Все было в общем-то неплохо
пока не стали улучшать
(с) Bazzlan
Если нет понимания, как измерять качество проекта, значит нет возможности управлять им и обеспечивать качество всего процесса разработки. Чтобы понять, достигается ли заданный уровень и приближается ли команда к цели, используются метрики. С ними должны уметь работать не только лиды и менеджмент, но и QA-специалисты.
В этой статье мы рассмотрим, каким минимальным требованиям должен удовлетворять проект и определим критерии для настройки сбора метрик. Разберем, что можно измерить на проекте, и как это сделать, чтобы процесс сбора метрик не вызывал негатива, а сами метрики были показательны и действительно помогали принимать управленческие решения.
Рекомендуем материал опытным тестировщикам, тем, кто выполняет роль QA Lead в команде, а также единственным QA на проекте, и всем, кто хочет улучшить качество и производительность процессов тестирования.

Вы не можете контролировать то, что не можете измерить.
Том ДеМарко
Разберем, когда стоит вводить метрики на проекте. Плохо, когда это происходит так:
в ситуациях из серии – «нам сказали собирать», «на других проектах есть, и нам надо»,
для поиска крайнего и назначения виноватого,
для штрафов, наказаний, санкций, депремирований,
в качестве введения соревновательной ноты между сотрудниками или командами.

Хорошо и правильно, когда метрики используют для:
оценки и при необходимости корректировки процессов,
анализа прогресса работ над приложением,
планирования ресурсов и трудозатрат,
аудита, поиска «узких горлышек» и возможных проблем,
отчетности, числового обоснования гипотез и предположений руководителям и управленцам проекта.
Не каждый проект готов для внедрения метрик. Сначала проверьте, готов ли ваш проект для запуска процесса сбора метрик.
все с виду вроде в шоколаде,
но если внюхаться, то нет
(с) из сети
Рассмотрим минимальные проектные требования для эффективного сбора и анализа метрик.
Стабильные процессы
Если на проекте бардак, отсутствует стабильный workflow, то метрики будут не показательны и иметь большую погрешность. Они могут применяться для наведения порядка на проекте, но даже в этом случае нужны минимальные стабильные процессы.
Инструменты
С помощью какого инструмента будут собираться метрики, в ручном или автоматическом режиме? Это могут быть таблицы с ручным заполнением, встроенные отчеты таск-трекера или автотестов. Внедрение метрик зависит от того, насколько автоматизирован и систематичен их сбор. Но ручной сбор метрик – трудоемкий процесс, есть вероятность человеческой ошибки.
Заинтересованные лица
Важным критерием в процессах сбора метрик является поддержка заинтересованных сторон. Если нет планов по обработке, дальнейшей аналитике метрик, не предполагаются корректировки процессов, то зачем на проекте нужны метрики? Сбор метрик только ради метрик – это самая неэффективная трата рабочего времени.
Готовность к изменениям
Команда должна понимать и принимать, что изменения будут. В процессы обеспечения качества вовлечены все члены команды, не только QA.
Итак, вы уверены, что на проекте выстроены процессы, понятен инструмент сбора метрик. Заинтересованные стороны и вся команда согласны с тем, что не стоит работать по ночам или регулярно заявлять в каждый спринт 30 задач, а делать 20. Все готовы к дальнейшим изменениям.
Что дальше?
Для последующей настройки метрик и непрерывной оценки качества процесса нужно определить:
Что хотим знать
Выделяем одну-две основные боли вашего проекта. Какую проблему хотим решить: почему не успеваем сделать задачу или не укладываемся в оценку, как повысить низкое качество продукта, избавиться от багов на проде, избежать превышения дедлайнов?
Когда хотим знать
Вам нужна информация до, во время или после итерации/спринта/релиза?
Как и кто будет собирать метрики
Кто отвечает за сбор метрик и их аналитику? Сбор метрик проходит в ручном режиме или в автоматическом? С помощью каких отчетов, инструментов?
