариант не подошел, поэтому мы пошли в сторону другого функционала, предлагаемого SAP.
Этап 1: Fast Restart — хранение данных между перезапусками БД
В версии SAP HANA 2.0 SPS 04 появилась новая функция — Fast Restart Option. Она позволяет сохранять и повторно использовать основные фрагменты данных в оперативной памяти для ускорения перезапуска БД. Эффект будет только в том случае, если ОС не перезапускается.
Это делается путем создания разделов tmpfs — временного файлового хранилища, предназначенного для монтирования файловой системы, но размещенного в ОЗУ вместо физического диска. Для каждой NUMA-ноды создаются разделы tmpfs, которые разделяются на одинаковые объемы и монтируются в соответствующие директории. Таблицы с данными хранятся в этих разделах, поэтому они не будут считываться из файлового хранилища при запуске БД. Первый запуск системы пройдет как обычно, а вот последующие перезапуски будут в разы быстрее.
Настроить эту опцию достаточно просто, подробная инструкция есть в официальной документации. Сначала выполняем настройки:
cat /sys/devices/system/node/node*/meminfo | grep MemTotal | awk 'BEGIN {printf "%10s | %20s\n", "NUMA NODE", "MEMORY GB"; while (i++ < 33) printf "-"; printf "\n"} {printf "%10d | %20.3f\n", $2, $4/1048576}'
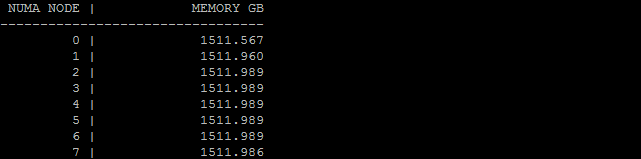
Далее монтируем директории:
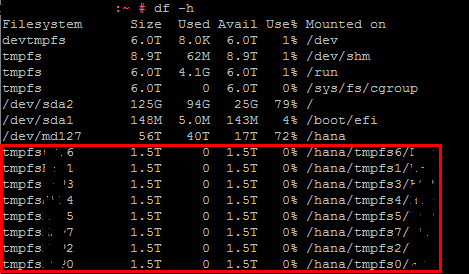
Директории смонтированы, но потребление памяти в них равно 0. Теперь необходимо прописать параметр basepath_persistent_memory_volumes с указанием всех монтируемых директорий через «;».

Для тестирования мы взяли два сервера: с 1,5 TB RAM и 12 TB RAM. Разный объем памяти выбрали специально, чтобы показать зависимость настройки от размера базы данных.
Мы будем анализировать два этапа загрузки:
Загрузка данных из Column Store (CS). Это область памяти в HANA, которая осуществляет поколоночное хранение данных в таблицах. По сути это означает загрузку основных данных в таблицы.
Полная загрузка БД. Это общая продолжительность полной загрузки БД: старт сервисов, загрузка метаданных, загрузка основных данных и прочее. По прошествии этого времени БД полностью готова к работе.
Сервер с 1,5 TB RAM | Сервер с 12 TB RAM | |||
Без Fast Restart | C Fast Restart | Без Fast Restart | C Fast Restart | |
Загрузка из CS | 3 минуты | 23 секунды | 65 минут | 2,6 минут |
Полная загрузка БД | 15 минут | 12,5 минут | 76 минут | 15 минут |
Проанализируем результаты:
Для сервера 1,5 TB время загрузки данных из CS сократилось почти в 8 раз. Это много, но в целом не сильно повлияло на общую скорость загрузки БД.
Для сервера 12 TB время загрузки данных из CS сократилось в 25 раз, а общее время загрузки сократилось в 5 раз.
Хороший пример, который демонстрирует эффективность Fast Restart в зависимости от объема БД: чем больше данных, тем лучше эффект.
Этап 2: быстрая перекачка данных в кластере
Теперь база данных перезапускается достаточно быстро. Но если остановить сервер полностью, придется снова ждать загрузки всех данных в оперативную память. Помочь тут может правильно настроенный кластер.
В нашем кластере две ноды: активная, в которой выполняются все рабочие операции, и пассивная, в которую просто реплицируются данные. Если нам потребуется перезапустить сервер, мы можем после перезапуска перекачать в него данные с пассивной ноды. Это будет быстрее, чем грузить их из файлового хранилища.
Репликация данных между нодами в SAP HANA может работать в трех режимах: delta_datashipping, logreplay, logreplay_readaccess. Мы рассмотрим только первые два режима, потому что logreplay и logreplay_readaccess работают одинаково в случае репликации между двумя нодами.
delta_datashipping. Этот режим применялся в HANA с первой версии. По умолчанию активная нода передает пассивной дельту данных каждые 15 минут. Снэпшоты с данными передаются в асинхронном режиме по аналогии с дифференциальным бэкапом. Если активную ноду необходимо убрать на техобслуживание, то сначала нужно полностью докачать дельту логов на пассивную ноду. При этом активная нода становится недоступна для записи, чтобы в БД не порождались новые данные.
logreplay. Этот режим появился в HANA 1.0 SPS 10 и установлен по умолчанию в HANA 2.0. В этом режиме дельта логов докатывается и воспроизводится на пассивной ноде непрерывно. Передавать дельту данных не нужно, поэтому объем данных, которые нужно передать на пассивную ноду для переключения, уменьшается.
Режим logreplay включается достаточно просто: изменением параметра в файле global.ini → [system_replication] → operation_mode = logreplay. Для применения режима пассивная нода должна быть оффлайн.
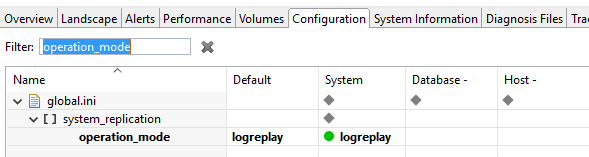
Теперь после перезапуска активной ноды мы можем перекачать в нее данные из пассивной. Это быстрее, чем грузить данные с дисков.
Вот результаты для 12 TB сервера с разными режимами репликации:
Режим | Скорость переезда |
delta_datashipping | 72 минуты |
logreplay | 2 минуты 1 секунда |
Результат: ускорение загрузки почти в 40 раз. Важно, что на это не будет влиять размер базы, а значит в будущем скорость останется примерно на этом же уровне.
Выводы
Проведенные изыскания здорово продвинули нас с точки зрения доступности системы. Начиная с 80 минут недоступности практически при любой проблеме или плановой перезагрузке, мы достигли результата в 15 минут при полной перезагрузке или буквально две минуты при наличии готового кластера.
Результат отличный, но не идеальный. Компания SAP постоянно предлагает новые «плюшки» для БД HANA, которые способствуют улучшению производительности, стабильности работы и гибкости системы. Посмотрим, что ждет нас дальше.
А вам доводилось укрощать HANA DB? Поделитесь своими историями в комментариях.
