Мы открыли исходный код всех наших продуктов, над которыми работали последний год, и в этом посте я хочу кратко рассказать о них.
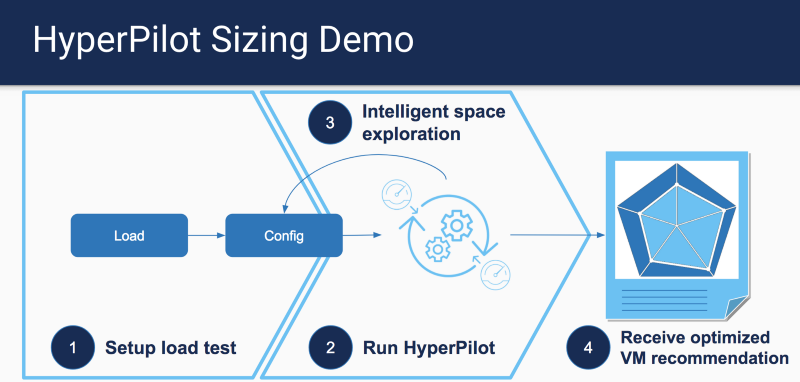
Последний год Hyperpilot работал в скрытом режиме, поэтому позвольте объяснить, что мы собирались делать. Наша миссия – дать интеллект инфраструктуре, чтобы увеличить эффективность и производительность. DevOps и системные инженеры постоянно сталкиваются с необходимостью принимать множество решений, связанных с контейнерной инфраструктурой и процессами, требующими ручной работы. Эти решения включают в себя весь путь от конфигурации виртуальных машин (тип инстанса, регион и т.д.), конфигурации контейнеров (запрос ресурсов, количество экземпляров контейнера и т.д.) до вариантов конфигурации уровня приложения (jvm и т.д). Операторы и разработчики часто делают статический выбор, и эксплуатационный персонал понятия не имеет, почему было принято такое решение. Хуже всего, что операторы склонны к переусердствованию, а это приводит к неэффективному использованию инфраструктуры. Мы работали над тремя продуктами, которые могли бы помочь операторам находить инструменты для лучших решений и автоматизации рекомендаций в будущем. Далее я расскажу о высокоуровневых продуктах, находящихся в открытом доступе.
HyperConfig: умный поиск конфигурации
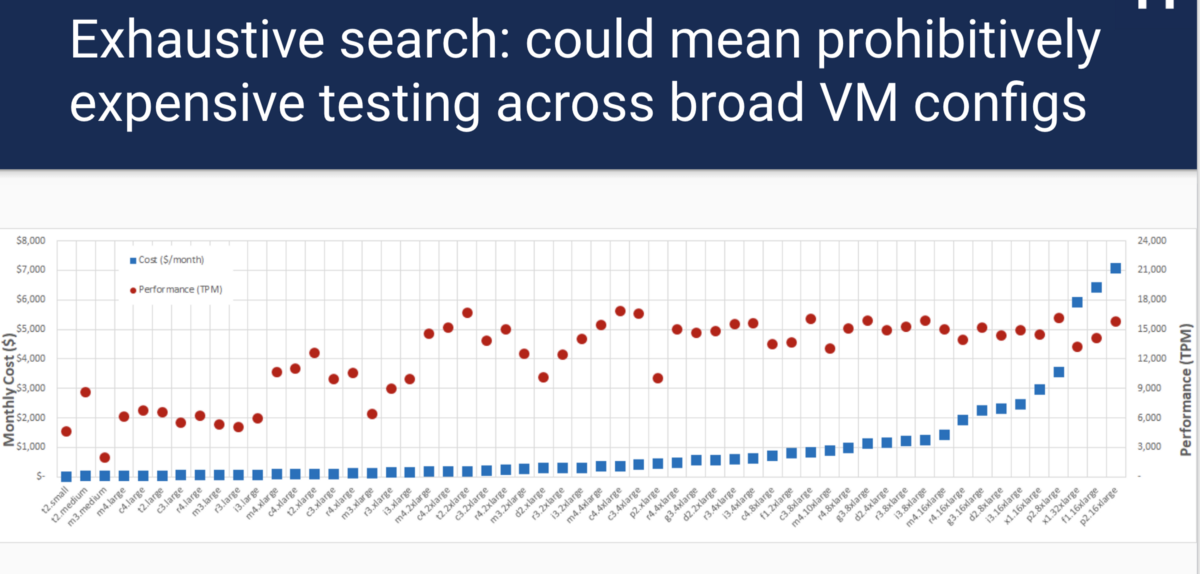
Если вы использовали облако, производили развертывание контейнеров docker с помощью Kubernetes или Mesos, то знаете: одна из первых проблем – выяснить, какая из конфигураций будет лучшей для каждого компонента. Например, какой тип инстанса виртуальной