Комментарии 87
Это не существенно. Если вы знаете, что в вашем конкретном случае они появляются не по порядку, вы можете использовать поле date. Всё абсолютно точно так же, date < ?last_seen, order by date desc
-- табличка, создаем сразу
use tempdb;
drop table if exists books;
create table books (id int not null identity primary key, val int not null, dt datetime default sysdatetime());
-- сессия 1
-- вот от этой штуки зависит результат
set transaction isolation level read committed;
begin tran;
insert into books(val) values (1);
waitfor delay '00:00:30';
commit;
-- сессия 2
-- уровень изоляции тот же, что в скрипте 1 для однозначности, например
set transaction isolation level read committed;
begin tran;
insert into books(val) values (2);
commit;
-- сессия 3
-- уровень изоляции тот же, что в скрипте 1 для однозначности, например
set transaction isolation level read committed;
select * from books;
В зависимости от уровней изоляции законно получаем разные эффекты, но всегда, абсолютно всегда сервером гарантируется, что более ранняя вставка имеет меньший identity. Если какие-то записи чтение/вставку не блокируют (например, при read uncommitted/RCSI), то никакого нарушения нет, а есть только в чистом виде эффекты изоляции. С тем же успехом можно было, например, заблокировать запись и делать широкие выводы вида «таракану оторвали ноги — таракан не слышит».
Для внешнего наблюдателя (txn3) из моего примера сначала появится запись из txn2Во-первых, абсолютно необязательно. Про уровни изоляции я не просто так обращал внимание. Обычный уровень RC и любой выше, как в моем примере, покажет в примере сразу две записи, и только когда завершится вторая сессия. А Read Uncommitted aka грязное чтение — и вовсе по мере появления незакоммиченных записей. А вот с RCSI действительно будет сначала результат второй транзакции, затем — обеих. С верным порядком ключей — сначала более ранняя вставка и никак иначе, ни при каком варианте!
Во-вторых, опять же, это ровно никакого отношения к порядку ключей относительно порядка вставки не имеет, могу лишь повторить повторить:
Тут чистая видимость транзакции — и, внезапно, никакого нарушения порядка вставки!Вещь эта, конечно, базовая, но базовая вообще безотносительно автоинкремента, уберите автоинкремент — и абсолютно ничего в примере не изменится.
А вот выше вы утверждали:
Вы же в курсе, да, что автоинкрементальные ID не обязаны появляться в БД в строгом порядке? И запись под номером 9 может появиться после записи под номером 11?Это, простите, просто дичь.
Очень интересно. И как же результат txn1, недостигшей еще COMMIT, будет виден другой транзакции с уровнем READ COMMITTED?У меня вообще-то написано ровно обратное, причем вы еще и окончание предложения снесли. Наверно, случайно так получилось:
Обычный уровень RC и любой выше, как в моем примере, покажет в примере сразу две записи, и только когда завершится вторая сессияЕще раз: при read committed результат будет виден извне только сразу для двоих записей. Сразу для двоих, т.е. одной записью из первой сессии выхлопа вообще не будет, понимаете? А случится это только тогда, когда обе транзакции из вашего примера зафиксируются.
PS. READ UNCOMMITTED это вообще хак, и далеко не везде он поддерживаетсяНе знаю, что такое хак в лично вашем определении, но то, что грязное чтение поддерживается не везде, опять же ничего не меняет.
