Привет, Хабр! Меня зовут Иван Вахмянин, и сегодня я хочу рассказать о том, что находится “под капотом” у современной BI-системы, от чего зависит ее производительность (и как можно её ненароком убить), и какие технические оптимизации позволяют технологии In-Memory OLAP выигрывать по скорости у других подходов.

Вообще, современные BI-платформы — это очень умный софт, который незаметно для пользователя делает множество оптимизаций, и чаще всего не требует каких-то особых ухищрений для настройки производительности. Но когда нагрузка становится действительно серьезной, BI-системой начинают пользоваться сотни пользователей, и решение обрабатывает сотни миллионов и миллиарды строк данных, иногда что-то идет не так.
С точки зрения бизнеса это бывает очень грустно. Какой-то пользователь создает дашборд, и всё падает. При этом увеличение объема памяти и количества процессоров не даёт почти никакого эффекта. Предотвратить или быстро решить такую проблему гораздо проще, если хотя бы в общих чертах представляешь, как система работает «под капотом».
Когда мы только начинали работать в сфере BI 5 лет назад, в основу продукта Visiology легла open-source библиотека Pentaho — Mondrian. Но достаточно быстро мы столкнулись с проблемами по части производительности и начали самостоятельно разрабатывать In-Memory OLAP движок под названием ViQube (об этом можно почитать в другой нашей статье — Как разработать BI-платформу — наш трудный, но интересный опыт). Собственно, в процессе этой разработки мы и накопили опыт, которым сейчас хотим поделиться.
На первый взгляд, все BI-платформы выглядят одинаково: у вас есть источники информации, у вас есть инструменты загрузки, анализа и визуализации данных, а на выходе пользователь получает разнообразные отчеты — от печатных форм до дашбордов, в том числе на мобильных, на видеостенах, на любых устройствах. В своей основе все BI-инструменты используют модель данных на основе OLAP (On-Line Analytical Processing, многомерное представление данных), но техническая реализация OLAP движка (который непосредственно занимается вычислениями) может быть реализован по-разному, и от этого очень сильно зависит производительность и масштабируемость системы.

— MOLAP
Технология OLAP возникла ещё в 80-х годах. В то время процессоры были намного медленнее, да и память была в дефиците, поэтому чтобы аналитик мог реально работать с данными в онлайн-режиме, придумали такую вещь как MOLAP (Multidimensional OLAP). Идея подхода в том, что для всего многомерного куба после загрузки данных производится предрасчет: на узлах иерархий предварительно рассчитываются агрегации, чтобы под любой более или менее типовой запрос пользователя можно было получить результат запроса без необходимости пересчитывать все строки. Да, при любом изменении данных нужно долго пересчитывать куб, а объем рассчитанного куба может быть в разы больше исходного датасета, но в то время других вариантов не было. MOLAP до сих пор существует и используется, например, в SQL Server Analysis Services, но на практике его используют все реже и реже.
— ROLAP
Позже появилась реляционный OLAP, или ROLAP. Отличие от MOLAP заключается в том, что не происходит никакого предварительного расчёта агрегаций, а вычисления происходят на СУБД из бэкэнда BI-платформы. В этом случае пользователь работает с удобными инструментами, например, с конструктором дашбордов, а под капотом ROLAP-движок преобразует его запросы на лету в SQL, и они просто выполняются на какой-то СУБД.
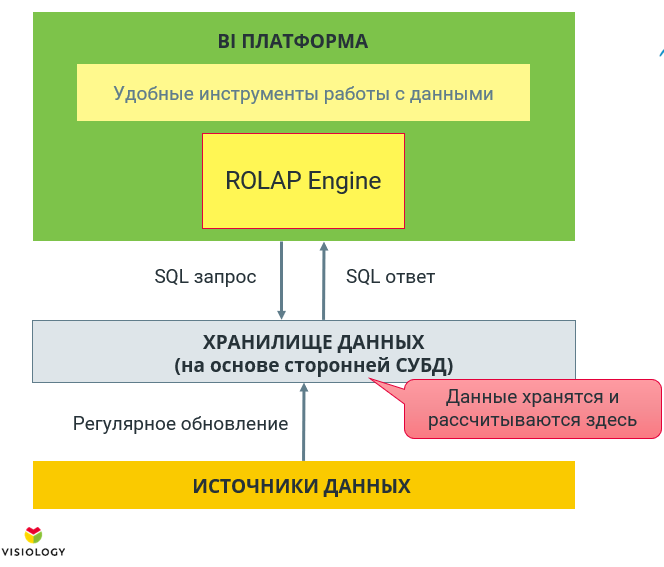
Подобный подход характерен, например, для таких open-source систем, как Pentaho или Metabase или проприетарного SAP Business Objects, Oracle OBIEE.
У ROLAP есть целый ряд недостатков. Во-первых, если, не использовать на бэкенде специальные аналитические СУБД, такие как ClickHouse или Vertica, все будет работать ооочень медленно (дальше будет понятно, почему). Во-вторых, даже при использовании аналитической СУБД, при работе с ROLAP очень неэффективно используется кэш, потому что СУБД и BI-платформа работают отдельно друг от друга. В-третьих, поскольку не все аналитические задачи можно завернуть в SQL-запрос, ограничивается аналитическая функциональность. Но зато, на сегодняшний день ROLAP — это единственный способ работы с реально большими объемами данных, которые не помещаются в память.
— In-Memory OLAP
Если речь идет о работе с данными объемом до терабайта, как правило, используется схема In-Memory. Данные постоянно находятся в памяти, и за расчеты отвечает специальный движок. В системах Qlik — это QIX, Power BI использует SQL Server Tabular Engine, который раньше был продуктом xVelocity, но Microsoft купил эту компанию, и теперь движок является частью MS SQL Server. У нас в Visiology движок In-Memory OLAP называется ViQube.
In-Memory OLAP привлекает простотой установки и работы, подобные движки изначально интегрированы в BI-платформы и укомплектованы удобными визуальными интерфейсами настройки, загрузки данных, управления правами и т.п. За счет размещения данных в памяти и специальных оптимизаций (про них ниже) многократно растет скорость обработки, расширяются возможности для аналитиков.

При этом у подхода In-Memory есть и свои недостатки. И главный из них — это предел емкости памяти. Если объем данных измеряется в терабайтах, вам нужно либо строить дорогой кластер, либо склоняться к ROLAP. Кроме этого, при таком подходе не всегда удается минимизировать задержку отображения обновлений, потому что для этого данные приходится перегружать из источника в память.
— Гибридный OLAP
Основной схемой работы для большинства промышленных BI становится гибридная схема с одновременным использованием и In-Memory OLAP, и реляционного OLAP-движка. Горячие данные хранятся в In-Memory, холодные данные, которые не влезли в заданный объем, — в СУБД. Такое решение в QlikView, например, называется Direct Discovery, в Power BI — Direct Query. В Visiology тоже поддерживаются интеграции с несколькими СУБД, в том числе с ClickHouse.