Критерии успешности
Как вы поймете — у вас все плохо или хорошо? Критерии индивидуальны для каждого из проектов. Для одного 40 багов blocker – не стоп для релиза, для другого проекта 1 баг – critical-показание к задержке релиза. Критерии согласовываются всей командой проекта при участии руководства, разработки, QA, аналитиков. Прекрасно в теории определить, что не должно быть ни одного бага на проде. Но если на практике их 100+, и количество не снижается от релиза к релизу, то выбрав критерием успешности 0 багов на проде, ваша команда объективно никогда его не достигнет.
Лица, принимающие решения
Так как метрики собирают не ради метрик, необходимы будут изменения, которые затронут процессы всей команды, поэтому должно быть должностное лицо, уполномоченное на введение этих изменений. Изменения должны идти не только снизу, но и подкрепляться сверху.
Что можем измерить?
Первое и самое простое – количественные показатели. Это количество багов и задач, время, затраченное на них, причины невыполнения задач в спринт и работа ночью и в выходные. Сюда же входят объяснения, почему команду уже полгода просят войти в положение и выйти поработать в ночь с пятницы на понедельник.
Измерить можно очень много всего, существует более двух сотен разнообразных проектных метрик, коэффициентов, числовых, временных и процентных показателей, в чистом виде или их соотношения. Ваша задача – выбрать из этого всего нужные вам, определить те метрики, которые предоставят информацию по конкретно вашему вопросу.
Есть разные классификации и группы видов метрик, но все они сводятся в большинстве к тому, что именно хотим измерить:
документация;
тест-кейсы;
автотесты;
баги;
задачи;
функциональность;
метрики управления.
В каждом из видов вышеприведенных метрик существует десяток показателей и коэффициентов. Ниже на примерах мы рассмотрим основные из них.
Документация
Что можно измерить по документации проекта?
Качество документации: полнота описания, актуальность и достоверность, есть ли макеты, mind-карты, схемы, описание методов. Сколько было заведено/задано уточнений по макетам, схемам или техническому заданию аналитикам.
Учтена ли сложность требований, интеграции, описание бизнес-логики, зафиксировано ли влияние задачи смежную функциональность всего проекта.
Каково покрытие требований кейсами, прописана ли матрица трассировки, какая глубина покрытия тестами функциональности, учтены ли положительные и отрицательные сценарии (все-все отрицательные не учитываем, призываем на помощь тест-дизайн).
Метрики документации могут стать бесполезными, если не учитывать при измерениях уровни сложности различной функциональности, сложность бизнес-логики, а также если упустить интеграции с внутренними и внешними подсистемами и не включать третью сторону – поставщиков продуктов и решений. Кроме того, усугубить ситуацию может поиск виноватых и планирование наказания за низкое качество документации.
Ответьте, выделяется ли на вашем проекте время на ведение тестовой документации, если да, то его достаточно? Присутствует ли на проекте раннее тестирование, ревью, shift-left? Если нет и качество документации низкое, самое время ввести.
Удостоверьтесь, что аналитикам проекта выделяется достаточно времени и информации на описание технических заданий, а в работу QA-специалистов заложено время на ведение и актуализацию тестовой документации.
Пример:
Наглядное представление покрытия требований – матрица трассировки. Матрица выглядит как таблица с функциональными требованиями и тест-кейсами, позволяет отследить, все ли требования покрыты проверками. Подробнее о ней рассказали в этой статье.

Тест-кейсы
Что можно измерить по тест-кейсам?
Количество тест-кейсов по функциональности и шагам в них, сколько времени уходит на их описание, поддержку и актуализацию. Также число успешно или неуспешно пройденных тест-кейсов во время тестового прогона и то, как ваши тест-кейсы находят баги функциональности.
Соотношение “passed/failed” тест-кейсов помогает отслеживать, сколько было неуспешно пройдено кейсов по разным причинам: заведен баг, кейс невозможно пройти, он блокирован или неактуален.
Метрики по тест-кейсам будут только вредить, если подсчитывать количественные показатели (сколько написано кейсов, сколько пройдено) в разрезе по специалистам, без учета сложности, предусловий и постусловий. Сравнение неравноценных кейсов субъективно и будет демотивировать специалистов, которых сравнивают.