Вы вообще чрезвычайно легко даете определения, категорически противоречащие общепринятым, чего стоит одно это:
Под автоинкрементом обычно подразумевается, что новой транзакции будет выдан номер больший, чем последний, использованный до этогоАвтоинкремент — это номер транзакции? Да, а номер транзакции — это что такое, вы забыли определить? И выводите из этого дальше сапоги всмятку. На самом деле автоикремент — это значение столбца, автозаполняемого монотонно данными с заданным приращением в порядке вставки. Вот вам, например, по-русски, ознакомьтесь: docs.microsoft.com/ru-ru/sql/t-sql/statements/create-table-transact-sql-identity-property?view=sql-server-ver15
Ну прочтите вы хоть что-то по теме, по которой собрались спорить, чтобы понять хоть этот абзац. Ну хотя бы про RC, что ли. Вы же даже логического смысла блокировок не понимаете, зато смело несете в массы свои определения типа
Это просто определение того, что значит «появиться раньше/позже» с точки зрения наблюдателя системы
А если там несколько записей с одним date, и страница закончилась в середине последовательности?
Вы же в курсе, да, что автоинкрементальные ID не обязаны появляться в БД в строгом порядке? И запись под номером 9 может появиться после записи под номером 11?Оба утверждения ложны: автоинкрементные столбцы появляются всегда в строго монотонном порядке (если исключить зацикливание в некоторых СУБД) и запись со значением 9 не может появиться после записи 11 (в случае положительного приращения и с тем же исключением, что и выше). Ну, или вы имели в виду написать совсем не то, что написали, дав свое определение понятия упорядочивания по времени (что, видимо, следует из комментов).
Да, разновидность этой проблемы (добавление данных после начала "листания") в статье уже указана. Решать её надо другими методами, которые зависят от критичности этой проблемы. Например можно с каждой страницей возвращать некий ETag, который сможет показать клиенту, что данные, с момента начала листинга, изменились.
Само по себе значение ETag не так важно. Важен факт его изменения. А это несколько проще реализовать. Например хранить в отдельной таблице (или даже в чём-то вроде Redis) некий uuid или просто автоинкремент, генерируемый при каждом изменении данных.
Нуу, тут можно книгу написать по этой теме. Всё зависит от требований к системе и имеющихся ресурсов. Варианты навскидку:
- ничего не делаем, продолжаем листать;
- перечитываем всё с начала в бесконечном цикле, пока не успеем всё прочитать в промежуток между изменениями;
- продолжаем листать дальше, а потом запрашиваем с сервера историю изменений за время пока листали, и с её помощью фиксим полученный список;
- и т.д. и т.п
Сосздание индексов на все случаи жизни — так себе решение, тк увеличивает нагрузку на сервер БД при вставке/модификации данных. Палка о 2-х концах, так сказать. К тому же это не сработает а случае join-ов.
Как правильно заметил delimer, метод не будет работать в случае сортировки по неуникальному полю, но идея хороша, хоть и для частных случаев.
Мое лично отношение к тем, кто выдвигает такие идеи — чтоб у вас, умников, книжки были исключительно с инфинити-скролом. Чтобы для того, чтобы продолжить читать с 300-й страницы, нужно было пролистать предыдущие 299.
Сразу возражу, то что они выводятся по одной за раз никак не влияет на механику постраничной навигации.
К тому же содержимое книги постоянно, а списки из БД могут меняться. их элемены могут добавляться/удаляться, поэтому что на какой странице находится не так уж и важно по большому счету. Никто такие списки не просматривает, начиная со страницы M. Аналогия с книгами неуместна, потому что списки на веб-страницах в общем случае не являются книгами, а не наоборот. К ним другие требования и возможности у них другие.
Указание номера страницы для щелчка — в любом случае плохое решение при разработке UI (прим.: мнение автора статьи).
Можно чуть подробнее раскрыть этот момент, почему «плохо»? В итоге мы получаем стрелочки
<- -> у которых «под капотом» скрывается id последнего отображенной сущности на странице?- Для получения номера последней страницы нужно выбрать и посчитать все записи. Уже при миллионах записей это работает никак. Для современных СУБД миллиард записей — нормальная ситуация. Даже для того, чтобы убедиться что страниц "очень много" (и можно забить на нумерацию) нужен достаточно тяжёлый запрос.
- Содержимое N-й страницы зависит от всех предыдущих и потенциально разное при каждом селекте.