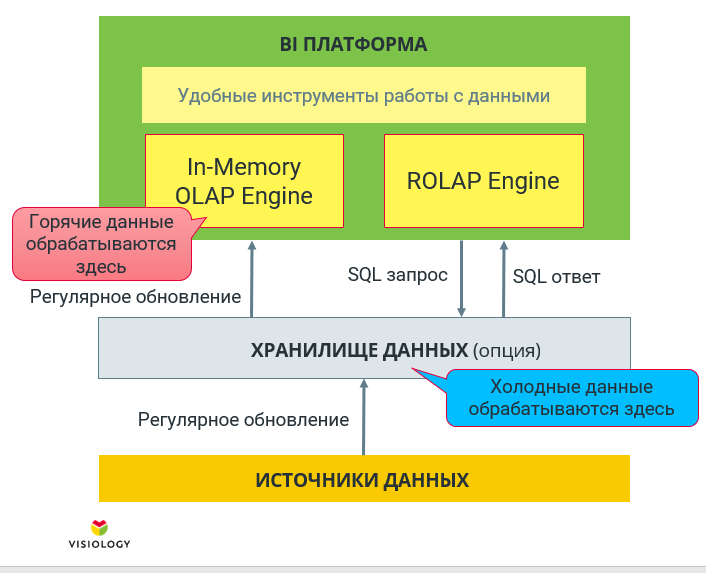
Кстати, выбор СУБД для гибридного режима также критически важен. Если мы будем работать с PostgreSQL, в котором лежит 5 терабайт данных, аналитические запросы будут исполняться крайне медленно. И если у вас не SAP HANA, придется вручную распределять данные на холодные и горячие. Как следствие, не все аналитические функции будут доступны на полном объёме данных. Но если памяти не хватает, увы, с таким положением дел приходится мириться.
Для скорости работы In-Memory OLAP есть как очевидные, так и скрытые причины. Тот факт, что работа движка происходит в памяти, а она намного быстрее, чем жесткий диск (спасибо, кэп) — это только 1/10 правды. Но давайте подумаем, как работают реляционные СУБД, например, тот же PostgreSQL. Ведь он в какой-то мере тоже является In-Memory. И вообще, любая современная СУБД активно использует как блочный кэш в памяти, так и внутренний.

Когда обычной дисковой СУБД, такой как PostgreSQL, нужно считать данные с жёсткого диска, она обращается к накопителю и считывает какую-то страницу. Эта страница помещается в блочный кэш (в Linux он располагается в свободном пространстве памяти). Допустим, у нас есть 128 гигабайт памяти, и 20 из них мы занимаем софтом. Всё остальное может использоваться под блочный кэш. И если СУБД нужно будет считать с этой страницы ещё что-нибудь, она возьмет эту информацию из памяти. И от того, насколько эффективно используется кэш, зависит производительность. Если для анализа используется, скажем, 30-40 гигабайт данных, мы можем расширить емкость оперативной памяти на сервере и уже после первого чтения СУБД все данные окажутся In-Memory, а обращения к диску на чтения будут происходить лишь эпизодически.

Кроме этого, у “умных” СУБД, в том числе у Postgres, имеется механизм cache-aware управления. Они могут выбирать, что складывать в кэш, а что – нет, какие данные надо заново прочитать с диска.

Источник: www.enterprisedb.com/blog/autoprewarm-new-functionality-pgprewarm
На графике выше — влияние прогрева кэша на производительность PostgreSQL. Жёлтым показана производительность в зависимости от времени, и наглядно видно, что по мере работы пользователей СУБД считывает данные, постепенно раскладывает всё в In-Memory и достигает предела своей производительности. Если же использовать prewarm и дать Postgres команду поднять все данные в память сразу, максимальная производительность достигается сразу.
Также стоит учитывать, что мы говорим об аналитической нагрузке. Она очень сильно отличается от транзакционных задач, когда в базу нужно внести запись о покупке в интернет-магазине или считать 10 строк с историей заказов. На графике ниже показан типовой аналитический запрос из теста TPC-H. Этот тест состоит из нескольких десятков реальных аналитических запросов и широко используется для нагрузочного тестирования.

Источник: www.tpc.org/information
В SQL-запросе из теста TPC-H можно найти много чего интересного. Во-первых, запрос идет не на поля, а на агрегации. Во-вторых, здесь присутствуют линейные арифметические операции. В-третьих, здесь часто встречаются фильтры по полям с малой кардинальностью: регионы и федеральные округа, в которых работает компания, типы клиента — активный, неактивный и так далее. В-четвертых, часто используются фильтры по полю с датой. Если мы изучаем динамику выручки, то нас интересуют такие периоды как год или квартал.
На входе подобного запроса всегда очень большое количество строк — миллионы или даже миллиарды. Поэтому СУБД вынуждена делать серию полных сканирований. С другой стороны, на выходе получается небольшое количество строк, ограниченное количеством точек, которые можно отобразить на графике — чаще всего десятки или сотни значений. Зная эти особенности аналитических запросов, можно провести оптимизацию и получить прирост производительности.
Учитывая особенности аналитических запросов, о которых мы уже говорили ранее, для движка BI возможен целый ряд оптимизаций, причем как технических, так и эвристических. Давайте рассмотрим их подробнее.
1. Колоночное хранение данных
Это первый шаг, дающий заметный эффект. Для обычных транзакционных запросов хранение в строках подходит оптимально. Но для аналитики необходимо получать данные по столбцам. Казалось бы, какая разница, ведь все это уже In-Memory? Но на практике кроме памяти, которая быстрее дисков, у нас также есть кэш процессора, как правило, трехуровневый. Он работает намного быстрее, чем память, доступ к которой занимает примерно 200 тактов процессора.

Процессор может считать из памяти только целую страницу, которая сразу попадает в кэш того или иного уровня. И если следующее нужное значение попало в эту же страницу, мы потратим 10-40 тактов, а если нет — в 10 раз больше. При колоночном режиме хранения при запросе мы получаем страницу памяти, в которой, скорее всего, будут лежать все данные из одной колонки. Поэтому процессору во много раз реже нужно будет обращаться к основной памяти.

Источник: arstechnica.com/gadgets/2002/07/caching/2
2. Сжатие
В этой оптимизации есть свои особенности. Для дисковых СУБД — это обязательная оптимизация. Здесь мы выигрываем за счет того, что реже ходим в медленное хранилище, но также проигрываем, потому что данные надо распаковать, а это — вычислительно ёмкая операция. Для дисковых СУБД получается очень выгодно, для In-Memory — все не так очевидно, потому что читать из памяти обычно быстрее, чем заниматься распаковкой.

