Привет. Меня зовут Саша Денисов, я инженер в Контуре.
Я веду блог во внутренних ресурсах компании и хочу поделиться им с вами. Это серия преимущественно развлекательных статей на инженерные темы, которые не претендуют на научность и полноту знаний в них. Каждая следующая статья зарождается в моменте, когда при решении очередной рабочей задачи в Контуре я (или мои близкие коллеги) сталкиваюсь с чем-то, что вдохновляет меня.
Я стараюсь выстроить статьи в серии таким образом, чтобы они постепенно погружали читателя в не самые очевидные части .Net вдоль различных векторов или областей знаний, которые часто хитро сплетены. Иногда затрагивая и более низкоуровневые (или наоборот высокоуровневые) интересные факты и полезные знания, которые можно применить на практике.
Вы уже могли видеть одну из мои статей про Guid.NewGuid(). Сегодня расскажу вам сказку про Method as Parameter.
Наверняка вы вызывали методы в C#. И казалось бы, что тут может быть интересного. Но тут есть о чем поговорить, есть что интересного рассказать.
Позвольте рассказать вам сказку про то, как обычное использование методов может утопить ваше приложение в GC, а наивная реализация может быть на порядок менее эффективной и при этом не быть проще и понятнее, чем более грамотная реализация.
Один из распространённых способов использовать методы — передавать их как аргументы. Например, внутрь класса можно передать метод, который будет возвращать настройки этого класса, чтобы динамически настраивать какой-нибудь уровень параллелизма. Или легко вспоминается LINQ, где в аргументы .Select() вы передаёте какой-нибудь selector.
Есть множество способов как определить эти методы, как передать их в качестве аргумента. И в зависимости от выбранного способа поведение программы может очень сильно отличаться. Давайте посмотрим на это подробнее.
Художественное отступление, шутка на текущую тему. Для того, чтобы узнать самое интересное, читать текст под катом совершенно не обязательно.
Весь пол был завален хаотично разбросанными открытыми конвертами. Уборщица изредка вываливалась из своей комнатушки и собирала часть конвертов, при этом загораживая всем проход и создавая дополнительные очереди.
На табло засветилась долгожданная строчка с номером полученного талона и номером окна. За окном сидело жутко недовольное лицо.
— Здравствуйте, хочу отправить письмо!
— Кладите письмо в конверт.
— Вот, держите. Отправлять по адресу 926FD361.
— Ну сколько можно, вы адрес в отдельный конверт положите, и мне передайте!
— Да зачем мне адрес в конверт класть, хотите, я вам продиктую его, хотите, так напишу.
— Вы что тут, самый умный что ли? Правила такие, кладите адрес в письмо, по‑другому не приму.
Спорить было бесполезно. Пришлось покупать ещё один ненавистный конверт и класть в него написанный на бумажке адрес. Лицо в окне, получив конверт, извлекло из него адрес и безжалостно выбросило конверт на пол.
— Всё, письмо ваше отправлено, всего хорошего.
Хм, не прихватить ли выброшенный конверт от адреса с собой, чтобы в следующий раз не тратиться и не покупать его ещё раз? Хотя, придётся его хранить, таскать с собой. Наверное, дешевле потом просто новый купить. Или нет.. Ладно, пусть валяется, уборщица соберет. А пока не пришла и не загородила все проходы, застопорив любые передвижения, пора выбираться отсюда.
Начнем с простого и искусственного
Выдумаем, для начала, искусственный пример. Для простоты. Потом обязательно посмотрим на более реальные примеры.
Что-нибудь очень простое. Допустим, у нас есть очень много пар чисел. И мы хотим их складывать. Но бывает так, что складывать числа надо по-разному. И мы хотим дать пользователю определять функцию сложения. Поэтому мы написали такую реализацию:
private int CallAdd(Func<int, int, int> userAdditionFunction, int arg1, int arg2)
{
return userAdditionFunction(arg1, arg2);
}Очевидно, в таком виде метод CallAdd бесполезен.
Но в реальности вокруг строчки return userAdditionFunction(arg1, arg2); может быть куча какой-то нашей логики. И наличие этого метода оправдано, чтобы избежать дублирования. Эдакий декоратор.
