

Создание внутренней платформы разработки — спасение для больших компаний во многих кейсах: помогает избавиться от «зоопарка технологий», унифицировать стандарты и подходы, обеспечить безопасность и стабильно улучшать ИТ внутри компании. Но создание единой платформы — результат эволюционного пути развития, и часто этот путь занимает десятки лет.
Меня зовут Николай Панченко, я ведущий специалист обеспечения Kubernetes- и Cloud-безопасности в Тинькофф. Расскажу историю развития ИТ в компании: с чего начинали, как реализовали платформенный подход для безопасности K8s и что планируем в перспективе.
Немного истории
Тинькофф — один из крупнейших банков России, в его портфеле десятки всевозможных цифровых сервисов и масштабная ИТ-инфраструктура, работающая с петабайтами данных и миллионами запросов.
Но так было не всегда: технический бэкенд развивался вместе с банком и прошел длинный путь. В зависимости от состояния бизнеса и количества разработчиков, ИТ-ландшафта, взаимодействия между командами и уровня ИТ-безопасности мы условно делим путь развития ИТ банка на три глобальные эры:
- доисторическую эру;
- эру свободного DevOps;
- эру просвещенного SRE.

«Доисторическая эра»: 2006–2013
Начало «доисторической эры» мы относим к 2006 году. В банке на тот момент было одно направление — обеспечение финансовых ресурсов.
ИТ-ландшафт компании строился на вендорских системах: Oracle, Siebel, IBM. Также мы активно работали с подрядчиками. Это создавало трудности и ограничения, поскольку многие вещи мы не могли реализовывать и решать самостоятельно. Проблемой было и то, что безопасность также строилась на основе вендорских решений — в итоге нам приходилось исходить из того, что дают.
Регламентов взаимодействия между командами тоже не было, из-за чего случались ситуации с дублированием работы и непониманием ценности задач соседней команды.
В итоге основной задачей для ИТ и ИБ на этапе «доисторической эры» было добиться бесперебойной работы систем.
Мы понимали, что для ухода от трудностей и ограничений, которые отчасти стали системными, нам надо:
- наладить взаимодействие между командами;
- развернуть выделенную инфраструктуру с собственной командой поддержки и собственным стеком инструментов;
- снизить зависимость от вендоров, внедрить собственные практики безопасности и сделать ИБ более доступным.
Исходя из этих потребностей мы начали постепенную оптимизацию ИТ в компании:
- наняли дополнительных сотрудников — начали выстраивать CI/CD;
- начали разрабатывать свой стек, в том числе с инструментами для ИБ и сбора метрик;
- создали выделенные отделы DevOps и ИБ, которые начали изобретать и внедрять собственные практики, пытаться привести все к стандартам.
Реализация подобных нововведений позволила нам перейти к новой эре.
«Эра свободного DevOps»: 2014—2019
К моменту перехода в «эру свободного DevOps» в нашей команде было уже более 500 разработчиков и бизнес-линии. Появилась собственная инфраструктура: сделали Kubernetes as a service. Разработали свой инструментарий, но он был низкоуровневым, а иногда и низкокачественным, поскольку писали инструменты DevOps-специалисты и команда ИБ.
Были и трудности. Разрастание команды на фоне отсутствия строгих и общепринятых стандартов и регламентов, в том числе в части ИБ, приводило к Blame culture: в случае неудач все обвиняли всех. Также к тому моменту бизнес перетек в бизнес-линии, каждая из которых предъявляла свои требования к обеспечению безопасности — выполнить их все силами небольшого отдела ИБ без департамента было крайне сложно.
Целью ИТ и ИБ было поддержание бесперебойной работы систем на собственной инфраструктуре, но мы четко понимали, что не планируем останавливаться на достигнутом и тянуть за собой накопившиеся проблемы.
Основные задачи в период «эры свободного DevOps»:
- получение большего контроля над поставками в привязке к бизнес-линиям;
- унификация работы с инфраструктурой;
- изменение цели предоставления инфраструктуры: контроль поставок был минимальным, а в каждой бизнес-линии работали подходы к обеспечению безопасности, что создавало риски, в том числе из-за доступного API Kubernetes;
- создание компромиссной культуры взаимодействия между командами ИТ, DevOps и ИБ;
- формирование единого источника идей ИБ, распространяемых в компании.