Источник: www.percona.com/blog/2016/03/09/evaluating-database-compression-methods
Самый быстрый из алгоритмов сжатия по скорости распаковки — LZ4. Он в среднем уменьшает размер всего в 2 раза, но зато очень быстро распаковывает, со скоростью порядка 500 мегабайт в секунду на ядро процессора. В бенчмарке на графике LZ4 вообще показал результат 3 гигабайта данных в секунду. Такая скорость дает очень хороший выигрыш для дисковых СУБД, скорость чтения для которых – те же 500 мегабайт в секунду. Но для памяти скорость передачи данных составляет десятки гигабайт в секунду, получить преимущество за счёт LZ4 оказывается сложно.
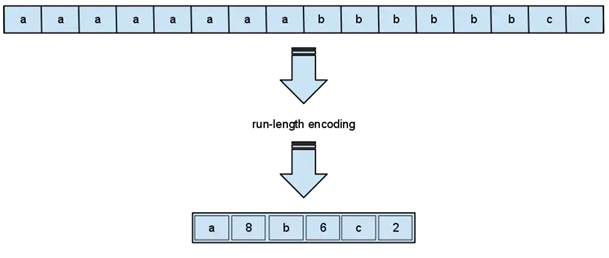
Однако не стоит забывать, что мы чаще всего работаем с данными низкой кардинальности. Например, в строке с названиями торговой точки очень часто будут повторяться одни и те же значения или их ID: “Москва, Москва, Москва, Москва…”
Источник: Guassian and speckle noise removal from ultrasound images using bivariate shrinkage by dual tree complex wavelet transform (Professor G R Sinha, 2015)
Для подобных данных есть ещё один алгоритм, который называется Run-length encoding. Он работает очень просто: строки типа ААААВВВВВСС он сжимает в виде 4A5B2C. Это прекрасный подход для данных с низкой кардинальностью, он помогает экономить память и оптимальнее использовать кэш процессора.
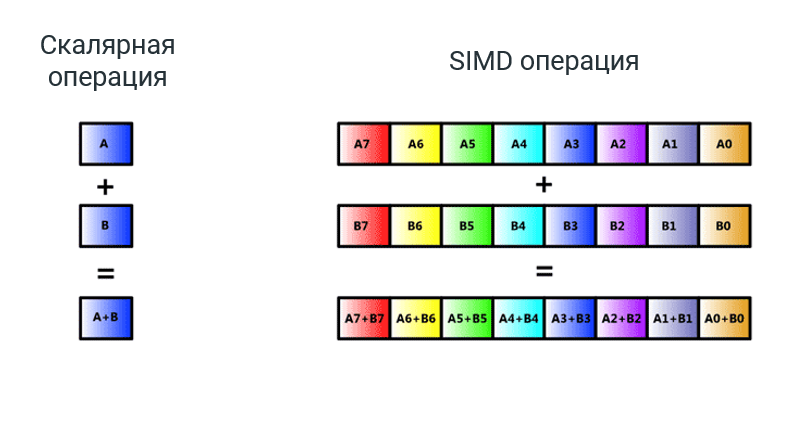
3. Векторные инструкции
Чтобы сложить 2 числа, мы кладём в один регистр процессора одно число, а в другой регистр — другое. Для ускорения этого процесса существуют векторные регистры и векторные операции (SIMD — Single Instruction Multiple Data). Они позволяют за одну операцию сложить сразу N чисел. Это уже очень зрелая технология, которая появилась в процессорах еще в 1993 году. Она поддерживалась еще в Pentium MMX (166 МГц — у меня такой был, до сих пор помню, как на него термопасту намазывал).
Источник: www.codetd.com/en/article/9633503
В Pentium MMX векторных регистров было 8, и они были рассчитаны только на целочисленную арифметику. На текущий момент практически во всех процессорах есть 128-битные регистры SSE и наборы инструкций. Регистры AVX уже 256-битные, а в серверах есть даже AVX 512. Они работают с числами с плавающей запятой, и их можно использовать для оптимизации аналитической нагрузки.

Источник: technews.tw/2020/07/16/linus-torvalds-avx-512-critique
При работе с AVX 512 мы можем обрабатывать в одном регистре 16 чисел со стандартной точностью. Теоретически тут можно получить хороший выигрыш, но для этого необходимо преодолеть ряд технических сложностей. Чтобы при компиляции оптимизация работала, нужно предусмотреть ее при написании кода. Для этого используются интринсики – особый набор функций, которые в явном виде указывают компилятору, какие инструкции процессора нужно использовать.
Вот пример, как для расчёта скалярного произведения используется AVX-инструкции 256-битных регистров.

На нашей практике использование именно AVX даёт от 1 до 10% прирост производительности, в зависимости от задач. Когда вы используете современную BI-систему, в зависимости от конкретного процессора, система будет применять разный код. Производительность от этого увеличивается, но не драматически, а в лишь в небольших пределах.
4. Поздняя материализация
Материализация — это процесс формирования результата, ответа на запрос. Например, простой SQL-запрос SELECT C1, С2, D1, D2 из 2 таблиц, получит 2 поля из одной и 2 поля из другой таблицы. Далее мы соединяем их по ключу — С1=D1.
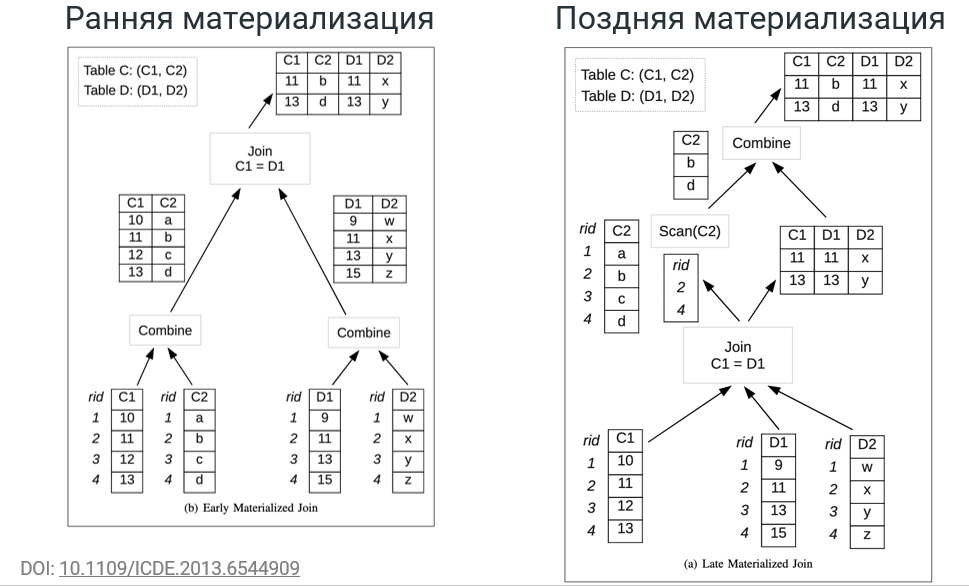
В случае ранней материализации мы получаем 4 колонки и работаем с колоночной базой. То есть мы сначала берём С1 и С2, соединяем их в таблицу. Потом делаем то же самое с D1, D2 и после этого выполняем Join, то есть формируем строки из этих 2 таблиц, для которых истинно условие С1=D1.
