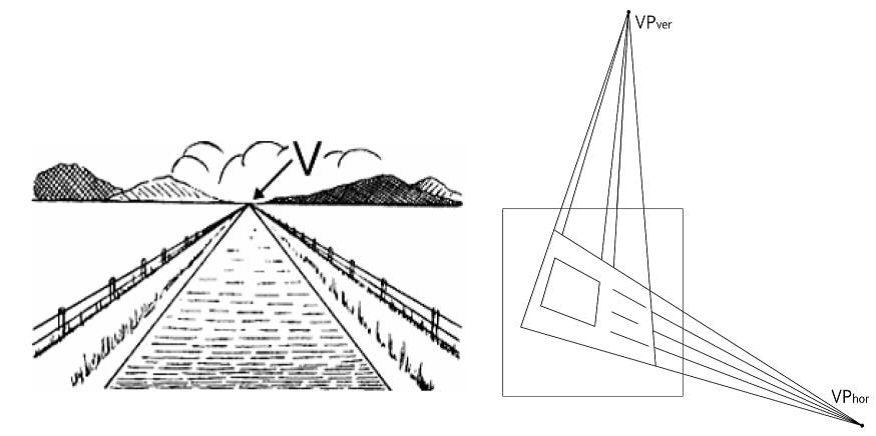
В наши дни трудно найти задачу, которую еще не предлагают решать нейронными сетями. А во многих задачах другие методы уже даже не рассматриваются. В такой ситуации логично, что в погоне за “серебряной пулей” исследователи и технологи предлагают все новые и новые модификации нейросетевых архитектур, которые должны принести прикладникам “счастье для всех, даром, и пусть никто не уйдет обиженным!” Впрочем, в индустриальных задачах чаще оказывается, что точность модели в основном зависит от чистоты, размера и структуры обучающей выборки, а от нейросетевой модели требуется разумность интерфейса (например, неприятно, когда ответом по логике должен быть список переменной длины).
Другое дело — производительность, быстродействие. Здесь зависимость от архитектуры прямая и вполне предсказуемая. Впрочем, не всем ученым интересная. Куда приятнее мыслить столетиями, эпохами, мысленно целиться в век, когда волшебным образом вычислительные мощности будут невообразимыми, а энергия добываться из воздуха. Однако и людей приземленных тоже хватает. И им важно, чтобы нейросети были компактнее, быстрее и энергоэффективнее уже сейчас. Например, это важно при работе на мобильных устройствах и во встроенных системах, где нет мощной видеокарты или нужно экономить аккумулятор. В этом направлении сделано немало: тут и малобитные целочисленные нейронные сети, и удаление избыточных нейронов, и тензорные декомпозиции сверток, и многое другое.
Нам же удалось убрать умножения из вычислений внутри нейрона, заменив их сложениями и взятием максимума, хотя мы и оставили возможность использовать умножения и нелинейные операции в функции активации. Предложенную модель мы назвали биполярной морфологической моделью нейрона.


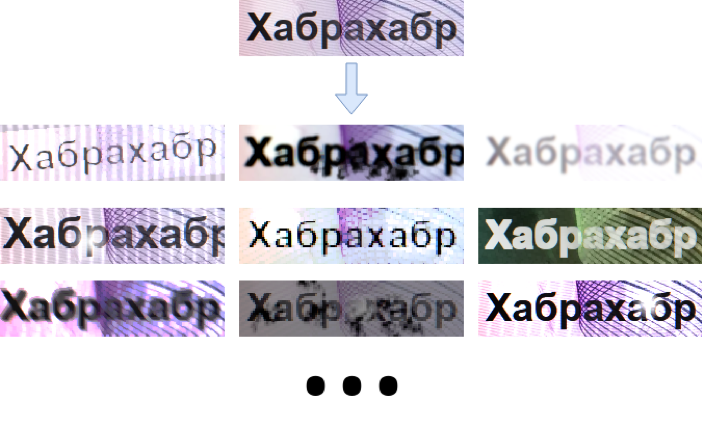





 Уверены, что на сегодняшний день не найдется ни одного читателя Хабра, который не был бы знаком с QR-кодами. Эти двумерные штрихкоды повсюду. Закономерно, что в мире существует много инструментов, позволяющих с некоторой долей эффективности добавить QR-коды в свой проект. Вся соль в том, что эта упомянутая эффективность напрямую зависит от качества инструмента, который используется для распознавания QR-кодов. И тут возникает классическая вилка: можно решить задачу (очень) хорошо и (очень) дорого, а можно бесплатно и как-то. А можно ли доработать бесплатное так, чтобы все-таки решить задачу хорошо? Если интересно, заглядывайте под кат.
Уверены, что на сегодняшний день не найдется ни одного читателя Хабра, который не был бы знаком с QR-кодами. Эти двумерные штрихкоды повсюду. Закономерно, что в мире существует много инструментов, позволяющих с некоторой долей эффективности добавить QR-коды в свой проект. Вся соль в том, что эта упомянутая эффективность напрямую зависит от качества инструмента, который используется для распознавания QR-кодов. И тут возникает классическая вилка: можно решить задачу (очень) хорошо и (очень) дорого, а можно бесплатно и как-то. А можно ли доработать бесплатное так, чтобы все-таки решить задачу хорошо? Если интересно, заглядывайте под кат.