Но иногда мы не хотим пользоваться той реализацией метода, которую передал пользователь. А хотим пользоваться своей собственной AdditionFunction, в зависимости от настройки UseCustomFunction. Вот мы её рядом и реализовали:
private int DefaultAdditionFunction(int x, int y)
{
return x + y;
}И вот такой у нас получился код основной работы (да, мы тут ничего не делаем с результатом, но это же искусственный пример):
private readonly Func<int, int, int> userFunction; //initialized in constructor
public void DoJob()
{
for (int i = 0; i < pairsOfNumbersCount; i++)
{
if (UseCustomFunction)
CallAdd(userFunction, i, i);
else
CallAdd(DefaultAdditionFunction, i, i);
}
}И вдруг, вы замечаете, что в случаях, когда UseCustomFunction = false (то есть, когда мы начинаем пользоваться нашей собственной реализацией DefaultAdditionFunction), ваше приложение начинает работать медленнее, потребляет больше CPU и погрязает в GC. Даже если код реализации userFunction абсолютно идентичен нашей собственной DefaultAdditionFunction.
Проверяем
Не верите? Давайте забенчмаркаем наш метод DoJob. Чтобы было честно, сделаем так: private readonly Func<int, int, int> userFunction = DefaultAdditionFunction;. То есть вызываемые функции будут абсолютно одинаковы. Ну и пусть pairsOfNumbersCount = 10 тысяч.
Под катом код всего бенчмарка
private const int PairsOfNumbersCount = 10_000;
private Func<int, int, int> userFunction;
[Params(true, false)]
public bool UseCustomFunction;
[GlobalSetup]
public void SetUp()
{
userFunction = DefaultAdditionFunction;
}
[Benchmark]
public void DoJob()
{
for (int i = 0; i < pairsOfNumbersCount; i++)
{
if (UseCustomFunction)
CallAdd(userFunction, i, i);
else
CallAdd(DefaultAdditionFunction, i, i);
}
}
private int CallAdd(Func<int, int, int> userAdditionFunction, int arg1, int arg2)
{
return userAdditionFunction(arg1, arg2);
}
private int DefaultAdditionFunction(int x, int y)
{
return x + y;
}Получим вот какой результат.
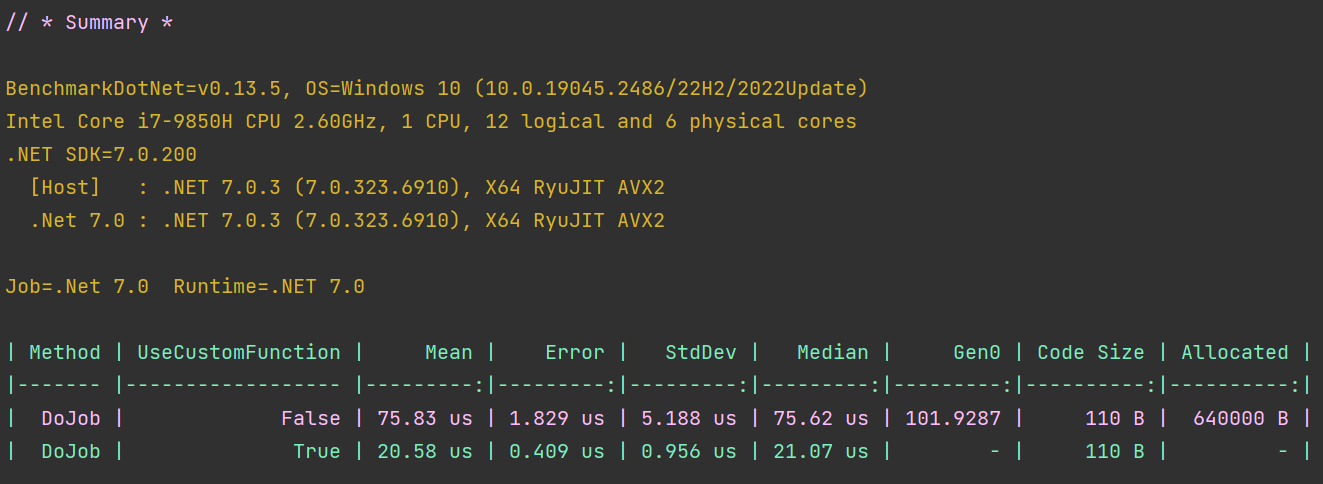
Для простоты выделим текстом самое важное:
| Method | UseCustomFunction | Mean | Gen0 | Allocated |
|------- |------------------ |---------:|---------:|----------:|
| DoJob | False | 75.83 us | 101.9287 | 640000 B |
| DoJob | True | 20.58 us | - | - |Почему-то, когда мы пользуемся нашей собственной реализацией (UseCustomFunction = false), код работает примерно в 3.75 раз медленнее (см. Mean, т.е. среднее время выполнения функции)! И выделяет кучу managed-объектов на хипе, за что мы расплачиваемся сборками мусора (см. Gen 0 — количество сборок мусора, и Allocated — сколько места заняли все выделенные managed-объекты за время работы функции).