В случае аналитической нагрузки на выходе всегда мало данных, потому что фильтры отсекают достаточно много значений. Когда выполняется JOIN, создаётся очень большая таблица, которая не нужна. Ведь на последней операции будет отброшено много данных.
При поздней материализации мы сначала разбираемся, что и в какой колонке нам нужно. Сначала выполняется операция JOIN С1 = D1, и мы выбираем нужные нам значения только из правой таблицы. Это можно сделать за один проход. А после этого можем взять из таблицы С только те поля, строки которых после JOIN остались. В итоге не нужно создавать большую промежуточную таблицу.
Конечно, такая оптимизация не сработает на любой нагрузке. Исследования Vertica, например, показывают, как многопрофильная СУБД позволяет выбирать различные стратегии материализации, в зависимости от задач. Но именно для BI характерна нагрузка, связанная с поздней материализацией, поэтому ее использование предпочтительно.
5. Эвристические оптимизации
In-Memory OLAP чаще всего является неотъемлемой частью BI-платформы, а BI-платформа прекрасно “знает”, какие данные в нее загружаются, как пользователь с ними работает. Конечно, это неочевидные вещи, они происходят “под капотом” BI-системы и не всегда даже видны, но позволяют получить хороший прирост производительности.
Во-первых, часто применяется автоматическая нормализация или денормализация. Данные с низкой кардинальностью иногда бывает выгодно нормализовывать, а иногда — наоборот. Чаще всего BI-платформы стараются максимально денормализовать таблицы. Такой подход позволяет максимально избегать достаточно тяжелых операций JOIN. Пользователь может даже не видеть этого: если мы загрузили в систему 2 таблицы и связали их по ключу, система может сразу превратить их в одну таблицу.
В некоторых случаях, наоборот, происходит автоматическая нормализация. Если поле очень жирное, например, с текстовым комментарием, держать его по всей колонке будет неоптимально. Вместо этого такое поле можно автоматически вывести в справочник. Вы будете видеть в таблице и строку, и столбец, а на самом деле данные будут находиться в отдельной таблице, а в памяти будет находиться только ID. Такие методики используются довольно часто.
6. Сортировка по календарю
Поскольку мы работаем с данными, которые практически всегда растянуты во времени, стоит учитывать интерес пользователей – а он чаще всего сконцентрирован на ближайших данных. Поэтому оказывается выгодно сортировать данные по календарному измерению. Действительно, если пользователь работает с текущим годом, зачем ему данные “с начала времён”?
Однако, если вы храните дату в виде строкового столбца, BI-система не сможет оптимизировать данные. Но если сортировка удается, иногда получается свести большой датасет к очень компактному, просто выкинув из него все года, кроме текущего.
7. Разделяемый кэш
Пользователи BI часто работают с одними и теми же данными. Поэтому хорошую эффективность показывает разделяемый кэш. Если пользователь А запустил дашборд и выполнил свой запрос, то пользователь В на том же дашборде сможет получить результат быстрее, потому что необходимые данные будут уже в кэше.
Разделяемый кэш под запросы позволяет кэшировать данные внутри запросов. Например, один пользователь запросил аналитику и отфильтровал её по отделу А, а другой хочет по отделу В. В этом случае оптимизации не получится, потому что фильтрация происходит на раннем этапе. Но в некоторых случаях и для подобных ситуаций удается оптимизировать запрос.
8. Обратный индекс
Многие BI-системы выстраивают обратный индекс для строковых полей. Он позволяет ускорить поиск с операторами по строкам. И хотя BI-системы и OLAP движок In-Memory — это не замена полнотекстовому поиску, подобные оптимизации встречаются достаточно часто.
Все перечисленные меры помогают сделать BI-систему, основанную на In-Memory OLAP, более устойчивой и производительной, не прибегая к гибридным схемам работы с подключением реляционных БД. Рост производительности сильно зависит от используемых задач, но в процессе работы над ViQube мы убедились в том, что оптимизации лучше всего закладывать на этапе исходного кода и изначально проектировать систему с учетом особенностей аналитических запросов.
Кроме этого, на своем опыте мы нашли ряд кейсов, которые позволяют легко “убить” производительность In-Memory OLAP. Можно считать этот набор “вредных советов” пасхалочкой для тех, кто дочитал до конца :)
BI-система, работающая на базе In-Memory OLAP, уже по определению имеет высокую производительность — однако она не будет неубиваемой! Ниже — список из 5 “вредных советов” по In-Memory, выстраданных на своей шкуре в процессе разработки движка ViQube и его использования в реальных проектах.
Прекрасными убийцами производительности In-Memory систем являются запросы, в которых плохо работает векторизация. Любые вычисления с использованием нелинейных функций, которые задействуют много полей, приводят к радикальному снижению скорости работы системы.
Очень часто в своей практике я сталкивался с тем, что аналитик пишет какое-то выражение на Qlik Expressions или на DAX в Power BI, которое хорошо работает, когда в базе 10 тысяч строк. Но по мере роста масштабов производительность начинает деградировать невероятными темпами.
Обычно это происходит потому, что формула запроса сложна и не даёт движку использовать преимущества колоночного хранения векторных инструкций. Вместо этого системе приходится находить все поля по строкам, перебирать их одну за другой. В этом случае производительность падает до уровня СУБД со строчным хранением. Конец оптимизации.
Вложенные запросы — крайне важная в аналитике вещь. Очень часто результатом ответа на первый запрос оказывается таблица, и по этой таблице мы производим дополнительный анализ. Например, в DAX подобный подход легко реализуется с помощью так называемых контекстов, и поэтому он весьма популярен среди аналитиков. Возможность создавать вложенные запросы есть и в других движках.
Однако пользоваться такими запросами нужно аккуратно. Ведь если первый запрос возвращает большой промежуточный результат (например, десятки миллионов строк), движок будет вынужден выполнить раннюю материализацию и создать огромную промежуточную таблицу.
Кстати, такой запрос может вообще не пройти в принципе, если движок упрётся в предельную емкость доступной памяти. А может привести к очень сильному замедлению работы BI-системы. Поэтому при создании вложенных запросов нужно оценивать размеры промежуточного результата.
Частое обновление данных не так страшно, если вы используете специальные инструменты для работы в режиме Real-time. Для чего? Почему BI-платформа In-Memory OLAP не очень любят Real-time и для Real-time предлагают, по сути, отдельные инструменты. В Power BI, например, Streaming Dataset. Зачем это сделано? Почему просто не дописывать и не считать заново?