Скорость разработки тест-кейсов напрямую зависит от сложности функциональности, принятого уровня детализации, количества предполагаемых шагов. Время на прохождение кейса должно учитывать подготовку тестовых данных, предусловия и постусловия, трудозатраты на заведение багов, найденных при прохождении кейсов.
Нельзя сравнивать тест-кейсы с 10 шагами и одним шагом. Хотя бывают такие кейсы, в которых для выполнения одного шага нужно предварительно пройти по разным системам и затратить в 10 раз больше времени, чем пройти по 10 шагам другого кейса.
Хорошо, когда работа с тестовой документацией внесена в workflow, а задача не закрывается, пока по ней не обновлено и не актуализировано описание. Но чаще реальность такова, что на документацию выделяется время по остаточному принципу: вот завершим важные задачи и займемся актуализацией. А важные задачи не заканчиваются никогда, и тестовая документация становится все больше неактуальной.
Пример:
Коэффициент notRun (Knr) по тест-кейсам показывает, сколько тестов осталось выполнить в данной фазе тестирования. Метрика чаще всего формируется автоматически встроенными инструментами отчетности в системы управления тест-кейсами.
Метрику notRun отслеживает во время тестирования QA Lead или специалист, выполняющий роль лида на проекте. NotRun показывает, какой процент кейсов не запускался, и используется для прогнозирования – сколько еще времени требуется для завершения тестирования.

Пояснения: например, из 300 тест-кейсов в текущем прогоне пройдено всего 100 тест-кейсов, 200 тест-кейсов пока не пройдено.

Согласно текущему показателю Knr=66%, больше половины тест-кейсов еще не пройдено, и если тестирование начали четыре часа назад, понятно, что в текущий восьмичасовой рабочий день команда не успеет завершить тестирование. Нужно увеличивать количество специалистов или сдвигать сроки завершения тестирования.
Автотесты
Что можно измерить в автотестах?
Самое очевидное – это их количество на проекте. Но фраза «У нас на проекте 400 автотестов» не говорит ни о чем. Работают ли и запускаются ли на проекте все эти 400 автотестов, оправданы ли они, каков процент покрытия автотестами функциональности и какого именно – вот что важно. Гораздо информативнее фраза: «У нас все кейсы регресса покрыты автотестами». Сразу понятно, что рутины автоматизированы, и на проекте экономится время и ресурс QA-специалистов.
Можно вычислить покрытие автотестами требований или функциональности, скорость разработки автотестов. Если при заведении бага, найденного с помощью автотестов, ставить метку, то можно оценить эффективность автотестов на предмет нахождения багов.
Как узнать, оправданы ли ваши автотесты, действительно ли трудозатраты на их разработку и поддержку экономят время команды? Посчитайте, сколько времени уходит на поддержку существующих автотестов, а сколько тратится на разработку новых. И если большая часть времени тратится на починку и поддержку автотестов, то не надо удивляться, почему медленно продвигается покрытие автотестами функциональности.
Если в автотестах много ложных срабатываний или дефектов, посмотрите, сколько времени уходит на разбор отчетов Allure. Возможно, вручную проходить эти кейсы будет быстрее.
По аналогии с тест-кейсами, метрики по автотестам будут не показательны, если подсчитывать количественные показатели по специалистам без учета сложности тестов и количества предполагаемых шагов. Совсем грустно будет автоматизатору, если код изначально не был заточен под автотесты – возникнут трудности в их реализации и поддержке.
Пример: отчет Allure по прогону показывает, сколько автотестов пройдено успешно, сколько провалено, и их нужно разобрать, завести баги или отправить автотест на актуализацию шагов или тестовых данных.