- Ну и как правильно указали в статье — для номерной страницы часто используют offset, который в лучшем случае линейно зависит от номера страницы.
AND id < ?last_seen_idЭто для всех типов ID, или строго Integer? А то там может быть и истинно рандомный GUID.
Такие ограничения очень сильно уменьшает возможности использования этого метода.
В MS SQL часто по подходящему уникальному полю есть кластеризованный индекс, а значит его значения есть в каждом некластеризованном. В этом случае на самом деле индекс (sort_column) и (sort_column, unique_column) на уровне движка БД тупо одинаковый.
PS: Для Oracle и PostgeSQL это не так.
Чем сложнее механизмы выборки данных, тем сложнее пользователю понять правила начитки и ориентироваться со списком.
В частности, как замечено в статье, в случае составных индексов, сортировок и фильтров, сложные механизмы механизмы начинают лажаться. Пользователь теряется.
При разработке под DOS постраничная выборка была нужна т.к. на экране список был со статической таблицей из пары десятков строк и я все еще помню приемы, которые использовал в ранних 90х.
При переходе под Винды было круто делать постраничную выборку но скролируемый список с фильтром был также в ходу — толстый клиент позволял закачивать большие объемы в приложение.
С добавлением ограничения на кол-во строк, фильтр с сортировкой стал превалировать и мои пользователи стали отходить от постраничной выборки.
С переходом на веб-приложения в последние 10 лет в контролах используем исключительно:
1. ограничение на размер возвращаемых записей (200-500)
2. фильтр по всем колонкам (в некоторых колонках multi-select из списка возможных) и сортировку.
Значительно упрощает обращение к базе, понимание пользователем настроек выборки, скорость просмотра записей (грид без постраничной выборки).
А как без нее? Всю базу сразу вываливать?Ограничивать выборку и делать удобную фильтртацию по клонокам.
Как я писал выше «SELECT TOP 500 ...»
Если программист вываливает пользователю больше 1000 записей одновременно, то нужно пересмотреть дизайн грида.
P.S. так то почему нет, достойный способ, но не подойдет для краулеров, котороым нужно проиндексировать все данные.
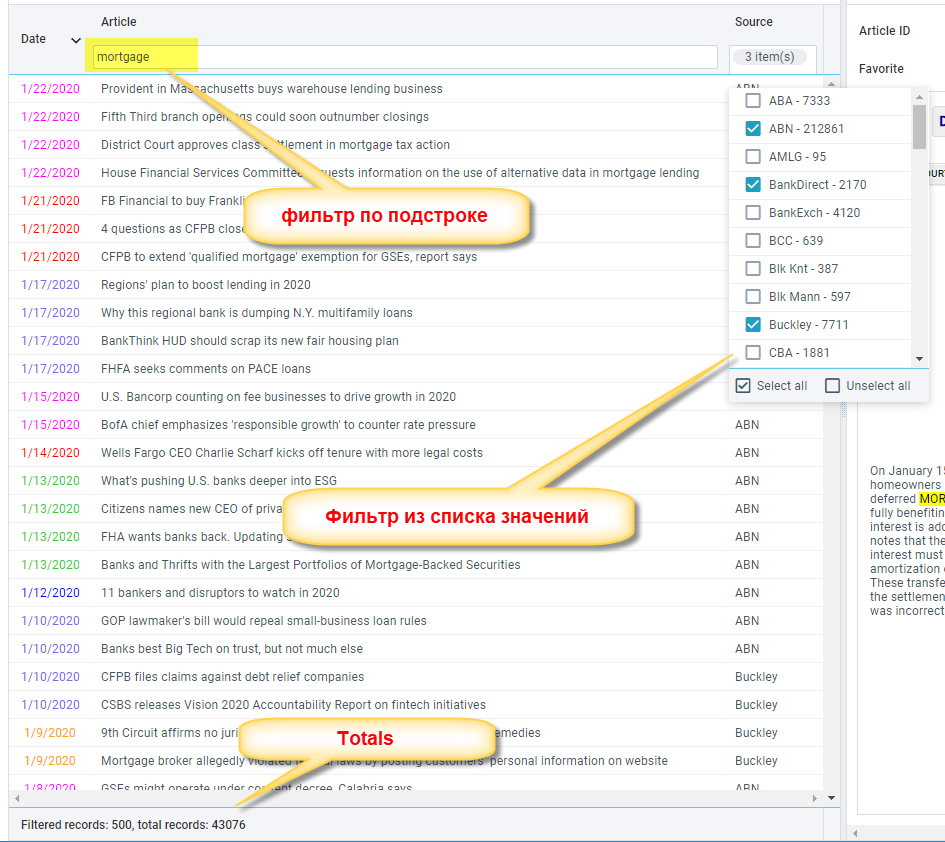
Интересно, что 1С с списками в экранных формах работает именно так — не через offset, а через top N where "записи ниже последней". Это и по причинам прозводительности и по причинам того, что 1С работает с 5 разными СУБД (часто используется общий функциональный минимум).