Каждый раз, когда мы что-то меняем в исходных данных, происходит серьёзная инвалидация кэша. То есть и общий кэш, и разделяемый кэш (свой для каждого пользователя), кэш под запрос — всё это приходится выкинуть и ждать, пока оно рассчитается заново. Даже добавление одной новой строки приводит к инвалидации, особенно если она реализована не слишком умно. К тому же BI-платформы чаще всего инвалидируют кэш с запасом, чтобы исключить показ пользователю неправильных данных.
Частая инвалидация ведёт к деградации производительности BI-системы, и это особенно заметно, если одновременно BI-система обрабатывает тысячи запросов. Как правило, большинство пользователей работают с готовыми дашбордами, для которых кэш — основной источник оптимизации. Когда мы проводили нагрузочное тестирование для профиля пользователя, который просто работает с дашбордом, 90-95% запросов в принципе не доходили до движка и обслуживались из кэша. Именно поэтому частая инвалидация ведет к падению производительности в 10 и более раз.
Иногда кажется, что для работы системы неважно, сколько имеется свободной оперативной памяти, лишь бы хватало общей емкости. Но на самом деле свободная память используется для буферного кэша. Можно сказать, что для In-Memory движков это не так критично, потому что они не так часто работают с жёстким диском. Но в те моменты, когда он “поднимает” данные, использует snapshot, сохраняет или загружает что-то, наличие буферного кэша оказывается очень даже важным фактором. К тому же, помимо In-Memory движка в любой BI есть и другие части системы, например, компоненты ОС. И если память кончится, они начнут резко тормозить, потому что не смогут использовать буферный кэш.
Но и это еще не все. Нехватка свободной памяти ведет к рискам просадки производительности в сложных запросах. Когда происходит создание больших объемов промежуточных данных, они тоже могут вытеснить буферный кэш, не позволяя использовать его. Что ещё хуже, такие запросы могут достичь предела доступной памяти, и вся система упадёт в swap. Это будет полный коллапс с точки зрения производительности.
Последний “вредный совет” — загружать строковые поля с высокой кардинальностью. Добавляя к датасету комментарии к заказам, сообщения из чата или что-то подобное, можно сильно просадить производительность. То, что хорошо подходит для полнотекстового поиска, плохо работает для движков In-Memory OLAP. Такие данные не дают использовать RLE, векторные инструкции. Здесь мы снова падаем в выполнение строковых операций, производительность для которых намного меньше, чем для арифметических. BI-система в принципе не всегда может создать индекс на такие строковые поля со всеми вытекающими последствиями.
Как я уже говорил, In-Memory OLAP — это продвинутая и умная технология, которая, чаще всего, «просто работает» и позволяет не задумываться о том, что внутри у BI-платформы. Но, исключения из правил случаются, и, я надеюсь, что эта статья поможет быть к ним готовым.
Всех с наступающим, и отличной производительности всем вашим сервисам в Новом Году!
Вообще, современные BI-платформы — это очень умный софт, который незаметно для пользователя делает множество оптимизаций, и чаще всего не требует каких-то особых ухищрений для настройки производительности. Но когда нагрузка становится действительно серьезной, BI-системой начинают пользоваться сотни пользователей, и решение обрабатывает сотни миллионов и миллиарды строк данных, иногда что-то идет не так.
С точки зрения бизнеса это бывает очень грустно. Какой-то пользователь создает дашборд, и всё падает. При этом увеличение объема памяти и количества процессоров не даёт почти никакого эффекта. Предотвратить или быстро решить такую проблему гораздо проще, если хотя бы в общих чертах представляешь, как система работает «под капотом».
Когда мы только начинали работать в сфере BI 5 лет назад, в основу продукта Visiology легла open-source библиотека Pentaho — Mondrian. Но достаточно быстро мы столкнулись с проблемами по части производительности и начали самостоятельно разрабатывать In-Memory OLAP движок под названием ViQube (об этом можно почитать в другой нашей статье — Как разработать BI-платформу — наш трудный, но интересный опыт). Собственно, в процессе этой разработки мы и накопили опыт, которым сейчас хотим поделиться.
Как работает OLAP
На первый взгляд, все BI-платформы выглядят одинаково: у вас есть источники информации, у вас есть инструменты загрузки, анализа и визуализации данных, а на выходе пользователь получает разнообразные отчеты — от печатных форм до дашбордов, в том числе на мобильных, на видеостенах, на любых устройствах. В своей основе все BI-инструменты используют модель данных на основе OLAP (On-Line Analytical Processing, многомерное представление данных), но техническая реализация OLAP движка (который непосредственно занимается вычислениями) может быть реализован по-разному, и от этого очень сильно зависит производительность и масштабируемость системы.
— MOLAP
Технология OLAP возникла ещё в 80-х годах. В то время процессоры были намного медленнее, да и память была в дефиците, поэтому чтобы аналитик мог реально работать с данными в онлайн-режиме, придумали такую вещь как MOLAP (Multidimensional OLAP). Идея подхода в том, что для всего многомерного куба после загрузки данных производится предрасчет: на узлах иерархий предварительно рассчитываются агрегации, чтобы под любой более или менее типовой запрос пользователя можно было получить результат запроса без необходимости пересчитывать все строки. Да, при любом изменении данных нужно долго пересчитывать куб, а объем рассчитанного куба может быть в разы больше исходного датасета, но в то время других вариантов не было. MOLAP до сих пор существует и используется, например, в SQL Server Analysis Services, но на практике его используют все реже и реже.
— ROLAP
Позже появилась реляционный OLAP, или ROLAP. Отличие от MOLAP заключается в том, что не происходит никакого предварительного расчёта агрегаций, а вычисления происходят на СУБД из бэкэнда BI-платформы. В этом случае пользователь работает с удобными инструментами, например, с конструктором дашбордов, а под капотом ROLAP-движок преобразует его запросы на лету в SQL, и они просто выполняются на какой-то СУБД.
Подобный подход характерен, например, для таких open-source систем, как Pentaho или Metabase или проприетарного SAP Business Objects, Oracle OBIEE.
У ROLAP есть целый ряд недостатков. Во-первых, если, не использовать на бэкенде специальные аналитические СУБД, такие как ClickHouse или Vertica, все будет работать ооочень медленно (дальше будет понятно, почему). Во-вторых, даже при использовании аналитической СУБД, при работе с ROLAP очень неэффективно используется кэш, потому что СУБД и BI-платформа работают отдельно друг от друга. В-третьих, поскольку не все аналитические задачи можно завернуть в SQL-запрос, ограничивается аналитическая функциональность. Но зато, на сегодняшний день ROLAP — это единственный способ работы с реально большими объемами данных, которые не помещаются в память.