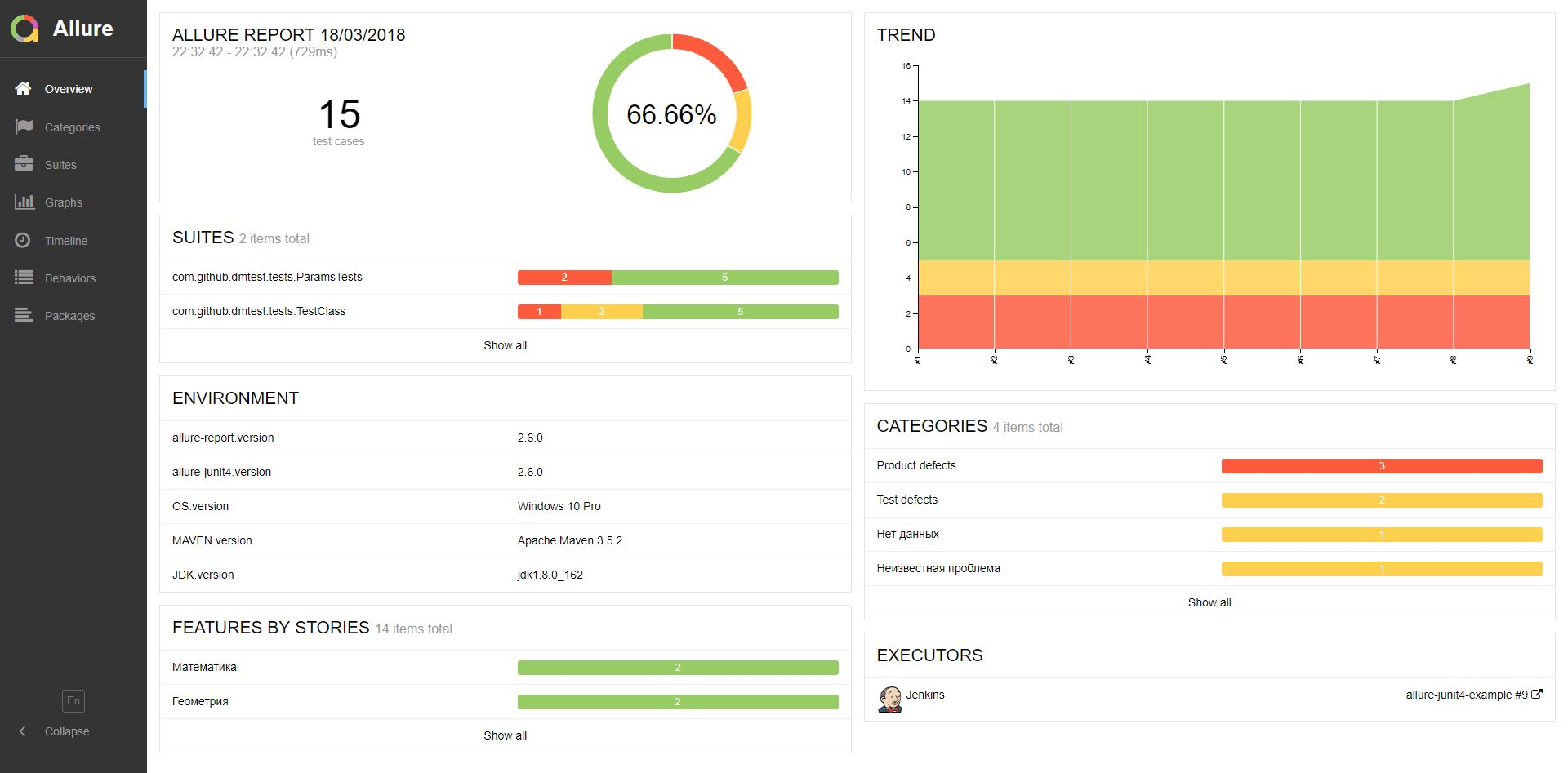
Баги
Что можно измерить по багам?
В автоматическом режиме по ним можно собирать количественные метрики. Это делается с помощью отчетов или встроенных инструментов систем управления проектами. Например, количество багов общее на проекте, на подпроектах, по функциональности, по задачам, баги в разрезе по приоритетам (High, Medium, Low) или критичности (Blocker, Critical, Major, Minor, Trivial).