машины следует использовать? Сколько узлов развернуть? Какое количество процессорного времени и памяти выделить контейнеру? Все эти вопросы подразумевают компромисс между стоимостью и производительностью. Для примера возьмем размер виртуальной машины. Выбор инстанса крупной виртуальной машины будет стоить намного дороже, но может дать лучшую производительность. Выбор слишком маленькой виртуальной машины приводит к проблемам производительности и SLA. Трудно определить, какое решение лучше: если вы берете сравнительный тест MySQL tpcc и запускаете его на каждом типе инстанса AWS, то лучший выбор производительности и соотношения затрат не следует линейному и прогнозируемому шаблону:
Кроме того, исчерпывающий поиск требует множество временных и денежных затрат. К счастью, это не новая проблема, и существует немало исследовательских решений, но нет общего решения с открытым исходным кодом, поддерживающим общий вывод нагрузочного тестирования.
Вдохновленные работой CherryPick, мы создали hyperconfig и предложили набор типов инстансов AWS для различных критериев, основанных на общем результате нагрузочного тестирования.
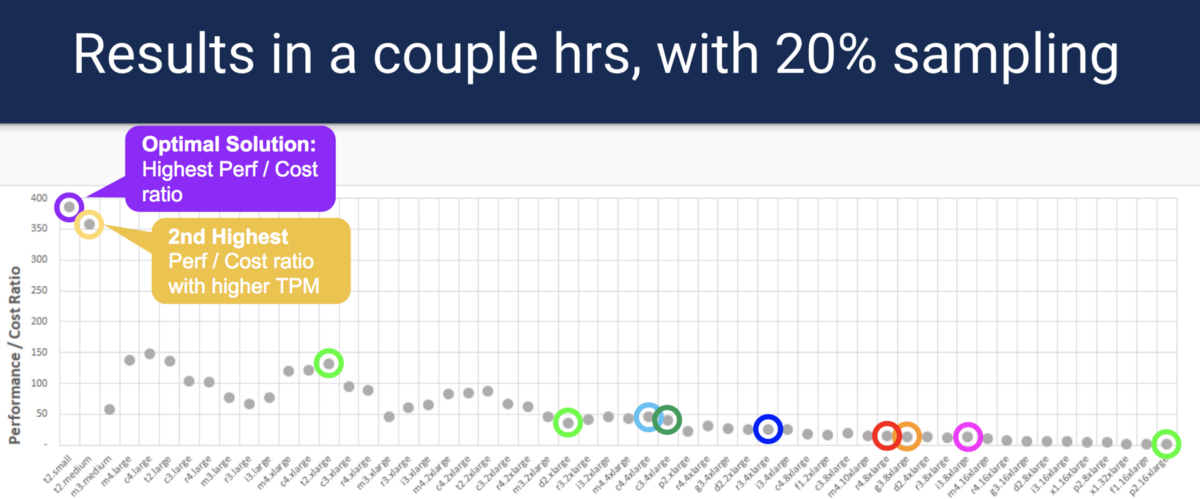
Вместо исчерпывающего поиска по каждому типу инстанса HyperConfig использует хорошо известный метод оптимизации, называемый Bayesian Optimization, чтобы найти оптимальные варианты, имея при этом меньшее количество точек выборки. Образцы можно запускать параллельно, что сокращает время и расходы. Обратите внимание: HyperConfig не гарантирует нахождение наиболее оптимального варианта, но подберет близкий к оптимальному вариант.
