DBA: грамотно организовываем синхронизации и импорты
9 мин
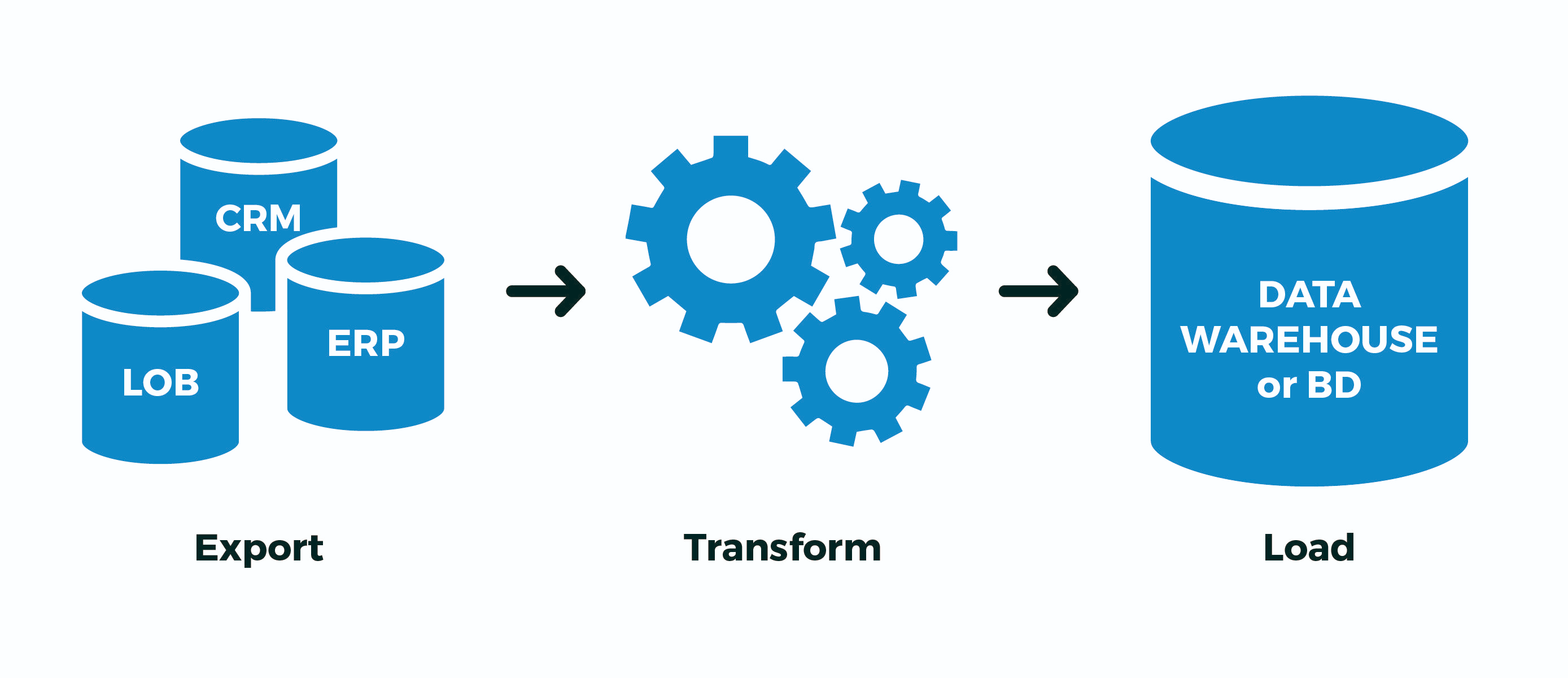
При сложной обработке больших наборов данных (разные ETL-процессы: импорты, конвертации и синхронизации с внешним источником) часто возникает необходимость временно «запомнить», и сразу быстро обработать что-то объемное.
Типовая задача подобного рода звучит обычно примерно так: «Вот тут бухгалтерия выгрузила из клиент-банка последние поступившие оплаты, надо их быстренько вкачать на сайт и привязать к счетам»
Но когда объем этого «чего-то» начинает измеряться сотнями мегабайт, а сервис при этом должен продолжать работать с базой в режиме 24x7, возникает множество side-эффектов, которые будут портить вам жизнь.
Чтобы справиться с ними в PostgreSQL (да и не только в нем), можно использовать некоторые возможности для оптимизаций, которые позволят обработать все быстрее и с меньшим расходом ресурсов.
Типовая задача подобного рода звучит обычно примерно так: «Вот тут бухгалтерия выгрузила из клиент-банка последние поступившие оплаты, надо их быстренько вкачать на сайт и привязать к счетам»
Но когда объем этого «чего-то» начинает измеряться сотнями мегабайт, а сервис при этом должен продолжать работать с базой в режиме 24x7, возникает множество side-эффектов, которые будут портить вам жизнь.
Чтобы справиться с ними в PostgreSQL (да и не только в нем), можно использовать некоторые возможности для оптимизаций, которые позволят обработать все быстрее и с меньшим расходом ресурсов.