Без учета приоритета и критичности сложно будет определить текущую ситуацию по оцениваемой функциональности. Например, у нас зафиксировано 10 багов по задаче 1, это больше, чем два заведенных бага по задаче 2. Но в задаче 1 все 10 багов критичности minor и trivial, а в задаче 2 оба бага blocker. Без учета критичности, казалось бы, ситуация по задаче 1 хуже, но с учетом критичности багов, дела плохи именно по задаче 2.
Одна из самых полезных метрик – плотность багов в функциональности. Принцип Парето 80:20 применим и к разработке. На 20% функциональности приходится 80% всех багов. Метрика плотности позволяет явно выявить эту функциональность, которой требуется больше внимания, чтобы в дальнейшем закладывать больше времени на задачи разработки и тестирования, если будет затронута подверженная багам часть.
Количественную метрику по багам можно отслеживать по функциональности, задачам, системам, спринтам, разработчикам, тестерам. А количество багов на проде – прямой показатель качества работы команд разработки и тестирования.
Время жизни бага полезно отслеживать, если среди них есть такие, которые кочуют из спринта в спринт, потому что они малозначительные, на них нет времени для принятия решений о введении стабилизационного спринта без новых задач.
Полезно вести метрику о происхождении бага, на какой стадии он возник – стадия требований, архитектуры, разработки базы данных, тестов и тест-кейсов, тестирования. Это даст понимание, на каком этапе работ недостаток времени или ресурсов влияет на возникновение багов.
Количественную метрику по багам чаще всего используют в отчетах по тестированию для определения качества задачи, сборки или проекта в целом.
Пример:
Отчет по тестированию о качестве версии, по количеству багов в разрезе критичности.
Всего было заведено 5500 дефектов. На момент выпуска актуален (не исправлен) 1771 дефект, из них – 45 blocker, 718 critical, 505 major, 140 minor, 363 trivial.

Задачи
Что можно измерить по задачам?
Самые популярные числовые метрики задач – это их общее количество: сколько завершенных, а сколько все еще открытых, время жизни задачи, превышения или срывы сроков по задачам, превышение или преуменьшение оценки, количество возвратов по задачам, на каком этапе они были и по какой причине.
Полезно учитывать «докинутые» в спринт задачи, которые изначально не планировали включать. Если уже запланировано 10 задач, а в процессе с комментарием «ну очень надо» добавили еще пять с просьбой успеть сделать все 15, то не стоит удивляться, как получилось, что не уложились в спринт.
Метрика будет иметь смысл, если анализировать количество задач с учетом их сложности и оценки. Также полезно вести метрику оценок задач, если есть трудности с попаданием в предварительную оценку, превышение или занижение времени на разработку и тестирование.
Чтобы метрики по задачам были информативны и показательны, во всех них следует учитывать скорость и экспертизу разработки, сложность реализуемых задач, интеграции. Было ли заложено изначально время на тестирование, время на риски, учтены ли были правки в техническом задании во время разработки или тестирования, какова вероятность возврата задач с изменением бизнес-логики, правок макетов «на лету», когда задачи готовы к проду.
Пример:
Диаграмма «Created and Resolved» из отчетов Jira

Функциональность
Что можно измерить в функциональности?
Функциональные метрики продукта – это такие показатели, как производительность, нагрузка, удобство пользования, безопасность. Это все отдельные большие группы метрик. На крупных проектах за них отвечают отдельные выделенные специалисты или команды специалистов.
Метрики удобства пользования являются частью доказательного дизайна: время выполнения сценария, его сложность, ошибки ввода, ошибки поиска информации пользователем, тепловые карты.
Метрики безопасности – индикаторы, позволяющие выявлять недостатки в системе: уязвимости, утечки информации, влияние вредоносных скриптов и программ, проникновения/атаки успешные/неуспешные, потери данных, OWASP.
Метрики нагрузки и производительности выявляют проблемы приложений и обеспечивают их эффективную работу для наилучшего обеспечения взаимодействия с пользователями в заданном и спрогнозировано масштабе. Примеры метрик: время отклика, время загрузки экрана/страницы, частота ошибок обработок запросов системе, производительность относительно количества пользователей, пропускная способность – количество обработанных запросов в секунду.