Для получения дополнительной информации о том, как запустить нашу демонстрационную версию, а также подробностей о коде, пожалуйста, обратитесь к разделу анализатора sizing.
HyperPath: анализ проблемных мест по ресурсам
Одна из проблем, с которой сталкиваются операторы, – поиск причины снижения производительности в кластере Kubernetes Проблема может исходить из разных источников инфраструктуры. Однако если сузить круг поиска проблемы до наиболее вероятных мест, то можно разработать систему, которая сможет диагностировать и найти источник проблемы производительности. HyperPath фокусируется на обнаружении проблемных мест cpu/memory/network/IO, а также определяет, возникает проблема из-за установленных для контейнера (-ов) лимитов или недостатка ресурсов узла (node).
HyperPath предполагает, что может получить доступ к метрике SLO приложения (например, задержка 95-го процентиля), а также к метрикам ресурсов, которые включают параметры контейнера cpu/mem/net/IO и аналогичные показатели уровня узла. С помощью этих данных HyperPath попытается соотнести, какие показатели ресурсов превысили порог, и ранжирует основные данные с самым высоким показателем корреляции.
В демонстрации вы увидите, что можно обнаружить узкие места процессора и других ресурсов, которые превысили порог SLO во время задержки приложения:
Для получения дополнительной информации и исходного кода, пожалуйста, обратитесь к разделу анализатора diagnosis.
Контроллер Best effort
Хорошо известно, что все операторы намеренно завышают необходимое количество ресурсов для своих приложений. Одна из самых важных причин такого поведения, – учет всплесков, которые могут произойти внезапно. Это приводит к низкой утилизации ресурсов кластера, поскольку пиковая нагрузка происходит только временами. Мы не можем просто выделить минимум ресурсов и надеяться на облако и автоскейлинг, поскольку процесс масштабирования кластера может занять минуту (-ы) во время пиковой нагрузки. Как же тогда использовать избыточные ресурсы? Одним из способов является запуск рабочих нагрузок best effort (BE). Нужно убедиться, что рабочие нагрузки можно контролировать, увеличивать или снижать количество доступных ресурсов во время всплесков.
Работа Christos Kozyrakis и David Lo над Heracles была направлена на решение проблемы повышения эффективности использования ресурсов. Для получения дополнительной информации о том, как работает Heracles, пожалуйста, обратитесь к исходному документу. На очень высоком уровне Heracles создает контроллер на каждом узле, и у каждого из этих контроллеров есть вспомогательный контроллер для каждого ресурса (процессор, память, сеть, IO, кеширование и т.д.), который следит за утилизацией ресурсов. Затем он использует основную SLO-метрику приложения в качестве входного сигнала, чтобы определить, когда и как масштабировать ресурсы для каждой рабочей нагрузки. Когда показатель приложения значительно увеличивается, мы можем начать выделять больше ресурсов для работ BE, и наоборот, уменьшать, когда нагрузка спадает.
В Hyperpilot мы разработали алгоритм Heracles и заставили его работать на Kubernetes. В следующем видео вы увидете контроллер в действии, когда мы запустили Spark с классом качества BestEffort QoS рядом с микросервисом.
Когда Spark запущен рядом с микросервисом без контроллера BE, вы увидите увеличение задержки из-за помех от Spark Job. Обратите внимание, что даже настройка BestEffort для работы Spark не исключает проблем с помехами. С включенным контроллером BE мы наблюдаем за задержкой, которая будет контролироваться в пределах порога SLO, а задания BE могут достигнуть прогресса без завершения.
Дополнительную информацию о кодовой базе можно найти здесь.
Я надеюсь, что эти проекты покажут, как использование данных об утилизации ресурсов из kubernetes и приложений могут повлиять на стоимость и производительность.
Оригинал: Hyperpilot open sourced 100% of its products.