При этом, кстати, корректно обрабатывается сортировка по нескольким полям при том что первые поля (и комбинации левого "подкортежа" сортировки) не являются уникальными. Там, правда, нюанс — "корректно" не всегда значит "эффективно" — в некоторых пограничных случаях идёт жёсткий пролёт мимо удачного плана, к счастью, это достаточно редкие случаи, которых можно/нужно избегать (а в SQL Server 2005 c SP до четвёртого приводил к падению SQL Server, но это именно бага SQL Server).
Кстати, чтобы не пролетать мимо планов есть куда эффективнее способ сначала читать ключи, потом читать колонки. Чуть подробнее в недавней статье.
Ну и еще круче на самом деле отбрасывать сложные фильтры без индексов, находить более широкое «окно» на простых фильтрах для которых есть индексы, а потом добавлять это «окно» в фильтр, чтобы это окно протолкнулось в эти сложные фильтры (чтобы они расчитывались не для всей базы). Но пока так даже lsFusion не умеет, хотя вся инфраструктура для этого есть, возможно в будущих версиях и появится.
В статье как бы смешались все.
Начнем по-порядку.
Сначала надо бы заметить и об этом уже много написано что пагинация есть зло с точки зрния интерфейса (и это не касается эффективноси в базе данных)
Решения пагинанции по ключам просто не существует в природе. Т.к пагинация предполагает произвольный выбор страниц: 3-я, 124-я, 45-я и как в этом случае помогут ключи? Имеется в виду наверное пагинация в стиле next/previous. Но это же как бы совсем другой вид навигации.
Что касается этого вида навигации то всегда нужно иметь в виду два момента
1) В запросах всегда всенепременно необходимо задавать сортировку
2) Т.к. в общем поля сортировки не обязаны является первичным ключом, неободимо в качестве дополнительного поля сортировки задавать первичный ключ.
К тому факту что за момент просмотра страницы пройдут где-то вставки/удаления — некоторые системы это отслеживают в реальном времени. но это же дико грузит и сеть и сервер и приложения. Поэтому уже почти как аксиома кажется что набор является "отсоединенным" от базы данных и иного не моет быть. А еще лет 20 назад все так и было. данные в приложениях менялись мгновенно после изменения их на сервере.
Поддержка подобных запросов была бы хороша не только на уровне фреймворков, но и на уровне СУБД.