Почему так?
Всё, на самом деле, достаточно просто. Метод CallAdd хочет видеть в аргументах объект типа Func<int, int, int>. Func — это объект. В случае, когда мы пользуемся локальной переменной userFunction, этот объект уже есть, он был создан, когда выполнилась написанная нами строчка userFunction = DefaultAdditionFunction;, и "лежит" в этой локальной переменной.
Когда же мы передаем в качестве аргумента "наш метод" DefaultAdditionFunction, мы каждый раз на каждой итерации цикла заново создаём экземпляр Func<int, int, int>, ссылающийся, очень грубо говоря, на реализацию DefaultAdditionFunction из MethodTable типа нашего класса в привязке к конкретному экземпляру нашего класса.
Возможность просто написать имя какого-то метода в качестве аргумента — это, можно сказать, сахар, предоставленный языком. Который нагло скрыл от нас то, что на самом деле произойдёт. А именно — создание объекта, который от нас на самом деле и хотели.
Это, кстати, можно проследить в листинге IL-кода:
.method public hidebysig instance void DoJob() cil managed
{
.custom instance void [BenchmarkDotNet.Annotations]BenchmarkDotNet.Attributes.BenchmarkAttribute::.ctor() = ( 01 00 00 00 )
// Code size 62 (0x3e)
.maxstack 3
.locals init (int32 V_0)
IL_0000: ldc.i4.0
IL_0001: stloc.0
IL_0002: br.s IL_0034
IL_0004: ldarg.0
IL_0005: ldfld bool benchmarks.FunctionCall::UseCustomFunction
IL_000a: brfalse.s IL_001c
IL_000c: ldarg.0
IL_000d: ldfld class [System.Runtime]System.Func`3<int32,int32,int32> benchmarks.FunctionCall::userFunction
IL_0012: ldloc.0
IL_0013: ldloc.0
IL_0014: call int32 benchmarks.FunctionCall::CallAdd(class [System.Runtime]System.Func`3<int32,int32,int32>,
int32,
int32)
IL_0019: pop
IL_001a: br.s IL_0030
IL_001c: ldnull
IL_001d: ldftn int32 benchmarks.FunctionCall::DefaultAdditionFunction(int32,
int32)
IL_0023: newobj instance void class [System.Runtime]System.Func`3<int32,int32,int32>::.ctor(object,
native int)
IL_0028: ldloc.0
IL_0029: ldloc.0
IL_002a: call int32 benchmarks.FunctionCall::CallAdd(class [System.Runtime]System.Func`3<int32,int32,int32>,
int32,
int32)
IL_002f: pop
IL_0030: ldloc.0
IL_0031: ldc.i4.1
IL_0032: add
IL_0033: stloc.0
IL_0034: ldloc.0
IL_0035: ldarg.0
IL_0036: ldfld int32 benchmarks.FunctionCall::pairsOfNumbersCount
IL_003b: blt.s IL_0004
IL_003d: ret
} // end of method FunctionCall::DoJobВот, в строке IL 0005 мы берем наш флажок UseCustomFunction. Если он false, прыгаем на адрес IL 001c. Иначе идем дальше. Давайте сравним эти две ветки.