Данные без привязки к продукту, например «нагрузка 100 операций в секунду» – не информативны (хорошо это или не очень?), нет ясности. Нужна конкретика именно этого проекта, критерии, профиль нагрузки.
Например, для небольшого цветочного магазина 100 операций в секунду — допустимая нагрузка, но 8 марта или 14 февраля количество запросов кратно возрастет, как и количество операций в секунду.
Пример: Профиль нагрузки в JMeter

Метрики управления
Что можно измерить на проекте для облегчения принятия управленческих решений?
Прямой показатель качества работы команды – количество пропущенных дефектов в продакшн. Нужно учитывать не только баги, действительно пропущенные командой на прод, но и пришедшие с саппорта или от пользователей, уже известные баги и заведенные командой в баг-трекер. Возможно, не было времени или возможности их править, они плохо воспроизводимые, редко встречающиеся или trivial по критичности. Если у вас есть пул таких багов, кочующих из спринта в спринт, стоит поднять вопрос о стабилизационном спринте, для фикса хвоста из таких багов.
Полезны для проекта статистические метрики: какими операционными системами, браузерами или девайсами пользуются конечные пользователи вашего приложения. Снять статистику можно с помощью таких инструментов, как matomo, Open Web Analytics, Яндекс.Метрика и других. Это даст уникальную информацию по профилю пользователя вашего продукта.
Пример:
Статистика matomo

Метрика, которую почти никто никогда не считает, а нужно – это накладные расходы. К ним относятся не прямые задачи разработки и тестирования: митинги, дейли, стендапы, ретро, длительные созвоны не по конкретной задаче, простои, недоступность стендов, настройка окружения, ожидание сборок, ожидание чего-либо или кого-либо, подготовка тестовых данных.
Накладные расходы рассчитываются по каждому специалисту как отношение потраченного времени на все, кроме непосредственно задач, к общему рабочему времени в 40 рабочих часов в неделю.

K > 0.4 – слишком много
0.1< K <0.4 – много
K < 0.1 - хорошо
Пример:
Т1 дейлик 1 час ежедневно, 5 часов в неделю
T2 недоступны стенды 3 часа в неделю
T3 ретро 4 часа, 1 раз в спринт, 2 часа в неделю
K = (5 + 3 + 2) / 40 = 0,25
K = 0.25 – это значит, что у каждого специалиста проекта 10 часов из его 40-часовой рабочей недели уходит не на рабочие задачи.
Нужно поднимать вопрос со стендами, и явно нужна оптимизация созвонов и разговоров. Нужно избегать ситуаций, когда вся команда из двадцати человек висит в звонке и слушает дискуссию двух членов команды. Вежливо просим коллег договориться в личных сообщениях, а в общий чат прислать итоги дискуссии и решение.
Хорошим значением считается K <0.1 – это значит, что на накладные расходы уходит менее 4 часов в неделю.
Заключение
Мы рассмотрели, как метрики и процесс их сбора могут вредить проекту и демотивировать команду, а значит сказываться на производительности, эффективности и результате. А также что нужно учитывать, чтобы избежать негативных влияний. Метрики – это инструмент, и работать с ним нужно учиться на практике.
Подытожим, когда метрики будут бесполезны и даже вредны:
Если нет минимальных процессов.
В отсутствие поддержки заинтересованных лиц и команды.
Без предполагаемой дальнейшей аналитики метрик.
Для поиска виноватых.
Для депремирований, санкций, соревнований.
Универсальных метрик не существует, их набор формируется под проект и конкретные задачи. Начните с честного ответа на вопрос «Зачем нужны метрики на этом конкретном проекте?»
Метрики принесут пользу, если планируется их использовать:
Для оценки и корректировки процессов.
Анализа прогресса работ, планирования.
Аудита, поиска «узких горлышек» и проблем.
Отчетности, числового обоснования.
Спасибо за внимание!
Авторские материалы для QA-специалистов мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