Для решения поставленных задач и дальнейшего развития на этапе «эры свободного DevOps» мы проделали большую работу:
- Полностью отдали DevOps-инженеров в команды. Это позволило глубже погрузиться в особенности каждой команды и решать возникающие запросы более рационально. Также каждая команда получила постоянных консультантов из отдела ИБ.
- Начали рассматривать комплексные платформенные решения. Анализ рынка показал, что к тому моменту собственную платформу разработки создавали многие компании — для «заезда» в целевую инфраструктуру, в том числе на базе Kubernetes. Реализации во многом решали запросы компаний, поэтому мы начали погружаться в нюансы создания такой платформы.
- Перешли к комитетам, чтобы обеспечить принятие компромиссных решений, которые устраивают всех участников процесса: ИТ, DevOps, ИБ. На основе комитетов начали вырабатывать единые требования к нагрузкам в K8s.
- Выделили ИБ в отдельный департамент и разработали распространяемый набор требований с учетом Defense in depth для получения глубокоэшелонированной защиты.
«Эра просвещенного SRE»: 2019 — н. в.
К моменту перехода в «эру просвещенного SRE», в 2019 году, бизнес и ИТ были уже зрелыми:
- компания выросла до бизнес-вертикалей;
- в штате было больше тысячи разработчиков;
- появилась своя инфраструктура, пока не платформенная, и стек своих инструментов;
- была выстроена культура взаимодействия между командами.
Но во многих вопросах у нас еще оставалось поле для доработок. Например, нам требовалось:
- сделать DevOps и ИБ доступнее, унифицировать практики — ввести единые требования ИТ и ИБ и так далее;
- управлять не только скоростью, но и качеством;
- предоставить необходимый удобный стек инструментов, реализовать удобные интеграции;
- убрать узкие места, которые на больших нагрузках плохо масштабируются, что было важно с учетом разрастания компании и появления новых бизнес-вертикалей;
- окончательно подружить ИТ с командой безопасности по целям и совместным решениям общих проблем.
С учетом имеющегося опыта и экспертных знаний, полученных в результате анализа реализаций других компаний, мы понимали, что закрыть эти потребности поможет создание единой платформы разработки.
От хаоса к структуре: платформа разработки
Работу над платформой мы начали во второй половине 2020 года. В первую очередь определили продуктовое видение платформы. Нам было важно, чтобы она обеспечивала:
- простые интерфейсы запуска и контроля приложений;
- простоту доставки приложений;
- харденинг и единую точку доступа к инфраструктуре;
- безопасную и надежную инфраструктуру.
Техническую реализацию мы начали с внутреннего исследования для определения потребностей собственных Kubernetes-кластеров. На этом же этапе стало понятно, что с переходом от IaaS к продуктовому подходу мы можем разделить Kubernetes, который стал целевой инфраструктурой, на три проекта (массива) под разные задачи:
- Build platform, который отвечает за сборку и доставку приложений, анализ на уязвимости и другие задачи;
- Runtime platform, который отвечает за обработку нагрузок;
- ML platform для работы с машинным обучением.

В самой платформе мы постарались консолидировать все решения, модули и сервисы, которые использовались в компании и были необходимы для безопасной разработки. Например, в рамках платформы у нас есть SSO, IAM, API Gateway, DWH, сервис контроля релизов и не только.