Посмотрим на случай, когда UseCustomFunction = false. В следующей за IL 001c строке, IL 001d, мы извлекаем адрес функции DefaultAdditionFunction из типа FunctionCall (простите, так мерзко назван класс, где размещены все наши методы для эксперимента). А в следующей строке IL 0023 есть четкая инструкция newobj Func3<int32,int32,int32>. Это мы создали наш необходимый Func. Это самый настоящий new object();.
Теперь посмотрим на случай, когда UseCustomFunction = true. Мы пойдем дальше, до строки IL_000d, и просто возьмём адрес поля с готовым экземпляром Func3<int32,int32,int32>.
Всё, дальше эти методы абсолютно одинаковы. Они вызывают CallAdd с подготовленными аргументами.
Как легко заметить, разница этих двух веток такая: одна ветка (UseCustomFunction = false) берет адрес метода и создаёт объект Func, а другая ветка (UseCustomFunction = true) берет адрес готового объекта из локального поля и больше ничего, что сильно дешевле и не создает объектов на хипе.
А жизненный пример будет?
Да, будет! На самом деле их полно, зачастую мы их даже не замечаем, когда пишем такой код.
Эта сказка основана на реальных событиях.
Приведенный выше "искусственный пример" на самом деле нисколько не искусственный, он взят из жизни.
В топе дампа одного важного приложения было замечено огромное количество Func'ов, больше, чем полезных объектов (почти все были уже без root'а, то есть на них не было ссылки, их уже отпустили, но GC пока не собрал их к моменту снятия дампа). Расследование привело к тому, что нашли место в коде, которое в цикле очень много раз вызывало определённый метод из одной библиотеки. А этот метод в библиотеке на каждый вызов внутри себя таким хитрым способом создавал объект Func.
После чего библиотеку пооптимизировали, закешировав Func один раз в локальную переменную. Из топа дампа пропали все эти функции. GC в приложении стало происходить поменьше.
А из самого простого, но при этом очень распространённого примера из жизни — LINQ. Не зря он упоминался в начале статьи. Каждый наверняка встречал и писал такой код:
collection.Select(DoSmth);Всё, в этот момент вы воспроизвели проблему с созданием лишних объектов, которую мы сейчас обсуждаем. На каждый вызов Select (к счастью, не на каждый элемент в коллекции, а один раз перед вызовом Select) будет создаваться новый объект Func, с помощью которого и будет вызываться наш метод DoSmth.
Давайте напишем бенчмарк, чтобы было нагляднее:
private Func<long, long> initializedFuncObject;
private long[] arguments;
[GlobalSetup]
public void Setup()
{
initializedFuncObject = Func;
arguments = new long[5];
for (var i = 0; i < arguments.Length; i++)
arguments[i] = i;
}
[Benchmark]
public long Naive()
{
return arguments.Select(Func).Sum();
}
[Benchmark]
public long CachedFunction()
{
return arguments.Select(initializedFuncObject).Sum();
}
public long Func(long x)
{
return x + 10;
}Пусть у нас есть коллекция arguments из N = 5 элементов. И мы хотим модифицировать каждый элемент какой-нибудь функцией Func. Возьмём самую тривиальную: будем прибавлять к числу 10. А чтобы ленивый IEnumerable всё-таки отработал, вызовем какую-нибудь агрегирующую функцию, Sum например.
Сравним эти методы:
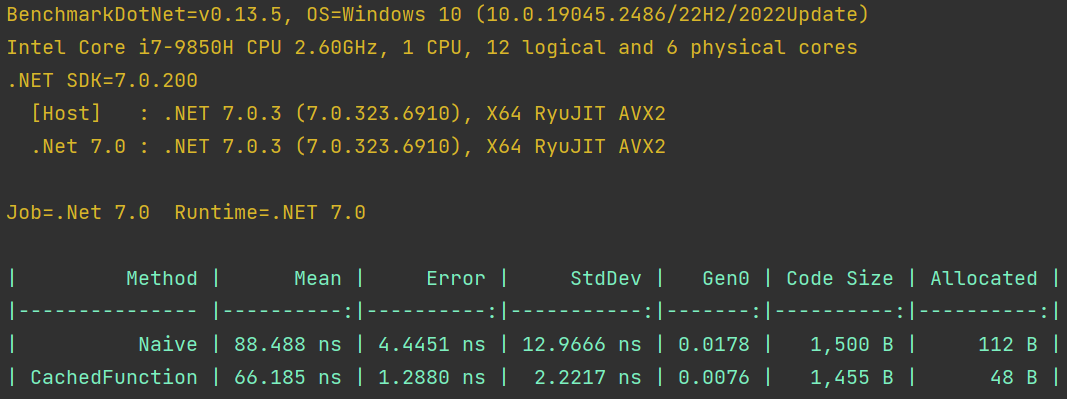
Результат интересный. Четко видно, что вариант с CachedFunction аллоцирует меньше объектов (как раз не создаёт этот самый Func), а значит потратит меньше времени и ресурсов на GC. И в целом работает чуточку быстрее наивной реализации (очевидно, чем больше количество элементов N, тем меньше будет заметна разница во времени работы метода; но легко представить ситуацию, когда, например, N маленькое, зато весь Select вызывают в каком-нибудь внешнем цикле очень часто).