— In-Memory OLAP
Если речь идет о работе с данными объемом до терабайта, как правило, используется схема In-Memory. Данные постоянно находятся в памяти, и за расчеты отвечает специальный движок. В системах Qlik — это QIX, Power BI использует SQL Server Tabular Engine, который раньше был продуктом xVelocity, но Microsoft купил эту компанию, и теперь движок является частью MS SQL Server. У нас в Visiology движок In-Memory OLAP называется ViQube.
In-Memory OLAP привлекает простотой установки и работы, подобные движки изначально интегрированы в BI-платформы и укомплектованы удобными визуальными интерфейсами настройки, загрузки данных, управления правами и т.п. За счет размещения данных в памяти и специальных оптимизаций (про них ниже) многократно растет скорость обработки, расширяются возможности для аналитиков.
При этом у подхода In-Memory есть и свои недостатки. И главный из них — это предел емкости памяти. Если объем данных измеряется в терабайтах, вам нужно либо строить дорогой кластер, либо склоняться к ROLAP. Кроме этого, при таком подходе не всегда удается минимизировать задержку отображения обновлений, потому что для этого данные приходится перегружать из источника в память.
— Гибридный OLAP
Основной схемой работы для большинства промышленных BI становится гибридная схема с одновременным использованием и In-Memory OLAP, и реляционного OLAP-движка. Горячие данные хранятся в In-Memory, холодные данные, которые не влезли в заданный объем, — в СУБД. Такое решение в QlikView, например, называется Direct Discovery, в Power BI — Direct Query. В Visiology тоже поддерживаются интеграции с несколькими СУБД, в том числе с ClickHouse.
Кстати, выбор СУБД для гибридного режима также критически важен. Если мы будем работать с PostgreSQL, в котором лежит 5 терабайт данных, аналитические запросы будут исполняться крайне медленно. И если у вас не SAP HANA, придется вручную распределять данные на холодные и горячие. Как следствие, не все аналитические функции будут доступны на полном объёме данных. Но если памяти не хватает, увы, с таким положением дел приходится мириться.
Откуда “растут” плюсы In-memory OLAP?
Для скорости работы In-Memory OLAP есть как очевидные, так и скрытые причины. Тот факт, что работа движка происходит в памяти, а она намного быстрее, чем жесткий диск (спасибо, кэп) — это только 1/10 правды. Но давайте подумаем, как работают реляционные СУБД, например, тот же PostgreSQL. Ведь он в какой-то мере тоже является In-Memory. И вообще, любая современная СУБД активно использует как блочный кэш в памяти, так и внутренний.
Когда обычной дисковой СУБД, такой как PostgreSQL, нужно считать данные с жёсткого диска, она обращается к накопителю и считывает какую-то страницу. Эта страница помещается в блочный кэш (в Linux он располагается в свободном пространстве памяти). Допустим, у нас есть 128 гигабайт памяти, и 20 из них мы занимаем софтом. Всё остальное может использоваться под блочный кэш. И если СУБД нужно будет считать с этой страницы ещё что-нибудь, она возьмет эту информацию из памяти. И от того, насколько эффективно используется кэш, зависит производительность. Если для анализа используется, скажем, 30-40 гигабайт данных, мы можем расширить емкость оперативной памяти на сервере и уже после первого чтения СУБД все данные окажутся In-Memory, а обращения к диску на чтения будут происходить лишь эпизодически.
Кроме этого, у “умных” СУБД, в том числе у Postgres, имеется механизм cache-aware управления. Они могут выбирать, что складывать в кэш, а что – нет, какие данные надо заново прочитать с диска.
Источник: www.enterprisedb.com/blog/autoprewarm-new-functionality-pgprewarm
На графике выше — влияние прогрева кэша на производительность PostgreSQL. Жёлтым показана производительность в зависимости от времени, и наглядно видно, что по мере работы пользователей СУБД считывает данные, постепенно раскладывает всё в In-Memory и достигает предела своей производительности. Если же использовать prewarm и дать Postgres команду поднять все данные в память сразу, максимальная производительность достигается сразу.
Также стоит учитывать, что мы говорим об аналитической нагрузке. Она очень сильно отличается от транзакционных задач, когда в базу нужно внести запись о покупке в интернет-магазине или считать 10 строк с историей заказов. На графике ниже показан типовой аналитический запрос из теста TPC-H. Этот тест состоит из нескольких десятков реальных аналитических запросов и широко используется для нагрузочного тестирования.
Источник: www.tpc.org/information
В SQL-запросе из теста TPC-H можно найти много чего интересного. Во-первых, запрос идет не на поля, а на агрегации. Во-вторых, здесь присутствуют линейные арифметические операции. В-третьих, здесь часто встречаются фильтры по полям с малой кардинальностью: регионы и федеральные округа, в которых работает компания, типы клиента — активный, неактивный и так далее. В-четвертых, часто используются фильтры по полю с датой. Если мы изучаем динамику выручки, то нас интересуют такие периоды как год или квартал.
На входе подобного запроса всегда очень большое количество строк — миллионы или даже миллиарды. Поэтому СУБД вынуждена делать серию полных сканирований. С другой стороны, на выходе получается небольшое количество строк, ограниченное количеством точек, которые можно отобразить на графике — чаще всего десятки или сотни значений. Зная эти особенности аналитических запросов, можно провести оптимизацию и получить прирост производительности.
In-Memory OLAP: конкретные примеры оптимизации для BI
Учитывая особенности аналитических запросов, о которых мы уже говорили ранее, для движка BI возможен целый ряд оптимизаций, причем как технических, так и эвристических. Давайте рассмотрим их подробнее.
1. Колоночное хранение данных
Это первый шаг, дающий заметный эффект. Для обычных транзакционных запросов хранение в строках подходит оптимально. Но для аналитики необходимо получать данные по столбцам. Казалось бы, какая разница, ведь все это уже In-Memory? Но на практике кроме памяти, которая быстрее дисков, у нас также есть кэш процессора, как правило, трехуровневый. Он работает намного быстрее, чем память, доступ к которой занимает примерно 200 тактов процессора.
Процессор может считать из памяти только целую страницу, которая сразу попадает в кэш того или иного уровня. И если следующее нужное значение попало в эту же страницу, мы потратим 10-40 тактов, а если нет — в 10 раз больше. При колоночном режиме хранения при запросе мы получаем страницу памяти, в которой, скорее всего, будут лежать все данные из одной колонки. Поэтому процессору во много раз реже нужно будет обращаться к основной памяти.
Источник: arstechnica.com/gadgets/2002/07/caching/2
2. Сжатие
В этой оптимизации есть свои особенности. Для дисковых СУБД — это обязательная оптимизация. Здесь мы выигрываем за счет того, что реже ходим в медленное хранилище, но также проигрываем, потому что данные надо распаковать, а это — вычислительно ёмкая операция. Для дисковых СУБД получается очень выгодно, для In-Memory — все не так очевидно, потому что читать из памяти обычно быстрее, чем заниматься распаковкой.