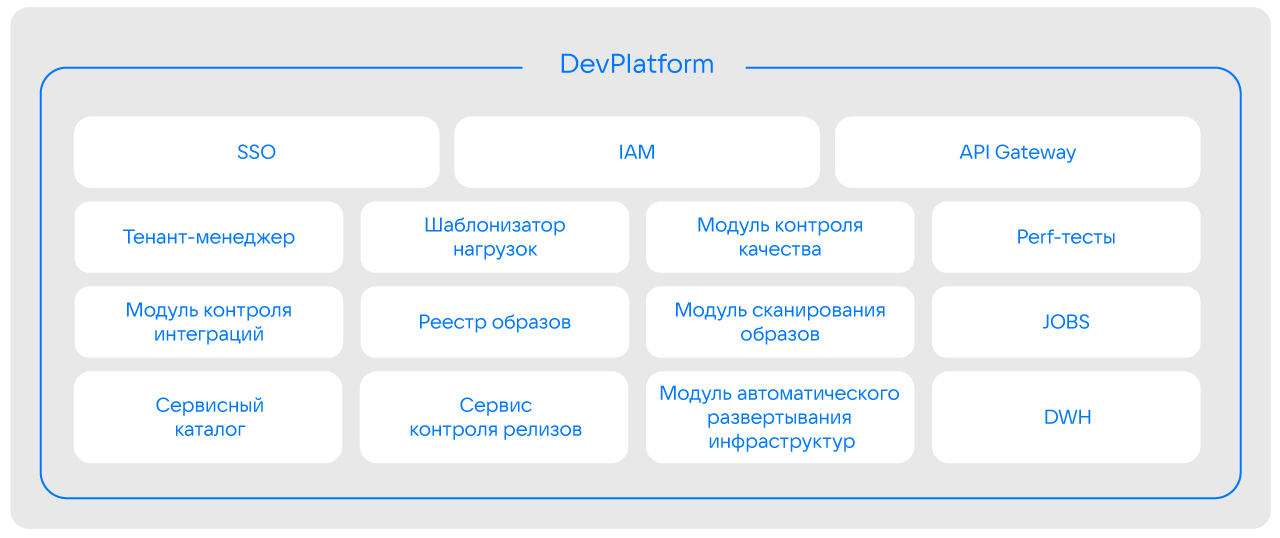
После консолидации решений мы приступили к разработке алгоритма работы с платформой, в том числе в части проработки цепочки поставок. После анализа пришли к следующему алгоритму:
- прорабатываем цепочку поставок;
- обеспечиваем доступ в кластер;
- реализуем минимальный харденинг нагрузки;
- анализируем контроль сети;
- обеспечиваем глубоко проработанный харденинг.
Для контроля поставок мы используем GitOps — оптимальное решение для нашей реализации на нынешний момент. Причина в том, что кластер сам себя деплоит, а мы обработали контроль поставок так, чтобы сертификаты невозможно было украсть из Git.
Чтобы реализовать полный цикл контроля поставок, мы:
- Выделили отдельную Built-инфраструктуру для обеспечения CI/CD. Запустили продукт для разработки безопасных базовых Golden-образов, которые дальше передаем в команды. Таким образом мы получаем подобие собственной Distroless-реализации.
- Внедрили GitOps, осуществляем доставку и развертывание через ArgoCD.
- Начали унифицировано использовать Vault для хранения секретов, что позволило создать удобные интеграции. Благодаря этому мы смогли отказаться от практики самостоятельного указания аутентификационных данных в конфигах и получили возможность контролировать через репозиторий ветки рабочих продуктов.
- Внедрили автоматическое сканирование на уязвимости и начали контролировать безопасность образов.
- Используем единый Service catalog для инвентаризации и контроля всех приложений компании, запускаемых в Kubernetes.
- Обеспечиваем мультитенантность: каждой команде выделяем Namespace и изолируем на уровне неймспейса. Благодаря этому можно накатывать харденинг на отдельные неймспейсы — и мы можем быть уверены, что команде видны только ее нагрузки, без доступа к данным всей платформы. Также мы внедрили собственную ролевую модель с разграничением на отдельные команды.
Контроль доступа в кластер, RBAC, мы тоже тщательно проработали. Нас не устраивал сценарий с цепочкой поставок, при которой все пытаются получить доступ к кластеру. Поэтому мы реализовали ряд мер в этом направлении:
- Написали свой IAM, сделали его собственным в рамках платформы и интегрировали с AD компании. Работаем через авторизационные хуки.
- «Отрезали» все ненужные «ручки» в API K8s, чтобы максимально исключить риски: пользователи получают только нужные «ручки» в рамках назначенных ролей специалистов и задач команд. Также создали собственные роли нашего IAM и разработали принцип их соотношения с Kubernetes-ролями.
- Ограничили доступ команд, оставили вход только в нужные им неймспейсы.
- Внедрили практику формирования персонального конфига kubectl по запросу через платформу и управления через специальные атрибуты.
Контроль сети, работа с CNI. Изначально мы использовали Calico, который работал на L2. Но при создании собственной платформы мы столкнулись с рядом ограничений: например, при росте нагрузки нам приходилось постоянно в ручном режиме запрашивать дополнительные ресурсы, но и это не давало гарантии быстрого получения нужных машин.