Для тех, кто всё понимает, и для зануд, как автор этого текста.
Нельзя не воспользоваться случаем и не похейтить LINQ. Очевидно, если мы гонимся за производительностью, LINQ наш враг. Не будем объяснять почему, просто покажем. Кому интересно, покопается сам.
Добавим в бенчмарк метод:
[Benchmark]
public long LinqHater()
{
var sum = 0L;
for (var i = 0; i < arguments.Length; i++)
sum += Func(arguments[i]);
return sum;
}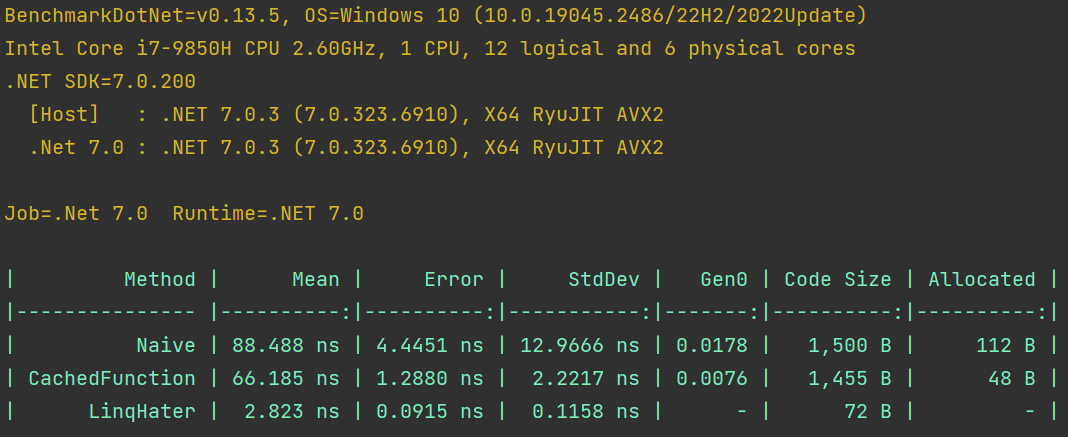
Вот так-то лучше, сразу стало спокойнее.
Но тут не всё рассказано!
Да, в этой теме (и вообще во всем том, чего мы касались в этом тексте) ещё очень много тонкостей и мелочей, которые хотелось бы показать. Ну например:
А что, если методы замыкаются на какие-то переменные?
А как повлияет Inlining\NoInlining методов?
Что такое бенчмарк, как он работает, как его запустить, как правильно писать бенчмарки?
А как вообще найти все такие (и при этом обязательно горячие) места в коде, ведь мы эти типы (Func'<>) нигде сами не создаём и не используем, их создаёт компилятор!
Как смотреть и как правильно читать IL-код?
Почему компилятор сам не может понять, что можно просто закешировать функцию один раз, и решить за нас эту проблему? (кстати, занятная ссылка)
Кто такой этот MethodTable?
…
И так уже получилось много текста. Может быть в другой раз, когда захочется рассказать очередную сказку. А ещё всегда можно поэкспериментировать и поразбираться самому.
Call to action?
А его не будет. Но теперь вы обладаете ещё одним небольшим знанием, а это уже хорошо. А как им пользоваться, личное дело каждого.