Источник: www.percona.com/blog/2016/03/09/evaluating-database-compression-methods
Самый быстрый из алгоритмов сжатия по скорости распаковки — LZ4. Он в среднем уменьшает размер всего в 2 раза, но зато очень быстро распаковывает, со скоростью порядка 500 мегабайт в секунду на ядро процессора. В бенчмарке на графике LZ4 вообще показал результат 3 гигабайта данных в секунду. Такая скорость дает очень хороший выигрыш для дисковых СУБД, скорость чтения для которых – те же 500 мегабайт в секунду. Но для памяти скорость передачи данных составляет десятки гигабайт в секунду, получить преимущество за счёт LZ4 оказывается сложно.
Однако не стоит забывать, что мы чаще всего работаем с данными низкой кардинальности. Например, в строке с названиями торговой точки очень часто будут повторяться одни и те же значения или их ID: “Москва, Москва, Москва, Москва…”
Источник: Guassian and speckle noise removal from ultrasound images using bivariate shrinkage by dual tree complex wavelet transform (Professor G R Sinha, 2015)
Для подобных данных есть ещё один алгоритм, который называется Run-length encoding. Он работает очень просто: строки типа ААААВВВВВСС он сжимает в виде 4A5B2C. Это прекрасный подход для данных с низкой кардинальностью, он помогает экономить память и оптимальнее использовать кэш процессора.
3. Векторные инструкции
Чтобы сложить 2 числа, мы кладём в один регистр процессора одно число, а в другой регистр — другое. Для ускорения этого процесса существуют векторные регистры и векторные операции (SIMD — Single Instruction Multiple Data). Они позволяют за одну операцию сложить сразу N чисел. Это уже очень зрелая технология, которая появилась в процессорах еще в 1993 году. Она поддерживалась еще в Pentium MMX (166 МГц — у меня такой был, до сих пор помню, как на него термопасту намазывал).
Источник: www.codetd.com/en/article/9633503
В Pentium MMX векторных регистров было 8, и они были рассчитаны только на целочисленную арифметику. На текущий момент практически во всех процессорах есть 128-битные регистры SSE и наборы инструкций. Регистры AVX уже 256-битные, а в серверах есть даже AVX 512. Они работают с числами с плавающей запятой, и их можно использовать для оптимизации аналитической нагрузки.
Источник: technews.tw/2020/07/16/linus-torvalds-avx-512-critique
При работе с AVX 512 мы можем обрабатывать в одном регистре 16 чисел со стандартной точностью. Теоретически тут можно получить хороший выигрыш, но для этого необходимо преодолеть ряд технических сложностей. Чтобы при компиляции оптимизация работала, нужно предусмотреть ее при написании кода. Для этого используются интринсики – особый набор функций, которые в явном виде указывают компилятору, какие инструкции процессора нужно использовать.
Вот пример, как для расчёта скалярного произведения используется AVX-инструкции 256-битных регистров.
На нашей практике использование именно AVX даёт от 1 до 10% прирост производительности, в зависимости от задач. Когда вы используете современную BI-систему, в зависимости от конкретного процессора, система будет применять разный код. Производительность от этого увеличивается, но не драматически, а в лишь в небольших пределах.
4. Поздняя материализация
Материализация — это процесс формирования результата, ответа на запрос. Например, простой SQL-запрос SELECT C1, С2, D1, D2 из 2 таблиц, получит 2 поля из одной и 2 поля из другой таблицы. Далее мы соединяем их по ключу — С1=D1.
В случае ранней материализации мы получаем 4 колонки и работаем с колоночной базой. То есть мы сначала берём С1 и С2, соединяем их в таблицу. Потом делаем то же самое с D1, D2 и после этого выполняем Join, то есть формируем строки из этих 2 таблиц, для которых истинно условие С1=D1.
В случае аналитической нагрузки на выходе всегда мало данных, потому что фильтры отсекают достаточно много значений. Когда выполняется JOIN, создаётся очень большая таблица, которая не нужна. Ведь на последней операции будет отброшено много данных.
При поздней материализации мы сначала разбираемся, что и в какой колонке нам нужно. Сначала выполняется операция JOIN С1 = D1, и мы выбираем нужные нам значения только из правой таблицы. Это можно сделать за один проход. А после этого можем взять из таблицы С только те поля, строки которых после JOIN остались. В итоге не нужно создавать большую промежуточную таблицу.
Конечно, такая оптимизация не сработает на любой нагрузке. Исследования Vertica, например, показывают, как многопрофильная СУБД позволяет выбирать различные стратегии материализации, в зависимости от задач. Но именно для BI характерна нагрузка, связанная с поздней материализацией, поэтому ее использование предпочтительно.
5. Эвристические оптимизации
In-Memory OLAP чаще всего является неотъемлемой частью BI-платформы, а BI-платформа прекрасно “знает”, какие данные в нее загружаются, как пользователь с ними работает. Конечно, это неочевидные вещи, они происходят “под капотом” BI-системы и не всегда даже видны, но позволяют получить хороший прирост производительности.
Во-первых, часто применяется автоматическая нормализация или денормализация. Данные с низкой кардинальностью иногда бывает выгодно нормализовывать, а иногда — наоборот. Чаще всего BI-платформы стараются максимально денормализовать таблицы. Такой подход позволяет максимально избегать достаточно тяжелых операций JOIN. Пользователь может даже не видеть этого: если мы загрузили в систему 2 таблицы и связали их по ключу, система может сразу превратить их в одну таблицу.
В некоторых случаях, наоборот, происходит автоматическая нормализация. Если поле очень жирное, например, с текстовым комментарием, держать его по всей колонке будет неоптимально. Вместо этого такое поле можно автоматически вывести в справочник. Вы будете видеть в таблице и строку, и столбец, а на самом деле данные будут находиться в отдельной таблице, а в памяти будет находиться только ID. Такие методики используются довольно часто.
6. Сортировка по календарю
Поскольку мы работаем с данными, которые практически всегда растянуты во времени, стоит учитывать интерес пользователей – а он чаще всего сконцентрирован на ближайших данных. Поэтому оказывается выгодно сортировать данные по календарному измерению. Действительно, если пользователь работает с текущим годом, зачем ему данные “с начала времён”?
Однако, если вы храните дату в виде строкового столбца, BI-система не сможет оптимизировать данные. Но если сортировка удается, иногда получается свести большой датасет к очень компактному, просто выкинув из него все года, кроме текущего.
7. Разделяемый кэш
Пользователи BI часто работают с одними и теми же данными. Поэтому хорошую эффективность показывает разделяемый кэш. Если пользователь А запустил дашборд и выполнил свой запрос, то пользователь В на том же дашборде сможет получить результат быстрее, потому что необходимые данные будут уже в кэше.