В итоге мы занялись поиском нового CNI и после сравнения вариантов выбрали Cilium на eBPF. Мы начинали работать на L3, но после решили поднять абстракцию сетевого взаимодействия на уровень L7, чтобы обеспечить максимальную безопасность взаимодействия между сервисами — как внутренними, так и внешними.
Контроль входа на ингрессах мы решили осуществлять через контроль балансировщиков и политик Istio. Это связано с тем, что изначально мы работали с Nginx Ingress, но он не справился с увеличивающимися нагрузками (в том числе gRPC-нагрузками) при росте банка. В итоге мы сделали свою реализацию на основе Istio & Envoy. А дополнительно, для защиты внутренних точек входа приложений от внешних подключений мы физически разграничили Ingress на External и Internal.
Еще мы решили отдать написание сетевых политик в команды с согласованием от ИБ. Чтобы исключить появление «зоопарка политик», мы разработали четкое описание, что позволило обеспечить унификацию реализаций. Таким образом мы смогли снять нагрузку с ИБ и DevOps, которые раньше отвечали за политики.
Кроме этого мы отключили Port-Forward с предоставлением тулинга — от идеи до реализации на это ушло около полугода. Но в результате мы смогли безопасно и без влияния на бизнес-процессы отказаться от Port-Forward в пользу внутренних сервисов.
Контроль нагрузок и харденинг мы также обеспечивали комплексно. Например, мы выработали жесткую политику контроля нагрузок, в рамках которой закатали все в ИТ-квоты и запретили повышенные привилегии.
Одновременно с этим мы внедрили политики OPA через Gatekeeper и контроль OPA, а также развернули средства защиты K8s. Для проверки эффективности выстроенной защиты проводим регулярные внутренние и внешние тестирования на проникновение в наш Kubernetes.
Планы: «эра иммутабельности, харденинга и ИИ»

Следующим этапом развития ИТ в компании мы считаем переход в «эру иммутабельности, харденинга и ИИ». Чтобы осуществить такой прыжок, мы планируем:
- перейти к иммутабельной инфраструктуре и работе на железе — использовать Talos Linux для харденинга K8s на уровне железа и OS;
- внедрить подсистемы изоляции и автоматического развертывания без участия команд разработчиков — вывести пользователей из кластера, забрав у них kubectl;
- реализовать более жесткий контроль K8s с помощью продвинутых средств защиты и переосмыслить работу SOC;
- внедрить искусственный интеллект в собственную систему логирования для анализа логов;
- продолжать модификацию внутренних процессов компании в сторону безопасной разработки кода и внедрять лучшие практики безопасности.
Итоги внедрения платформенного подхода
Внедрение платформенного подхода и создание собственной платформы разработки позволило нам:
- уйти от «зоопарка технологий» и выработать общие стандарты работы для всех команд, как результат — упростить онбординг новых специалистов;
- поддерживать синергию между ИТ, DevOps, ИБ и бизнесом, в том числе с помощью комитетов;
- минимизировать количество потенциально уязвимых мест и уменьшить поверхность атаки;
- управлять не только скоростью, но и качеством для получения защищенной и эффективной экосистемы внутри компании.
Чтобы понять, нужна ли своя платформа разработки, достаточно ответить на три вопроса:
- Сколько разработчиков в компании? Нам кажется, внедрение такого решения оправданно, если разработчиков становится больше тысячи и без унификации работа скатывается в хаос.
- Готова ли компания внедрять у себя платформенный подход? Разработку платформы рационально начинать с глубокого анализа и унификации практик внутри компании, на что бизнес не всегда согласен.
- Достаточно ли у компании ресурсов и времени на создание собственной платформы? На разработку платформы у нас уже ушло четыре года, и работа еще продолжается. При этом в процесс вовлечено около 50 разработчиков и сотрудников других департаментов. Это большие ресурсы, поэтому создание платформы должно быть оправданно.
Если подобный порог входа не смущает и своя платформа действительно нужна, начинать стоит последовательно:
- Проведите внутренний анализ потребностей собственных кластеров.
- Детально проработайте RBAC.
- Поработайте над харденингом нагрузок.
- Модифицируйте процесс контроля сети.
- Проанализируйте цепочку поставок на наличие узких или потенциально уязвимых мест.
Удачи! Дорогу осилит идущий!
Материал подготовлен по мотивам моего доклада на VK Kubernetes Conf.