Уже несколько лет как я пишу по этой проблеме и делал доклад на JPoint, наиболее удачное изложение, на мой взгляд, здесь: dzone.com/articles/hidden-complexity-of-a-routine-task-presenting-tab
В целом в статье не только про фреймворки говорится, а что нет комплексных решений для такого подхода. Хотелось бы иметь сквозную технологию, которая упрощала бы все это на всех уровнях, от баз данных до исполнения на фронте
Не совсем понимаю какие проблемы с реализацией непрерывного скрола в тех же гридах с данными в смысле если отбросить проблемы с интерфейсом. Есть на самом деле интересные задачи. Например на популярном сайте который хостинг которое циклические видео нужно показывать список в порядке убывания рейтинга. Но рейтинг постоянно меняется и уже просмотренное видео может показаться в другом месте и его нужно исключить из показа. Или же в магазине с большой номенклатурой нужно показывать клиентам рандомный список товаров чтобы они равномерно продавались а не только те что в верхней части алфавита или в топе продаж.
Отдельная тема обновление данных естественно так чтобы не положить сервер. Тут уже были бы в помощь базы данных с подпиской на обновление. Такой функционал есть например у rethinktdb разработка которой к сожалению остановлена вендоргм и перешла в оперативную разработку и наверное уже практически не продвигается.
На самом деле, идеальный вариант это использование одного и того же курсора, которые, кстати, могут быть и двунаправленными, те можно читать и предыдущие строки. Переоткрытие курсора для пагинации в любом случае гораздо более тяжёлая операция, а особенно при отсутствии подходящих ключей. Есть, конечно, некоторая сложность в сохранении открытого курсора при трехзвенке, но вполне решаемая(как будет время, покажу мой вариант). А для двухзвенки, так вообще единственно правильный вариант.
Но курсоры это же не у всех без данных. Это же oracle и pervasive и может быть mssql не помню точно
В статье указан тег PostgreSQL, соответственно про долгоиграющие транзакции с открыми курсорами можно забыть. Это связано с особенностями реализации MVCC и возможным распуханием таблиц и индексов. С Ораклом вроде бы должно прокатить, потому что там MVCC работает совсем по другому, через Undo сегменты. Но сейчас мало кто делает монолиты, уж точно не Тинькофф, значит каждый запрос к back-end (дай следующую порцию данных из курсора) направляется балансировщиком к разным нодам/репликам. Получается, никаких долгоживущих курсоров. Но в теории да, курсоры были бы тут очень кстати, особенно вкупе с уровнем изоляции Repeatable Read, чтоб исключить большинство аномалий чтения.
Описанное Маркусом наивное решение подходит лишь для самых простых случаев, когда сортировки прибиты гвоздями в коде. Мне наверное так повезло, но все системы, в разработке которых я участвовал последние лет 20 (финансовая аналитика, страхование, банки и проч.), поддерживали множественные сортировки и фильтры по всем полям в гридах, во всех экранных формах. Юзер может кликать в заголовки колонок в гриде и выбирать одно или сразу несколько полей для сортировки, и менять её направление.
Это всегда динамический SQL, и значит индексы для чтения с диска "сразу в правильном порядке" тут не работают. Но при грамотном дизайне хранилища эта проблема решается. Идея в том, что индексы должны отработать раньше, еще до сортировок и лимитов, и это обычно какие-то особые хитрые индексы по всяким служебным полям в таблицах/mat. views.
В первую очередь большую БД хорошо бы распилить на мелкие кусочки и разнести их физически. Это сокращает размеры сегментов таблиц и высоту индексов, повышает степень параллелизма. Сначала оптимизатор выбирает ноду/шард/партицию, потом по комбинации индексов (partial/functional индексы в сочетании с бинарными рулят) получается уже небольшой кусок данных (ну например десятки тысяч строк), и потом только выполняются сортировки этого ограниченного набора — строго в оперативной памяти, это быстро. Иногда можно помочь оптимизатору избежать дисковой сортировки, подкрутив размер рабочей памяти у конкретных запросов. При скроллинге грида следующие порции выдаются повторными запросами быстрее, т.к. данные кешируются в буферах СУБД и ОС.
Почему нужна инструментальная поддержка пагинации на ключах