Разделяемый кэш под запросы позволяет кэшировать данные внутри запросов. Например, один пользователь запросил аналитику и отфильтровал её по отделу А, а другой хочет по отделу В. В этом случае оптимизации не получится, потому что фильтрация происходит на раннем этапе. Но в некоторых случаях и для подобных ситуаций удается оптимизировать запрос.
8. Обратный индекс
Многие BI-системы выстраивают обратный индекс для строковых полей. Он позволяет ускорить поиск с операторами по строкам. И хотя BI-системы и OLAP движок In-Memory — это не замена полнотекстовому поиску, подобные оптимизации встречаются достаточно часто.
Каков эффект?
Все перечисленные меры помогают сделать BI-систему, основанную на In-Memory OLAP, более устойчивой и производительной, не прибегая к гибридным схемам работы с подключением реляционных БД. Рост производительности сильно зависит от используемых задач, но в процессе работы над ViQube мы убедились в том, что оптимизации лучше всего закладывать на этапе исходного кода и изначально проектировать систему с учетом особенностей аналитических запросов.
Кроме этого, на своем опыте мы нашли ряд кейсов, которые позволяют легко “убить” производительность In-Memory OLAP. Можно считать этот набор “вредных советов” пасхалочкой для тех, кто дочитал до конца :)
5 способов убить производительность In-Memory OLAP
BI-система, работающая на базе In-Memory OLAP, уже по определению имеет высокую производительность — однако она не будет неубиваемой! Ниже — список из 5 “вредных советов” по In-Memory, выстраданных на своей шкуре в процессе разработки движка ViQube и его использования в реальных проектах.
1. Сложные вложенные выражения
Прекрасными убийцами производительности In-Memory систем являются запросы, в которых плохо работает векторизация. Любые вычисления с использованием нелинейных функций, которые задействуют много полей, приводят к радикальному снижению скорости работы системы.
Очень часто в своей практике я сталкивался с тем, что аналитик пишет какое-то выражение на Qlik Expressions или на DAX в Power BI, которое хорошо работает, когда в базе 10 тысяч строк. Но по мере роста масштабов производительность начинает деградировать невероятными темпами.
Обычно это происходит потому, что формула запроса сложна и не даёт движку использовать преимущества колоночного хранения векторных инструкций. Вместо этого системе приходится находить все поля по строкам, перебирать их одну за другой. В этом случае производительность падает до уровня СУБД со строчным хранением. Конец оптимизации.
2. Вложенные запросы
Вложенные запросы — крайне важная в аналитике вещь. Очень часто результатом ответа на первый запрос оказывается таблица, и по этой таблице мы производим дополнительный анализ. Например, в DAX подобный подход легко реализуется с помощью так называемых контекстов, и поэтому он весьма популярен среди аналитиков. Возможность создавать вложенные запросы есть и в других движках.
Однако пользоваться такими запросами нужно аккуратно. Ведь если первый запрос возвращает большой промежуточный результат (например, десятки миллионов строк), движок будет вынужден выполнить раннюю материализацию и создать огромную промежуточную таблицу.
Кстати, такой запрос может вообще не пройти в принципе, если движок упрётся в предельную емкость доступной памяти. А может привести к очень сильному замедлению работы BI-системы. Поэтому при создании вложенных запросов нужно оценивать размеры промежуточного результата.
3. Частое обновление данных
Частое обновление данных не так страшно, если вы используете специальные инструменты для работы в режиме Real-time. Для чего? Почему BI-платформа In-Memory OLAP не очень любят Real-time и для Real-time предлагают, по сути, отдельные инструменты. В Power BI, например, Streaming Dataset. Зачем это сделано? Почему просто не дописывать и не считать заново?
Каждый раз, когда мы что-то меняем в исходных данных, происходит серьёзная инвалидация кэша. То есть и общий кэш, и разделяемый кэш (свой для каждого пользователя), кэш под запрос — всё это приходится выкинуть и ждать, пока оно рассчитается заново. Даже добавление одной новой строки приводит к инвалидации, особенно если она реализована не слишком умно. К тому же BI-платформы чаще всего инвалидируют кэш с запасом, чтобы исключить показ пользователю неправильных данных.
Частая инвалидация ведёт к деградации производительности BI-системы, и это особенно заметно, если одновременно BI-система обрабатывает тысячи запросов. Как правило, большинство пользователей работают с готовыми дашбордами, для которых кэш — основной источник оптимизации. Когда мы проводили нагрузочное тестирование для профиля пользователя, который просто работает с дашбордом, 90-95% запросов в принципе не доходили до движка и обслуживались из кэша. Именно поэтому частая инвалидация ведет к падению производительности в 10 и более раз.
4. Маленький запас свободной памяти
Иногда кажется, что для работы системы неважно, сколько имеется свободной оперативной памяти, лишь бы хватало общей емкости. Но на самом деле свободная память используется для буферного кэша. Можно сказать, что для In-Memory движков это не так критично, потому что они не так часто работают с жёстким диском. Но в те моменты, когда он “поднимает” данные, использует snapshot, сохраняет или загружает что-то, наличие буферного кэша оказывается очень даже важным фактором. К тому же, помимо In-Memory движка в любой BI есть и другие части системы, например, компоненты ОС. И если память кончится, они начнут резко тормозить, потому что не смогут использовать буферный кэш.
Но и это еще не все. Нехватка свободной памяти ведет к рискам просадки производительности в сложных запросах. Когда происходит создание больших объемов промежуточных данных, они тоже могут вытеснить буферный кэш, не позволяя использовать его. Что ещё хуже, такие запросы могут достичь предела доступной памяти, и вся система упадёт в swap. Это будет полный коллапс с точки зрения производительности.
5. Строковые поля с высокой кардинальностью
Последний “вредный совет” — загружать строковые поля с высокой кардинальностью. Добавляя к датасету комментарии к заказам, сообщения из чата или что-то подобное, можно сильно просадить производительность. То, что хорошо подходит для полнотекстового поиска, плохо работает для движков In-Memory OLAP. Такие данные не дают использовать RLE, векторные инструкции. Здесь мы снова падаем в выполнение строковых операций, производительность для которых намного меньше, чем для арифметических. BI-система в принципе не всегда может создать индекс на такие строковые поля со всеми вытекающими последствиями.
Да пребудет с вами производительность
Как я уже говорил, In-Memory OLAP — это продвинутая и умная технология, которая, чаще всего, «просто работает» и позволяет не задумываться о том, что внутри у BI-платформы. Но, исключения из правил случаются, и, я надеюсь, что эта статья поможет быть к ним готовым.
Всех с наступающим, и отличной производительности всем вашим сервисам в Новом Году!
